Анализ запросов
Оптимизация производительности запросов — это часто задаваемый вопрос. Медленные запросы ухудшают пользовательский опыт, а также производительность кластера. Важно анализировать и оптимизировать производительность запросов.
Вы можете просматривать информацию о запросах в fe/log/fe.audit.log. Каждый запрос соответствует QueryID, который можно использовать для поиска QueryPlan и Profile запроса. QueryPlan — это план выполнения, сгенерированный FE путем разбора SQL-операторов. Profile — это результат выполнения BE и содержит информацию, такую как время, затраченное на каждый шаг, и �объем данных, обработанных на каждом шаге.
Анализ плана
В Selena жизненный цикл SQL-оператора можно разделить на три фазы: разбор запроса, планирование запроса и выполнение запроса. Разбор запроса обычно не является узким местом, поскольку требуемый QPS аналитических рабочих нагрузок невысок.
Производительность запросов в Selena определяется планированием запросов и выполнением запросов. Планирование запросов отвечает за координацию операторов (Join/Order/Aggregate), а выполнение запросов отвечает за выполнение конкретных операций.
План запроса предоставляет администратору базы данных макроперспективу для доступа к информации о запросах. План запроса является ключом к производительности запросов и хорошим ресурсом для справки администратора базы данных. Следующий фрагмент кода использует TPCDS query96 в качестве примера, чтобы показать, как просматривать план запроса.
Используйте оператор EXPLAIN для просмотра плана запроса.
EXPLAIN select count(*)
from store_sales
,household_demographics
,time_dim
, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'
order by count(*) limit 100;
Существует два типа планов запросов — логический план запроса и физический план запроса. План запроса, описанный здесь, относится к логическому плану запроса. План запроса, соответствующий TPCDS query96.sql, показан ниже.
+------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 11> |
| PARTITION: UNPARTITIONED |
| RESULT SINK |
| 12:MERGING-EXCHANGE |
| limit: 100 |
| tuple ids: 5 |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 12 |
| UNPARTITIONED |
| |
| 8:TOP-N |
| | order by: <slot 11> ASC |
| | offset: 0 |
| | limit: 100 |
| | tuple ids: 5 |
| | |
| 7:AGGREGATE (update finalize) |
| | output: count(*) |
| | group by: |
| | tuple ids: 4 |
| | |
| 6:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: left hash join node can not do colocate |
| | equal join conjunct: `ss_store_sk` = `s_store_sk` |
| | tuple ids: 0 2 1 3 |
| | |
| |----11:EXCHANGE |
| | tuple ids: 3 |
| | |
| 4:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: left hash join node can not do colocate |
| | equal join conjunct: `ss_hdemo_sk`=`household_demographics`.`hd_demo_sk`|
| | tuple ids: 0 2 1 |
| | |
| |----10:EXCHANGE |
| | tuple ids: 1 |
| | |
| 2:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: table not in same group |
| | equal join conjunct: `ss_sold_time_sk` = `time_dim`.`t_time_sk` |
| | tuple ids: 0 2 |
| | |
| |----9:EXCHANGE |
| | tuple ids: 2 |
| | |
| 0:OlapScanNode |
| TABLE: store_sales |
| PREAGGREGATION: OFF. Reason: `ss_sold_time_sk` is value column |
| partitions=1/1 |
| rollup: store_sales |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 0 |
| |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 11 |
| UNPARTITIONED |
| |
| 5:OlapScanNode |
| TABLE: store |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `store`.`s_store_name` = 'ese' |
| partitions=1/1 |
| rollup: store |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 3 |
| |
| PLAN FRAGMENT 3 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 10 |
| UNPARTITIONED |
| |
| 3:OlapScanNode |
| TABLE: household_demographics |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `household_demographics`.`hd_dep_count` = 5 |
| partitions=1/1 |
| rollup: household_demographics |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 1 |
| |
| PLAN FRAGMENT 4 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 09 |
| UNPARTITIONED |
| |
| 1:OlapScanNode |
| TABLE: time_dim |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `time_dim`.`t_hour` = 8, `time_dim`.`t_minute` >= 30 |
| partitions=1/1 |
| rollup: time_dim |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 2 |
+------------------------------------------------------------------------------+
128 rows in set (0.02 sec)
Запрос 96 показывает план запроса, который включает несколько концепций Selena.
| Название | Объяснение |
|---|---|
| avgRowSize | Средний размер сканируемых строк данных |
| cardinality | Общее количество строк данных в сканируемой таблице |
| colocate | Находится ли таблица в режиме colocate |
| numNodes | Количество узлов для сканирования |
| rollup | Материализованное представление |
| preaggregation | Предварительная агрегация |
| predicates | Предикаты, фильтры запроса |
План запроса Query 96 разделен на пять фрагментов, пронумерованных от 0 до 4. План запроса можно читать один за другим снизу вверх.
Fragment 4 отвечает за сканирование таблицы time_dim и выполнение связанного условия запроса (т.е. time_dim.t_hour = 8 and time_dim.t_minute >= 30) заранее. Этот шаг также известен как проталкивание предикатов. Selena решает, включать ли PREAGGREGATION для агрегационных таблиц. На предыдущем рисунке предварительная агрегация time_dim отключена. В этом случае читаются все столбцы измерений time_dim, что может негативно повлиять на производительность, если в таблице много столбцов измерений. Если таблица time_dim выбирает range partition для разделения данных, в плане запроса будет затронуто несколько разделов, и нерелевантные разделы будут автоматически отфильтрованы. Если есть материализованное представление, Selena автоматически выберет материализованное представление на основе запроса. Если материализованного представления нет, запрос автоматически попадет в базовую таблицу (например, rollup: time_dim на предыдущем рисунке).
Когда сканирование завершено, Fragment 4 заканчивается. Данные будут переданы другим фрагментам, как указано EXCHANGE ID : 09 на предыдущем рисунке, принимающему узлу с меткой 9.
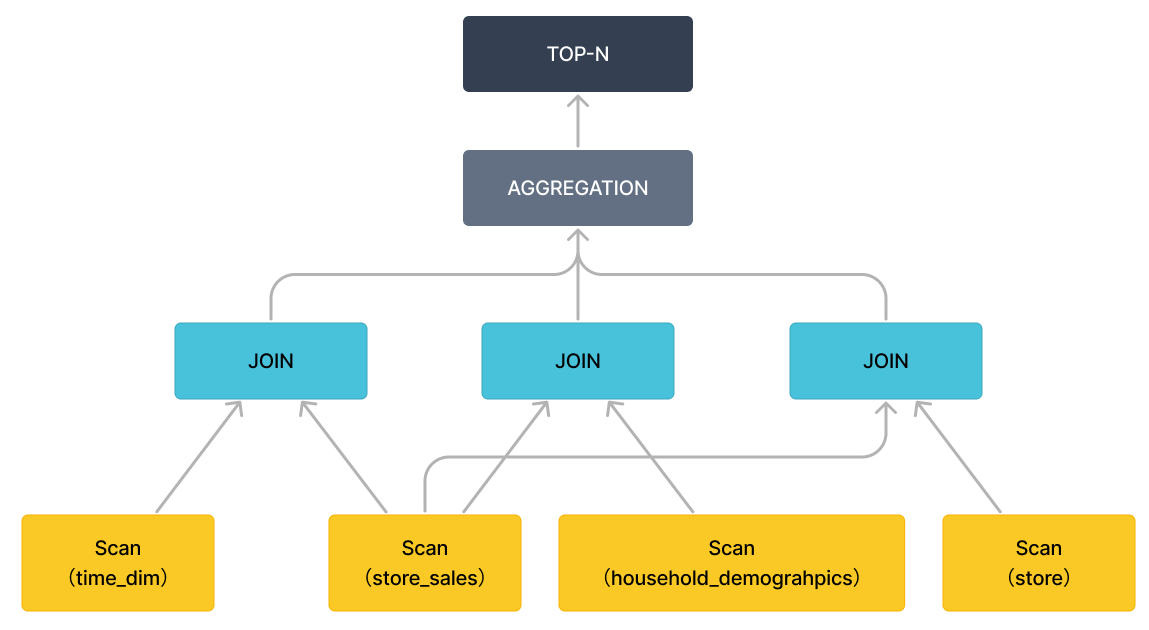
Для плана запроса Query 96 Fragment 2, 3 и 4 имеют схожие функции, но они отвечают за сканирование разных таблиц. В частности, операции Order/Aggregation/Join в запросе выполняются во Fragment 1.
Fragment 1 использует метод BROADCAST для выполнения операций Order/Aggregation/Join, то есть для трансляции маленькой таблицы в большую таблицу. Если обе таблицы большие, мы рекомендуем использовать метод SHUFFLE. В настоящее время Selena поддерживает только HASH JOIN. Поле colocate используется для показа того, что две соединяемые таблицы разделены и сгруппированы одинаковым образом, поэтому операция соединения может выполняться локально без миграции данных. Когда операция Join завершена, будут выполнены операции верхнего уровня aggregation, order by и top-n.
Удалив конкретные выражения (оставив только операторы), план запроса можно представить в более макроскопическом виде, как показано на следующем рисунке.
Подсказки запроса
Подсказки запроса — это директивы или комментарии, которые явно предлагают оптимизатору запросов, как выполнить запрос. В настоящее время Selena поддерживает три типа подсказок: подсказка системной переменной (SET_VAR), подсказка пользовательской переменной (SET_USER_VARIABLE) и подсказка Join. Подсказки действуют только в рамках одного запроса.
Подсказка системной переменной
Вы можете использовать подсказку SET_VAR для установки одной или нескольких системных переменных в операторах SELECT и SUBMIT TASK, а затем выполнить операторы. Вы также можете использовать подсказку SET_VAR в предложении SELECT, включенном в другие операторы, такие как CREATE MATERIALIZED VIEW AS SELECT и CREATE VIEW AS SELECT. Обратите внимание, что если подсказка SET_VAR используется в предложении SELECT CTE, подсказка SET_VAR не действует, даже если оператор выполняется успешно.
По сравнению с общим использованием системных переменных, которое действует на уровне сессии, подсказка SET_VAR действует на уровне оператора и не влияет на всю сессию.
Синтаксис
[...] SELECT /*+ SET_VAR(key=value [, key = value]) */ ...
SUBMIT [/*+ SET_VAR(key=value [, key = value]) */] TASK ...
Примеры
Чтобы указать режим агрегации для агрегатного запроса, используйте подсказку SET_VAR для установки системных переменных streaming_preaggregation_mode и new_planner_agg_stage в агрегатном запросе.
SELECT /*+ SET_VAR (streaming_preaggregation_mode = 'force_streaming',new_planner_agg_stage = '2') */ SUM(sales_amount) AS total_sales_amount FROM sales_orders;
Чтобы указать тайм-аут выполнения для оператора SUBMIT TASK, используйте подсказку SET_VAR для установки системной переменной query_timeout в операторе SUBMIT TASK.
SUBMIT /*+ SET_VAR(query_timeout=3) */ TASK AS CREATE TABLE temp AS SELECT count(*) AS cnt FROM tbl1;
Чтобы указать тайм-аут выполнения подзапроса для создания материализованного представления, используйте подсказку SET_VAR для установки системной переменной query_timeout в предложении SELECT.
CREATE MATERIALIZED VIEW mv
PARTITION BY dt
DISTRIBUTED BY HASH(`key`)
BUCKETS 10
REFRESH ASYNC
AS SELECT /*+ SET_VAR(query_timeout=500) */ * from dual;
Подсказка пользовательской переменной
Вы можете использовать подсказку SET_USER_VARIABLE для установки одной или нескольких пользовательских переменных в операторах SELECT или INSERT. Если другие операторы содержат предложение SELECT, вы также можете использовать подсказку SET_USER_VARIABLE в этом предложении SELECT. Другими операторами могут быть операторы SELECT и INSERT, но не могут быть операторы CREATE MATERIALIZED VIEW AS SELECT и CREATE VIEW AS SELECT. Обратите внимание, что если подсказка SET_USER_VARIABLE используется в предложении SELECT CTE, подсказка SET_USER_VARIABLE не действует, даже если оператор выполняется успешно. Начиная с версии 1.5.0, Selena поддерживает подсказку пользовательской переменной.
По сравнению с общим использованием пользовательских переменных, которое действует на уровне сессии, подсказка SET_USER_VARIABLE действует на уровне оператора и не влияет на всю сессию.
Синтаксис
[...] SELECT /*+ SET_USER_VARIABLE(@var_name = expr [, @var_name = expr]) */ ...
INSERT /*+ SET_USER_VARIABLE(@var_name = expr [, @var_name = expr]) */ ...
Примеры
Следующий оператор SELECT ссылается на скалярные подзапросы select max(age) from users и select min(name) from users, поэтому вы можете использовать подсказку SET_USER_VARIABLE для установки этих двух скалярных подзапросов как пользовательских переменных, а затем выполнить запрос.
SELECT /*+ SET_USER_VARIABLE (@a = (select max(age) from users), @b = (select min(name) from users)) */ * FROM sales_orders where sales_orders.age = @a and sales_orders.name = @b;
Подсказка Join
Для запросов Join с несколькими таблицами оптимизатор обычно выбирает оптимальный метод выполнения Join. В особых случаях вы можете использовать подсказку Join, чтобы явно предложить оптимизатору метод выполнения Join или отключить Join Reorder. В настоящее время подсказка Join поддерживает предложение Shuffle Join, Broadcast Join, Bucket Shuffle Join или Colocate Join в качестве метода выполнения Join. Когда используется подсказка Join, оптимизатор не выполняет Join Reorder. Поэтому вам нужно выбрать меньшую таблицу в качестве правой таблицы. Кроме того, при предложении Colocate Join или Bucket Shuffle Join в качестве метода выполнения Join убедитесь, что распределение данных соединяемой таблицы соответствует требованиям этих методов выполнения Join. В противном случае предложенный метод выполнения Join не может вступить в силу.
Синтаксис
... JOIN { [BROADCAST] | [SHUFFLE] | [BUCKET] | [COLOCATE] | [UNREORDER]} ...
Подсказка Join нечувствительна к регистру.
Примеры
-
Shuffle Join
Если вам нужно перемешать строки данных с одинаковыми значениями ключей группировки из таблиц A и B на одну машину перед выполнением операции Join, вы можете указать метод выполнения Join как Shuffle Join.
select k1 from t1 join [SHUFFLE] t2 on t1.k1 = t2.k2 group by t2.k2; -
Broadcast Join
Если таблица A — большая таблица, а таблица B — маленькая таблица, вы можете указать метод выполнения Join как Broadcast Join. Данные таблицы B полностью транслируются на машины, на которых находятся данные таблицы A, а затем выполняется операция Join. По сравнению с Shuffle Join, Broadcast Join экономит затраты на перемешивание данных таблицы A.
select k1 from t1 join [BROADCAST] t2 on t1.k1 = t2.k2 group by t2.k2; -
Bucket Shuffle Join
Если выражение Join equijoin в запросе Join содержит ключ группировки таблицы A, особенно когда обе таблицы A и B являются большими таблицами, вы можете указать метод выполнения Join как Bucket Shuffle Join. Данные таблицы B перемешиваются на машины, на которых находятся данные таблицы A, согласно распределению данных таблицы A, а затем выполняется операция Join. По сравнению с Broadcast Join, Bucket Shuffle Join значительно сокращает передачу данных, поскольку данные таблицы B перемешиваются только один раз глобально. Таблицы, участвующие в Bucket Shuffle Join, должны быть либо неразделенными, либо colocated.
select k1 from t1 join [BUCKET] t2 on t1.k1 = t2.k2 group by t2.k2; -
Colocate Join
Если таблицы A и B принадлежат к одной Colocation Group, которая указывается при создании таблицы, строки данных с одинаковыми значениями ключей группировки из таблиц A и B распределяются на одном узле BE. Когда выражение Join equijoin содержит ключ группировки таблиц A и B в запросе Join, вы можете указать метод выполнения Join как Colocate Join. Данные с одинаковыми значениями ключей соединяются непосредственно локально, сокращая время, затрачиваемое на передачу данных между узлами, и улучшая производительность запросов.
select k1 from t1 join [COLOCATE] t2 on t1.k1 = t2.k2 group by t2.k2;
Просмотр метода выполнения Join
Используйте команду EXPLAIN для просмотра фактического метода выполнения Join. Если возвращенный результат показывает, что метод выполнения Join соответствует подсказке Join, это означает, что подсказка Join эффективна.
EXPLAIN select k1 from t1 join [COLOCATE] t2 on t1.k1 = t2.k2 group by t2.k2;
Отпечаток SQL
Отпечат�ок SQL используется для оптимизации медленных запросов и улучшения использования системных ресурсов. Selena использует функцию отпечатка SQL для нормализации SQL-операторов в журнале медленных запросов (fe.audit.log.slow_query), категоризирует SQL-операторы на разные типы и вычисляет MD5-хеш каждого типа SQL для идентификации медленных запросов. MD5-хеш указывается полем Digest.
2021-12-27 15:13:39,108 [slow_query] |Client=172.26.xx.xxx:54956|User=root|Db=default_cluster:test|State=EOF|Time=2469|ScanBytes=0|ScanRows=0|ReturnRows=6|StmtId=3|QueryId=824d8dc0-66e4-11ec-9fdc-00163e04d4c2|IsQuery=true|feIp=172.26.92.195|Stmt=select count(*) from test_basic group by id_bigint|Digest=51390da6b57461f571f0712d527320f4
Нормализация SQL-операторов преобразует текст оператора в более нормализованный формат и сохраняет только важную структуру оператора.
-
Сохраняет идентификаторы объектов, такие как имена баз данных и таблиц.
-
Преобразует константы в знак вопроса (?).
-
Удаляет комментарии и форматирует пробелы.
Например, следующие два SQL-оператора принадлежат к одному типу после нормализации.
- SQL-операторы до нормализации
SELECT * FROM orders WHERE customer_id=10 AND quantity>20
SELECT * FROM orders WHERE customer_id = 20 AND quantity > 100
- SQL-оператор после нормализации
SELECT * FROM orders WHERE customer_id=? AND quantity>?