Cluster Snapshot
В этом разделе описывается использование Cluster Snapshot для аварийного восстановления на cluster с разделяемыми данными (shared-data).
Эта функция поддерживается начиная с версии v1.5.2 и доступна только на cluster с разделяемыми данными.
Обзор
Основная идея аварийного восстановления для cluster с разделяемыми данными заключается в том, чтобы обеспечить хранение полного состояния cluster (включая данные и метаданные) в объектном хранилище. Таким образом, если cluster столкнётся со сбоем, его можно восстановить из объектного хранилища, если данные и метаданные останутся нетронутыми. Кроме того, такие функции, как резервное копирование и кросс-региональная репликация, предлагаемые облачными провайдерами, могут использоваться для удалённого восстановления и кросс-региональ ного аварийного восстановления.
В cluster с разделяемыми данными состояние CN (данные) хранится в объ�ектном хранилище, но состояние FE (метаданные) остаётся локальным. Чтобы гарантировать, что объектное хранилище содержит всё состояние cluster для восстановления, Selena теперь поддерживает Cluster Snapshot как для данных, так и для метаданных в объектном хранилище.
Рабочий процесс
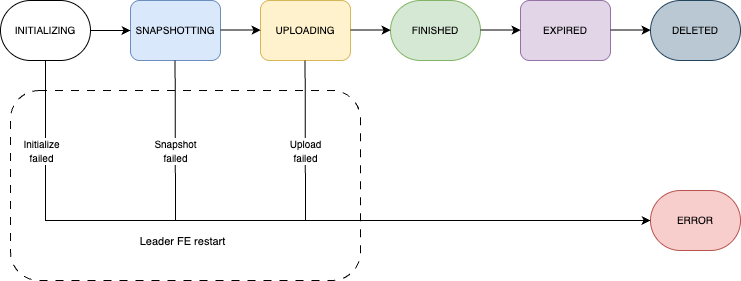
Термины
-
Cluster snapshot
Cluster snapshot означает snapshot состояния cluster в определённый момент времени. Он содержит все объекты в cluster, такие как каталоги, базы данных, таблицы, пользователи и привилегии, задачи загрузки и многое другое. Он не включает все внешние зависимые объекты, такие как конфигурационные файлы внешних каталогов и локальные JAR-пакеты UDF.
-
Создание cluster snapshot
Система автоматически п�оддерживает snapshot, близко следующий за последним состоянием cluster. Исторические snapshot удаляются сразу после создания последнего, сохраняя только один snapshot доступным всё время.
-
Восстановление cluster
Восстановление cluster из snapshot.
Автоматический cluster snapshot
Автоматический Cluster Snapshot отключён по умолчанию.
Используйте следующую команду для включения этой функции:
Синтаксис:
ADMIN SET AUTOMATED CLUSTER SNAPSHOT ON
[STORAGE VOLUME <storage_volume_name>]
Параметр:
storage_volume_name: Указывает storage volume, используемый для хранения snapshot. Если этот параметр не указан, будет использоваться storage volume по умолчанию. Подробнее о создании storage volume см. CREATE STORAGE VOLUME.
Каждый раз, когда FE создаёт новый образ метаданных после завершения checkpoint метаданных, автоматически создаётся snapshot. Имя snapshot генерируется системой по формату automated_cluster_snapshot_{timestamp}.
Snapshot метаданных хранятся в /{storage_volume_locations}/{service_id}/meta/image/automated_cluster_snapshot_timestamp. Snapshot данных хранятся в том же месте, что и исходные данные.
Параметр конфигурации FE automated_cluster_snapshot_interval_seconds управляет циклом автоматизации snapshot. Значение по умолчанию — 600 секунд (10 минут).
Отключение автоматического cluster snapshot
Используйте следующую команду для отключения автоматического cluster snapshot:
ADMIN SET AUTOMATED CLUSTER SNAPSHOT OFF
После отключения автоматического Cluster Snapshot система автоматически удалит исторический snapshot.
Просмотр cluster snapshot
Вы можете запросить представление information_schema.cluster_snapshots для просмотра последнего cluster snapshot и snapshot, которые ещё не были удалены.
SELECT * FROM information_schema.cluster_snapshots;
Возвращаемые поля:
| Поле | Описание |
|---|---|
| snapshot_name | Имя snapshot. |
| snapshot_type | Тип snapshot. Допустимые значения: automated и manual. |
| created_time | Время создания snapshot. |
| fe_journal_id | ID журнала FE. |
| starmgr_journal_id | ID журнала StarManager. |
| properties | Относится к функции, которая ещё не доступна. |
| storage_volume | Storage volume, где хранится snapshot. |
| storage_path | Путь хранения, в котором находится snapshot. |
Просмотр задания cluster snapshot
Вы можете запросить представление information_schema.cluster_snapshot_jobs для просмотра информации о заданиях cluster snapshot.
SELECT * FROM information_schema.cluster_snapshot_jobs;
Возвращаемые поля:
| Поле | Описание |
|---|---|
| snapshot_name | Имя snapshot. |
| job_id | ID задания. |
| created_time | Время создания задания. |
| finished_time | Время завершения задания. |
| state | Состояние задания. Допустимые значения: INITIALIZING, SNAPSHOTING, FINISHED, EXPIRED, DELETED и ERROR. |
| detail_info | Информация о прогрессе текущего этапа выполнения. |
| error_message | Сообщение об ошибке задания (если есть). |
Восстанов�ление cluster
Выполните следующие шаги для восстановления cluster с помощью cluster snapshot.
-
(Опционально) Если местоположение хранилища (storage volume), в котором хранится cluster snapshot, изменилось, все файлы из исходного пути хранения должны быть скопированы в новый путь. Для этого вам необходимо изменить конфигурационный файл cluster_snapshot.yaml в директории
fe/confузлов Leader FE. Шаблон cluster_snapshot.yaml см. в Приложении. -
Запустите узел Leader FE.
./fe/bin/start_fe.sh --cluster_snapshot --daemon -
Запустите другие узлы FE после очистки директорий
meta../fe/bin/start_fe.sh --helper <leader_ip>:<leader_edit_log_port> --daemon -
Запустите узлы CN после очистки директорий
storage_root_path../be/bin/start_cn.sh --daemon
Если вы изменили cluster_snapshot.yaml на шаге 1, узел и storage volume будут переконфигурированы в новом cluster в соответствии с информацией в файле.
Приложение
Шаблон cluster_snapshot.yaml:
# Информация о cluster snapshot, который будет загружен для восстановления.
cluster_snapshot:
# URI snapshot.
# Пример 1: s3://defaultbucket/test/f7265e80-631c-44d3-a8ac-cf7cdc7adec811019/meta/image/automated_cluster_snapshot_1704038400000
# Пример 2: s3://defaultbucket/test/f7265e80-631c-44d3-a8ac-cf7cdc7adec811019/meta
cluster_snapshot_path: <cluster_snapshot_uri>
# Имя storage volume для хранения snapshot. Вы должны определить его в разделе `storage_volumes`.
# ПРИМЕЧАНИЕ: Оно должно быть идентичным тому, что было в исходном cluster.
storage_volume_name: my_s3_volume
# [Опционально] Информация об узлах нового cluster, в котором будет восстановлен snapshot.
# Если этот раздел не указан, новый cluster после восстановления будет содержать только узел Leader FE.
# Узлы CN сохраняют информацию исходного cluster.
# ПРИМЕЧАНИЕ: НЕ включайте узел Leader FE в этот раздел.
frontends:
# Хост FE.
- host: xxx.xx.xx.x1
# edit_log_port FE.
edit_log_port: 9010
# Тип узла FE. Допустимые значения: `follower` (по умолчанию) и `observer`.
type: follower
- host: xxx.xx.xx.x2
edit_log_port: 9010
type: observer
compute_nodes:
# Хост CN.
- host: xxx.xx.xx.x3
# heartbeat_service_port CN.
heartbeat_service_port: 9050
- host: xxx.xx.xx.x4
heartbeat_service_port: 9050
# Информация о storage volume в новом cluster. Используется для восстановления клонированного snapshot.
# ПРИМЕЧАНИЕ: Имя storage volume должно быть идентичным тому, что было в исходном cluster.
storage_volumes:
# Пример для S3-совместимого storage volume.
- name: my_s3_volume
type: S3
location: s3://defaultbucket/test/
comment: my s3 volume
properties:
- key: aws.s3.region
value: us-west-2
- key: aws.s3.endpoint
value: https://s3.us-west-2.amazonaws.com
- key: aws.s3.access_key
value: xxxxxxxxxx
- key: aws.s3.secret_key
value: yyyyyyyyyy
# Пример для HDFS storage volume.
- name: my_hdfs_volume
type: HDFS
location: hdfs://127.0.0.1:9000/sr/test/
comment: my hdfs volume
properties:
- key: hadoop.security.authentication
value: simple
- key: username
value: selena
Подробнее об учётных данных для AWS см. Аутентификация в AWS S3.