Selena Migration Tool (SMT)
Selena Migration Tool (SMT) — это инструмент миграции данных, предоставляемый Selena для загрузки данных из исходных баз данных через Flink в Selena. Основные возможности SMT:
- Генерация операторов создания таблиц в Selena на основе информации об исходной базе данных и целевом cluster Selena.
- Генерация SQL-операторов, которые могут быть выполнены в SQL-клиенте Flink для отправки задани�й Flink по синхронизации данных, что упрощает полную или инкрементную синхронизацию данных в pipeline. В настоящее время SMT поддерживает следующие исходные базы данных:
| Исходная база данных | Генерация оператора создания таблицы в Selena | Полная синхронизация данных | Инкрементная синхронизация данных |
|---|---|---|---|
| MySQL | Поддерживается | Поддерживается | Поддерживается |
| PostgreSQL | Поддерживается | Поддерживается | Поддерживается |
| Oracle | Поддерживается | Поддерживается | Поддерживается |
| Hive | Поддерживается | Поддерживается | Не поддерживается |
| ClickHouse | Поддерживается | Поддерживается | Не поддерживается |
| SQL Server | Поддерживается | Поддерживается | Поддерживается |
| TiDB | Поддерживается | Поддерживается | Поддерживается |
Ссылка для скачивания: https://cdn-thirdparty.selena.com/smt.tar.gz?r=2
Шаги для использования SMT
Общие шаги следующие:
-
Настройте файл conf/config_prod.conf.
-
Выполните selena-migration-tool.
-
После выполнения SQL-скрипты генерируются в директории result по умолчанию.
Затем вы можете использовать SQL-скрипты из директории result для синхронизации метаданных или данных.
Конфигурация SMT
-
[db]: информация для подключения к источнику данных. Настройте информацию для подключения к источнику данных, соответствующему типу базы данных, указанному в параметреtype. -
[other]: дополнительные настройки. Рекомендуется указать фактическое количество BE-узлов в параметреbe_num. -
flink.selena.sink.*: конфигурации flink-connector-selena. Подробное описание конфигураций см. в описании конфигурации. -
[table-rule.1]: правило для сопоставления таблиц в источнике данных. Оператор CREATE TABLE генерируется на основе регулярных выражений, настроенных в правиле для сопоставления имен баз данных и таблиц в источнике данных. Можно настроить несколько правил, и каждое правило генерирует соответствующий файл результата, например:[table-rule.1]->result/selena-create.1.sql[table-rule.2]->result/selena-create.2.sql
Каждое правило должно содержать конфигурации базы данных, таблицы и flink-connector-selena.
[table-rule.1]
# pattern to match databases for setting properties
database = ^ database1.*$
# pattern to match tables for setting properties
table = ^.*$
schema = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.selena.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.selena.load-url= 192.168.1.1:8030
flink.selena.username=root
flink.selena.password=
flink.selena.sink.max-retries=10
flink.selena.sink.buffer-flush.interval-ms=15000
flink.selena.sink.properties.format=json
flink.selena.sink.properties.strip_outer_array=true
[table-rule.2]
# pattern to match databases for setting properties
database = ^database2.*$
# pattern to match tables for setting properties
table = ^.*$
schema = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.selena.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.selena.load-url= 192.168.1.1:8030
flink.selena.username=root
flink.selena.password=
flink.selena.sink.max-retries=10
flink.selena.sink.buffer-flush.interval-ms=15000
flink.selena.sink.properties.format=json
flink.selena.sink.properties.strip_outer_array=true -
Для большой таблицы, разделенной на шарды в базах данных, можно настроить отдельное правило. Например, предположим, что две базы данных
edu_db_1иedu_db_2содержат таблицыcourse_1иcourse_2соответственно, и эти две таблицы имеют одинаковую структуру. Вы можете использовать следующее правило для загрузки данных из этих двух таблиц в одну таблицу Selena для анализа.[table-rule.3]
# pattern to match databases for setting properties
database = ^edu_db_[0-9]*$
# pattern to match tables for setting properties
table = ^course_[0-9]*$
schema = ^.*$Это правило автоматически сформирует отношение загрузки "многие к одному". Имя таблицы по умолчанию, которая будет создана в Selena, —
course__auto_shard, и вы также можете изменить имя таблицы в соответствующем SQL-скрипте, таком какresult/selena-create.3.sql.
Синхронизация MySQL с Selena
Введение
Flink CDC connector и SMT могут синхронизировать данные из MySQL в течение доли секунды.
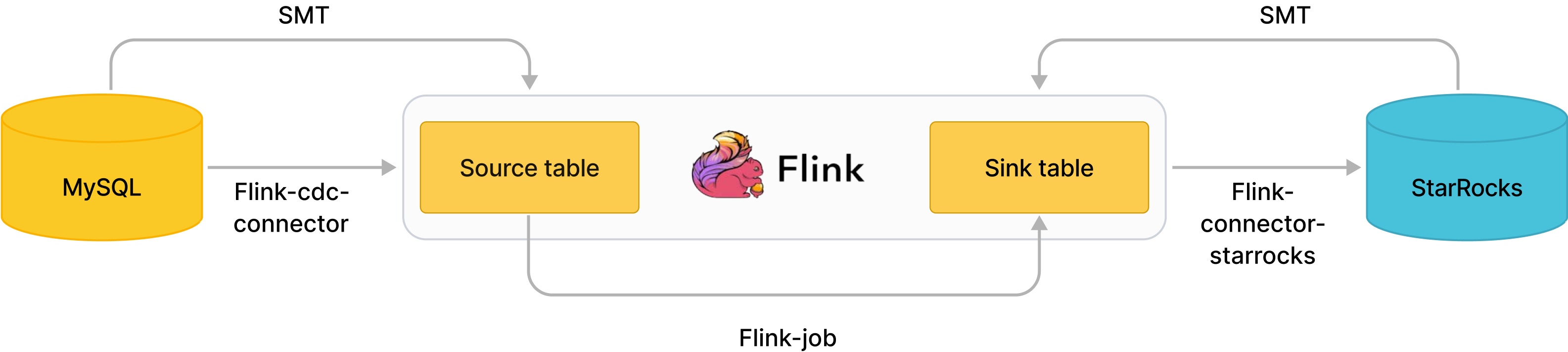
Как показано на изображении, SMT может автоматически генерировать операторы CREATE TABLE для исходных и целевых таблиц Flink на основе информации о cluster и структуре таблиц MySQL и Selena. Flink CDC connector читает MySQL Binlog, а Flink-connector-selena записывает данные в Selena.
Шаги
| Зависимость | Имя пакета | Ссылка для скачивания |
|---|---|---|
| Flink | flink-x.x.x-bin-scala_2.12.tgz | Нажмите здесь |
| Flink CDC connector | flink-sql-connector-mysql-cdc-x.x.x.jar | Нажмите здесь |
| Flink-connector-selena | flink-connector-selena-x.x.x_flink-x.x.jar | Нажмите здесь |
| SMT | smt.tar.gz | Нажмите здесь |
-
Скачайте Flink. Поддерживается Flink 1.11 или более поздней версии.
-
Скачайте Flink CDC connector. Убедитесь, что вы скачали
flink-sql-connector-mysql-cdc-xxx.jar, соответствующий версии Flink. -
Скачайте Flink-connector-selena.
-
Скопируйте flink-sql-connector-mysql-cdc-xxx.jar и flink-connector-selena-xxx.jar в flink-xxx/lib/.
-
Скачайте smt.tar.gz.
-
Распакуйте и измените файл конфигурации SMT.
[db]
host = 192.168.1.1
port = 3306
user = root
password =
type = mysql
[other]
# number of backends in Selena
be_num = 3
# `decimal_v3` is supported since Selena-1.18.1
use_decimal_v3 = false
# directory to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# pattern to match databases for setting properties
database = ^db$
# pattern to match tables for setting properties
table = ^table$
schema = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.selena.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.selena.load-url= 192.168.1.1:8030
flink.selena.username=root
flink.selena.password=
flink.selena.sink.max-retries=10
flink.selena.sink.buffer-flush.interval-ms=15000
flink.selena.sink.properties.format=json
flink.selena.sink.properties.strip_outer_array=true -
Выполните selena-migrate-tool. Все SQL-скрипты генерируются в директории result.
$./selena-migrate-tool
$ls result
flink-create.1.sql smt.tar.gz selena-create.all.sql
flink-create.all.sql selena-create.1.sql selena-external-create.all.sql -
Используйте SQL-скрипт с префиксом selena-create для создания таблицы в Selena.
mysql -hxx.xx.xx.x -P9030 -uroot -p < selena-create.all.sql -
Используйте SQL-скрипт с префиксом flink-create для создания исходных и целевых таблиц Flink и запуска задания Flink для синхронизации данных.
bin/sql-client.sh embedded < flink-create.all.sqlПосле успешного выполнения указанной выше команды задание Flink по синхронизации данных продолжает работать.
-
Наблюдайте за статусом задания Flink.
bin/flink listЕсли при выполнении задания возникает ошибка, вы можете просмотреть подробную информацию об ошибке в логах Flink. Кроме того, вы можете изменить конфигурации Flink в файле conf/flink-conf.yaml, такие как память и slot.
Примечания
-
Как включить MySQL binlog?
-
Измените /etc/my.cnf:
# Enable binlog
log-bin=/var/lib/mysql/mysql-bin
#log_bin=ON
## Base name of binlog files
#log_bin_basename=/var/lib/mysql/mysql-bin
## Index file for binlog files, managing all binlog files
#log_bin_index=/var/lib/mysql/mysql-bin.index
# Configure server id
server-id=1
binlog_format = row -
Перезапустите mysqld. Вы можете проверить, включен ли MySQL binlog, выполнив
SHOW VARIABLES LIKE 'log_bin';.
-
Синхронизация PostgreSQL с Selena
Введение
Flink CDC connector и SMT могут синхронизировать данные из PostgreSQL в течение доли секунды.
SMT может автоматически генерировать операторы CREATE TABLE для исходных и целевых таблиц Flink на основе информации о cluster и структуре таблиц PostgreSQL и Selena.
Flink CDC connector читает WAL PostgreSQL, а Flink-connector-selena записывает данные в Selena.
Шаги
-
Скачайте Flink. Поддерживается версия Flink 1.11 или более поздняя.
-
Скачайте Flink CDC connector. Убедитесь, что вы скачали flink-sql-connector-postgres-cdc-xxx.jar, соответствующий версии Flink.
-
Скачайте Flink Selena connector.
-
Скопируйте flink-sql-connector-postgres-cdc-xxx.jar и flink-connector-selena-xxx.jar в flink-xxx/lib/.
-
Скачайте smt.tar.gz.
-
Распакуйте и измените файл конфигурации SMT.
[db]
host = 192.168.1.1
port = 5432
user = xxx
password = xxx
type = pgsql
[other]
# number of backends in Selena
be_num = 3
# `decimal_v3` is supported since Selena-1.18.1
use_decimal_v3 = false
# directory to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# pattern to match databases for setting properties
database = ^db$
# pattern to match tables for setting properties
table = ^table$
# pattern to match schemas for setting properties
schema = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.selena.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.selena.load-url= 192.168.1.1:8030
flink.selena.username=root
flink.selena.password=
flink.selena.sink.max-retries=10
flink.selena.sink.buffer-flush.interval-ms=15000
flink.selena.sink.properties.format=json
flink.selena.sink.properties.strip_outer_array=true -
Выполните selena-migrate-tool. Все SQL-скрипты генерируются в директории result.
$./selena-migrate-tool
$ls result
flink-create.1.sql smt.tar.gz selena-create.all.sql
flink-create.all.sql selena-create.1.sql -
Используйте SQL-скрипт с префиксом selena-create для создания таблицы в Selena.
mysql -hxx.xx.xx.x -P9030 -uroot -p < selena-create.all.sql -
Используйте SQL-скрипт с префиксом flink-create для создания исходных и целевых таблиц Flink и запуска задания Flink для синхронизации данных.
bin/sql-client.sh embedded < flink-create.all.sqlПосле успешного выполнения указанной выше команды задание Flink по синхронизации данных продолжает работать.
-
Наблюдайте за статусом задания Flink.
bin/flink listЕсли при выполнении задания возникает ошибка, вы можете просмотреть подробную информацию об ошибке в логах Flink. Кроме того, вы можете изменить конфигурации Flink в файле conf/flink-conf.yaml, такие как память и slot.
Примечания
-
Для PostgreSQL
v9.*требуется специальная конфигурация flink-cdc, как показано ниже (Рекомендуется использовать PostgreSQLv10.*или более поздней версии. В противном случае вам необходимо установить плагины декодирования WAL):############################################
############################################
### flink-cdc plugin configuration for `postgresql`
############################################
### for `9.*` decoderbufs, wal2json, wal2json_rds, wal2json_streaming, wal2json_rds_streaming
### refer to https://ververica.github.io/flink-cdc-connectors/master/content/connectors/postgres-cdc.html
### and https://debezium.io/documentation/reference/postgres-plugins.html
### flink.cdc.decoding.plugin.name = decoderbufs -
Как включить PostgreSQL WAL?
# Open connection permissions
echo "host all all 0.0.0.0/32 trust" >> pg_hba.conf
echo "host replication all 0.0.0.0/32 trust" >> pg_hba.conf
# Enable wal logical replication
echo "wal_level = logical" >> postgresql.conf
echo "max_wal_senders = 2" >> postgresql.conf
echo "max_replication_slots = 8" >> postgresql.confУкажите replica identity FULL для таблиц, которые необходимо синхронизировать.
ALTER TABLE schema_name.table_name REPLICA IDENTITY FULLПосле внесения этих изменений перезапустите PostgreSQL.
Синхронизация Oracle с Selena
Введение
Flink CDC connector и SMT могут синхронизировать данные из Oracle в течение доли секунды.
SMT может автоматически генерировать операторы CREATE TABLE для исходных и целевых таблиц Flink на основе информации о cluster и структуре таблиц Oracle и Selena.
Flink CDC connector читает logminer Oracle, а Flink-connector-selena записывает данные в Selena.
Шаги
-
Скачайте Flink. Поддерживается версия Flink 1.11 или более поздняя.
-
Скачайте Flink CDC connector. Убедитесь, что вы скачали flink-sql-connector-oracle-cdc-xxx.jar, соответствующий версии Flink.
-
Скачайте Flink Selena connector.
-
Скопируйте
flink-sql-connector-oracle-cdc-xxx.jarиflink-connector-selena-xxx.jarвflink-xxx/lib/. -
Скачайте smt.tar.gz.
-
Распакуйте и измените файл конфигурации SMT.
[db]
host = 192.168.1.1
port = 1521
user = xxx
password = xxx
type = oracle
[other]
# number of backends in Selena
be_num = 3
# `decimal_v3` is supported since Selena-1.18.1
use_decimal_v3 = false
# directory to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# pattern to match databases for setting properties
database = ^db$
# pattern to match tables for setting properties
table = ^table$
# pattern to match schemas for setting properties
schema = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.selena.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.selena.load-url= 192.168.1.1:8030
flink.selena.username=root
flink.selena.password=
flink.selena.sink.max-retries=10
flink.selena.sink.buffer-flush.interval-ms=15000
flink.selena.sink.properties.format=json
flink.selena.sink.properties.strip_outer_array=true -
Выполните selena-migrate-tool. Все SQL-скрипты генерируются в директории result.
$./selena-migrate-tool
$ls result
flink-create.1.sql smt.tar.gz selena-create.all.sql
flink-create.all.sql selena-create.1.sql -
Используйте SQL-скрипт с префиксом selena-create для создания таблицы в Selena.
mysql -hxx.xx.xx.x -P9030 -uroot -p < selena-create.all.sql -
Используйте SQL-скрипт с префиксом flink-create для создания исходных и целевых таблиц Flink и запуска задания Flink для синхронизации данных.
bin/sql-client.sh embedded < flink-create.all.sqlПосле успешного выполнения указанной выше команды задание Flink по синхронизации данных продолжает работать.
-
Наблюдайте за статусом задания Flink.
bin/flink listЕсли при выполнении задания возникает ошибка, вы можете просмотреть подробную информацию об ошибке в логах Flink. Кроме того, вы можете изменить конфигурации Flink в файле conf/flink-conf.yaml, такие как память и slot.
Примечания
-
Синхронизация Oracle с использованием logminer:
# Enable logging
alter system set db_recovery_file_dest = '/home/oracle/data' scope=spfile;
alter system set db_recovery_file_dest_size = 10G;
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
ALTER TABLE schema_name.table_name ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
# Authorize user creation and grant permissions
GRANT CREATE SESSION TO flinkuser;
GRANT SET CONTAINER TO flinkuser;
GRANT SELECT ON V_$DATABASE TO flinkuser;
GRANT FLASHBACK ANY TABLE TO flinkuser;
GRANT SELECT ANY TABLE TO flinkuser;
GRANT SELECT_CATALOG_ROLE TO flinkuser;
GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
GRANT SELECT ANY TRANSACTION TO flinkuser;
GRANT LOGMINING TO flinkuser;
GRANT CREATE TABLE TO flinkuser;
GRANT LOCK ANY TABLE TO flinkuser;
GRANT ALTER ANY TABLE TO flinkuser;
GRANT CREATE SEQUENCE TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser;
GRANT SELECT ON V_$LOG TO flinkuser;
GRANT SELECT ON V_$LOG_HISTORY TO flinkuser;
GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser;
GRANT SELECT ON V_$LOGFILE TO flinkuser;
GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser; -
Конфигурация базы данных в [table-rule.1] не поддерживает регулярные выражения, поэтому необходимо указывать полные имена баз данных.
-
Поскольку Oracle12c поддерживает режим CDB, SMT внутренне автоматически определяет, включен ли CDB, и соответствующим образом изменяет конфигурацию flink-cdc. Однако пользователям необходимо обратить внимание на то, нужно ли добавлять префикс c## к конфигурации
[db].user, чтобы избежать проблем с недостаточными разрешениями.
Синхронизация Hive с Selena
Введение
Это руководство объясняет, как использовать SMT для синхронизации данных Hive с Selena. Во время синхронизации в Selena создается Duplicate-таблица, и задание Flink продолжает работать для синхронизации данных.
Шаги
Подготовка
[db]
# hiveserver2 service ip
host = 127.0.0.1
# hiveserver2 service port
port = 10000
user = hive/emr-header-1.cluster-49148
password =
type = hive
# only takes effect with `type = hive`.
# Available values: kerberos, none, nosasl, kerberos_http, none_http, zk, ldap
authentication = kerberos
Поддерживаемые методы аутентификации следующие:
- nosasl, zk: не нужно указывать
userиpassword. - none, none_http, ldap: указывайте
userиpassword. - kerberos, kerberos_http: выполните следующие шаги:
- Выполните
kadmin.localна cluster Hive и проверьтеlist_principals, чтобы найти соответствующее имя principal. Например, когда имя principal —hive/emr-header-1.cluster-49148@EMR.49148.COM, пользователь должен быть установлен какhive/emr-header-1.cluster-49148, а пароль остается пустым. - Выполните
kinit -kt /path/to/keytab principalна машине, где выполняется SMT, и выполнитеklist, чтобы проверить, сгенерирован ли правильный токен.
- Выполните
Синхронизация данных
-
Выполните selena-migrate-tool.
-
Используйте SQL-скрипт с префиксом selena-create для создания таблицы в Selena.
mysql -hxx.xx.xx.x -P9030 -uroot -p < selena-create.all.sql -
В flink/conf/ создайте и отредактируйте файл sql-client-defaults.yaml:
execution:
planner: blink
type: batch
current-catalog: hive-selena
catalogs:
- name: hive-selena
type: hive
hive-conf-dir: /path/to/apache-hive-xxxx-bin/conf -
Скачайте пакет зависимостей (flink-sql-connector-hive-xxxx) со страницы Hive соответствующей версии Flink и поместите его в директорию
flink/lib. -
Запустите cluster Flink и выполните
flink/bin/sql-client.sh embedded < result/flink-create.all.sqlдля запуска синхронизации данных.
Синхронизация SQL Server с Selena
Введение
Flink CDC connector и SMT могут синхронизировать данные из SQL Server в течение доли секунды.
SMT может автоматически генерировать операторы CREATE TABLE для исходных и целевых таблиц Flink на основе информации о cluster и структуре таблиц SQL Server и Selena.
Flink CDC connector захватывает и записывает изменения на уровне строк, происходящие на сервере базы данных SQL Server. Принцип заключается в использовании функции CDC, предоставляемой самим SQL Server. Возможность CDC самого SQL Server может архивировать указанные изменения в базе данных в указанные таблицы изменений. SQL Server CDC connector сначала считывает исторические данные из таблицы с помощью JDBC, а затем извлекает инкрементные изменения из таблиц изменений, тем самым достигая полной инкрементной синхронизации. Затем Flink-connector-selena записывает данные в Selena.
Шаги
-
Скачайте Flink. Поддерживается версия Flink 1.11 или более поздняя.
-
Скачайте Flink CDC connector. Убедитесь, что вы скачали flink-sql-connector-sqlserver-cdc-xxx.jar, соответствующий версии Flink.
-
Скачайте Flink Selena connector.
-
Скопируйте flink-sql-connector-sqlserver-cdc-xxx.jar, flink-connector-selena-xxx.jar в flink-xxx/lib/.
-
Скачайте smt.tar.gz.
-
Распакуйте и измените файл конфигурации SMT.
[db]
host = 127.0.0.1
port = 1433
user = xxx
password = xxx
# currently available types: `mysql`, `pgsql`, `oracle`, `hive`, `clickhouse`
type = sqlserver
[other]
# number of backends in Selena
be_num = 3
# `decimal_v3` is supported since Selena-1.18.1
use_decimal_v3 = false
# directory to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# pattern to match databases for setting properties
database = ^db$
# pattern to match tables for setting properties
table = ^table$
schema = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.selena.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.selena.load-url= 192.168.1.1:8030
flink.selena.username=root
flink.selena.password=
flink.selena.sink.max-retries=10
flink.selena.sink.buffer-flush.interval-ms=15000
flink.selena.sink.properties.format=json
flink.selena.sink.properties.strip_outer_array=true -
Выполните selena-migrate-tool. Все SQL-ск�рипты генерируются в директории
result.
```Bash $./selena-migrate-tool $ls result flink-create.1.sql smt.tar.gz selena-create.all.sql flink-create.all.sql selena-create.1.sql selena-external-create.all.sql
8. Используйте SQL-скрипт с префиксом `selena-create` для создания таблицы в Selena.
```Bash
mysql -hxx.xx.xx.x -P9030 -uroot -p < selena-create.all.sql
-
Используйте SQL-скрипт с префиксом
flink-createдля создания исходных и целевых таблиц Flink и запуска задания Flink для синхронизации данных.bin/sql-client.sh embedded < flink-create.all.sqlПосле успешного выполнения указанной выше команды задание Flink по синхронизации данных продолжает работать.
-
Наблюдайте за статусом задания Flink.
bin/flink listЕсли при выполнении задания возникает ошибка, вы можете просмотреть подробную информацию об ошибке в логах Flink. Кроме того, вы можете изменить конфигурации Flink в файле conf/flink-conf.yaml, такие как память и slot.
Примечания
-
Убедитесь, что Server Agent Service включен.
Проверьте, работает ли Server Agent Service нормально.
EXEC master.dbo.xp_servicecontrol N'QUERYSTATE', N'SQLSERVERAGENT'
GOВключите Server Agent Service.
/opt/mssql/bin/mssql-conf set sqlagent.enabled true -
Убедитесь, что CDC для соответствующей базы данных включен.
Проверьте, включен ли CDC для соответствующей базы данных.
select is_cdc_enabled, name from sys.databases where name = 'XXX_databases'
GO Включите CDC.
:::note
При выполнении этой команды убедитесь, что
serverRoleпользователя —sysadmin. :::
USE XXX_databases
GO
EXEC sys.sp_cdc_enable_db
GO -
Убедитесь, что CDC для соответствующей таблицы включен.
EXEC sys.sp_cdc_enable_table
@source_schema = 'XXX_schema',
@source_name = 'XXX_table',
@role_name = NULL,
@supports_net_changes = 0;
GO
Синхронизация TiDB с Selena
Введение
Flink CDC connector и SMT могут синхронизировать данные из TiDB в течение доли секунды.
SMT может автоматически генерировать DDL-операторы для исходных и целевых таблиц Flink на основе информации о cluster и структуре таблиц TiDB и Selena.
Flink CDC connector захватывае�т данные путем прямого чтения полных и инкрементных данных из базового хранилища TiKV. Полные данные получаются из диапазонов, разделенных по ключам, а инкрементные данные получаются с использованием CDC Client, предоставляемого TiDB. Затем данные записываются в Selena через Flink-connector-selena.
Шаги
-
Скачайте Flink. Поддерживается версия Flink 1.11 или более поздняя.
-
Скачайте Flink CDC connector. Убедитесь, что вы скачали flink-sql-connector-tidb-cdc-xxx.jar, соответствующий версии Flink.
-
Скачайте Flink Selena connector.
-
Скопируйте flink-sql-connector-tidb-cdc-xxx.jar, flink-connector-selena-xxx.jar в flink-xxx/lib/.
-
Скачайте smt.tar.gz.
-
Распакуйте и измените файл конфигурации SMT.
[db]
host = 127.0.0.1
port = 4000
user = root
password =
# currently available types: `mysql`, `pgsql`, `oracle`, `hive`, `clickhouse`, `sqlserver`, `tidb`
type = tidb
# # only takes effect on `type == hive`.
# # Available values: kerberos, none, nosasl, kerberos_http, none_http, zk, ldap
# authentication = kerberos
[other]
# number of backends in Selena
be_num = 3
# `decimal_v3` is supported since Selena-1.18.1
use_decimal_v3 = false
# directory to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# pattern to match databases for setting properties
database = ^db$
# pattern to match tables for setting properties
table = ^table$
schema = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.selena.jdbc-url=jdbc:mysql://192.168.1.1:9030
flink.selena.load-url= 192.168.1.1:8030
flink.selena.username=root
flink.selena.password=
flink.selena.sink.max-retries=10
flink.selena.sink.buffer-flush.interval-ms=15000
flink.selena.sink.properties.format=json
flink.selena.sink.properties.strip_outer_array=true
############################################
### flink-cdc configuration for `tidb`
############################################
# # Only takes effect on TiDB before v2.0.0.
# # TiKV cluster's PD address.
# flink.cdc.pd-addresses = 127.0.0.1:2379 -
Выполните selena-migrate-tool. Все SQL-скрипты генерируются в директории
result.$./selena-migrate-tool
$ls result
flink-create.1.sql smt.tar.gz selena-create.all.sql
flink-create.all.sql selena-create.1.sql selena-external-create.all.sql -
Используйте SQL-скрипт с префиксом
selena-createдля создания таблицы в Selena.mysql -hxx.xx.xx.x -P9030 -uroot -p < selena-create.all.sql -
Используйте SQL-скрипт с префиксом
flink-createдля создания исходных и целевых таблиц Flink и запуска задания Flink для синхронизации данных.bin/sql-client.sh embedded < flink-create.all.sql
После успешного выполнения указанной выше команды задание Flink по синхронизации данных продолжает работать.
-
Наблюдайте за статусом задания Flink.
bin/flink listЕсли при выполнении задания возникает ошибка, вы можете просмотреть подробную информацию об ошибке в логах Flink. Кроме того, вы можете изменить конфигурации Flink в файле conf/flink-conf.yaml, такие как память и slot.
Примечания
Для TiDB версии до v2.0.0 требуется дополнительная конфигурация flink.cdc.pd-addresses.
############################################
### flink-cdc configuration for `tidb`
############################################
# # Only takes effect on TiDB before v2.0.0.
# # TiKV cluster's PD address.
# flink.cdc.pd-addresses = 127.0.0.1:2379