Использование GCS для shared-data
Эта тема описывает, как развернуть и использовать кластер Selena с разделяемыми данными. Эта функция поддерживается начиная с версии 1.5.0 для S3-совместимого хранилища и версии 3.1 для Azure Blob Storage.
ПРИМЕЧАНИЕ
- Версия Selena 3.1 вносит некоторые изменения в развертывание и конфигурацию разделяемых данных. Пожалуйста, используйте этот документ, если вы работаете с версией 3.1 или выше.
- Если вы используете версию 3.0, пожалуйста, обратитесь к документации версии 3.0.
- Кластеры Selena с разделяемыми данными не поддерживают резервное копирование (BACKUP) и восстановление (RESTORE) данных.
Кластер Selena с разделяемыми данными специально разработан для облачной среды на основе принципа разделения хранилища и вычислений. Он позволяет хранить данные в объектном хранилище (например, AWS S3, Google GCS, Azure Blob Storage и MinIO). Вы можете достичь не только более дешевого хранения и лучшей изоляции ресурсов, но и эластичной масштабируемости для вашего кластера. Производительность запросов кл�астера Selena с разделяемыми данными соответствует производительности кластера Selena с неразделяемыми данными при попадании в локальный дисковый кеш.
В версии 3.1 и выше кластер Selena с разделяемыми данными состоит из Frontend Engines (FE) и Compute Nodes (CN). CN заменяют классические Backend Engines (BE) в кластерах с разделяемыми данными.
По сравнению с классической архитектурой Selena с неразделяемыми данными, разделение хранилища и вычислений предлагает широкий спектр преимуществ. Разделяя эти компоненты, Selena обеспечивает:
- Недорогое и легко масштабируемое хранилище.
- Эластично масштабируемые вычисления. Поскольку данные не хранятся в Compute Nodes (CN), масштабирование может выполняться без миграции данных или перемешивания между узлами.
- Локальный дисковый кеш для горячих данных для повышения производительности запросов.
- Асинхронную загрузку данных в объектное хранилище, что позволяет значительно улучшить производительность загрузки.
Архитектура
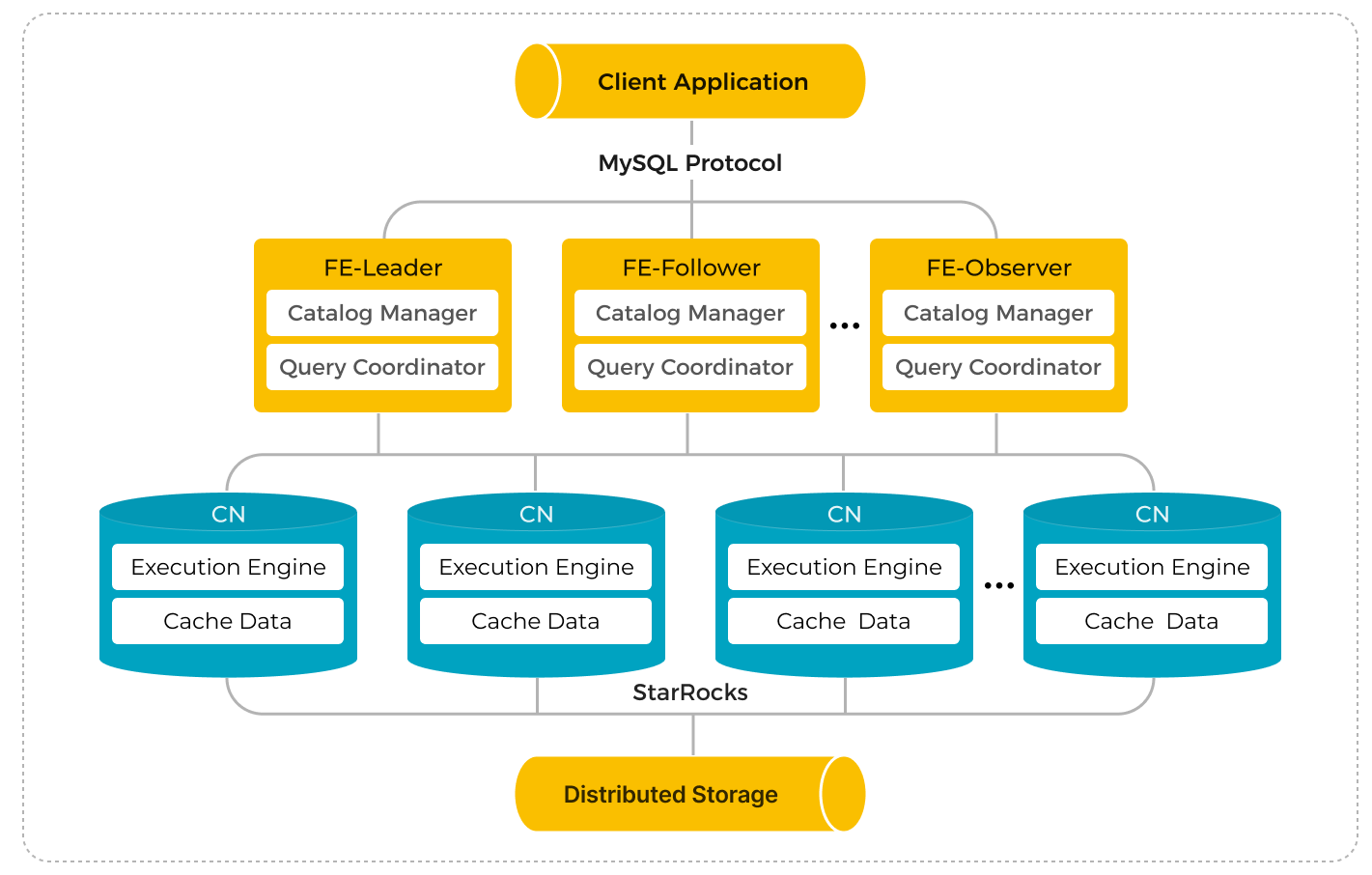
Развертывание кластера Selena с shared-data
Развертывание кластера Selena с shared-data аналогично развертыванию кластера Selena с shared-nothing. Единственное отличие заключается в том, что в кластере с shared-data необходимо развертывать CN вместо BE. В этом разделе перечислены только дополнительные элементы конфигурации FE и CN, которые необходимо добавить в файлы конфигурации FE и CN fe.conf и cn.conf при развертывании кластера Selena с shared-data. Подробные инструкции по развертыванию кластера Selena см. в разделе Развертывание Selena.
ПРИМЕЧАНИЕ
Не запускайте кластер до тех пор, пока он не будет настроен для shared-storage в следующем разделе этого документа.
Настройка узлов FE для Selena с shared-data
Перед запуском кластера настройте FE и CN. Ниже приведен пример конфигурации, а затем подробности для каждого параметра.
Пример конфигурации FE для GCS
Пример дополнений shared-data для вашего fe.conf можно добавить в файл fe.conf на каждом из ваших узлов FE. Поскольку доступ к хранилищу GCS осуществляется с использованием Cloud Storage XML API, параметры используют префикс aws_s3.
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# Например, testbucket/subpath
aws_s3_path = <s3_path>
# Например: us-east1
aws_s3_region = <region>
# Например: https://storage.googleapis.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <HMAC access_key>
aws_s3_secret_key = <HMAC secret_key>
Все параметры FE, связанные с shared-storage с GCS
run_mode
Режим работы кластера Selena. Допустимые значения:
shared_datashared_nothing(По умолчанию)
ПРИМЕЧАНИЕ
- Вы не можете одновременно использовать режимы
shared_dataиshared_nothingдля кластера Selena. Смешанное развертывание не поддерживается.- Не изменяйте
run_modeпосле развертывания кластера. В противном случае кластер не сможет перезапуститься. Преобразование из кластера shared-nothing в кластер shared-data или наоборот не поддерживается.
cloud_native_meta_port
Порт RPC для cloud-native мета-сервиса.
- По умолчанию:
6090
enable_load_volume_from_conf
Разрешить ли Selena создавать том хранения по умолчанию, используя свойства объектного хранилища, указанные в файле конфигурации FE. Допустимые значения:
true(По умолчанию) Если вы указываете этот элемент какtrueпри создании нового кластера shared-data, Selena создает встроенный том храненияbuiltin_storage_volume, используя свойства объектного хранилища в файле конфигурации FE, и устанавливает его как том хранения по умолчанию. Однако, если вы не указали свойства объектного хранилища, Selena не сможет запуститься.falseЕсли вы указываете этот элемент какfalseпри создании нового кластера shared-data, Selena запускается напрямую без создания встроенного тома хранения. Вы должны вручную создать том хранения и установить его как том хранения по умолчанию перед созданием любого объекта в Selena. Для получения дополнительной информации см. Создание тома хранения по умолчанию.
Поддерживается с версии v3.1.0.
ВНИМАНИЕ
Мы настоятельно �рекомендуем оставить этот элемент как
trueпри обновлении существующего кластера shared-data с версии v3.0. Если вы укажете этот элемент какfalse, базы данных и таблицы, созданные до обновления, станут доступными только для чтения, и вы не сможете загружать в них данные.
cloud_native_storage_type
Тип объектного хранилища, которое вы используете. В режиме shared-data Selena поддерживает хранение данных в Azure Blob (поддерживается с версии v3.1.1), и объектных хранилищах, совместимых с протоколом S3 (таких как AWS S3, Google GCS и MinIO). Допустимые значения:
S3(По умолчанию)AZBLOBHDFS
ПРИМЕЧАНИЕ
- Если вы указываете этот параметр как
S3, вы должны добавить параметры с префиксомaws_s3.- Если вы указываете этот параметр как
AZBLOB, вы должны добавить параметры с префиксомazure_blob.- Если вы указываете этот параметр как
HDFS, вы должны добавить параметрcloud_native_hdfs_url.
aws_s3_path
Путь S3, используемый для хранения данных. Он состоит из имени вашего S3 bucket и подпути (если есть) под ним, например, testbucket/subpath.
aws_s3_endpoint
Конечная точка, используемая для доступа к вашему S3 bucket, например, https://storage.googleapis.com/
aws_s3_region
Регион, в котором находится ваш S3 bucket, например, us-west-2.
aws_s3_use_instance_profile
Использовать ли Instance Profile и Assumed Role в качестве методов аутентификации для доступа к GCS. Допустимые значения:
truefalse(По умолчанию)
Если вы используете аутентификацию на основе пользователя IAM (Access Key и Secret Key) для доступа к GCS, вы должны указать этот элемент как false и указать aws_s3_access_key и aws_s3_secret_key.
Если вы используете Instance Profile для доступа к GCS, вы должны указать этот элемент как true.
Если вы используете Assumed Role для доступа к GCS, вы должны указать этот элемент как true и указать aws_s3_iam_role_arn.
И если вы используете внешний аккаунт AWS, вы также должны указать aws_s3_external_id.
aws_s3_access_key
HMAC Access Key ID, используемый для доступа к вашему GCS bucket.
aws_s3_secret_key
HMAC Secret Access Key, используемый для доступа к вашему GCS bucket.
aws_s3_iam_role_arn
ARN роли IAM, которая имеет привилегии на ваш GCS bucket, в котором хранятся ваши файлы данных.
aws_s3_external_id
Внешний ID аккаунта AWS, который используется для межаккаунтного доступа к вашему GCS bucket.
ПРИМЕЧАНИЕ
Только элементы конфигурации, связанные с аутентификацией, могут быть изменены после создания вашего кластера Selena с shared-data. Если вы изменили исходные элементы конфигурации, связанные с путем хранения, базы данных и таблицы, созданные до изменения, станут доступными только для чтения, и вы не сможете загружать в них данные.
Если вы хотите создать том хранения по умолчанию вручную после создания кластера, вам нужно добавить только следующие элементы конфигурации:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
enable_load_volume_from_conf = false
Настройка узлов CN для Selena с shared-data
Перед запуском CN, добавьте следующие элементы конфигурации в файл конфигурации CN cn.conf:
starlet_port = <starlet_port>
storage_root_path = <storage_root_path>
starlet_port
Порт службы heartbeat CN для кластера Selena shared-data. Значение по умолчанию: 9070.
storage_root_path
Каталог тома хранения, от которого зависят локально кэшированные данные. Несколько томов разделяются точкой с запятой (;). Пример: /data1;/data2.
Значение по умолчанию для storage_root_path — ${STARROCKS_HOME}/storage.
Локальный кэш эффективен, когда запросы выполняются часто и запрашиваемые данные являются свежими, но есть случаи, когда вы можете захотеть полностью отключить локальный кэш.
- В среде Kubernetes с подами CN, которые масштабируются вверх и вниз по требованию, к подам могут не быть подключены тома хранения.
- Когда запрашиваемые данные находятся в озере данных в удаленном хранилище и большая их часть представляет собой архивные (старые) данные. Если запросы выполняются редко, кэш данных будет иметь низкий коэффициент попаданий, и преимущества могут не оправдывать наличие кэша.
Чтобы отключить кэш данных, установите:
storage_root_path =
ПРИМЕЧАНИЕ
Данные кэшируются в каталоге
<storage_root_path>/starlet_cache.
Использование вашего кластера Selena с shared-data
Использование кластеров Selena с общими данными также аналогично использованию классического кластера Selena с изолированными данными, за исключением того, что кластер с общими данными использует тома хранения и облачные таблицы для хранения данных в объектном хранилище.
Создание тома хранения по умолчанию
Вы можете использовать встроенные тома хранения, которые Selena создает автоматически, или вручную создать и установить том хранения по умолчанию. В этом разделе описывается, как вручную создать и установить том хранения по умолчанию.
ПРИМЕЧАНИЕ
Если ваш кластер Selena с общими данными был обновлен с версии v3.0, вам не нужно определять том хранения по умолчанию, поскольку Selena создала его с параметрами объектного хранилища, которые вы указали в конфигурационном файле FE fe.conf. Вы все еще можете создавать новые тома хранения с другими ресурсами объектного хранилища и по-разному устанавливать том хранения по умолчанию.
Чтобы предоставить вашему кластеру Selena с общими данными разрешение на хранение данных в вашем объектном хранилище, вы должны ссылаться на том хранения при создании баз данных или облачных таблиц. Том хранения состоит из свойств и учетных данных удаленного хранилища данных. Если вы развернули новый кластер Selena с общими данными и запретили Selena создавать встроенный том хранения (указав enable_load_volume_from_conf как false), вы должны определить том хранения по умолчанию, прежде чем сможете создавать базы данных и таблицы в к�ластере.
Следующий пример создает том хранения def_volume для GCS bucket defaultbucket с HMAC Access Key и Secret Key, включает функцию Partitioned Prefix и устанавливает его как том хранения по умолчанию:
CREATE STORAGE VOLUME def_volume
TYPE = S3
LOCATIONS = ("s3://defaultbucket")
PROPERTIES
(
"enabled" = "true",
"aws.s3.region" = "us-east1",
"aws.s3.endpoint" = "https://storage.googleapis.com",
"aws.s3.access_key" = "<HMAC access key>",
"aws.s3.secret_key" = "<HMAC secret key>",
"aws.s3.enable_partitioned_prefix" = "true"
);
SET def_volume AS DEFAULT STORAGE VOLUME;
Для получения дополнительной информации о том, как создать storage volume для других объектных хранилищ и установить storage volume по умолчанию, см. CREATE STORAGE VOLUME и SET DEFAULT STORAGE VOLUME.
Создание базы данных и облачной таблицы
После создания storage volume по умолчанию вы можете создать базу данных и облачную таблицу, используя этот storage volume.
Кластеры Selena с разделяемыми данными поддерживают все типы таблиц Selena.
Следующий пример создает базу данных cloud_db и таблицу detail_demo на основе типа таблицы Duplicate Key, включает локальный дисковый кеш, устанавливает срок действия горячих данных на один месяц и отключает асинхронную загрузку данных в объектное хранилище:
CREATE DATABASE cloud_db;
USE cloud_db;
CREATE TABLE IF NOT EXISTS detail_demo (
recruit_date DATE NOT NULL COMMENT "YYYY-MM-DD",
region_num TINYINT COMMENT "range [-128, 127]",
num_plate SMALLINT COMMENT "range [-32768, 32767] ",
tel INT COMMENT "range [-2147483648, 2147483647]",
id BIGINT COMMENT "range [-2^63 + 1 ~ 2^63 - 1]",
password LARGEINT COMMENT "range [-2^127 + 1 ~ 2^127 - 1]",
name CHAR(20) NOT NULL COMMENT "range char(m),m in (1-255) ",
profile VARCHAR(500) NOT NULL COMMENT "upper limit value 65533 bytes",
ispass BOOLEAN COMMENT "true/false")
DUPLICATE KEY(recruit_date, region_num)
DISTRIBUTED BY HASH(recruit_date, region_num)
PROPERTIES (
"storage_volume" = "def_volume",
"datacache.enable" = "true",
"datacache.partition_duration" = "1 MONTH"
);
ПРИМЕЧАНИЕ
Storage volume по умолчанию используется при создании базы данных или облачной таблицы в кластере Selena с разделяемыми данными, если storage volume не указан.
В дополнение к обычным PROPERTIES таблицы, вам необходимо указать следующие PROPERTIES при создании таблицы для кластера Selena с разделяемыми данными:
datacache.enable
Включить ли локальный дисковый кеш.
true(По умолчанию) Когда это свойство установлено вtrue, загружаемые данные одновременно записываются в объектное хранилище и на локальный диск (в качестве кеша для ускорения запросов).falseКогда это свойство установлено вfalse, данные загружаются только в объектное хранилище.
ПРИМЕЧАНИЕ
В версии 3.0 это свойство называлось
enable_storage_cache.Чтобы включить локальный дисковый кеш, необходимо указать директорию диска в параметре конфигурации CN
storage_root_path.
datacache.partition_duration
Срок действия горячих данных. Когда локальный дисковый кеш включен, все данные загружаются в кеш. Когда кеш заполняется, Selena удаляет менее недавно используемые данные из кеша. Когда запрос требует сканирования удаленных данных, Selena проверяет, находятся ли данные в пределах срока действия, начиная с текущего времени. Если данные находятся в пределах срока действия, Selena снова загружает данные в кеш. Если данные не находятся в пределах срока действия, Selena не загружает их в кеш. Это свойство представляет собой строковое значение, которое может быть указано со следующими единицами: YEAR, MONTH, DAY и HOUR, например, 7 DAY и 12 HOUR. Если не указано, все данные кешируются как горячие данные.
ПРИМЕЧАНИЕ
В версии 3.0 это свойство называлось
storage_cache_ttl.Это свойство доступно только когда
datacache.enableустановлено вtrue.
Просмотр информации о таблице
Вы можете просмотреть информацию о таблицах в конкретной базе данных, используя SHOW PROC "/dbs/<db_id>". См. SHOW PROC для получения дополнительной информации.
Приме�р:
mysql> SHOW PROC "/dbs/xxxxx";
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
| TableId | TableName | IndexNum | PartitionColumnName | PartitionNum | State | Type | LastConsistencyCheckTime | ReplicaCount | PartitionType | StoragePath |
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
| 12003 | detail_demo | 1 | NULL | 1 | NORMAL | CLOUD_NATIVE | NULL | 8 | UNPARTITIONED | s3://xxxxxxxxxxxxxx/1/12003/ |
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
Type таблицы в кластере Selena с разделяемыми данными — CLOUD_NATIVE. В поле StoragePath Selena возвращает директорию объектного хранилища, где хранится таблица.
Загрузка данных в кластер Selena с разделяемыми данными
Кластеры Selena с разделяемыми данными поддерживают все методы загрузки, предоставляемые Selena. См. Варианты загрузки для получения дополнительной информации.
Запросы в кластере Selena с разделяемыми данными
Таблицы в кластере Selena с разделяемыми данными поддерживают все типы запросов, предоставляемые Selena. См. SELECT Selena для получения дополнительной информации.
ПРИМЕЧАНИЕ
Кластеры Selena с разделяемыми данными не поддерживают синхронные материализованные представления.