Мониторинг и управление большими запросами
В этом разделе описывается, как мониторить и управлять большими запросами в вашем cluster Selena.
Большие запросы включают запросы, которые сканируют слишком много строк или занимают слишком много ресурсов CPU и памяти. Они могут легко исчерпать ресурсы cluster и вызвать перегрузку системы, если не наложить на них ограничения. Для решения этой проблемы Selena предоставляет ряд мер для мониторинга и управления большими запросами, предотвращая монополизацию ресурсов cluster запросами.
Общая идея обработки больших запросов в Selena следующая:
- Настроить автоматические меры предосторожности против больших запросов с помощью групп ресурсов и очередей запросов.
- Мониторить большие запросы в реальном времени и завершать те, которые обходят меры предосторожности.
- Анализировать журналы аудита и журналы больших запросов для изучения паттернов больших запросов и тонкой настройки механизмов предосторожности, настроенных ранее.
Эта функция поддерживается с версии v1.5.2.
Настройка мер предосторожности против больших запросов
Selena предоставляет два инструмента предосторожности для работы с большими запросами — группы ресурсов и очереди запросов. Вы можете использовать группы ресурсов для остановки выполнения больших запросов. Очереди запросов, с другой стороны, могут помочь вам ставить входящие запросы в очередь, когда достигнут порог параллелизма или лимит ресурсов, предотвращая перегрузку системы.
Фильтрация больших запросов через группы ресурсов
Группы ресурсов могут автоматически идентифицировать и завершать большие запросы. При создании группы ресурсов вы можете указать верхний предел времени CPU, использования памяти или количества просканированны�х строк, на которые запрос имеет право. Среди всех запросов, попадающих в группу ресурсов, любые запросы, требующие больше ресурсов, отклоняются и возвращаются с ошибкой. Дополнительную информацию и инструкции по группам ресурсов см. в разделе Изоляция ресурсов.
Перед созданием групп ресурсов необходимо выполнить следующее выражение для включения Pipeline Engine, от которого зависит функция группы ресурсов:
SET GLOBAL enable_pipeline_engine = true;
Следующий пример создаёт группу ресурсов bigQuery, которая ограничивает верхний предел времени CPU до 100 секунд, верхний предел количества просканированных строк до 100000 и верхн�ий предел использования памяти до 1073741824 байт (1 ГБ):
CREATE RESOURCE GROUP bigQuery
TO
(db='sr_hub')
WITH (
'cpu_weight' = '10',
'mem_limit' = '20%',
'big_query_cpu_second_limit' = '100',
'big_query_scan_rows_limit' = '100000',
'big_query_mem_limit' = '1073741824'
);
Если требуемые ресурсы запроса превышают любой из лимитов, запрос не будет выполнен и вернётся с ошибкой. Следующий пример показывает сообщение об ошибке, возвращаемое, когда запрос требует слишком много просканированных строк:
ERROR 1064 (HY000): exceed big query scan_rows limit: current is 4 but limit is 1
Если вы впервые настраиваете группы ресурсов, рекомендуется установить относительно более высокие лимиты, чтобы они не препятствовали обычным запросам. Вы можете тонко настроить эти лимиты после того, как лучше узнаете паттерны больших запросов.
Смягчение перегрузки системы через очереди запросов
Очереди запросов предназначены для смягчения ухудшения перегрузки системы, когда занятость ресурсов cluster превышает заранее определённые пороги. Вы можете установить пороги для максимального параллелизма, использования памяти и использования CPU. Selena автоматически ставит входящие запросы в очередь, когда достигнут любой из этих порогов. Ожидающие запросы либо ждут в очереди выполнения, либо отменяются, когда достигнут заранее определённый порог ресурсов. Дополнительную информацию см. в разделе Очереди запросов.
Выполните следующие выражения для включения очередей запросов для SELECT-запросов:
SET GLOBAL enable_query_queue_select = true;
После включения функции очереди запросов вы можете определить правила для запуска очередей запросов.
-
Укажите порог параллелизма для запуска очереди запросов.
Следующий пример устанавливает порог параллелизма на
100:SET GLOBAL query_queue_concurrency_limit = 100; -
Укажите порог коэффициента использования памяти для запуска очереди запросов.
Следующий пример устанавливает порог коэффициента использования памяти на
0.9:SET GLOBAL query_queue_mem_used_pct_limit = 0.9; -
Укажите порог коэффициента использования CPU для запуска очереди запросов.
Следующий пример устанавливает порог промилле использования CPU (использование CPU * 1000) на
800:SET GLOBAL query_queue_cpu_used_permille_limit = 800;
Вы также можете решить, как обрабатывать эти запросы в очереди, настроив максимальную длину очереди и тайм-аут для каждого ожидающего запроса в очереди.
-
Укажите максимальную длину очереди запросов. При достижении этого порога входящие запросы отклоняются.
Следующий пример устанавливает длину очереди запросов на
100:SET GLOBAL query_queue_max_queued_queries = 100; -
Укажите максимальный тайм-аут ожидающего запроса в очереди. При достижении этого порога соответствующий запрос отклоняется.
Следующий пример устанавливает максимальный тайм-аут на
480секунд:SET GLOBAL query_queue_pending_timeout_second = 480;
Вы можете проверить, находится ли запрос в ожидании, с помощью SHOW PROCESSLIST.
mysql> SHOW PROCESSLIST;
+------+------+---------------------+-------+---------+---------------------+------+-------+-------------------+-----------+
| Id | User | Host | Db | Command | ConnectionStartTime | Time | State | Info | IsPending |
+------+------+---------------------+-------+---------+---------------------+------+-------+-------------------+-----------+
| 2 | root | xxx.xx.xxx.xx:xxxxx | | Query | 2022-11-24 18:08:29 | 0 | OK | SHOW PROCESSLIST | false |
+------+------+---------------------+-------+---------+---------------------+------+-------+-------------------+-----------+
Если IsPending равно true, соответствующий запрос ожидает в очереди запросов.
Мониторинг больших запросов в реальном времени
Начиная с версии v1.5.2, Selena поддерживает просмотр запросов, которые в данный момент обрабатываются в cluster, и ресурсов, которые они занимают. Это позволяет мониторить cluster на случай, если какие-либо большие запросы обходят меры предосторожности и вызывают неожиданную перегрузку системы.
Мониторинг через клиент MySQL
-
Вы можете просмотреть запросы, которые в данный момент обрабатываются (
current_queries), с помощью SHOW PROC.SHOW PROC '/current_queries';Selena возвращает ID запроса (
QueryId), ID соединения (ConnectionId) и потребление ресурсов каждого запроса, включая размер просканированных данных (ScanBytes), количество обработанных строк (ProcessRows), время CPU (CPUCostSeconds), использование памяти (MemoryUsageBytes) и время выполнения (ExecTime).mysql> SHOW PROC '/current_queries';
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
| QueryId | ConnectionId | Database | User | ScanBytes | ProcessRows | CPUCostSeconds | MemoryUsageBytes | ExecTime |
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
| 7c56495f-ae8b-11ed-8ebf-00163e00accc | 4 | tpcds_100g | root | 37.88 MB | 1075769 Rows | 11.13 Seconds | 146.70 MB | 3804 |
| 7d543160-ae8b-11ed-8ebf-00163e00accc | 6 | tpcds_100g | root | 13.02 GB | 487873176 Rows | 81.23 Seconds | 6.37 GB | 2090 |
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
2 rows in set (0.01 sec) -
Вы можете дополнительно изучить потребление ресурсов запроса на каждом узле BE, указав ID запроса.
SHOW PROC '/current_queries/<QueryId>/hosts';Selena возвращает размер просканированных данных запроса (
ScanBytes), количество просканированных строк (ScanRows), время CPU (CPUCostSeconds) и использование памяти (MemUsageBytes) на каждом узле BE.mysql> show proc '/current_queries/7c56495f-ae8b-11ed-8ebf-00163e00accc/hosts';
+--------------------+-----------+-------------+----------------+---------------+
| Host | ScanBytes | ScanRows | CpuCostSeconds | MemUsageBytes |
+--------------------+-----------+-------------+----------------+---------------+
| 172.26.34.185:8060 | 11.61 MB | 356252 Rows | 52.93 Seconds | 51.14 MB |
| 172.26.34.186:8060 | 14.66 MB | 362646 Rows | 52.89 Seconds | 50.44 MB |
| 172.26.34.187:8060 | 11.60 MB | 356871 Rows | 52.91 Seconds | 48.95 MB |
+--------------------+-----------+-------------+----------------+---------------+
3 rows in set (0.00 sec)
Мониторинг через консоль FE
Помимо клиента MySQL, вы можете использовать консоль FE для визуализированного интерактивного мониторинга.
-
Перейдите в консоль FE в браузере, используя следующий URL:
http://<fe_IP>:<fe_http_port>/system?path=//current_queries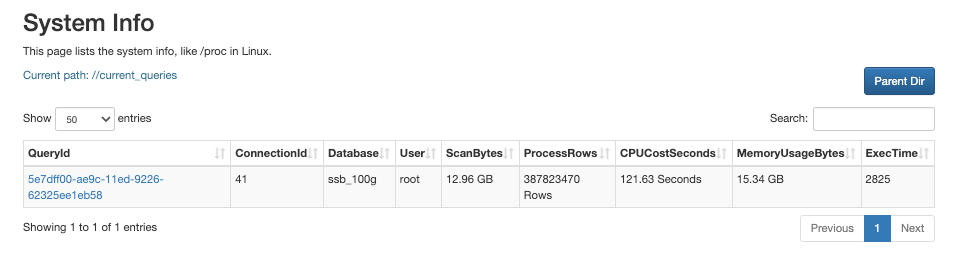
На странице System Info вы можете просмотреть запросы, которые в данный момент обрабатываются, и их потребление ресурсов.
-
Нажмите на QueryID запроса.
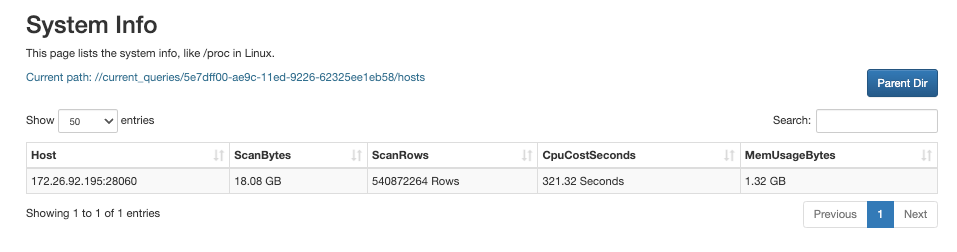
На появившейся странице вы можете просмотреть подробную информацию о потреблении ресурсов по узлам.
Ручное завершение больших запросов
Если какие-либо большие запросы обходят установленные вами меры предосторожности и угрожают досту�пности системы, вы можете завершить их вручную, используя соответствующий ID соединения в выражении KILL:
KILL QUERY <ConnectionId>;
Анализ журналов больших запросов
Начиная с версии v1.5.2, Selena поддерживает журналы больших запросов, которые хранятся в файле fe/log/fe.big_query.log. По сравнению с журналами аудита Selena, журналы больших запросов выводят три дополнительных поля:
bigQueryLogCPUSecondThresholdbigQueryLogScanBytesThresholdbigQueryLogScanRowsThreshold
Эти три поля соответствуют порогам потребления ресурсов, которые вы определили, чтобы определить, является ли запрос большим.
Чтобы включить журналы больших запросов, выполните следующее выражение:
SET GLOBAL enable_big_query_log = true;
После включения журналов больших запросов вы можете определить правила для их запуска.
-
Укажите порог времени CPU для запуска журналов больших запросов.
Следующий пример устанавливает порог времени CPU на
600секунд:SET GLOBAL big_query_log_cpu_second_threshold = 600; -
Укажите порог размера сканируемых данных для запуска журналов больших запросов.
Следующий пример устанавливает порог размера сканируемых данных на
10737418240байт (10 ГБ):SET GLOBAL big_query_log_scan_bytes_threshold = 10737418240; -
Укажите порог количества просканированных строк для запуска журналов больших запросов.
Следующий пример устанавливает порог количества просканирован�ных строк на
1500000000:SET GLOBAL big_query_log_scan_rows_threshold = 1500000000;
Тонкая настройка мер предосторожности
Из статистики, полученной при мониторинге в реальном времени и из журналов больших запросов, вы можете изучить паттерны пропущенных больших запросов (или обычных запросов, ошибочно диагностированных как большие) в вашем cluster, а затем оптимизировать настройки для групп ресурсов и очереди запросов.
Ес�ли значительная часть больших запросов соответствует определённому паттерну SQL и вы хотите навсегда запретить этот паттерн SQL, вы можете добавить этот паттерн в чёрный список SQL. Selena отклоняет все запросы, соответствующие любым паттернам, указанным в чёрном списке SQL, и возвращает ошибку. Дополнительную информацию см. в разделе Управление чёрным списком SQL.
Чтобы включить чёрный список SQL, выполните следующее выражение:
ADMIN SET FRONTEND CONFIG ("enable_sql_blacklist" = "true");
Затем вы можете добавить регулярное выражение, представляющее паттерн SQL, �в чёрный список SQL с помощью ADD SQLBLACKLIST.
Следующий пример добавляет COUNT(DISTINCT) в чёрный список SQL:
ADD SQLBLACKLIST "SELECT COUNT(DISTINCT .+) FROM .+";