Apache Spark Load
Массовая загрузка данных с помощью Spark Load
Этот метод загрузки использует внешние ресурсы Apache Spark™ для предварительной обработки импортируемых данных, что улучшает производительность импорта и экономит вычислительные ресурсы. Он в основном используется для начальной миграции и импорта больших объёмов данных в Selena (объём данных до уровня ТБ).
Spark load — это асинхронный метод импорта, который требует от пользователей создания задач импорта типа Spark через протокол MySQL и просмотра результатов импорта с помощью SHOW LOAD.
ВНИМАНИЕ
- Только пользователи с привилегией INSERT на таблицу Selena могут загружать данные в эту таблицу. Вы можете следовать инструкциям в GRANT, чтобы пр�едоставить необходимую привилегию.
- Spark Load нельзя использовать для загрузки данных в таблицу с Primary Key.
Объяснение терминологии
- Spark ETL: Отвечает главным образом за ETL данных в процессе импорта, включая построение глобального словаря (тип BITMAP), партиционирование, сортировку, агрегацию и т.д.
- Broker: Broker — это независимый процесс без состояния. Он инкапсулирует интерфейс файловой системы и предоставляет Selena возможность читать файлы из удалённых систем хранения.
- Глобальный словарь: Сохраняет структуру данных, которая сопоставляет данные от исходного значения к закодированному значению. Исходное значение может быть любого типа данных, в то время как закодированное значение является целым числом. Глобальный словарь в основном используется в сценариях, где предварительно вычисляется точный count distinct.
Основы
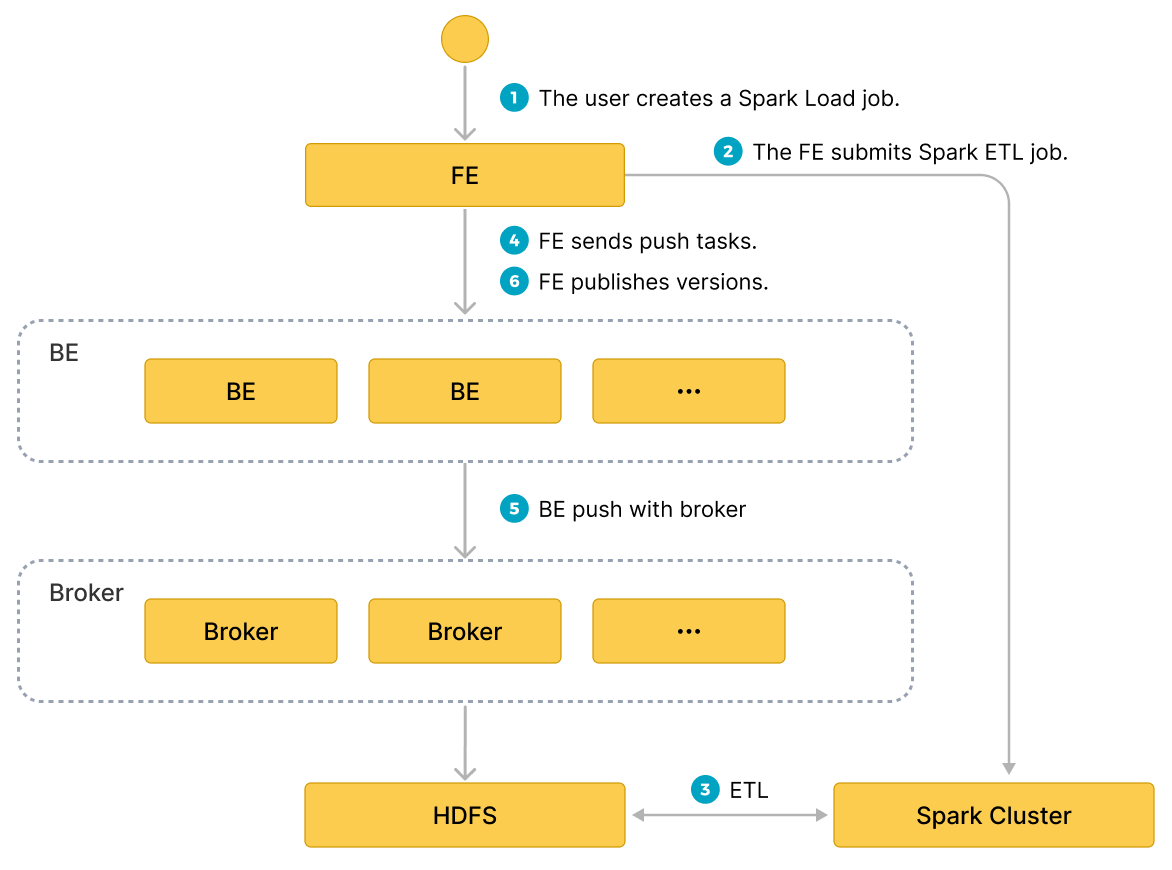
Пользователь отправляет задачу импорта типа Spark через MySQL-клиент; FE записывает метаданные и возвращает результат отправки.
Выполнение задачи Spark load делится на следующие основные фазы.
- Пользователь отправляет задачу Spark load в FE.
- FE планирует отправку задачи ETL в cluster Apache Spark™ для выполнения.
- Cluster Apache Spark™ выполняет задачу ETL, которая включает построение глобального словаря (тип BITMAP), партиционирование, сортировку, агрегацию и т.д.
- После завершения задачи ETL FE получает путь к данным каждого предварительно обработанного среза и планирует соответствующие BE для выполнения задачи Push.
- BE читает данные через процесс Broker из HDFS и конвертирует их в формат хранения Selena.
Если вы решите не использовать процесс Broker, BE читает данные из HDFS напрямую.
- FE планирует эффективную версию и завершает задачу импорта.
Следующая диаграмма иллюстрирует основной поток Spark load.
Глобальный словарь
Применимые сценарии
В настоящее время столбец BITMAP в Selena реализован с использованием Roaringbitmap, который принимает только целые числа в качестве типа входных данных. Поэтому, если вы хотите реализовать предварительное вычисление для столбца BITMAP в процессе импорта, вам нужно преобразовать тип входных данных в целое число.
В существующем процессе импорта Selena структура данных глобального словаря реализована на основе таблицы Hive, которая сохраняет сопоставление от исходного значения к закодированному значению.
Процесс построения
- Чтен�ие данных из вышестоящего источника данных и генерация временной таблицы Hive с именем
hive-table. - Извлечение значений дедуплицируемых полей из
hive-tableдля генерации новой таблицы Hive с именемdistinct-value-table. - Создание новой таблицы глобального словаря с именем
dict-tableс одним столбцом для исходных значений и одним столбцом для закодированных значений. - Left join между
distinct-value-tableиdict-table, а затем использование оконной функции для кодирования этого набора. Наконец, как исходное значение, так и закодированное значение дедуплицированного столбца записываются обратно вdict-table. - Join между
dict-tableиhive-tableдля завершения работы по замене исходного значения вhive-tableна целочисленное закодированное значение. hive-tableбудет прочитана при следующей предварительной обработке данных, а затем импортирована в Selena после вычисления.
Предварительная обработка данных
Базовый процесс предварительной обработки данных следующий:
- Чтение данных из вышестоящего источника данных (файл HDFS или таблица Hive).
- Выполнение сопоставления полей и вычисления для прочитанных данных, затем генерация
bucket-idна основе информации о partition. - Генерация RollupTree на основе метаданных Rollup таблицы Selena.
- Итерация по RollupTree и выполнение иерархических операций агрегации. Rollup следующей иерархии может быть вычислен из Rollup предыдущей иерархии.
- Каждый раз после завершения вычисления агрегации данные разбиваются по bucket в соответствии с
bucket-idи затем записываются в HDFS. - Последующий процесс Broker будет извлекать файлы из HDFS и импортировать их в узел BE Selena.
Базовые операции
Конфигурация cluster ETL
Apache Spark™ используется в качестве внешнего вычислительного ресурса в Selena для работы ETL. К Selena могут быть добавлены и другие внешние ресурсы, такие как Spark/GPU для запросов, HDFS/S3 для внешнего хранилища, MapReduce для ETL и т.д. Поэтому мы вводим Resource Management для управления этими внешними ресурсами, используемыми Selena.
Перед отправкой задачи импорта Apache Spark™ настройте cluster Apache Spark™ для выполнения задач ETL. Синтаксис операции следующий:
-- создание ресурса Apache Spark™
CREATE EXTERNAL RESOURCE resource_name
PROPERTIES
(
type = spark,
spark_conf_key = spark_conf_value,
working_dir = path,
broker = broker_name,
broker.property_key = property_value
);
-- удалени�е ресурса Apache Spark™
DROP RESOURCE resource_name;
-- просмотр ресурсов
SHOW RESOURCES
SHOW PROC "/resources";
-- привилегии
GRANT USAGE_PRIV ON RESOURCE resource_name TO user_identityGRANT USAGE_PRIV ON RESOURCE resource_name TO ROLE role_name;
REVOKE USAGE_PRIV ON RESOURCE resource_name FROM user_identityREVOKE USAGE_PRIV ON RESOURCE resource_name FROM ROLE role_name;
- Создание ресурса
Пример:
-- режим yarn cluster
CREATE EXTERNAL RESOURCE "spark0"
PROPERTIES
(
"type" = "spark",
"spark.master" = "yarn",
"spark.submit.deployMode" = "cluster",
"spark.jars" = "xxx.jar,yyy.jar",
"spark.files" = "/tmp/aaa,/tmp/bbb",
"spark.executor.memory" = "1g",
"spark.yarn.queue" = "queue0",
"spark.hadoop.yarn.resourcemanager.address" = "127.0.0.1:9999",
"spark.hadoop.fs.defaultFS" = "hdfs://127.0.0.1:10000",
"working_dir" = "hdfs://127.0.0.1:10000/tmp/selena",
"broker" = "broker0",
"broker.username" = "user0",
"broker.password" = "password0"
);
-- режим yarn HA cluster
CREATE EXTERNAL RESOURCE "spark1"
PROPERTIES
(
"type" = "spark",
"spark.master" = "yarn",
"spark.submit.deployMode" = "cluster",
"spark.hadoop.yarn.resourcemanager.ha.enabled" = "true",
"spark.hadoop.yarn.resourcemanager.ha.rm-ids" = "rm1,rm2",
"spark.hadoop.yarn.resourcemanager.hostname.rm1" = "host1",
"spark.hadoop.yarn.resourcemanager.hostname.rm2" = "host2",
"spark.hadoop.fs.defaultFS" = "hdfs://127.0.0.1:10000",
"working_dir" = "hdfs://127.0.0.1:10000/tmp/selena",
"broker" = "broker1"
);
resource-name — это имя ресурса Apache Spark™, настроенного в Selena.
PROPERTIES включает параметры, относящиеся к ресурсу Apache Spark™, следующим образом:
Примечание
Для получения подробного описания PROPERTIES ресурса Apache Spark™ см. CREATE RESOURCE
-
Параметры, связанные со Spark:
type: Тип ресурса, обязательный, в настоящее время поддерживается толькоspark.spark.master: Обязательный, в настоящее время поддерживается толькоyarn.spark.submit.deployMode: Режим развёртывания программы Apache Spark™, обязательный, в настоящее время поддерживаются какcluster, так иclient.spark.hadoop.fs.defaultFS: Обязательный, если master — yarn.- Параметры, связанные с yarn resource manager, обязательные.
- один ResourceManager на одн�ом узле
spark.hadoop.yarn.resourcemanager.address: Адрес единственного resource manager. - ResourceManager HA
Вы можете выбрать указание hostname или адреса ResourceManager.
spark.hadoop.yarn.resourcemanager.ha.enabled: Включить HA resource manager, установите вtrue.spark.hadoop.yarn.resourcemanager.ha.rm-ids: список логических идентификаторов resource manager.spark.hadoop.yarn.resourcemanager.hostname.rm-id: Для каждого rm-id укажите hostname, соответствующий resource manager.spark.hadoop.yarn.resourcemanager.address.rm-id: Для каждого rm-id укажитеhost:portдля клиента для отправки задач.
- один ResourceManager на одн�ом узле
-
*working_dir: Каталог, используемый ETL. Обязательный, если Apache Spark™ используется в качестве ресурса ETL. Например:hdfs://host:port/tmp/selena. -
Параметры, связанные с Broker:
broker: Имя Broker. Обязательный, если Apache Spark™ используется в качестве ресурса ETL. Вам нужно заранее выполнить настройку с помощью командыALTER SYSTEM ADD BROKER.broker.property_key: Информация (например, информация для аутентификации), которая должна быть указана, когда процесс Broker читает промежуточный файл, сгенерированный ETL.
Предостережение:
Выш�е приведено описание параметров для загрузки через процесс Broker. Если вы намерены загружать данные без процесса Broker, следует обратить внимание на следующее.
- Вам не нужно указывать
broker. - Если вам нужно настроить аутентификацию пользователя и HA для узлов NameNode, вам нужно настроить параметры в файле hdfs-site.xml в cluster HDFS, см. описания параметров в broker_properties. и вам нужно переместить файл hdfs-site.xml в $FE_HOME/conf для каждого FE и $BE_HOME/conf для каждого BE.
Примечание
Если файл HDFS доступен только определённому пользователю, вам всё ещё нужно указать имя пользователя HDFS в
broker.nameи пароль пользователя вbroker.password.
- Просмотр ресурсов
Обычные учётные записи могут просматривать только ресурсы, к которым у них есть доступ USAGE-PRIV. Учётные записи root и admin могут просматривать все ресурсы.
- Разрешения ресурсов
Разрешения ресурсов управляются через GRANT REVOKE, который в настоящее время поддерживает только разрешения USAGE-PRIV. Вы можете предоставить разрешения USAGE-PRIV пользователю или роли.
-- Предоставить доступ к ресурсам spark0 пользователю user0
GRANT USAGE_PRIV ON RESOURCE "spark0" TO "user0"@"%";
-- Предоставить доступ к ресурсам spark0 роли role0
GRANT USAGE_PRIV ON RESOURCE "spark0" TO ROLE "role0";
-- Предоставить доступ ко всем ресурсам пользователю user0
GRANT USAGE_PRIV ON RESOURCE* TO "user0"@"%";
-- Предоставить доступ ко всем ресурсам роли role0
GRANT USAGE_PRIV ON RESOURCE* TO ROLE "role0";
-- Отозвать привилегии использования ресурсов spark0 у пользователя user0
REVOKE USAGE_PRIV ON RESOURCE "spark0" FROM "user0"@"%";
Конфигурация клиента Spark
Настройте клиент Spark для FE, чтобы последний мог отправлять задачи Spark, выполняя команду spark-submit. Рекомендуется использовать официальную версию Spark2 2.4.5 или выше (адрес загрузки spark). После загрузки используйте следующие шаги для завершения конфигурации.
- Настройка
SPARK-HOME
Разместите клиент Spark в каталоге на той же машине, что и FE, и настройте spark_home_default_dir в файле конфигурации FE на этот каталог, который по умолчанию является путём lib/spark2x в корневом каталоге FE и не может быть пустым.
- Настройка пакета зависимостей SPARK
Для настройки пакета зависимостей заархивируйте все jar-файлы в папке jars под клиентом Spark и настройте элемент spark_resource_path в конфигурации FE на этот zip-файл. Если эта конфигурация пуста, FE попытается найти файл lib/spark2x/jars/spark-2x.zip в корневом каталоге FE. Если FE не найдёт его, будет выдана ошибка.
При отправке задачи Spark load заархивированные файлы зависимостей будут загружены в удалённый репозиторий. П�уть репозитория по умолчанию находится в каталоге working_dir/{cluster_id} с именем --spark-repository--{resource-name}, что означает, что ресурс в cluster соответствует удалённому репозиторию. Структура каталога приведена ниже:
---spark-repository--spark0/
|---archive-1.0.0/
| |\---lib-990325d2c0d1d5e45bf675e54e44fb16-spark-dpp-1.0.0\-jar-with-dependencies.jar
| |\---lib-7670c29daf535efe3c9b923f778f61fc-spark-2x.zip
|---archive-1.1.0/
| |\---lib-64d5696f99c379af2bee28c1c84271d5-spark-dpp-1.1.0\-jar-with-dependencies.jar
| |\---lib-1bbb74bb6b264a270bc7fca3e964160f-spark-2x.zip
|---archive-1.2.0/
| |-...
Помимо зависимостей Spark (по умолчанию названных spark-2x.zip), FE также загружает зависимости DPP в удалённый репозиторий. Если все зависимости, отправленные Spark load, уже существуют в удалённом репозитории, то нет необходимости загружать зависимости снова, что экономит время на повторную загрузку большого количества файлов каждый раз.
Конфигурация клиента YARN
Настройте клиент yarn для FE, чтобы FE мог выполнять команды yarn для получения статуса запущенного приложения или его остановки. Рекомендуется использовать официальн�ую версию Hadoop2 2.5.2 или выше (адрес загрузки hadoop). После загрузки используйте следующие шаги для завершения конфигурации:
- Настройка пути к исполняемому файлу YARN
Разместите загруженный клиент yarn в каталоге на той же машине, что и FE, и настройте элемент yarn_client_path в файле конфигурации FE на бинарный исполняемый файл yarn, который по умолчанию является путём lib/yarn-client/hadoop/bin/yarn в корневом каталоге FE.
- Настройка пути к файлу конфигурации, необходимому для генерации YARN (опционально)
Когда FE через клиент yarn получает статус приложения или останавливает приложение, по умолчанию Selena генерирует файл конфигурации, необходимый для выполнения команды yarn, в пути lib/yarn-config корневого каталога FE. Этот путь можно изменить, настроив запись yarn_config_dir в файле конфигурации FE, которая в настоящее время включает core-site.xml и yarn-site.xml.
Создание задачи импорта
Синтаксис:
LOAD LABEL load_label
(data_desc, ...)
WITH RESOURCE resource_name
[resource_properties]
[PROPERTIES (key1=value1, ... )]
* load_label:
db_name.label_name
* data_desc:
DATA INFILE ('file_path', ...)
[NEGATIVE]
INTO TABLE tbl_name
[PARTITION (p1, p2)]
[COLUMNS TERMINATED BY separator ]
[(col1, ...)]
[COLUMNS FROM PATH AS (col2, ...)]
[SET (k1=f1(xx), k2=f2(xx))]
[WHERE predicate]
DATA FROM TABLE hive_external_tbl
[NEGATIVE]
INTO TABLE tbl_name
[PARTITION (p1, p2)]
[SET (k1=f1(xx), k2=f2(xx))]
[WHERE predicate]
* resource_properties:
(key2=value2, ...)
Пример 1: Случай, когда вышестоящий источник данных — HDFS
LOAD LABEL db1.label1
(
DATA INFILE("hdfs://abc.com:8888/user/selena/test/ml/file1")
INTO TABLE tbl1
COLUMNS TERMINATED BY ","
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
),
DATA INFILE("hdfs://abc.com:8888/user/selena/test/ml/file2")
INTO TABLE tbl2
COLUMNS TERMINATED BY ","
(col1, col2)
where col1 > 1
)
WITH RESOURCE 'spark0'
(
"spark.executor.memory" = "2g",
"spark.shuffle.compress" = "true"
)
PROPERTIES
(
"timeout" = "3600"
);
Пример 2: Случай, когда вышестоящий источник данных — Hive.
- Шаг 1: Создайте новый ресурс hive
CREATE EXTERNAL RESOURCE hive0
PROPERTIES
(
"type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:8080"
);
- Шаг 2: Создайте новую внешнюю таблицу hive
CREATE EXTERNAL TABLE hive_t1
(
k1 INT,
K2 SMALLINT,
k3 varchar(50),
uuid varchar(100)
)
ENGINE=hive
PROPERTIES
(
"resource" = "hive0",
"database" = "tmp",
"table" = "t1"
);
- Шаг 3: Отправьте команду загрузки, требуя, чтобы столбцы в импортируемой таблице Selena существовали в�о внешней таблице hive.
LOAD LABEL db1.label1
(
DATA FROM TABLE hive_t1
INTO TABLE tbl1
SET
(
uuid=bitmap_dict(uuid)
)
)
WITH RESOURCE 'spark0'
(
"spark.executor.memory" = "2g",
"spark.shuffle.compress" = "true"
)
PROPERTIES
(
"timeout" = "3600"
);
Введение в параметры в Spark load:
- Label
Label задачи импорта. Каждая задача импорта имеет Label, который уникален в пределах базы данных, следуя тем же правилам, что и broker load.
- Параметры класса описания данных
В настоящее время поддерживаемые источники данных — CSV и таблица Hive. Остальные правила такие же, как и для broker load.
- Параметры задачи импорта
Параметры задачи импорта относятся к параметрам, принадлежащим разделу opt_properties оператора импорта. Эти параметры применяются ко всей задаче импорта. Правила такие же, как и для broker load.
- Параметры ресурса Spark
Ресурсы Spark должны быть заранее настроены в Selena, и пользователям необходимо предоставить разрешения USAGE-PRIV, прежде чем они смогут применять ресурсы к Spark load. Параметры ресурса Spark можно установить, когда у пользователя есть временная потребность, например, добавление ресурсов для задачи и изменение конфигураций Spark. Настройка действует только для этой задачи и не влияет на существующие конфигурации в cluster Selena.
WITH RESOURCE 'spark0'
(
"spark.driver.memory" = "1g",
"spark.executor.memory" = "3g"
)
- Импорт, когда источник данных — Hive
В настоящее время для использования таблицы Hive в процессе импорта вам нужно создать внешнюю таблицу типа Hive, а затем указать её имя при отправке команды импорта.
- Процесс импорта для построения глобального словаря
В команде загрузки вы можете указать необходимые поля для построения глобального словаря в следующем формате: имя поля Selena=bitmap_dict(имя поля таблицы hive). Обратите внимание, что в настоящее время глобальный словарь поддерживается только когда вышестоящий источник данных — таблица Hive.
- Загрузка данных бинарного типа
Начиная с версии v1.5.2, Spark Load поддерживает функцию bitmap_from_binary, которая может конвертировать бинарные данные в данные bitmap. Если тип столбца таблицы Hive или файла HDFS — binary, а соответствующий столбец в таблице Selena — агрегатный столбец типа bitmap, вы можете указать поля в команде загрузки в следующем формате: имя поля Selena=bitmap_from_binary(имя поля таблицы Hive). Это устраняет необходимость построения глобального словаря.
Просмотр задач импорта
Импорт Spark load является асинхронным, как и broker load. Пользователь должен записать label задачи импорта и использовать его в команде SHOW LOAD для просмотра результатов импорта. Команда просмотра импорта общая для всех методов импорта. Пример следующий.
Обратитесь к Broker Load для получения подробного объяснения возвращаемых параметров. Различия следующие.
mysql> show load order by createtime desc limit 1\G
*************************** 1. row ***************************
JobId: 76391
Label: label1
State: FINISHED
Progress: ETL:100%; LOAD:100%
Type: SPARK
EtlInfo: unselected.rows=4; dpp.abnorm.ALL=15; dpp.norm.ALL=28133376
TaskInfo: cluster:cluster0; timeout(s):10800; max_filter_ratio:5.0E-5
ErrorMsg: N/A
CreateTime: 2019-07-27 11:46:42
EtlStartTime: 2019-07-27 11:46:44
EtlFinishTime: 2019-07-27 11:49:44
LoadStartTime: 2019-07-27 11:49:44
LoadFinishTime: 2019-07-27 11:50:16
URL: http://1.1.1.1:8089/proxy/application_1586619723848_0035/
JobDetails: {"ScannedRows":28133395,"TaskNumber":1,"FileNumber":1,"FileSize":200000}
- State
Текущая стадия импортируемой задачи. PENDING: Задача зафиксирована. ETL: Spark ETL зафиксирован. LOADING: FE планирует BE для выполнения операции push. FINISHED: Push завершён, и версия эффективна.
Есть две финальные стадии задачи импорта — CANCELLED и FINISHED, обе указывают на завершение задачи загрузки. CANCELLED указывает на неудачу импорта, а FINISHED указывает на успех импорта.
- Progress
Описание прогресса задачи импорта. Есть два типа прогресса — ETL и LOAD, которые соответствуют двум фазам процесса импорта, ETL и LOADING.
- Диапазон прогресса для LOAD — 0~100%.
LOAD прогресс = количество текущих завершённых tablet всех replica импортов / общее количество tablet этой задачи импорта * 100%.
-
Если все таблицы были импортированы, прогресс LOAD составляет 99% и меняется на 100%, когда импорт входит в финальную фазу проверки.
-
Прогресс импорта не линейный. Если прогресс не меняется в течение некоторого времени, это не означает, что импорт не выполняется.
-
Type
Тип задачи импорта. SPARK для Spark load.
- CreateTime/EtlStartTime/EtlFinishTime/LoadStartTime/LoadFinishTime
Эти значения представляют время создания импорта, время начала фазы ETL, время завершения фазы ETL, время начала фазы LOADING и время завершения всей задачи импорта.
- JobDetails
Отображает подробный статус выполнения задачи, включая количество импортированных файлов, общий размер (в байтах), количество подзадач, количество обработанных исходных строк и т.д. Например:
{"ScannedRows":139264,"TaskNumber":1,"FileNumber":1,"FileSize":940754064}
- URL
Вы можете скопировать ввод в ваш браузер для доступа к веб-интерфейсу соответствующего приложения.
Просмотр логов отправки Apache Spark™ Launcher
Иногда пользователям нужно просмотреть подробные логи, сгенерированные во время отправки задачи Apache Spark™. По умолчанию логи сохраняются в пути log/spark_launcher_log в корневом каталоге FE с именем spark-launcher-{load-job-id}-{label}.log. Логи сохраняются в этом каталоге в течение определённого времени и будут стёрты при очистке ин�формации об импорте в метаданных FE. Время хранения по умолчанию — 3 дня.
Отмена импорта
Когда статус задачи Spark load не CANCELLED или FINISHED, она может быть отменена вручную пользователем путём указания Label задачи импорта.
Связанные системные конфигурации
Конфигурация FE: Следующая конфигурация является конфигурацией системного уровня для Spark load, которая применяется ко всем задачам импорта Spark load. Значения конфигурации можно настроить главным образом путём изменения fe.conf.
- enable-spark-load: Включить Spark load и создание ресурсов со значением по умолчанию false.
- spark-load-default-timeout-second: Таймаут по умолчанию для задачи — 259200 секунд (3 дня).
- spark-home-default-dir: Путь к клиенту Spark (
fe/lib/spark2x). - spark-resource-path: Путь к упакованному файлу зависимостей Spark (по умолчанию пустой).
- spark-launcher-log-dir: Каталог, где хранится лог отправки клиента Spark (
fe/log/spark-launcher-log). - yarn-client-path: Путь к бинарному исполняемому файлу yarn (
fe/lib/yarn-client/hadoop/bin/yarn). - yarn-config-dir: Путь к файлу конфигурации Yarn (
fe/lib/yarn-config).
Лучшие практики
Наиболее подходящий сценарий для использования Spark load — когда исходные данные находятся в файловой системе (HDFS), а объём данных составляет от десятков ГБ до уровня ТБ. Используйте Stream Load или Broker Load для меньших объёмов данных.
Для полного примера импорта Spark load обратитесь к демо на github: https://github.com/Selena/demo/blob/master/docs/03_sparkLoad2Selena.md
FAQ
Error: When running with master 'yarn' either HADOOP-CONF-DIR or YARN-CONF-DIR must be set in the environment.
Использование Spark Load без настройки переменной окружения HADOOP-CONF-DIR в spark-env.sh клиента Spark.
Error: Cannot run program "xxx/bin/spark-submit": error=2, No such file or directory
Элемент конфигурации spark_home_default_dir не указывает корневой каталог клиента Spark при использовании Spark Load.
Error: File xxx/jars/spark-2x.zip does not exist.
Элемент конфигурации spark-resource-path не указывает на упакованный zip-файл при использовании Spark load.
Error: yarn client does not exist in path: xxx/yarn-client/hadoop/bin/yarn
Элемент конфигурации yarn-client-path не указывает исполняемый файл yarn при использовании Spark load.
ERROR: Cannot execute hadoop-yarn/bin/... /libexec/yarn-config.sh
При использовании Hadoop с CDH вам нужно настроить переменную окружения HADOOP_LIBEXEC_DIR.
Поскольку hadoop-yarn и каталоги hadoop разные, каталог libexec по умолчанию будет искать hadoop-yarn/bin/... /libexec, в то время как libexec находится в каталоге hadoop.
Команда ```yarn application status`` для получения статуса задачи Spark выдала ошибку, что привело к сбою задачи импорта.