Группа ресурсов
В этом разделе описывается функция группы ресурсов в Selena.
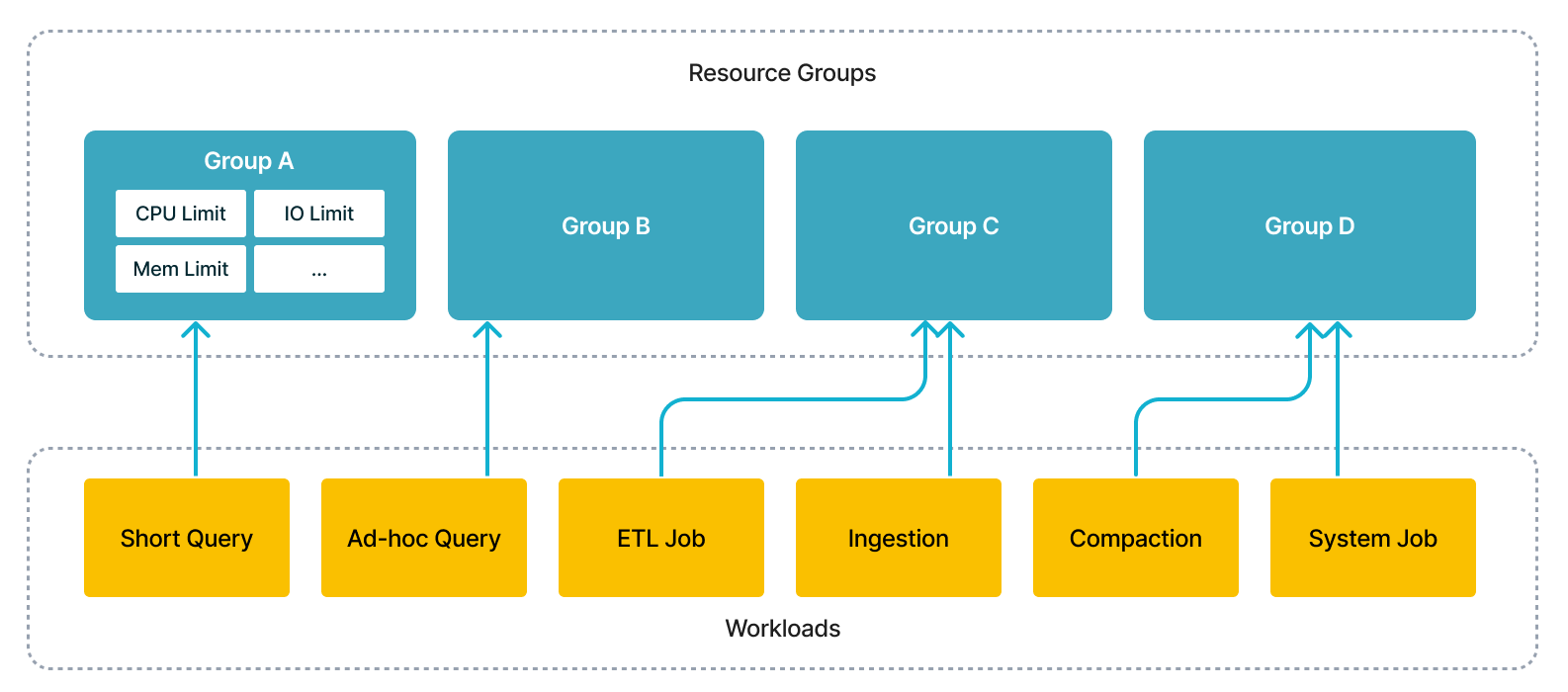
С помощью этой функции вы можете одновременно запускать несколько рабочих нагрузок в одном cluster, включая короткие запросы, ad-hoc запросы, ETL-задания, чтобы сэкономить дополнительные затраты на развёртывание нескольких cluster. С технической точки зрения, движок выполнения планирует параллельные рабочие нагрузки в соответствии со спецификациями поль�зователей и изолирует помехи между ними.
Дорожная карта группы ресурсов:
- Начиная с версии v1.5.2, Selena поддерживает ограничение потребления ресурсов для запросов и реализацию изоляции и эффективного использования ресурсов между арендаторами в одном cluster.
- В Selena v1.5.2 вы можете дополнительно ограничить потребление ресурсов для больших запросов и предотвратить исчерпание ресурсов cluster чрезмерно большими запросами, чтобы гарантировать стабильность системы.
- Selena v1.5.2 поддерживает ограничение потребления вычислительных ресурсов для загрузки данных (INSERT).
- Начиная с версии v1.5.2, Selena поддерживает наложение жёстких ограничений на ресурсы CPU.
| Внутренняя таблица | Внешняя таблица | Ограничение больших запросов | INSERT INTO | Broker Load | Routine Load, Stream Load, Schema Change | Жёсткий лимит CPU | |
|---|---|---|---|---|---|---|---|
| 2.2 | √ | × | × | × | × | × | x |
| 2.3 | √ | √ | √ | × | × | × | x |
| 2.5 | √ | √ | √ | √ | × | × | x |
| 3.1 & 3.2 | √ | √ | √ | √ | √ | × | x |
| 3.3.5 и позже | √ | √ | √ | √ | √ | × | √ |
Термины
В этом разделе описываются термины, которые необходимо понять перед использованием функции группы ресурсов.
Группа ресурсов
Каждая группа ресурсов — это набор вычислительных ресурсов с определённого BE. Вы можете разделить каждый BE вашего cluster на несколько групп ресурсов. Когда запрос назначается группе ресурсов, Selena выделяет ресурсы CPU и памяти для группы ресурсов на основе квот ресурсов, которые вы указали для группы ресурсов.
Вы можете указать квоты ресурсов CPU и памяти для группы ресурсов на BE, используя следующие параметры:
| Параметр | Описание | Диапазон значений | По умолчанию |
|---|---|---|---|
| cpu_weight | Вес планирования CPU этой группы ресурсов на узле BE. | (0, avg_be_cpu_cores] (действует при значении больше 0) | 0 |
| exclusive_cpu_cores | Параметр жёсткой изоляции CPU для этой группы ресурсов. | (0, min_be_cpu_cores - 1] (действует при значении больше 0) | 0 |
| mem_limit | Процент памяти, доступной для запросов этой группы ресурсов на текущем узле BE. | (0, 1] (обязательно) | - |
| mem_pool | Группирует группы ресурсов для совместного использования лимита памяти. | Строка | default_mem_pool |
| spill_mem_limit_threshold | Порог использования памяти, который вызывает сброс на диск. | (0, 1] | 1.0 |
| concurrency_limit | Максимальное количество параллельных запросов в этой группе ресурсов. | Целое число (действует при значении больше 0) | 0 |
| big_query_cpu_second_limit | Максимальное время CPU (в секундах) для задач больших запросов на каждом узле BE. | Целое число (действует при значении больше 0) | 0 |
| big_query_scan_rows_limit | Максимальное количество строк, которые задачи больших запросов могут сканировать на каждом узле BE. | Целое число (действует при значении больше 0) | 0 |
| big_query_mem_limit | Максимальная память, которую задачи больших запросов могут использовать на каждом узле BE. | Целое число (действует при знач�ении больше 0) | 0 |
Параметры ресурсов CPU
cpu_weight
Этот параметр указывает вес планирования CPU группы ресурсов на одном узле BE, определяя относительную долю времени CPU, выделенную задачам из этой группы. До версии v1.5.2 это называлось cpu_core_limit.
Диапазон значений: (0, avg_be_cpu_cores], где avg_be_cpu_cores — среднее количество ядер CPU на всех узлах BE. Параметр действует только при значении больше 0. Должен быть установлен либо cpu_weight, либо exclusive_cpu_cores больше 0, но не оба одновременно.
ПРИМЕЧАНИЕ
Например, предположим, что три группы ресурсов rg1, rg2 и rg3 имеют значения cpu_weight 2, 6 и 8 соответственно. На полностью загруженном узле BE эти группы получат 12.5%, 37.5% и 50% времени CPU. Если узел не полностью загружен и rg1 и rg2 под нагрузкой, а rg3 простаивает, rg1 и rg2 получа�т 25% и 75% времени CPU соответственно.
exclusive_cpu_cores
Этот параметр определяет жёсткий лимит CPU для группы ресурсов. Он имеет два значения:
- Эксклюзивность: Резервирует
exclusive_cpu_coresядер CPU исключительно для этой группы ресурсов, делая их недоступными для других групп, даже когда они простаивают. - Квота: Ограничивает группу ресурсов использованием только этих зарезервированных ядер CPU, предотвращая использование доступных ресурсов CPU из других групп.
Диапазон значений: (0, min_be_cpu_cores - 1], где min_be_cpu_cores — минимальное количество ядер CPU на всех узлах BE. Действует только при значении больше 0. Только один из cpu_weight или exclusive_cpu_cores может быть установлен больше 0.
- Группы ресурсов с
exclusive_cpu_coresбольше 0 называются Эксклюзивными группами ресурсов, а ядра CPU, выделенные им, называются Эксклюзивными ядрами. Другие группы называются Общими группами ресурсов и работают на Общих ядрах. - Общее количество
exclusive_cpu_coresпо всем группам ресурсов не может превышатьmin_be_cpu_cores - 1. Верхний предел установлен, чтобы оставить как минимум одно Общее ядро доступным.
Связь между exclusive_cpu_cores и cpu_weight:
Только один из cpu_weight или exclusive_cpu_cores может быть активен одновременно. Эксклюзивные группы ресурсов работают на своих собственных зарезервированных Эксклюзивных ядрах без необходимости делить время CPU через cpu_weight.
Вы можете настроить, могут ли Общие группы ресурсов заимствовать Эксклюзивные ядра у Эксклюзивных групп ресурсов, используя конфигурацию BE enable_resource_group_cpu_borrowing. При значении true (по умолчанию) Общие группы могут заимствовать ресурсы CPU, когда Эксклюзивные группы простаивают.
Чтобы изменить эту конфигурацию динамически, используйте следующую команду:
UPDATE information_schema.be_configs SET VALUE = "false" WHERE NAME = "enable_resource_group_cpu_borrowing";
Параметры ресурсов памяти
mem_limit
Указывает процент памяти (пул запросов), доступной для группы ресурсов на текущем узле BE. Диапазон значений: (0,1].
mem_pool�
Начиная с версии v2.0.0, указывает идентификатор общего пула памяти. Группы ресурсов с одинаковым идентификатором mem_pool используют общий пул памяти, коллективно ограниченный mem_limit. Если не указано, группа ресурсов назначается в default_mem_pool, и её использование памяти ограничивается только её собственным mem_limit.
Все группы ресурсов, использующие один и тот же mem_pool, должны быть настроены с одинаковым mem_limit.
Чтобы ограничить две группы ресурсов совокупным потреблением 50% памяти, их можно определить следующим образом:
CREATE RESOURCE GROUP rg1
TO (db='db1')
WITH (
'mem_limit' = '50%',
'mem_pool' = 'shared_pool'
);
CREATE RESOURCE GROUP rg2
TO (db='db1')
WITH (
'mem_limit' = '50%',
'mem_pool' = 'shared_pool'
);
spill_mem_limit_threshold
Определяет порог использования памяти, который вызывает сброс на диск. Диапазон значений: (0,1], по умолчанию 1 (неактивно). Введён в версии v1.5.2.
- Когда автоматический сброс включён (
spill_modeустановлен вauto), но группы ресурсов отключены, система сбросит промежуточные результаты на диск, когда использование памяти запроса превысит 80% отquery_mem_limit. - Когда группы ресурсов включены, сброс произойдёт, если:
- Общее использование памяти всех запросов в группе превышает
текущий лимит памяти BE * mem_limit * spill_mem_limit_threshold, или - Использование памяти текущего запроса превышает 80% от
query_mem_limit.
- Общее использование памяти всех запросов в группе превышает
Параметры параллелизма запросов
concurrency_limit
Определяет максимальное количество параллельных запросов в группе ресурсов для предотвращения перегрузки системы. Действует только при значении больше 0, по умолчанию 0.
Параметры ресурсов больших запросов
Вы можете настроить лимиты ресурсов специально для больших запросов, используя следующие параметры:
big_query_cpu_second_limit
Указывает максимальное время CPU (в секундах), которое задачи больших запросов могут использовать на каждом узле BE, суммируя фактическое время CPU, использованное параллельными задачами. Действует только при значении больше 0, по умолчанию 0.
big_query_scan_rows_limit
Устанавливает лимит на количество строк, которые задачи больших запросов могут сканировать на каждом узле BE. Действует только при значении больше 0, по умолчанию 0.
big_query_mem_limit
Определяет максимальную память, которую задачи больших запросов могут использовать на каждом узле BE, в байтах. Действует только при значении больше 0, по умолчанию 0.
ПРИМЕЧАНИЕ
Когда запрос, выполняющийся в группе ресурсов, превышает указанный выше лимит больших запросов, запрос будет прерван с ошибкой. Вы также можете просматривать сообщения об ошибках в столбце
ErrorCodeузла FE fe.audit.log.
Тип (Устарел с версии v1.5.2)
До версии v1.5.2 Selena позволяла устанавливать type гр�уппы ресурсов в short_query. Однако параметр type устарел и заменён на exclusive_cpu_cores. Для любых существующих групп ресурсов этого типа система автоматически преобразует их в Эксклюзивную группу ресурсов, где значение exclusive_cpu_cores равно cpu_weight после обновления до версии v1.5.2.
Системные группы ресурсов
В каждом экземпляре Selena есть две системные группы ресурсов: default_wg и default_mv_wg. Вы можете изменить конфигурацию системных групп ресурсов с помощью команды ALTER RESOURCE GROUP, но не можете определять для них классификаторы или удалять системные группы ресурсов.
default_wg
default_wg будет назначена обычным запросам, которые находятся под управлением групп ресурсов, но не соответствуют ни одному классификатору. Лимиты ресурсов по умолчанию для default_wg следующие:
cpu_weight: Количество ядер CPU BE.mem_limit: 100%.concurrency_limit: 0.big_query_cpu_second_limit: 0.big_query_scan_rows_limit: 0.big_query_mem_limit: 0.spill_mem_limit_threshold: 1.
default_mv_wg
default_mv_wg будет назначена задачам обновления асинхронных материализованных представлений, если группа ресурсов не была выделена соответствующему материализованному представлению в свойстве resource_group при создании материализованного представления. Лимиты ресурсов по умолчанию для default_mv_wg следующие:
cpu_weight: 1.mem_limit: 80%.concurrency_limit: 0.spill_mem_limit_threshold: 80%.
Классификатор
Каждый классификатор содержит одно или несколько условий, которые могут быть сопоставлены со свойствами запросов. Selena определяет классификатор, который лучше всего соответствует каждому запросу на основе условий соответствия, и назначает ресурсы для выполнения запроса.
Классификаторы поддерживают следующие условия:
user: имя пользователя.role: роль пользователя.query_type: тип запроса. ПоддерживаютсяSELECTиINSERT(с версии v1.5.2). Когда задачи INSERT INTO или BROKER LOAD попадают в группу ресурсов сquery_typeравнымinsert, узел BE резервирует указанные ресурсы CPU для задач.source_ip: блок CIDR, из которого инициирован запрос.db: база данных, к которой обращается запрос. Может быть указана строками, разделёнными запятыми,.plan_cpu_cost_range: Диапазон предполагаемой стоимости CPU запроса. Формат:(DOUBLE, DOUBLE]. По умолчанию NULL, что означает отсутствие такого ограничения. СтолбецPlanCpuCostвfe.audit.logпредставляет оценку системы стоимости CPU для запроса. Этот параметр поддерживается с версии v1.5.2.plan_mem_cost_range: Диапазон предполагаемой стоимости памяти запроса. Формат:(DOUBLE, DOUBLE]. По умолчанию NULL, что означает отсутствие такого ограничения. СтолбецPlanMemCostвfe.audit.logпредставляет оценку системы стоимости памяти для запроса. Этот параметр поддерживается с версии v1.5.2.
Классификатор соответствует запросу только тогда, когда одно или все условия классификатора соответствуют информации о запросе. Если несколько классификаторов соответствуют запросу, Selena вычисляет степень соответствия между запросом и каждым классификатором и определяет классификатор с наивысшей степенью соответствия.
ПРИМЕЧАНИЕ
Вы можете просмотреть группу ресурсов, к которой принадлежит запрос, в столбце
ResourceGroupузла FE fe.audit.log или выполнивEXPLAIN VERBOSE <query>, как описано в Просмотр группы ресурсов запроса.
Selena вычисляет степень соответствия между запросом и классификатором, используя следующие правила:
- Если классификатор имеет то же значение
user, что и запрос, степень соответствия классификатора увеличивается на 1. - Если классификатор имеет то же значение
role, что и запрос, ст�епень соответствия классификатора увеличивается на 1. - Если классификатор имеет то же значение
query_type, что и запрос, степень соответствия классификатора увеличивается на 1 плюс число, полученное из следующего расчёта: 1/Количество полейquery_typeв классификаторе. - Если классификатор имеет то же значение
source_ip, что и запрос, степень соответствия классификатора увеличивается на 1 плюс число, полученное из следующего расчёта: (32 -cidr_prefix)/64. - Если классификатор имеет то же значение
db, что и запрос, степень соответствия классификатора увеличивается на 10. - Если стоимость CPU запроса попадает в
plan_cpu_cost_range, степень соответствия классификатора увеличивается на 1. - Если стоимость памяти запроса попадает в
plan_mem_cost_range, степень соответствия классификатора увеличивается на 1.
Если несколько классификаторов соответствуют запросу, классификатор с большим количеством условий имеет более высокую степень соответствия.
-- Классификатор B имеет больше условий, чем классификатор A. Поэтому классификатор B имеет более высокую степень соответствия, чем классификатор A.
classifier A (user='Alice')
classifier B (user='Alice', source_ip = '192.168.1.0/24')
Если несколько соответствующих классификаторов имеют одинаковое количество условий, классификатор, условия которого описаны более точно, имеет более высокую степень соответствия.
-- Блок CIDR, указанный в классификаторе B, меньше по диапазону, чем классификатор A. Поэтому классификатор B имеет более высокую степень соответствия, чем классификатор A.
classifier A (user='Alice', source_ip = '192.168.1.0/16')
classifier B (user='Alice', source_ip = '192.168.1.0/24')
-- Классификатор C имеет меньше типов запросов, указанных в нём, чем классификатор D. Поэтому классификатор C имеет более высокую степень соответствия, чем классификатор D.
classifier C (user='Alice', query_type in ('select'))
classifier D (user='Alice', query_type in ('insert','select'))
Если несколько классификаторов имеют одинаковую степень соответствия, один из классификаторов будет выбран случайным образом.
-- Если запрос одновременно обращается к db1 и db2, и классификаторы E и F имеют
-- наивысшую степень соответствия среди попавших классификаторов, один из E и F будет выбран случайным образом.
classifier E (db='db1')
classifier F (db='db2')
Изоляция вычислительных ресурсов
Вы можете изолировать вычислительные ресурсы между запросами, настроив группы ресурсов и классификаторы.
Включение групп ресурсов
Чтобы использовать группу ресурсов, вы должны включить Pipeline Engine для вашего cluster Selena:
-- Включить Pipeline Engine в текущей сессии.
SET enable_pipeline_engine = true;
-- Включить Pipeline Engine глобально.
SET GLOBAL enable_pipeline_engine = true;
ПРИМЕЧАНИЕ
Начиная с версии v1.5.2, группа ресурсов включена по умолчанию, и переменная сессии
enable_resource_groupустарела.
Создание групп ресурсов и классификаторов
Выполните следующее выражение, чтобы создать группу ресурсов, связать группу ресурсов с классификатором и выделить вычислительные ресурсы группе ресурсов:
CREATE RESOURCE GROUP <group_name>
TO (
user='string',
role='string',
query_type in ('select'),
source_ip='cidr'
) --Создать классификатор. Если вы создаёте более одного классификатора, разделите классификаторы запятыми (`,`).
WITH (
"{ cpu_weight | exclusive_cpu_cores }" = "INT",
"mem_limit" = "m%",
"concurrency_limit" = "INT",
"type" = "str" --Тип группы ресурсов. Установите значение normal.
);
Пример:
CREATE RESOURCE GROUP rg1
TO
(user='rg1_user1', role='rg1_role1', query_type in ('select'), source_ip='192.168.x.x/24'),
(user='rg1_user2', query_type in ('select'), source_ip='192.168.x.x/24'),
(user='rg1_user3', source_ip='192.168.x.x/24'),
(user='rg1_user4'),
(db='db1')
WITH (
'exclusive_cpu_cores' = '10',
'mem_limit' = '20%',
'big_query_cpu_second_limit' = '100',
'big_query_scan_rows_limit' = '100000',
'big_query_mem_limit' = '1073741824'
);
Указание группы ресурсов (опционально)
Вы можете указать группу ресурсов для текущей сессии напрямую, включая default_wg и default_mv_wg.
SET resource_group = 'group_name';
Просмотр групп ресурсов и классификаторов
Выполните следующее выражение, чтобы запросить все группы ресурсов и классификаторы:
SHOW RESOURCE GROUPS ALL;
Выполните следующее выражение, чтобы запросить группы ресурсов и классификаторы вошедшего пользователя:
SHOW RESOURCE GROUPS;
Выполните следующее выражение, чтобы запросить указанную группу ресурсов и её классификаторы:
SHOW RESOURCE GROUP group_name;
Пример:
mysql> SHOW RESOURCE GROUPS ALL;
+---------------+-------+------------+---------------------+-----------+----------------------------+---------------------------+---------------------+-------------------+---------------------------+----------------------------------------+
| name | id | cpu_weight | exclusive_cpu_cores | mem_limit | big_query_cpu_second_limit | big_query_scan_rows_limit | big_query_mem_limit | concurrency_limit | spill_mem_limit_threshold | classifiers |
+---------------+-------+------------+---------------------+-----------+----------------------------+---------------------------+---------------------+-------------------+---------------------------+----------------------------------------+
| default_mv_wg | 3 | 1 | 0 | 80.0% | 0 | 0 | 0 | null | 80% | (id=0, weight=0.0) |
| default_wg | 2 | 1 | 0 | 100.0% | 0 | 0 | 0 | null | 100% | (id=0, weight=0.0) |
| rge1 | 15015 | 0 | 6 | 90.0% | 0 | 0 | 0 | null | 100% | (id=15016, weight=1.0, user=rg1_user) |
| rgs1 | 15017 | 8 | 0 | 90.0% | 0 | 0 | 0 | null | 100% | (id=15018, weight=1.0, user=rgs1_user) |
| rgs2 | 15019 | 8 | 0 | 90.0% | 0 | 0 | 0 | null | 100% | (id=15020, weight=1.0, user=rgs2_user) |
+---------------+-------+------------+---------------------+-----------+----------------------------+---------------------------+---------------------+-------------------+---------------------------+----------------------------------------+
ПРИМЕЧАНИЕ
В приведённом выше примере
weightуказывает степень соответствия.
Чтобы запросить все поля группы ресурсов, включая устаревшие поля.
Добавив ключевое слово VERBOSE к трём командам, упомянутым выше, вы можете просмотреть все поля группы ресурсов, включая устаревшие, такие как type и max_cpu_cores.
SHOW VERBOSE RESOURCE GROUPS ALL;
SHOW VERBOSE RESOURCE GROUPS;
SHOW VERBOSE RESOURCE GROUP group_name;
Управление группами ресурсов и классификаторами
Вы можете изменить квоты ресурсов для каждой группы ресурсов. Вы также можете добавлять или удалять классификаторы из групп ресурсов.
Выполните следующее выражение, чтобы изменить квоты ресурсов для существующей группы ресурсов:
ALTER RESOURCE GROUP group_name WITH (
'cpu_core_limit' = 'INT',
'mem_limit' = 'm%'
);
Выполните следующее выражение, чтобы удалить группу ресурсов:
DROP RESOURCE GROUP group_name;
Выполните следующее выражение, чтобы добавить классификатор в группу ресурсов:
ALTER RESOURCE GROUP <group_name> ADD (user='string', role='string', query_type in ('select'), source_ip='cidr');
Выполните следующее выражение, чтобы удалить классификатор из группы ресурсов:
ALTER RESOURCE GROUP <group_name> DROP (CLASSIFIER_ID_1, CLASSIFIER_ID_2, ...);
Выполните следующее выражение, чтобы удалить все классификаторы группы ресурсов:
ALTER RESOURCE GROUP <group_name> DROP ALL;
Наблюдение за группами ресурсов
Просмотр группы ресурсов запроса
Для запросов, которые ещё не были выполнены, вы можете просмотреть группу ресурсов, которой соответствует запрос, в поле RESOURCE GROUP, возвращаемом EXPLAIN VERBOSE <query>.
Пока запрос выполняется, вы можете проверить, в какую группу ресурсов попал запрос, из поля ResourceGroup, возвращаемого SHOW PROC '/current_queries' и SHOW PROC '/global_current_queries'.
После завершения запроса вы можете просмотреть группу ресурсов, которой соответствовал запрос, проверив поле ResourceGroup в файле fe.audit.log на узле FE.
- Если запрос не находится под управлением групп ресурсов, значение столбца — пустая строка
"". - Если запрос находится под управлением групп ресурсов, но не соответствует ни одному классификатору, значение столбца — пустая строка
"". Но этот запрос назначен группе ресурсов по умолчаниюdefault_wg.
Мониторинг групп ресурсов
Вы можете настроить мониторинг и оповещения для ваших групп ресурсов.
Метрики FE и BE, связанные с группами ресурсов, следующие. Все метрики ниже имеют метку name, указывающую на соответствующую группу ресурсов.
Метрики FE
Следующие метрики FE предоставляют статистику только в пределах текущего узла FE:
| Метрика | Единица | Тип | Описание |
|---|---|---|---|
| selena_fe_query_resource_group | Количество | Мгновенное | Количество исторически выполненных запросов в этой группе ресурсов (включая выполняющиеся в данный момент). |
| selena_fe_query_resource_group_latency | мс | Мгновенное | Процентиль задержки запросов для этой группы ресурсов. Метка type указывает конкретные процентили, включая mean, 75_quantile, 95_quantile, 98_quantile, 99_quantile, 999_quantile. |
| selena_fe_query_resource_group_err | Количество | Мгновенное | Количество запросов в этой группе ресурсов, которые завершились с ошибкой. |
| selena_fe_resource_group_query_queue_total | Количество | Мгновенное | Общее количество исторически поставленных в очередь запросов в этой группе ресурсов (включая выполняющиеся в данный момент). Эта метрика поддерживается с версии v1.5.2. Действительна только при включённых очередях запросов. |
| selena_fe_resource_group_query_queue_pending | Количество | Мгновенное | Количество запросов, в данный момент находящихся в очереди этой группы ресурсов. Эта метрика поддерживается с версии v1.5.2. Действительна только при включённых очередях запросов. |
| selena_fe_resource_group_query_queue_timeout | Количество | Мгновенное | Количество запросов в этой группе ресурсов, которые истекли по тайм-ауту в очереди. Эта метрика поддерживается с версии v1.5.2. Действительна только при включённых очередях запросов. |
Метрики BE
| Метрика | Единица | Тип | Описание |
|---|---|---|---|
| resource_group_running_queries | Количество | Мгновенное | Количество запросов, в данный момент выполняющихся в этой группе ресурсов. |
| resource_group_total_queries | Количество | Мгновенное | Количество исторически выполненных запросов в этой группе ресурсов (включая выполняющиеся в данный момент). |
| resource_group_bigquery_count | Количество | Мгновенное | Количество запросов в этой группе ресурсов, которые превысили лимит больших запросов. |
| resource_group_concurrency_overflow_count | Количество | Мгновенное | Количество запросов в этой группе ресурсов, которые превысили лимит concurrency_limit. |
| resource_group_mem_limit_bytes | Байты | Мгновенное | Лимит памяти для этой группы ресурсов. |
| resource_group_mem_inuse_bytes | Байты | Мгновенное | Память, в данный момент используемая этой группой ресурсов. |
| resource_group_cpu_limit_ratio | Процент | Мгновенное | Соотношение cpu_core_limit этой группы ресурсов к общему cpu_core_limit всех групп ресурсов. |
| resource_group_inuse_cpu_cores | Количество | Среднее | Расчётное количество ядер CPU, используемых этой группой ресурсов. Это значение является приблизительной оценкой. Оно представляет среднее значение, рассчитанное на основе статистики двух последовательных сборов метрик. Эта метри�ка поддерживается с версии v1.5.2. |
| resource_group_cpu_use_ratio | Процент | Среднее | Устарело Соотношение временных квантов потока Pipeline, используемых этой группой ресурсов, к общим временным квантам потока Pipeline, используемым всеми группами ресурсов. Представляет среднее значение, рассчитанное на основе статистики двух последовательных сборов метрик. |
| resource_group_connector_scan_use_ratio | Процент | Среднее | Устарело Соотношение временных квантов потока Scan внешней таблицы, используемых этой группой ресурсов, к общим временным квантам потока Pipeline, используемым всеми группами ресурсов. Представляет среднее значение, рассчитанное на основе статистики двух последовательных сборов метрик. |
| resource_group_scan_use_ratio | Процент | Среднее | Устарело Соотношение временных квантов потока Scan внутренней таблицы, используемых этой группой ресурсов, к общим временным квантам потока Pipeline, используемым всеми группами ресурсов. Представляет среднее значение, рассчитанное на основе статистики двух последовательных сборов метрик. |
Просмотр информации об использовании группы ресурсов
Начиная с версии v1.5.2, Selena поддерживает SQL-выражение SHOW USAGE RESOURCE GROUPS, которое используется для отображения информации об использовании для каждой группы ресурсов на всех BE. Описания каждого поля следующие:
Name: Имя группы ресурсов.Id: ID группы ресурсов.Backend: IP или FQDN BE.BEInUseCpuCores: Количество ядер CPU, в данный момент используемых этой группой ресурсов на этом BE. Это значение является приблизительной оценкой.BEInUseMemBytes: Количество байт памяти, в данный момент используемых этой группой ресурсов на этом BE.BERunningQueries: Количество запросов из этой группы ресурсов, всё ещё выполняющихся на этом BE.
Обратите внимание:
- BE периодически отправляют эту информацию об использовании ресурсов в Leader FE с интервалом, указанным в
report_resource_usage_interval_ms, который по умолчанию установлен на 1 секунду. - Результаты покажут только строки, где по крайней мере один из
BEInUseCpuCores/BEInUseMemBytes/BERunningQueriesявляется положительным числом. Другими словами, информация отображается только тогда, когда группа ресурсов активно использует какие-либо ресурсы на BE.
Пример:
MySQL [(none)]> SHOW USAGE RESOURCE GROUPS;
+------------+----+-----------+-----------------+-----------------+------------------+
| Name | Id | Backend | BEInUseCpuCores | BEInUseMemBytes | BERunningQueries |
+------------+----+-----------+-----------------+-----------------+------------------+
| default_wg | 0 | 127.0.0.1 | 0.100 | 1 | 5 |
+------------+----+-----------+-----------------+-----------------+------------------+
| default_wg | 0 | 127.0.0.2 | 0.200 | 2 | 6 |
+------------+----+-----------+-----------------+-----------------+------------------+
| wg1 | 0 | 127.0.0.1 | 0.300 | 3 | 7 |
+------------+----+-----------+-----------------+-----------------+------------------+
| wg2 | 0 | 127.0.0.1 | 0.400 | 4 | 8 |
+------------+----+-----------+-----------------+-----------------+------------------+
Просмотр информации о потоках для Эксклюзивных и Общих групп ресурсов
Выполнение запросов в основном включает три пула потоков: pip_exec, pip_scan и pip_con_scan.
- Эксклюзивные группы ресурсов работают в своих выделенных пулах потоков и привязаны к Эксклюзивным ядрам CPU, выделенным им.
- Общие группы ресурсов работают в общих пулах потоков и привязаны к оставшимся Общим ядрам CPU.
Потоки в этих трёх пулах следуют соглашению об именовании { pip_exec | pip_scan | pip_con_scan }_{ com | <resource_group_id> }, где com относится к общему пулу потоков, а <resource_group_id> относится к ID Эксклюзивной группы ресурсов.
Вы можете просмотреть информацию о CPU, привязанном к каждому потоку BE, через системное представление information_schema.be_threads. Поля BE_ID, NAME и BOUND_CPUS представляют ID BE, имя потока и количество ядер CPU, привязанных к этому потоку, соответственно.
select * from information_schema.be_threads where name like '%pip_exec%';
select * from information_schema.be_threads where name like '%pip_scan%';
select * from information_schema.be_threads where name like '%pip_con_scan%';
Пример:
select BE_ID, NAME, FINISHED_TASKS, BOUND_CPUS from information_schema.be_threads where name like '%pip_exec_com%' and be_id = 10223;
+-------+--------------+----------------+------------+
| BE_ID | NAME | FINISHED_TASKS | BOUND_CPUS |
+-------+--------------+----------------+------------+
| 10223 | pip_exec_com | 2091295 | 10 |
| 10223 | pip_exec_com | 2088025 | 10 |
| 10223 | pip_exec_com | 1637603 | 6 |
| 10223 | pip_exec_com | 1641260 | 6 |
| 10223 | pip_exec_com | 1634197 | 6 |
| 10223 | pip_exec_com | 1633804 | 6 |
| 10223 | pip_exec_com | 1638184 | 6 |
| 10223 | pip_exec_com | 1636374 | 6 |
| 10223 | pip_exec_com | 2095951 | 10 |
| 10223 | pip_exec_com | 2095248 | 10 |
| 10223 | pip_exec_com | 2098745 | 10 |
| 10223 | pip_exec_com | 2085338 | 10 |
| 10223 | pip_exec_com | 2101221 | 10 |
| 10223 | pip_exec_com | 2093901 | 10 |
| 10223 | pip_exec_com | 2092364 | 10 |
| 10223 | pip_exec_com | 2091366 | 10 |
+-------+--------------+----------------+------------+