Поддержка функций: аналитика Data Lake
Начиная с версии v1.5.2, Selena поддерживает управление внешними источниками данных и анализ данных в Data Lake через внешние catalog.
Этот документ описывает поддержку функций для внешних catalog и поддерживаемые версии задействованных функций.
Универсальные функции
В этом разделе перечислены универсальные функции внешних catalog, включая системы хранения, читатели файлов, учётные данные, привилегии и Data Cache.
Внешние системы хранения
| Система хранения | Поддерживаемая версия |
|---|---|
| HDFS | v1.5.2+ |
| AWS S3 | v1.5.2+ |
| Microsoft Azure Storage | v1.5.2+ |
| Google GCS | v1.5.2+ |
| Alibaba Cloud OSS | v1.5.2+ |
| Huawei Cloud OBS | v1.5.2+ |
| Tencent Cloud COS | v1.5.2+ |
| Volcengine TOS | v1.5.2+ |
| Kingsoft Cloud KS3 | v1.5.2+ |
| MinIO | v1.5.2+ |
| Ceph S3 | v1.5.2+ |
В дополнение к нативной поддержке систем хранения, перечисленных выше, Selena также поддерживает следующие типы сервисов объектного хранения:
- HDFS-совместимые сервисы объектного хранения, такие как COS Cloud HDFS, OSS-HDFS и OBS PFS
- Описание: Необходимо указать префикс URI объектного хранилища в параметре конфигурации BE
fallback_to_hadoop_fs_listи загрузить .jar-пакет, предоставленный облачным поставщиком, в директорию /lib/hadoop/hdfs/. Обратите внимание, что вы должны создать внешний catalog, используя префикс, указанный вfallback_to_hadoop_fs_list. - Поддерживаемые версии: v1.5.2+, v1.5.2+
- Описание: Необходимо указать префикс URI объектного хранилища в параметре конфигурации BE
- S3-совместимые сервисы объектного хранения, отличные от перечисленных выше
- Описание: Необходимо указать префикс URI объектного хранилища в параметре конфигурации BE
s3_compatible_fs_list. Обратите внимание, что вы должны создать внешний catalog, используя префикс, указанный вs3_compatible_fs_list. - Поддерживаемые версии: v1.5.2+, v1.5.2+
- Описание: Необходимо указать префикс URI объектного хранилища в параметре конфигурации BE
Форматы сжатия
В этом разделе перечислены только форматы сжатия, поддерживаемые каждым форматом файлов. Информацию о форматах файлов, поддерживаемых каждым внешним catalog, см. в разделе соответствующего внешнего catalog.
| Формат файла | Форматы сжатия |
|---|---|
| Parquet | NO_COMPRESSION, SNAPPY, LZ4, ZSTD, GZIP, LZO (v1.5.2+) |
| ORC | NO_COMPRESSION, ZLIB, SNAPPY, LZO, LZ4, ZSTD |
| Text | NO_COMPRESSION, LZO (v1.5.2+) |
| Avro | NO_COMPRESSION, DEFLATE, SNAPPY, BZIP2 (v1.5.2+) |
| RCFile | NO_COMPRESSION, DEFLATE, SNAPPY, GZIP (v1.5.2+) |
| SequenceFile | NO_COMPRESSION, DEFLATE, SNAPPY, BZIP2, GZIP (v1.5.2+) |
Форматы файлов Avro, RCFile и SequenceFile читаются через Java Native Interface (JNI), а не через нативные читатели Selena. Поэтому производительность чтения для этих форматов файлов может быть не такой хорошей, как для Parquet и ORC.
Управление, учётные данные и контроль доступа
| Функция | Описание | Поддерживаемые версии |
|---|---|---|
| Information Schema | Поддерживает Information Schema для внешних catalog. | v1.5.2+ |
| Контроль доступа к Data Lake | Поддерживает нативную модель RBAC Selena для внешних catalog. Вы можете управлять привилегиями баз данных, таблиц и представлений (�в настоящее время только Hive views и Iceberg views) во внешних catalog так же, как и в default catalog Selena. | v1.5.2+ |
| Повторное использование внешних сервисов на Apache Ranger | Поддерживает повторное использование внешнего сервиса (например, Hive Service) на Apache Ranger для контроля доступа. | v1.5.2+ |
| Аутентификация Kerberos | Поддерживает аутентификацию Kerberos для HDFS или Hive Metastore. | v1.5.2+ |
Data Cache
| Функция | Описание | Поддерживаемые версии |
|---|---|---|
| Data Cache (Block Cache) | Начиная с версии v1.5.2, Selena поддерживала функцию Data Cache (тогда называвшуюся Block Cache), реализованную с использованием CacheLib, что приводило к ограниченному потенциалу оптимизации её расширяемости. Начиная с версии v1.5.2, Selena переработала реализацию кэша и добавила новые функции в Data Cache, что привело к улучшению производительности с каждой последующей версией. | v1.5.2+ |
| Ребалансировка данных между локальными дисками | Поддерживает стратегию ребалансировки данных для обеспечения контроля перекоса данных в пределах 10%. | v1.5.2+ |
| Замена Block Cache на Data Cache | Изменения параметров Конфигурации BE:
| v1.5.2+ |
| Новые метрики для API мониторинга Data Cache | Поддерживает отдельный API для мониторинга Data Cache, включая ёмкость кэша и попадания. Вы можете просматривать метрики Data Cache через интерфейс http://${BE_HOST}:${BE_HTTP_PORT}/api/datacache/stat. | v1.5.2+ |
| Memory Tracker для Data Cache | Поддерживает Memory Tracker для Data Cache. Вы можете просматривать метрики, связанные с памятью, через интерфейс http://${BE_HOST}:${BE_HTTP_PORT}/mem_tracker. | v1.5.2+ |
| Прогрев Data Cache | Выполняя CACHE SELECT, вы можете заранее активно заполнить кэш нужными данными из удалённого хранилища, чтобы первый запрос не занимал слишком много времени на получение данных. CACHE SELECT не выводит данные и не выполняет вычисления. Он только получает данные. | v1.5.2+ |
Hive Catalog
Метаданные
При выполнении запросов к данным Hive через Hive catalog Selena будет кэшировать метаданные таблиц для снижения затрат на частый доступ к удалённому хранилищу. Этот механизм обеспечивает производительность запросов, поддерживая свежесть данных через политику асинхронного обновления и истечения срока действия.
Кэшируемые метаданные
Selena будет кэшировать следующие метаданные во время запросов:
-
Метаданные уровня таблицы или partition
- Содержимое:
- Информация о таблице: база данных, схема таблицы, имена столбцов и ключи partition
- Информация о partition: список partition и расположение partition
- Влияние: обнаружение существования таблицы (была ли таблица удалена и/или пересоздана)
- Свойства catalog:
enable_metastore_cache: Управляет включением кэша metastore. Значение по умолчанию:true.metastore_cache_refresh_interval_sec: Управляет интервалом времени, в течение ко�торого кэшированные метаданные считаются свежими. Значение по умолчанию:60. Единица измерения: секунды.
- Расположение: Metastore (HMS или Glue)
- Содержимое:
-
Список имён partition
- Содержимое: Список имён partition, используемый для поиска и отсечения partition. Хотя список имён partition был собран как информация о partition в разделе выше, существует отдельная конфигурация для включения или отключения этой функции в определённых обстоятельствах.
- Влияние: обнаружение существования partition (появился ли новый partition или partition был удалён и/или пересоздан)
- Свойства catalog:
enable_cache_list_names: Управляет включением кэша списка имён partition. Значение по умолчанию:true.metastore_cache_refresh_interval_sec: Управляет интервалом времени, в течение которого кэшированные метаданные считаются свежими. Значение по умолчанию:60. Единица измерения: секунды.
- Расположение: Metastore (HMS или Glue)
-
Метаданные уровня файла
- Содержимое: Пути к файлам в папке partition.
- Влияние: Загрузка данных в существующий partition.
- Свойства catalog:
enable_remote_file_cache: Управ�ляет включением кэша метаданных для файлов в удалённом хранилище. Значение по умолчанию:true.remote_file_cache_refresh_interval_sec: Управляет интервалом времени, в течение которого метаданные файлов считаются свежими. Значение по умолчанию:60. Единица измерения: секунды.remote_file_cache_memory_ratio: Управляет долей памяти, которая может использоваться для кэша метаданных файлов. Значение по умолчанию:0.1(10%).
- Расположение: Удалённое хранилище (HDFS или S3)
Политика асинхронного обновления
Следующий параметр конфигурации FE управляет политикой асинхронного обновления метаданных:
| Параметр конфигурации | Значение по умолчанию | Описание |
|---|---|---|
| enable_background_refresh_connector_metadata | true в v1.5.2false в v1.5.2 | Включать ли периодическое обновление кэша метаданных. После включения Selena опрашивает metastore и обновляет кэшированные метаданные часто используемых внешних catalog для обнаружения изменений данных. true означает включить обновление кэша метаданных Hive, false означает отключить. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
| background_refresh_metadata_interval_millis | 600000 (10 минут) | Интервал между двумя последовательными обновлениями кэша метаданных. Единица измерения: миллисекунды. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
| background_refresh_metadata_time_secs_since_last_access_secs | 86400 (24 часа) | Время истечения срока действия задачи обновления кэша метаданных. Для внешнего catalog, к которому был доступ, если к нему не обращались более указанного времени, Selena прекращает обновление его кэшированных метаданных. Для внешнего catalog, к которому не было доступа, Selena не будет обновлять его кэшированные метаданные. Единица измерения: секунды. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
Поведение кэша метаданных
В этом разделе используется поведение по умолчанию для объяснения поведения метаданных во время обновления метаданных и запросов.
По умолчанию, когда выполняется запрос к таблице, Selena кэширует метаданные таблицы, partition и файлов и поддерживает их активными в течение следующих 24 часов. В течение 24 часов система обеспечит обновление кэша не реже, чем каждые 10 минут (обратите внимание, что 10 минут — это расчётное время для раунда обновления метаданных. Если есть слишком много внешних таблиц, ожидающих обновления метаданных, общий интервал обновления метаданных может быть больше 10 минут). Если к таблице не обращались более 24 часов, Selena удаляет связанные метаданные. Другими словами, любой запрос, который вы делаете в течение 24 часов, в худшем случае будет использовать метаданные 10-минутной давности.
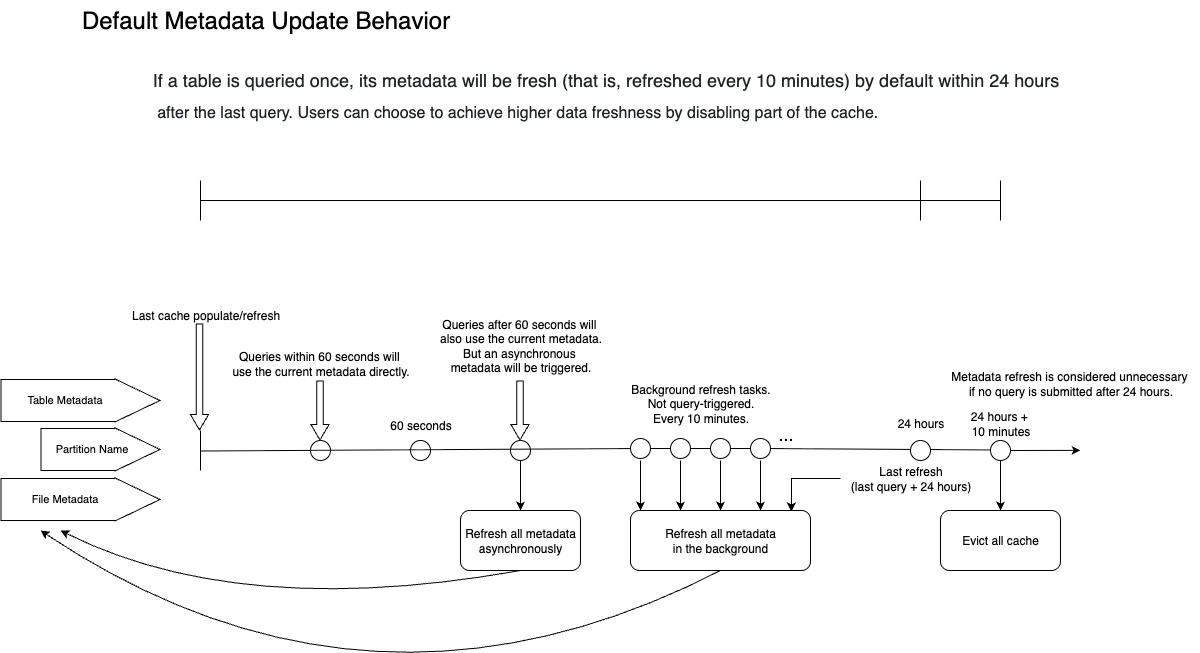
Подробнее:
- Предположим, первый запрос затрагивает partition
P1таблицыA. Selena кэширует метаданные уровня таблицы, списки имён partition и информацию о путях к файлам вP1. Кэш заполняется синхронно во время выполнения запроса. - Если второй запрос отправлен в течение 60 секунд после заполнения кэша и затрагивает partition
P1таблицыA, Selena использует кэш метаданных напрямую, и в этот момент Selena считает все кэшированные метаданные свежими (metastore_cache_refresh_interval_secиremote_file_cache_refresh_interval_secуправляют временным окном, в течение которого Selena считает метаданные свежими). - Если третий запрос отправлен через 90 секунд и затрагивает partition
P1таблицыA, Selena всё равно будет использовать кэш метаданных напрямую для завершения запроса. Однако, поскольку прошло более 60 секунд с момента последнего обновления метаданных, Selena будет считать метаданные устаревшими. Поэтому Selena запустит асинхронное обновление для устаревших метаданных. Асинхронное о�бновление не повлияет на результат текущего запроса, потому что запрос всё ещё будет использовать устаревшие метаданные. - Поскольку был выполнен запрос к partition
P1таблицыA, ожидается, что метаданные будут обновляться каждые 10 минут (управляетсяbackground_refresh_metadata_interval_millis) в течение следующих 24 часов (управляетсяbackground_refresh_metadata_time_secs_since_last_access_secs). Фактический интервал между раундами обновления метаданных также зависит от общего количества ожидающих задач обновления в системе. - Если таблица
Aне участвует ни в каком запросе в течение 24 часов, Selena удалит её кэш метаданных через 24 часа.
Лучшие практики
Поддержка Hive Catalog для Hive Metastore (HMS) и AWS Glue в основном совпадает, за исключением того, что функция автоматического инкрементального обновления для HMS не рекомендуется. Конфигурация по умолчанию рекомендуется в большинстве случаев.
Производительность получения метаданных во многом зависит от производительности HMS пользователя или HDFS NameNode. Пожалуйста, учитывайте все факторы и основывайте своё решение на результатах тестирования.
- [По умолчанию и рекомендуется] Лучшая производительность с допуском несогласованности данных на уровне минут
- Конфигурация: Вы можете использовать настройку по умолчанию. Данные, обновлённые в течение 10 минут (по умолчанию), не видны. В течение этого периода запросы будут возвращать старые данные.
- Преимущество: Лучшая производительность запросов.
- Недостаток: Несогласованность данных из-за задержки.
- Поддерживаемые версии: v1.5.2+ (отключено по умолчанию в v1.5.2 и включено по умолчанию в v1.5.2+)
- Мгновенная видимость недавно загруженных данных (файлов) без ручного обновления
- Конфигурация: Отключите кэш для метаданных базовых файлов данных, установив свойство catalog
enable_remote_file_cacheвfalse. - Преимущество: Видимость изменений файлов без задержки.
- Недостаток: Более низкая производительность при отключённом кэше метаданных файлов. Каждый запрос должен обращаться к списку файлов.
- Поддерживаемые версии: v1.5.2+
- Конфигурация: Отключите кэш для метаданных базовых файлов данных, установив свойство catalog
- Мгновенная видимость изменений partition без ручного обновления
- Конфигурация: Отключите кэш для имён partition Hive, установив свойство catalog
enable_cache_list_namesвfalse. - Преимущество: Видимость изменений partition без задержки
- Недостаток: Более низкая производительность при отключённом кэше имён partition. Каждый запрос должен обращаться к списку partition.
- Поддерживаемые версии: v1.5.2+
- Конфигурация: Отключите кэш для имён partition Hive, установив свойство catalog
Если вы требуете обновлений в реальном времени об изменениях данных, а производительность вашего HMS не оптимизирована, вы можете включить кэш, отключить автоматическое инкрементальное обновление и вручную обновлять метаданные (используя REFRESH EXTERNAL TABLE) через систему планирования всякий раз, когда происходит изменение данных upstream.
Система хранения
| Функция | Описание | Поддерживаемые версии |
|---|---|---|
| Рекурсивный листинг поддиректорий | Включите рекурсивный листинг поддиректорий, установив свойство catalog enable_recursive_listing в true. Когда рекурсивный листинг включён, Selena будет читать данные из таблицы и её partition, а также из поддиректорий в физических расположениях таблицы и её partition. Эта функция предназначена для решения проблемы многоуровневых вложенных директорий. | v1.5.2+ |
Форматы файлов и типы данных
Форматы файлов
| Функция | Поддерживаемые форматы файлов |
|---|---|
| Чтение | Parquet, ORC, TEXT, Avro, RCFile, SequenceFile |
| Запись | Parquet (v1.5.2+), ORC (v1.5.2+), TEXT (v1.5.2+) |
Типы данных
Типы INTERVAL, BINARY и UNION не поддерживаются.
Таблицы Hive в формате TEXT не поддерживают типы MAP и STRUCT.
Типы таблиц
Чтение транзакционных таблиц Hive не поддерживается.
Hive views
Selena поддерживает запросы к Hive views начиная с версии v1.5.2.
Интерфейсы статистики запросов
| Функция | Поддерживаемые версии |
|---|---|
| Поддерживает SHOW CREATE TABLE для просмотра схемы таблицы Hive | v1.5.2+ |
| Поддерживает ANALYZE для сбора статистики | v1.5.2+ |
| Поддерживает сбор гистограмм и статистики подполей STRUCT | v1.5.2+ |
Запись данных
| Функция | Поддерживаемые версии | Примечание |
|---|---|---|
| CREATE DATABASE | v1.5.2+ | Вы можете выбрать, указывать ли расположение для базы данных, созданной в Hive, или нет. Если вы не укажете расположение для базы данных, вам нужно будет указать расположение для таблиц, созданных в этой базе данных. В противном случае будет возвращена ошибка. Если вы указали расположение для базы данных, таблицы без указанного расположения унаследуют расположение базы данных. И если вы указали расположения как для базы данных, так и для таблицы, расположение таблицы будет иметь приоритет. |
| CREATE TABLE | v1.5.2+ | Для партиционированных и непартиционированных таблиц. |
| CREATE TABLE AS SELECT | v1.5.2+ | |
| INSERT INTO/OVERWRITE | v1.5.2+ | Для партиционированных и непартиционированных таблиц. |
| CREATE TABLE LIKE | v1.5.2+ | |
| Размер файла при записи | v1.5.2+ | Вы можете определить максимальный размер каждого записываемого файла данных с помощью сессионной переменной connector_sink_target_max_file_size. |
Iceberg Catalog
Метаданные
При выполнении запросов к данным Iceberg через Iceberg catalog Selena будет кэшировать метаданные таблиц для снижения затрат на частый доступ к удалённому хранилищу. Этот механизм обеспечивает производительность запросов, поддерживая свежесть данных через политику асинхронного обновления и истечения срока действия.
Кэшируемые метаданные
Selena будет кэшировать следующие метаданные во время запросов:
-
Кэш указателя метаданных
- Содержимое: JSON-файл указателя метаданных
- Snapshot ID
- Расположение списков манифестов
- Влияние: обнаружение изменений данных (если происходит изменение данных, Snapshot ID изменится.)
- Свойства catalog:
enable_iceberg_metadata_cache: Управляет включением кэша метаданных Iceberg. Значение по умолчанию:true.iceberg_table_cache_refresh_interval_sec: Управляет интервалом времени, в течение которого кэшированные метаданные считаются свежими. Значение по умолчанию:60. Единица измерения: секунды.
- Содержимое: JSON-файл указателя метаданных
-
Кэш метаданных
- Содержимое:
- Манифест для пути к файлу данных
- Мани�фест для пути к файлу удаления
- База данных
- Partition (для перезаписи материализованного представления)
- Влияние:
- Не влияет на свежесть данных для запросов, поскольку манифесты для файлов данных или удаления не могут быть изменены.
- Может влиять на перезапись материализованного представления, заставляя запросы пропускать материализованное представление. Метаданные partition будут удалены при обновлении Snapshot ID. Поэтому новый Snapshot ID не имеет метаданных partition, что приводит к пропуску перезаписи материализованного представления.
- Свойства catalog:
enable_cache_list_names: Управляет включением кэша списка имён partition. Значение по умолчанию:true.metastore_cache_refresh_interval_sec: Управляет интервалом времени, в течение которого кэшированные метаданные считаются свежими. Значение по умолчанию:60. Единица измерения: секунды.iceberg_data_file_cache_memory_usage_ratio: Управляет долей памяти, которая может использоваться для кэша метаданных файлов данных. Значение по умолчанию:0.1(10%).iceberg_delete_file_cache_memory_usage_ratio: Управляет долей памяти, которая может использоваться для кэша метаданных файлов удаления. Значение по умолчанию:0.1(10%).
- Содержимое:
Политика асинхронного обновления
Следующий параметр конфигурации FE управляет политикой асинхронного обновления метаданных:
| Параметр конфигурации | Значение по умолчанию | Описание |
|---|---|---|
| enable_background_refresh_connector_metadata | true в v1.5.2false в v1.5.2 | Включать ли периодическое обновление кэша метаданных. После включения Selena опрашивает metastore и обновляет кэшированные метаданные часто используемых внешних catalog для обнаружения изменений данных. true означает включить обновление кэша метаданных Hive, false означает отключить. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
| background_refresh_metadata_interval_millis | 600000 (10 минут) | Интервал между двумя последовательными обновлениями кэша метаданных. Единица измерения: миллисекунды. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
| background_refresh_metadata_time_secs_since_last_access_secs | 86400 (24 часа) | Время истечения срока действия задачи обновления кэша метаданных. Для внешнего catalog, к которому был доступ, если к нему не обращались более указанного времени, Selena прекращает обновление его кэшированных метаданных. Для внешнего catalog, к которому не было доступа, Selena не будет обновлять его кэшированные метаданные. Единица измерения: секунды. Это динамический параметр FE. Вы можете изменить его с помощью команды ADMIN SET FRONTEND CONFIG. |
Поведение кэша метаданных
В этом разделе используется поведение по умолчанию для объяснения поведения метаданных во время обновления метаданных и запросов.
По умолчанию, когда выполняется запрос к таблице, Selena кэширует метаданные таблицы и поддерживает их активными в течение следующих 24 часов. В течение 24 часов система обеспечит обновление кэша не реже, чем каждые 10 минут (обратите внимание, что 10 минут — это расчётное время для раунда обновления метаданных. Если есть слишком много внешних таблиц, ожидающих обновления метаданных, общий интервал обновления метаданных может быть больше 10 минут). Если к таблице не обращались более 24 часов, Selena удаляет связанные метаданные. Другими словами, любой запрос, который вы делаете в течение 24 часов, в худшем случае будет использовать метаданные 10-минутной давности.
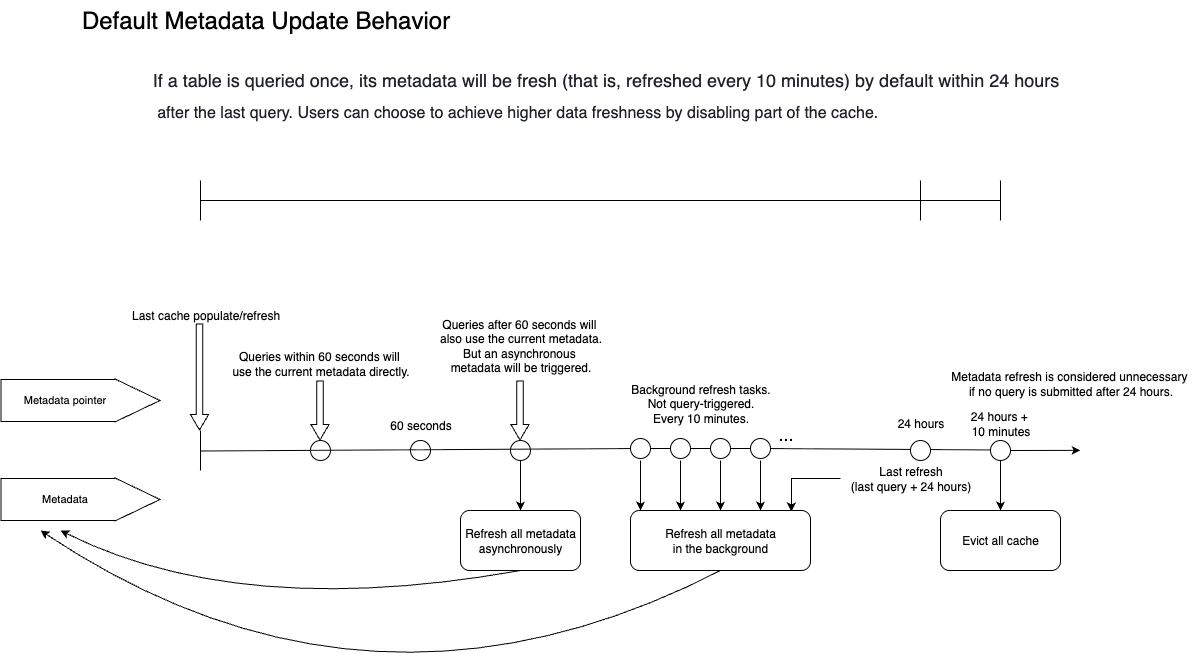
Подробнее:
- Предположим, первый запрос затрагивает таблицу
A. Selena кэширует её последний snapshot и метаданные. Кэш заполняется синхронно во время выполнения запроса. - Если второй запрос отправлен в течение 60 секунд после заполнения кэша и затрагивает таблицу
A, Selena использует кэш метаданных напрямую, и в этот момент Selena считает все кэшированные метаданные свежими (iceberg_table_cache_refresh_interval_secуправляет временным окном, в течение которого Selena считает метаданные свежими). - Если третий запрос отправлен через 90 секунд и затрагивает таблицу
A, Selena всё равно будет использовать кэш метаданных напрямую для завершения запроса. Однако, поскольку прошло более 60 секунд с момента последнего обновления метаданных, Selena будет считать метаданные устаревшими. Поэтому Selena запустит асинхронное обновление для устаревших метаданных. Асинхронное обновление не повлияет на результат текущего запроса, потому что запрос всё ещё будет использовать устаревшие метаданные. - Поскольку был выполнен запрос к таблице
A, ожидается, что метаданные будут обновляться каждые 10 минут (управляетсяbackground_refresh_metadata_interval_millis) в течение следующих 24 часов (управляетсяbackground_refresh_metadata_time_secs_since_last_access_secs). Фактический интервал между раундами обновления метаданных также зависит от общего количества ожидающих задач обновления в системе. - Если таблица
Aне участвует ни в каком запросе в течение 24 часов, Selena удалит её кэш метаданных через 24 часа.
Лучшие практики
Iceberg Catalog поддерживает HMS, Glue и Tabular в качестве metastore. Конфигурация по умолчанию рекомендуется в большинстве случаев.
Обратите внимание, что значение по умолчанию сессионной переменной enable_iceberg_metadata_cache было изменено для адаптации к различным сценариям:
- С версии v1.5.2 по v1.5.2 этот параметр по умолчанию установлен в
true, независимо от используемого сервиса metastore. - В версии v1.5.2 и позже, если Iceberg cluster использует AWS Glue в качестве metastore, этот параметр по-прежнему по умолчанию
true. Однако, если Iceberg cluster использует другие сервисы metastore, такие как Hive metastore, этот параметр по умолчаниюfalse. - С версии v1.5.2 значение этого параметра по умолчанию снова установлено в
true, поскольку Selena поддерживает новый фреймворк метаданных Iceberg. Iceberg Catalog и Hive Catalog теперь используют один и тот же механизм опроса метаданных и параметр конфигурации FEbackground_refresh_metadata_interval_millis.
| Функция | Поддерживаемые версии |
|---|---|
| Распределённый план метаданных (рекомендуется для сценариев с большим объёмом метаданных) | v1.5.2+ |
| Кэш манифестов (рекомендуется для сценариев с небольшим объёмом метаданных, но высокими требованиями к задержке) | v1.5.2+ |
Начиная с версии v1.5.2, Selena поддерживает политики чтения и кэширования метаданных, описанные выше. Система автоматически настроит выбор политики в соответствии с машинами в вашем cluster. Обычно вам не нужно его менять. Поскольку кэширование метаданных включено, возможно, что свежесть метаданных может быть скомпрометирована из соображений производительности. Поэтому вы можете настроить его в соответствии с вашими конкретными требованиями к запросам:
- [По умолчанию и рекомендуется] Оптимальная производительность с допуском несогласованности данных на уровне минут
- Настройка: Дополнительная настройка не требуется. По умолчанию данные, обновлённые в течение 10 минут, не видны. В течение этого времени запросы будут возвращать старые данные.
- Преимущества: Лучшая производительность запросов.
- Недостаток: несогласованность данных из-за задержек.
- Новые файлы данных, сгенерированные импортом, и добавления или удаления partition видны немедленно, ручное обновление не требуется
- Настройка: Установите свойство catalog
iceberg_table_cache_ttl_secв0, чтобы позволить Selena получать новый snapshot для каждого запроса. - Преимущества: Изменения файлов и partition видны без задержки.
- Недостаток: Более низкая производительность из-за поведения получения snapshot для каждого запроса.
- Настройка: Установите свойство catalog
Форматы файлов
| Функция | Поддерживаемые форматы файлов |
|---|---|
| Чтение | Parquet, ORC |
| Запись | Parquet |
- Таблицы Iceberg V1 в форматах Parquet и ORC поддерживают position deletes и equality deletes.
- Таблицы Iceberg V2 в формате ORC поддерживают position deletes с версии v1.5.2, а в формате Parquet — с версии v1.5.2.
- Таблицы Iceberg V2 в формате ORC поддерживают equality deletes с v1.5.2.
Iceberg views
Selena поддерживает запросы к Iceberg views начиная с версии v1.5.2 и создание Iceberg views с версии v1.5.2.
В настоящее время поддерживаются только Iceberg views, созданные через Selena. Начиная с версии v1.5.2, поддерживается добавление определений в стиле синтаксиса Selena к существующим Iceberg views.
Интерфейсы статистики запросов
| Функция | Поддерживаемые версии |
|---|---|
| Поддерживает SHOW CREATE TABLE для просмотра схемы таблицы Iceberg | v1.5.2+ |
| Поддерживает ANALYZE для сбора статистики | v1.5.2+ |
| Поддерживает сбор гистограмм и статистики подполей STRUCT | v1.5.2+ |
Запись данных
| Функция | Поддерживаемые версии | Примечание |
|---|---|---|
| CREATE DATABASE | v1.5.2+ | Вы можете выбрать, указывать ли расположение для базы данных, созданной в Iceberg, или нет. Если вы не укажете расположение для базы данных, вам нужно будет указать расположение для таблиц, созданных в этой базе данных. В противном случае будет возвращена ошибка. Если вы указали расположение для базы данных, таблицы без указанного расположения унаследуют расположение базы данных. И если в�ы указали расположения как для базы данных, так и для таблицы, расположение таблицы будет иметь приоритет. |
| CREATE TABLE | v1.5.2+ | Поддерживает партиционированные и непартиционированные таблицы. Начиная с v2.0.0, поддерживает создание таблиц со скрытыми partition. |
| CREATE TABLE AS SELECT | v1.5.2+ | |
| INSERT INTO/OVERWRITE | v1.5.2+ | Для партиционированных и непартиционированных таблиц. |
Прочая поддержка
| Функция | Поддерживаемые версии |
|---|---|
Поддерживает чтение форматов partition типа TIMESTAMP yyyy-MM-ddTHH:mm и yyyy-MM-dd HH:mm. | v1.5.2+ |
| Поддерживает таблицу метаданных Iceberg | v1.5.2+ |
| Поддерживает Iceberg TimeTravel | v1.5.2+ |
Hudi Catalog
- Selena поддерживает запросы к данным в формате Parquet в Hudi и поддерживает форматы сжатия SNAPPY, LZ4, ZSTD, GZIP и NO_COMPRESSION для файлов Parquet.
- Selena полностью поддерживает таблицы Hudi Copy On Write (COW) и Merge On Read (MOR).
- Selena поддерживает SHOW CREATE TABLE для просмотра схемы таблицы Hudi начиная с версии v1.5.2.
- Selena v1.5.2 поддерживает Hudi 0.15.0.
Delta Lake Catalog
- Selena поддерживает запросы к данным в формате Parquet в Delta Lake и поддерживает форматы сжатия SNAPPY, LZ4, ZSTD, GZIP и NO_COMPRESSION для файлов Parquet.
- Selena не поддерживает запросы к данным типов MAP и STRUCT в Delta Lake.
- Selena поддерживает SHOW CREATE TABLE для просмотра схемы таблицы Delta Lake начиная с версии v1.5.2.
- В настоящее время Delta Lake catalog поддерживают следующие функции таблиц:
- V2 Checkpoint (с версии v1.5.2)
- Timestamp without Timezone (с версии v1.5.2)
- Column mapping (с версии v1.5.2)
- Deletion Vector (с версии v1.5.2)
JDBC Catalog
| Тип catalog | Поддерживаемые версии |
|---|---|
| MySQL | v1.5.2+ |
| PostgreSQL | v1.5.2+ |
| ClickHouse | v1.5.2+ |
| Oracle | v1.5.2+ |
| SQL Server | v1.5.2+ |
MySQL
| Функция | Поддерживаемые версии |
|---|---|
| Кэш метаданных | v1.5.2+ |
Соответствие типов данных
| MySQL | Selena | Поддерживаемые версии |
|---|---|---|
| BOOLEAN | BOOLEAN | v1.5.2+ |
| BIT | BOOLEAN | v1.5.2+ |
| SIGNED TINYINT | TINYINT | v1.5.2+ |
| UNSIGNED TINYINT | SMALLINT | v1.5.2+ |
| SIGNED SMALLINT | SMALLINT | v1.5.2+ |
| UNSIGNED SMALLINT | INT | v1.5.2+ |
| SIGNED INTEGER | INT | v1.5.2+ |
| UNSIGNED INTEGER | BIGINT | v1.5.2+ |
| SIGNED BIGINT | BIGINT | v1.5.2+ |
| UNSIGNED BIGINT | LARGEINT | v1.5.2+ |
| FLOAT | FLOAT | v1.5.2+ |
| REAL | FLOAT | v1.5.2+ |
| DOUBLE | DOUBLE | v1.5.2+ |
| DECIMAL | DECIMAL32 | v1.5.2+ |
| CHAR | VARCHAR(columnsize) | v1.5.2+ |
| VARCHAR | VARCHAR | v1.5.2+ |
| TEXT | VARCHAR(columnsize) | v1.5.2+ |
| DATE | DATE | v1.5.2+ |
| TIME | TIME | v1.5.2+ |
| TIMESTAMP | DATETIME | v1.5.2+ |
PostgreSQL
Соответствие типов данных
| PGSQL | Selena | Поддерживаемые версии |
|---|---|---|
| BIT | BOOLEAN | v1.5.2+ |
| SMALLINT | SMALLINT | v1.5.2+ |
| INTEGER | INT | v1.5.2+ |
| BIGINT | BIGINT | v1.5.2+ |
| REAL | FLOAT | v1.5.2+ |
| DOUBLE | DOUBLE | v1.5.2+ |
| NUMERIC | DECIMAL32 | v1.5.2+ |
| CHAR | VARCHAR(columnsize) | v1.5.2+ |
| VARCHAR | VARCHAR | v1.5.2+ |
| TEXT | VARCHAR(columnsize) | v1.5.2+ |
| DATE | DATE | v1.5.2+ |
| TIMESTAMP | DATETIME | v1.5.2+ |
| UUID | VARBINARY | v1.5.2+ |
ClickHouse
Поддерживается с версии v1.5.2.
Oracle
Поддерживается с версии v1.5.2.
SQL Server
Поддерживается с версии v1.5.2.
Elasticsearch Catalog
Elasticsearch Catalog поддерживается с версии v1.5.2.
Paimon Catalog
Paimon Catalog поддерживается с версии v1.5.2.
MaxCompute Catalog
MaxCompute Catalog поддерживается с версии v1.5.2.
Kudu Catalog
Kudu Catalog поддерживается с версии v1.5.2.