Dataphin
Dataphin - это облачная реализация внутренних практик методологии управления данными OneData группы Alibaba. Он предоставляет комплексное решение для интеграции, построения, управления и использования данных на протяжении всего жизненного цикла больших данных, помогая предприятиям значительно повысить уровень управления данными и создать корпоративную платформу данных с высоким и надёжным качеством, удобным потреблением, безопасным и экономичным производством. Dataphin обеспечивает поддержку различных вычислительных платформ и расширяемые открытые возможности для соответствия архитектуре технической платформы и специфическим требованиям предприятий в различных отраслях.
Существует несколько способов интеграции Dataphin с Selena:
-
В качестве источника или целевого источника данных для интеграции данных. Данные могут читаться из Selena и передаваться в другие источники данных, или данные могут извлекаться из других источников данных и записываться в Selena.
-
В качестве исходной таблицы (неограниченное сканирование), таблицы измерений (ограниченное сканирование) или таблицы результатов (потоковая и пакетная запись) для разработки Flink SQL и datastream.
-
В качестве хранилища данных или витрины данных. Selena может быть зарегистрирована как вычислительный источник, который может использоваться для разработки SQL-скриптов, планирования, обнаружения качества данных, идентификации безопасности и других задач исследования и управления данными.
Интеграция данных
Вы можете создавать источники данных Selena и использовать их в качестве исходных или целевых баз данных в задачах офлайн-интеграции. Процедура следующая:
Создание источника данных Selena
Основная информация
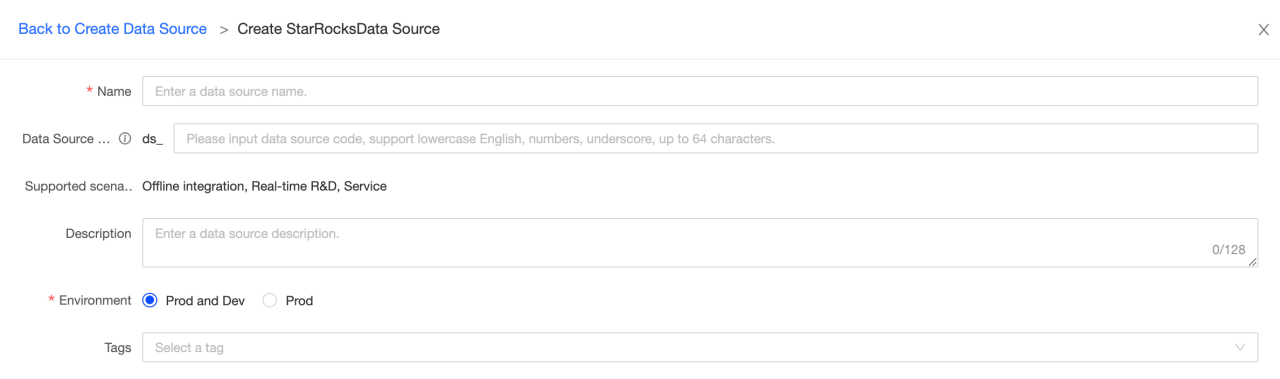
-
Name: Обязательно. Введите имя источника данных. Может содержать только китайские символы, буквы, цифры, подчёркивания (_) и дефисы (-). Не может превышать 64 символа.
-
Data source code: Необязательно. После настройки кода источника данных вы можете использовать формат
код источника данных.таблицаиликод источника данных.схема.таблицадля ссылки на Flink SQL в исто�чнике данных. Если вы хотите автоматически получить доступ к источнику данных в соответствующей среде, используйте формат${код источника данных}.таблицаили${код источника данных}.схема.таблица.ПРИМЕЧАНИЕ
В настоящее время поддерживаются только источники данных MySQL, Hologres и MaxCompute.
-
Support scenerios: Сценарии, в которых может применяться источник данных.
-
Description: Необязательно. Вы можете ввести краткое описание источника данных. Максимум 128 символов.
-
Environment: Если бизнес-источник данных различает производственный и разрабатываемый источник данных, выберите Prod and Dev. Если бизнес-источник данных не различает производственный и разрабатываемый источники данных, выберите Prod.
-
Tags: Вы можете выбрать теги для маркировки источников данных.
Информация о конфигурации

-
JDBC URL: Обязательно. Формат:
jdbc:mysql://<host>:<port>/<dbname>.host- это IP-адрес хоста FE (Front End) в cluster Selena,port- порт запросов FE, аdbname- имя базы данных. -
Load URL: Обязательно. Формат:
fe_ip:http_port;fe_ip:http_port.fe_ip- это хост FE (Front End), аhttp_port- порт FE. -
Username: Обязательно. Имя пользователя базы данных.
-
Password: Обязательно. Пароль базы данных.
Расширенные настройки

-
connectTimeout: таймаут подключения (в мс) базы данных. Значение по умолчанию: 900000 миллисекунд (15 минут).
-
socketTimeout: таймаут сокета (в мс) базы данных. Значение по умолчанию: 1800000 миллисекунд (30 минут).
Чтение данных из источников данных Selena и запись данных в другие источники данных
Перетащите компонент ввода Selena на холст задачи офлайн-интеграции
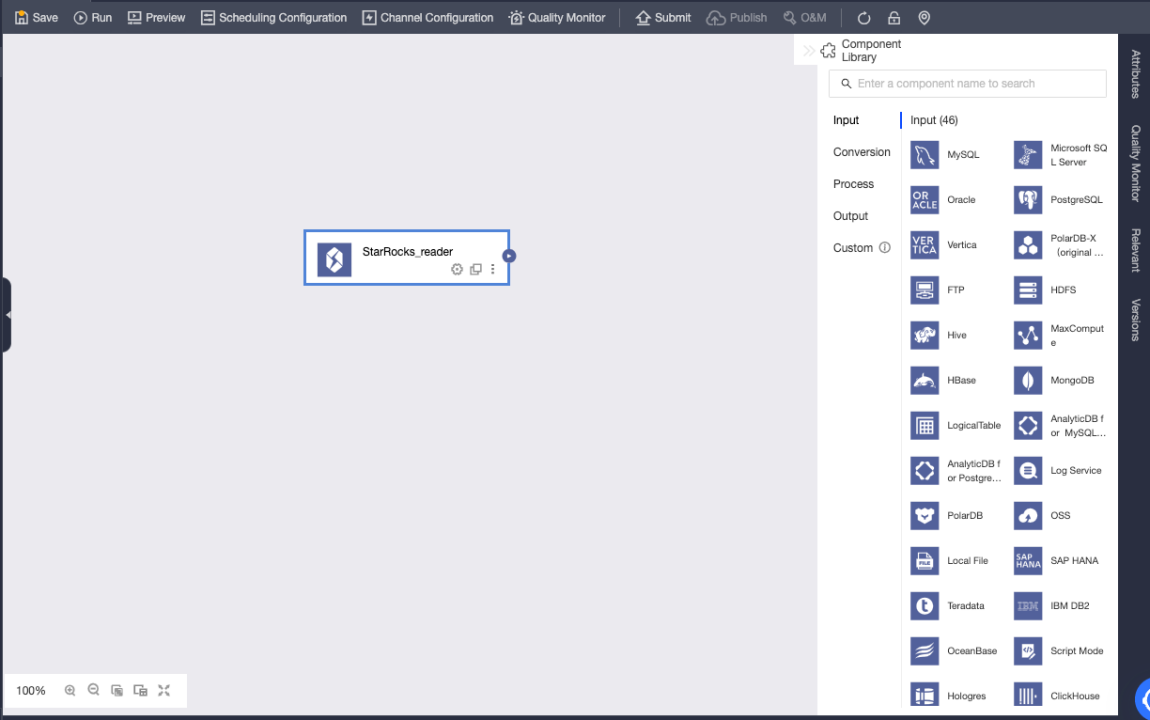
Конфигурация компонента ввода Selena
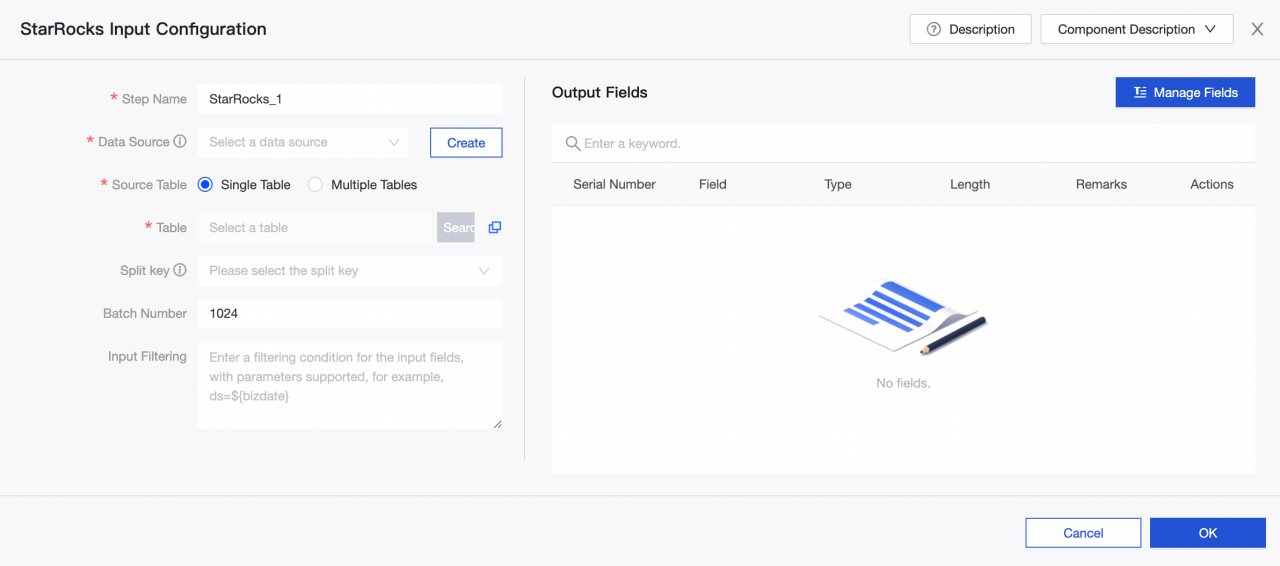
-
Step name: Введите подходящее имя на основе сценария и расположения текущего компонента.
-
Data source: Выберите источник данных Selena или проект, созданный в Dataphin. Требуется разрешение на чтение источника данных. Если подходящего источника данных нет, вы можете добавить источник данных или запросить соответствующие разрешения.
-
Source table: Выберите одну таблицу или несколько таблиц с одинаковой структурой в качестве входных данных.
-
Table: Выберите таблицу в источнике данных Selena из выпадающего списка.
-
Split key: Используется с конфигурацией параллелизма. Вы можете использовать столбец в исходной таблице данных в качестве ключа разделения. Рекомендуется использовать первичный ключ или индексированный столбец в качестве ключа разделения.
-
Batch number: Количество записей данных, извлекаемых в пакете.
-
Input Filtering: Необязательно.
В следующих двух случаях необходимо заполнить информацию о фильтре:
- Если вы хотите отфильтровать определённую часть данных.
- Если вам нужно инкрементально добавлять данные ежедневно или получать полные данные, необходимо заполнить дату, значение которой установлено как системное время консоли Dataphin. Например, таблица транзакций в Selena, и дата создания транзакции установлена как
${bizdate}.
-
Output fields: Список связанных полей на основе информации о входной таблице. Вы можете снова переименовывать, удалять, добавлять и перемещать поля. Как правило, поля переименовываются для повышения читаемости данных нижестоящего потока или для облегчения сопоставления полей при выводе. Поля могут быть удалены на этапе ввода, потому что соответствующие поля не нужны в сценариях применения. Порядок полей изменяется, чтобы гарантировать эффективное объединение данных или сопоставление выходных данных путём сопоставления полей с разными именами в одной строке при объединении или выводе нескольких входных данных на нижестоящей стороне.
Выберите и настройте компонент вывода в качестве целевого источника данных
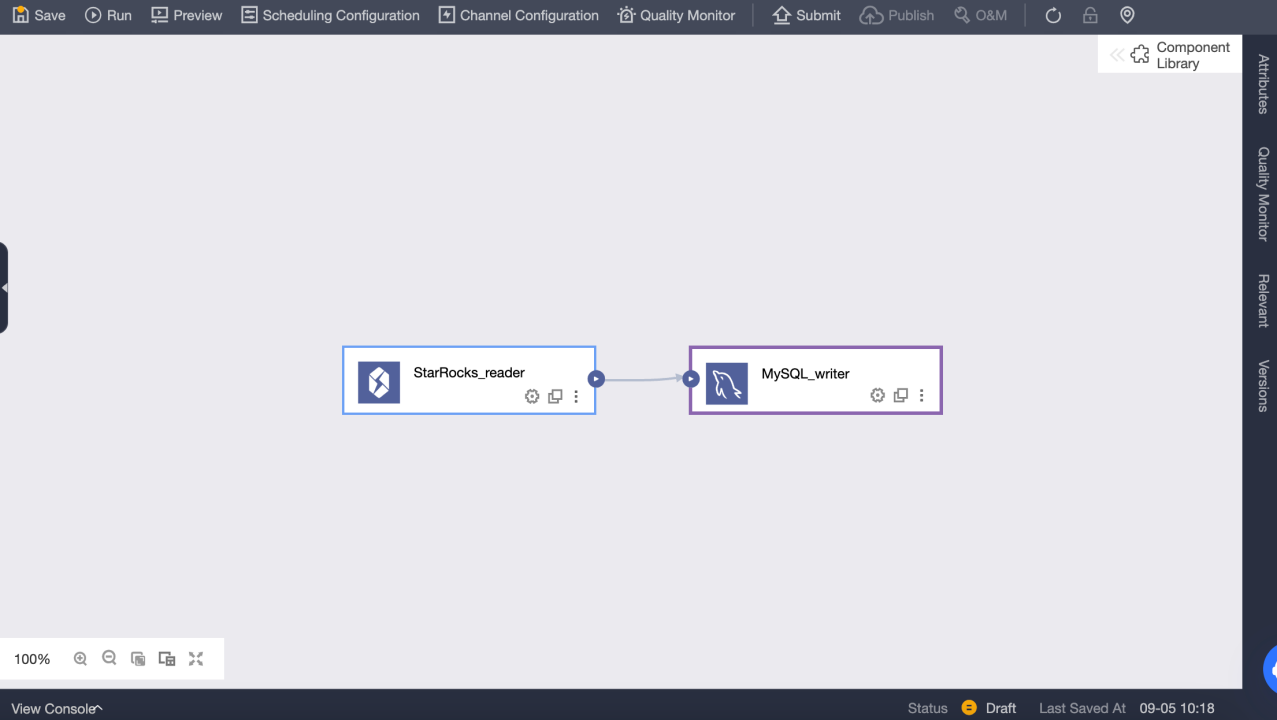
Чтение данных из других источников данных и запись данных в источники данных Selena
Настройте компонент ввода в задаче офлайн-интеграции и выберите и настройте компонент вывода Selena в качестве целевого источника данных
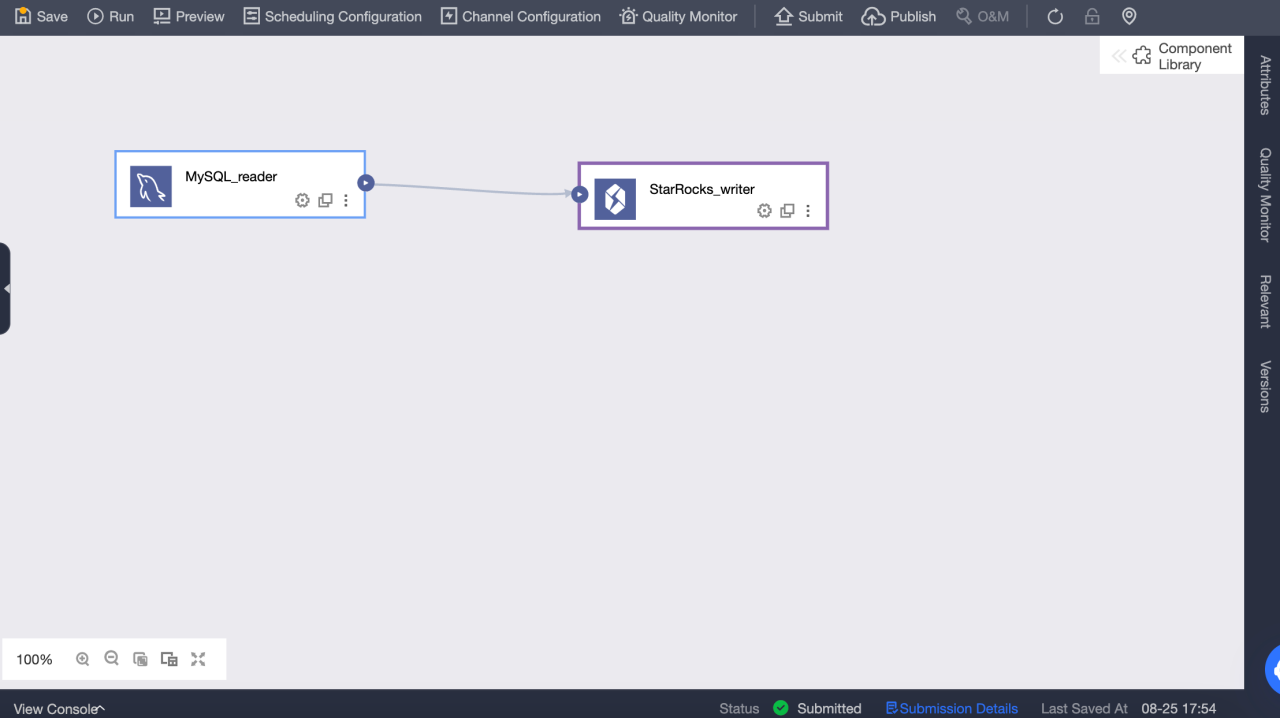
Конфигурация компонента вывода Selena
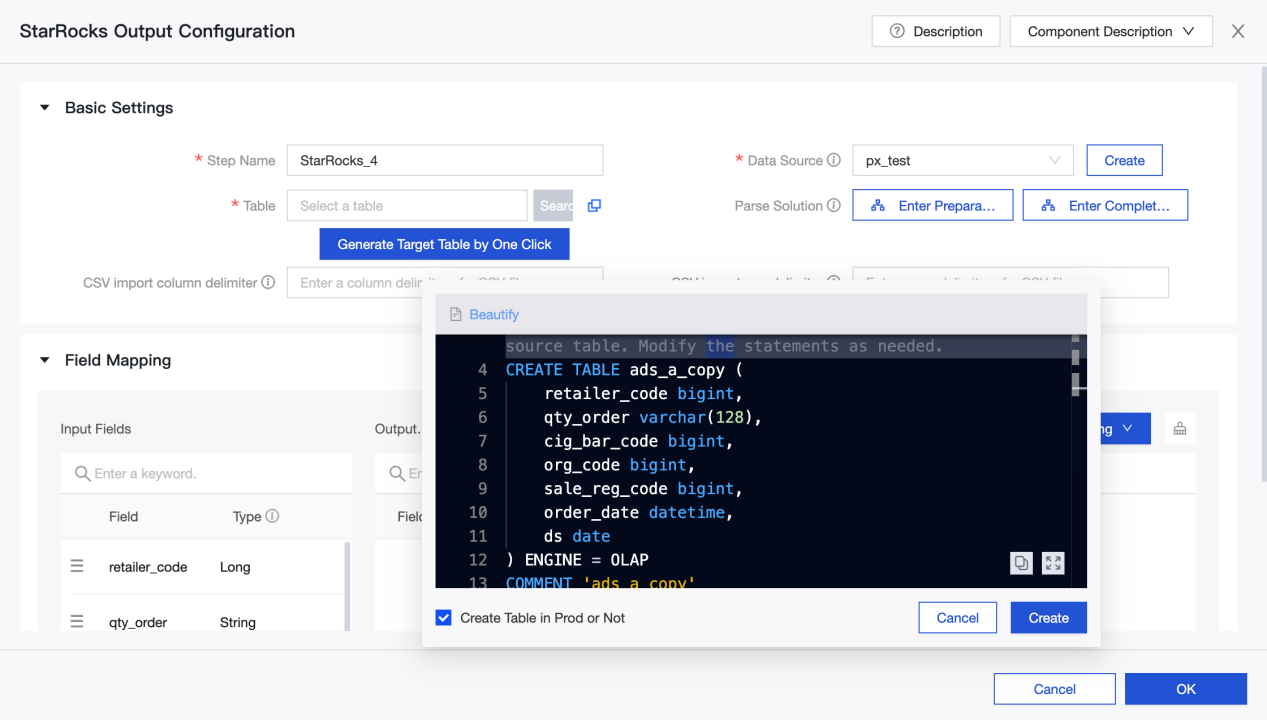
-
Step Name: Введите подходящее имя на основе сценария и расположения текущего компонента.
-
Data Source: Выберите источник данных или проект Dataphin, созданный в Selena. Источник данных, на который у конфигурирующего персонала есть разрешение на синхронную запись. Если источник данных не подходит, вы можете добавить источник данных или запросить соответствующие разрешения.
-
Table: Выберите таблицу в источнике данных Selena из выпадающего списка.
-
Generate Target Table by One Click: Если вы не создали целевую таблицу в источнике данных Selena, вы можете автоматически получить имя, тип и примечания полей, считанных из вышестоящего потока, и сгенерировать оператор создания таблицы. Нажмите для создания целевой таблицы одним щелчком.
-
CSV import column delimiter: Используйте StreamLoad CSV для импорта. В�ы можете настроить разделитель столбцов при импорте CSV. Значение по умолчанию
\t. Не указывайте здесь значение по умолчанию. Если сами данные содержат\t, необходимо использовать другие символы в качестве разделителей. -
CSV import row delimiter: Используйте StreamLoad CSV для импорта. Вы можете настроить разделитель строк при импорте CSV. Значение по умолчанию:
\n. Не указывайте здесь значение по умолчанию. Если сами данные содержат\n, необходимо использовать другие символы в качестве разделителей. -
Parse Solution: Необязательно. Это специальная обработка до или после записи данных. Подготовительный оператор выполняется перед записью данных в источник данных Selena, а оператор завершения выполняется после записи данных.
-
Field Mapping: Вы можете вручную выбрать поля для сопоставления или использовать сопоставление на основе имени или позиции для обработки нескольких полей одновременно на основе полей из вышестоящего ввода и полей в целевой таблице.
Разработка в реальном времени
Краткое введение
Selena - это быстрая и масштабируемая база данных для анализа в реальном времени. Она обычно используется в вычислениях реального времени для чтения и записи данных для удовлетворения потребностей анализа и запросов данных в реальном времени. Она широко используется в корпоративных сценариях вычислений реального времени. Может использоваться в мониторинге и анализе бизнеса в реальном времени, анализе поведения пользователей в реальном времени, системах торгов рекламой в реальном времени, контроле рисков в реальном времени, защите от мошенничества, мониторинге и раннем предупреждении в реальном времени и других прикладных сценариях. Анализируя и запрашивая данные в реальном времени, предприятия могут быстро понимать условия бизнеса, оптимизировать решения, предоставлять лучшие услуги и защищать свои интересы.
Selena Connector
Коннектор Selena поддерживает следующую информацию:
| Категория | Факты и цифры |
|---|---|
| Поддерживаемые типы | Исходная таблица, таблица измерений, таблица результатов |
| Режим работы | Потоковый режим и пакетный режим |
| Формат данных | JSON и CSV |
| Специальные метрики | Нет |
| Тип API | Datastream и SQL |
| Поддержка обновления или удаления данных в таблице результатов? | Да |
Как использовать?
Dataphin поддерживает источники данных Selena в качестве целей чтения и записи для вычислений реального времени. Вы можете создавать мета-таблицы Selena и использовать их для задач вычислений реального времени:
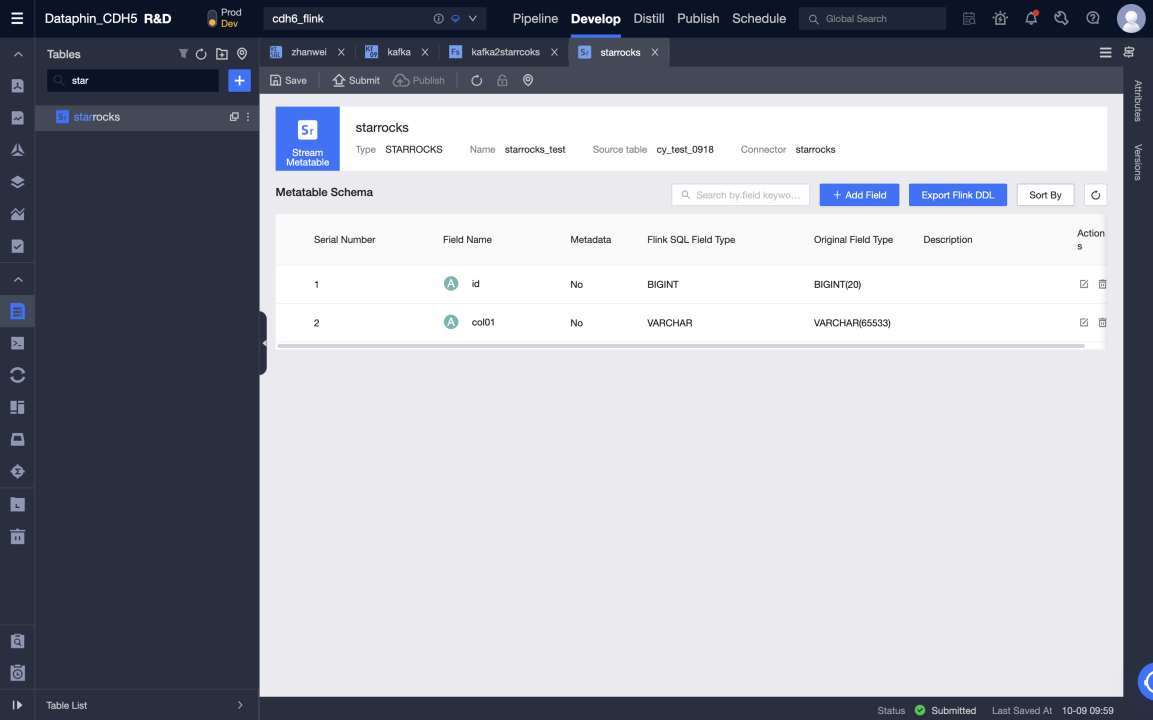
Создание мета-таблицы Selena
-
Перейдите в Dataphin > R & D > Develop > Tables.
-
Нажмите Create для выбора таблицы вычислений реального времени.
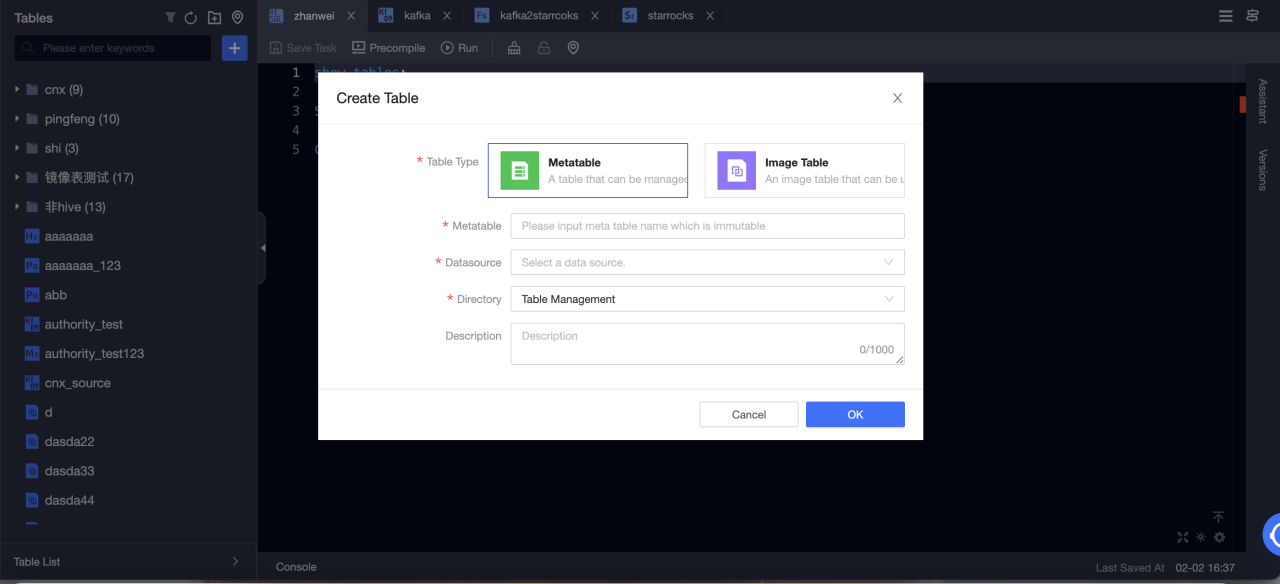
-
Table type: Выберите Metatable.
-
Metatable: Введите имя мета-таблицы. Имя неизменяемо.
-
Datasource: Выберите источник данных Selena.
-
Directory: Выберите каталог, в котором вы хотите создать таблицу.
-
Description: Необязательно.
-
-
После создания мета-таблицы вы можете редактировать мета-таблицу, включая изменение источников данных, исходных таблиц, полей мета-таблицы и настройку параметров мета-таблицы.
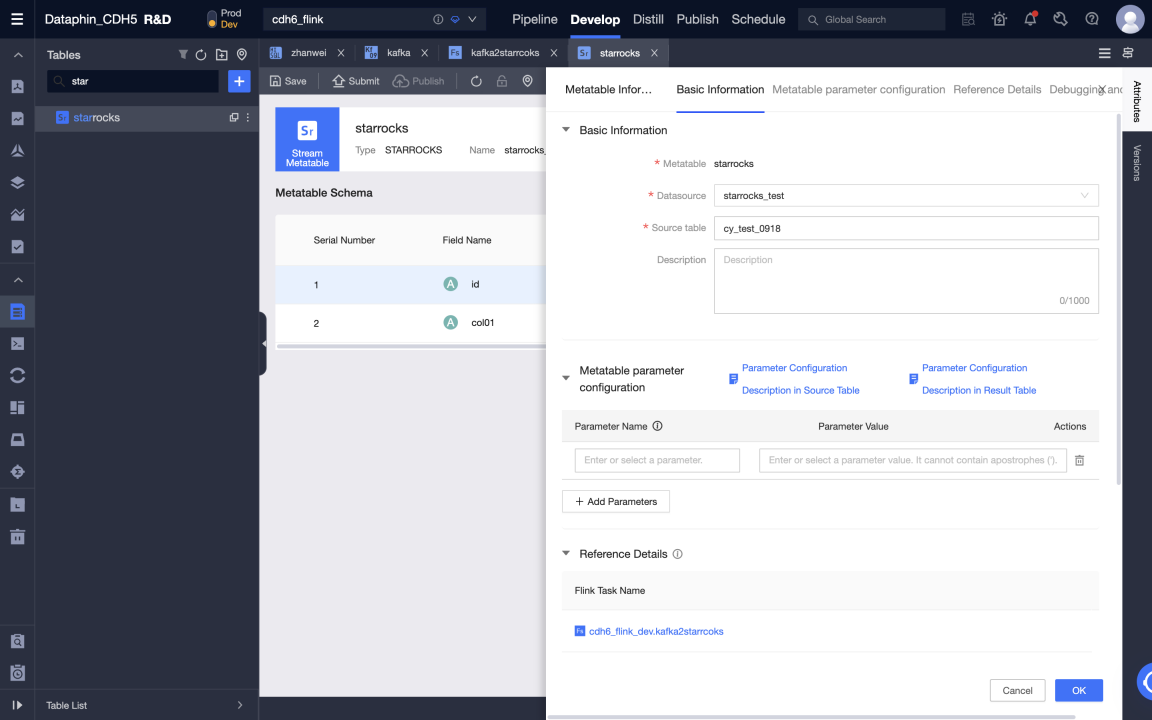
-
Отправьте мета-таблицу.
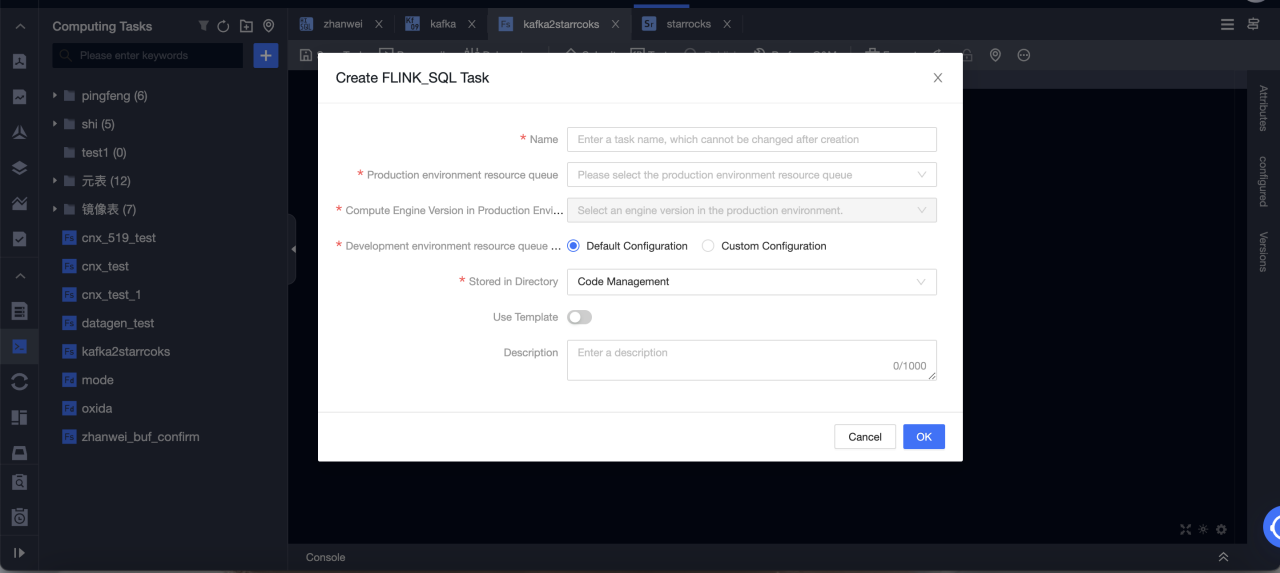
Создание задачи Flink SQL для записи данных из Kafka в Selena в реальном времени
-
Перейдите в Dataphin > R & D > Develop > Computing Tasks.
-
Нажмите Create Flink SQL task.
-
Отредактируйте код Flink SQL и предварительно скомпилируйте его. Мета-таблица Kafka используется как входная таблица, а мета-таблица Selena - как выходная таблица.
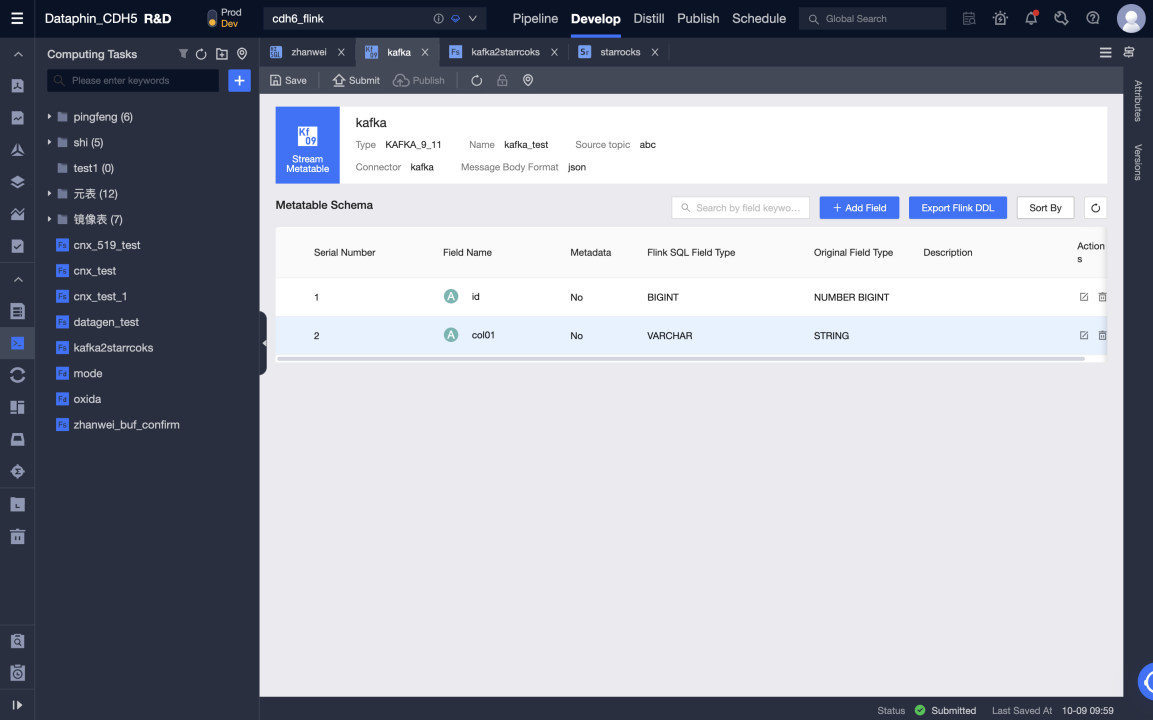
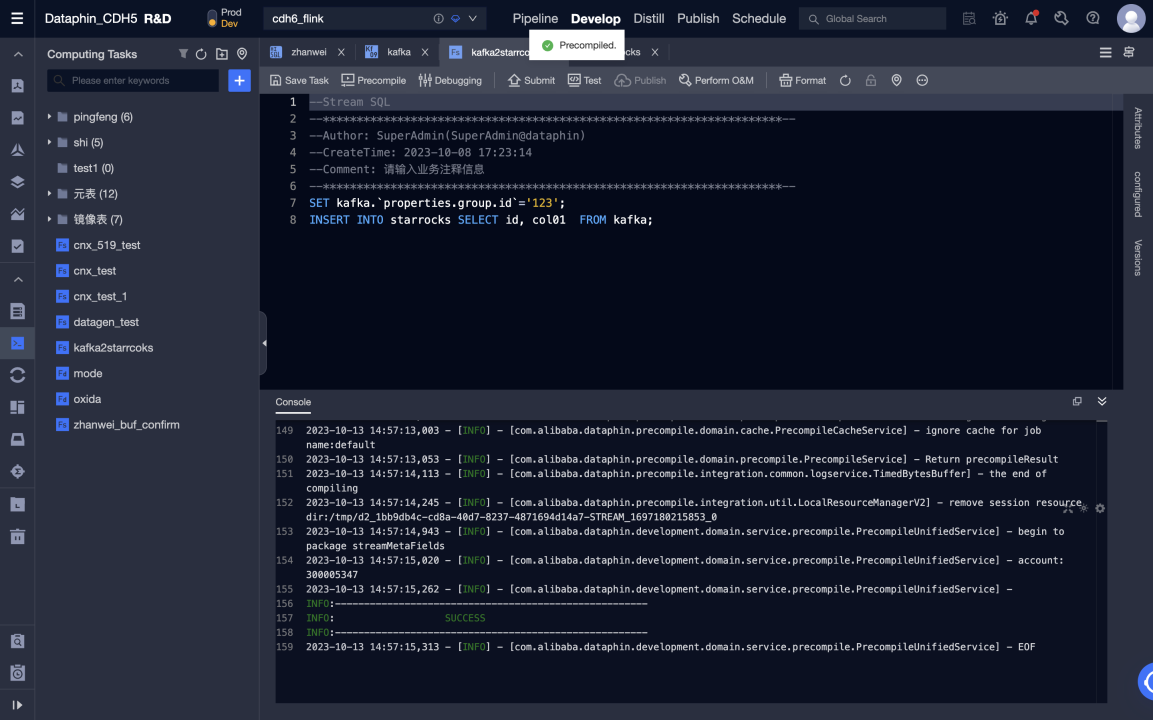
-
После успешной предварительной компиляции вы можете отладить и отправить код.
-
Тестирование в среде разработки может выполняться путём печати логов и записи тестовых таблиц. Тестовые таблицы можно установить в Meta Tables > Properties > debugging test configurations.
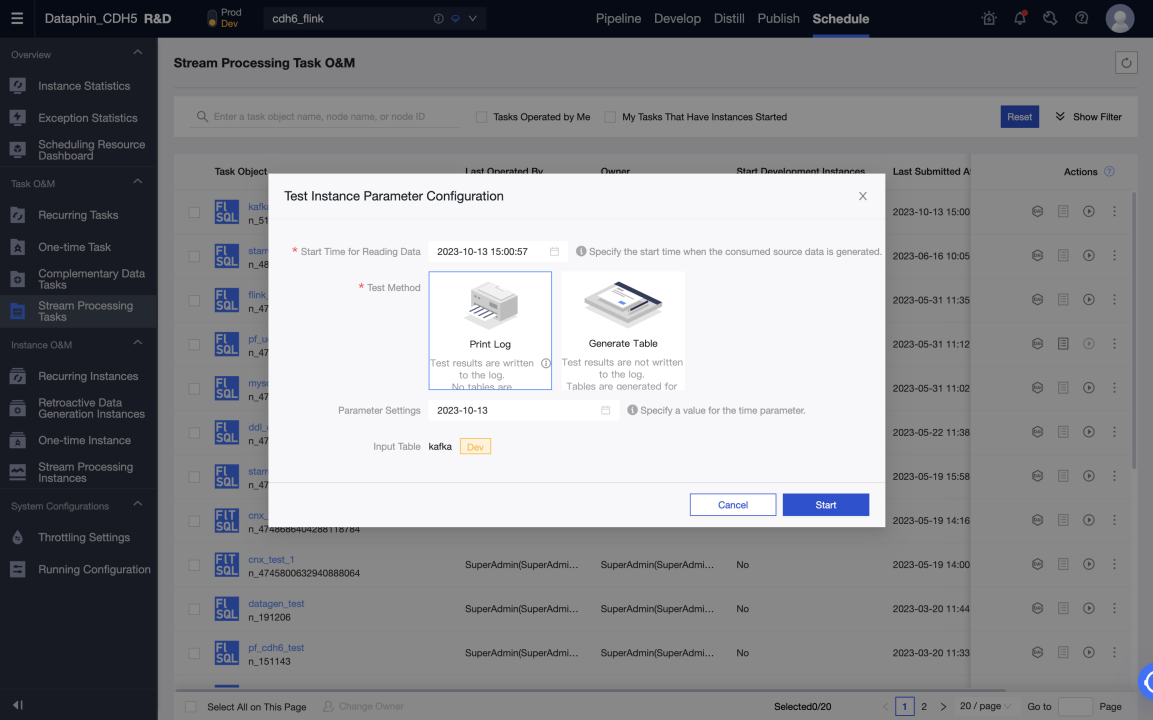
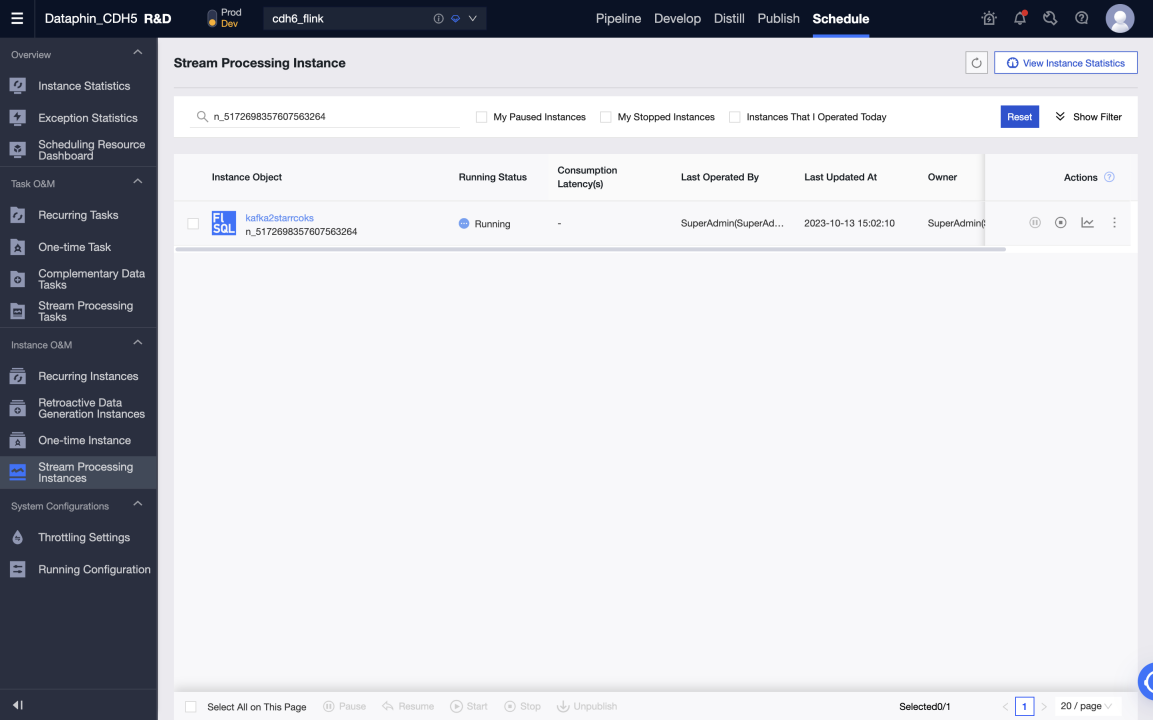
-
После нормальной работы задачи в среде разработки вы можете опубликовать задачу и используемую мета-таблицу в производственную среду.
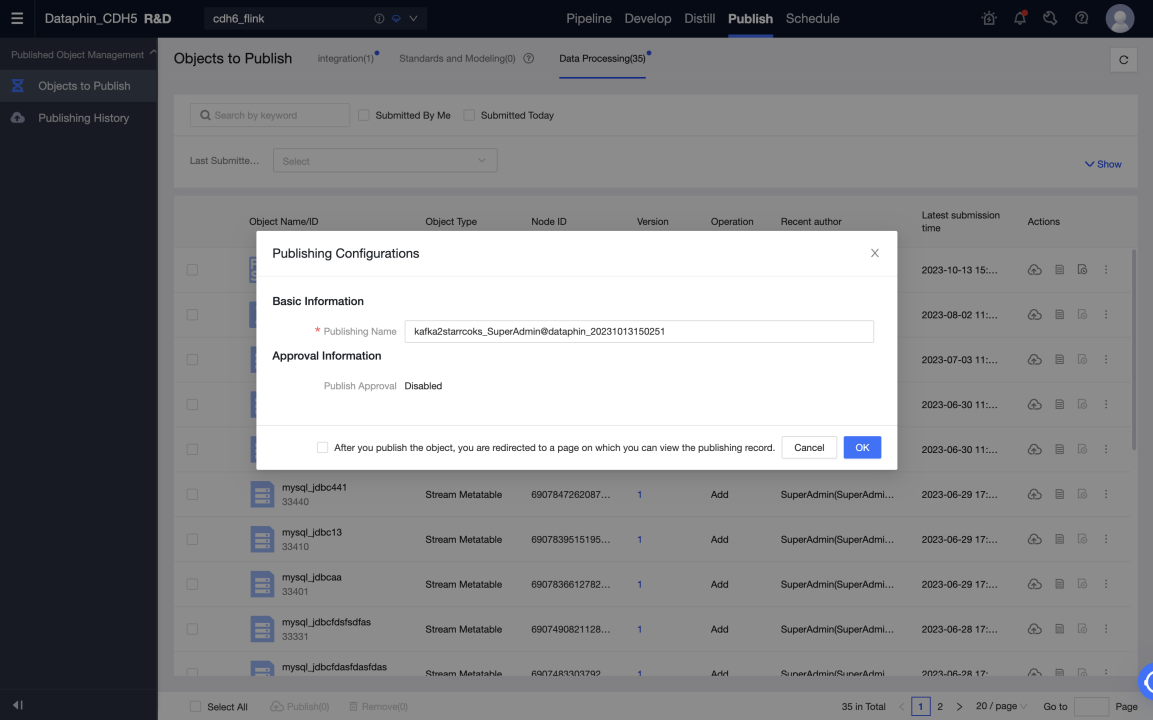
-
Запустите задачу в производственной среде для записи данных из Kafka в Selena в реальном времени. Вы можете просматривать статус и логи каждой метрики в анализе выполнения, чтобы узнать о статусе выполнения задачи, или настроить оповещения мониторинга для задачи.
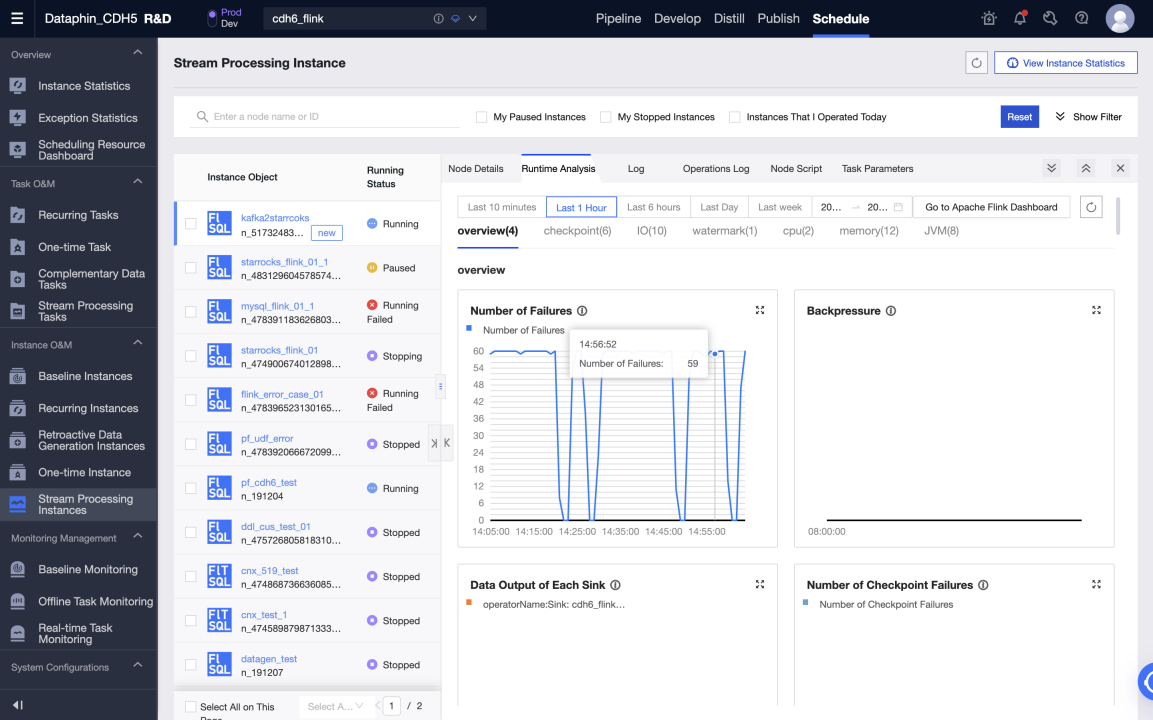
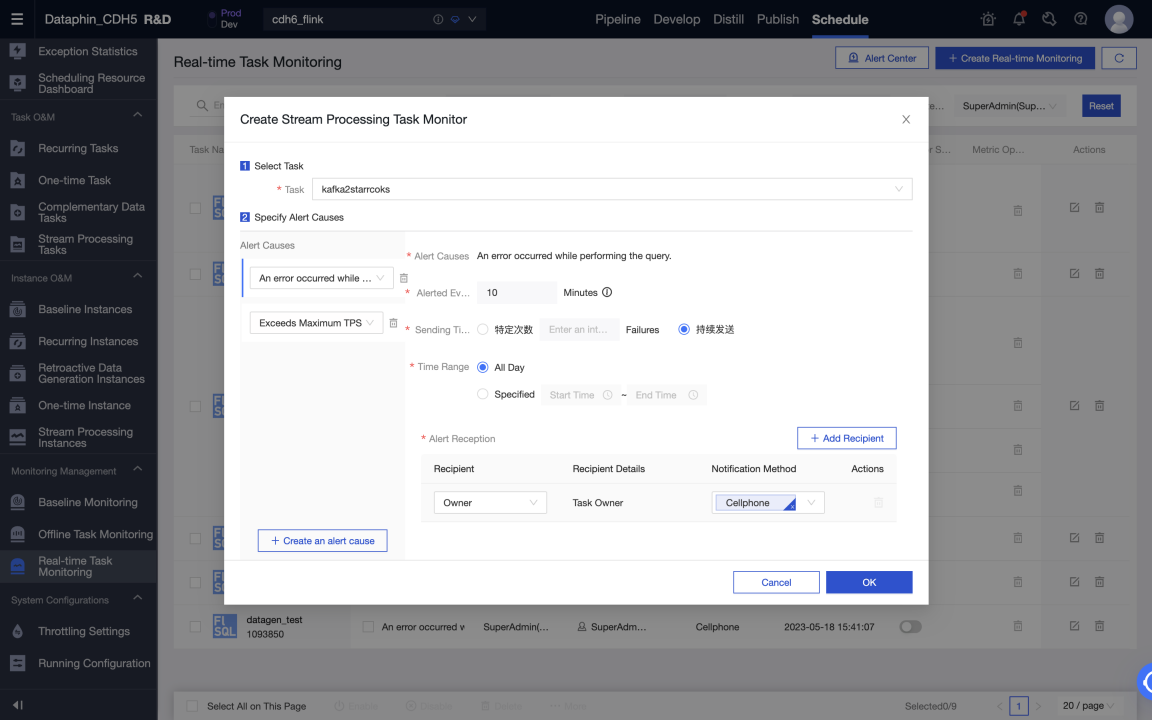
Хранилище данных или витрина данных
Предварительные требования
-
Версия Selena 3.0.6 или выше.
-
Dataphin установлен, и версия Dataphin 3.12 или выше.
-
Сбор статистики должен быть включён. После установки Selena сбор включён по умолчанию. Подробнее см. Сбор статистики для CBO.
-
Поддерживается внутренний каталог Selena (каталог по умолчанию), внешний каталог не поддерживается.
Ко�нфигурация подключения
Настройки хранилища метаданных
Dataphin может представлять и отображать информацию на основе метаданных, включая информацию об использовании таблиц и изменения метаданных. Вы можете использовать Selena для обработки и расчёта метаданных. Поэтому перед использованием необходимо инициализировать вычислительный движок метаданных (хранилище метаданных). Процедура следующая:
-
Используйте учётную запись администратора для входа в арендатора хранилища метаданных Dataphin
-
Перейдите в Administration > System > Metadata Warehouse Configuration
a. Нажмите Start
b. Выберите Selena
c. Настройте параметры. После прохождения тестового подключения нажмите далее.
d. Завершите инициализацию хранилища метаданных
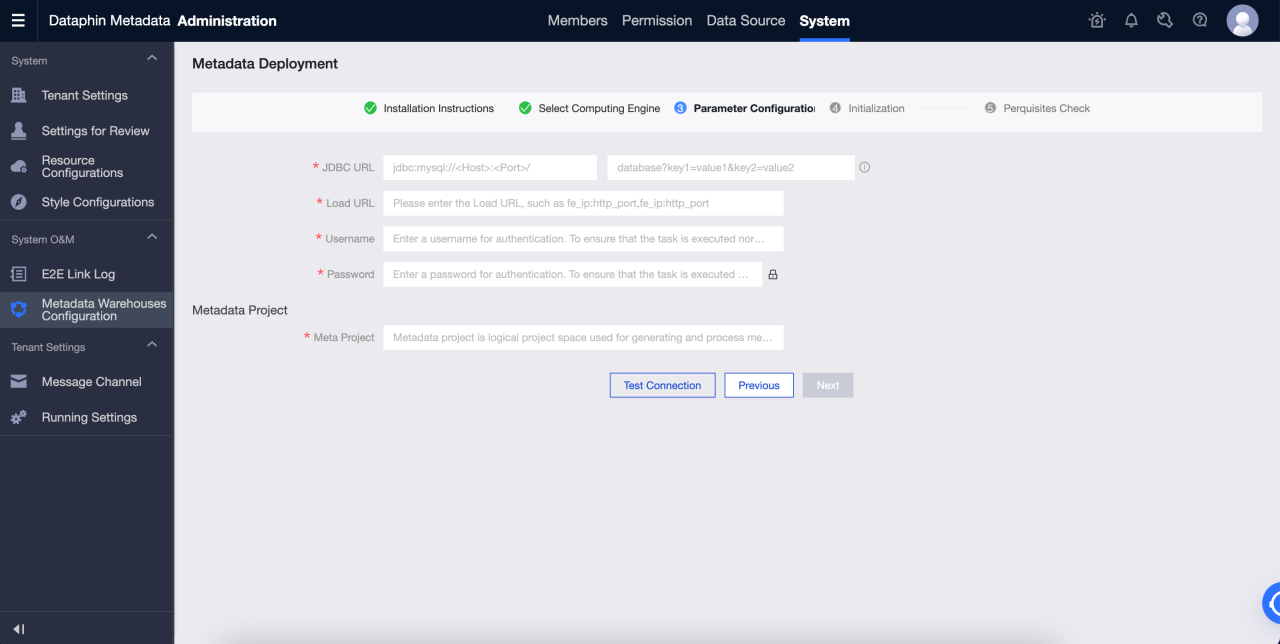
Параметры описаны следующим образом:
-
JDBC URL: Строка подключения JDBC, которая делится на две части:
-
Часть I: Формат
jdbc:mysql://<Host>:<Port>/.Host- это IP-адрес хоста FE в cluster Selena.Port- порт запросов FE. Значение по умолчанию:9030. -
Часть II: формат
database? key1 = value1 & key2 = value2, гдеdatabase- это имя базы данных Selena, используемой для расчёта метаданных, которое обязательно. Параметр после '?' необязателен.
-
-
Load URL: Формат
fe_ip:http_port;fe_ip:http_port.fe_ip- это хост FE (Front End), аhttp_port- порт FE. -
Username: Имя пользователя для подключения к Selena.
Пользователь должен иметь разрешения на чтение и запись в базу данных, указанную в JDBC URL, и должен иметь разрешения на доступ к следующим базам данных и таблицам:
-
Все таблицы в Information Schema
-
statistics.column_statistics
-
statistics.table_statistic_v1
-
-
Password: Пароль для подключения к Selena.
-
Meta Project: Имя �проекта, используемого для обработки метаданных в Dataphin. Используется только внутри системы Dataphin. Рекомендуется использовать
dataphin_metaв качестве имени проекта.
Создание проекта Selena и начало разработки данных
Чтобы начать разработку данных, выполните следующие шаги:
-
Настройки вычислений.
-
Создайте вычислительный источник Selena.
-
Создайте проект.
-
Создайте задачу Selena SQL.
Настройки вычислений
Настройки вычислений устанавливают тип вычислительного движка и адрес cluster арендатора. Подробные шаги следующие:
-
Войдите в Dataphin как системный администратор или �суперадминистратор.
-
Перейдите в Administration > System > Computation Configuration.
-
Выберите Selena и нажмите Next.
-
Введите JDBC URL и проверьте его. Формат JDBC URL:
jdbc:mysql://<Host>:<Port>/.Host- это IP-адрес хоста FE в cluster Selena.Port- порт запросов FE. Значение по умолчанию:9030.
Вычислительный источник Selena
Вычислительный источник - это концепция Dataphin. Его основная цель - связать и зарегистрировать пространство проекта Dataphin с пространством хранения и вычислений Selena (базой данных). Вы должны создать вычислительный источник для каждого проекта. Подробные шаги следующие:
-
Войдите в Dataphin как системный администратор или суперадминистратор.
-
Перейдите в Planning > Engine.
-
Нажмите Add Computing Engine в правом верхнем углу для создания вычислительного источника.
Подробная информация о конфигурации следующая:
-
Основная информация
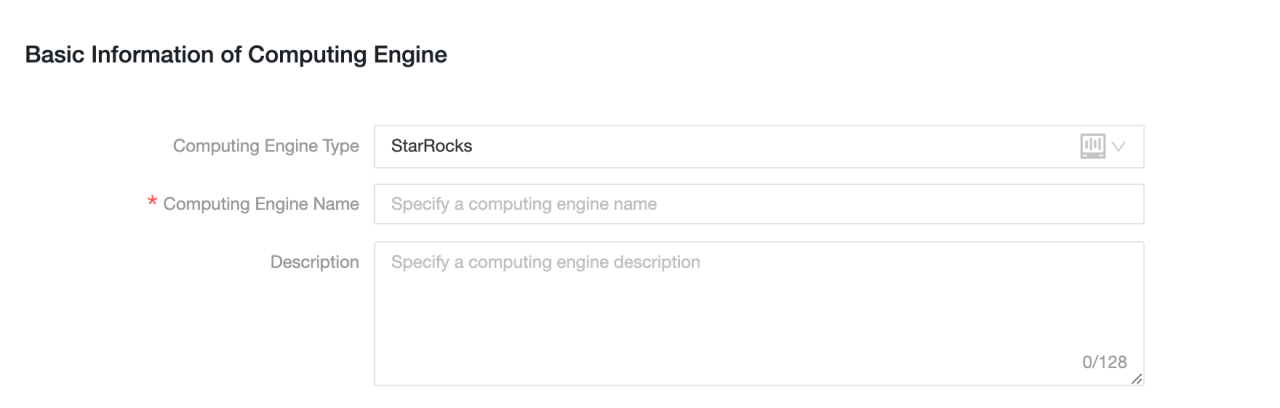
-
Computing Engine Type: Выберите Selena.
-
Computing Engine Name: Рекомендуется использовать то же имя, что и у создаваемого проекта. Для проектов разработки добавьте суффикс
_dev. -
Description: Необязательно. Введите описание вычислительного источника.
-
-
Информация о конфигурации
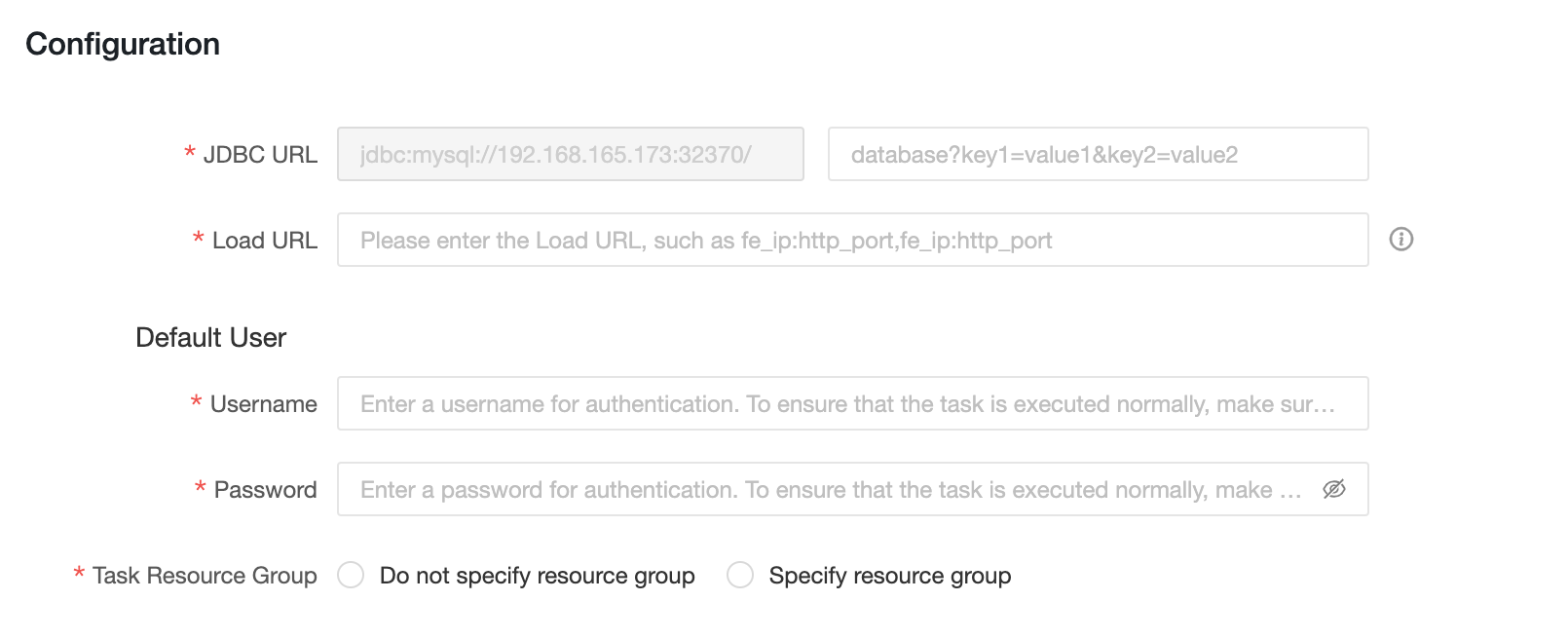
-
JDBC URL: Формат
jdbc:mysql://<Host>:<Port>/.Host- это IP-адрес хоста FE в cluster Selena.Port- порт запросов FE. Значение по умолчанию:9030. -
Load URL: Формат
fe_ip:http_port;fe_ip:http_port.fe_ip- это хост FE (Front End), аhttp_port- порт FE. -
Username: Имя пользователя для подключения к Selena.
-
Password: Пароль Selena.
-
Task Resource Group: вы можете указать разные группы ресурсов Selena для задач с разными приоритетами. Когда вы выбираете не указывать группу ресурсов, движок Selena определяет группу ресурсов для выполнения. Когда вы выбираете указать группу ресурсов, задачи с разными приоритетами назначаются указанной группе ресурсов Dataphin. Если группа ресурсов указана в коде SQL-задачи или в материализованной конфигурации логической таблицы, конфигурация группы ресурсов задачи вычислительного источника игнорируется при выполнении задачи.
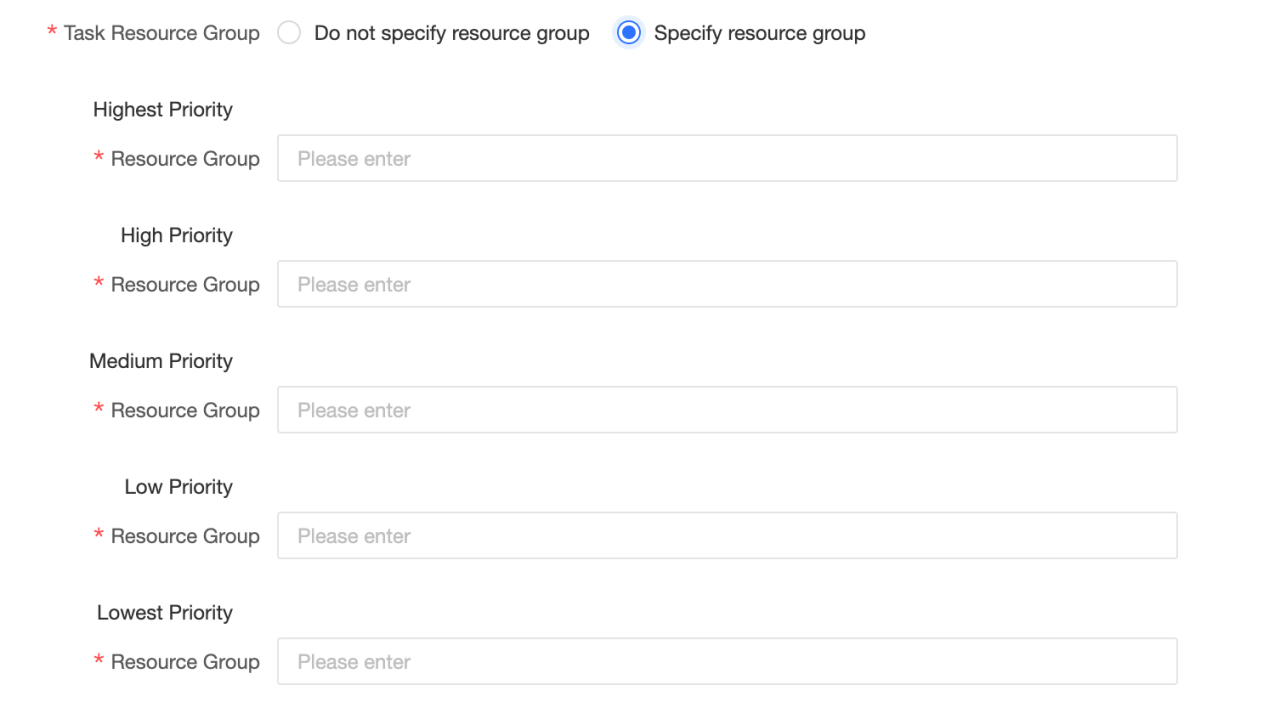
-
Проект Dataphin
После создания вычислительного источника вы можете привязать его к проекту Dataphin. Проект Dataphin управляет участниками проекта, хранилищем и вычислительным пространством Selena, а также управляет и поддерживает вычислительные задачи.
Чтобы создать проект Dataphin, выполните следующие шаги:
-
Войдите в Dataphin как системный администратор или суперадминистратор.
-
Перейдите в Planning > Project Management.
-
Нажмите Create project в правом верхнем углу для создания проекта.
-
Введите основную информацию и выберите движок Selena, созданный на предыдущем шаге, из офлайн-движка.
-
Нажмите Create.
Selena SQL
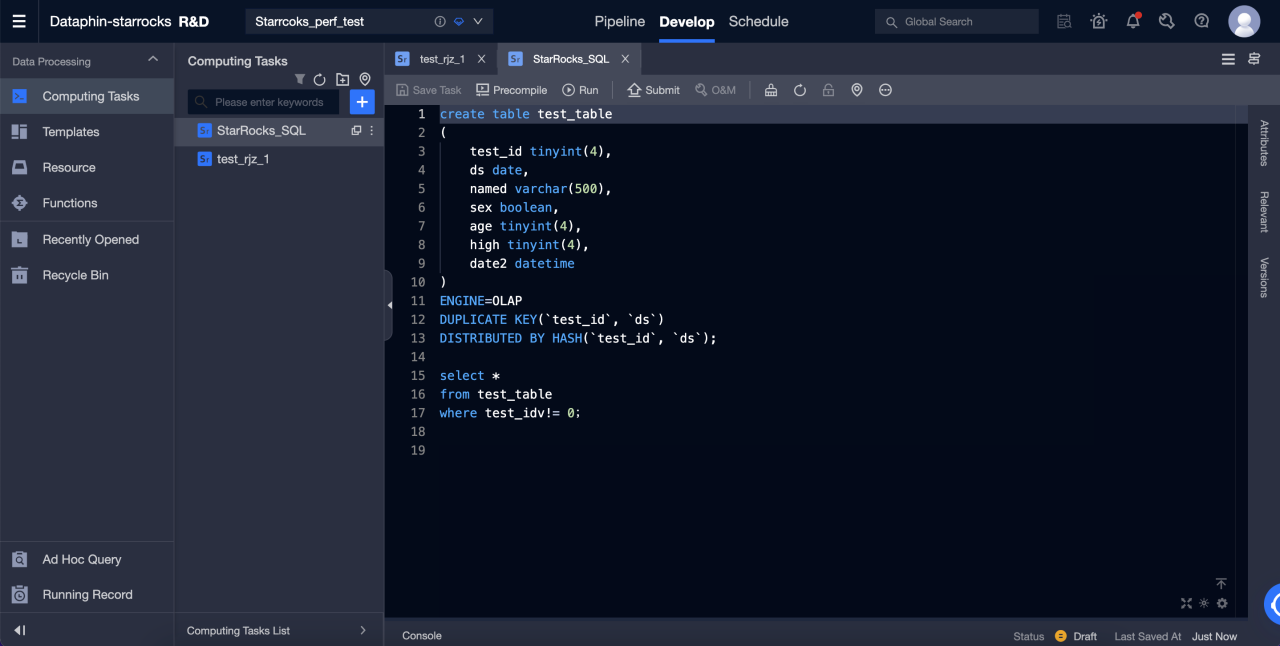
После создания проекта вы можете создать задачу Selena SQL для выполнения операций DDL или DML в Selena.
Подробные шаги следующие:
-
Перейдите в R & D > Develop.
-
Нажмите '+' в правом верхнем углу для создания задачи Selena SQL.
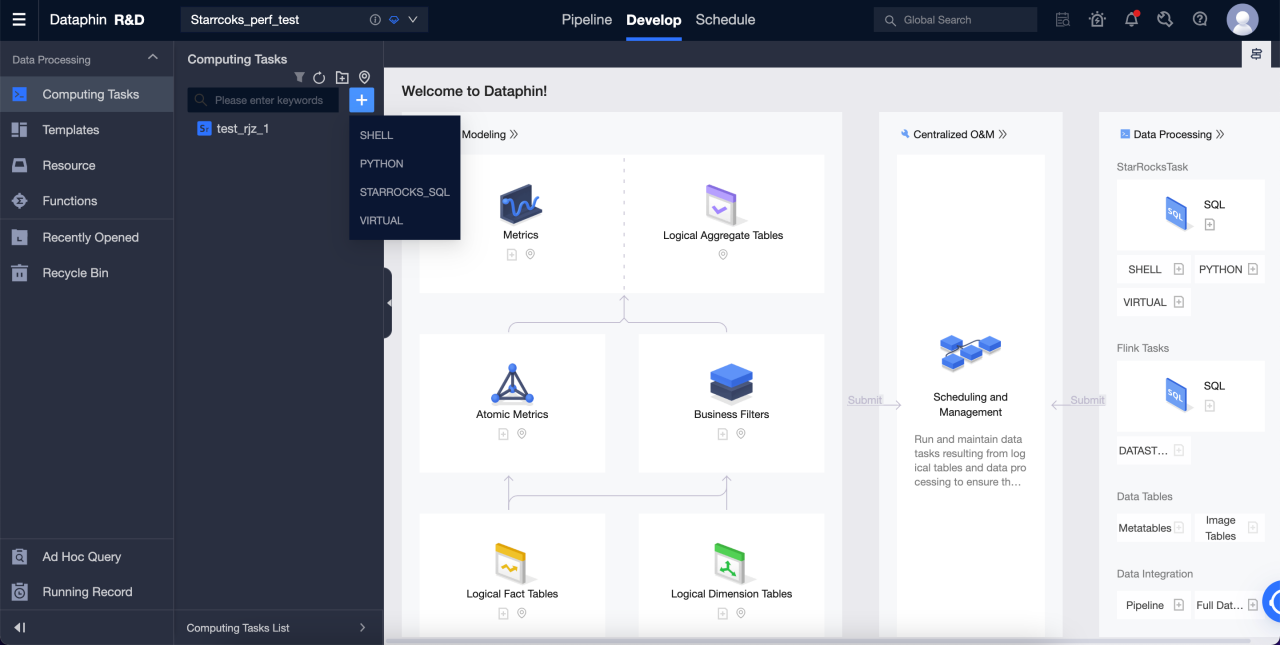
-
Введите имя и тип планирования для создания SQL-задачи.
-
Введите SQL в редакторе для начала операций DDL и DML в Selena.