Data Lakehouse
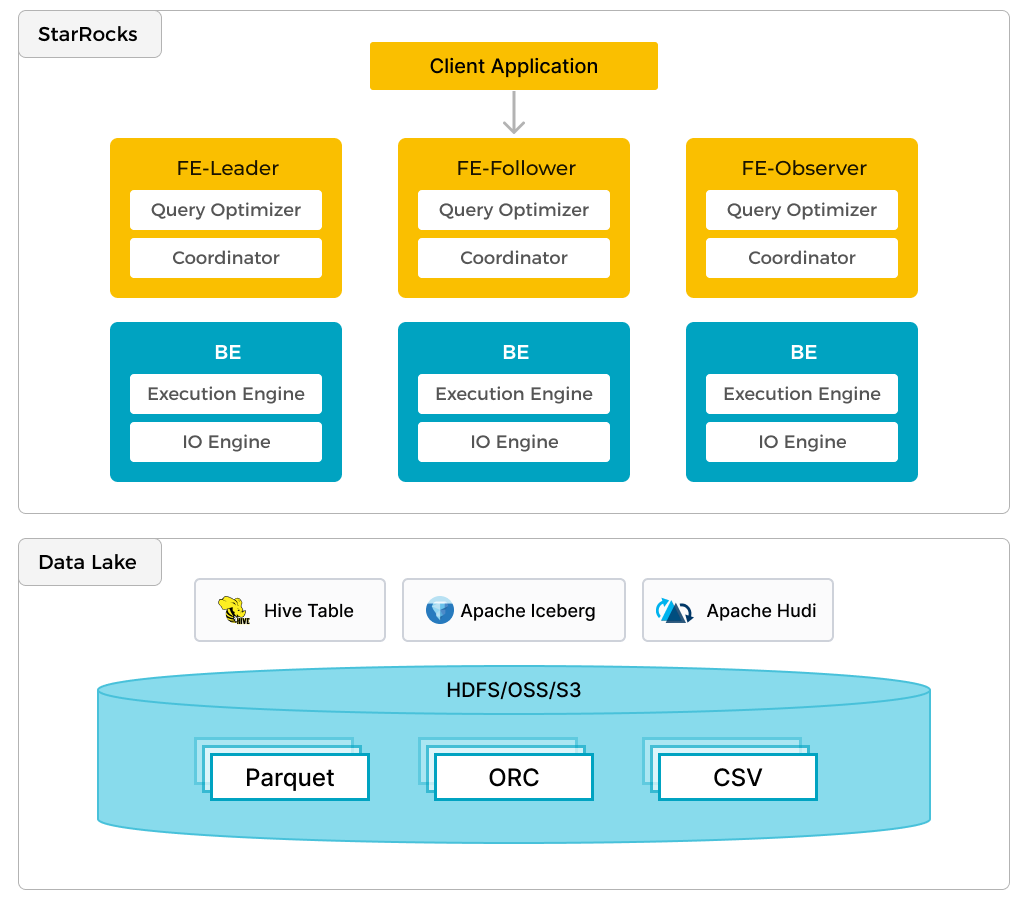
Помимо эффективной аналитики локальных данных, Selena может работать как вычислительный движок для анализа данных, хранящихся в озерах данных, таких как Apache Hudi, Apache Iceberg и Delta Lake. Одной из ключевых особенностей Selena является external catalog, который выступает в качестве связующего звена с внешне поддерживае�мым метахранилищем. Эта функциональность предоставляет пользователям возможность беспрепятственно запрашивать внешние источники данных, устраняя необходимость в миграции данных. Таким образом, пользователи могут анализировать данные из различных систем, таких как HDFS и Amazon S3, в различных форматах файлов, таких как Parquet, ORC и CSV и т.д.
Предыдущий рисунок показывает сценарий аналитики озера данных, где Selena отвечает за вычисления и анализ данных, а озеро данных отвечает за хранение, организацию и обслуживание данных. Озера данных позволяют пользователям хранить данные в открытых форматах хранения и использовать гибкие схемы для создания отчетов на основе "единого источника истины" для различных случаев использования BI, AI, ad-hoc и отчетности. Selena полностью использует преимущества своего векторизационного движка и CBO, значительно улучшая производительность аналитики озера данных.
Ключевые идеи
- Открытые форматы данных: Поддержива�ет различные типы данных, включая JSON, Parquet и Avro, облегчая хранение и обработку как структурированных, так и неструктурированных данных.
- Управление метаданными: Реализует общий слой метаданных, часто используя форматы, такие как формат таблиц Iceberg, для эффективной организации и управления данными.
- Разнообразные движки запросов: Включает несколько движков, таких как улучшенные версии Presto и Spark, для различных случаев использования аналитики и ИИ.
- Управление и безопасность: Обладает надежными встроенными механизмами для безопасности данных, конфиденциальности и соответствия требованиям, обеспечивая целостность и надежность данных.
Преимущества архитектуры Data Lakehouse
- Гибкость и масштабируемость: Легко управляет различными типами данных и масштабируется в соответствии с потребностями организации.
- Экономическая эффективность: Предлаг�ает экономичную альтернативу для хранения и обработки данных по сравнению с традиционными методами.
- Улучшенное управление данными: Повышает контроль, управление и целостность данных, обеспечивая надежную и безопасную обработку данных.
- Готовность к ИИ и аналитике: Идеально подходит для сложных аналитических задач, включая машинное обучение и обработку данных на основе ИИ.
Подход Selena
Ключевые моменты для рассмотрения:
- Стандартизация интеграции с catalog или службами метаданных
- Эластичная масштабируемость вычислительных узлов
- Гибкие механизмы кэширования
Catalogs
Selena имеет два типа catalogs: внутренние и внешние. Внутренний catalog содержит метаданные для данных, хранящихся в базах данных Selena. External catalogs используются для работы с данными, хранящимися внешне, включая данные, управляемые Hive, Iceberg, Delta Lake �и Hudi. Существует множество других внешних систем, ссылки находятся в разделе "Дополнительная информация" в нижней части страницы.
Масштабирование вычислительных узлов (CN)
Разделение хранения и вычислений снижает сложность масштабирования. Поскольку вычислительные узлы Selena хранят только локальный кэш, узлы можно добавлять или удалять в зависимости от нагрузки.
Data cache
Кэш на вычислительных узлах является опциональным. Если ваши вычислительные узлы быстро запускаются и останавливаются на основе быстро меняющихся паттернов нагрузки или ваши запросы часто касаются только самых последних данных, кэширование данных может не иметь смысла.
🗃️ Каталог
14 элементов
🗃️ Кэш данных
4 элемента
📄️ External table
- Начиная с версии 1.5.0, мы рекомендуем использовать каталоги для запроса данных из Hive, Iceberg и Hudi. См. Hive catalog, Iceberg catalog и Hudi catalog.
📄️ Внешняя таблица файлов
Внешняя таблица файлов — это специальный тип внешней таблицы. Она позволяет напрямую запрашивать файлы данных Parquet и ORC во внешних системах хранения без загрузки данных в Selena. Кроме того, внешние таблицы файлов не зависят от метахранилища. В текущей версии Selena поддерживает следующие внешние системы хранения: HDFS, Amazon S3 и другие S3-совместимые системы хранения.
📄️ FAQ по озеру данных
В этом разделе описаны часто задаваемые вопросы (FAQ) об озере данных и предоставлены решения этих проблем. Некоторые метрики, упомянутые в этом разделе, можно получить только из профилей SQL-запросов. Чтобы получить профили SQL-запросов, необходимо указать set enable_profile=true.
📄️ Поддержка функций
Начиная с версии 1.5.0, Selena поддерживает управление внешними источниками данных и анализ данных в озерах данных через external catalog.