Мониторинг и алертинг с Prometheus и Grafana
Selena предоставляет решение для мониторинга и алертинга с использованием Prometheus и Grafana. Это позволяет визуализировать работу вашего cluster, облегчая мониторинг и устранение неполадок.
Обзор
Selena предоставляет интерфейс сбора и�нформации, совместимый с Prometheus. Prometheus может получать метрики Selena, подключаясь к HTTP-портам узлов BE и FE и сохраняя информацию в своей собственной базе данных временных рядов. Grafana затем может использовать Prometheus в качестве источника данных для визуализации метрик. Используя шаблоны dashboard, предоставленные Selena, вы можете легко мониторить свой cluster Selena и настроить алерты для него с помощью Grafana.
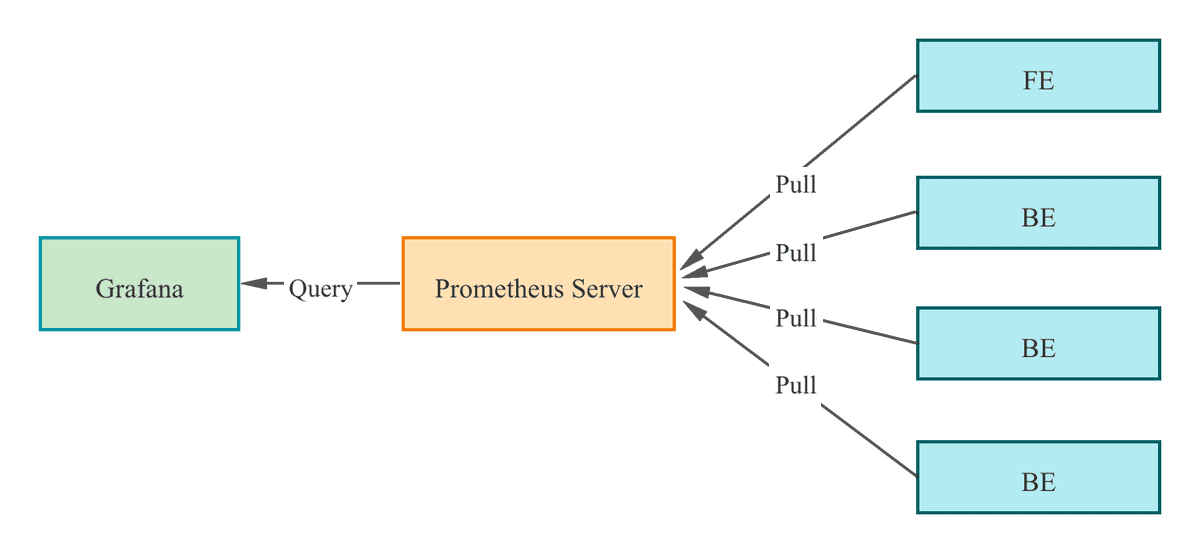
Выполните следующие шаги для интеграции вашего cluster Selena с Prometheus и Grafana:
- Установите необходимые компоненты - Prometheus и Grafana.
- Изучите основные метрики мониторинга Selena.
- Настройте канал алертов и правила алертов.
Шаг 1: Установка компонентов мониторинга
Порты по умолчанию Prometheus и Grafana не конфликтуют с портами Selena. Однако для production рекомендуется ра�зворачивать их на сервере, отличном от серверов ваших cluster Selena. Это уменьшает риск конфликтов ресурсов и избегает потенциального сбоя алертов из-за аварийного завершения работы сервера.
Кроме того, обратите внимание, что Prometheus и Grafana не могут мониторить доступность своих собственных сервисов. Поэтому в production-окружении рекомендуется использовать Supervisor для настройки heartbeat-сервиса для них.
Следующий tutorial разворачивает компоненты мониторинга на узле мониторинга (IP: 192.168.110.23) с использованием пользователя ОС root. Они мониторят следующий cluster Selena (который использует порты по умолчанию). При настройке сервиса мониторинга для вашего собственного cluster Selena на основе этого tutorial вам нужно только заменить IP-адреса.
| Host | IP | OS user | Services |
|---|---|---|---|
| node01 | 192.168.110.101 | root | 1 FE + 1 BE |
| node02 | 192.168.110.102 | root | 1 FE + 1 BE |
| node03 | 192.168.110.103 | root | 1 FE + 1 BE |
ПРИМЕЧАНИЕ
Prometheus и Grafana могут мониторить только узлы FE, BE и CN, но не узлы Broker.
1.1 Развертывание Prometheus
1.1.1 Загрузка Prometheus
Для Selena вам нужно только загрузить установочный пакет сервера Prometheus. Загрузите пакет на узел мониторинга.
Нажмите здесь, чтобы загрузить Prometheus.
Возьмем в качестве примера LTS-версию v1.5.2, нажмите на пакет, чтобы загрузить его.
Alternatively, вы можете загрузить его с помощью команды wget:
# Следующий пример загружает LTS-версию v1.5.2.
# Вы можете загрузить другие версии, заменив номер версии в команде.
wget https://github.com/prometheus/prometheus/releases/download/v1.5.2/prometheus-2.45.0.linux-amd64.tar.gz
После завершения загрузки загрузите или скопируйте установочный пакет в каталог /opt на узле мониторинга.
1.1.2 Установка Prometheus
-
Перейдите в /opt и распакуйте установочный пакет Prometheus.
cd /opt
tar xvf prometheus-2.45.0.linux-amd64.tar.gz -
Для удобства управления переименуйте распакованный каталог в prometheus.
mv prometheus-2.45.0.linux-amd64 prometheus -
Создайте путь для хранения данных для Prometheus.
mkdir prometheus/data -
Для удобства управления вы можете создать файл запуска системного сервиса для Prometheus.
vim /etc/systemd/system/prometheus.serviceДобавьте следующее содержимое в файл:
[Unit]
Description=Prometheus service
After=network.target
[Service]
User=root
Type=simple
ExecReload=/bin/sh -c "/bin/kill -1 `/usr/bin/pgrep prometheus`"
ExecStop=/bin/sh -c "/bin/kill -9 `/usr/bin/pgrep prometheus`"
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/opt/prometheus/data --storage.tsdb.retention.time=30d --storage.tsdb.retention.size=30GB
[Install]
WantedBy=multi-user.targetЗатем сохраните и выйдите из редактора.
ПРИМЕЧАНИЕ
Если вы разворачиваете Prometheus по другому пути, убедитесь, что синхронизировали путь в команде ExecStart в файле выше. Кроме того, файл настраивает условия истечения срока для хранения данных Prometheus как "30 дней или более" или "более 30 ГБ". Вы можете изменить это в соответствии с вашими потребностями.
-
Измените конфигурационный файл Prometheus prometheus/prometheus.yml. Этот файл имеет строгие требования к формату содержимого. Пожалуйста, обращайте особое внимание на пробелы и отступы при внесении изменений.
vim prometheus/prometheus.ymlДобавьте следующее содержимое в файл:
global:
scrape_interval: 15s # Установите глобальный интервал scrape равным 15s. По умолчанию 1 мин.
evaluation_interval: 15s # Установите глобальный интервал evaluation правил равным 15s. По умолчанию 1 мин.
scrape_configs:
- job_name: 'Selena_Cluster01' # Мониторимый cluster соответствует job. Вы можете настроить имя cluster Selena здесь.
metrics_path: '/metrics' # Укажите Restful API для получения метрик мониторинга.
static_configs:
# Следующая конфигурация указывает группу FE, которая включает 3 узла FE.
# Здесь вам нужно заполнить IP и HTTP-порты, соответствующие каждому FE.
# �Если вы изменили HTTP-порты во время развертывания cluster, обязательно настройте их соответственно.
- targets: ['192.168.110.101:8030','192.168.110.102:8030','192.168.110.103:8030']
labels:
group: fe
# Следующая конфигурация указывает группу BE, которая включает 3 узла BE.
# Здесь вам нужно заполнить IP и HTTP-порты, соответствующие каждому BE.
# Если вы изменили HTTP-порты во время развертывания cluster, обязательно настройте их соответственно.
- targets: ['192.168.110.101:8040','192.168.110.102:8040','192.168.110.103:8040']
labels:
group: beпримечаниеОбратите внимание, что Prometheus не может обнаружить изменения сервиса (
targets) после масштабирования cluster. Например, для cluster, развернутых на AWS, вы можете предоставить инстансу EC2, который размещает сервис Prometheus, разрешенияec2:DescribeInstancesиec2:DescribeTags, и добавить свойстваec2_sd_configsиrelabel_configsв prometheus/prometheus.yml. Для подробных инструкций см. Приложение - Включение обнаружения сервисов для Prometheus.После того, как вы изменили конфигурационный файл, вы можете использовать
promtoolдля проверки правильности изменений../prometheus/promtool check config prometheus/prometheus.ymlСледующее сообщение указывает, что проверка пройдена. Вы можете продолжить.
SUCCESS: prometheus/prometheus.yml is valid prometheus config file syntax -
Запустите Prometheus.
systemctl daemon-reload
systemctl start prometheus.service -
Проверьте статус Prometheus.
systemctl status prometheus.serviceЕсли возвращается
Active: active (running), это указывает, что Prometheus успешно запущен.Вы также можете использовать
netstatдля проверки статуса порта Prometheus по умолчанию (9090).netstat -nltp | grep 9090 -
Настройте Prometheus на запуск при загрузке.
systemctl enable prometheus.service
Другие команды:
-
Остановить Prometheus.
systemctl stop prometheus.service -
Перезапустить Prometheus.
systemctl restart prometheus.service -
Перезагрузить конфигурацию во время работы.
systemctl reload prometheus.service -
Отключить запуск при загрузке.
systemctl disable prometheus.service
1.1.3 Доступ к Prometheus
Вы можете получить доступ к Web UI Prometheus через браузер, порт по умолчанию - 9090. Для узла мониторинга в этом tutorial вам нужно посетить 192.168.110.23:9090.
На домашней странице Prometheus перейдите в Status --> Targets в верхнем меню. Здесь вы можете увидеть все мониторимые узлы для каждой группы job, настроенной в файле prometheus.yml. Обычно статус всех узлов должен быть UP, указывая, что коммуникация сервиса нормальная.
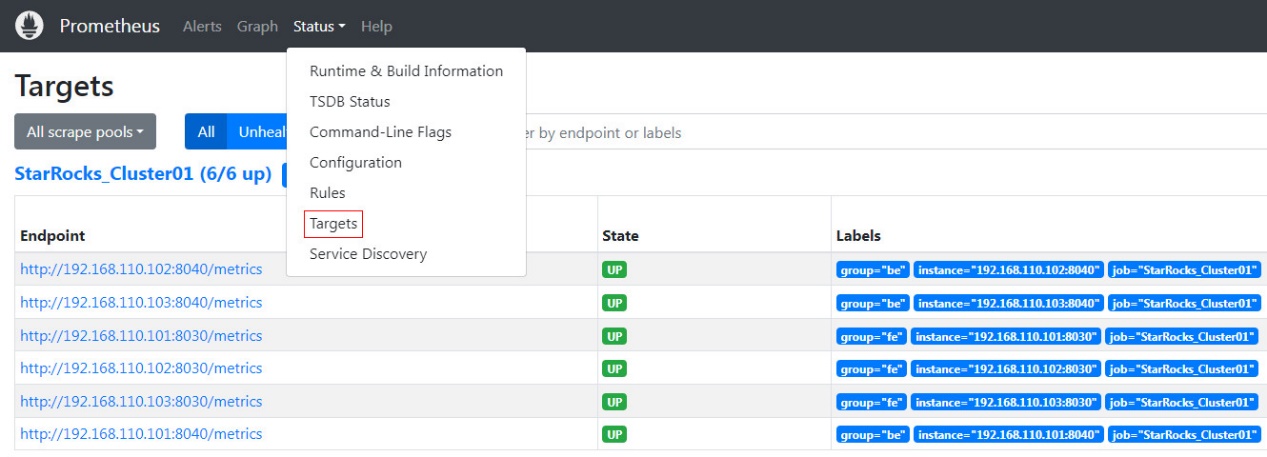
На этом этапе Prometheus настроен и установлен. Для более подробной информации вы можете обратиться к д�окументации Prometheus.
1.2 Развертывание Grafana
1.2.1 Загрузка Grafana
Нажмите здесь, чтобы загрузить Grafana.
Alternatively, вы можете использовать команду wget для загрузки установочного пакета Grafana RPM.
# Следующий пример загружает LTS-версию v10.0.3.
# Вы можете загрузить другие версии, заменив номер версии в команде.
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.3-1.x86_64.rpm
1.2.2 Установка Grafana
-
Используйте команду
yumдля установки Grafana. Эта команда автоматически установит зависимости, необходимые для Grafana.yum -y install grafana-enterprise-10.0.3-1.x86_64.rpm -
Запустите Grafana.
systemctl start grafana-server.service -
Проверьте статус Grafana.
systemctl status grafana-server.serviceЕсли возвращается
Active: active (running), это указывает, что Grafana успешно запущена.Вы также можете использовать
netstatдля проверки статуса порта Grafana по умолчанию (3000).netstat -nltp | grep 3000 -
Настройте Grafana на запуск при загрузке.
systemctl enable grafana-server.service
Другие команды:
-
Остановить Grafana.
systemctl stop grafana-server.service -
Перезапустить Grafana.
systemctl restart grafana-server.service -
Отключить запуск при загрузке.
systemctl disable grafana-server.service
Для дополнительной информации обратитесь к документации Grafana.
1.2.3 Доступ к Grafana
Вы можете получить доступ к Web UI Grafana через браузер, порт по умолчанию - 3000. Для узла мониторинга в этом tutorial вам нужно посетить 192.168.110.23:3000. Имя пользователя и пароль по умолчанию, необходимые для входа, оба установлены на admin. При первом входе Grafana предложит вам изменить пароль по умолчанию. Если вы хотите пропустить это сейчас, вы можете нажать Skip. Затем вы будете перенаправлены на домашнюю страницу Web UI Grafana.
1.2.4 Настройка источников данных
Нажмите на кнопку меню в верхнем левом углу, разверните Administration, а затем нажмите Data sources.
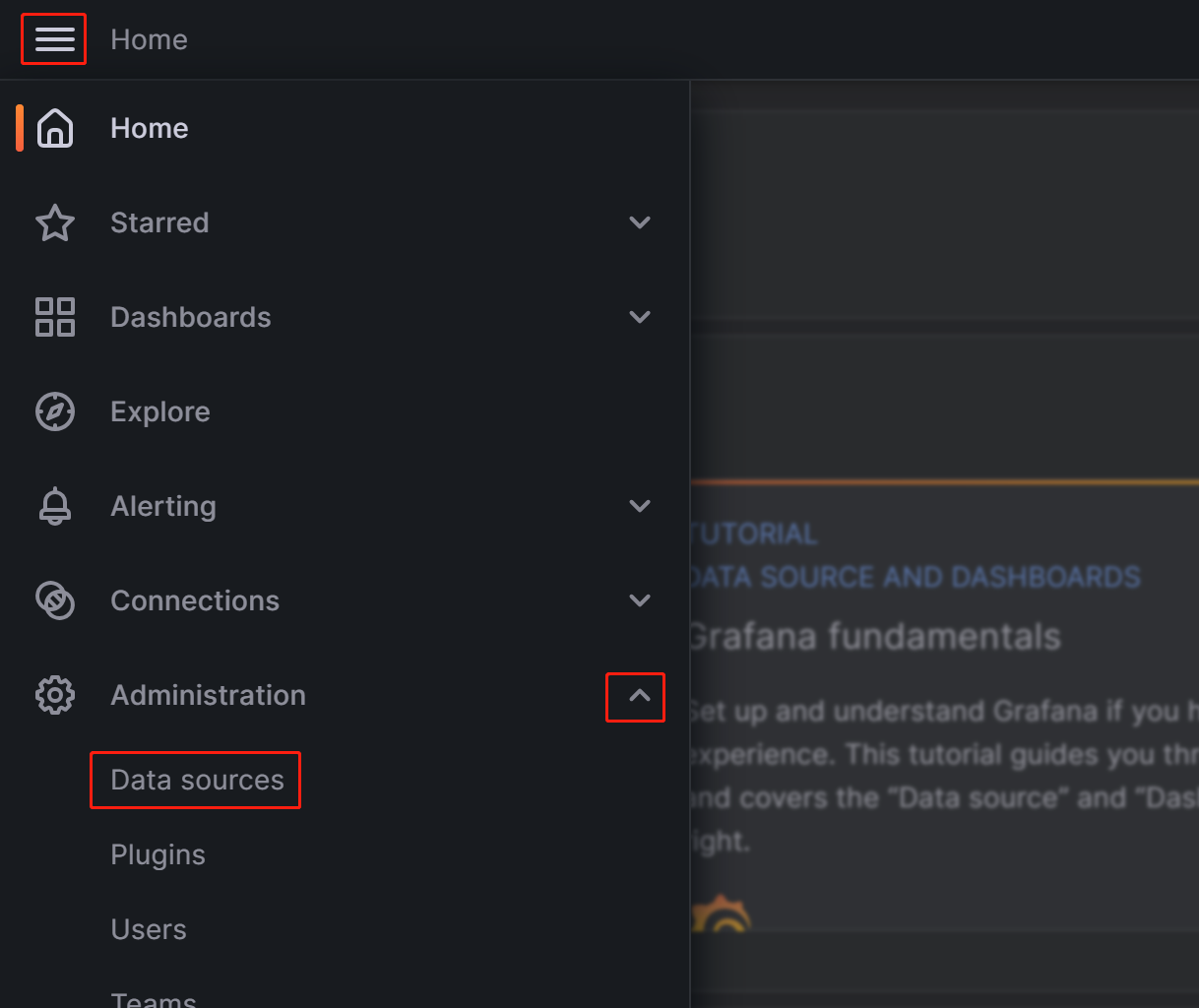
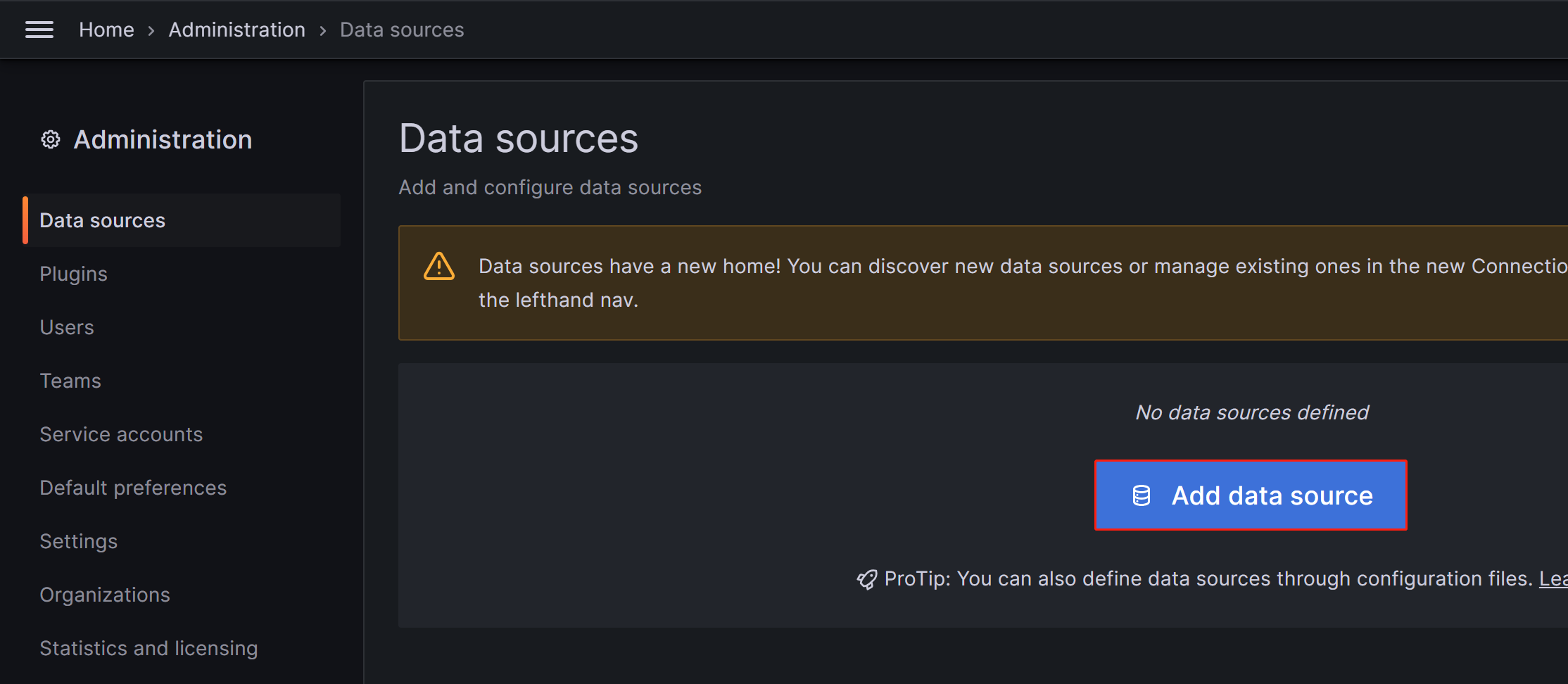
На появившейся странице нажмите Add data source, а затем выберите Prometheus.
Чтобы интегрировать Grafana с вашим сервисом Prometheus, вам необходимо изменить следующую конфигурацию:
-
Name: Имя источника данных. Вы можете настроить имя для источника данных.

-
Prometheus Server URL: URL сервера Prometheus, который в этом tutorial является
http://192.168.110.23:9090.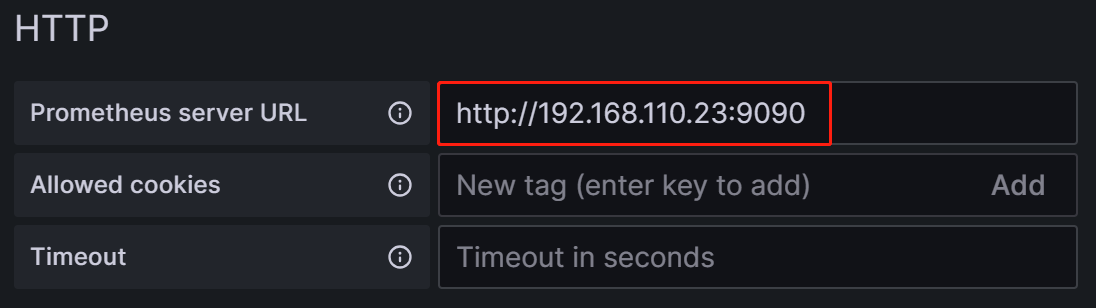
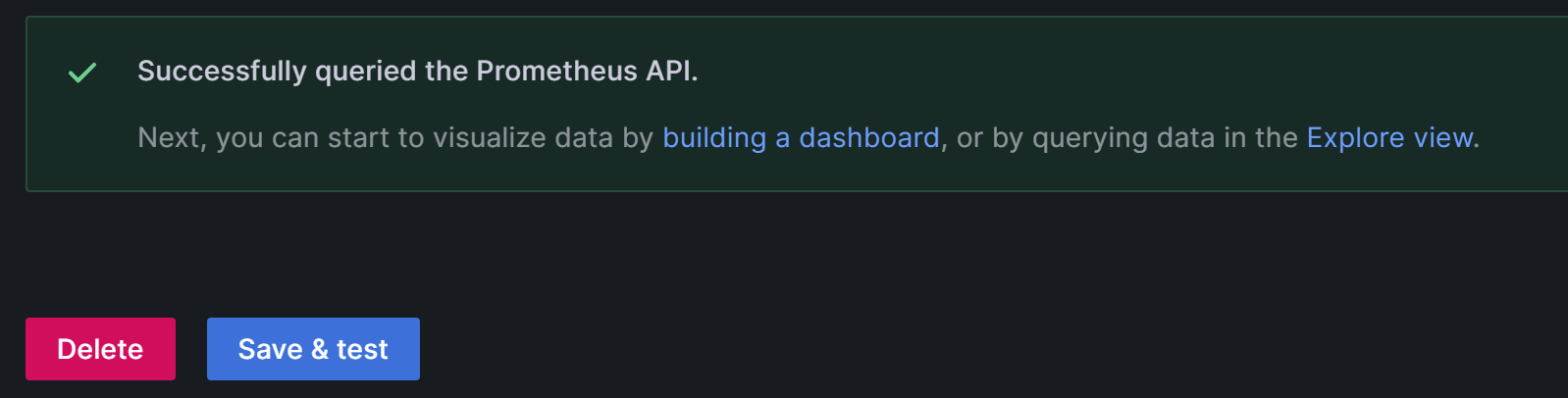
После завершения конфигурации нажмите Save & Test, чтобы сохранить и проверить конфигурацию. Если отображается Successfully queried the Prometheus API, это означает, что источник данных доступен.
1.2.5 Настройка Dashboard
-
Загрузите соответствующий шаблон Dashboard на основе вашей версии Selena.
- Шаблон Dashboard для всех архитектур
- Шаблон Dashboard для Shared-data Cluster - General
- Шаблон Dashboard для Shared-data Cluster - Starlet
ПРИМЕЧАНИЕ
Файл шаблона необходимо загрузить через Web UI Grafana. Поэтому вам нужно загрузить файл шаблона на машину, которую вы используете для доступа к Grafana, а не на сам узел мониторинга.
-
Настройте шаблон Dashboard.
Нажмите на кнопку меню в верхнем левом углу и нажмите Dashboards.
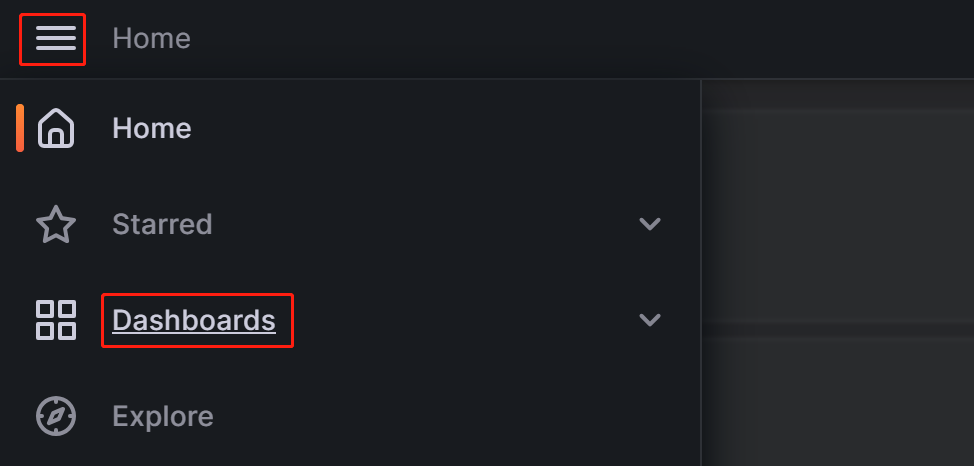
На появившейся странице разверните кнопку New и нажмите Import.
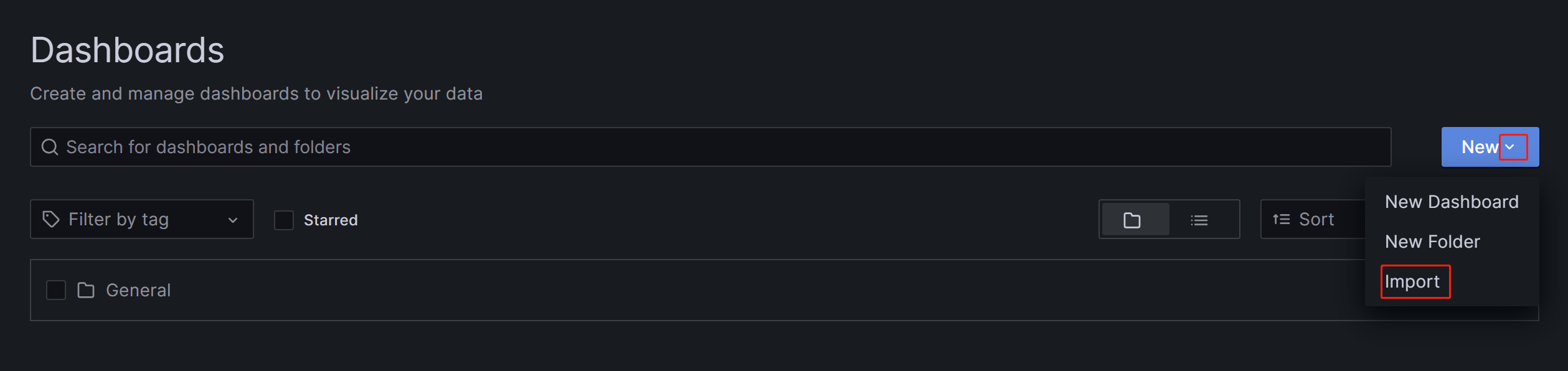
На новой странице нажмите на Upload Dashboard JSON file и загрузите файл шаблона, который вы загрузили ранее.
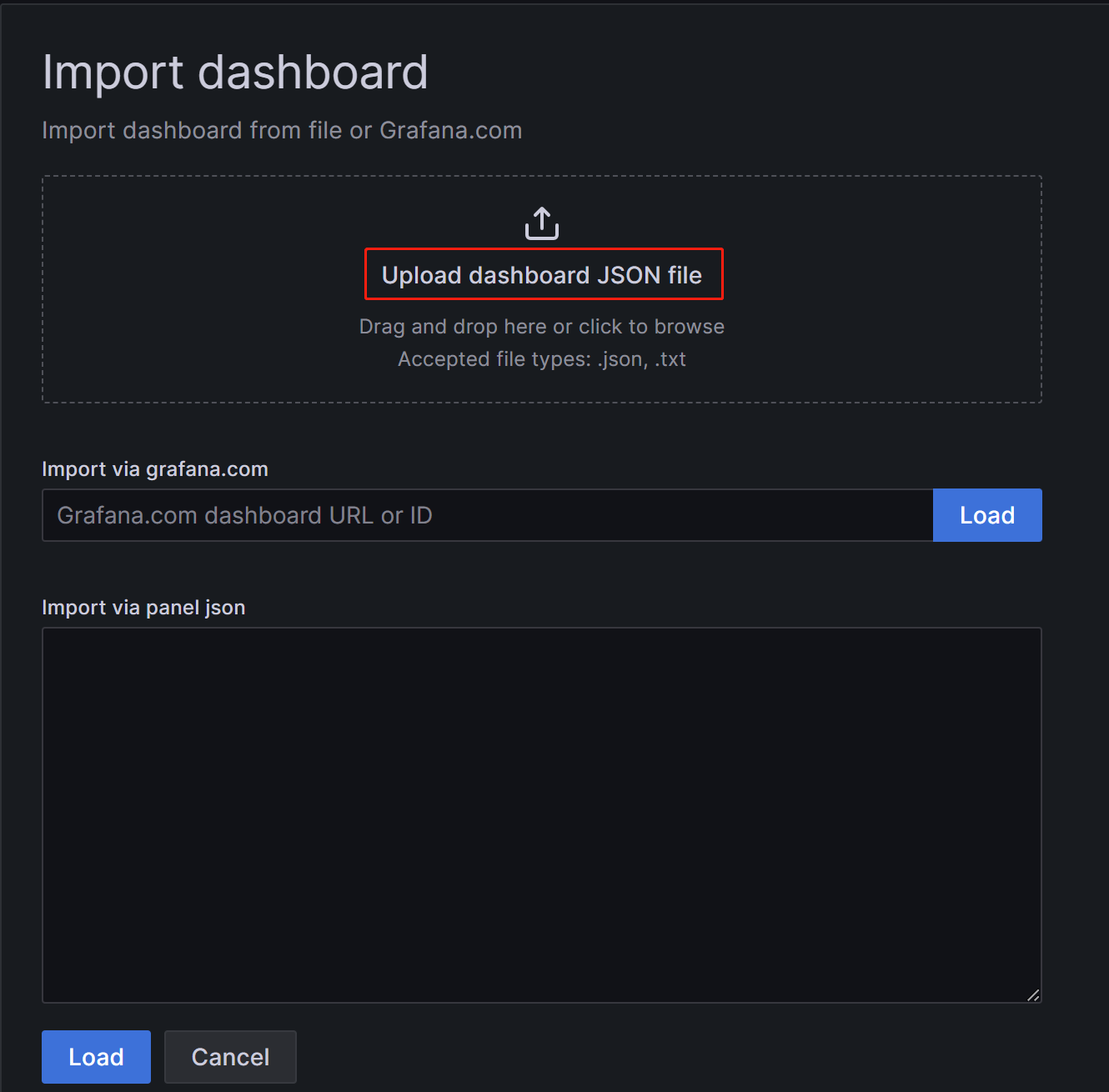
После загрузки файла вы можете переименовать Dashboard. По умолчанию он назван
Selena Overview. Затем выберите источник данных, который вы создали ранее (selena_monitor). Затем нажмите Import.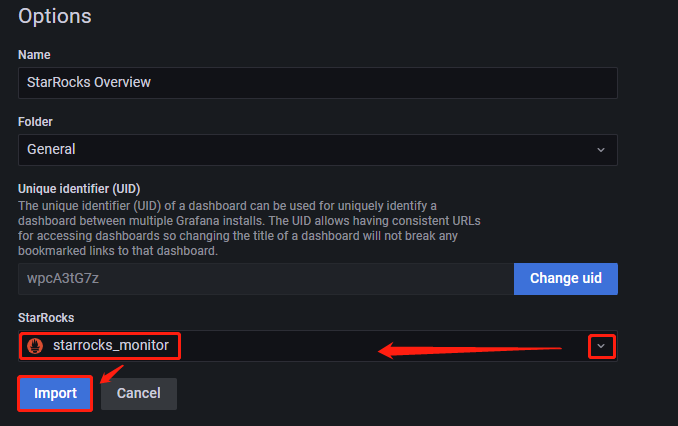
После завершения импорта вы долж�ны увидеть отображенный Dashboard Selena.
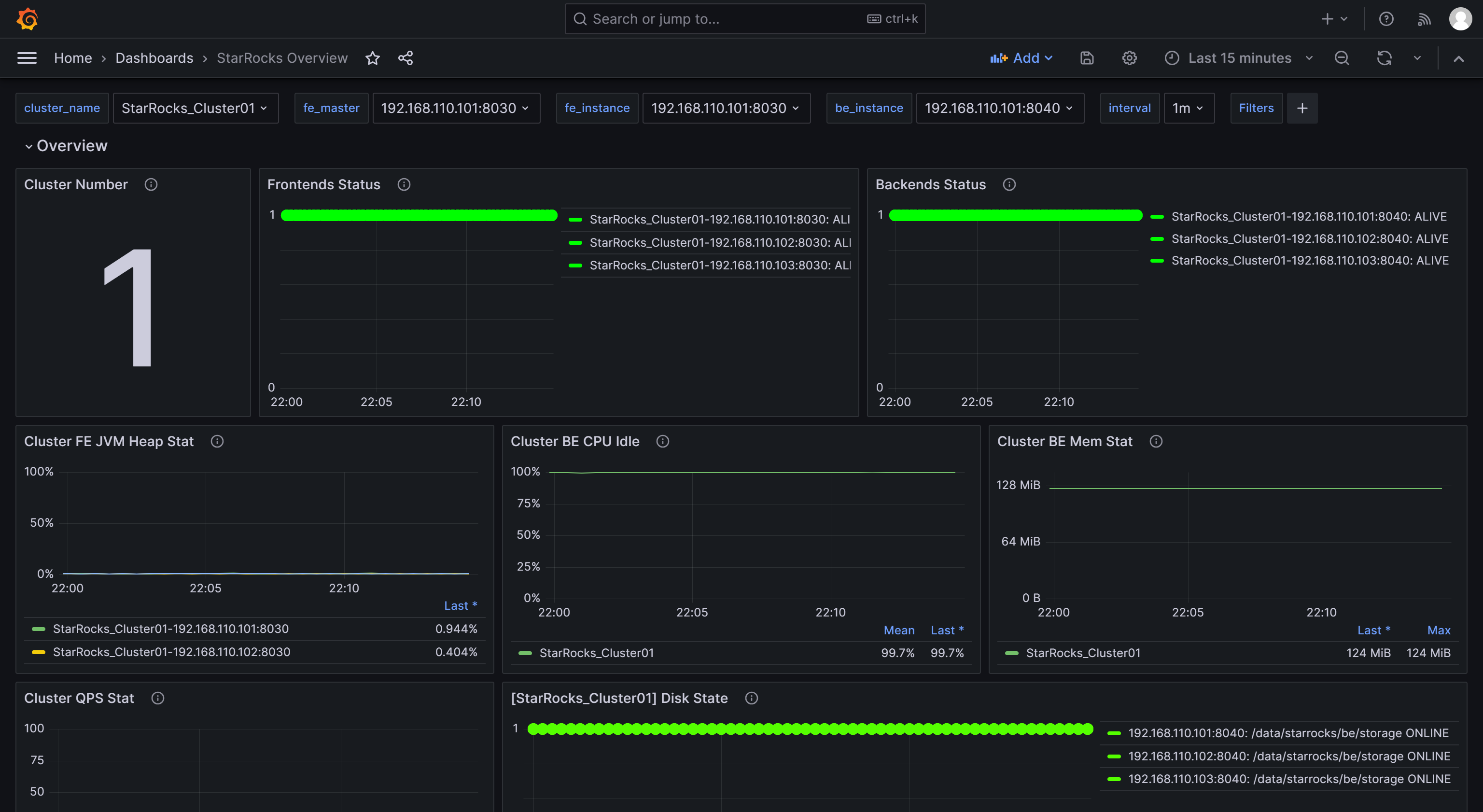
1.2.6 Мониторинг Selena через Grafana
Войдите в Web UI Grafana, нажмите на кнопку меню в верхнем левом углу и нажмите Dashboards.
На появившейся странице выберите Selena Overview из каталога General.
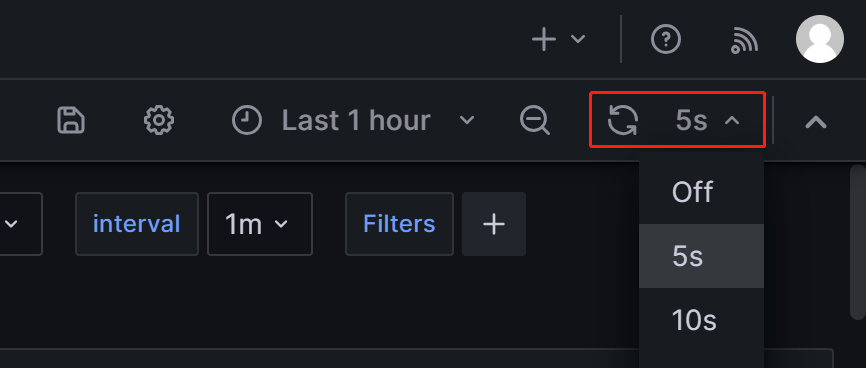
После входа в Dashboard мониторинга Selena вы можете вручную обновить страницу в верхнем правом углу или установить интервал автоматического обновления для мониторинга статуса cluster Selena.
Шаг 2: Понимание основных метрик мониторинга
Чтобы удовлетворить потребности разработки, operations, DBA и других, Selena предоставляет широкий спектр метрик мониторинга. В этом разделе представлены только некоторые важные метрики, обычно используемые в бизнесе, и их правила алертов. Для других деталей метрик, пожалуйста, обратитесь к Метрики мониторинга.
2.1 Метрики для статуса FE и BE
| Metric | Description | Alert rule | Note |
|---|---|---|---|
| Frontends Status | Статус узла FE. Статус активного узла представлен как 1, в то время как узел, который выключен (DEAD), будет отображаться как 0. | Статус всех узлов FE должен быть активным, и любой узел FE со статусом DEAD должен вызывать алерт. | Сбой любых узлов FE или BE считается критическим и требует немедленного устранения неполадок для выявления причины сбоя. |
| Backends Status | Статус узла BE. Статус активного узла представлен как 1, в то время как узел, который выключен (DEAD), будет отображаться как 0. | Статус всех узлов BE должен быть активным, и любой узел BE со статусом DEAD должен вызывать алерт. |
2.2 Метрики для сбоев запросов
| Metric | Description | Alert rule | Note |
|---|---|---|---|
| Query Error | Частота сбоев запросов (включая timeout) в течение одной минуты. Его значение рассчитывается как количество неудачных запросов за одну минуту, деленное на 60 секунд. | Вы можете настроить это на основе фактического QPS вашего бизнеса. Например, 0.05 можно использовать в качестве предварительной настройки. Вы можете настроить это позже по мере необходимости. | Обычно частота сбоев запросов должна быть низкой. Установка этого порога на 0.05 означает допущение максимум 3 неудачных запросов в минуту. Если вы получите алерт от этого элемента, вы можете проверить использование ресурсов или соответствующим образом настроить timeout запроса. |
2.3 Метрики для сбоев внешних операций
| Metric | Description | Alert rule | Note |
|---|---|---|---|
| Schema Change | Частота сбоев операции Schema Change. | Schema Change - это низкочастотная операция. Вы можете настроить этот элемент для отправки алерта немедленно при сбое. | Обычно операции Schema Change не должны завершаться сбоем. Если алерт запускается для этого элемента, вы можете рассмотреть возможность увеличения лимита памяти операций Schema Change, который по умолчанию установлен на 2 ГБ. |
2.4 Метрики для сбоев внутренних операций
| Metric | Description | Alert rule | Note |
|---|---|---|---|
| BE Compaction Score | Наивысший Compaction Score среди всех узлов BE, указывающий на текущее давление compaction. | В типичных offline-сценариях это значение обычно ниже 100. Однако при большом количестве задач загрузки Compaction Score может значительно увеличиться. В большинстве случаев требуется вмешательство, когда это значение превышает 800. | Обычно, если Compaction Score больше 1000, Selena вернет ошибку "Too many versions". В таких случаях вы можете рассмотреть возможность уменьшения concurrency и частоты загрузки. |
| Clone | Частота сбоев операции клонирования tablet. | Вы можете настроить этот элемент для отправки алерта немедленно при сбое. | Если алерт запускается для этого элемента, вы можете проверить статус узлов BE, статус диска и статус сети. |
2.5 Метрики для доступности сервиса
| Metric | Description | Alert rule | Note |
|---|---|---|---|
| Meta Log Count | Количество записей лога метаданных BDB на узле FE. | Рекомендуется настроить этот элемент для немедленного алерта, если он превышает 100 000. | По умолчанию узел leader FE запускает checkpoint для сброса лога на диск, когда количество логов превышает 50 000. Если это значение превышает 50 000 на большой запас, это обычно указывает на сбой checkpoint. Вы можете проверить, является ли конфигурация heap-памяти Xmx разумной в fe.conf. |
2.6 Метрики для нагрузки системы
| Metric | Description | Alert rule | Note |
|---|---|---|---|
| BE CPU Idle | Процент простоя CPU узла BE. | Рекомендуется настроить этот элемент для алерта, если процент простоя ниже 10% в течение 30 последовательных секунд. | Этот элемент используется для мониторинга узких мест ресурсов CPU. Использование CPU может значительно колебаться, и установка небольшого интервала опроса может привести к ложным алертам. Поэтому вам нужно настроить этот элемент на основе фактических условий бизнеса. Если у вас есть несколько задач пакетной обработки или большое количество запросов, вы можете рассмотреть возможность установки более низкого порога. |
| BE Mem | Использование памяти для узла BE. | Рекомендуется настроить этот элемент на 90% от доступного размера памяти для каждого BE. | Это значение эквивалентно значению Process Mem, и лимит памяти BE по умолчанию составляет 90% от размера памяти сервера (контролируется конфигурацией mem_limit в be.conf). Если вы развернули другие сервисы на том же сервере, обязательно настройте это значение, чтобы избежать OOM. Порог алерта для этого элемента должен быть установлен на 90% от фактического лимита памяти BE, чтобы вы могли подтвердить, достигли ли ресурсы памяти BE узкого места. |
| Disks Avail Capacity | Соотношение доступного дискового пространства (процент) локальных дисков на каждом узле BE. | Рекомендуется настроить этот элемент для алерта, если значение меньше 20%. | Рекомендуется зарезервировать достаточное доступное пространство для Selena на основе ваших бизнес-требований. |
| FE JVM Heap Stat | Процент использования heap-памяти JVM для каждого узла FE в cluster. | Рекомендуется настроить этот элемент для алерта, если значение больше или равно 80%. | Если алерт запускается для этого элемента, рекомендуется увеличить конфигурацию heap-памяти Xmx в fe.conf; в противном случае это может повлиять на эффективность запросов или привести к проблемам FE OOM. |
Шаг 3: Настройка алертов через Email
3.1 Настройка SMTP-сервиса
Grafana поддерживает различные решения для алертов, такие как email и webhooks. Этот tutorial использует email в качестве примера.
Чтобы включить алерты по email, сначала вам нужно настроить информацию SMTP в Grafana, позволяя Grafana отправлять email на ваш почтовый ящик. Большинство часто используемых почтовых провайдеров поддерживают SMTP-сервисы, и вам нужно включить SMTP-сервис для вашей учетной записи email и получить код авторизации.
После выполнения этих шагов измените конфигурационный файл Grafana на узле, где развернута Grafana.
vim /usr/share/grafana/conf/defaults.ini
Пример:
###################### SMTP / Emailing #####################
[smtp]
enabled = true
host = <smtp_server_address_and_port>
user = johndoe@gmail.com
# If the password contains # or ; you have to wrap it with triple quotes.Ex """#password;"""
password = ABCDEFGHIJKLMNOP # Пароль авторизации, полученный после включения SMTP.
cert_file =
key_file =
skip_verify = true ## Проверить SSL для SMTP-сервера
from_address = johndoe@gmail.com ## Адрес, используемый при отправке email.
from_name = Grafana
ehlo_identity =
startTLS_policy =
[emails]
welcome_email_on_sign_up = false
templates_pattern = emails/*.html, emails/*.txt
content_types = text/html
Вам необходимо изменить следующие элементы конфигурации:
enabled: Разрешить ли Grafana отправлять email-алерты. Установите этот элемент наtrue.host: Адрес и порт SMTP-сервера для вашего email, разделенные двоеточием (:). Пример:smtp.gmail.com:465.user: Имя пользователя SMTP.password: Пароль авторизации, полученный после включения SMTP.skip_verify: Пропускать ли проверку SSL для SMTP-сервера. Установите этот элемент наtrue.from_address: Адрес email, используемый для отправки email-алертов.
После завершения конфигурации перезапустите Grafana.
systemctl daemon-reload
systemctl restart grafana-server.service
3.2 Создание канала алертов
Вам нужно создать канал алертов (Contact Point) в Grafana, чтобы указать, как уведомлять контакты, когда запускается алерт.
-
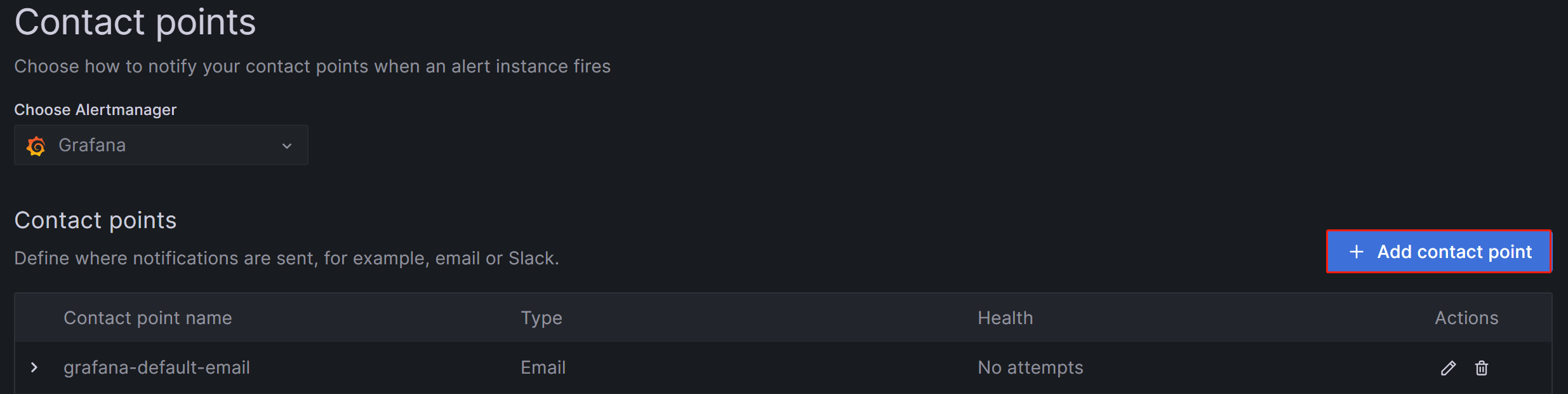
Войдите в Web UI Grafana, нажмите на кнопку меню в верхнем левом углу, разверните Alerting и выберите Contact Points. На странице Contact points нажмите Add contact point, чтобы создать новый канал алертов.
-
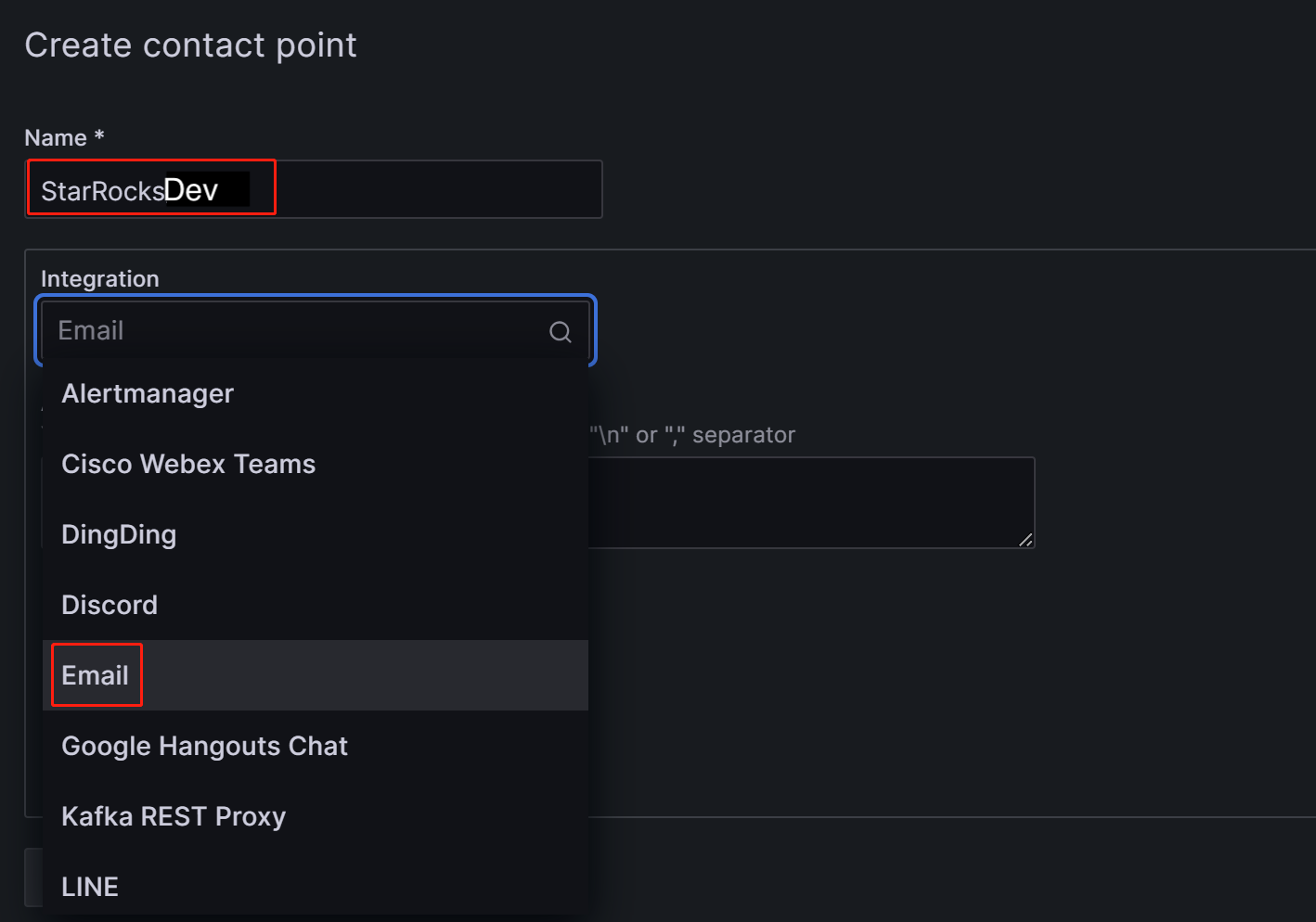
В поле Name настройте имя точки контакта. Затем в выпадающем списке Integration выберите Email.
-
В поле Addresses введите адрес�а email контактов для получения алерта. Если есть несколько адресов email, разделите адреса точками с запятой (
;), запятыми (,) или переносами строк.Конфигурации на странице можно оставить со значениями по умолчанию, за исключением следующих двух элементов:
- Single email: При включении, если есть несколько контактов, алерт будет отправлен им через один email. Рекомендуется включить этот элемент.
- Disable resolved message: По умолчанию, когда проблема, вызвавшая алерт, решена, Grafana отправляет другое уведомление о восстановлении сервиса. Если вам не нужно это уведомление о восстановлении, вы можете отключить этот элемент. Не рекомендуется отключать эту опцию.
-
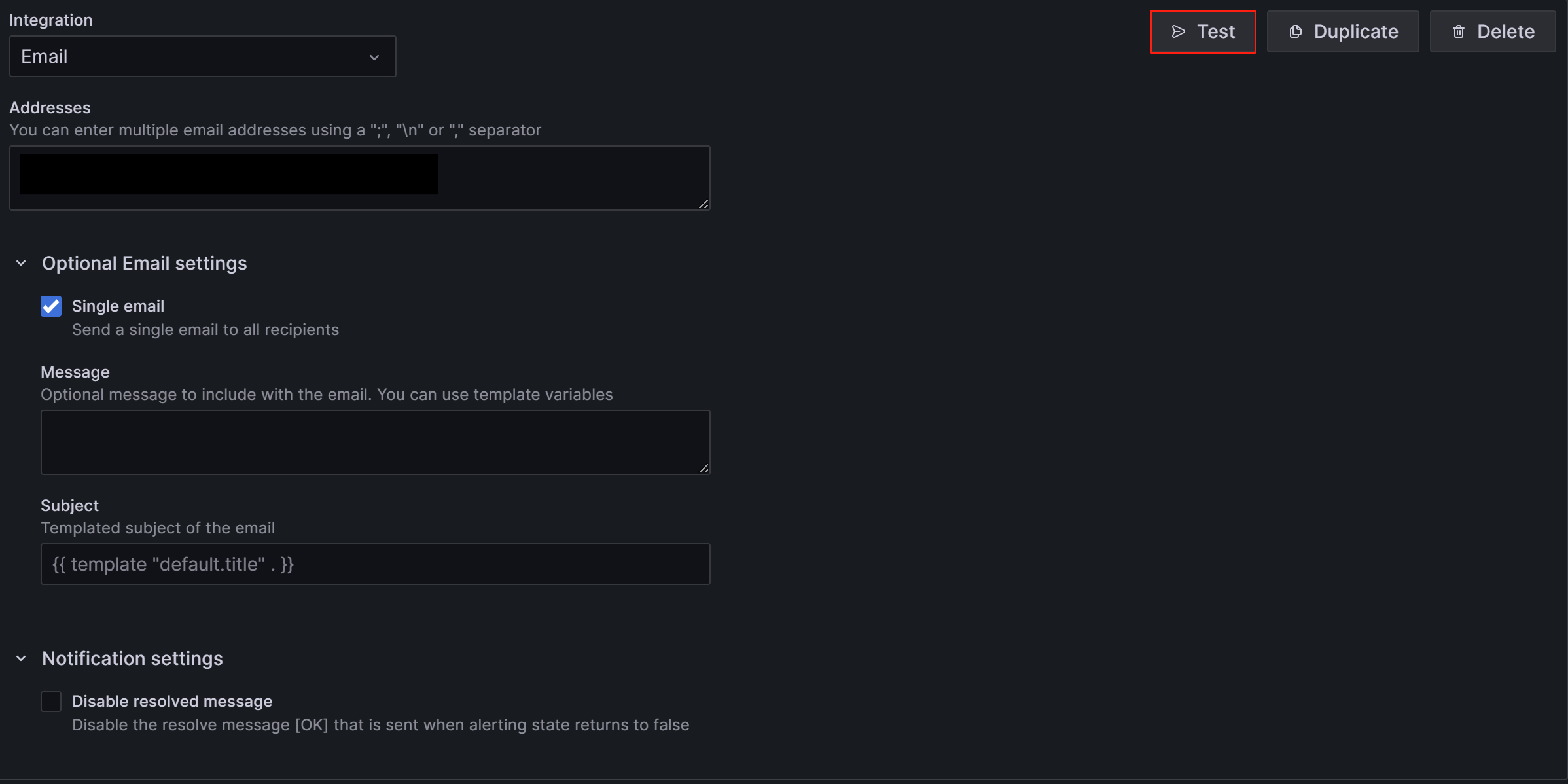
После завершения конфигурации нажмите кнопку Test в верхнем правом углу страницы. В появившемся сообщении нажмите Sent test notification. Если ваш SMTP-сервис и конфигурация адреса правильные, целевая учетная запись email должна получить тестовый email с темой "TestAlert Grafana". После подтверждения, что вы можете успешно получить тестовый email алерта, нажмите кнопку Save contact point внизу страницы, чтобы завершить к�онфигурацию.
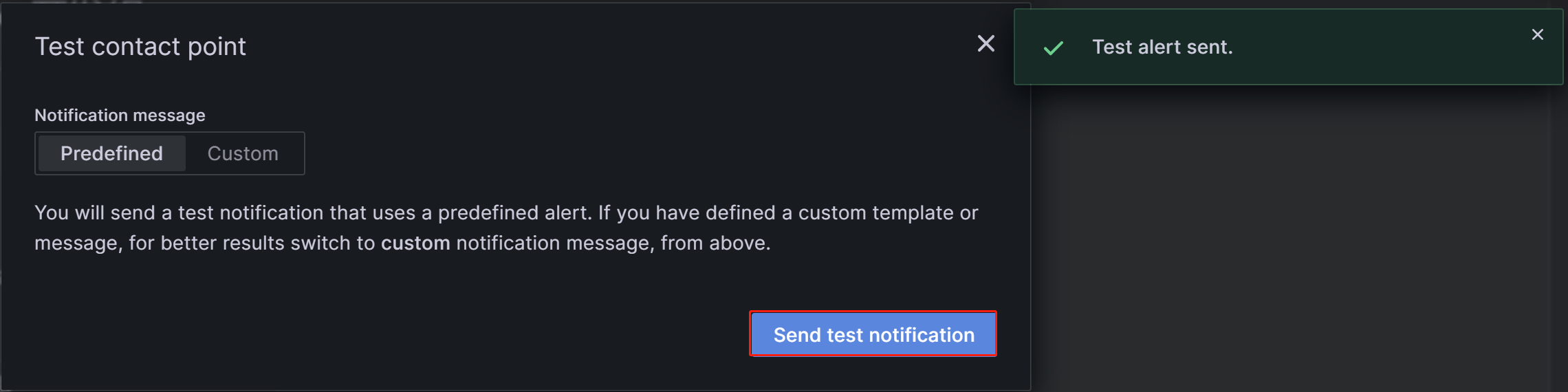
Вы можете настроить несколько методов уведомлений для каждой точки контакта через "Add contact point integration", что не будет подробно рассмотрено здесь. Для более подробной информации о Contact Points вы можете обратиться к документации Grafana
Для последующей демонстрации предположим, что на этом шаге вы создали две точки контакта, "SelenaDev" и "SelenaOp", используя разные адреса email.
3.3 Установка политик уведомлений
Grafana использует политики уведомлений для связывания точек контакта с правилами алертов. Политики уведомлений используют соответствующие labels для обеспечения гибкого �способа маршрутизации различных алертов разным контактам, позволяя группировку алертов во время O&M.
-
Войдите в Web UI Grafana, нажмите на кнопку меню в верхнем левом углу, разверните Alerting и выберите Notification policies.
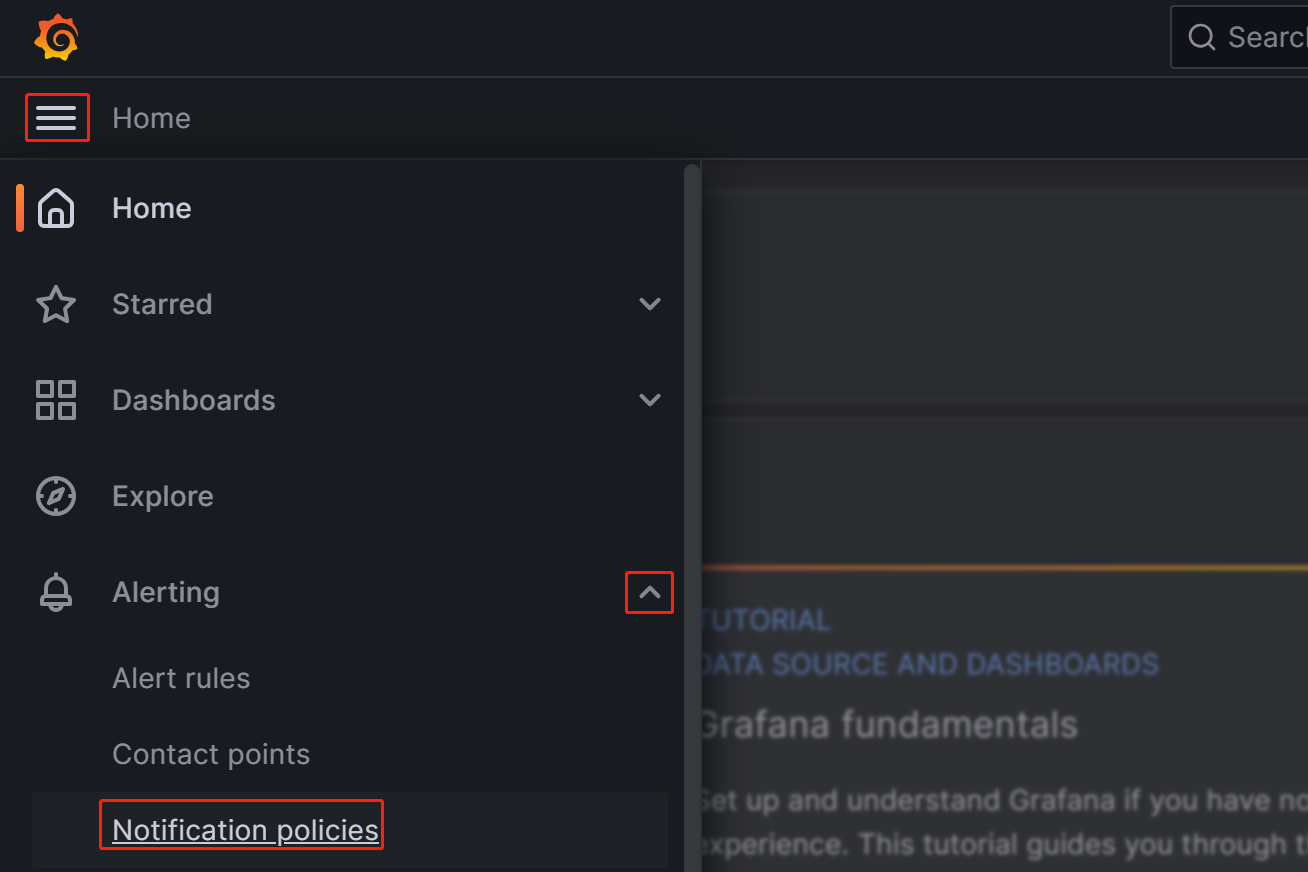
-
На странице Notification policies нажмите значок more (...) справа от Default policy и нажмите Edit, чтобы изменить политику по умолчанию.
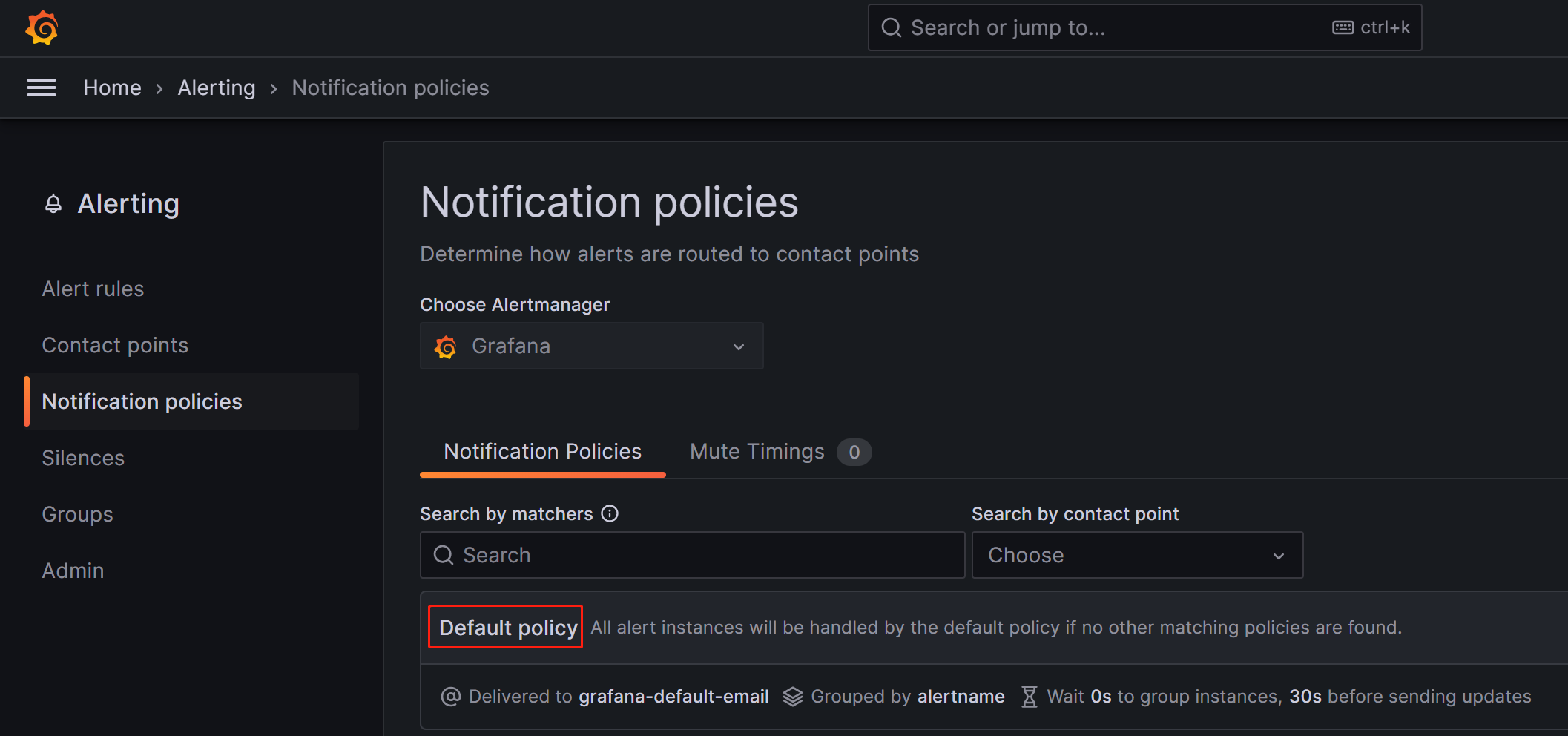
Политики уведомлений используют древовидную структуру, и политика по умолчанию представляет собой корневую политику по умолчанию для уведомления. Когда другие политики не установлены, все правила алертов по умолчанию будут соответствовать этой политике. Затем она будет использовать точку контакта по умолчанию, настроенную в ней, для уведомлений.
-
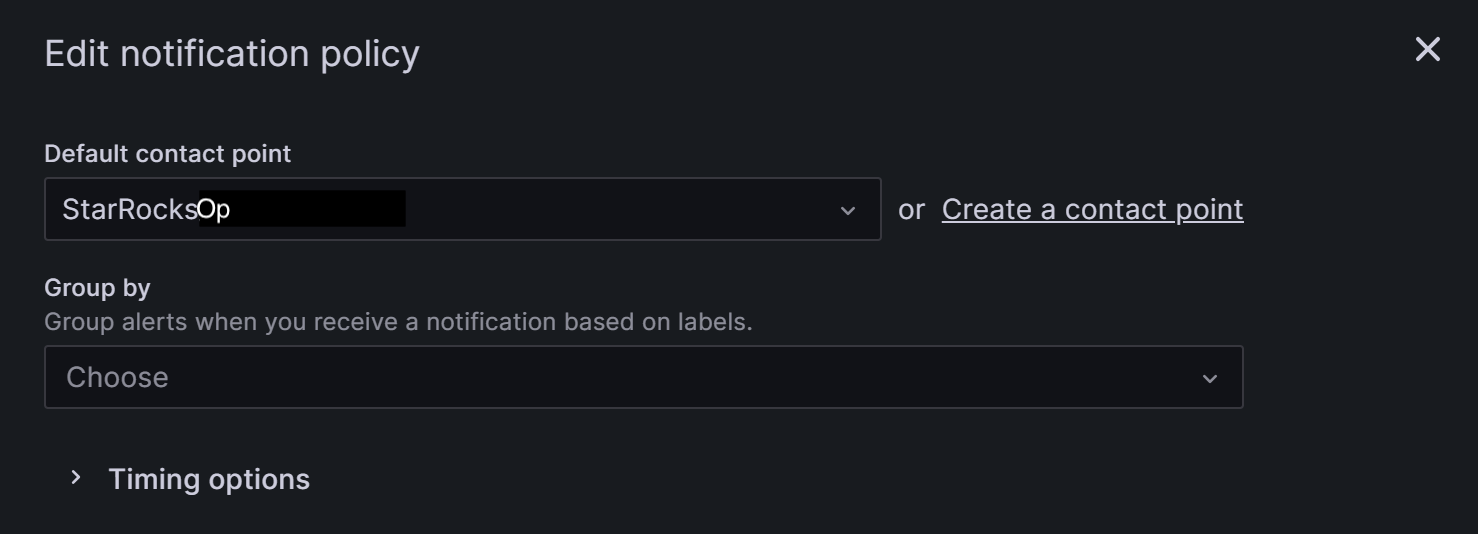
В поле Default contact point выберите точку контакта, которую вы создали ранее, например, "SelenaOp".
-
Group by - это ключевая концепция в Grafana Alerting, группирующая инстансы алертов с похожими характеристиками в одну воронку. Этот tutorial не включает группировку, и вы можете использовать настройку по умолчанию.
-
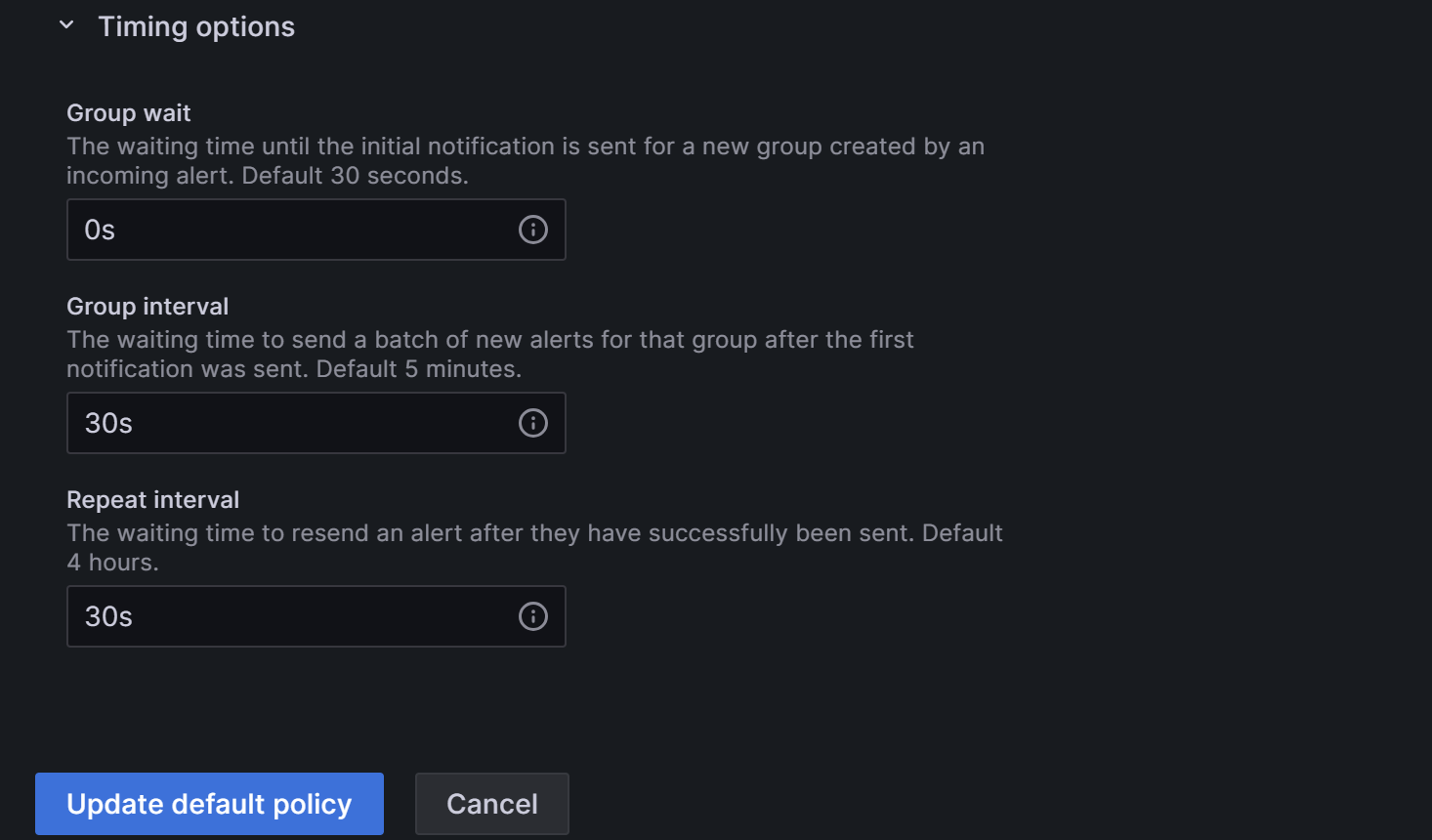
Разверните поле Timing options и настройте Group wait, Group interval и Repeat interval.
- Group wait: Время ожидания для начальной отправки уведомления после того, как новый алерт создает новую группу. По умолчанию 30 секунд.
- Group interval: Интервал, с которым отправляются алерты для существующей группы. По умолчанию 5 минут, что означает, что уведомления не будут отправляться этой группе раньше, чем через 5 минут с момента отправки предыдущего алерта. Это означает, что уведомления не будут отправляться раньше, чем через 5 минут (по умолчанию) с момента последней пакетной доставки обновлений, независимо от того, был ли интервал правила алерта для этих инстансов алертов ниже. По умолчанию 5 минут.
- Repeat interval: Время ожидания для повторной отправки алерта после того, как они были успешно отправлены. Интервал, с которым отправляются алерты для существующей группы. По умолчанию 5 минут, что означает, что уведомления не будут отправляться этой группе раньше, чем через 5 минут с момента отправки предыдущего алерта.
Вы можете настроить параметры, как показано ниже, чтобы Grafana отправляла алерт по этим правилам: 0 секунд (Group wait) после выполнения условий алерта, Grafana отправит первый email алерта. После этого Grafana будет повторно отправлять алерт каждую 1 минуту (Group interval + Repeat interval).
ПРИМЕЧАНИЕ
В предыдущем абзаце используется "выполнение условий алерта", а не "достижение порога алерта", чтобы избежать ложных алертов. Рекомендуется установить алерт для запуска через определенную продолжительность времени после достижения порога.
-
-
После завершения конфигурации нажмите Update default policy.
-
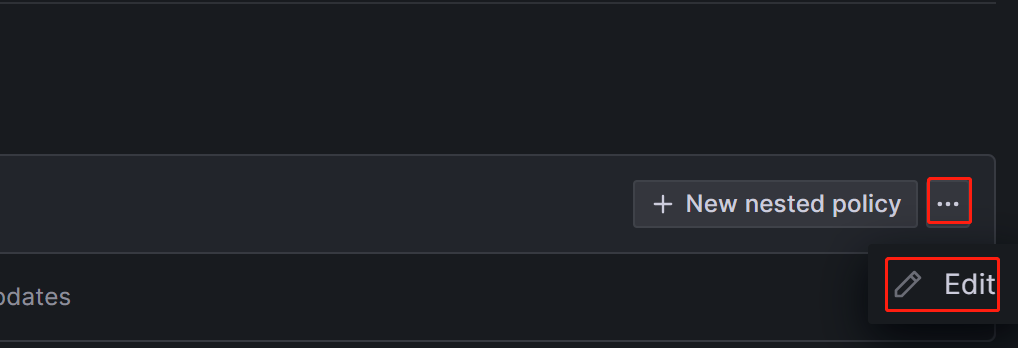
Если вам нужно создать вложенную политику, нажмите на New nested policy на странице Notification policies.
Вложенные политики используют labels для определения правил соответствия. Labels, определенные во вложенной политике, могут использоваться в качестве условий для соответствия при настройке правил алертов позже. Следующий пример настраивает label как
Group=Development_team.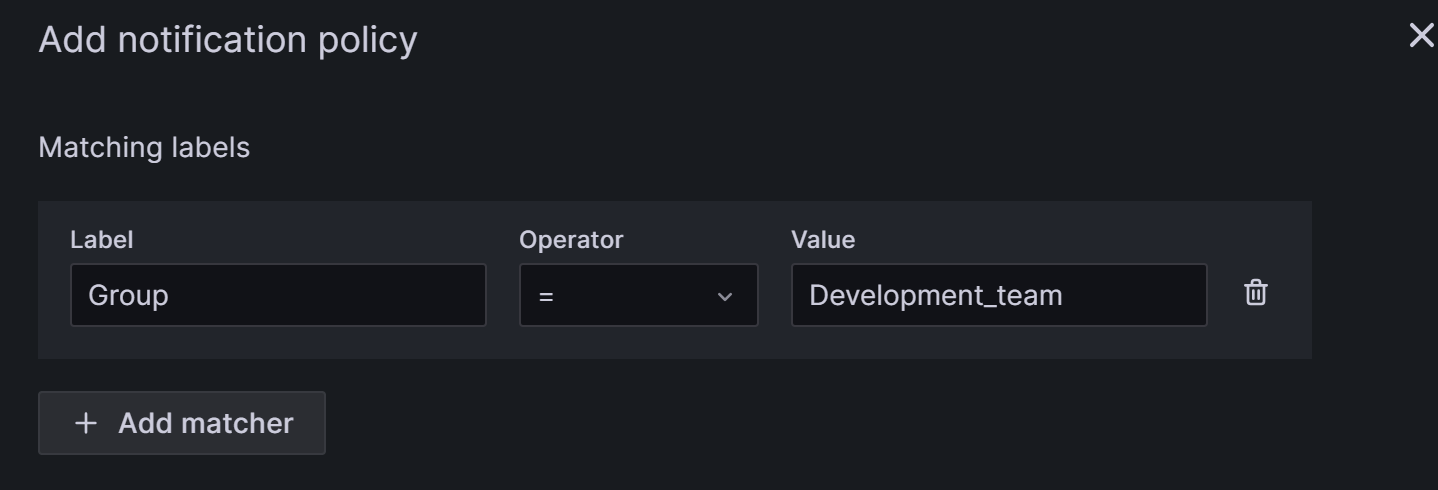
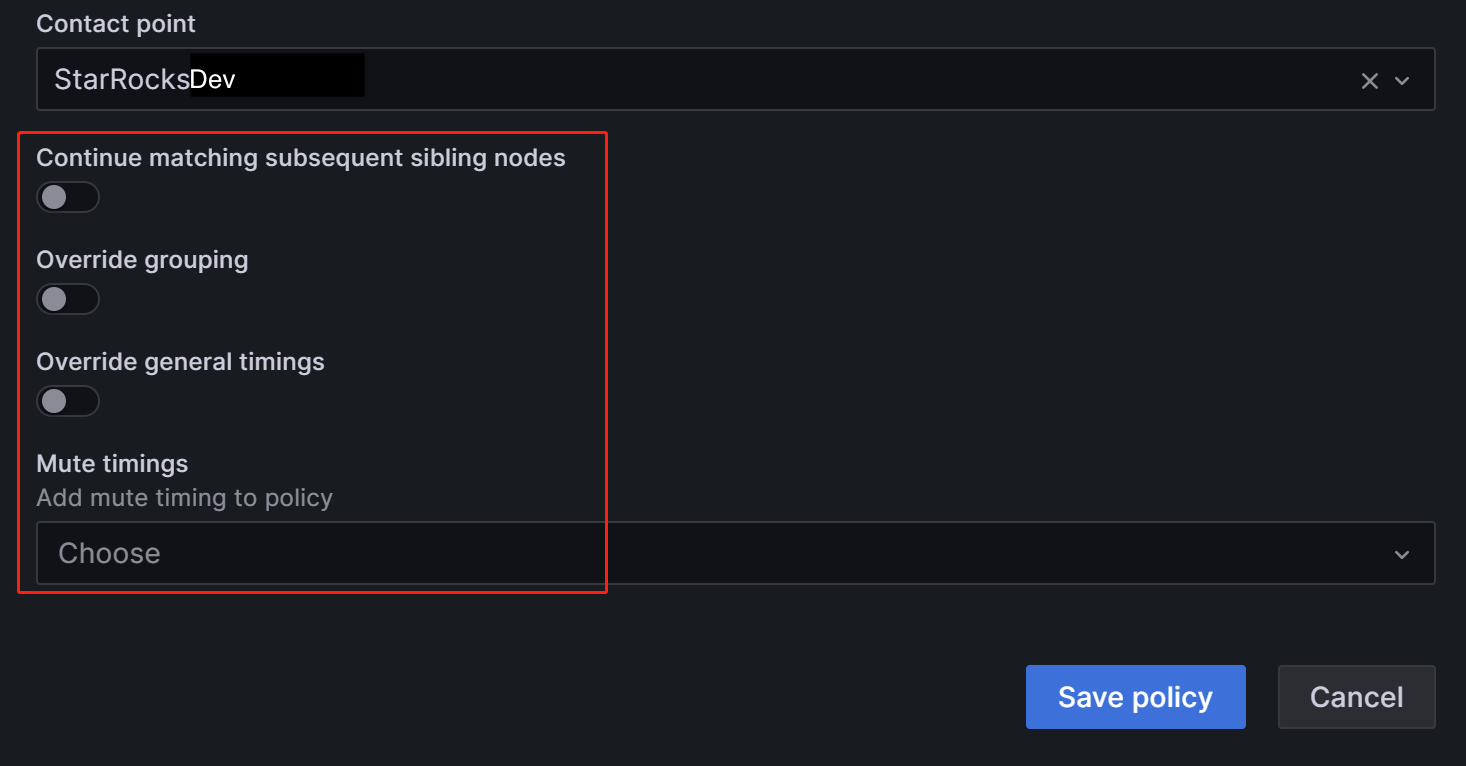
В поле Contact point выберите "SelenaDev". Таким образом, при настройке правил алертов с label
Group=Development_team, "SelenaDev" будет настроен для получения алертов.Вы можете сделать так, чтобы вложенная политика наследовала опции времени от родительской политики. После завершения конфигурации нажмите Save policy, чтобы сохранить политику.
Если вас интересуют детали политик уведомлений или если ваш бизнес имеет более сложные сценарии алертов, вы можете обратиться к документации Grafana для дополнительной информации.
3.4 Определение правил алертов
После настройки политик уведомлений вам также нужно определить правила алертов для Selena.
Войдите в Web UI Grafana, найдите и перейдите к ранее настроенному Selena Overview Dashboard.

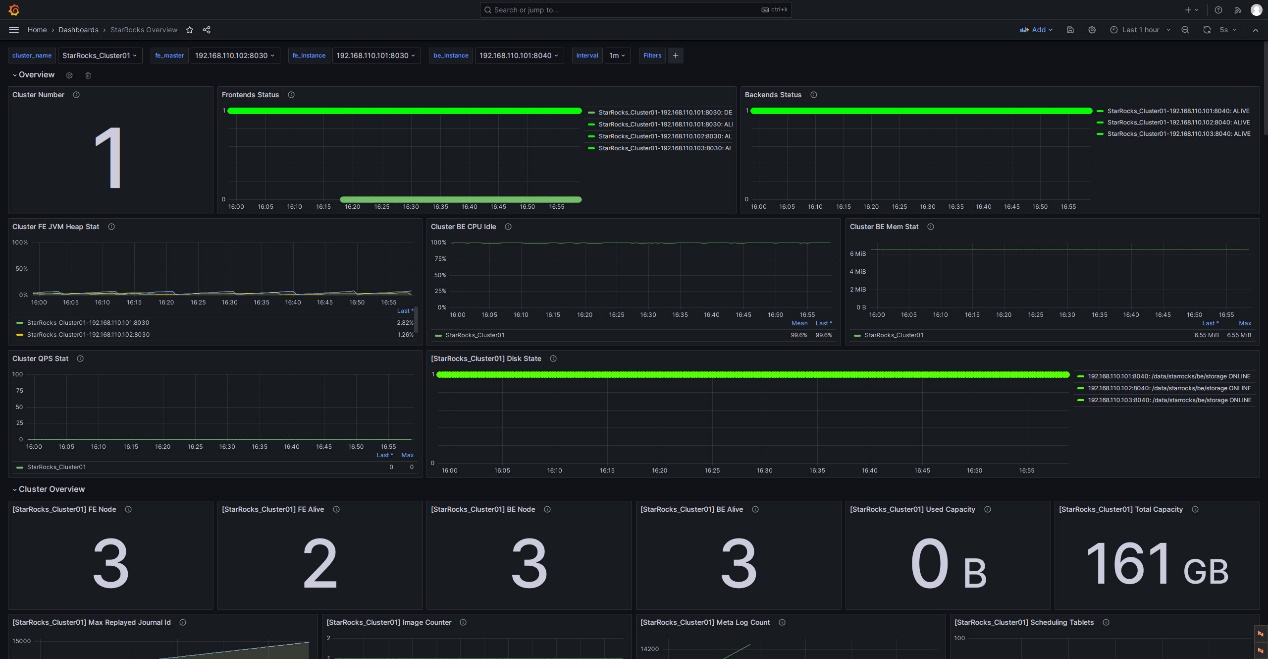
3.4.1 Правило алерта для статуса FE и BE
Для cluster Selena статус всех узлов FE и BE должен быть активным. Любой узел со статусом DEAD должен вызывать алерт.
Следующий пример использует метрики Frontends Status и Backends Status в Selena Overview для мониторинга статуса FE и BE. Поскольку вы можете настроить несколько cluster Selena в Prometheus, обратите внимание, что метрики Frontends Status и Backends Status предназначены для всех cluster, которые вы зарегистрировали.
Настройка правила алерта для FE
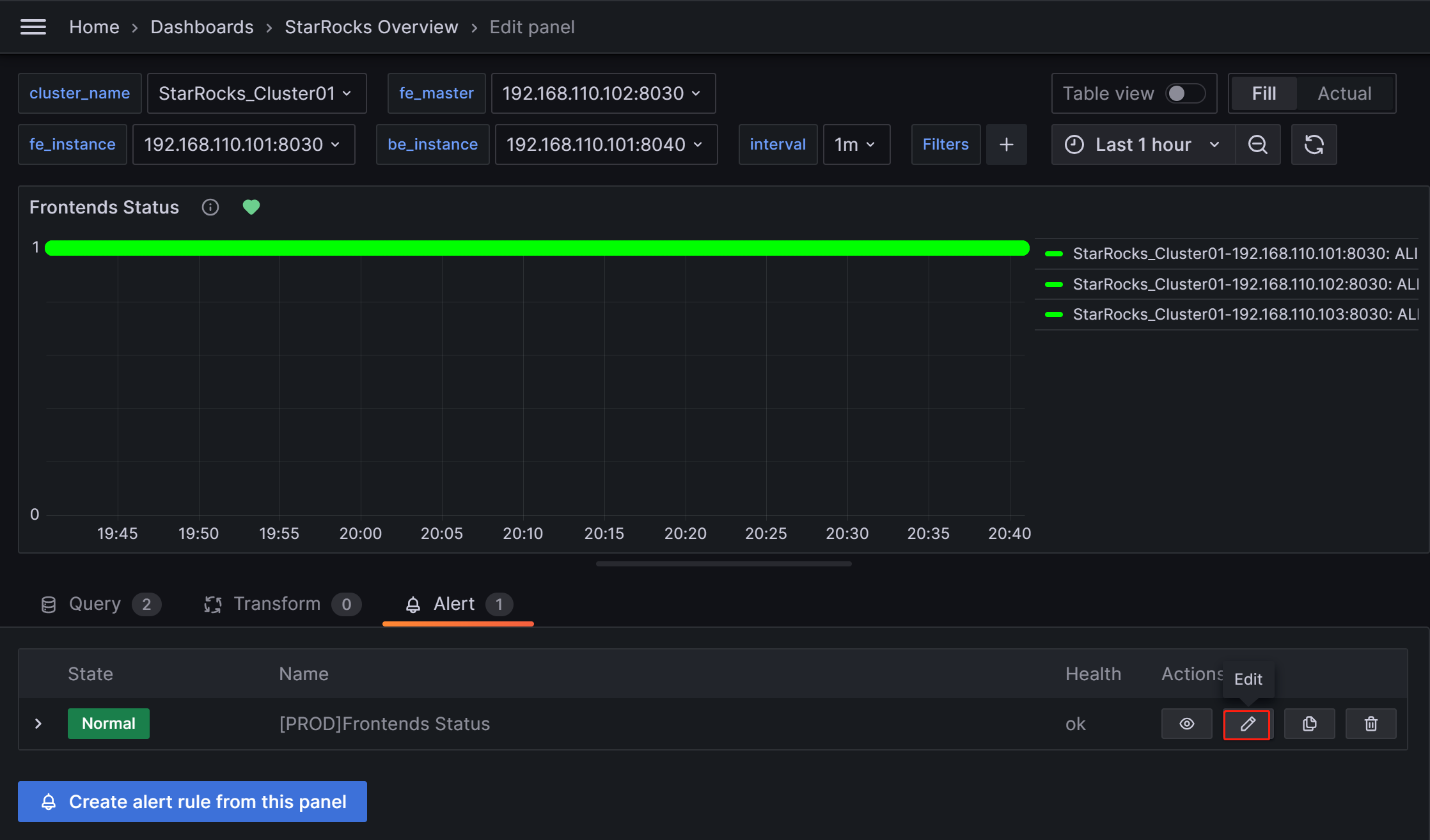
Выполните следующие процедуры для настройки алертов для Frontends Status:
-
Нажмите на значок More (...) справа от элемента мониторинга Frontends Status и нажмите Edit.
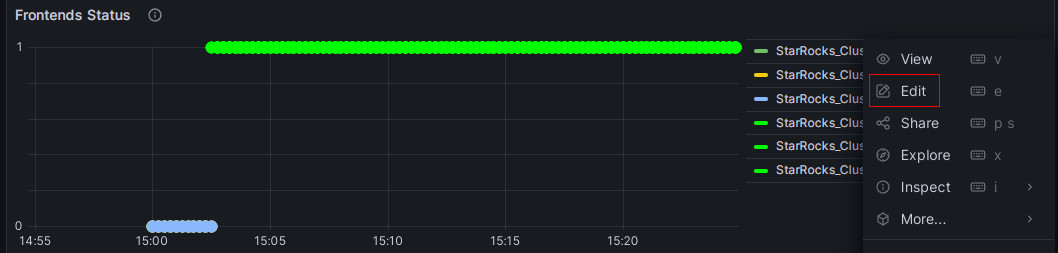
-
На новой странице выберите Alert, затем нажмите Create alert rule from this panel, чтобы войти на страницу создания правила.
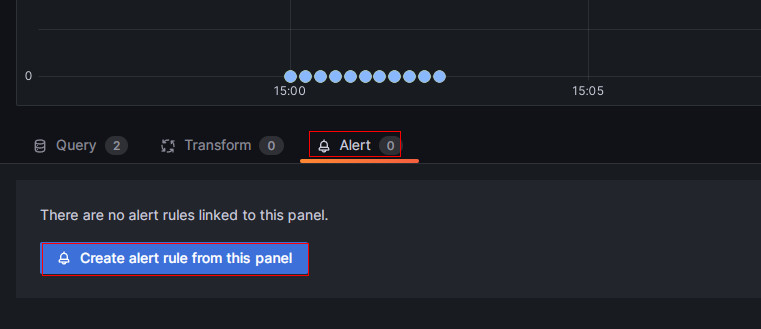
-
Установите имя правила в поле Rule name. Значение по умолчанию - заголовок метрики мониторинга. Если у вас несколько cluster, вы можете добавить имя cluster в качестве префикса для различения, например, "[PROD]Frontends Status".
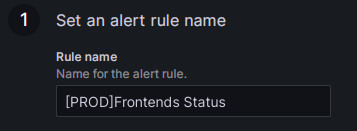
-
Настройте правило алерта следующим образом.
- Выберите Grafana managed alert.
- Для секции B измените правило как
(up{group="fe"}). - Нажмите на значок удаления справа от секции A, чтобы удалить секцию A.
- Для секции C измените поле Input на B.
- Для секции D измените условие на
IS BELOW 1.
После завершения этих настроек страница будет выглядеть, как показано ниже:
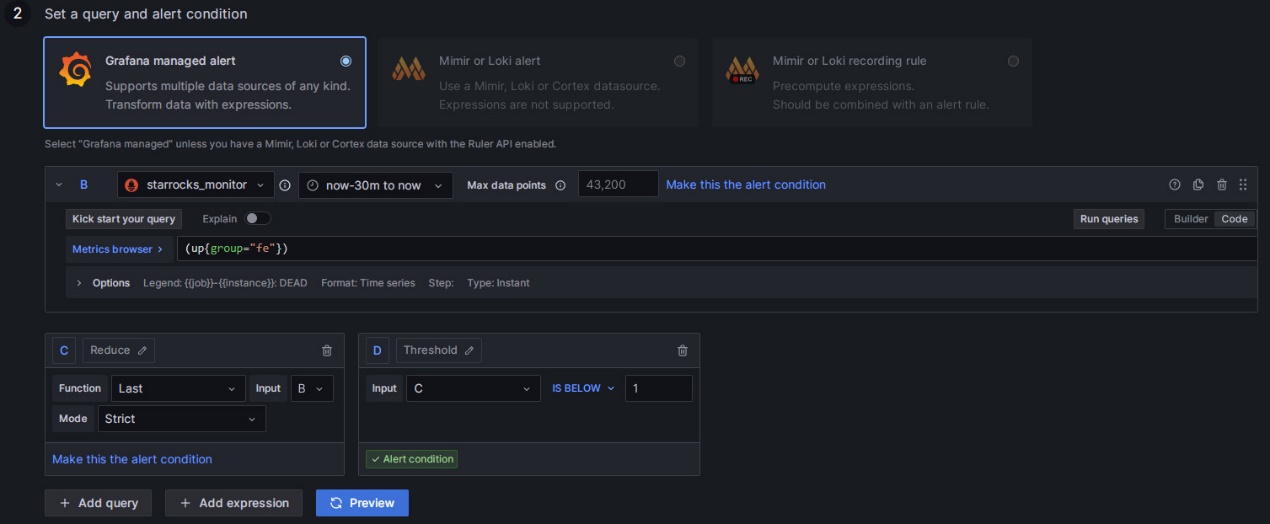
Нажмите, чтобы просмотреть подробные инструкции
Настройка правил алертов в Grafana обычно включает три шага:
- Получите значения метрик из Prometheus через PromQL-запросы. PromQL - это язык DSL для запросов данных, разработанный Prometheus, и он также используется в JSON-шаблонах Dashboards. Свойство
exprкаждого элемента мониторинга соответствует соответствующему PromQL. Вы можете нажать Run queries на странице настройки правил для просмотра результатов запроса. - Примените функции и режимы для обработки данных результата из вышеприведенных запросов. Обычно вам нужно использовать функцию Last для получения последнего значения и использовать режим Strict, чтобы гарантировать, что если возвращенное значение является нечисловыми данными, оно может отображаться как
NaN. - Установите правила для обработанных результатов запроса. Возьмем FE в качестве примера, если статус узла FE активен, выходной результат -
1. Если узел FE выключен, результат -0. Поэтому вы можете установить правило какIS BELOW 1, что означает, что алерт будет запущен, когда это условие произойдет.
-
Установите правила оценки алертов.
Согласно документации Grafana, вам нужно настроить частоту оценки правил алертов и частоту, с которой меняется их статус. Простыми словами, это включает настройку "как часто проверять с правилами алертов" и "как долго должно сохраняться аномальное состояние после обнаружения перед запуском алерта (чтобы избежать ложных алертов, вызванных временными всплесками)". Каждая группа Evaluation содержит независимый интервал оценки для определения частоты проверки правил алертов. Вы можете создать новую папку с именем PROD специально для production cluster Selena и создать новую группу Evaluation
01в ней. Затем настройте эту группу для проверки каждые10секунд и запустите алерт, если аномалия сохраняется в течение30секунд.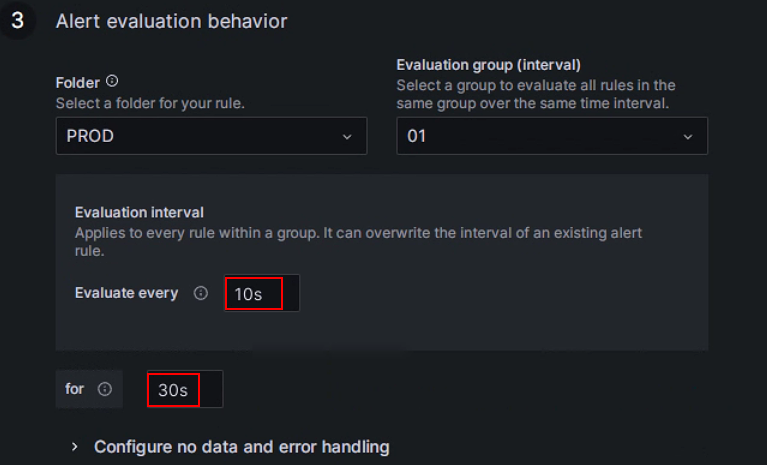
ПРИМЕЧАНИЕ
Упомянутая ранее опция "Disable resolved message" в разделе конфигурации канала алертов, которая контролирует время отправки email для восстановления сервиса cluster, также зависит от параметра "Evaluate every" выше. Другими словами, когда Grafana выполняет новую проверку и обнаруживает, что сервис восстановлен, он отправляет email для уведомления контактов.
-
Добавьте аннотации алертов.
В секции Add details for your alert rule нажмите Add annotation, чтобы настроить содержимое email алерта. Обратите внимание, не изменяйте поля Dashboard UID и Panel ID.
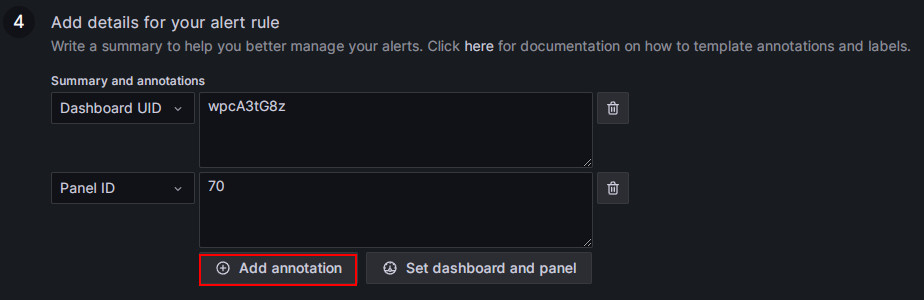
В выпадающем списке Choose выберите Description и добавьте описательное содержимое для email алерта, например, "FE node in your Selena production cluster failed, please check!"
-
Соответствие политикам уведомлений.
Укажите политику уведомлений для правила алерта. По умолчанию все правила алертов соответствуют политике по умолчанию. Когда условие алерта выполнено, Grafana будет использовать точку контакта "SelenaOp" в политике по умолчанию для отправки сообщений алертов в настроенную группу email.
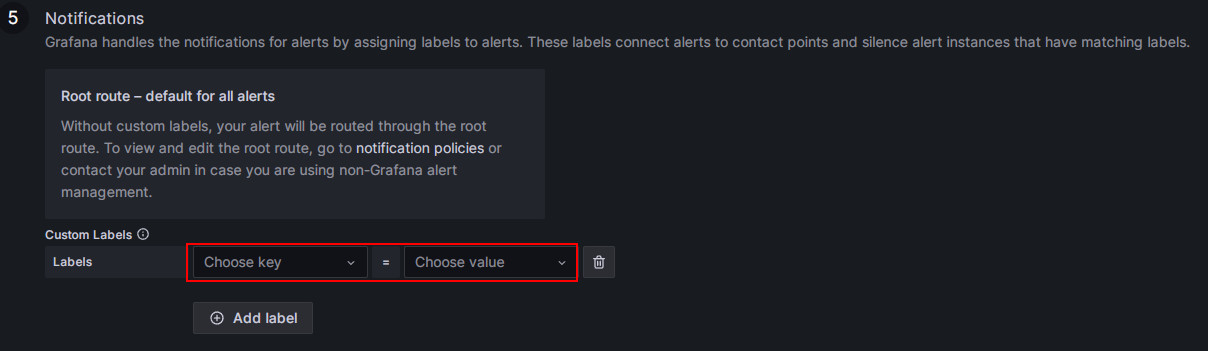
Если вы хотите использовать вложенную политику, установите поле Label на соответствующую вложенную политику, например,
Group=Development_team.Пример:

Когда условие алерта выполнено, email будут отправлены на "SelenaDev" вместо "SelenaOp" в политике по умолчанию.
-
После завершения всех конфигураций нажмите Save rule and exit.

Тестирование запуска алерта
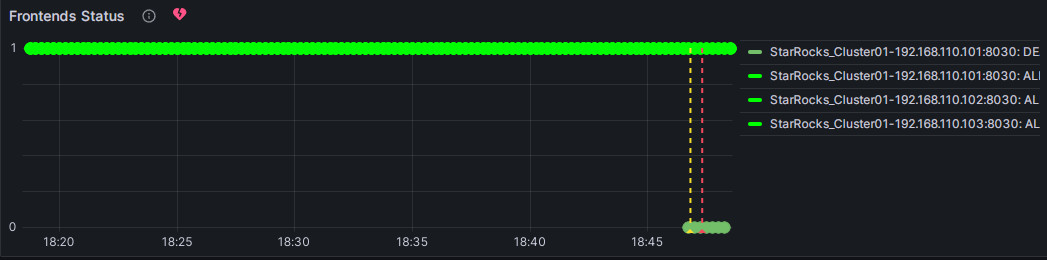
Вы можете вручную остановить узел FE для тестирования алерта. В этот момент символ в форме сердца справа от Frontends Status изменится с зеленого на желтый, а затем на красный.
Зеленый: Указывает, что во время последней периодической проверки статус каждого инстанса элемента метрики был нормальным, и алерт не был запущен. Зеленый статус не гарантирует, что текущий узел находится в нормальном статусе. Может быть задержка в изменении статуса после аномалии сервиса узла, но обычно задержка не в порядке минут.
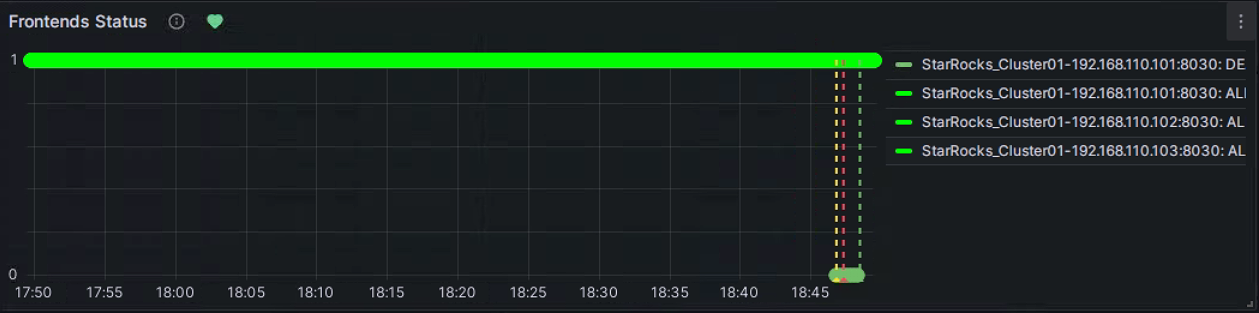
Желтый: Указывает, что во время последней периодической проверки инстанс элемента метрики был обнаружен аномальным, но продолжительность аномального состояния еще не достигла "Duration", настроенного выше. В эт�от момент Grafana не отправит алерт и продолжит периодические проверки до тех пор, пока продолжительность аномального состояния не достигнет настроенного "Duration". В течение этого периода, если статус восстановлен, символ изменится обратно на зеленый.
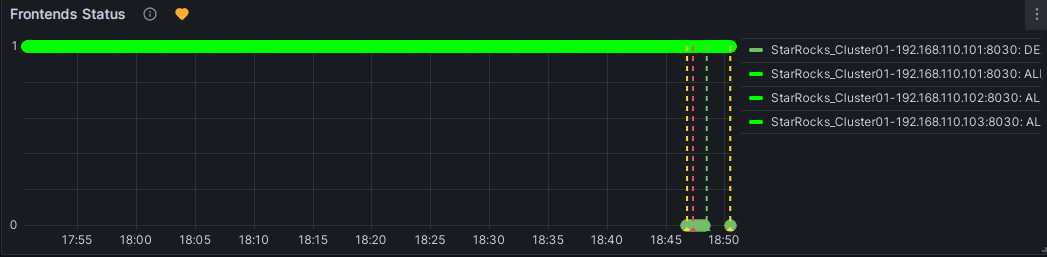
Красный: Когда продолжительность аномального состояния достигает настроенного "Duration", символ становится красным, и Grafana отправит email алерта. Символ останется красным до тех пор, пока аномальное состояние не будет решено, после чего он изменится обратно на зеленый.
Ручная приостановка алертов
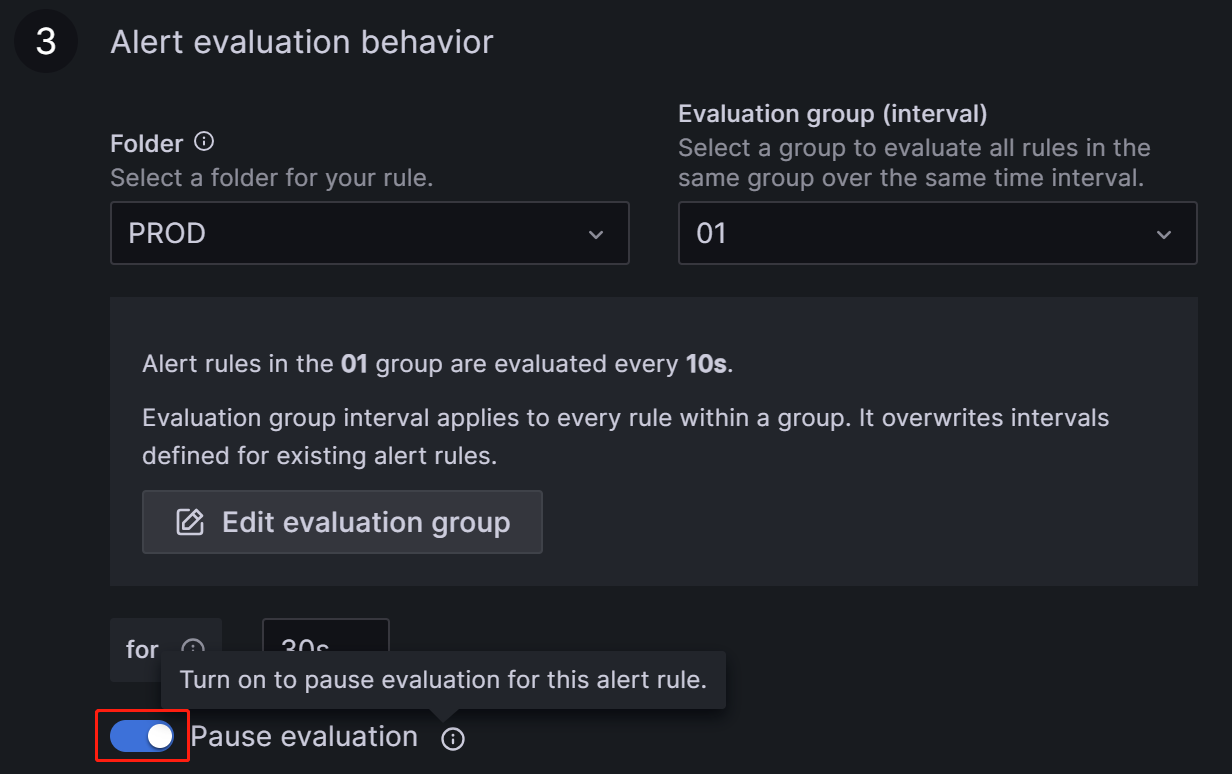
Предположим, что аномалия требует продолжительного периода для решения или алерты постоянно запускаются по причинам, отличным от аномалии. Вы �можете временно приостановить оценку правила алерта, чтобы предотвратить постоянную отправку email алертов Grafana.
Перейдите на вкладку Alert, соответствующую элементу метрики на Dashboard, и нажмите значок редактирования:
В секции Alert Evaluation Behavior переключите переключатель Pause Evaluation в положение ON.
ПРИМЕЧАНИЕ
После приостановки оценки вы получите email, уведомляющий вас о том, что сервис восстановлен.
Настройка правила алерта для BE
Вы можете следовать приведенному выше процессу для настройки правил алертов для BE.
Редактирование конфигурации для элемента метрики Backends Status:
- В секции Set an alert rule name настройте имя как "[PROD]Backends Status".
- В секции Set a query and alert condition установите PromSQL как
(up{group="be"})и используйте те же настройки, что и в правиле алерта FE для других элементов. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "BE node in your Selena production cluster failed, please check! Stack information for BE failure will be printed in the BE log file be.out. You can identify the cause based on the logs".
- В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
3.4.2 Правило алерта запросов
Элемент метрики для сбоев запросов - Query Error в Query Statistic.
Настройте правило алерта для элемента метрики "Query Error" следующим образом:
- В секции Set an alert rule name настройте имя как "[PROD] Query Error".
- В секции Set a query and alert condition удалите секцию B. Установите Input в секции A на C. В секции C используйте значение по умолчанию для PromQL, которое является
rate(selena_fe_query_err{job="Selena_Cluster01"}[1m]), представляя количество неудачных запросов в минуту, деленное на 60s. Это включает как неудачные запросы, так и запросы, которые превысили лимит timeout. Затем в секции D настройте правило какA IS ABOVE 0.05. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "High query failure rate, please check the resource usage or configure query timeout reasonably. If queries are failing due to timeouts, you can adjust the query timeout by setting the system variable
query_timeout". - В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать полити�ку по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
3.4.3 Правило алерта сбоя пользовательской операции
Этот элемент мониторит частоту сбоев операции Schema Change, соответствующий элементу метрики Schema Change в BE tasks. Он должен быть настроен для алерта, когда больше 0.
- В секции Set an alert rule name настройте имя как "[PROD] Schema Change".
- В секции Set a query and alert condition удалите секцию A. Установите Input в секции C на B. В секции B используйте значение по умолчанию для PromQL, которое является
irate(selena_be_engine_requests_total{job="Selena_Cluster01", type="create_rollup", status="failed"}[1m]), представляя количество неудачных задач Schema Change в минуту, деленное на 60s. Затем в секции D настройте правило какC IS ABOVE 0. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "Failed Schema Change tasks detected, please check promptly. You can increase the memory limit available for Schema Change by adjusting the BE configuration parameter
memory_limitation_per_thread_for_schema_change, which is set to 2GB by default". - В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
3.4.4 Правило алерта сбоя операции Selena
BE Compaction Score
Этот элемент соответствует BE Compaction Score в Cluster Overview и используется для мониторинга давления compaction на cluster.
- В секции Set an alert rule name настройте имя как "[PROD] BE Compaction Score".
- В секции Set a query and alert condition настройте правило в секции C как
B IS ABOVE 0. Вы можете использовать значения по умолчанию для других элементов. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "High compaction pressure. Please check whether there are high-frequency or high concurrency loading tasks and reduce the loading frequency. If the cluster has sufficient CPU, memory, and I/O resources, consider adjusting the cluster compaction strategy".
- В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
Clone
Этот элемент соответствует Clone в BE tasks и в осн�овном используется для мониторинга балансировки replica или операций восстановления replica внутри Selena, которые обычно не должны завершаться сбоем.
- В секции Set an alert rule name настройте имя как "[PROD] Clone".
- В секции Set a query and alert condition удалите секцию A. Установите Input в секции C на B. В секции B используйте значение по умолчанию для PromQL, которое является
irate(selena_be_engine_requests_total{job="Selena_Cluster01", type="clone", status="failed"}[1m]), представляя количество неудачных задач Clone в минуту, деленное на 60s. Затем в секции D настройте правило какC IS ABOVE 0. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "Detected a failure in the clone task. Please check the cluster BE status, disk status, and network status".
- В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправля�ть email алертов на канал алертов "SelenaOp".
3.4.5 Правило алерта доступности сервиса
Этот элемент мониторит количество логов метаданных в BDB, соответствующий элементу мониторинга Meta Log Count в Cluster Overview.
- В секции Set an alert rule name настройте имя как "[PROD] Meta Log Count".
- В секции Set a query and alert condition настройте правило в секции C как
B IS ABOVE 100000. Вы можете использовать значения по умолчанию для других элементов. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "Detected that the metadata count in FE BDB is significantly higher than the expected value, which can indicate a failed Checkpoint operation. Please check whether the Xmx heap memory configuration in the FE configuration file fe.conf is reasonable".
- В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
3.4.6 Правило алерта перегрузки системы
BE CPU Idle
Этот элемент мониторит процент простоя CPU на узлах BE.
- В секции Set an alert rule name настройте имя как "[PROD] BE CPU Idle".
- В секции Set a query and alert condition настройте правило в секции C как
B IS BELOW 10. Вы можете использовать значения по умолчанию для других элементов. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "Detected that BE CPU load is consistently high. It will impact other tasks in the cluster. Please check whether the cluster is abnormal or if there is a CPU resource bottleneck".
- В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
BE Memory
Этот элемент соответствует BE Mem в BE, мониторящий использование памяти на узлах BE.
- В секции Set an alert rule name настройте имя как "[PROD] BE Mem".
- В секции Set a query and alert condition настройте PromSQL как
selena_be_process_mem_bytes{job="Selena_Cluster01"}/(<be_mem_limit>*1024*1024*1024), где<be_mem_limit>необходимо заменить текущим лимитом доступной памяти узла BE, то есть размером памяти сервера, умноженным на значение элемента конфигурации BEmem_limit. Пример:selena_be_process_mem_bytes{job="Selena_Cluster01"}/(49*1024*1024*1024). Затем в секции C настройте правило какB IS ABOVE 0.9. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "Detected that BE memory usage is consistently high. To prevent query failure, please consider expanding memory size or adding BE nodes".
- В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
Disks Avail Capacity
Этот элемент соответствует Disk Usage в BE, мониторящий соотношение оставшегося пространства в каталоге, где находится путь хранения BE.
- В секции Set an alert rule name настройте имя как "[PROD] Disks Avail Capacity".
- В секции Set a query and alert condition настройте правило в секции C как
B`` IS BELOW 0.2. Вы можете использовать значения по умолчанию для других элементов. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "Detected that BE disk available space is below 20%, please release disk space or expand the disk".
- В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
FE JVM Heap Stat
Этот элемент соответствует Cluster FE JVM Heap Stat в Overview, мониторящий пропорцию использования памяти JVM FE к лимиту heap-памяти FE.
- В секции Set an alert rule name настройте имя как "[PROD] FE JVM Heap Stat".
- В секции Set a query and alert condition настройте правило в секции C как
B IS ABOVE 80. Вы можете использовать значения по умолчанию для других эле�ментов. - В секции Alert evaluation behavior выберите каталог PROD и группу Evaluation 01, созданные ранее, и установите duration равной 30 секундам.
- В секции Add details for your alert rule нажмите Add annotation, выберите Description и введите содержимое алерта, например, "Detected that FE heap memory usage is high, please adjust the heap memory limit in the FE configuration file fe.conf".
- В секции Notifications настройте Labels так же, как правило алерта FE. Если Labels не настроены, Grafana будет использовать политику по умолчанию и отправлять email алертов на канал алертов "SelenaOp".
Приложение
Включение обнаружения сервисов для Prometheus
Вы можете включить обнаружение сервисов для Prometheus, чтобы он мог автоматически обнаруживать сервисы (узлы) после масштабирования cluster.
Следующий раздел использует AWS в качестве примера.
-
Предоставьте инстансу EC2, который размещает ваш сервис Prometheus, следующие разрешения, используя IAM Policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances",
"ec2:DescribeTags"
],
"Resource": "*"
}
]
}Для подробных инструкций по аутентификации к ресурсам AWS см. Authenticate to AWS resources.
С этими разрешениями Prometheus может перечислять инстансы и их tags в регионе.
-
Добавьте секции
ec2_sd_configsиrelabel_configsв prometheus/prometheus.yml.Пример:
global:
scrape_interval: 15s # Установите глобальный интервал scrape равным 15s. По умолчанию 1 мин.
evaluation_interval: 15s # Установите глобальный интервал evaluation правил равным 15s. По умолчанию 1 мин.
scrape_configs:
- job_name: 'Selena_Cluster01'
metrics_path: '/metrics'
ec2_sd_configs:
- region: us-west-2
port: 8030
filters:
- name: tag:ClusterName
values: ['test-stage-20251021']
- name: tag:ProcessType
values: ['FE']
- region: us-west-2
port: 8040
filters:
- name: tag:ClusterName
values: ['test-stage-20251021']
- name: tag:ProcessType
values: ['BE']
relabel_configs:
- source_labels: [__meta_ec2_tag_ClusterName]
regex: test-stage-20251021
target_label: cluster
replacement: test-stage-20251021
- source_labels: [__meta_ec2_tag_ProcessType]
regex: FE
target_label: group
replacement: fe
- source_labels: [__meta_ec2_tag_ProcessType]
regex: BE
target_label: group
replacement: be
Q&A
Q: Почему Dashboard не может обнаружить аномалии?
A: Grafana Dashboard полагается на системное время сервера, на котором он размещен, для получения значений для элементов мониторинга. Если страница Grafana Dashboard остается неизменной после аномалии cluster, вы можете проверить, синхронизированы ли системные часы серверов, а затем выполнить калибровку времени cluster.
Q: Как я могу реализовать градацию алертов?
A: Возьмем элемент Query Error в качестве примера, вы можете создать два правила алертов для него с разными порогами алертов. Например:
- Уровень риска: Установите частоту сбоев больше 0.05, указывающую на риск. Отправьте алерт команде разработки.
- Уровень серьезности: Установите частоту сбоев больше 0.20, указывающую на серьезность. В этот момент уведомление об алерте будет отправлено как команде разработки, так и команде operations одновременно.
Q: Как я могу получить более подробные метрики, включая метрики на уровне таблицы, метрики materialized view и статистику соединений с labels пользователей?
A: По умолчанию endpoint /metrics собирает метрики в минимизированном режиме для минимизации влияния на производительность. Чтобы получить подробные метрики, вам необходимо добавить определенные параметры к запросу и предоставить учетные данные Basic Authentication для пользователя с привилегиями ADMIN.
Поддерживаемые параметры:
with_table_metrics=all: Собирает все метрики на уровне таблицы.with_materialized_view_metrics=all: Собирает все метрики materialized view.with_user_connections=all: Собирает статистику соединений, категоризированную по labels пользователей.
Требование аутентификации:
Эти параметры вступают в силу только тогда, когда запрос вкл�ючает действительные учетные данные Basic Authentication для пользователя ADMIN. Если запрос анонимный или у пользователя отсутствуют привилегии ADMIN, эти параметры игнорируются, и возвращаются только метрики по умолчанию.
Пример команды Curl:
curl -u <admin_username>:<admin_password> \
"http://<fe_host>:<fe_http_port>/metrics?with_table_metrics=all&with_materialized_view_metrics=all&with_user_connections=all"
Пример конфигурации Prometheus:
Чтобы включить сбор подробных метрик в Prometheus, настройте params и basic_auth в вашем prometheus.yml:
scrape_configs:
- job_name: 'Selena_Detailed_Metrics'
metrics_path: '/metrics'
params:
with_table_metrics: ['all']
with_materialized_view_metrics: ['all']
with_user_connections: ['all']
basic_auth:
username: '<admin_username>'
password: '<admin_password>'
static_configs:
- targets: ['<fe_host>:<fe_http_port>']
Сбор всех метрик таблиц и materialized view может увеличить нагрузку на узел FE. Используйте эти параметры с осторожностью в крупномасштабных окружениях.