Структура и метрики Query Profile
Обзор
Query Profile — это подробный отчет, который предоставляет информацию о выполнении SQL-запроса в Selena. Он п�редлагает комплексное представление о производительности запроса, включая время, затраченное на каждую операцию, объем обработанных данных и другие соответствующие метрики. Эта информация неоценима для оптимизации производительности запросов, выявления узких мест и устранения неполадок.
80% медленных запросов в реальных условиях решаются путем обнаружения одной из трех критических метрик. Эта шпаргалка поможет вам найти их, прежде чем вы утонете в цифрах.
Быстрый старт
Профилирование недавнего запроса:
1. Список недавних ID запросов
Для анализа профиля запроса необходим ID запроса. Используйте SHOW PROFILELIST;:
SHOW PROFILELIST;
SHOW PROFILELIST подробно описан в Текстовый анализ Query Profile. Обратитесь к этой странице, если вы только начинаете.
2. Откройте профиль рядом с вашим SQL
Выполните ANALYZE PROFILE FOR <query_id>\G или нажмите Profile в веб-интерфейсе CelerData.
3. Просмотрите баннер "Execution Overview"
Изучите ключевые метрики для общей производительности выполнения:
- QueryExecutionWallTime: Общее время выполнения запроса по настенным часам
- QueryPeakMemoryUsagePerNode: Пиковое использование памяти на узел, значения превышающие 80% памяти BE указывают на потенциальные риски переполнения данных или ошибок нехватки памяти (OOM)
- QueryCumulativeCpuTime / WallTime < 0.5 * num_cpu_cores означает, что CPU ожидает (вероятно, I/O или сеть)
Если ни одна из них не срабатывает, ваш запрос обычно в порядке — остановитесь здесь.
4. Углубитесь на один уровень
Определите операторы, которые потребляют больше всего времени или памяти, проанализируйте их метрики и определите основную причину для выявления узких мест производительности.
Раздел "Operator Metrics" предлагает множество рекомендаций для помощи в выявлении первопричины проблем с производительностью.
Основные концепции
Поток выполнения запроса
Компле�ксный поток выполнения SQL-запроса включает следующие этапы:
- Планирование: Запрос проходит парсинг, анализ и оптимизацию, завершающиеся генерацией плана запроса.
- Планирование: Планировщик и координатор работают вместе для распределения плана запроса по всем участвующим backend-узлам.
- Выполнение: План запроса выполняется с использованием движка конвейерного выполнения.
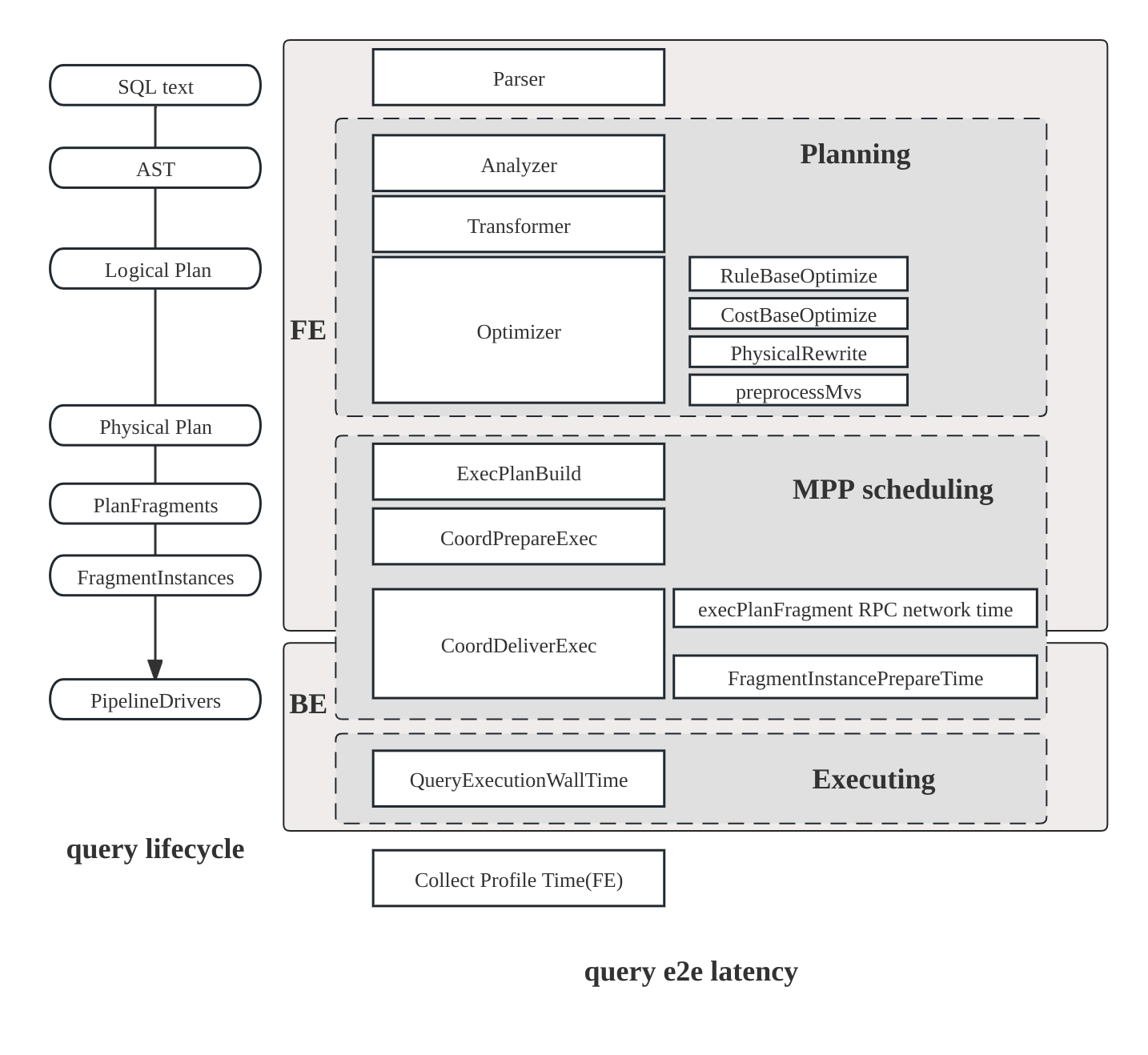
Структура плана запроса
Движок выполнения Selena разработан для выполнения запросов в распределенном режиме, и структура Query Profile отражает этот дизайн. Следующие компоненты составляют распределенный план запроса:
- Fragment: Высший уровень дерева выполнения, представляющий логическую единицу работы. Запрос может быть разделен на один или несколько фрагментов.
- FragmentInstance: Каждый фрагмент создается несколько раз, при этом каждый экземпляр (FragmentInstance) выполняется на разном вычислительном узле. Это позволяет параллельную обработку между узлами.
- Pipeline: FragmentInstance далее разделяется на несколько конвейеров, которые являются последовательностями соединенных экземпляров Operator. Конвейеры определяют путь выполнения для FragmentInstance.
- PipelineDriver: Для максимального использования вычислительных ресурсов каждый конвейер может иметь несколько экземпляров, известных как PipelineDrivers. Эти драйверы выполняют конвейер параллельно, используя несколько вычислительных ядер.
- Operator: Основная единица выполнения, экземпляр Operator является частью PipelineDriver. Операторы реализуют специфические алгоритмы, такие как агрегация, соединение или сканирование, для обработки данных.
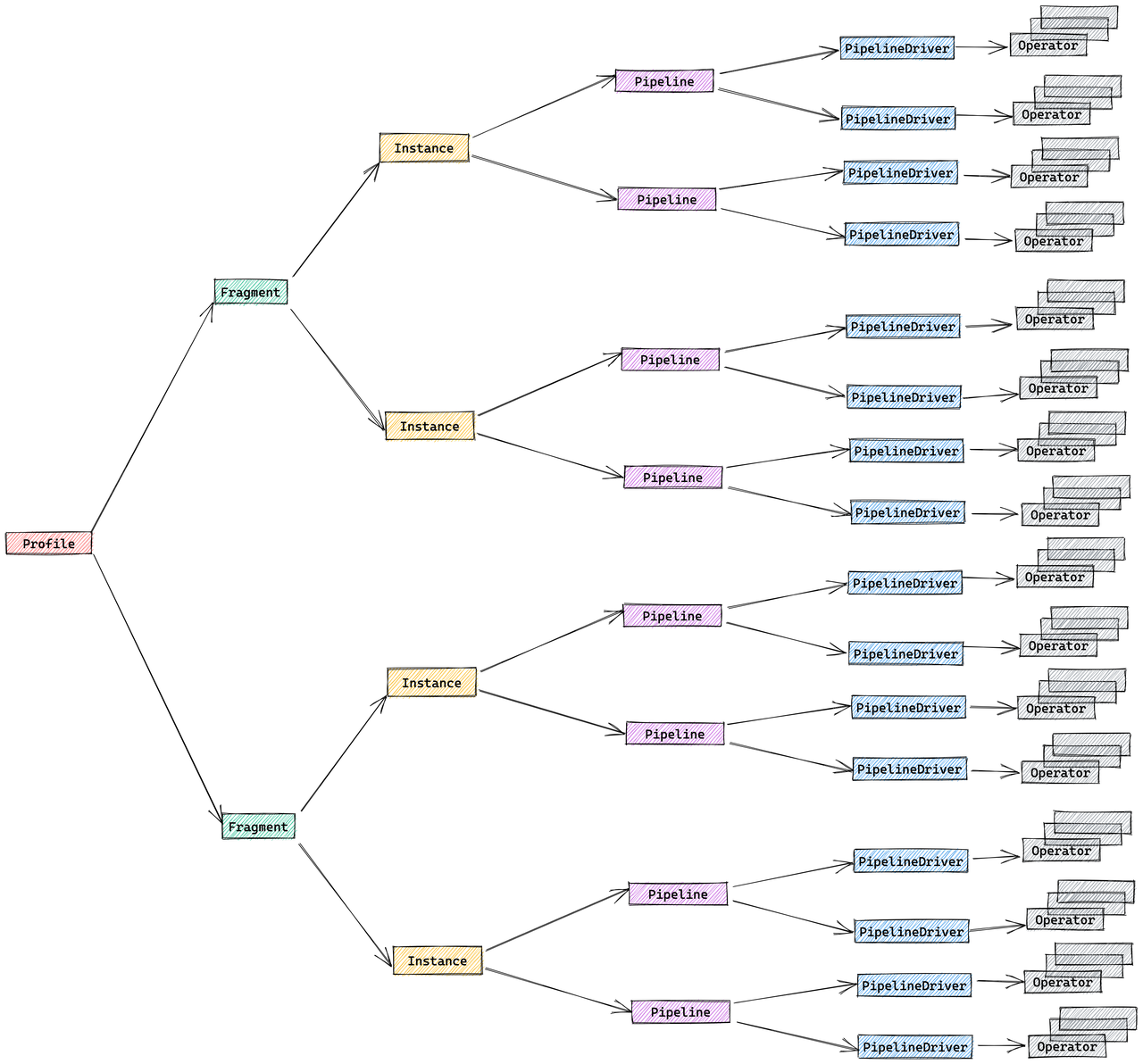
Концепции движка конвейерного выполнения
Pipeline Engine является ключевым компонентом движка выполнения Selena. Он отвечает за выполнение плана запроса параллельным и эффективным способом. Pipeline Engine разработан для обработки сложных планов запросов и больших объемов данных, обеспечивая высокую производительность и масштабируемость.
Ключевые концепции в Pipeline Engine:
- Operator: Основная единица выполнения, отвечающая за реализацию специфических алгоритмов (например, агрегация, соединение, сканирование)
- Pipeline: Последовательность соединенных экземпляров Operator, представляющая путь выполнения
- PipelineDriver: Несколько экземпляров конвейера для параллельного выполнения
- Schedule: Неблокирующее планирование конвейеров с использованием пользовательского разделения времени
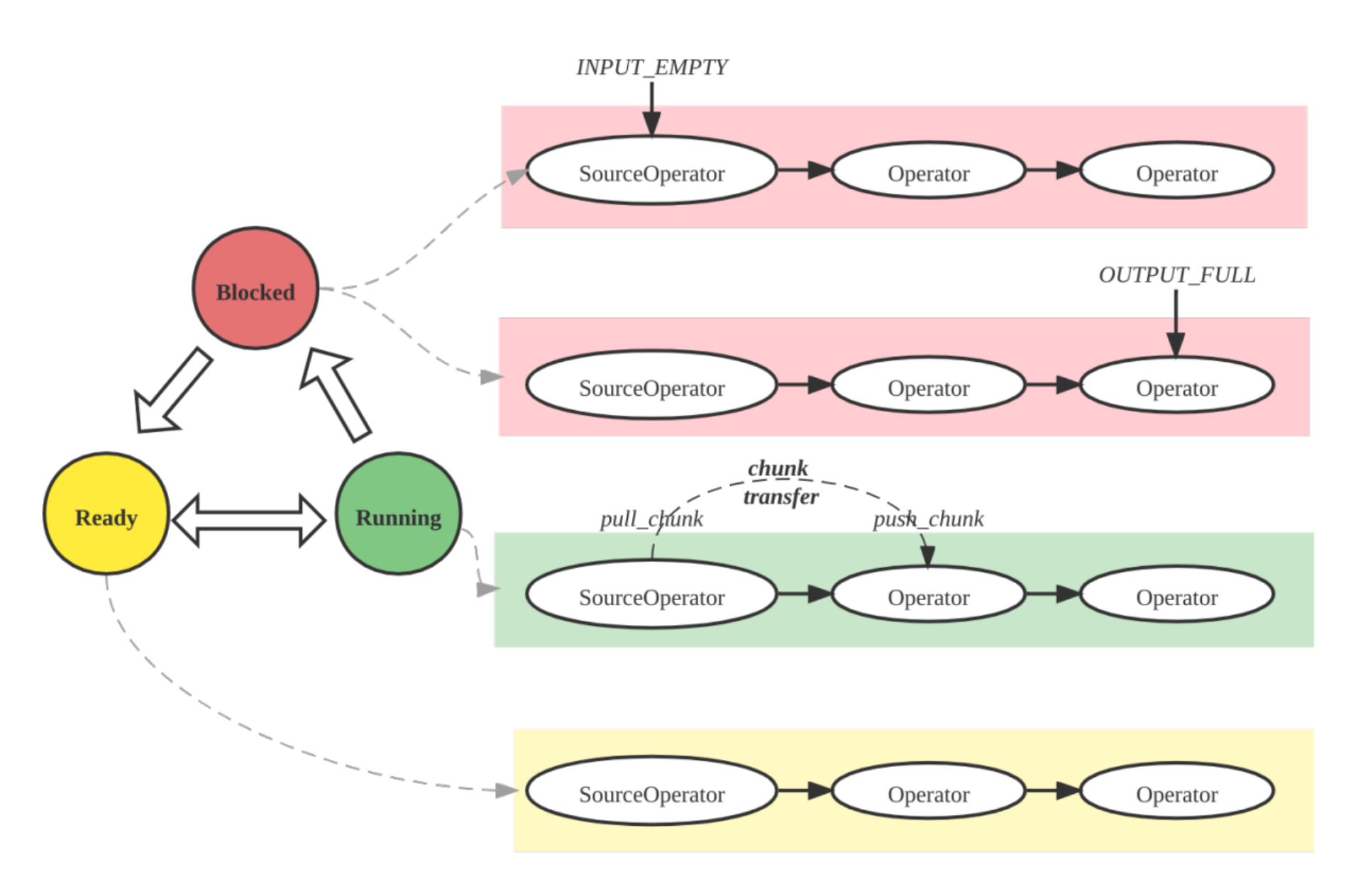
Стратегия объединения метрик
По умолчанию Selena объединяет слои FragmentInstance и PipelineDriver для уменьшения объема профиля, что приводит к упрощенной трехслойной структуре:
- Fragment
- Pipeline
- Operator
Вы можете контролировать это поведение объединения через переменную сессии pipeline_profile_level:
1(По умолчанию): Объединенная трехслойная структура2: Оригинальная пятислойная структура- Другие значения: Обрабатываются как
1
При объединении метрик используются разные стратегии в зависимости от типа метрики:
-
Временные метрики: Берется среднее значение
- Пример:
OperatorTotalTime— это среднее время потребления __MAX_OF_OperatorTotalTimeи__MIN_OF_OperatorTotalTimeзаписывают крайние значения
- Пример:
-
Не временные метрики: Суммируются значения
- Пример:
PullChunkNum— это сумма по всем экземплярам __MAX_OF_PullChunkNumи__MIN_OF_PullChunkNumзаписывают крайние значения
- Пример:
-
Константные метрики: Одинаковое значение для всех экземпляров (например,
DegreeOfParallelism)
Значительные различия между значениями MIN и MAX часто указывают на перекос данных, особенно в операциях агрегации и соединения.
Метрики Query Profile
Сводные метрики
Базовая информация о выполнении запроса:
| Метрика | Описание |
|---|---|
| Total | Общее время, потребленное запросом, включая длительность фаз Planning, Executing и Profiling. |
| Query State | Состояние запроса, возможные состояния включают Finished, Error и Running. |
| Query ID | Уникальный идентификатор запроса. |
| Start Time | Временная метка начала запроса. |
| End Time | Временная метка окончания запроса. |
| Total | Общая длительность запроса. |
| Query Type | Тип запроса. |
| Query State | Текущее состояние запроса. |
| Selena Version | Версия используемой Selena. |
| User | Пользователь, выполнивший запрос. |
| Default Db | База данных по умолчанию, используемая для запроса. |
| Sql Statement | Выполненный SQL-оператор. |
| Variables | Важные переменные, используемые для запроса. |
| NonDefaultSessionVariables | Не по умолчанию переменные сессии, используемые для запроса. |
| Collect Profile Time | Время, затраченное на сбор профиля. |
| IsProfileAsync | Указывает, был ли сбор профиля асинхронным. |
Метрики планировщика
Предоставляет комплексный обзор планировщика. Обычно, если общее время, затраченное на планировщик, составляет менее 10 мс, это не вызывает беспокойства.
В определенных сценариях планировщику может потребоваться больше времени:
- Сложные запросы могут потребовать дополнительного времени для парсинга и оптимизации для обеспечения оптимального плана выполнения.
- Наличие многочисленных материализованных представлений может увеличить время, необходимое для перезаписи запроса.
- Когда несколько одновременных запросов исчерпывают системные ресурсы и используется очередь запросов, время
Pendingможет быть продлено. - Запросы, включающие внешние таблицы, могут потребовать дополнительного времени для связи с внешним сервером метаданных.
Пример:
- -- Parser[1] 0
- -- Total[1] 3ms
- -- Analyzer[1] 0
- -- Lock[1] 0
- -- AnalyzeDatabase[1] 0
- -- AnalyzeTemporaryTable[1] 0
- -- AnalyzeTable[1] 0
- -- Transformer[1] 0
- -- Optimizer[1] 1ms
- -- MVPreprocess[1] 0
- -- MVTextRewrite[1] 0
- -- RuleBaseOptimize[1] 0
- -- CostBaseOptimize[1] 0
- -- PhysicalRewrite[1] 0
- -- DynamicRewrite[1] 0
- -- PlanValidate[1] 0
- -- InputDependenciesChecker[1] 0
- -- TypeChecker[1] 0
- -- CTEUniqueChecker[1] 0
- -- ColumnReuseChecker[1] 0
- -- ExecPlanBuild[1] 0
- -- Pending[1] 0
- -- Prepare[1] 0
- -- Deploy[1] 2ms
- -- DeployLockInternalTime[1] 2ms
- -- DeploySerializeConcurrencyTime[2] 0
- -- DeployStageByStageTime[6] 0
- -- DeployWaitTime[6] 1ms
- -- DeployAsyncSendTime[2] 0
- DeployDataSize: 10916
Reason:
Метрики обзора выполнения
Высокоуровневая статистика выполнения:
| Метрика | Описание | Эмпирическое правило |
|---|---|---|
| FrontendProfileMergeTime | Время обработки профиля на стороне FE | < 10мс нормально |
| QueryAllocatedMemoryUsage | Общая выделенная память по узлам | |
| QueryDeallocatedMemoryUsage | Общая освобожденная память по узлам | |
| QueryPeakMemoryUsagePerNode | Максимальная пиковая память на узел | < 80% емкости нормально |
| QuerySumMemoryUsage | Общая пиковая память по узлам | |
| QueryExecutionWallTime | Время выполнения по настенным часам | |
| QueryCumulativeCpuTime | Общее время CPU по узлам | Сравните с walltime * totalCpuCores |
| QueryCumulativeOperatorTime | Общее время выполнения операторов | Знаменатель для процентов времени операторов |
| QueryCumulativeNetworkTime | Общее сетевое время узлов Exchange | |
| QueryCumulativeScanTime | Общее время I/O узлов Scan | |
| QueryPeakScheduleTime | Максимальное ScheduleTime конвейера | < 1с нормально для простых запросов |
| QuerySpillBytes | Данные, сброшенные на диск | < 1ГБ нормально |
Метрики фрагментов
Детали выполнения на уровне фрагментов:
| Метрика | Описание |
|---|---|
| InstanceNum | Количество FragmentInstances |
| InstanceIds | ID всех FragmentInstances |
| BackendNum | Количество участвующих BE |
| BackendAddresses | Адреса BE |
| FragmentInstancePrepareTime | Длительность фазы подготовки фрагмента |
| InstanceAllocatedMemoryUsage | Общая выделенная память для экземпляров |
| InstanceDeallocatedMemoryUsage | Общая освобожденная память для экземпляров |
| InstancePeakMemoryUsage | Пиковая память по экземплярам |
Метрики конвейера
Детали выполнения конвейера и взаимосвязи:
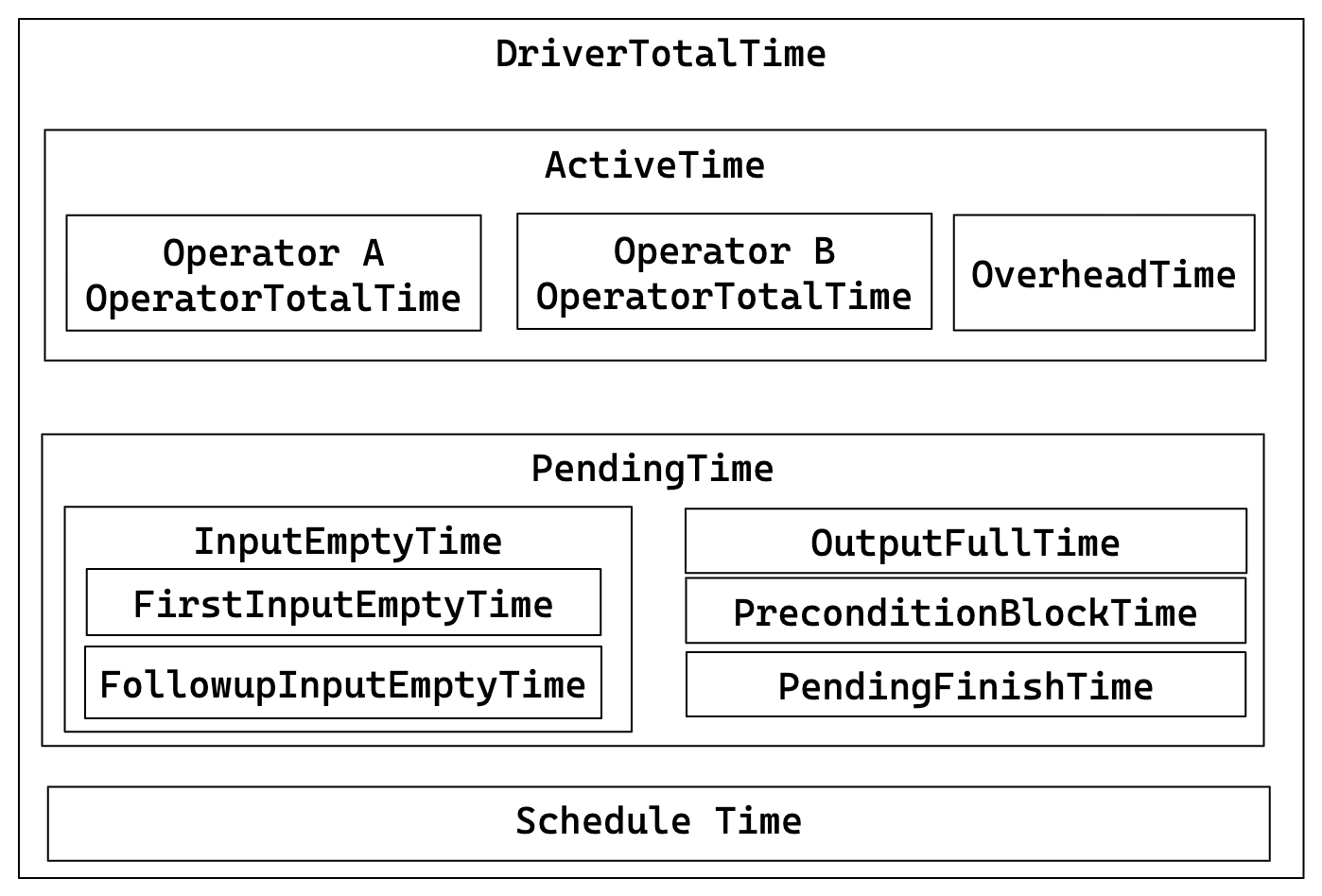
Ключевые взаимосвязи:
- DriverTotalTime = ActiveTime + PendingTime + ScheduleTime
- ActiveTime = ∑ OperatorTotalTime + OverheadTime
- PendingTime = InputEmptyTime + OutputFullTime + PreconditionBlockTime + PendingFinishTime
- InputEmptyTime = FirstInputEmptyTime + FollowupInputEmptyTime
| Метрика | Описание |
|---|---|
| DegreeOfParallelism | Степень параллелизма выполнения конвейера. |
| TotalDegreeOfParallelism | Сумма степеней параллелизма. Поскольку один и тот же Pipeline может выполняться на нескольких машинах, �этот элемент агрегирует все значения. |
| DriverPrepareTime | Время, затраченное на фазу подготовки. Эта метрика не включена в DriverTotalTime. |
| DriverTotalTime | Общее время выполнения Pipeline, исключая время, затраченное на фазу подготовки. |
| ActiveTime | Время выполнения Pipeline, включая время выполнения каждого оператора и общие накладные расходы фреймворка, такие как время, затраченное на вызов методов типа has_output, need_input и т.д. |
| PendingTime | Время, когда Pipeline заблокирован от планирования по различным причинам. |
| InputEmptyTime | Время, когда Pipeline заблокирован из-за пустой входной очереди. |
| FirstInputEmptyTime | Время, когда Pipeline впервые заблокирован из-за пустой входной очереди. Первое время блокировки рассчитывается отдельно, поскольку первая блокировка в основном вызвана зависимостями Pipeline. |
| FollowupInputEmptyTime | Время, когда Pipeline впоследствии заблокирован из-за пустой входной очереди. |
| OutputFullTime | Время, когда Pipeline заблокирован из-за полной выходной очереди. |
| PreconditionBlockTime | Время, когда Pipeline заблокирован из-за невыполненных зависимостей. |
| PendingFinishTime | Время, когда Pipeline заблокирован в ожидании завершения асинхронных задач. |
| ScheduleTime | Время планирования Pipeline, от входа в очередь готовности до планирования для выполнения. |
| BlockByInputEmpty | Количество раз, когда конвейер заблокирован из-за InputEmpty. |
| BlockByOutputFull | Количество раз, когда конвейер заблокирован из-за OutputFull. |
| BlockByPrecondition | Количество раз, когда конвейер заблокирован из-за невыполненных предварительных условий. |
Метрики операторов
| Метрика | Описание |
|---|---|
| PrepareTime | Время, затраченное на подготовку. |
| OperatorTotalTime | Общее время, потребленное Operator. Удовлетворяет уравнению: OperatorTotalTime = PullTotalTime + PushTotalTime + SetFinishingTime + SetFinishedTime + CloseTime. Исключает время, затраченное на подготовку. |
| PullTotalTime | Общее время, которое Operator тратит на выполнение push_chunk. |
| PushTotalTime | Общее время, которое Operator тратит на выполнение pull_chunk. |
| SetFinishingTime | Об�щее время, которое Operator тратит на выполнение set_finishing. |
| SetFinishedTime | Общее время, которое Operator тратит на выполнение set_finished. |
| PushRowNum | Кумулятивное количество входных строк для Operator. |
| PullRowNum | Кумулятивное количество выходных строк для Operator. |
| JoinRuntimeFilterEvaluate | Количество раз оценки Join Runtime Filter. |
| JoinRuntimeFilterHashTime | Время, затраченное на вычисление хеша для Join Runtime Filter. |
| JoinRuntimeFilterInputRows | Количество входных строк для Join Runtime Filter. |
| JoinRuntimeFilterOutputRows | Количество выходных строк для Join Runtime Filter. |
| JoinRuntimeFilterTime | Время, затраченное на Join Runtime Filter. |
Scan Operator
Для облегчения лучшего понимания различных метрик в Scan Operator, следующая диаграмма демонстрирует связи между этими метриками и структурами хранения.
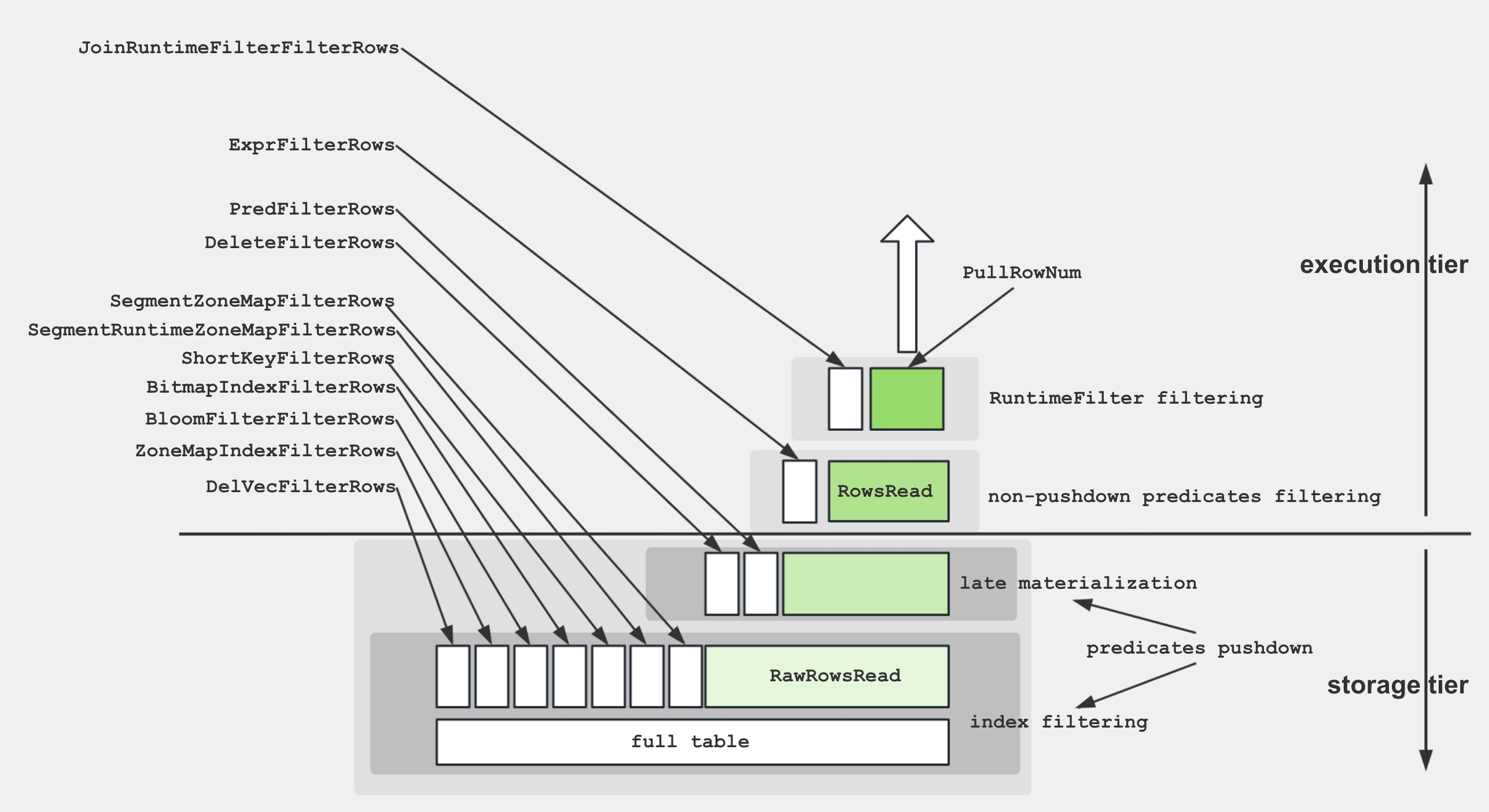
Для извлечения данных с диска и применения предикатов движок хранения использует н�есколько техник:
- Хранение данных: Закодированные и сжатые данные хранятся на диске в сегментах, сопровождаемых различными индексами.
- Фильтрация индексов: Движок использует индексы, такие как BitmapIndex, BloomfilterIndex, ZonemapIndex, ShortKeyIndex и NGramIndex, для пропуска ненужных данных.
- Pushdown предикаты: Простые предикаты, такие как
a > 1, проталкиваются вниз для оценки на конкретных столбцах. - Поздняя материализация: Только необходимые столбцы и отфильтрованные строки извлекаются с диска.
- Не-Pushdown предикаты: Предикаты, которые не могут быть протолкнуты вниз, оцениваются.
- Выражение проекции: Выражения, такие как
SELECT a + 1, вычисляются.
Общие узкие места производительности и их решения:
Тяжелый Raw I/O или медленное хранилище
Критические метрики / симптомы: BytesRead, RawRowsRead, CompressedBytesRead, ScanTime, IOTaskExecTime доминируют
Почему это замедляет OLAP сканирование: Пропускная способность чтения диска (или объектного хранилища) становится ограничением
Решения: Поместите горячие данные на NVMe/SSD, включите кеш хранилища
Плохой предикат
Критические метрики / симптомы: PushdownPredicates≈0; ExprFilterRows доминирует; LIKE '%x%' или другие сложные предикаты
Почему это замедляет OLAP сканирование: Больше строк поступает в пул потоков CPU, поскольку фильтры не применяются на уровне хранения
Решения: Перепишите фильтры на простые сравнения, создайте целевые MV/индексы
Низкий DOP или насыщение пула потоков
Критические метрики / симптомы: Высокий IOTaskWaitTime; низкий PeakIOTasks
Почему это замедляет OLAP сканирование: Слишком мало параллельных задач сканирования или потоки заблокированы в ожидании слотов I/O
Решения: Увеличьте пропускную способность диска или расширьте кеш
Перекос Tablet / данных между BE
Критические метрики / симптомы: Большой разрыв max-min для OperatorTotalTime или BytesRead; один tablet владеет большинством данных
Почему это замедляет OLAP сканирование: Один поток выполняет непропорциональную работу, все остальные простаивают
Решения: Hash-bucket на ключе высокой кардинальности; увеличьте количество buckets
Фрагментированные Rowsets и крошечные сегменты
Критические метрики / симптомы: Высокий RowsetsReadCount / SegmentsReadCount; долгое время SegmentInit
Почему это замедляет OLAP сканирование: Много маленьких файлов заставляют часто выполнять вызовы open/seek
Решения: Увеличьте потоки компакций или выполните ручные компакции; пакетируйте мини-загрузки
Высокое количество мягко удаленных записей
Критические метрики / симптомы: Высокий DeleteFilterRows
Почему это замедляет OLAP сканиров�ание: Мягкое удаление будет применять предикат удаления при чтении
Решения: Компактируйте данные; уменьшите частоту операций удаления
Scan Operator использует дополнительный пул потоков для выполнения IO задач. Поэтому взаимосвязь между временными метриками для этого узла показана ниже:

OLAP Scan Operator
OLAP_SCAN Operator отвечает за чтение данных из нативных таблиц Selena.
| Метрика | Описание |
|---|---|
| Table | Имя таблицы. |
| Rollup | Имя материализованного представления. Если материализованное представление не найдено, оно эквивалентно имени таблицы. |
| SharedScan | Включена ли переменная сессии enable_shared_scan. |
| TabletCount | Количество tablets. |
| MorselsCount | Количество morsels, которые являются базовой единицей выполнения IO. |
| PushdownPredicates | Количество pushdown предикатов. |
| Predicates | Выражения предикатов. |
| BytesRead | Размер прочитанных данных. |
| CompressedBytesRead | Размер сжатых данных, прочитанных с диска. |
| UncompressedBytesRead | Размер несжатых данных, прочитанных с диска. |
| RowsRead | Количество прочитанных строк (после фильтрации предикатов). |
| RawRowsRead | Количество сырых прочитанных строк (до фильтрации предикатов). |
| ReadPagesNum | Количество прочитанных страниц. |
| CachedPagesNum | Количество кешированных страниц. |
| ChunkBufferCapacity | Емкость Chunk Buffer. |
| DefaultChunkBufferCapacity | Емкость Chunk Buffer по умолчанию. |
| PeakChunkBufferMemoryUsage | Пиковое использование памяти Chunk Buffer. |
| PeakChunkBufferSize | Пиковый размер Chunk Buffer. |
| PrepareChunkSourceTime | Время, затраченное на подготовку Chunk Source. |
| ScanTime | Кумулятивное время сканирования. Операции сканирования выполняются в асинхронном пуле потоков I/O. |
| IOTaskExecTime | Время выполнения IO задач. |
| IOTaskWaitTime | Время ожидания от успешной отправки до запланированного выполнения IO задач. |
| SubmitTaskCount | Количество раз отправки IO задач. |
| SubmitTaskTime | Время, затраченное на от�правку задач. |
| PeakIOTasks | Пиковое количество IO задач. |
| PeakScanTaskQueueSize | Пиковый размер очереди IO задач. |
Connector Scan Operator
Похож на OLAP_SCAN operator, но используется для сканирования внешних таблиц, таких как Iceberg/Hive/Hudi/Delta.
| Метрика | Описание |
|---|---|
| DataSourceType | Тип источника данных, может быть HiveDataSource, ESDataSource и так далее. |
| Table | Имя таблицы. |
| TabletCount | Количество tablets. |
| MorselsCount | Количество morsels. |
| Predicates | Выражение предиката. |
| PredicatesPartition | Выражение предиката, применяемое к разделам. |
| SharedScan | Включена ли переменная сессии enable_shared_scan. |
| ChunkBufferCapacity | Емкость Chunk Buffer. |
| DefaultChunkBufferCapacity | Емкость Chunk Buffer по умолчанию. |
| PeakChunkBufferMemoryUsage | Пиковое использование памяти Chunk Buffer. |
| PeakChunkBufferSize | Пиковый размер Chunk Buffer. |
| PrepareChunkSourceTime | Время, затраченное на подготовку Chunk Source. |
| ScanTime | Кумулятивное время сканирования. Операция сканирования выполняется в асинхронном пуле потоков I/O. |
| IOTaskExecTime | Время выполнения I/O задач. |
| IOTaskWaitTime | Время ожидания от успешной отправки до запланированного выполнения IO задач. |
| SubmitTaskCount | Количество раз отправки IO задач. |
| SubmitTaskTime | Время, затраченное на отправку задач. |
| PeakIOTasks | Пиковое количество IO задач. |
| PeakScanTaskQueueSize | Пиковый размер очереди IO задач. |
Exchange Operator
Exchange Operator отвечает за передачу данных между узлами BE. Может быть несколько видов операций exchange: GATHER/BROADCAST/SHUFFLE.
Типичные сценарии, которые могут сделать Exchange Operator узким местом запроса:
- Broadcast Join: Это подходящий метод для небольшой таблицы. Однако в исключительных случаях, когда оптимизатор выбирает неоптимальный план запроса, это может привести к значительному увеличению пропускной способности сети.
- Shuffle Aggregation/Join: Перемешивание большой таблицы может привести к значительному ув�еличению пропускной способности сети.
Exchange Sink Operator
| Метрика | Описание |
|---|---|
| ChannelNum | Количество каналов. Обычно количество каналов равно количеству получателей. |
| DestFragments | Список ID целевых FragmentInstance. |
| DestID | ID целевого узла. |
| PartType | Режим распределения данных, включая: UNPARTITIONED, RANDOM, HASH_PARTITIONED и BUCKET_SHUFFLE_HASH_PARTITIONED. |
| SerializeChunkTime | Время, затраченное на сериализацию chunks. |
| SerializedBytes | Размер сериализованных данных. |
| ShuffleChunkAppendCounter | Количество операций Chunk Append, когда PartType равен HASH_PARTITIONED или BUCKET_SHUFFLE_HASH_PARTITIONED. |
| ShuffleChunkAppendTime | Время, затраченное на операции Chunk Append, когда PartType равен HASH_PARTITIONED или BUCKET_SHUFFLE_HASH_PARTITIONED. |
| ShuffleHashTime | Время, затраченное на вычисление хеша, когда PartType равен HASH_PARTITIONED или BUCKET_SHUFFLE_HASH_PARTITIONED. |
| RequestSent | Количество отправленных пакетов данных. |
| RequestUnsent | Количество неотправленных пакетов данных. Эта метрика не равна нулю при наличии логики короткого замыкания; в противном случае она равна нулю. |
| BytesSent | Размер отправленных данных. |
| BytesUnsent | Размер неотправленных данных. Эта метрика не равна нулю при наличии логики короткого замыкания; в противном случае она равна нулю. |
| BytesPassThrough | Если целевой узел является текущим узлом, данные не будут передаваться по сети, что называется passthrough данными. Эта метрика указывает размер таких passthrough данных. Passthrough контролируется enable_exchange_pass_through. |
| PassThroughBufferPeakMemoryUsage | Пиковое использование памяти PassThrough Buffer. |
| CompressTime | Время сжатия. |
| CompressedBytes | Размер сжатых данных. |
| OverallThroughput | Скорость пропускной способности. |
| NetworkTime | Время, затраченное на передачу пакетов данных (исключая время обработки после получения). |
| NetworkBandwidth | Оценочная пропускная способность сети. |
| WaitTime | Время ожидания из-за полной очереди отправителя. |
| OverallTime | Общее время для всего процесса передачи, то есть от отправки первого пакета данных до подтверждения правильного получения последнего пак�ета данных. |
| RpcAvgTime | Среднее время для RPC. |
| RpcCount | Общее количество RPC. |
Exchange Source Operator
| Метрика | Описание |
|---|---|
| RequestReceived | Размер полученных пакетов данных. |
| BytesReceived | Размер полученных данных. |
| DecompressChunkTime | Время, затраченное на распаковку chunks. |
| DeserializeChunkTime | Время, затраченное на десериализацию chunks. |
| ClosureBlockCount | Количество заблокированных Closures. |
| ClosureBlockTime | Время блокировки для Closures. |
| ReceiverProcessTotalTime | Общее время, затраченное на обработку на стороне получателя. |
| WaitLockTime | Время ожидания блокировки. |
Aggregate Operator
 Aggregate Operator отвечает за выполнение агрегатных функций,
Aggregate Operator отвечает за выполнение агрегатных функций, GROUP BY и DISTINCT.
Множественные формы алгоритма агрегации
| Форма | Когда планировщик выбирает её | Внутренняя структура данных | Особенности / предостережения |
|---|---|---|---|
| Hash aggregation | ключи помещаются в память; кардинальность не экстремальная | Компактная хеш-таблица с SIMD зондированием | путь по умолчанию, отличный для умеренного количества ключей |
| Sorted aggregation | входные данные уже упорядочены по ключам GROUP BY | Простое сравнение строк + текущее состояние | нулевая стоимость хеш-таблицы, часто в 2-3 раза быстрее при тяжелых перекосах зондирования |
| Spillable aggregation (3.2+) | хеш-таблица превышает лимит памяти | Гибридный hash/merge с разделами сброса на диск | предотвращает OOM, сохраняет параллелизм конвейера |
Многоэтапная распределенная агрегация
В Selena агрегация реализована распределенным способом, который может быть многоэтапным в зависимости от шаблона запроса и решения оптимизатора.
┌─────────┐ ┌──────────┐ ┌────────────┐ ┌────────────┐
│ Stage 0 │ local │ Stage 1 │ shard/ │ Stage 2 │ gather/│ Stage 3 │ final
│ Partial │───► │ Update │ hash │ Merge │ shard │ Finalize │ output
└─────────┘ └──────────┘ └────────────┘ └────────────┘
| Этапы | Когда используется | Что происходит |
|---|---|---|
| Одноэтапный | DISTRIBUTED BY является подмножеством GROUP BY, разделы размещены совместно | Частичные агрегаты сразу становятся финальным результатом. |
| Двухэтапный (локальный + глобальный) | Типичный распределенный GROUP BY | Этап 0 внутри каждого BE адаптивно сворачивает дубликаты; Этап 1 перемешивает данные на основе GROUP BY, затем выполняет глобальную агрегацию |
| Трехэтапный (локальный + shuffle + финальный) | Тяжелый DISTINCT и высококардинальный GROUP BY | Этап 0 как выше; Этап 1 перемешивает по GROUP BY, затем агрегирует по GROUP BY и DISTINCT; Этап 2 объединяет частичное состояние как GROUP BY |
| Четырехэтапный (локальный + частичный + промежуточный + финальный) | Тяжелый DISTINCT и низкокардинальный GROUP BY | Вводит дополнительный этап для перемешивания по GROUP BY и DISTINCT, чтобы избежать узкого места единой точки |
Общие узкие места производительности и их решения:
Причина узкого места
Высококардинальный GROUP BY → переразмерная хеш-таблица
Критические метрики / симптомы: HashTableSize, HashTableMemoryUsage и AggComputeTime раздуваются; запрос приближается к лимиту памяти
Почему это вредит операторам Agg: Hash-aggregate создает одну запись на группу; если миллионы групп попадают в RAM, хеш-таблица становится ограниченной по CPU и памяти и может даже переполниться
Решения: Включите sorted streaming aggregate; добавьте предварительно агрегированные MV или roll-ups; уменьшите ширину ключа / приведите к INT
Перекошенное перемешивание данных между частичными → финальными этапами
Критические метрики / симптомы: Огромный разрыв в HashTableSize или InputRowCount между экземплярами; AggComputeTime одного фрагмента затмевает другие
Почему эт�о вредит операторам Agg: Один backend получает большинство горячих ключей и блокирует конвейер
Решения: Добавьте salt столбец в агрегацию; используйте подсказку DISTINCT [skew]
Дорогие или DISTINCT-стильные агрегатные функции (например, ARRAY_AGG, HLL_UNION, BITMAP_UNION, COUNT(DISTINCT))
Критические метрики / симптомы: AggregateFunctions доминирует время оператора; CPU все еще около 100% после завершения построения хеша
Почему это вредит операторам Agg: Функции агрегации с тяжелым состоянием хранят значительные эскизы и выполняют SIMD-тяжелые циклы каждую строку
Решения: Предварительно вычислите HLL/Bitmap столбцы при загрузке; используй�те approx_count_distinct или multi_distinct_* где позволяет точность;
Плохая агрегация первого этапа (частичная)
Критические метрики / симптомы: Очень большой InputRowCount, но AggComputeTime скромный; PassThroughRowCount высокий; upstream EXCHANGE показывает массивный BytesSent
Почему это вредит операторам Agg: Если частичная агрегация на каждом BE не предварительно агрегирует набор данных хорошо, большинство сырых строк проходят по сети и накапливаются в финальном AGG
Решения: Подтвердите, что план показывает двух- или трехэтапную агрегацию; перепишите запрос на простые ключи GROUP BY, чтобы оптимизатор мог протолкнуть частичный AGG; установите streaming_preaggregation_mode = 'force_preaggregation'
Тяжелая оценка выражений на ключах GROUP BY
Критические метрики / симптомы: ExprComputeTime высокий относительно AggComputeTime
Почему это вредит операторам Agg: Сложные функции на каждой строке перед хешированием доминируют CPU
Решения: Материализуйте вычисленные ключи в подзапросе или генерируемом столбце; используйте словарь столбцов / предварительно закодированные значения; проецируйте downstream вместо этого
Список метрик
| Метрика | Описание |
|---|---|
GroupingKeys | Столбцы GROUP BY. |
AggregateFunctions | Время, затраченное на вычисления агрегатных функций. |
AggComputeTime | Время для AggregateFunctions + Group By. |
ChunkBufferPeakMem | Пиковое использование памяти Chunk Buffer. |
ChunkBufferPeakSize | Пиковый размер Chunk Buffer. |
ExprComputeTime | Время для вычисления выражений. |
ExprReleaseTime | Время для освобождения выражений. |
GetResultsTime | Время для извлечения резуль�татов агрегации. |
HashTableSize | Размер Hash Table. |
HashTableMemoryUsage | Размер памяти Hash Table. |
InputRowCount | Количество входных строк. |
PassThroughRowCount | В режиме Auto количество строк данных, обработанных в потоковом режиме после низкой агрегации, приводящей к деградации в потоковый режим. |
ResultAggAppendTime | Время, затраченное на добавление столбцов результата агрегации. |
ResultGroupByAppendTime | Время, затраченное на добавление столбцов Group By. |
ResultIteratorTime | Время для итерации по Hash Table. |
StreamingTime | Время обработки в потоковом режиме. |
Join Operator
Join Operator отвечает за реализацию явных соединений или неявных соединений.
Во время выполнения оператор соединения разделяется на фазы Build (построение хеш-таблицы) и Probe, которые выполняются параллельно внутри движка конвейера. Векторные chunks (до 4096 строк) пакетно хешируются с SIMD; потребляемые ключи генерируют runtime фильтры — Bloom или IN фильтры — проталкиваемые обратно к upstream сканированиям для раннего сокращения входных данных probe.
Стратегии соединения
Selena полагается на векторизованное, дружественное к конвейеру ядро hash-join, которое может быть подключено к четырем физическим стратегиям, которые оптимизатор на основе стоимости взвешивает во время планирования:
| Стратегия | Когда оптимизатор выбирает её | Что делает её быстрой |
|---|---|---|
| Colocate Join | Обе таблицы принадлежат одной и той же группе размещения (идентичные ключи bucket, количество bucket и макет реплик). | Нет сетевого перемешивания: каждый BE соединяет только свои локальные buckets. |
| Bucket-Shuffle Join | Одна из таблиц соединения имеет тот же ключ bucket, что и ключ соединения | Нужно перемешать только одну таблицу соединения, что может снизить сетевые затраты |
| Broadcast Join | Сторона Build очень мала (пороги строк/байтов или явная подсказка). | Маленькая таблица реплицируется на каждый узел probe; избегает перемешивания бо�льшой таблицы. |
| Shuffle (Hash) Join | Общий случай, ключи не выровнены. | Hash-разделение каждой строки по ключу соединения, чтобы probes были сбалансированы между BE. |
Когда соединения становятся узким местом
Таблица Build-стороны слишком велика для RAM
Симптомы профиля / горячие метрики: BuildRows, HashTableSize, BuildHashTableTime доминируют; память близка к лимиту или переполняется
Почему это вредит: Хеш-таблица должна находиться в памяти, может стать медленной, если не помещается в кеш CPU
Решения:
- меньшая таблица как сторона build
- Добавьте предварительную агрегацию или селективную проекцию
- Увеличьте память запроса/BE или включите hash-spill
Большое время probe соединения
Симптомы профиля / горячие метрики: Высокий SearchHashTableTime
Почему это вредит: Неэффективная кластеризация данных может привести к плохой локальности кеша CPU
Решения: Оптимизируйте кластеризацию данных, сортируя таблицу probe по ключам соединения
Избыточные выходные столбцы
Симптомы профиля / горячие метрики: Высокий OutputBuildColumnTime или OutputProbeColumnTime
Почему это вредит: Обработка многочисленных выходных столбцов требует существенного копирования данных, что может быть интенсивным по CPU
Решения: Оптимизируйте выходные столбцы, уменьшив их количество; исключите тяжелые столбцы из вывода; рассмотрите получение ненужных столбцов после соединения
Перекос данных после перемешивания
Симптомы профиля / горячие метрики: ProbeRows одного фрагмента ≫ других; OperatorTotalTime сильно несбалансирован
Почему это вредит: Один BE получает большинство горячих ключей; другие простаивают
Решения:
- Используйте ключ более высокой кардинальности
- дополните составной ключ (concat(key,'-',mod(id,16)))
Трансляция не-такой-маленькой таблицы
Симптомы профиля / горячие метрики: Тип соединения BROADCAST; BytesSent и SendBatchTime взлетают на каждом BE
Почему это вредит: O(N²) сетевой трафик и десериализация
Решения:
- Позвольте оптимизатору выбрать shuffle (
SET broadcast_row_limit = lower) - Принудительная подсказка shuffle
- Анализируйте таблицу для сбора статистики.
Отсутствующие или неэффективные runtime фильтры
Симптомы профиля / горячие метрики: JoinRuntimeFilterEvaluate маленький, сканирования все еще читают полную таблицу
Почему это вредит: Сканирования проталкивают все строки в сторону probe, тратя CPU и I/O
Решения: Перепишите предикат соединения на чистое равенство, чтобы RF мог быть сгенерирован; избегайте приведения типов в ключе соединения
Проникновение Non-equi (nested-loop) соединения
Симптомы профиля / го�рячие метрики: Узел Join показывает CROSS или NESTLOOP; ProbeRows*BuildRows взлетает
Почему это вредит: O(строки×строки) сравнения; нет хеш-ключа
Решения:
- Добавьте правильный предикат равенства или предварительный фильтр
- Материализуйте результат предиката во временной таблице, затем повторно соедините
Стоимость приведения/выражения хеш-ключа
Симптомы профиля / горячие метрики: Высокий ExprComputeTime; время хеш-функции соперничает со временем probe
Почему это вредит: Ключи должны быть приведены или оценены на строку перед хешированием
Решения:
- Храните ключи с соответствующими типами
- Предварительно вычислите сложные выражения в генерируемых столбцах
Нет размещения на большом соединении
Симптомы профиля / горячие метрики: Shuffle соединение между фактом и измерением, хотя buckets совпадают
Почему это вредит: Случайное размещение заставляет перемешивать каждый запрос
Решения:
- Поместите две таблицы в одну группу размещения
- Проверьте идентичное количество/ключ bucket перед загрузкой
Список метрик
| Метрика | Описание |
|---|---|
DistributionMode | Тип распределения, включая: BROADCAST, PARTITIONED, COLOCATE и т.д. |
JoinPredicates | Предикаты соединения. |
JoinType | Тип соединения. |
BuildBuckets | Количество buckets в Hash Table. |
BuildKeysPerBucket | Количество ключей на bucket в Hash Table. |
BuildConjunctEvaluateTime | Время, затраченное на оценку conjunct во время фазы build. |
BuildHashTableTime | Время, затраченное на построение Hash Table. |
ProbeConjunctEvaluateTime | Время, затрачен�ное на оценку conjunct во время фазы probe. |
SearchHashTableTimer | Время, затраченное на поиск в Hash Table. |
CopyRightTableChunkTime | Время, затраченное на копирование chunks из правой таблицы. |
OutputBuildColumnTime | Время, затраченное на вывод столбца стороны build. |
OutputProbeColumnTime | Время, затраченное на вывод столбца стороны probe. |
HashTableMemoryUsage | Использование памяти Hash Table. |
RuntimeFilterBuildTime | Время, затраченное на построение runtime фильтров. |
RuntimeFilterNum | Количество runtime фильтров. |
Window Function Operator
| Метрика | Описание |
|---|---|
ProcessMode | Режим выполнения, включающий две части: первая часть включает Materializing и Streaming; вторая часть включает Cumulative, RemovableCumulative, ByDefinition. |
ComputeTime | Время, затраченное на вычисления оконных функций. |
PartitionKeys | Столбцы разделов. |
AggregateFunctions | Агрегатные функции. |
ColumnResizeTime | Время, затраченное на изменение размера столбцов. |
PartitionSearchTime | Время, затраченное на поиск границ разделов. |
PeerGroupSearchTime | Время, затраченное на поиск границ Peer Group. Имеет смысл только когда тип окна RANGE. |
PeakBufferedRows | Пиковое количество строк в буфере. |
RemoveUnusedRowsCount | Количество раз удаления неиспользуемых буферов. |
RemoveUnusedTotalRows | Общее количество строк, удаленных из неиспользуемых буферов. |
Sort Operator
| Метрика | Описание |
|---|---|
SortKeys | Ключи сортировки. |
SortType | Метод сортировки результатов запроса: полная сортировка или сортировка топ N результатов. |
MaxBufferedBytes | Пиковый размер буферизованных данных. |
MaxBufferedRows | Пиковое количество буферизованных строк. |
NumSortedRuns | Количество отсортированных прогонов. |
BuildingTime | Время, затраченное на поддержание внутренних структур данных во время сортировки. |
MergingTime | Время, затраченное на объединение отсортированных прогонов во время сортировки. |
SortingTime | Время, затраченное на сортировку. |
OutputTime | Время, затраченное на построение выходной отсортированной последовательности. |
Merge Operator
Для облегчения понимания различных метрик Merge может быть представлен как следующий механизм состояний:
┌────────── PENDING ◄──────────┐
│ │
│ │
├─────────��─────◄───────────────┤
│ │
▼ │
INIT ──► PREPARE ──► SPLIT_CHUNK ──► FETCH_CHUNK ──► FINISHED
▲
|
| one traverse from leaf to root
|
▼
PROCESS
| Метрика | Описание | Уровень |
|---|---|---|
Limit | Лимит. | Первичный |
Offset | Смещение. | Первичный |
StreamingBatchSize | Размер данных, обрабатываемых за операцию Merge, когда Merge выполняется в потоковом режиме | Первичный |
LateMaterializationMaxBufferChunkNum | Максимальное количество chunks в буфере при включенной поздней материализации. | Первичный |
OverallStageCount | Общее количество выполнений всех этапов. | Первичный |
OverallStageTime | Общее время выполнения для каждого этапа. | Первичный |
1-InitStageCount | Количество выполнений этапа Init. | Вторичный |
2-PrepareStageCount | Количество выполнений этапа Prepare. | Вторичный |
3-ProcessStageCount | Количество выполнений этапа Process. | Вторичный |
4-SplitChunkStageCount | Количество выполнений этапа SplitChunk. | Вторичный |
5-FetchChunkStageCount | Количество выполнений этапа FetchChunk. | Вторичный |
6-PendingStageCount | Количество выполнений этапа Pending. | Вторичный |
7-FinishedStageCount | Количество выполнений этапа Finished. | Вторичный |
1-InitStageTime | Время выполнения этапа Init. | Вторичный |
2-PrepareStageTime | Время выполнения этапа Prepare. | Вторичный |
3-ProcessStageTime | Время выполнения этапа Process. | Вторичный |
4-SplitChunkStageTime | Время, затраченное на этап Split. | Вторичный |
5-FetchChunkStageTime | Время, затраченное на этап Fetch. | Вторичный |
6-PendingStageTime | Время, затраченное на этап Pending. | Вторичный |
7-FinishedStageTime | Время, затраченное на этап Finished. | Вторичный |
LateMaterializationGenerateOrdinalTime | Время, затраченное на генерацию порядковых столбцов во время поздней материализации. | Третичный |
SortedRunProviderTime | Время, затраченное на получение данных от провайдера во время этапа Process. | Третичный |
TableFunction Operator
| Метрика | Описание |
|---|---|
TableFunctionExecTime | Время вычисления Table Function. |
TableFunctionExecCount | Количество выполнений Table Function. |
Project Operator
Project Operator отвечает за выполнение SELECT <expr>. Если в запросе есть дорогие выражения, этот оператор может занимать значительное время.
| Метрика | Описание |
|---|---|
ExprComputeTime | Время вычисления выражений. |
CommonSubExprComputeTime | Время вычисления общих подвыражений. |
LocalExchange Operator
| Метрика | Описание |
|---|---|
| Type | Тип Local Exchange, включая: Passthrough, Partition и Broadcast. |
ShuffleNum | Количество перемешиваний. Эта метрика действительна только когда Type равен Partition. |
LocalExchangePeakMemoryUsage | Пиковое использование памяти. |
LocalExchangePeakBufferSize | Пиковый размер буфера. |
LocalExchangePeakBufferMemoryUsage | Пиковое использование памяти буфера. |
LocalExchangePeakBufferChunkNum | Пиковое количество chunks в буфере. |
LocalExchangePeakBufferRowNum | Пиковое количество строк в буфере. |
LocalExchangePeakBufferBytes | Пиковый размер данных в буфере. |
LocalExchangePeakBufferChunkSize | Пиковый размер chunks в буфере. |
LocalExchangePeakBufferChunkRowNum | Пиковое количество строк на chunk в буфере. |
LocalExchangePeakBufferChunkBytes | Пиковый размер данных на chunk в буфере. |
OlapTableSink Operator
OlapTableSink Operator отвечает за выполнение операции INSERT INTO <table>.
- Чрезмерная разница между значениями Max и Min метрики
PushChunkNumуOlapTableSinkуказывает на перекос данных в upstream операторах, что может привести к узкому месту в производительности загрузки. RpcClientSideTimeравенRpcServerSideTimeплюс время передачи по сети плюс время обработки RPC фреймворка. Если есть значительная разница междуRpcClientSideTimeиRpcServerSideTime, рассмотрите включ�ение сжатия для уменьшения времени передачи.
| Метрика | Описание |
|---|---|
IndexNum | Количество синхронных материализованных представлений, созданных для целевой таблицы. |
ReplicatedStorage | Включена ли Single Leader Replication. |
TxnID | ID транзакции загрузки. |
RowsRead | Количество строк, прочитанных из upstream операторов. |
RowsFiltered | Количество строк, отфильтрованных из-за неадекватного качества данных. |
RowsReturned | Количество строк, записанных в целевую таблицу. |
RpcClientSideTime | Общее потребление времени RPC для загрузки, записанное на стороне клиента. |
RpcServerSideTime | Общее потребление времени RPC для загрузки, записанное на стороне сервера. |
PrepareDataTime | Общее потребление времени для фазы подготовки данных, включая преобразование формата данных и проверку качества данных. |
SendDataTime | Локальное потребление времени для отправки данных, включая время для сериализации и сжатия данных, и для отправки задач в очередь отправителя. |