Hive catalog
Hive catalog - это тип external catalog, который поддерживается Selena начиная с версии v1.5.2. В рамках Hive catalog вы можете:
- Напрямую запрашивать данные, хранящиеся в Hive, без необходимости вручную создавать таблицы.
- Использовать INSERT INTO или асинхронные материал�изованные представления (которые поддерживаются начиная с версии v1.5.2) для обработки данных, хранящихся в Hive, и загрузки данных в Selena.
- Выполнять операции в Selena для создания или удаления баз данных и таблиц Hive, или загружать данные из таблиц Selena в таблицы Hive в форматах Parquet (поддерживается начиная с версии v1.5.2), ORC или Textfile (поддерживается начиная с версии v1.5.2) с помощью INSERT INTO.
Чтобы обеспечить успешное выполнение SQL-операций на вашем Hive cluster, ваш Selena cluster должен иметь доступ к системе хранения и metastore вашего Hive cluster. Selena поддерживает следующие системы хранения и metastore:
-
Distributed file system (HDFS) или object storage, такие как AWS S3, Microsoft Azure Storage, Google GCS или другие S3-совместимые системы хранения (например, MinIO)
-
Metastore, такие как Hive metastore или AWS Glue
примечаниеЕсли вы выберете AWS S3 в качестве хранилища, вы можете использовать HMS или AWS Glue в качестве metastore. Если вы выберете любую другую систему хранения, вы можете использовать только HMS в качестве metastore.
Примечания по использованию
-
Selena поддерживает запросы к таблицам Hive в форматах файлов Parquet, ORC, Textfile, Avro, RCFile и SequenceFile:
- Файлы Parquet поддерживают следующие форматы сжатия: SNAPPY, LZ4, ZSTD, GZIP и NO_COMPRESSION. Начиная с версии v1.5.2, файлы Parquet также поддерживают формат сжатия LZO.
- Файлы ORC поддерживают следующие форматы сжатия: ZLIB, SNAPPY, LZO, LZ4, ZSTD и NO_COMPRESSION.
- Файлы Textfile поддерживают формат сжатия LZO начиная с версии v1.5.2.
-
Типы данных Hive, которые Selena не поддерживает: INTERVAL, BINARY и UNION. Кроме того, Selena не поддерживает типы данных MAP и STRUCT для таблиц Hive в формате Textfile.
-
Selena поддерживает загрузку данных в таблицы Hive в форматах Parquet (поддерживается начиная с версии v1.5.2), ORC или Textfile (поддерживается начиная с версии v1.5.2):
- Файлы Parquet и ORC поддерживают следующие форматы сжатия: NO_COMPRESSION, SNAPPY, LZ4, ZSTD и GZIP.
- Файлы Textfile поддерживают формат сжатия NO_COMPRESSION.
Вы можете использовать свойство таблицы
compression_codecили системную переменнуюconnector_sink_compression_codecдля указания алгоритма сжатия, используемого при загрузке данных в таблицы Hive.При записи в таблицу Hive, если свойства таблицы включают compression codec, Selena будет приоритетно использовать этот алгоритм для сжатия записываемых данных. В противном случае будет использован алгоритм сжатия, установленный в системной переменной
connector_sink_compression_codec.
Подготовка к интеграции
Перед созданием Hive catalog убедитесь, что ваш Selena cluster может интегрироваться с системой хранения и metastore вашего Hive cluster.
AWS IAM
Если ваш Hive cluster использует AWS S3 в качестве хранилища или AWS Glue в качестве metastore, выберите подходящий метод аутентификации и выполните необходимые подготовительные действия, чтобы ваш Selena cluster мог получить доступ к соответствующим облачным ресурсам AWS.
Рекомендуются следующие методы аутентификации:
- Instance profile
- Assumed role
- IAM user
Из этих трех методов аутентификации наиболее широко используется instance profile.
Для получения дополнительной информации см. Подготовка к аутентификации в AWS IAM.
HDFS
Если вы выбрали HDFS в качестве хранилища, настройте ваш Selena cluster следующим образом:
-
(Опционально) Установите имя пользователя, которое используется для доступа к вашему HDFS cluster и Hive metastore. По умолчанию Selena использует имя пользоват�еля процессов FE и BE или CN для доступа к вашему HDFS cluster и Hive metastore. Вы также можете установить имя пользователя, добавив
export HADOOP_USER_NAME="<user_name>"в начало файла fe/conf/hadoop_env.sh каждого FE и в начало файла be/conf/hadoop_env.sh каждого BE или файла cn/conf/hadoop_env.sh каждого CN. После установки имени пользователя в этих файлах перезапустите каждый FE и каждый BE или CN, чтобы настройки параметров вступили в силу. Вы можете установить только одно имя пользователя для каждого Selena cluster. -
Когда вы запрашиваете данные Hive, FE и BE или CN вашего Selena cluster используют HDFS client для доступа к вашему HDFS cluster. В большинстве случаев вам не нужно настраивать ваш Selena cluster для этой цели, и Selena запускает HDFS client с использованием конфигураций по умолчанию. Вам нужно настроить ваш Selena cluster только в следующих ситуациях:
- High availability (HA) включена для вашего HDFS cluster: Добавьте файл hdfs-site.xml вашего HDFS cluster в путь $FE_HOME/conf каждого FE и в путь $BE_HOME/conf каждого BE или путь $CN_HOME/conf каждого CN.
- View File System (ViewFs) включена для вашего HDFS cluster: Добавьте файл core-site.xml вашего HDFS cluster в путь $FE_HOME/conf каждого FE и в путь $BE_HOME/conf каждого BE или путь $CN_HOME/conf каждого CN.
Если при отправке запроса возвращается ошибка, указывающая на неизвестный хост, вы должны добавить сопоставление между именами хостов и IP-адресами узлов вашего HDFS cluster в путь /etc/hosts.
Аутентификация Kerberos
Если аутентификация Kerberos включена для вашего HDFS cluster или Hive metastore, настройте ваш Selena cluster следующим образом:
- Выполните команду
kinit -kt keytab_path principalна каждо�м FE и каждом BE или CN для получения Ticket Granting Ticket (TGT) из Key Distribution Center (KDC). Для выполнения этой команды вы должны иметь разрешения на доступ к вашему HDFS cluster и Hive metastore. Обратите внимание, что доступ к KDC с помощью этой команды зависит от времени. Поэтому вам нужно использовать cron для периодического выполнения этой команды. - Добавьте
JAVA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf"в файл $FE_HOME/conf/fe.conf каждого FE и в файл $BE_HOME/conf/be.conf каждого BE или файл $CN_HOME/conf/cn.conf каждого CN. В этом примере/etc/krb5.conf- это путь сохранения файла krb5.conf. Вы можете изменить путь в соответствии с вашими потребностями.
Создание Hive catalog
Синтаксис
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
(
"type" = "hive",
GeneralParams,
MetastoreParams,
StorageCredentialParams,
MetadataUpdateParams
)
Параметры
catalog_name
Имя Hive catalog. Соглашения об именовании следующие:
- Имя может содержать буквы, цифры (0-9) и подчеркивания (_). Оно должно начинаться с буквы.
- Имя чувствительно к регистру и не может превышать 1023 символа в длину.
comment
Описание Hive catalog. Этот параметр необязателен.
type
Тип вашего источника данных. Установите значение hive.
GeneralParams
Набор общих параметров.
В следующей таблице описаны параметры, которые вы можете настроить в GeneralParams.
| Параметр | Обязательный | Описание |
|---|---|---|
| enable_recursive_listing | Нет | Указывает, читает ли Selena данные из таблицы и ее partitions, а также из подкаталогов в физических расположениях таблицы и ее partitions. Допустимые значения: true и false. Значение по умолчанию: true. Значение true указывает на рекурсивный список подкаталогов, а значение false указывает на игнорирование подкаталогов. |
MetastoreParams
Набор параметров о том, как Selena интегрируется с metastore вашего источника данных.
Hive metastore
Если вы выбрали Hive metastore в качестве metastore вашего источника данных, настройте MetastoreParams следующим образом:
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "<hive_metastore_uri>"
Перед запросом данных Hive вы должны добавить сопоставление между именами хостов и IP-адресами узлов вашего Hive metastore в путь /etc/hosts. В противном случае Selena может не получить доступ к вашему Hive metastore при запуске запроса.
В следующей таблице описан параметр, который вам нужно настроить в MetastoreParams.
| Параметр | Обязательный | Описание |
|---|---|---|
| hive.metastore.type | Да | Тип metastore, который вы используете для вашего Hive cluster. Установите значение hive. |
| hive.metastore.uris | Да | URI вашего Hive metastore. Формат: thrift://<metastore_IP_address>:<metastore_port>.Если high availability (HA) включена для вашего Hive metastore, вы можете указать несколько URI metastore и разделить их запятыми ( ,), например, "thrift://<metastore_IP_address_1>:<metastore_port_1>,thrift://<metastore_IP_address_2>:<metastore_port_2>,thrift://<metastore_IP_address_3>:<metastore_port_3>". |
AWS Glue
Если вы выбрали AWS Glue в качестве metastore вашего источника данных, что поддерживается только при выборе AWS S3 в качестве хранилища, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации на основе instance profile, настройте
MetastoreParamsследующим образом:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "<aws_glue_region>" -
Чтобы выбрать метод аутентификации на основе assumed role, настройте
MetastoreParamsследующим образом:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "<iam_role_arn>",
"aws.glue.region" = "<aws_glue_region>" -
Чтобы выбрать метод аутентификации на основе IAM user, настройте
MetastoreParamsследующим образом:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "<aws_s3_region>"
В следующей таблице описаны параметры, которые вам нужно настроить в MetastoreParams.
| Параметр | Обязательный | Описание |
|---|---|---|
| hive.metastore.type | Да | Тип metastore, который вы используете для вашего Hive cluster. Установите значение glue. |
| aws.glue.use_instance_profile | Да | Указывает, включить ли метод аутентификации на основе instance profile и метод аутентификации на основе assumed role. Допустимые значения: true и false. Значение по умолчанию: false. |
| aws.glue.iam_role_arn | Нет | ARN IAM роли, которая имеет привилегии на ваш AWS Glue Data Catalog. Если вы используете метод аутентификации на основе assumed role для доступа к AWS Glue, вы должны указать этот параметр. |
| aws.glue.region | Да | Регион, в котором находится ваш AWS Glue Data Catalog. Пример: us-west-1. |
| aws.glue.access_key | Нет | Access key вашего AWS IAM user. Если вы используете метод аутентификации на основе IAM user для доступа к AWS Glue, вы должны указать этот параметр. |
| aws.glue.secret_key | Нет | Secret key вашего AWS IAM user. Если вы используете метод аутентификации на основе IAM user для доступа к AWS Glue, вы должны указать этот параметр. |
| hive.metastore.glue.catalogid | Нет | ID AWS Glue Data Catalog для использования. Если не указан, используется catalog в текущей учетной записи AWS. Вы должны указать этот параметр, когда вам нужно получить доступ к Glue Data Catalog в другой учетной записи AWS (cross-account access). |
Для получения информации о том, как выбрать метод аутентификации для доступа к AWS Glue и как настроить политику контроля доступа в AWS IAM Console, см. Параметры аутентификации для доступа к AWS Glue.
StorageCredentialParams
Набор параметров о том, как Selena интегрируется с вашей системой хранения. Этот набор параметров необязателен.
Если вы используете HDFS в качестве хранилища, вам не нужно настраивать StorageCredentialParams.
Если вы используете AWS S3, другую S3-совместимую систему хранения, Microsoft Azure Storage или Google GCS в качестве хранилища, вы должны настроить StorageCredentialParams.
AWS S3
Если вы выбрали AWS S3 в качестве хранилища для вашего Hive cluster, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации на основе instance profile, настройте
StorageCredentialParamsследующим образом:"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
Чтобы выбрать метод аутентификации на основе assumed role, настройте
StorageCredentialParamsследующим образом:"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
Чтобы выбрать метод аутентификации на основе IAM user, настройте
StorageCredentialParamsследующим образом:"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
В следующей таблице описаны параметры, которые вам нужно настроить в StorageCredentialParams.
| Параметр | Обязательный | Описание |
|---|---|---|
| aws.s3.use_instance_profile | Да | Указывает, включить ли метод аутентификации на основе instance profile и метод аутентификации на основе assumed role. Допустимые значения: true и false. Значение по умолчанию: false. |
| aws.s3.iam_role_arn | Нет | ARN IAM роли, которая имеет привилегии на ваш AWS S3 bucket. Если вы используете метод аутентификации на основе assumed role для доступа к AWS S3, вы должны указать этот параметр. |
| aws.s3.region | Да | Регион, в котором находится ваш AWS S3 bucket. Пример: us-west-1. |
| aws.s3.access_key | Нет | Access key вашего IAM user. Если вы используете метод аутентификации на основе IAM user для доступа к AWS S3, вы должны указать этот параметр. |
| aws.s3.secret_key | Нет | Secret key вашего IAM user. Если вы используете метод аутентификации на основе IAM user для доступа к AWS S3, вы должны указать этот параметр. |
Для получения информации о том, как выбрать метод аутентификации для доступа к AWS S3 и как настроить политику контроля доступа в AWS IAM Console, см. Параметры аутентификации для доступа к AWS S3.
S3-совместимая система хранения
Hive catalogs поддерживают S3-совместимые системы хранения начиная с версии v1.5.2.
Если вы выбрали S3-совместимую систему хра�нения, такую как MinIO, в качестве хранилища для вашего Hive cluster, настройте StorageCredentialParams следующим образом для обеспечения успешной интеграции:
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
В следующей таблице описаны параметры, которые вам нужно настроить в StorageCredentialParams.
| Параметр | Обязательный | Описание |
|---|---|---|
| aws.s3.enable_ssl | Да | Указывает, включить ли SSL-соединение. Допустимые значения: true и false. Значение по умолчанию: true. |
| aws.s3.enable_path_style_access | Да | Указывает, включить ли доступ в стиле пути. Допустимые значения: true и false. Значение по умолчанию: false. Для MinIO вы должны установить значение true.URL-адреса в стиле пути используют следующий формат: https://s3.<region_code>.amazonaws.com/<bucket_name>/<key_name>. Например, если вы создаете bucket с именем DOC-EXAMPLE-BUCKET1 в регионе US West (Oregon) и хотите получить доступ к объекту alice.jpg в этом bucket, вы можете использовать следующий URL в стиле пути: https://s3.us-west-2.amazonaws.com/DOC-EXAMPLE-BUCKET1/alice.jpg. |
| aws.s3.endpoint | Да | Endpoint, который используется для подключения к вашей S3-совместимой системе хранения вместо AWS S3. |
| aws.s3.access_key | Да | Access key вашего IAM user. |
| aws.s3.secret_key | Да | Secret key вашего IAM user. |
Microsoft Azure Storage
Hive catalogs поддерживают Microsoft Azure Storage начиная с версии v1.5.2.
Azure Blob Storage
Если вы выбрали Blob Storage в качестве хранилища для вашего Hive cluster, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации Shared Key, настройте
StorageCredentialParamsследующим образом:"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.shared_key" = "<storage_account_shared_key>"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Обязательный Описание azure.blob.storage_account Да Имя пользователя вашей учетной записи Blob Storage. azure.blob.shared_key Да Shared key вашей учетной записи Blob Storage. -
Чтобы выбрать метод аутентификации SAS Token, настройте
StorageCredentialParamsследующим образом:"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.container" = "<container_name>",
"azure.blob.sas_token" = "<storage_account_SAS_token>"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Обязательный Описание azure.blob.storage_account Да Имя пользователя в�ашей учетной записи Blob Storage. azure.blob.container Да Имя blob container, в котором хранятся ваши данные. azure.blob.sas_token Да SAS token, который используется для доступа к вашей учетной записи Blob Storage.
Azure Data Lake Storage Gen2
Если вы выбрали Data Lake Storage Gen2 в качестве хранилища для вашего Hive cluster, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации Managed Identity, настройте
StorageCredentialParamsследующим образом:"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Обязательный Описание azure.adls2.oauth2_use_managed_identity Да Указывает, включить ли метод аутентификации Managed Identity. Установите значение true.azure.adls2.oauth2_tenant_id Да ID tenant, данные которого вы хотите получить. azure.adls2.oauth2_client_id Да Client (application) ID managed identity. -
Чтобы выбрать метод аутентификации Shared Key, настройте
StorageCredentialParamsследующим образом:"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<storage_account_shared_key>"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Обязательный Описание azure.adls2.storage_account Да Имя пользователя вашей учетной записи хранения Data Lake Storage Gen2. azure.adls2.shared_key Да Shared key вашей учетной записи хранения Data Lake Storage Gen2. -
Чтобы выбрать метод аутентификации Service Principal, настройте
StorageCredentialParamsследующим образом:"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Обязательный Описание azure.adls2.oauth2_client_id Да Client (application) ID service principal. azure.adls2.oauth2_client_secret Да Значение нового созданного client (application) secret. azure.adls2.oauth2_client_endpoint Да OAuth 2.0 token endpoint (v1) service principal или application.
Azure Data Lake Storage Gen1
Если вы выбрали Data Lake Storage Gen1 в качестве хранилища для вашего Hive cluster, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации Managed Service Identity, настройте
StorageCredentialParamsследующим образом:"azure.adls1.use_managed_service_identity" = "true"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Обязательный Описание azure.adls1.use_managed_service_identity Да Указывает, включить ли метод аутентификации Managed Service Identity. Установите значение true. -
Чтобы выбрать метод аутентификации Service Principal, настройте
StorageCredentialParamsследующим образом:"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Обязательный Описание azure.adls1.oauth2_client_id Да Client (application) ID service principal. azure.adls1.oauth2_credential Да Значение нового созданного client (application) secret. azure.adls1.oauth2_endpoint Да OAuth 2.0 token endpoint (v1) service principal или application.
Google GCS
Hive catalogs поддерживают Google GCS начиная с версии v1.5.2.
Если вы выбрали Google GCS в качестве хранилища для вашего Hive cluster, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации на основе VM, настройте
StorageCredentialParamsследующим образом:"gcp.gcs.use_compute_engine_service_account" = "true"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Значение по умолчанию Пример значения Описание gcp.gcs.use_compute_engine_service_account false true Указывает, использовать ли напрямую service account, привязанный к вашему Compute Engine. -
Чтобы выбрать метод аутентификации на основе service account, настройте
StorageCredentialParamsследующим образом:"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Значение по умолчанию Пример значения Описание gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" Адрес электронной почты в JSON-файле, созданном при создании service account. gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" ID private key в JSON-файле, созданном при создании service account. gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" Private key в JSON-файле, созданном при создании service account. -
Чтобы выбрать метод аутентификации на основе impersonation, настройте
StorageCredentialParamsследующим образом:-
Заставить VM instance имперсонировать service account:
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"В следующей таблице описаны пара�метры, которые вам нужно настроить в
StorageCredentialParams.Параметр Значение по умолчанию Пример значения Описание gcp.gcs.use_compute_engine_service_account false true Указывает, использовать ли напрямую service account, привязанный к вашему Compute Engine. gcp.gcs.impersonation_service_account "" "hello" Service account, который вы хотите имперсонировать. -
Заставить service account (временно названный meta service account) имперсонировать другой service account (временно названный data service account):
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"В следующей таблице описаны параметры, которые вам нужно настроить в
StorageCredentialParams.Параметр Значение по умолчанию Пример значения Описание gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" Адрес электронной почты в JSON-файле, созданном при создании meta service account. gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" ID private key в JSON-файле, созданном при создании meta service account. gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" Private key в JSON-файле, созданном при создании meta service account. gcp.gcs.impersonation_service_account "" "hello" Data service account, который вы хотите имперсонировать.
-
MetadataUpdateParams
Набор параметров о том, как Selena обновляет кэшированные метаданные Hive. Этот набор параметров необязателен.
Selena реализует политику автоматического асинхронного обновления по умолчанию.
В большинстве случаев вы можете игнорировать MetadataUpdateParams и не настраивать параметры политики в нем, потому что значения по умолчанию этих параметров уже обеспечивают готовую к использованию производительность.
Однако, если частота обновления данных в Hive высока, вы можете настроить эти параметры для дальнейшей оптимизации производительности автоматических асинхронных обновлений.
В большинстве случаев, если ваши данные Hive обновляются с детализацией 1 час или меньше, частота обновления данных считается высокой.
| Параметр | Обязательный | Описание |
|---|---|---|
| enable_metastore_cache | Нет | Указывает, кэширует ли Selena метаданные таблиц Hive. Допустимые значения: true и false. Значение по умолчанию: true. Значение true включает кэш, а значение false отключает кэш. |
| enable_remote_file_cache | Нет | Указывает, кэширует ли Selena метаданные базовых файлов данных таблиц или partitions Hive. Допустимые значения: true и false. Значение по умолчанию: true. Значение true включает кэш, а значение false отключает кэш. |
| metastore_cache_refresh_interval_sec | Нет | Интервал времени, с которым Selena асинхронно обновляет метаданные таблиц или partitions Hive, кэшированные в себе. Единица измерения: секунды. Значение по умолчанию: 60, что составляет одну минуту. Начиная с версии v1.5.2, значение по умолчанию этого свойства изменено с 7200 на 60. |
| remote_file_cache_refresh_interval_sec | Нет | Интервал времени, с которым Selena асинхронно обновляет метаданные базовых файлов данных таблиц или partitions Hive, кэшированные в себе. Единица измерения: секунды. Значение по умолчанию: 60. |
| metastore_cache_ttl_sec | Нет | Интервал времени, с которым Selena автоматически отбрасывает метаданные таблиц или partitions Hive, кэшированные в себе. Единица измерения: секунды. Значение по умолчанию: 86400, что составляет 24 часа. |
| remote_file_cache_ttl_sec | Нет | Интервал времени, с которым Selena автоматически отбрасывает метаданные базовых файлов данных таблиц или partitions Hive, кэшированные в себе. Единица измерения: секунды. Значен�ие по умолчанию: 129600, что составляет 36 часов. |
| enable_cache_list_names | Нет | Указывает, кэширует ли Selena имена partitions Hive. Допустимые значения: true и false. Значение по умолчанию: true. Значение true включает кэш, а значение false отключает кэш. |
| remote_file_cache_memory_ratio | Нет | Максимальное соотношение использования памяти для кэша удаленных файлов. Значение по умолчанию: 0.1, что составляет 10%. Поддерживается начиная с версии v1.5.2. |
Примеры
Следующие примеры создают Hive catalog с именем hive_catalog_hms или hive_catalog_glue, в зависимости от типа metastore, который вы используете, для запроса данных из вашего Hive cluster.
HDFS
Если вы используете HDFS в качестве хранилища, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
AWS S3
Аутентификация на основе instance profile
-
Если вы используете Hive metastore в вашем Hive cluster, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
); -
Если вы используете AWS Glue в вашем Amazon EMR Hive cluster, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
);
Аутентификация на основе assumed role
-
Если вы используете Hive metastore в вашем Hive cluster, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
); -
Если вы используете AWS Glue в вашем Amazon EMR Hive cluster, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "arn:aws:iam::081976408565:role/test_glue_role",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
);
Аутентификация на основе IAM user
-
Если вы используете Hive metastore в вашем Hive cluster, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_access_key>",
"aws.s3.region" = "us-west-2"
); -
Если вы используете AWS Glue в вашем Amazon EMR Hive cluster, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "us-west-2"
);
S3-совместимая система хранения
Используйте MinIO в качестве примера. Выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.enable_ssl" = "true",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
Microsoft Azure Storage
Azure Blob Storage
-
Если вы выберете метод аутентификации Shared Key, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
); -
Если вы выберете метод аутентификации SAS Token, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.container" = "<blob_container_name>",
"azure.blob.sas_token" = "<blob_storage_account_SAS_token>"
);
Azure Data Lake Storage Gen1
-
Если вы выберете метод аутентификации Managed Service Identity, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.use_managed_service_identity" = "true"
); -
Если вы выберете метод аутентификации Service Principal, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
);
Azure Data Lake Storage Gen2
-
Если вы выберете метод аутентификации Managed Identity, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"
); -
Если вы выберете метод аутентификации Shared Key, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<shared_key>"
); -
Если вы выберете метод аутентификации Service Principal, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
);
Google GCS
-
Если вы выберете метод аутентификации на основе VM, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true"
); -
Если вы выберете метод аутентификации на основе service account, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"
); -
Если вы выберете метод аутентификации на основе impersonation:
-
Если вы заставляете VM instance имперсонировать service account, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"
); -
Если вы заставляете service account имперсонировать другой service account, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
);
-
Просмотр Hive catalogs
Вы можете использовать SHOW CATALOGS для запроса всех catalogs в текущем Selena cluster:
SHOW CATALOGS;
Вы также можете использовать SHOW CREATE CATALOG для запроса инструкции создания external catalog. Следующий пример запрашивает инструкцию создания Hive catalog с именем hive_catalog_glue:
SHOW CREATE CATALOG hive_catalog_glue;
Переключение на Hive Catalog и базу данных в нем
Вы можете использовать один из следующих методов для переключения на Hive catalog и базу данных в нем:
-
Используйте SET CATALOG для указания Hive catalog в текущей сессии, а затем используйте USE для указания активной базы данных:
-- Переключитесь на указанный catalog в текущей сессии:
SET CATALOG <catalog_name>
-- Укажите активную базу данных в текущей сессии:
USE <db_name> -
Непосредственно используйте USE для переключения на Hive catalog и базу данных в нем:
USE <catalog_name>.<db_name>
Удаление Hive catalog
Вы можете использовать DROP CATALOG для удаления external catalog.
Следующий пример удаляет Hive catalog с именем hive_catalog_glue:
DROP Catalog hive_catalog_glue;
Просмотр схемы таблицы Hive
Вы можете использовать один из следующих синтаксисов для просмотра схемы таблицы Hive:
-
Просмотр схемы
DESC[RIBE] <catalog_name>.<database_name>.<table_name> -
Просмотр схемы и расположения из инструкции CREATE
SHOW CREATE TABLE <catalog_name>.<database_name>.<table_name>
Запрос таблицы Hive
-
Используйте SHOW DATABASES для просмотра баз данных в вашем Hive cluster:
SHOW DATABASES FROM <catalog_name> -
Используйте SELECT для запроса целевой таблицы в указанной базе данных:
SELECT count(*) FROM <table_name> LIMIT 10
Загрузка данных из Hive
Предположим, у вас есть OLAP-таблица с именем olap_tbl, вы можете преобразовать и загрузить данные следующим образом:
INSERT INTO default_catalog.olap_db.olap_tbl SELECT * FROM hive_table
Предоставление привилегий на таблицы и представления Hive
Вы можете использовать инструкцию GRANT для предоставления привилегий на все таблицы и представления в Hive catalog определенной роли. Синтаксис команды следующий:
GRANT SELECT ON ALL TABLES IN ALL DATABASES TO ROLE <role_name>
Например, используйте следующие команды для создания роли с именем hive_role_table, переключитесь на Hive catalog hive_catalog, а затем предоставьте роли hive_role_table привилегию запроса всех таблиц и представлений в Hive catalog hive_catalog:
-- Создайте роль с именем hive_role_table.
CREATE ROLE hive_role_table;
-- Переключитесь на Hive catalog hive_catalog.
SET CATALOG hive_catalog;
-- Предоставьте роли hive_role_table привилегию запроса всех таблиц и представлений в Hive catalog hive_catalog.
GRANT SELECT ON ALL TABLES IN ALL DATABASES TO ROLE hive_role_table;
Создание базы данных Hive
Подобно внутреннему catalog Selena, если у вас есть привилегия CREATE DATABASE на Hive catalog, вы можете использовать инструкцию CREATE DATABASE для создания базы данных в этом Hive catalog. Эта функция поддерживается начиная с версии v1.5.2.
Вы можете предоставлять и отзывать привилегии с помощью GRANT и REVOKE.
Переключитесь на Hive catalog, а затем используйте следующую инструкцию для создания базы данных Hive в этом catalog:
CREATE DATABASE <database_name>
[PROPERTIES ("location" = "<prefix>://<path_to_database>/<database_name.db>")]
Параметр location указывает путь к файлу, в котором вы хотите создать базу данных, который может быть либо в HDFS, либо в облачном хранилище.
- Когда вы используете Hive metastore в кач�естве metastore вашего Hive cluster, параметр
locationпо умолчанию принимает значение<warehouse_location>/<database_name.db>, которое поддерживается Hive metastore, если вы не указываете этот параметр при создании базы данных. - Когда вы используете AWS Glue в качестве metastore вашего Hive cluster, параметр
locationне имеет значения по умолчанию, и поэтому вы должны указать этот параметр при создании базы данных.
Значение prefix зависит от системы хранения, которую вы используете:
| Система хранения | Значение prefix |
|---|---|
| HDFS | hdfs |
| Google GCS | gs |
| Azure Blob Storage |
|
| Azure Data Lake Storage Gen1 | adl |
| Azure Data Lake Storage Gen2 |
|
| AWS S3 или другое S3-совместимое хранилище (например, MinIO) | s3 |
Удаление базы данных Hive
Подобно внутренним базам данных Selena, если у вас есть привилегия DROP на базу данных Hive, вы можете использовать инструкцию DROP DATABASE для удаления этой базы данных Hive. Эта функция поддерживается начиная с версии v1.5.2. Вы можете удалять только пустые базы данных.
Когда вы удаляете базу данных Hive, путь к файлу базы данных в вашем HDFS cluster или облачном хранилище не будет удален вместе с базой данных.
Переключитесь на Hive catalog, а затем используйте следующую инструкцию для удаления базы данных Hive в этом catalog:
DROP DATABASE <database_name>
Создание таблицы Hive
Подобно внут�ренним базам данных Selena, если у вас есть привилегия CREATE TABLE на базу данных Hive, вы можете использовать инструкции CREATE TABLE, CREATE TABLE AS SELECT или CREATE TABLE LIKE для создания управляемой таблицы в этой базе данных Hive.
Эта функция поддерживается с версии v1.5.2, в которой Selena поддерживает только создание таблиц Hive в формате Parquet. Начиная с версии v1.5.2, Selena также поддерживает создание таблиц Hive в форматах ORC и Textfile.
Переключитесь на Hive catalog и базу данных в нем, а затем используйте следующий синтаксис для создания управляемой таблицы Hive в этой базе данных.
Синтаксис
CREATE TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...
partition_column_definition1,partition_column_definition2...])
[partition_desc]
[PROPERTIES ("key" = "value", ...)]
[AS SELECT query]
[LIKE [database.]<source_table_name>]
Параметры
column_definition
Синтаксис column_definition следующий:
col_name col_type [COMMENT 'comment']
В следующей таблице описаны параметры.
| Параметр | Описание |
|---|---|
| col_name | Имя столбца. |
| col_type | Тип данных столбца. Поддерживаются следующие типы данных: TINYINT, SMALLINT, INT, BIGINT, FLOAT, DOUBLE, DECIMAL, DATE, DATETIME, CHAR, VARCHAR[(length)], ARRAY, MAP и STRUCT. Типы данных LARGEINT, HLL и BITMAP не поддерживаются. |
ПРИМЕЧАНИЕ
Все не-partition столбцы должны использовать
NULLв качестве значения по умолчанию. Это означает, что вы должны указатьDEFAULT "NULL"для каждого из не-partition столбцов в инструкции создания таблицы. Кроме того, partition столбцы должны быть определены после не-partition столбцов и не могут использоватьNULLв качестве значения по умолчанию.
partition_desc
Синтаксис partition_desc следующий:
PARTITION BY (par_col1[, par_col2...])
В настоящее время Selena поддерживает только identity transforms, что означает, что Selena создает partition для каждого уникального значения partition.
ПРИМЕЧАНИЕ
Partition столбцы должны быть определены после не-partition столбцов. Partition столбцы поддерживают все типы данных, за исключением FLOAT, DOUBLE, DECIMAL и DATETIME, и не могут использовать
NULLв качестве значения по умолчанию. Кроме того, последовательность partition столбцов, объявленных вpartition_desc, должна соответствовать последовательности столбцов, определенных вcolumn_definition.
PROPERTIES
Вы можете указать атрибуты таблицы в формате "key" = "value" в properties.
В следующей таблице описано несколько ключевых свойств.
| Свойство | Описание |
|---|---|
| location | Путь к файлу, в котором вы хотите создать управляемую таблицу. Когда вы используете HMS в качестве metastore, вам не нужно указывать параметр location, потому что Selena создаст таблицу в пути к файлу по умолчанию текущего Hive catalog. Когда вы используете AWS Glue в качестве службы метаданных:
|
| file_format | Формат файла управляемой таблицы. Поддерживаемые форматы файлов: Parquet, ORC и Textfile. Форматы ORC и Textfile поддерживаются начиная с версии v1.5.2. Допустимые значения: parquet, orc и textfile. Значение по умолчанию: parquet. |
| compression_codec | Алгоритм сжатия, используемый для управляемой таблицы. |
Примеры
Следующие DDL используют формат файла Parquet по умолчанию в качестве примера.
-
Создайте не-партиционированн�ую таблицу с именем
unpartition_tbl. Таблица состоит из двух столбцов,idиscore, как показано ниже:CREATE TABLE unpartition_tbl
(
id int,
score double
); -
Создайте партиционированную таблицу с именем
partition_tbl_1. Таблица состоит из трех столбцов,action,idиdt, из которыхidиdtопределены как partition столбцы, как показано ниже:CREATE TABLE partition_tbl_1
(
action varchar(20),
id int,
dt date
)
PARTITION BY (id,dt); -
Запросите существующую таблицу с именем
partition_tbl_1и создайте партиционированную таблицу с именемpartition_tbl_2на основе результата запросаpartition_tbl_1. Дляpartition_tbl_2idиdtопределены как partition столбцы, как показано ниже:CREATE TABLE partition_tbl_2
PARTITION BY (k1, k2)
AS SELECT * from partition_tbl_1;
Загрузка данных в таблицу Hive
Подобно внутренним таблицам Selena, если у вас есть привилегия INSERT на таблицу Hive (которая может быть управляемой таблицей или внешней таблицей), вы можете использовать инструкцию INSERT для загрузки данных из таблицы Selena в эту таблицу Hive.
Эта функция поддерживается с версии v1.5.2, в которой данные могут быть загружены только в таблицы Hive в формате Parquet. Начин�ая с версии v1.5.2, Selena также поддерживает загрузку данных в таблицы Hive в форматах ORC и Textfile.
Обратите внимание, что загрузка данных во внешние таблицы по умолчанию отключена. Чтобы загружать данные во внешние таблицы, вы должны установить системную переменную ENABLE_WRITE_HIVE_EXTERNAL_TABLE в true.
- Вы можете предоставлять и отзывать привилегии с помощью GRANT и REVOKE.
- Вы можете использовать свойство таблицы
compression_codecили системную переменнуюconnector_sink_compression_codecдля указания алгоритма сжатия, используемого при загрузке данных в таблицы Hive. Selena будет приоритетно использовать compression codec, указанный в свойстве таблицы.
Переключитесь на Hive catalog и базу данных в нем, а затем используйте следующий синтаксис для загрузки данных из таблицы Selena в таблицу Hive в формате Parquet в этой базе данных.
Синтаксис
INSERT {INTO | OVERWRITE} <table_name>
[ (column_name [, ...]) ]
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
-- Если вы хотите загрузить данные в указанные partitions, используйте следующий синтаксис:
INSERT {INTO | OVERWRITE} <table_name>
PARTITION (par_col1=<value> [, par_col2=<value>...])
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
ПРИМЕЧАНИЕ
Partition столбцы не допускают значения
NULL. Поэтому вы должны убедиться, что в partition столбцы таблицы Hive не загружаются пустые значения.
Параметры
| Параметр | Описание |
|---|---|
| INTO | Для добавления данных из таблицы Selena в таблицу Hive. |
| OVERWRITE | Для перезаписи существующих данных таблицы Hive данными из таблицы Selena. |
| column_name | Имя целевого столбца, в который вы хотите загрузить данные. Вы можете указать один или несколько столбцов. Если вы указываете несколько столбцов, разделите их запятыми (,). Вы можете указывать только столбцы, которые фактически существуют в таблице Hive, и целевые столбцы, которые вы указываете, должны включать partition столбцы таблицы Hive. Целевые столбцы, которые вы указываете, сопоставляются один к одному в последовательности со столбцами таблицы Selena, независимо от того, какие имена целевых столбцов. Если целевые столбцы не указаны, данные загружаются во все столбцы таблицы Hive. Если не-partition столбец таблицы Selena не может быть сопоставлен ни с одним столбцом таблицы Hive, Selena записывает значение по умолчанию NULL в столбец таблицы Hive. Если инструкция INSERT содержит инструкцию запроса, типы возвращаемых столбцов которой отличаются от типов данных целевых столбцов, Selena выполняет неявное преобразование несоответствующих столбцов. Если преобразование не удается, будет возвращена ошибка синтаксического анализа. |
| expression | Выражение, которое присваивает значения целевому столбцу. |
| DEFAULT | Присваивает значение по умолчанию целевому столбцу. |
| query | Инструкция запроса, результат которой будет загружен в таблицу Hive. Это может быть любая SQL-инструкция, поддерживаемая Selena. |
| PARTITION | Partitions, в которые вы хотите загрузить данные. Вы должны указать все partition столбцы таблицы Hive в этом свойстве. Partition столбцы, которые вы указываете в этом свойстве, могут быть в другой последовательности, чем partition столб�цы, которые вы определили в инструкции создания таблицы. Если вы указываете это свойство, вы не можете указывать свойство column_name. |
Примеры
Следующие DML используют формат файла Parquet по умолчанию в качестве примера.
-
Вставьте три строки данных в таблицу
partition_tbl_1:INSERT INTO partition_tbl_1
VALUES
("buy", 1, "2023-09-01"),
("sell", 2, "2023-09-02"),
("buy", 3, "2023-09-03"); -
Вставьте результат запроса SELECT, который содержит простые вычисления, в таблицу
partition_tbl_1:INSERT INTO partition_tbl_1 (id, action, dt) SELECT 1+1, 'buy', '2023-09-03'; -
Вставьте результат запроса SELECT, который читает данные из таблицы
partition_tbl_1, в ту же таблицу:INSERT INTO partition_tbl_1 SELECT 'buy', 1, date_add(dt, INTERVAL 2 DAY)
FROM partition_tbl_1
WHERE id=1; -
Вставьте результат запроса SELECT в partitions, которые соответствуют двум условиям,
dt='2023-09-01'иid=1, таблицыpartition_tbl_2:INSERT INTO partition_tbl_2 SELECT 'order', 1, '2023-09-01';Или
INSERT INTO partition_tbl_2 partition(dt='2023-09-01',id=1) SELECT 'order'; -
Перезаписать все значения столбца
actionв partitions, которые соответствуют двум условиям,dt='2023-09-01'иid=1, таблицыpartition_tbl_1значениемclose:INSERT OVERWRITE partition_tbl_1 SELECT 'close', 1, '2023-09-01';Или
INSERT OVERWRITE partition_tbl_1 partition(dt='2023-09-01',id=1) SELECT 'close';
Удаление таблицы Hive
Подобно внутренним таблицам Selena, если у вас есть привилегия DROP на таблицу Hive, вы можете использовать инструкцию DROP TABLE для удаления этой таблицы Hive. Эта функция поддерживается начиная с версии v1.5.2. Обратите внимание, что в настоящее время Selena поддерживает удаление только управляемых таблиц Hive.
Когда вы удаляете таблицу Hive, вы должны указать ключевое слово FORCE в инструкции DROP TABLE. После завершения операции путь к файлу таблицы сохраняется, но все данные таблицы в вашем HDFS cluster или облачном хранилище удаляются вместе с таблицей. Будьте осторожны при выполнении этой операции для удаления таблицы Hive.
Переключитесь на Hive catalog и базу данных в нем, а затем используйте следующую инструкцию для удаления таблицы Hive в этой базе данных.
DROP TABLE <table_name> FORCE
Ручное или автоматическое обновление кэша метаданных
Ручное обновление
По умолчанию Selena кэширует метаданные Hive и автоматически обновляет метаданные в асинхронном режиме для повышения производительности. Кроме того, после внесения некоторых изменений схемы или обновлений таблицы в таблицу Hive, вы также можете использовать REFRESH EXTERNAL TABLE для ручного обновления ее метаданных, тем самым гарантируя, что Selena сможет получить актуальные метаданные при первой возможности и сгенерировать соответствующие планы выполнения:
REFRESH EXTERNAL TABLE <table_name> [PARTITION ('partition_name', ...)]
Вам необходимо вручную обновлять метаданные в следующих ситуациях:
-
Файл данных в существующем partition изменяется, например, путем выполнения команды
INSERT OVERWRITE ... PARTITION .... -
Изменения схемы вносятся в таблицу Hive.
-
Существующая таблица Hive удаляется с помощью инструкции DROP, и создается новая таблица Hive с тем же именем, что и удаленная таблица Hive.
-
Вы указали
"enable_cache_list_names" = "true"вPROPERTIESпри создании вашего Hive catalog, и вы хотите запросить новые partitions, которые вы только что создали в вашем Hive cluster.примечаниеНачиная с версии v1.5.2, Selena предоставляет функцию периодического обновления кэша метаданных Hive. Для получения дополнительной информации см. ниже раздел "Периодическое обновление кэша метаданных" этой темы. После включения этой функции Selena обновляет кэш метаданных Hive каждые 10 минут по умолчанию. Поэтому ручное обновление не требуется в большинстве случаев. Вам нужно выполнить ручное обновление только тогда, когда вы хотите немедленно запросить новые partitions после создания новых partitions в вашем Hive cluster.
Обратите внимание, что REFRESH EXTERNAL TABLE обновляет только таблицы и partitions, кэшир�ованные в ваших FE.
Периодическое обновление кэша метаданных
Начиная с версии v1.5.2, Selena может периодически обновлять кэшированные метаданные часто используемых Hive catalogs для восприятия изменений данных. Вы можете настроить обновление кэша метаданных Hive с помощью следующих параметров FE:
| Элемент конфигурации | По умолчанию | Описание |
|---|---|---|
| enable_background_refresh_connector_metadata | true в v1.5.2false в v1.5.2 | Включить ли периодическое обновление кэша метаданных Hive. После включения Selena опрашивает metastore (Hive Metastore или AWS Glue) вашего Hive cluster и обновляет кэшированные метаданные часто используемых Hive catalogs для восприятия изменений данных. true указывает на включение обновления кэша метаданных Hive, а false указывает на отключение. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
| background_refresh_metadata_interval_millis | 600000 (10 минут) | Интервал между двумя последовательными обновлениями кэша метаданных Hive. Единица измерения: миллисекунды. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
| background_refresh_metadata_time_secs_since_last_access_secs | 86400 (24 часа) | Время истечения задачи обновления кэша метаданных Hive. Для Hive catalog, к которому был осуществлен доступ, если к нему не было доступа более указанного времени, Selena прекращает обновление его кэшированных метаданных. Для Hive catalog, к которому не было доступа, Selena не будет обновлять его кэшированные метаданные. Единица измерения: секунды. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
Исп�ользование функции периодического обновления кэша метаданных Hive и политики автоматического асинхронного обновления метаданных вместе значительно ускоряет доступ к данным, снижает нагрузку на чтение из внешних источников данных и повышает производительность запросов.
Приложение: Понимание автоматического асинхронного обновления метаданных
Автоматическое асинхронное обновление - это политика по умолчанию, которую Selena использует для обновления метаданных в Hive catalogs.
По умолчанию (а именно, когда параметры enable_metastore_cache и enable_remote_file_cache оба установлены в true), если запрос попадает в partition таблицы Hive, Selena автоматически кэширует метаданные partition и метаданные базовых файлов данных partition. Кэшированные метаданные обновляются с использованием политики ленивого обновления.
Например, есть таблица Hive с именем table2, которая имеет четыре partitions: p1, p2, p3 и p4. Запрос попадает в p1, и Selena кэширует метаданные p1 и метаданные базовых файлов данных p1. Предположим, что интервалы времени по умолчанию для обновления и отбрасывания кэшированных метаданных следующие:
- Интервал времени (указанный параметром
metastore_cache_refresh_interval_sec) для асинхронного обновления кэшированных метаданныхp1составляет 60 секунд. - Интервал времени (указанный параметром
remote_file_cache_refresh_interval_sec) для асинхронного обновления кэшированных метаданных базовых файлов данныхp1составляет 60 секунд. - Интервал времени (указанный параметром
metastore_cache_ttl_sec) для автоматического отбрасывания кэшированных метаданныхp1составляет 24 часа. - Интервал времени (указанный параметром
remote_file_cache_ttl_sec) для автоматического отбрасывания кэшированных метаданных базовых файлов данныхp1составляет 36 часов.
На следую�щем рисунке показаны интервалы времени на временной шкале для более легкого понимания.
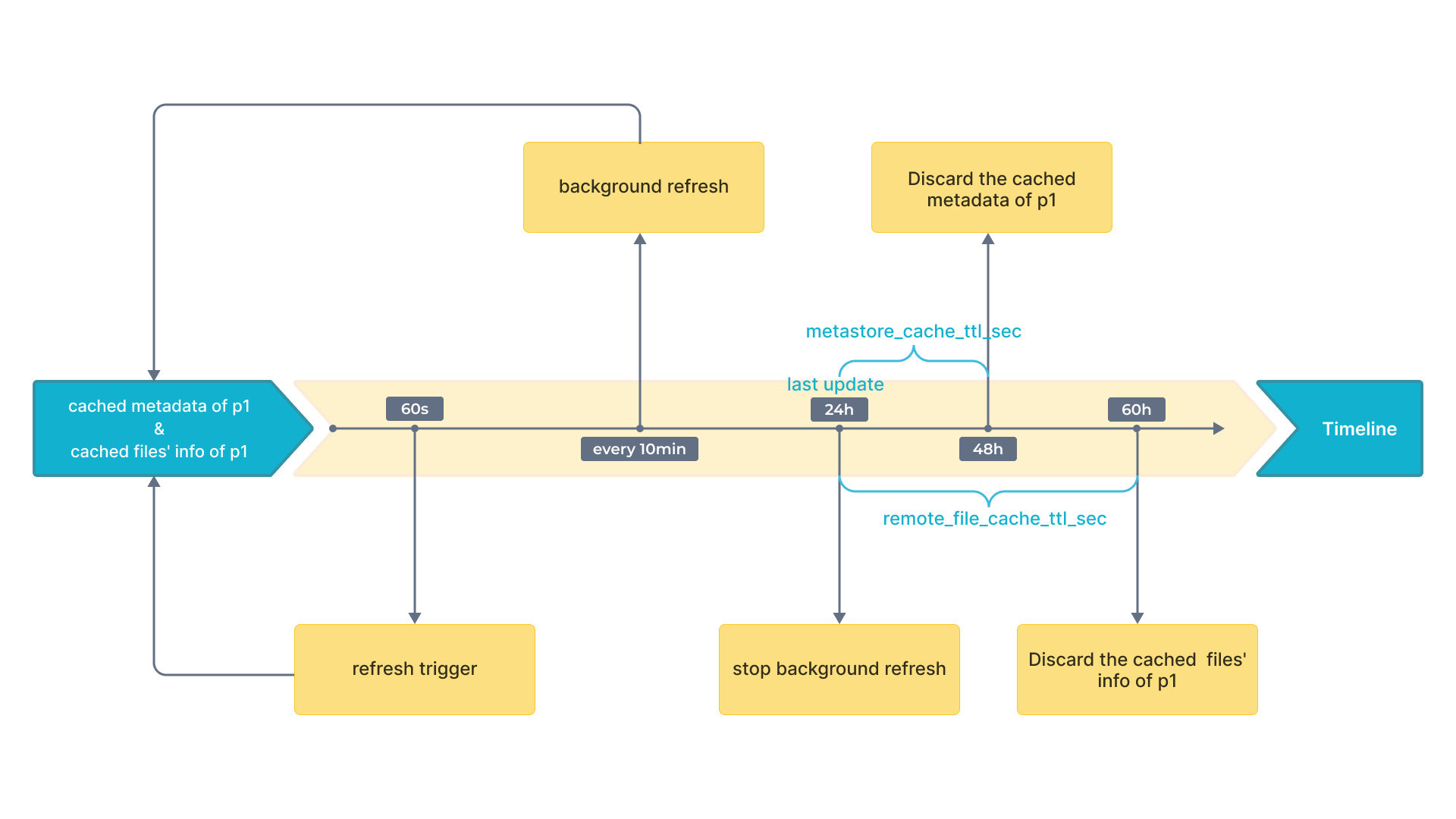
Затем Selena обновляет или отбрасывает метаданные в соответствии со следующими правилами:
- Если другой запрос снова попадает в
p1и текущее время с момента последнего обновления составляет менее 60 секунд, Selena не обновляет кэшированные метаданныеp1или кэшированные метаданные базовых файлов данныхp1. - Если другой запрос снова попадает в
p1и текущее время с момента последнего обновления составляет более 60 секунд, Selena обновляет кэшированные метаданныеp1и кэшированные метаданные базовых файлов данныхp1. - Если к таблице был осуществлен доступ в течение 24 часов, соответствующий кэш будет обновляться каждые 10 минут в фоновом режиме.
- Если к
p1не было доступа в течение 24 часов с момента последнего обновления, Selena отбрасывает кэшированные метаданныеp1. Метаданные будут кэшированы при следующем запросе. - Если к
p1�не было доступа в течение 36 часов с момента последнего обновления, Selena отбрасывает кэшированные метаданные базовых файлов данныхp1. Метаданные будут кэшированы при следующем запросе.