Управление алертами
В этом разделе представлены различные элементы алертов с разных измерений, включая непрерывность бизнеса, доступность cluster и нагрузку машины, и предоставляются соответствующие решения.
В следующих примерах все переменные имеют префикс $. Они должны быть заменены в соответствии с вашей бизнес-средой. Например, $job_name должен быть заменен соответствующим именем Job в конфигурации Prometheus, а $fe_leader должен быть заменен IP-адресом Leader FE.
Алерты приостановки сервиса
Приостановка сервиса FE
PromSQL
count(up{group="fe", job="$job_name"}) >= 3
Описание алерта
Алерт запускается, когда количество активных узлов FE падает ниже указанного значения. Вы можете настроить это значение на основе фактического количества узлов FE.
Решение
Попытайтесь перезапустить приостановленный узел FE.
Приостановка сервиса BE
PromSQL
node_info{type="be_node_num", job="$job_name",state="dead"} > 1
Описание алерта
Алерт запускается, когда более одного узла BE приостановлено.
Решение
Попытайтесь перезапустить приостановленный узел BE.
Алерты нагрузки машины
Алерт CPU BE
PromSQL
(1-(sum(rate(selena_be_cpu{mode="idle", job="$job_name",instance=~".*"}[5m])) by (job, instance)) / (sum(rate(selena_be_cpu{job="$job_name",host=~".*"}[5m])) by (job, instance))) * 100 > 90
Описание алерта
Алерт запускается, когда использование CPU BE превышает 90%.
Решение
Проверьте, есть ли большие запросы или крупномасштабная загрузка данных, и передайте детали команде поддержки для дальнейшего исследования.
-
Используйте команду
topдля проверки использования ресурсов процессами.top -Hp $be_pid -
Используйте команду
perfдля сбора и анализа данных производительности.# Выполните команду в течение 1-2 минут и завершите ее, нажав CTRL+C.
sudo perf top -p $be_pid -g >/tmp/perf.txt
В чрезвычайных ситуациях для быстрого восстановления сервиса вы можете попытаться перезапустить соответствующий узел BE после сохранения стека. Чрезвычайная ситуация здесь относится к ситуации, когда использование CPU узла BE остается аномально высоким, и нет эффективных средств для снижения использования CPU.
Алерт памяти
PromSQL
(1-node_memory_MemAvailable_bytes{instance=~".*"}/node_memory_MemTotal_bytes{instance=~".*"})*100 > 90
Описание алерта
Алерт запускается, когда использование памяти превышает 90%.
Решение
Обратитесь к Get Heap Profile для устранения неполадок.
- В чрезвычайных ситуациях вы можете попытаться перезапустить соответствующий сервис BE для восстановления сервиса. Чрезвычайная ситуация здесь относится к ситуации, когда использование памяти узла BE остается аномально высоким, и нет эффективных средств для снижения использования памяти.
- Если другие смешанно развернутые сервисы влияют на систему, вы можете рассмотреть возможность завершения этих сервисов в чрезвычайных ситуациях.
Алерты диска
Алерт нагрузки диска
PromSQL
rate(node_disk_io_time_seconds_total{instance=~".*"}[1m]) * 100 > 90
Описание алерта
Алерт запускается, когда нагрузка диска превышает 90%.
Решение
Если cluster запускает алерт node_disk_io_time_seconds_total, сначала проверьте, есть ли какие-либо изменения в бизнесе. Если да, рассмотрите возможность отката изменений для поддержания предыдущего баланса ресурсов. Если изменения не идентифицированы или откат невозможен, рассмотрите, приводит ли нормальный рост бизнеса к необходимости расширения ресурсов. Вы можете использовать инструмент iotop для анализа использования I/O диска. iotop имеет UI, похожий на top, и включает информацию, такую как pid, user и I/O.
Вы также можете использовать следующий SQL-запрос для идентификации tablets, потребляющих значительное I/O, и отследить их до конкретных задач и таблиц.
-- "all" указывает на все сервисы. 10 указывает, что сбор длится 10 секунд. 3 указывает на получение топ-3 результатов.
ADMIN EXECUTE ON $backend_id 'System.print(ExecEnv.io_profile_and_get_topn_stats("all", 10, 3))';
Алерт емкости корневого пути
PromSQL
node_filesystem_free_bytes{mountpoint="/"} /1024/1024/1024 < 5
Описание алерта
Алерт запускается, когда доступное пространство в корневом каталоге меньше 5 ГБ.
Решение
Общие каталоги, которые могут занимать значительное пространство, включают /var, **/**opt и /tmp. Используйте следующую команду для проверки больших файлов и очистки ненужных файлов.
du -sh / --max-depth=1
Алерт емкости диска данных
PromSQL
(SUM(selena_be_disks_total_capacity{job="$job"}) by (host, path) - SUM(selena_be_disks_avail_capacity{job="$job"}) by (host, path)) / SUM(selena_be_disks_total_capacity{job="$job"}) by (host, path) * 100 > 90
Описание алерта
Алерт запускается, когда использование емкости диска превышает 90%.
Решение
-
Проверьте, были ли изменения в объеме загруженных данных.
Мониторьте метрику
load_bytesв Grafana. Если произошло значительное увеличение объема загрузки данных, вам может потребоваться масштабировать ресурсы системы. -
Проверьте наличие операций DROP.
Если объем загрузки данных не сильно изменился, выполните
SHOW BACKENDS. Если отчетное использование диска не соответствует фактическому использованию, проверьте FE Audit Log на наличие недавних операций DROP DATABASE, TABLE или PARTITION.Метаданные для этих операций остаются в памяти FE в течение одного дня, позволяя вам восстановить данные с помощью инструкции RECOVER в течение 24 часов для избежания ошибочных операций. После восстановления фактическое использование диска может превышать то, что показано в
SHOW BACKENDS.Период хранения удаленных данных в памяти можно настроить с помощью динамического параметра FE
catalog_trash_expire_second(значение по умолчанию: 86400).ADMIN SET FRONTEND CONFIG ("catalog_trash_expire_second"="86400");Чтобы сохранить это изменение, добавьте элемент конфигурации в конфигурационный файл FE fe.conf.
После этого удаленные данные будут перемещены в каталог trash на узлах BE (
$storage_root_path/trash). По умолчанию удаленные данные хранятся в каталоге trash в течение одного дня, что также может привести к тому, что фактическое использование диска превысит то, что показано вSHOW BACKENDS.Время хранения удаленных данных в каталоге trash можно настроить с помощью динамического параметра BE
trash_file_expire_time_sec(значение по умолчан�ию: 86400).curl http://$be_ip:$be_http_port/api/update_config?trash_file_expire_time_sec=86400
Алерт емкости диска метаданных FE
PromSQL
node_filesystem_free_bytes{mountpoint="${meta_path}"} /1024/1024/1024 < 10
Описание алерта
Алерт запускается, когда доступное дисковое пространство для метаданных FE меньше 10 ГБ.
Решение
Используйте следующие команды для проверки каталогов, занимающих большие объемы пространства, и очистите ненужные файлы. Путь метаданных указывается конфигурацией meta_dir в fe.conf.
du -sh /${meta_dir} --max-depth=1
Если каталог метаданных занимает много пространства, это обычно потому, что каталог bdb большой, возможно, из-за сбоя CheckPoint. Обратитесь к Алерт сбоя CheckPoint для устранения неполадок. Если этот метод не решит проблему, обратитесь в команду технической поддержки.
Алерты исключений сервиса cluster
Алерты сбоя Compaction
Алерт сбоя Cumulative Compaction
PromSQL
increase(selena_be_engine_requests_total{job="$job_name" ,status="failed",type="cumulative_compaction"}[1m]) > 3
increase(selena_be_engine_requests_total{job="$job_name" ,status="failed",type="base_compaction"}[1m]) > 3
Описание алерта
Алерт запускается, когда происходят три сбоя в Cumulative Compaction или Base Compaction в течение последней минуты.
Решение
Найдите лог соответствующего узла BE для следующих ключевых слов для идентификации вовлеченного tablet.
grep -E 'compaction' be.INFO | grep failed
Запись лога, подобная следующей, указывает на сбой Compaction.
W0924 17:52:56:537041 123639 comaction_task_cpp:193] compaction task:8482. tablet:8423674 failed.
Вы можете проверить контекст лога для анализа сбоя. Обычно сбой мог быть вызван операцией DROP TABLE или PARTITION во время процесса Compaction. Система имеет внутренний механизм повтора для Compaction, и вы также можете вручную установить статус tablet как BAD и запустить задачу Clone для его восстановления.
Перед выполнением следующей операции убедитесь, что таблица имеет по крайней мере три полные replicas.
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "$tablet_id", "backend_id" = "$backend_id", "status" = "bad");
Алерт высокого давления Compaction
PromSQL
selena_fe_max_tablet_compaction_score{job="$job_name",instance="$fe_leader"} > 100
Описание алерта
Алерт запускается, когда наивысший Compaction Score превышает 100, указывая на высокое давление Compaction.
Решение
Этот алерт обычно вызван частой загрузкой, INSERT INTO VALUES или операциями DELETE (со скоростью 1 в секунду). Рекомендуется установить интервал между задачами загрузки или DELETE более 5 секунд и избегать отправки задач DELETE с высокой concurrency.
Алерт превышения количества версий
PromSQL
selena_be_max_tablet_rowset_num{job="$job_name"} > 700
Описание алерта
Алерт запускается, когда tablet на узле BE имеет более 700 версий данных.
Решение
Используйте следующую команду для проверки tablet с превышенными версиями:
SELECT BE_ID,TABLET_ID FROM information_schema.be_tablets WHERE NUM_ROWSET>700;
Пример для Tablet с ID 2889156:
SHOW TABLET 2889156;
Выполните команду, возвращенную в поле DetailCmd:
SHOW PROC '/dbs/2601148/2889154/partitions/2889153/2889155/2889156';
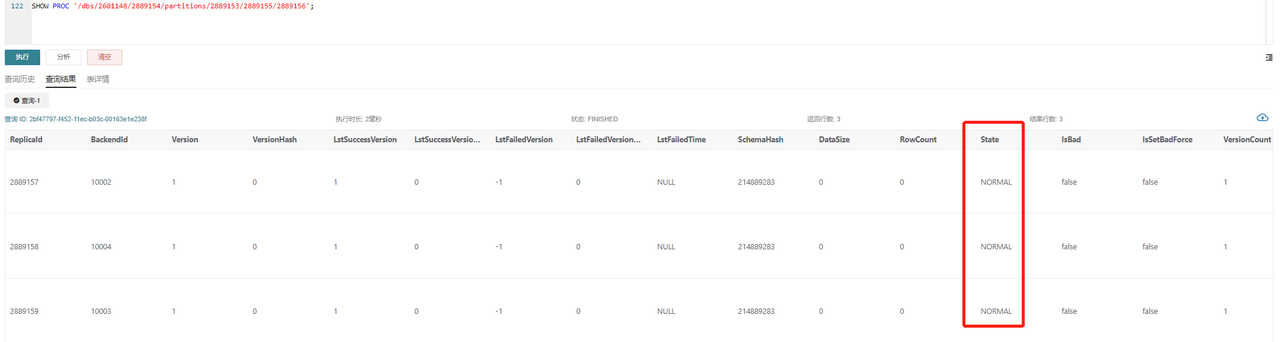
В нормальных обстоятельствах, как показано, все три replicas должны быть в статусе NORMAL, и другие метрики, такие как RowCount и DataSize, должны оставаться согласованными. Если только одна replica превышает лимит версий 700, вы можете запустить задачу Clone на основе других replicas с помощью следующей команды:
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "$tablet_id", "backend_id" = "$backend_id", "status" = "bad");
Если две или более replicas превышают лимит версий, вы можете временно увеличить лимит количества версий:
# Замените be_ip на IP узла BE, который хранит tablet, превышающий лимит версий.
# По умолчанию be_http_port равен 8040.
# Значение по умолчанию tablet_max_versions равно 1000.
curl -XPOST http://$be_ip:$be_http_port/api/update_config?tablet_max_versions=2000
Алерт сбоя CheckPoint
PromSQL
selena_fe_meta_log_count{job="$job_name",instance="$fe_master"} > 100000
Описание алерта
Алерт запускается, когда количество логов BDB узла FE превышает 100 000. По умолчанию система выполняет CheckPoint, когда количество логов BDB превышает 50 000, а затем сбрасывает счетчик на 0.
Решение
Этот алерт указывает, что CheckPoint не был выполнен. Вам нужно исследовать логи FE для анализа процесса CheckPoint и решения проблемы:
В fe.log узла Leader FE найдите записи, такие как begin to generate new image: image.xxxx. Если найдено, это означает, что система начала генерировать новый образ. Продолжайте проверять логи на наличие записей, таких как checkpoint finished save image.xxxx, чтобы подтвердить успешное создание образа. Если вы найдете Exception when generate new image file, генерация образа не удалась. Вам следует тщательно обработать метаданные на основе конкретной ошибки. Рекомендуется обратиться в команду поддержки для дальнейшего анализа.
Алерт превышения количества потоков FE
PromSQL
selena_fe_thread_pool{job="$job_name", type!="completed_task_count"} > 3000
Описание алерта
Алерт запускается, когда количество потоков на FE превышает 3000.
Решение
Лимит количества потоков по умолчанию для узлов FE и BE составляет 4096. Большое количество запросов UNION ALL обычно приводит к превышению количества потоков. Рекомендуется уменьшить concurrency запросов UNION ALL и настроить системную переменную pipeline_dop. Если невозможно настроить гранулярность SQL-запросов, вы можете глобально настроить pipeline_dop:
SET GLOBAL pipeline_dop=8;
В чрезвычайных ситуациях для быстрого восстановления сервисов вы можете увеличить динамический параметр FE thrift_server_max_worker_threads (значение по умолчанию: 4096).
ADMIN SET FRONTEND CONFIG ("thrift_server_max_worker_threads"="8192");
Алерт высокого использования FE JVM
PromSQL
sum(jvm_heap_size_bytes{job="$job_name", type="used"}) * 100 / sum(jvm_heap_size_bytes{job="$job_name", type="max"}) > 90
Описание алерта
Алерт запускается, когда использование JVM на узле FE превышает 90%.
Решение
Этот алерт указывает, что использование JVM слишком высокое. Вы можете использовать команду jmap для анализа ситуации. Поскольку детальная информация мониторинга для этой метрики все еще находится в разработке, прямые инсайты ограничены. Выполните следующие действия и отправьте результаты команде поддержки для анализа:
# Обратите внимание, что указание `live` в команде может привести к перезапуску FE.
jmap -histo[:live] $fe_pid > jmap.dump
В чрезвычайных ситуациях для быстрого восстановления сервисов вы можете перезапустить соответствующий узел FE или увеличить размер JVM (Xmx), а затем перезапустить сервис FE.
Алерты доступности сервиса
Алерты исключений загрузки
Алерт сбоя загрузки
PromSQL
rate(selena_fe_txn_failed{job="$job_name",instance="$fe_master"}[5m]) * 100 > 5
Описание алерта
Алерт запускается, когда количество неудачных транзакций загрузки превышает 5% от общего числа.
Решение
Проверьте логи узла Leader FE, чтобы найти информацию об ошибках загрузки. Найдите ключевое слово status: ABORTED для идентификации неудачных задач загрузки.
2024-04-09 18:34:02.363+08:00 INFO (thrift-server-pool-8845163|12111749) [DatabaseTransactionMgr.abortTransaction():1279] transaction:[TransactionState. txn_id: 7398864, label: 967009-2f20a55e-368d-48cf-833a-762cf1fe07c5, db id: 10139, table id list: 155532, callback id: 967009, coordinator: FE: 192.168.2.1, transaction status: ABORTED, error replicas num: 0, replica ids: , prepare time: 1712658795053, commit time: -1, finish time: 1712658842360, total cost: 47307ms, reason: [E1008]Reached timeout=30000ms @192.168.1.1:8060 attachment: RLTaskTxnCommitAttachment [filteredRows=0, loadedRows=0, unselectedRows=0, receivedBytes=1033110486, taskExecutionTimeMs=0, taskId=TUniqueId(hi:3395895943098091727, lo:-8990743770681178171), jobId=967009, progress=KafkaProgress [partitionIdToOffset=2_1211970882|7_1211893755]]] successfully rollback
Алерт задержки потребления Routine Load
PromSQL
(sum by (job_name)(selena_fe_routine_load_max_lag_of_partition{job="$job_name",instance="$fe_mater"})) > 300000
selena_fe_routine_load_jobs{job="$job_name",host="$fe_mater",state="NEED_SCHEDULE"} > 3
selena_fe_routine_load_jobs{job="$job_name",host="$fe_mater",state="PAUSED"} > 0
selena_fe_routine_load_jobs{job="$job_name",host="$fe_mater",state="UNSTABLE"} > 0
Описание алерта
- Алерт запускается, когда более 300 000 записей задержаны в потреблении.
- Алерт запускается, когда количество ожидающих задач Routine Load превышает 3.
- Алерт запускается, когда есть задачи в статусе
PAUSED. - Алерт запускается, когда есть задачи в статусе
UNSTABLE.
Решение
-
Сначала проверьте, является ли статус задачи Routine Load
RUNNING.SHOW ROUTINE LOAD FROM $db;Обратите внимание на поле
Stateв возвращенных данных. -
Если какая-либо задача Routine Load находится в статусе
PAUSED, изучите поляReasonOfStateChanged,ErrorLogUrlsиTrackingSQL. Обычно выполнение SQL-запроса вTrackingSQLможет выявить конкретную ошибку.Пример:

-
Если статус задачи Routine Load
RUNNING, вы можете попытаться увеличить concurrency задачи. Concurrency отдельных задач Routine Load определяется минимальным значением из следующих четырех параметров:kafka_partition_num: Количество partitions в Kafka Topic.desired_concurrent_number: Установленная concurrency для задачи.alive_be_num: Количество активных узлов BE.max_routine_load_task_concurrent_num: Параметр конфигурации FE, со знач�ением по умолчанию 5.
В большинстве случаев вам может потребоваться настроить concurrency задачи или количество partitions Kafka Topic (обратитесь в поддержку Kafka при необходимости).
Следующий пример показывает, как установить concurrency для задачи.
ALTER ROUTINE LOAD FOR ${routine_load_jobname}
PROPERTIES
(
"desired_concurrent_number" = "5"
);
Алерт лимита транзакций загрузки для одной базы данных
PromSQL
sum(selena_fe_txn_running{job="$job_name"}) by(db) > 900
Описание алерта
Алерт запускается, когда количество транзакций загрузки для одной базы данных превышает 900 (100 в версиях до v1.5.2).
Решение
Этот алерт обычно запускается большим количеством вновь добавленных задач загрузки. Вы можете временно увеличить лимит на транзакции загрузки для одной базы данных.
ADMIN SET FRONTEND CONFIG ("max_running_txn_num_per_db" = "2000");
Алерты исключений запросов
Алерт задержки запроса
PromSQL
selena_fe_query_latency_ms{job="$job_name", quantile="0.95"} > 5000
Описание алерта
Алерт запускается, когда задержка P95 запроса превышает 5 секунд.
Решение
-
Исследуйте, есть ли какие-либо большие запросы.
Проверьте, потребили ли большие запросы значительные ресурсы машины во время исключения, что привело к тайм-ауту или сбою других запросов.
-
Выполните
show proc '/current_queries';для просмотраQueryIdбольших запросов. Если вам нужно быстро восстановить сервис, вы можете использовать командуKILLдля завершения долго выполняющихся запросов.mysql> SHOW PROC '/current_queries';
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
| QueryId | ConnectionId | Database | User | ScanBytes | ProcessRows | CPUCostSeconds | MemoryUsageBytes | ExecTime |
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
| 7c56495f-ae8b-11ed-8ebf-00163e00accc | 4 | tpcds_100g | root | 37.88 MB | 1075769 Rows | 11.13 Seconds | 146.70 MB | 3804 |
| 7d543160-ae8b-11ed-8ebf-00163e00accc | 6 | tpcds_100g | root | 13.02 GB | 487873176 Rows | 81.23 Seconds | 6.37 GB | 2090 |
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
2 rows in set (0.01 sec) -
Вы также можете перезапустить узлы BE с высоким использованием CPU для решения проблемы.
-
-
Проверьте, достаточны ли ресурсы машины.
Проверьте, являются ли нормальными CPU, память, I/O диска и сетевой трафик во время исключения. Если обнаружены аномалии, исследуйте основную причину, изучив вариации пикового трафика и использование ресурсов cluster. Если проблема сохраняется, рассмотрите возможность перезапуска затронутого узла.
В чрезвычайных ситуациях вы можете решить проблему следующим образом:
- Уменьшение трафика бизнеса и перезапуск затронутого узла BE, если внезапный всплеск трафика вызвал чрезмерное использование ресурсов и сбой запроса.
- Расширение емкости узлов, если высокое использование ресурсов связано с нормальными операциями.
Алерт сбоя запроса
PromSQL
sum by (job,instance)(selena_fe_query_err_rate{job="$job_name"}) * 100 > 10
# Этот PromSQL поддерживается с v1.5.2 и далее.
increase(selena_fe_query_internal_err{job="$job_name"})[1m] >10
Описание алерта
Алерт запускается, когда частота сбоев запросов превышает 0.1/секунду или 10 неудачных запросов происходят в течение одной минуты.
Решение
Когда этот алерт запускается, проверьте логи для идентификации запросов, которые завершились сбоем.
grep 'State=ERR' fe.audit.log
Если у вас установлен плагин AuditLoader, вы можете найти соответствующие запросы с помощью следующего запроса.
SELECT stmt FROM selena_audit_db__.selena_audit_tbl__ WHERE state='ERR';
Обратите внимание, что запросы, которые завершаются сбоем из-за синтаксических ошибок или тайм-аутов, также записываются в selena_fe_query_err_rate.
Для сбоев запросов, вызванных проблемами ядра, найдите в fe.log ошибку и получите полный стек трассировки и Query Dump, и обратитесь в команду поддержки для устранения неполадок.
Алерт перегрузки запросов
PromSQL
abs((sum by (exported_job)(rate(selena_fe_query_total{process="FE",job="$job_name"}[3m]))-sum by (exported_job)(rate(selena_fe_query_total{process="FE",job="$job_name"}[3m] offset 1m)))/sum by (exported_job)(rate(selena_fe_query_total{process="FE",job="$job_name"}[3m]))) * 100 > 100
abs((sum(selena_fe_connection_total{job="$job_name"})-sum(selena_fe_connection_total{job="$job_name"} offset 3m))/sum(selena_fe_connection_total{job="$job_name"})) * 100 > 100
Описание алерта
Алерт запускается, когда QPS или количество соединений увеличивается на 100% в течение последней минуты.
Решение
Проверьте, являются ли высокочастотные запросы в fe.audit.log ожидаемыми. Если есть законные изменения в поведении бизнеса (например, новые сервисы, запущенные в эксплуатацию, или увеличенные объемы данных), мониторьте нагрузку машины и масштабируйте узлы BE по мере необходимости.
Алерт превышения лимита соединений пользователя
PromSQL
sum(selena_fe_connection_total{job="$job_name"}) by(user) > 90
Описание алерта
Алерт запускается, когда количество соединений пользователя превышает 90. (Лимиты соедине�ний пользователя поддерживаются с версий v1.5.2 и далее.)
Решение
Используйте SQL-команду SHOW PROCESSLIST для проверки, соответствует ли количество текущих соединений ожидаемому. Вы можете завершить неожиданные соединения с помощью команды KILL. Кроме того, убедитесь, что frontend-сервисы не удерживают соединения открытыми слишком долго, и рассмотрите возможность настройки системной переменной wait_timeout (Единица: Секунды) для ускорения автоматического завершения системой незанятых соединений.
SET wait_timeout = 3600;
В чрезвычайных ситуациях вы можете временно увеличить лимит соединений пользователя для восстановления сервиса:
-
Для v1.5.2 или позднее:
ALTER USER 'jack' SET PROPERTIES ("max_user_connections" = "1000"); -
Для v1.5.2 и ранее:
SET PROPERTY FOR 'jack' 'max_user_connections' = '1000';
Алерт исключения Schema Change
PromSQL
increase(selena_be_engine_requests_total{job="$job_name",type="schema_change", status="failed"}[1m]) > 1
Описание алерта
Алерт запускается, когда более одной задачи Schema Change завершается сбоем в последнюю минуту.
Решение
Выполните следующую инструкцию для проверки, содержит ли поле Msg какие-либо сообщения об ошибках:
SHOW ALTER COLUMN FROM $db;
Если сообщение не найдено, найдите JobId из предыдущего шага в логах Leader FE, чтобы получить контекст.
-
Schema Change Out of Memory
Если Schema Change завершается сбоем из-за недостаточной памяти, найдите в логах be.WARNING
failed to process the version,failed to process the schema change from tabletилиMemory of schema change task exceeded limitдля идентификации записей лога, показанных ниже:fail to execute schema change: Memory of schema change task exceed limit. DirectSchemaChange Used: 2149621304, Limit: 2147483648. You can change the limit by modify BE config [memory_limitation_per_thread_for_schema_change]Ошибка лимита памяти обычно вызвана превышением лимита памяти 2 ГБ для одного Schema Change, контролируемого динамическим параметром BE
memory_limitation_per_thread_for_schema_change. Вы можете изменить этот параметр для решения проблемы.curl -XPOST http://be_host:http_port/api/update_config?memory_limitation_per_thread_for_schema_change=8 -
Schema Change Timeout
За исключением добавления столбцов, которое является легковесной реализацией, большинство Schema Changes включают создание большого количества новых tablets, переписывание исходных данных и реализацию операции через SWAP.
Create replicas failed. Error: Error replicas:21539953=99583471, 21539953=99583467, 21539953=99599851Вы можете решить это следующим образом:
-
Уве�личение тайм-аута для создания tablets (По умолчанию: 10 секунд).
ADMIN SET FRONTEND CONFIG ("tablet_create_timeout_second"="60"); -
Увеличение количества потоков для создания tablets (по умолчанию: 3).
curl -XPOST http://be_host:http_port/api/update_config?alter_tablet_worker_count=6
-
-
Ненормальное состояние Tablet
-
Если tablet находится в ненормальном состоянии, найдите в логах be.WARNING
tablet is not normalи выполнитеSHOW PROC '/statistic'для проверкиUnhealthyTabletNumна уровне cluster.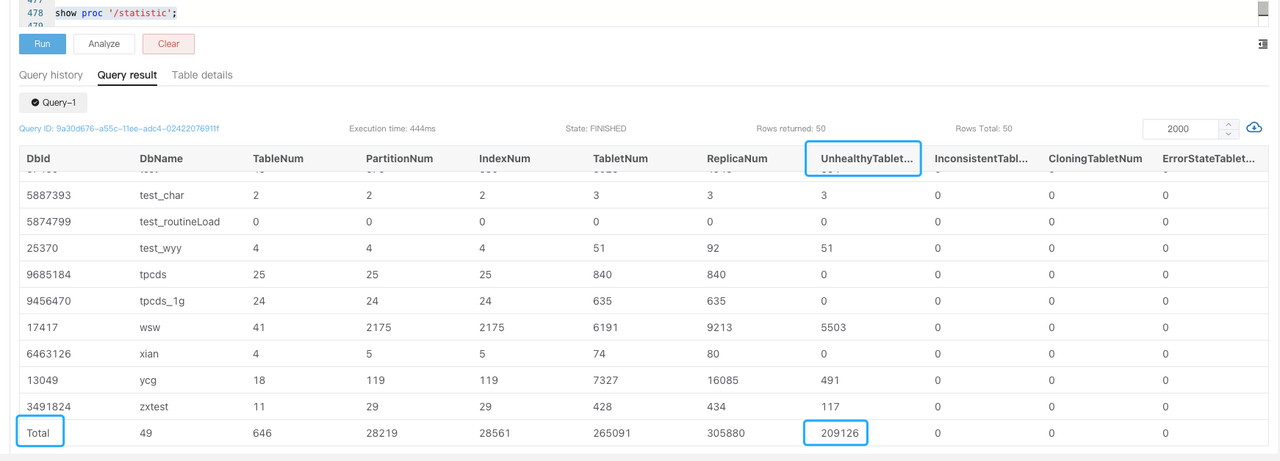
-
Выполните
SHOW PROC '/statistic/$DbId'для проверки количества нездоровых tablets в указанной базе данных.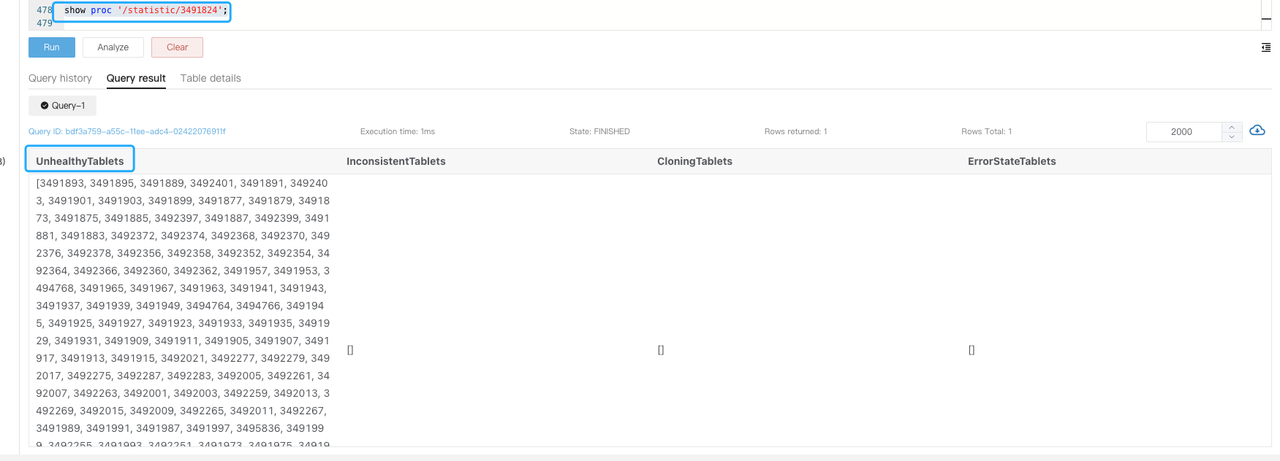
-
Выполните
SHOW TABLET $tablet_idдля просмотра информации о таблице соответствующего tablet.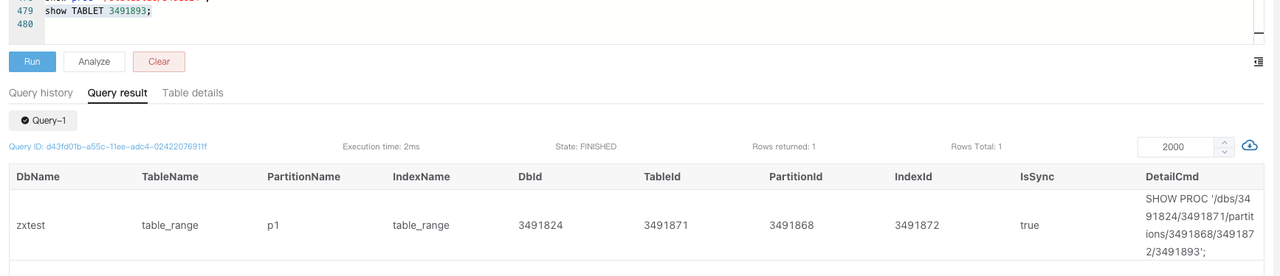
-
Выполните команду, возвращенную в поле
DetailCmd, для идентификации причины нездоровых tablets.
Обычно нездоровые, а также несогласованные replicas обычно вызваны высокочастотной загрузкой, где прогресс записей в разные replicas не синхронизирован. Вы можете проверить, есть ли у таблицы большое количество записей в реальном времени, и уменьшить количество аномальных replicas, уменьшив частоту загрузки или временно приостановив сервис и повторив задачу после этого.
-
В чрезвычайных ситуациях для восстановления сервиса вы можете установить ненормальные replicas как Bad для запуска задачи Clone.
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "$tablet_id", "backend_id" = "$backend_id", "status" = "bad");
Перед выполнением этой операции убедитесь, что таблица имеет по крайней мере три полные replicas с только одной ненормальной replica.
Алерт исключения обновления Materialized View
PromSQL
increase(selena_fe_mv_refresh_total_failed_jobs[5m]) > 0
Описание алерта
Алерт запускается, когда более одного обновления materialized view завершается сбоем в последние пять минут.
Решение
-
Проверьте materialized views, которые завершились сбоем при обновлении.
SELECT TABLE_NAME,IS_ACTIVE,INACTIVE_REASON,TASK_NAME FROM information_schema.materialized_views WHERE LAST_REFRESH_STATE !=" SUCCESS"; -
Попытайтесь вручную обновить materialized view.
REFRESH MATERIALIZED VIEW $mv_name; -
Если materialized view находится в статусе
INACTIVE, попытайтесь вручную активировать его.ALTER MATERIALIZED VIEW $mv_name ACTIVE; -
Исследуйте причину сбоя обновления.
SELECT * FROM information_schema.task_runs WHERE task_name ='mv-112517' \G