Iceberg catalog
Этот пример использует набор данных Local Climatological Data(LCD), представленный в руководстве Основы Selena. Вы можете загрузить данные и попробовать пример самостоятельно.
Iceberg catalog — это тип external catalog, который поддерживается Selena начиная с версии 1.5.0. С помощью Iceberg catalogs вы можете:
- Напрямую запрашивать данные, хранящиеся в Iceberg, без необходимости вручную создавать таблицы.
- Использовать INSERT INTO или асинхронные материализованные представления (которые поддерживаются начиная с v2.5) для обработки данных, хранящихся в Iceberg, и загрузки данных в Selena.
- Выполнять операции в Selena для создания или удаления баз данных и таблиц Iceberg, или выгружать данные из таблиц Selena в таблицы Iceberg в формате Parquet с помощью INSERT INTO (эта функция поддерживается н�ачиная с v3.1).
Чтобы обеспечить успешное выполнение SQL-запросов в вашем кластере Iceberg, ваш кластер Selena должен иметь доступ к системе хранения и metastore вашего кластера Iceberg. Selena поддерживает следующие системы хранения и metastore:
-
Распределенная файловая система (HDFS) или объектное хранилище, такое как AWS S3, Microsoft Azure Storage, Google GCS или другая S3-совместимая система хранения (например, MinIO)
-
Metastore, такой как Hive metastore, AWS Glue или Tabular
- Если вы выбираете AWS S3 в качестве хранилища, вы можете использовать HMS или AWS Glue в качестве metastore. Если вы выбираете любую другую систему хранения, вы можете использовать только HMS в качестве metastore.
- Если вы выбираете Tabular в к�ачестве metastore, вам необходимо использовать Iceberg REST catalog.
Примечания по использованию
Обратите внимание на следующие моменты при использовании Selena для запроса данных из Iceberg:
| Формат файла | Формат сжатия | Версия таблицы Iceberg |
|---|---|---|
| Parquet | SNAPPY, LZ4, ZSTD, GZIP, и NO_COMPRESSION |
|
| ORC | ZLIB, SNAPPY, LZO, LZ4, ZSTD, и NO_COMPRESSION |
|
Подготовка к интеграции
Перед созданием Iceberg catalog убедитесь, что ваш кластер Selena может интегрироваться с системой хранения и metastore вашего кластера Iceberg.
Хранилище
Выберите вкладку, соответствующую вашему типу хранилища:
- AWS S3
- HDFS
Если ваш кластер Iceberg использует AWS S3 в качестве хранилища или AWS Glue в качестве metastore, выберите подходящий метод аутентификации и выполните необходимые приготовления, чтобы обеспечить доступ вашего кластера Selena к соответствующим облачным ресурсам AWS.
Рекомендуются следующие методы аутентификации:
- Instance profile
- Assumed role
- IAM user
Из вышеупомянутых трех методов аутентификации instance profile используется наиболее широко.
Для получения дополнительной информации см. Подготовка к аутентификации в AWS IAM.
Если вы выбираете HDFS в качестве хранилища, настройте ваш кластер Selena следующим образом:
-
(Опционально) Установите имя пользователя, которое используется для доступа к вашему кластеру HDFS и Hive metastore. По умолчанию Selena использует имя пользователя процессов FE и BE или CN для доступа к вашему кластеру HDFS и Hive metastore. Вы также можете установить имя пользователя, добавив
export HADOOP_USER_NAME="<user_name>"в начало файла fe/conf/hadoop_env.sh каждого FE и в начало файла be/conf/hadoop_env.sh каждого BE или файла cn/conf/hadoop_env.sh каждого CN. После установки имени пользователя в этих файлах перезапустите каждый FE и каждый BE или CN, чтобы настройки параметров вступили в силу. Вы можете установить только одно имя пользователя для каждого кластера Selena. -
При запросе данных Iceberg FE и BE или CN вашего кластера Selena используют клиент HDFS для доступа к вашему кластеру HDFS. В большинстве случаев вам не нужно настраивать ваш кластер Selena для достижения этой цели, и Selena запускает клиент HDFS, используя конфигурации по умолчанию. Вам нужно настроить ваш кластер Selena только в следующих ситуациях:
- Высокая доступность (HA) включена для вашего кластера HDFS: Добавьте файл hdfs-site.xml вашего кластера HDFS в путь $FE_HOME/conf каждого FE и в путь $BE_HOME/conf каждого BE или путь $CN_HOME/conf каждого CN.
- View File System (ViewFs) включена для вашего кластера HDFS: Добавьте файл core-site.xml вашего кластера HDFS в путь $FE_HOME/conf каждого FE и в путь $BE_HOME/conf каждого BE или путь $CN_HOME/conf каждого CN.
Если при отправке запроса возвращается ошибка, указываю�щая на неизвестный хост, вы должны добавить сопоставление между именами хостов и IP-адресами узлов вашего кластера HDFS в путь /etc/hosts.
Аутентификация Kerberos
Если аутентификация Kerberos включена для вашего кластера HDFS или Hive metastore, настройте ваш кластер Selena следующим образом:
- Выполните команду
kinit -kt keytab_path principalна каждом FE и каждом BE или CN, чтобы получить Ticket Granting Ticket (TGT) от Key Distribution Center (KDC). Для выполнения этой команды у вас должны быть разрешения на доступ к вашему кластеру HDFS и Hive metastore. Обратите внимание, что доступ к KDC с помощью этой команды зависит от времени. Поэтому вам нужно использовать cron для периодического выполнения этой команды. - Добавьте
JAVA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf"в файл $FE_HOME/conf/fe.conf каждого FE и в файл $BE_HOME/conf/be.conf каждого BE или файл $CN_HOME/conf/cn.conf каждого CN. В этом примере/etc/krb5.conf— это путь сохранения файла krb5.conf. Вы можете изм�енить путь в соответствии с вашими потребностями.
Создание Iceberg catalog
Синтаксис
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
(
"type" = "iceberg",
MetastoreParams,
StorageCredentialParams,
MetadataUpdateParams
)
Параметры
catalog_name
Имя Iceberg catalog. Соглашения об име�новании следующие:
- Имя может содержать буквы, цифры (0-9) и подчеркивания (_). Оно должно начинаться с буквы.
- Имя чувствительно к регистру и не может превышать 1023 символа в длину.
comment
Описание Iceberg catalog. Этот параметр является опциональным.
type
Тип вашего источника данных. Установите значение iceberg.
MetastoreParams
Набор параметров о том, как Selena интегрируется с metastore вашего источника данных. Выберите вкладку, соответствующую вашему типу metastore:
- Hive metastore
- AWS Glue
- Tabular
Hive metastore
Если вы выбираете Hive metastore в качестве metastore вашего источника данных, настройте MetastoreParams следующим образом:
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "<hive_metastore_uri>"
Перед запросом данных Iceberg вы должны добавить сопоставление между именами хостов и IP-адресами узлов вашего Hive metastore в путь /etc/hosts. В противном случае Selena может не получить доступ к вашему Hive metastore при запуске запроса.
В следующей таблице описан параметр, который вам нужно настроить в MetastoreParams.
iceberg.catalog.type
Обязательный: Да
Описание: Тип metastore, который вы используете для вашего кластера Iceberg. Установите значение hive.
hive.metastore.uris
Обязательный: Да
Описание: URI вашего Hive metastore. Формат: thrift://<metastore_IP_address>:<metastore_port>.
Если высокая доступность (HA) включена для вашего Hive metastore, вы можете указать несколько URI metastore и разделить их запятыми (,), например, "thrift://<metastore_IP_address_1>:<metastore_port_1>,thrift://<metastore_IP_address_2>:<metastore_port_2>,thrift://<metastore_IP_address_3>:<metastore_port_3>".
AWS Glue
Если вы выбираете AWS Glue в качестве metastore вашего источника данных, что поддерживается только при выборе AWS S3 в качестве хранилища, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации на основе instance profile, настройте
MetastoreParamsследующим образом:"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "<aws_glue_region>" -
Чтобы выбрать метод аутентификации на основе assumed role, настройте
MetastoreParamsследующим образом:"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "<iam_role_arn>",
"aws.glue.region" = "<aws_glue_region>" -
Чтобы выбрать метод аутентификации на основе IAM user, настройте
MetastoreParamsследующим образом:"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "<aws_s3_region>"
MetastoreParams для AWS Glue:
iceberg.catalog.type
Обязательный: Да
Описание: Тип metastore, который вы используете для вашего кластера Iceberg. Установите значение glue.
aws.glue.use_instance_profile
Обязательный: Да
Описание: Указывает, следует ли включить метод аутентификации на основе instance profile и метод аутентификации на основе assumed role. Допустимые значения: true и false. Значение по умолчанию: false.
aws.glue.iam_role_arn
Обязательный: Нет Описание: ARN роли IAM, которая имеет привилегии на ваш AWS Glue Data Catalog. Если вы используете метод аутентификации на основе assumed role для доступа к AWS Glue, вы должны указать этот параметр.
aws.glue.region
Обязательный: Да
Описание: Регион, в котором находится ваш AWS Glue Data Catalog. Пример: us-west-1.
aws.glue.access_key
Обязательный: Нет Описание: Ключ доступа вашего пользователя AWS IAM. Если вы используете метод аутентификации на основе IAM user для доступа к AWS Glue, вы должны указать этот параметр.
aws.glue.secret_key
Обязательный: Нет Описание: Секретный ключ вашего пользователя AWS IAM. Если вы используете метод аутентификации на основе IAM user для доступа к AWS Glue, вы должны указать этот параметр.
Для получения информации о том, как выбрать метод аутентификации для доступа к AWS Glue и как настроить политику контроля доступа в консоли AWS IAM, см. Параметры аутентификации для доступа к AWS Glue.
Tabular
Если вы используете Tabular в качестве metastore, вы должны указать тип metastore как REST ("iceberg.catalog.type" = "rest"). Настройте MetastoreParams следующим образом:
"iceberg.catalog.type" = "rest",
"iceberg.catalog.uri" = "<rest_server_api_endpoint>",
"iceberg.catalog.credential" = "<credential>",
"iceberg.catalog.warehouse" = "<identifier_or_path_to_warehouse>"
MetastoreParams для Tabular:
iceberg.catalog.type
Обязательный: Да
Описание: Тип metastore, который вы используете для вашего кластера Iceberg. Установите значение rest.
iceberg.catalog.uri
Обязательный: Да
Описание: URI конечной точки сервиса Tabular. Пример: https://api.tabular.io/ws.
iceberg.catalog.credential
Обязательный: Да Описание: Информация аутентификации сервиса Tabular.
iceberg.catalog.warehouse
Обязательный: Нет
Описание: Местоположение или идентификатор хранилища Iceberg catalog. Пример: s3://my_bucket/warehouse_location или sandbox.
Следующий пример создает Iceberg catalog с именем tabular, который использует Tabular в качестве metastore:
CREATE EXTERNAL CATALOG tabular
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "rest",
"iceberg.catalog.uri" = "https://api.tabular.io/ws",
"iceberg.catalog.credential" = "t-5Ii8e3FIbT9m0:aaaa-3bbbbbbbbbbbbbbbbbbb",
"iceberg.catalog.warehouse" = "sandbox"
);
StorageCredentialParams
Набор параметров о том, как Selena интегрируется с вашей системой хранения. Этот набор параметров является опциональным.
Обратите внимание на следующие моменты:
-
Если вы используете HDFS в качестве хранилища, вам не нужно настраивать
StorageCredentialParamsи можете пропустить этот раздел. Если вы используете AWS S3, другую S3-совместимую систему хранения, Microsoft Azure Storage или Google GCS в качестве хранилища, вы должны настроитьStorageCredentialParams. -
Если вы используете Tabular в качестве metastore, вам не нужно настраивать
StorageCredentialParamsи можете пропустить этот раздел. Если вы используете HMS или AWS Glue в качестве metastore, вы должны настроитьStorageCredentialParams.
Выберите вкладку, соответствующую вашему типу хранилища:
- AWS S3
- HDFS
- MinIO
- Microsoft Azure Blob Storage
- Google GCS
AWS S3
Если вы выбираете AWS S3 в качестве хранилища для вашего кластера Iceberg, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации на основе instance profile, настройте
StorageCredentialParamsследующим образом:"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
Чтобы выбрать метод аутентификации на основе assumed role, настройте
StorageCredentialParamsследующим образом:"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
Чтобы выбрать метод аутентификации на основе IAM user, настройте
StorageCredentialParamsследующим образом:"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
StorageCredentialParams для AWS S3:
aws.s3.use_instance_profile
Обязательный: Да
Описание: Указывает, следует ли включить метод аутентификации на основе instance profile и метод аутентификации на основе assumed role. Допустимые значения: true и false. Значение по умолчанию: false.
aws.s3.iam_role_arn
Обязательный: Нет Описание: ARN роли IAM, которая имеет привилегии на ваш bucket AWS S3. Если вы используете метод аутентификации на основе assumed role для доступа к AWS S3, вы должны указать этот параметр.
aws.s3.region
Обязательный: Да
Описание: Регион, в котором находится ваш bucket AWS S3. Пример: us-west-1.
aws.s3.access_key
Обязательный: Нет Описание: Ключ доступа вашего пользователя IAM. Если вы используете метод аутентификации на основе IAM user для доступа к AWS S3, вы должны указать этот параметр.
aws.s3.secret_key
Обязательный: Нет Описание: Секретный ключ вашего пользователя IAM. Если вы используете метод аутентификации на основе IAM user для доступа к AWS S3, вы должны указать этот параметр.
Для получения информации о том, как выбрать метод аутентификации для доступа к AWS S3 и как настроить политику контроля доступа в консоли AWS IAM, см. Параметры аутентификации для доступа к AWS S3.
При использовании хранилища HDFS пропустите учетные данные хранилища.
S3-совместимая система хранения
Iceberg catalogs поддерживают S3-совместимые системы хранения начиная с v2.5.
Если вы выбираете S3-совместимую систему хранения, такую как MinIO, в качестве хранилища для вашего кластера Iceberg, настройте StorageCredentialParams следующим образом для обеспечения успешной интеграции:
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
StorageCredentialParams для MinIO и других S3-совместимых систем:
aws.s3.enable_ssl
Обязательный: Да
Описание: Указывает, следует ли включить SSL-соединение.
Допустимые значения: true и false. Значение по умолчанию: true.
aws.s3.enable_path_style_access
Обязательный: Да
Описание: Указывает, следует ли включить доступ в стиле пути.
Допустимые значения: true и false. Значение по умолчанию: false. Для MinIO вы должны установить значение true.
URL в стиле пути используют следующий формат: https://s3.<region_code>.amazonaws.com/<bucket_name>/<key_name>. Например, если вы создаете bucket с именем DOC-EXAMPLE-BUCKET1 в регионе US West (Oregon) и хотите получить доступ к объекту alice.jpg в этом bucket, вы можете использовать следующий URL в стиле пути: https://s3.us-west-2.amazonaws.com/DOC-EXAMPLE-BUCKET1/alice.jpg.
aws.s3.endpoint
Обязательный: Да Описание: Конечная точка, которая используется для подключения к вашей S3-совместимой системе хранения вместо AWS S3.
aws.s3.access_key
Обязательный: Да Описание: Ключ доступа вашего пользователя IAM.
aws.s3.secret_key
Обязательный: Да Описание: Секретный ключ вашего пользователя IAM.
Microsoft Azure Storage
Iceberg catalogs поддерживают Microsoft Azure Storage начиная с v3.0.
Azure Blob Storage
Если вы выбираете Blob Storage в качестве хранилища для вашего кластера Iceberg, выполните одно из следующих действий:
-
Что�бы выбрать метод аутентификации Shared Key, настройте
StorageCredentialParamsследующим образом:"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.shared_key" = "<storage_account_shared_key>" -
Чтобы выбрать метод аутентификации SAS Token, настройте
StorageCredentialParamsследующим образом:"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.container" = "<container_name>",
"azure.blob.sas_token" = "<storage_account_SAS_token>"
StorageCredentialParams для Microsoft Azure:
azure.blob.storage_account
Обязательный: Да Описание: Имя пользователя вашей учетной записи Blob Storage.
azure.blob.shared_key
Обязательный: Да Описание: Общий ключ вашей учетной записи Blob Storage.
azure.blob.account_name
Обязательный: Да Описание: Имя пользователя вашей учетной записи Blob Storage.
azure.blob.container
Обязательный: Да Описание: Имя контейнера blob, который хранит ваши данные.
azure.blob.sas_token
Обязательный: Да Описание: SAS-токен, который используется для доступа к вашей учетной записи Blob Storage.
Azure Data Lake Storage Gen1
Если вы выбираете Data Lake Storage Gen1 в качестве хранилища для вашего кластера Iceberg, выпо�лните одно из следующих действий:
-
Чтобы выбрать метод аутентификации Managed Service Identity, настройте
StorageCredentialParamsследующим образом:"azure.adls1.use_managed_service_identity" = "true"
Или:
-
Чтобы выбрать метод аутентификации Service Principal, настройте
StorageCredentialParamsследующим образом:"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
Azure Data Lake Storage Gen2
Если вы выбираете Data Lake Storage Gen2 в качестве хранилища для вашего кластера Iceberg, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации Managed Identity, настройте
StorageCredentialParamsследующим образом:"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"Или:
-
Чтобы выбрать метод аутентификации Shared Key, настройте
StorageCredentialParamsследующим образом:"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<storage_account_shared_key>"Или:
-
Чтобы выбрать метод аутентификации Service Principal, настройте
StorageCredentialParamsследующим образом:"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
Google GCS
Iceberg catalogs поддерживают Google GCS начиная с v3.0.
Если вы выбираете Google GCS в качестве хранилища для вашего кластера Iceberg, выполните одно из следующих действий:
-
Чтобы выбрать метод аутентификации на основе VM, настройте
StorageCredentialParamsследующим образом:"gcp.gcs.use_compute_engine_service_account" = "true" -
Чтобы выбрать метод аутентификации на основе service account, настройте
StorageCredentialParamsследующим образом:"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>" -
Чтобы выбрать метод аутентификации на основе impersonation, настройте
StorageCredentialParamsследующим образом:-
Заставить экземпляр VM выдавать себя за service account:
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>" -
Заставить service account (временно названный meta service account) выдавать себя за другой service account (временно названный data service account):
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
-
StorageCredentialParams для Google GCS:
gcp.gcs.service_account_email
Значение по умолчанию: "" Пример: "user@hello.iam.gserviceaccount.com" Описание: Адрес электронной почты в JSON-файле, созданном при создании service account.
gcp.gcs.service_account_private_key_id
Значение по умолчанию: "" Пример: "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" Описание: ID приватного ключа в JSON-файле, созданном при создании service account.
gcp.gcs.service_account_private_key
Значени�е по умолчанию: ""
Пример: "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n"
Описание: Приватный ключ в JSON-файле, созданном при создании service account.
gcp.gcs.impersonation_service_account
Значение по умолчанию: ""
Пример: "hello"
Описание: Service account, за который вы хотите выдавать себя.
MetadataUpdateParams
Набор параметров о том, как Selena обновляет кэш метаданных Iceberg. Этот набор параметров является опциональным.
Начиная с v3.3.3, Selena поддерживает стратегию периодического обновления метаданных. В большинстве случаев вы можете игнорировать MetadataUpdateParams и не настраивать параметры политики в нем, поскольку значения по умолчанию этих параметров уже обеспечивают готовую к использованию производительность. Вы можете настроить режи�м парсинга метаданных Iceberg, используя системную переменную plan_mode.
| Параметр | По умолчанию | Описание |
|---|---|---|
| enable_iceberg_metadata_cache | true | Следует ли кэшировать метаданные, связанные с Iceberg, включая Table Cache, Partition Name Cache и Data File Cache и Delete Data File Cache в Manifest. |
| iceberg_manifest_cache_with_column_statistics | false | Следует ли кэшировать статистику столбцов. |
| iceberg_manifest_cache_max_num | 100000 | Максимальное количество файлов Manifest, которые могут быть кэшированы. |
| refresh_iceberg_manifest_min_length | 2 * 1024 * 1024 | Минимальная длина файла Manifest, которая запускает обновление Data File Cache. |
Примеры
Следующие примеры создают Iceberg catalog с именем iceberg_catalog_hms или iceberg_catalog_glue, в зависимости от типа metastore, который вы используете, для запроса данных из вашего кластера Iceberg. Выберите вкладку, соответствующую вашему типу хранилища:
- AWS S3
- HDFS
- MinIO
- Microsoft Azure Blob Storage
- Google GCS
AWS S3
Если вы выбираете учетные данные на основе instance profile
-
Если вы используете Hive metastore в вашем кластере Iceberg, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
); -
Если вы используете AWS Glue в вашем кластере Amazon EMR Iceberg, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_glue
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
);
Если вы выбираете учетные данные на основе assumed role
-
Если вы используете Hive metastore в вашем кластере Iceberg, выпол�ните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
); -
Если вы используете AWS Glue в вашем кластере Amazon EMR Iceberg, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_glue
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "arn:aws:iam::081976408565:role/test_glue_role",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
);
Если вы выбираете учетные данные на основе IAM user
-
Если вы используете Hive metastore в вашем кластере Iceberg, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_access_key>",
"aws.s3.region" = "us-west-2"
); -
Если вы используете AWS Glue в вашем кластере Amazon EMR Iceberg, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_glue
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "us-west-2"
);
HDFS
Если вы используете HDFS в качестве хранилища, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
S3-совместимая система хранения
Используйте MinIO в качестве примера. Выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.enable_ssl" = "true",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
Microsoft Azure Storage
Azure Blob Storage
-
Если вы выбираете метод аутентификации Shared Key, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
); -
Если вы выбираете метод аутентификации SAS Token, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.container" = "<blob_container_name>",
"azure.blob.sas_token" = "<blob_storage_account_SAS_token>"
);
Azure Data Lake Storage Gen1
-
Если вы выбираете метод аутентификации Managed Service Identity, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.use_managed_service_identity" = "true"
); -
Если вы выбираете метод аутентификации Service Principal, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
);
Azure Data Lake Storage Gen2
-
Если вы выбираете метод аутентификации Managed Identity, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"
); -
Если вы выбираете метод аутентификации Shared Key, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<shared_key>"
); -
Если вы выбираете метод ау�тентификации Service Principal, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
);
Google GCS
-
Если вы выбираете метод аутентификации на основе VM, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true"
); -
Если вы выбираете метод аутентификации на основе service account, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"
); -
Если вы выбираете метод аутентификации на основе impersonation:
-
Если вы заставляете экземпляр VM выдавать себя за service account, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"
); -
Если вы заставляете service account выдавать себя за другой service account, выполните команду, подобную приведенной ниже:
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
);
-
Использование вашего catalog
Просмотр Iceberg catalogs
Вы можете использовать SHOW CATALOGS для запроса всех catalogs в текущем кластере Selena:
SHOW CATALOGS;
Вы также можете использовать SHOW CREATE CATALOG для запроса оператора создания external catalog. Следующий пример запрашивает оператор создания Iceberg catalog с именем iceberg_catalog_glue:
SHOW CREATE CATALOG iceberg_catalog_glue;
Переключение на Iceberg Catalog и базу данных в нем
Вы можете использовать один из следующих методов для переключения на Iceberg catalog и базу данных в нем:
-
Используйте SET CATALOG для указания Iceberg catalog в текущей сессии, а затем используйте USE для указания активной базы данных:
-- Переключиться на указанный catalog в текущей сессии:
SET CATALOG <catalog_name>
-- Указать активную базу данных в текущей сессии:
USE <db_name> -
Напрямую используйте USE для переключения на Iceberg catalog и базу данных в нем:
USE <catalog_name>.<db_name>
Удаление Iceberg catalog
Вы можете использовать DROP CATALOG для удаления external catalog.
Следующий пример удаляет Iceberg catalog с именем iceberg_catalog_glue:
DROP Catalog iceberg_catalog_glue;
Просмотр схемы таблицы Iceberg
Вы можете использовать один из следующих синтаксисов для просмотра схемы таблицы Iceberg:
-
Просмотр схемы
DESC[RIBE] <catalog_name>.<database_name>.<table_name> -
Просмотр схемы и местоположения из оператора CREATE
SHOW CREATE TABLE <catalog_name>.<database_name>.<table_name>
Запрос таблицы Iceberg
-
Используйте SHOW DATABASES для просмотра баз данных в вашем кластере Iceberg:
SHOW DATABASES FROM <catalog_name> -
Используйте SELECT для запроса целевой таблицы в указанной базе данных:
SELECT count(*) FROM <table_name> LIMIT 10
Создание базы данных Iceberg
Аналогично внутреннему catalog Selena, если у вас есть привилегия CREATE DATABASE на Iceberg catalog, вы можете использовать оператор CREATE DATABASE для создания баз данных в этом Iceberg catalog. Эта функция поддерживается начиная с v3.1.
Переключитесь на Iceberg catalog, а затем используйте следующий оператор для создания базы данных Iceberg в этом catalog:
CREATE DATABASE <database_name>
[PROPERTIES ("location" = "<prefix>://<path_to_database>/<database_name.db>/")]
Вы можете использовать параметр location для указания пути к файлу, в котором вы хотите создать базу данных. Поддерживаются как HDFS, так и облачное хранилище. Если вы не указываете параметр location, Selena создает базу данных в пути к файлу по умолчанию Iceberg catalog.
prefix варьируется в зависимости от используемой вами системы хранения:
HDFS
Значение Prefix: hdfs
Google GCS
Значение Prefix: gs
Azure Blob Storage
Значение Prefix:
- Если ваша учетная запись хранения разрешает доступ по HTTP,
prefix— этоwasb. - Если ваша учетная запись хранения разрешает доступ по HTTPS,
prefix— этоwasbs.
Azure Data Lake Storage Gen1
Значение Prefix: adl
Azure Data Lake Storage Gen2
Значение Prefix:
- Если ваша учетная запись хранения разрешает доступ по HTTP,
prefix— этоabfs. - Если ваша учетная запись хранения разрешает доступ по HTTPS,
prefix— этоabfss.
AWS S3 или другое S3-совместимое хранилище (например, MinIO)
Значение Prefix: s3
Удаление базы данных Iceberg
Аналогично внутренним базам данных Selena, если у вас есть привилегия DROP на базу данных Iceberg, вы можете использовать оператор DROP DATABASE для удаления этой базы данных Iceberg. Эта функция поддерживается начиная с v3.1. Вы можете удалять только пустые базы данных.
При удалении базы данных Iceberg путь к файлу базы данных в вашем кластере HDFS или облачном хранилище не будет удален вместе с базой данных.
Переключитесь на Iceberg catalog, а затем используйте следующий оператор для удаления базы данных Iceberg в этом catalog:
DROP DATABASE <database_name>;
Создание таблицы Iceberg
Аналогично внутренним базам данных Selena, если у вас есть привилегия CREATE TABLE на базу данных Iceberg, вы можете использовать оператор CREATE TABLE или CREATE TABLE AS SELECT для создания таблицы в этой базе данных Iceberg. Эта функция поддерживается начиная с v3.1.
Переключитесь на Iceberg catalog и базу данных в нем, а затем используйте следующий синтаксис для создания таблицы Iceberg в этой базе данных.
Синтаксис
CREATE TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...
partition_column_definition1,partition_column_definition2...])
[partition_desc]
[PROPERTIES ("key" = "value", ...)]
[AS SELECT query]
Параметры
column_definition
Синтаксис column_definition следующий:
col_name col_type [COMMENT 'comment']
Все столбцы, не являющиеся разделами, должны использовать NULL в качестве значения по умолчанию. Это означает, что вы должны указать DEFAULT "NULL" для каждого из столбцов, не являющихся разделами, в операторе создания таблицы. Кроме того, столбцы разделов должны быть определены после столбцов, не являющихся разделами, и не могут использовать NULL в качестве значения по умолчанию.
partition_desc
Синтаксис partition_desc следующий:
PARTITION BY (par_col1[, par_col2...])
В настоящее время Selena поддерживает только identity transforms, что означает, что Selena создает раздел для каждого уникального значения раздела.
Столбцы разделов должны быть определены после столбцов, не являющихся разделами. Столбц�ы разделов поддерживают все типы данных, исключая FLOAT, DOUBLE, DECIMAL и DATETIME, и не могут использовать NULL в качестве значения по умолчанию.
PROPERTIES
Вы можете указать атрибуты таблицы в формате "key" = "value" в PROPERTIES. См. Атрибуты таблицы Iceberg.
В следующей таблице описаны несколько ключевых свойств.
location
Описание: Путь к файлу, в котором вы хотите создать таблицу Iceberg. При использовании HMS в качестве metastore вам не нужно указывать параметр location, поскольку Selena создаст таблицу в пути к файлу по умолчанию текущего Iceberg catalog. При использовании AWS Glue в качестве metastore:
- Если вы указали параметр
locationдля базы данных, в которой вы хотите создать таблицу, вам не нужно указывать параметрlocationдля таблицы. Таким образом, таблица по умолчанию использует путь �к файлу базы данных, к которой она принадлежит. - Если вы не указали
locationдля базы данных, в которой вы хотите создать таблицу, вы должны указать параметрlocationдля таблицы.
file_format
Описание: Формат файла таблицы Iceberg. Поддерживается только формат Parquet. Значение по умолчанию: parquet.
compression_codec
Описание: Алгоритм сжатия, используемый для таблицы Iceberg. Поддерживаемые алгоритмы сжатия: SNAPPY, GZIP, ZSTD и LZ4. Значение по умолчанию: gzip. Это свойство устарело в v3.2.3, начиная с которой версии алгоритм сжатия, используемый для выгрузки данных в таблицы Iceberg, единообразно контролируется переменной сессии connector_sink_compression_codec.
Примеры
-
Создайте неразделенную таблиц�у с именем
unpartition_tbl. Таблица состоит из двух столбцов,idиscore, как показано ниже:CREATE TABLE unpartition_tbl
(
id int,
score double
); -
Создайте разделенную таблицу с именем
partition_tbl_1. Таблица состоит из трех столбцов,action,idиdt, из которыхidиdtопределены как столбцы разделов, как показано ниже:CREATE TABLE partition_tbl_1
(
action varchar(20),
id int,
dt date
)
PARTITION BY (id,dt); -
Запросите существующую таблицу с именем
partition_tbl_1и создайте разделенную таблицу с именемpartition_tbl_2на основе результата запросаpartition_tbl_1. Дляpartition_tbl_2idиdtопределены как столбцы разделов, как показано ниже:CREATE TABLE partition_tbl_2
PARTITION BY (id, dt)
AS SELECT * from employee;
Выгрузка данных в таблицу Iceberg
Аналогично внутренним таблицам Selena, если у вас есть привилегия INSERT на таблицу Iceberg, вы можете использовать оператор INSERT для выгрузки данных таблицы Selena в эту таблицу Iceberg (в настоящее время поддерживаются только таблицы Iceberg в формате Parquet). Эта функция поддерживается начиная с v3.1.
Переключитесь на Iceberg catalog и базу данных в нем, а затем используйте следующий синтаксис для выгрузки данных таблицы Selena в таблицу Iceberg в формате Parquet в этой базе данных.
Синтаксис
INSERT {INTO | OVERWRITE} <table_name>
[ (column_name [, ...]) ]
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
-- Если вы хотите выгрузить данные в указанные разделы, используйте следующий синтаксис:
INSERT {INTO | OVERWRITE} <table_name>
PARTITION (par_col1=<value> [, par_col2=<value>...])
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
Столбцы разделов не допускают значения NULL. Поэтому вы должны убедиться, что никакие пустые значения не загружаются в столбцы разделов таблицы Iceberg.
Параметры
INTO
Для добавления данных таблицы Selena к таблице Iceberg.
OVERWRITE
Для перезаписи существующих данных таблицы Iceberg данными таблицы Selena.
column_name
Имя целевого столбца, в который вы хотите загрузить данные. Вы можете указать один или несколько столбцов. Если вы указываете несколько столбцов, разделите их запятыми (,). Вы можете указывать только столбцы, которые фактически существуют в таблице Iceberg, и целевые столбцы, которые вы указываете, должны включать столбцы разделов таблицы Iceberg. Целевые столбцы, которые вы указываете, сопоставляются один к одному в последовательности со столбцами таблицы Selena, независимо от того, какие имена целевых столбцов. Если целевые столбцы не указаны, данные загружаются во все столбцы таблицы Iceberg. Если столбец таблицы Selena, не являющийся разделом, не может быть сопоставлен ни с одним столбцом таблицы Iceberg, Selena записывает значение по умолчанию NULL в столбец таблицы Iceberg. Если оператор INSERT содержит оператор запроса, возвращаемые типы столбцов которого отличаются от типов данных целевых столбцов, Selena выполняет неявное преобразование несовпадающих столбцов. Если преобразование не удается, будет возвращена ошибка синтаксического анализа.
expression
Выражение, которое присваивает значения целевому столбцу.
DEFAULT
Присваивает значение по умолчанию целевому столбцу.
query
Оператор запроса, результат которого будет загружен в таблицу Iceberg. Это может быть любой SQL-оператор, поддерживаемый Selena.
PARTITION
Разделы, в которые вы хотите загрузить данные. Вы должны указать все столбцы разделов таблицы Iceberg в этом свойстве. Столбцы разделов, которые вы указываете в этом свойстве, могут быть в другой последовательности, чем столбцы разделов, которые вы определили в операторе создания таблицы. Если вы указываете это свойство, вы не можете указать свойство column_name.
Примеры
-
Вставьте три строки данных в таблицу
partition_tbl_1:INSERT INTO partition_tbl_1
VALUES
("buy", 1, "2023-09-01"),
("sell", 2, "2023-09-02"),
("buy", 3, "2023-09-03"); -
Вставьте результат запроса SELECT, который содержит простые вычисления, в таблицу
partition_tbl_1:INSERT INTO partition_tbl_1 (id, action, dt) SELECT 1+1, 'buy', '2023-09-03'; -
Вставьте результат запроса SELECT, который читает данные из таблицы
partition_tbl_1, в ту же таблицу:INSERT INTO partition_tbl_1 SELECT 'buy', 1, date_add(dt, INTERVAL 2 DAY)
FROM partition_tbl_1
WHERE id=1; -
Вставьте результат запроса SELECT в разделы, которые соответствуют двум условиям,
dt='2023-09-01'иid=1, таблицыpartition_tbl_2:INSERT INTO partition_tbl_2 SELECT 'order', 1, '2023-09-01';Или
INSERT INTO partition_tbl_2 partition(dt='2023-09-01',id=1) SELECT 'order'; -
Перезапишите все значения столбца
actionв разделах, которые соответствуют двум условиям,dt='2023-09-01'иid=1, таблицыpartition_tbl_1наclose:INSERT OVERWRITE partition_tbl_1 SELECT 'close', 1, '2023-09-01';Или
INSERT OVERWRITE partition_tbl_1 partition(dt='2023-09-01',id=1) SELECT 'close';
Удаление таблицы Iceberg
Аналогично внутренним таблицам Selena, если у вас есть привилегия DROP на таблицу Iceberg, вы можете использовать оператор DROP TABLE для удаления этой таблицы Iceberg. Эта функция поддерживается начиная с v3.1.
При удалени�и таблицы Iceberg путь к файлу таблицы и данные в вашем кластере HDFS или облачном хранилище не будут удалены вместе с таблицей.
При принудительном удалении таблицы Iceberg (а именно, с ключевым словом FORCE, указанным в операторе DROP TABLE), данные таблицы в вашем кластере HDFS или облачном хранилище будут удалены вместе с таблицей, но путь к файлу таблицы сохраняется.
Переключитесь на Iceberg catalog и базу данных в нем, а затем используйте следующий оператор для удаления таблицы Iceberg в этой базе данных.
DROP TABLE <table_name> [FORCE];
Настройка кэширования метаданных
Файлы метаданных вашего кластера Iceberg могут храниться в удаленном хранилище, таком как AWS S3 или HDFS. По умолчанию Selena кэширует метаданные Iceberg в памяти. Для ускорения запросов Selena использует двухуровневый механизм кэширования метаданных, с помощью которого она может кэшировать метаданные как в памяти, так и на диске. Для каждого первоначального запроса Selena кэширует результаты их вычислений. Если выдается любой последующий запрос, который семантически эквивалентен предыдущему запросу, Selena сначала пытается получить запрошенные метаданные из своих кэшей, и она получает метаданные из удаленного хранилища только тогда, когда метаданные не могут быть найдены в ее кэшах.
Selena использует алгоритм Least Recently Used (LRU) для кэширования и вытеснения данных. Основные правила следующие:
- Selena сначала пытается получить запрошенные метаданные из памяти. Если метаданные не могут быть найдены в памяти, Selena пытается получить метаданные с дисков. Метаданные, которые Selena получила с дисков, будут загружены в память. Если метаданные не могут быть найдены и на дисках, Selena получает метаданные из удаленного хранилища и кэширует полученные метаданные в памяти.
- Selena записывает метаданные, вытесненные из памяти, на диски, но она напрямую отбрасывает метаданные, вытесненные с дисков.
Начиная с v3.3.3, Selena поддерживает стратегию периодического обновления метаданных. Вы можете настроить план кэширования метаданных Iceberg, используя системную переменную plan_mode.
Конфигурации FE для кэширования метаданных Iceberg
enable_iceberg_metadata_disk_cache
- Единица: Н/Д
- Значение по умолчанию:
false - Описание: Указывает, следует ли включить дисковый кэш.
iceberg_metadata_cache_disk_path
- Единица: Н/Д
- Значение по умолчанию:
StarRocksFE.STARROCKS_HOME_DIR + "/caches/iceberg" - Описание: Путь сохранения кэшированных файлов метаданных на диске.
iceberg_metadata_disk_cache_capacity
- Единица: Байты
- Значение по умолчанию:
2147483648, эквивалентно 2 ГБ - Описание: Максимальный размер кэшированных метаданных, разрешенный на диске.
iceberg_metadata_memory_cache_capacity
- Единица: Байты
- Значение по умолчанию:
536870912, эквивалентно 512 МБ - Описание: Максимальный размер кэшированных метаданных, разрешенный в памяти.
iceberg_metadata_memory_cache_expiration_seconds
- Единица: Секунды
- Значение по умолчанию:
86500 - Описание: Количество времени, после которого запись кэша в памяти истекает, считая с момента ее последнего доступа.
iceberg_metadata_disk_cache_expiration_seconds
- Единица: Секунды
- Значение по умолчанию:
604800, эквивалентно одной неделе - Описание: Количество времени, после которого запись кэша на диске истекает, считая с момента ее последнего доступа.
iceberg_metadata_cache_max_entry_size
- Единица: Байты
- Значение по умолчанию:
8388608, эквивалентно 8 МБ - Описание: Максимальный размер файла, который может быть кэширован. Файлы, размер которых превышает значение этого параметра, не могут быть кэшированы. Если запрос запрашивает эти файлы, Selena получает их из удаленного хранилища.
enable_background_refresh_connector_metadata
- Единица: -
- Значение по умолчанию: true
- Описание: Следует ли включить периодическое обновление кэша метаданных Iceberg. После включения Selena опрашивает metastore (Hive Metastore или AWS Glue) вашего кластера Iceberg и обновляет кэшированные метаданные часто используемых Iceberg catalogs для восприятия изменений данных.
trueуказывает на включение обновления кэша метаданных Iceberg, аfalseуказывает на его отключение.
background_refresh_metadata_interval_millis
- Единица: Миллисекунда
- Значение по умолчанию: 600000
- Описание: Интервал между двумя последовательными обновлениями кэша метаданных Iceberg. - Единица: миллисекунда.
background_refresh_metadata_time_secs_since_last_access_sec
- Единица: Секунда
- Значение по умолчанию: 86400
- Описание: Время истечения задачи обновления кэша метаданных Iceberg. Для Iceberg catalog, к которому был осуществлен доступ, если к нему не было доступа более указанного времени, Selena прекращает обновление его кэшированных метад�анных. Для Iceberg catalog, к которому не было доступа, Selena не будет обновлять его кэшированные метаданные.
Приложение A: Стратегия периодического обновления метаданных
Iceberg поддерживает снимки начиная с v3.4. С новейшим снимком вы можете получить новейший результат. Поэтому только кэшированные снимки могут влиять на свежесть данных. В результате вам нужно обращать внимание только на стратегию обновления кэша, который содержит снимок.
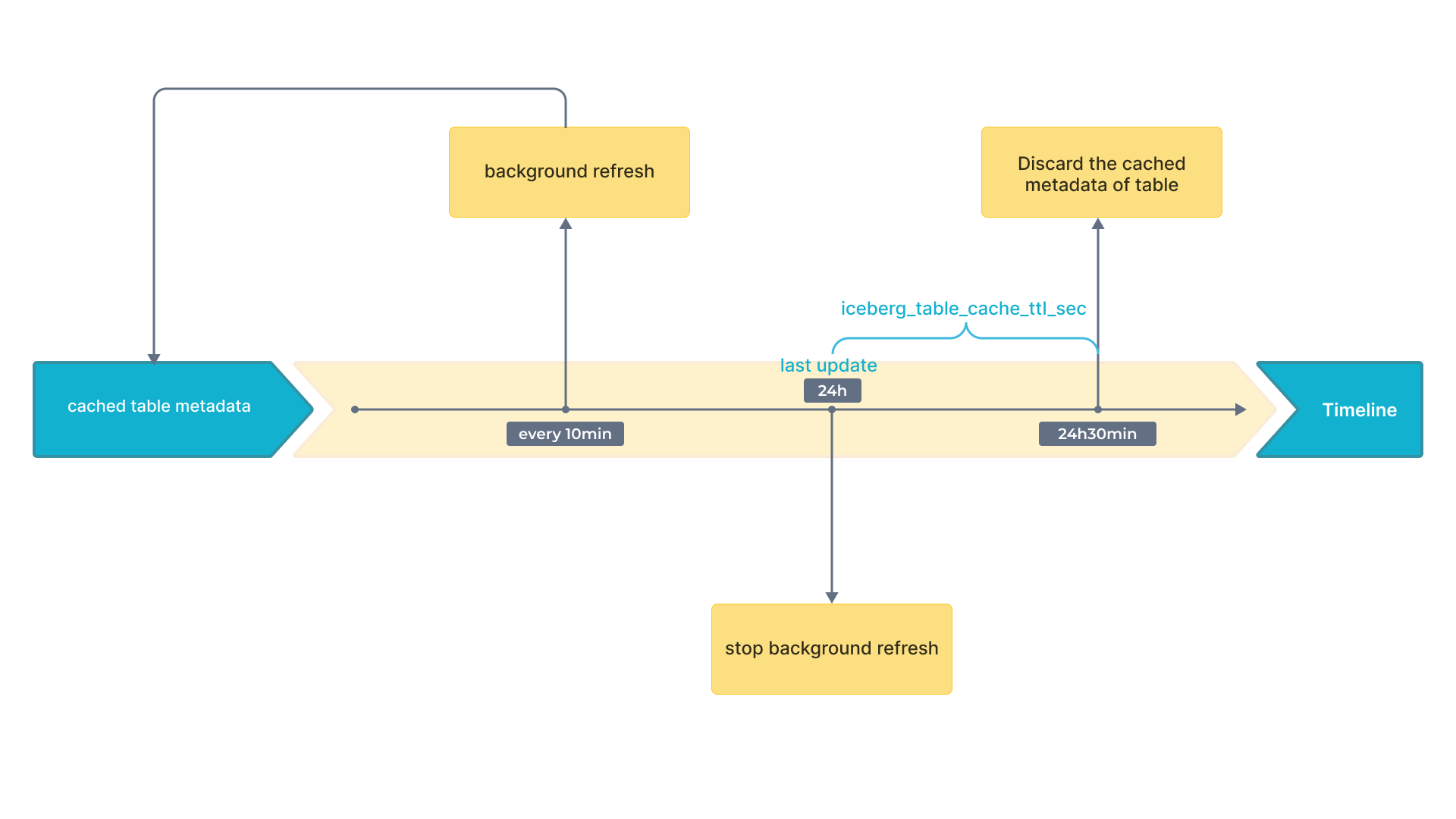
Следующая блок-схема показывает временные интервалы на временной шкале.
Приложение B: Парсинг файлов метаданных
-
Распределенный план для большого объема метаданных
Для эффективной обработки большого объема метаданных Selena использует распределенный подход, используя несколько узлов BE и CN. Этот метод использует возможности параллельных вычислений современных движков запросов, которые могут распределять задачи, такие как чтение, декомпрессия и фильтрация файлов manifest, по нескольким узлам. Обрабатывая эти файлы manifest параллельно, время, необходимое для получения метаданных, значительно сокращается, что приводит к более быстрому планированию заданий. Это особенно полезно для больших запросов, включающих множество файлов manifest, поскольку устраняет узкие места в одной точке и повышает общую эффективность выполнения запросов.
-
Локальный план для небольшого объема метаданных
Для меньших запросов, где повторная декомпрессия и парсинг файлов manifest могут вносить ненужные задержки, используется дру�гая стратегия. Selena кэширует десериализованные объекты памяти, особенно файлы Avro, для решения этой проблемы. Сохраняя эти десериализованные файлы в памяти, система может обойти этапы декомпрессии и парсинга для последующих запросов. Этот механизм кэширования позволяет прямой доступ к необходимым метаданным, значительно сокращая время получения. В результате система становится более отзывчивой и лучше подходит для удовлетворения высоких требований к запросам и потребностей перезаписи материализованных представлений.
-
Адаптивная стратегия получения метаданных (По умолчанию)
Selena разработана для автоматического выбора подходящего метода получения метаданных на основе различных факторов, включая количество узлов FE и BE/CN, количество их ядер CPU и количество файлов manifest, необходимых для текущего запроса. Этот адаптивный подход обеспечивает динамическую оптимизацию получения метаданных системой без необходимости ручной настройки параметров, связанных с метаданными. Таким образом, Selena обеспечивает бесшовный опыт, балансируя между распределенными и локальными планами для дос�тижения оптимальной производительности запросов в различных условиях.
Вы можете настроить план кэширования метаданных Iceberg, используя системную переменную plan_mode.