Загрузка из HDFS
Загрузка данных из HDFS
Selena предоставляет следующие варианты загрузки данных из HDFS:
- Синхронная загрузка с использованием INSERT+
FILES() - Асинхронная загрузка с использованием Broker Load
- Непрерывная асинхронная загрузка с использованием Pipe
Каждый из этих вариантов имеет свои преимущества, которые подробно описаны в следующих разделах.
В большинстве случаев мы рекомендуем использовать метод INSERT+FILES(), который намного проще в использовании.
Однако метод INSERT+FILES() в настоящее время поддерживает только форматы файлов Parquet, ORC и CSV. Поэтому, если вам нужно загружать данные других форматов файлов, таких как JSON, или выполнять изменения данных, такие как DELETE, во время загрузки данных, вы можете использовать Broker Load.
Если вам нужно загрузить больш�ое количество файлов данных со значительным общим объёмом данных (например, более 100 ГБ или даже 1 ТБ), мы рекомендуем использовать метод Pipe. Pipe может разбивать файлы по их количеству или размеру, разделяя задание загрузки на более мелкие последовательные задачи. Такой подход гарантирует, что ошибки в одном файле не повлияют на всё задание загрузки, и минимизирует необходимость повторных попыток из-за ошибок в данных.
Перед началом работы
Подготовка исходных данных
Убедитесь, что исходные данные, которые вы хотите загрузить в Selena, правильно хранятся в вашем cluster HDFS. В этой теме предполагается, что вы хотите загрузить /user/amber/user_behavior_ten_million_rows.parquet из HDFS в Selena.
Проверка привилегий
Вы можете загружать данные в таблицы Selena только как пользователь, имеющий привилегию INSERT на эти таблицы Selena. Если у вас нет привилегии INSERT, следуйте инструкциям в разделе GRANT, чтобы предоставить привилегию INSERT пользователю, которого вы используете для подключения к вашему cluster Selena. Синтаксис: GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}.
Сбор данных аутентификации
Вы можете использовать простой метод аутентификации для установления соединений с вашим cluster HDFS. Чтобы использовать простую аутентификацию, вам нужно собрать имя пользователя и пароль учётной записи, которую вы можете использовать для доступа к NameNode cluster HDFS.
Использование INSERT+FILES()
Этот метод доступен начиная с версии v1.5.2 и в настоящее время поддерживает только форматы файлов Parquet, ORC и CSV (начиная с версии v1.5.2).
Преимущества INSERT+FILES()
FILES() может читать файл, хранящийся в облачном хранилище, на основе указанных вами свойств, связанных с путём, выводить схему таблицы данных в файле, а затем возвращать данные из файла в виде строк данных.
С помощью FILES() вы можете:
- Запрашивать данные напрямую из HDFS с помощью SELECT.
- Создавать и загружать таблицу с помощью CREATE TABLE AS SELECT (CTAS).
- Загружать данные в существующую таблицу с помощью INSERT.
Типичные примеры
Прямой запрос из HDFS с помощью SELECT
Прямой запрос из HDFS с помощью SELECT+FILES() позволяет получить хороший предварительный просмотр содержимого набора данных перед созданием таблицы. Например:
- Получить предварительный просмотр набора данных без сохранения данных.
- Запросить минимальные и максимальные значения и решить, какие типы данных использовать.
- Проверить наличие значений
NULL.
Следующий пример запрашивает файл данных /user/amber/user_behavior_ten_million_rows.parquet, хранящийся в cluster HDFS:
SELECT * FROM FILES
(
"path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
)
LIMIT 3;
Система возвращает следующий результат запроса:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 543711 | 829192 | 2355072 | pv | 2017-11-27 08:22:37 |
| 543711 | 2056618 | 3645362 | pv | 2017-11-27 10:16:46 |
| 543711 | 1165492 | 3645362 | pv | 2017-11-27 10:17:00 |
+--------+---------+------------+--------------+---------------------+
ПРИМЕЧАНИЕ
Обратите внимание, что имена столбцов, возвращённые выше, предоставлены файлом Parquet.
Создание и загрузка таблицы с помощью CTAS
Это продолжение предыдущего примера. Предыдущий запрос обёрнут в CREATE TABLE AS SELECT (CTAS) для автоматиза�ции создания таблицы с использованием вывода схемы. Это означает, что Selena выведет схему таблицы, создаст нужную вам таблицу, а затем загрузит данные в таблицу. Имена и типы столбцов не требуются для создания таблицы при использовании табличной функции FILES() с файлами Parquet, поскольку формат Parquet включает имена столбцов.
ПРИМЕЧАНИЕ
Синтаксис CREATE TABLE при использовании вывода схемы не позволяет устанавливать количество replica, поэтому установите его перед созданием таблицы. Пример ниже для системы с тремя replica:
ADMIN SET FRONTEND CONFIG ('default_replication_num' = "3");
Создайте базу данных и переключитесь на неё:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Используйте CTAS для создания таблицы и загрузки данных из файла данных /user/amber/user_behavior_ten_million_rows.parquet в таблицу:
CREATE TABLE user_behavior_inferred AS
SELECT * FROM FILES
(
"path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
После создания таблицы вы можете просмотреть её схему с помощью DESCRIBE:
DESCRIBE user_behavior_inferred;
Система возвращает следующий результат запроса:
+--------------+-----------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------+------+-------+---------+-------+
| UserID | bigint | YES | true | NULL | |
| ItemID | bigint | YES | true | NULL | |
| CategoryID | bigint | YES | true | NULL | |
| BehaviorType | varbinary | YES | false | NULL | |
| Timestamp | varbinary | YES | false | NULL | |
+--------------+-----------+------+-------+---------+-------+
Запрос�ите таблицу, чтобы убедиться, что данные были загружены в неё. Пример:
SELECT * from user_behavior_inferred LIMIT 3;
Возвращается следующий результат запроса, указывающий, что данные были успешно загружены:
+--------+--------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+--------+------------+--------------+---------------------+
| 84 | 56257 | 1879194 | pv | 2017-11-26 05:56:23 |
| 84 | 108021 | 2982027 | pv | 2017-12-02 05:43:00 |
| 84 | 390657 | 1879194 | pv | 2017-11-28 11:20:30 |
+--------+--------+------------+--------------+---------------------+
Загрузка в существующую таблицу с помощью INSERT
Вы можете захотеть настроить таблицу, в которую вставляете данные, например:
- тип данных столбца, настройку nullable или значения по умолчанию
- типы ключей и столбцы
- разбиение данных на partition и bucket
ПРИМЕЧАНИЕ
Создание наиболее эффективной структуры таблицы требует знания того, как данные будут использоваться и содержимого столбцов. Эта тема не охватывает проектирование таблиц. Для получения информации о проектировании таблиц см. Типы таблиц.
В этом примере мы создаём таблицу на основе знаний о том, как таблица будет запрашиваться, и данных в файле Parquet. Знание данных в файле Parquet можно получить, запросив файл напрямую в HDFS.
- Поскольку запрос набора данных в HDFS указывает, что столбец
Timestampсодержит данные, соответствующие типу данных VARBINARY, тип столбца указан в следующем DDL. - Запрашивая данные в HDFS, вы можете обнаружить, что в наборе данных нет значений
NULL, поэтому DDL не устанавливает какие-либо столбцы как nullable. - На основе знаний об ожидаемых типах запросов sort key и столбец для bucket установлены на столбец
UserID. Ваш случай использования может отличаться для этих данных, поэтому вы можете решить использоватьItemIDв дополнение кUserIDили вместо него для sort key.
Создайте базу данных и переключитесь на неё:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Создайте таблицу вручную (мы рекомендуем, чтобы таблица имела ту же схему, что и файл Parquet, который вы хотите загрузить из HDFS):
CREATE TABLE user_behavior_declared
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp varbinary
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
Отобразите схему, чтобы вы могли сравнить её с выведенной схемой, созданной табличной функцией FILES():
DESCRIBE user_behavior_declared;
+--------------+----------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+----------------+------+-------+---------+-------+
| UserID | int | NO | true | NULL | |
| ItemID | int | NO | false | NULL | |
| CategoryID | int | NO | false | NULL | |
| BehaviorType | varchar(65533) | NO | false | NULL | |
| Timestamp | varbinary | NO | false | NULL | |
+--------------+----------------+------+-------+---------+-------+
5 rows in set (0.00 sec)
Сравните схему, которую вы только что создали, со схемой, выведенной ранее с помощью табличной функции FILES(). Посмотрите на:
- типы данных
- nullable
- ключевые поля
Для лучшего контроля схемы целевой таблицы и лучшей производительности запросов мы рекомендуем указывать схему таблицы вручную в производственных средах.
После создания таблицы вы можете загрузить её с помощью INSERT INTO SELECT FROM FILES():
INSERT INTO user_behavior_declared
SELECT * FROM FILES
(
"path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
После завершения загрузки вы можете запросить таблицу, чтобы убедиться, что данные были загружены в неё. Пример:
SELECT * from user_behavior_declared LIMIT 3;
Возвращается следующий результат запроса, указывающий, что данные были успешно загружены:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 107 | 1568743 | 4476428 | pv | 2017-11-25 14:29:53 |
| 107 | 470767 | 1020087 | pv | 2017-11-25 14:32:31 |
| 107 | 358238 | 1817004 | pv | 2017-11-25 14:43:23 |
+--------+---------+------------+--------------+---------------------+
Проверка прогресса загрузки
Вы можете запросить прогресс заданий INSERT из представления loads в Information Schema Selena. Эта функция поддерживается начиная с версии v1.5.2. Пример:
SELECT * FROM information_schema.loads ORDER BY JOB_ID DESC;
Для получения информации о полях, предоставляемых в представлении loads, см. loads.
Если вы отправили несколько заданий загрузки, вы можете фильтровать по LABEL, связанному с заданием. Пример:
SELECT * FROM information_schema.loads WHERE LABEL = 'insert_0d86c3f9-851f-11ee-9c3e-00163e044958' \G
*************************** 1. row ***************************
JOB_ID: 10214
LABEL: insert_0d86c3f9-851f-11ee-9c3e-00163e044958
DATABASE_NAME: mydatabase
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: INSERT
PRIORITY: NORMAL
SCAN_ROWS: 10000000
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 10000000
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):300; max_filter_ratio:0.0
CREATE_TIME: 2023-11-17 15:58:14
ETL_START_TIME: 2023-11-17 15:58:14
ETL_FINISH_TIME: 2023-11-17 15:58:14
LOAD_START_TIME: 2023-11-17 15:58:14
LOAD_FINISH_TIME: 2023-11-17 15:58:18
JOB_DETAILS: {"All backends":{"0d86c3f9-851f-11ee-9c3e-00163e044958":[10120]},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":311710786,"InternalTableLoadRows":10000000,"ScanBytes":581574034,"ScanRows":10000000,"TaskNumber":1,"Unfinished backends":{"0d86c3f9-851f-11ee-9c3e-00163e044958":[]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
REJECTED_RECORD_PATH: NULL
ПРИМЕЧАНИЕ
INSERT — это синхронная команда. Если задание INSERT всё ещё выполняется, ва�м нужно открыть другую сессию, чтобы проверить его статус выполнения.
Использование Broker Load
Асинхронный процесс Broker Load обрабатывает подключение к HDFS, извлечение данных и сохранение данных в Selena.
Этот метод поддерживает следующие форматы файлов:
- Parquet
- ORC
- CSV
- JSON (поддерживается начиная с версии v1.5.2)
Преимущества Broker Load
- Broker Load выполняется в фоновом режиме, и клиентам не нужно оставаться подключёнными для продолжения задания.
- Broker Load предпочтителен для длительных заданий, тайм-аут по умолчанию составляет 4 часа.
- В дополнение к форматам файлов Parquet и ORC, Broker Load поддерживает формат файлов CSV и формат файлов JSON (формат файлов JSON поддерживается начиная с версии v1.5.2).
Поток данных
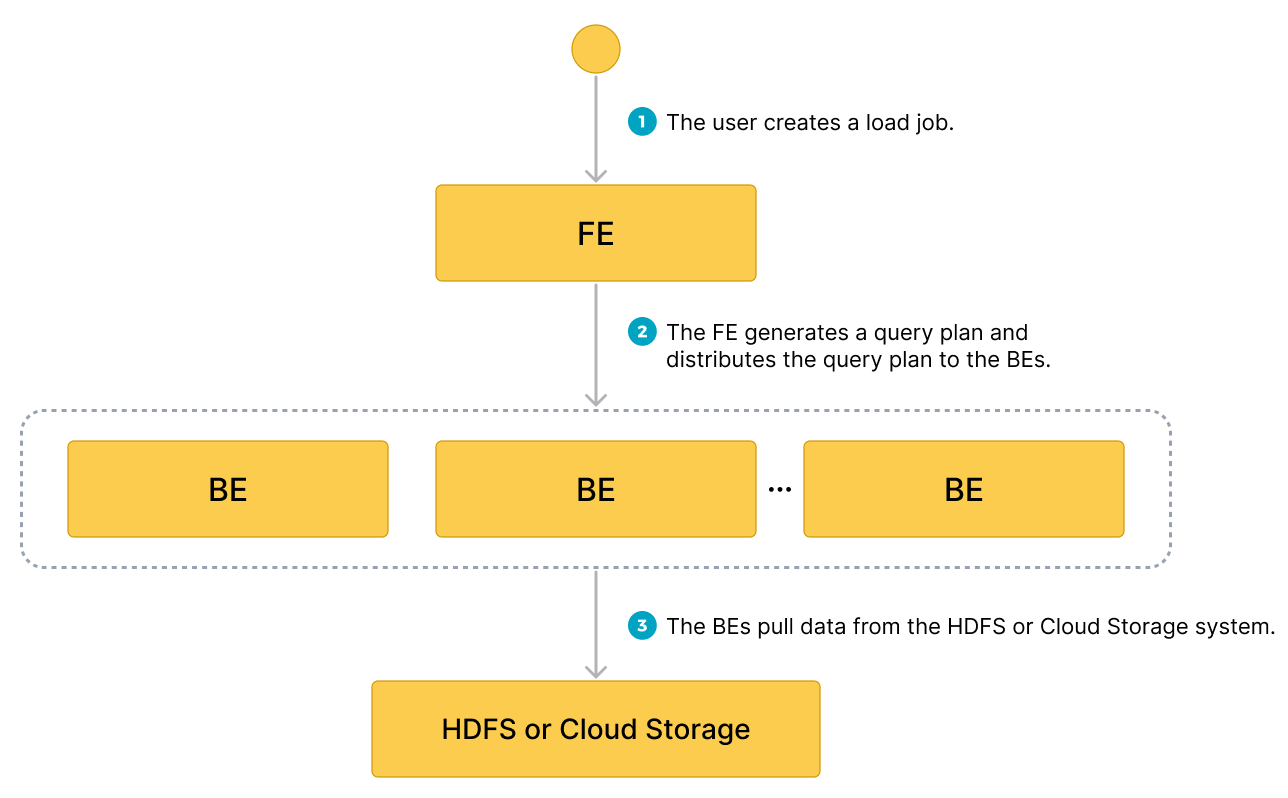
- Пользователь создаёт задание загрузки.
- Frontend (FE) создаёт план запроса и распределяет план на backend-узлы (BE) или compute-узлы (CN).
- BE или CN извлекают данные из источника и загружают данные в Selena.
Типичный пример
Создайте таблицу, запустите процесс загрузки, который извлекает файл данных /user/amber/user_behavior_ten_million_rows.parquet из HDFS, и проверьте прогресс и успешность загрузки данных.
Создание базы данных и таблицы
Создайте базу данных и переключитесь на неё:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Создайте таблицу вручную (мы рекомендуем, чтобы таблица имела ту же схему, что и файл Parquet, который вы хотите загрузить из HDFS):
CREATE TABLE user_behavior
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp varbinary
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
Запуск Broker Load
Выполните следующую команду, чтобы запустить задание Broker Load, которое загружает данные из файла данных /user/amber/user_behavior_ten_million_rows.parquet в таблицу user_behavior:
LOAD LABEL user_behavior
(
DATA INFILE("hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet")
INTO TABLE user_behavior
FORMAT AS "parquet"
)
WITH BROKER
(
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
)
PROPERTIES
(
"timeout" = "72000"
);
Это задание имеет четыре основных раздела:
LABEL: Строка, используемая при запросе состояния задания загрузки.LOADdeclaration: URI источника, формат исходных данных и имя целевой таблицы.BROKER: Данные подключения к источнику.PROPERTIES: Значение тайм-аута и любые другие свойства, применяемые к заданию загрузки.
Подробный синтаксис и описание параметров см. в BROKER LOAD.
Проверка прогресса загрузки
Вы можете запросить прогресс заданий Broker Load из представления information_schema.loads. Эта функция поддерживается начиная с версии v1.5.2.
SELECT * FROM information_schema.loads;
Для получения информации о полях, предоставляемых в представлении loads, см. Information Schema).
Если вы отправили несколько заданий загрузки, вы можете фильтровать по LABEL, связанному с заданием. Пример:
SELECT * FROM information_schema.loads WHERE LABEL = 'user_behavior';
В выводе ниже есть две записи для задания загрузки user_behavior:
- Первая запись показывает состояние
CANCELLED. Прокрутите доERROR_MSG, и вы увидите, что задание завершилось неудачей из-заlistPath failed. - Вторая запись показывает состояние
FINISHED, что означает, что задание выполнено успешно.
JOB_ID|LABEL |DATABASE_NAME|STATE |PROGRESS |TYPE |PRIORITY|SCAN_ROWS|FILTERED_ROWS|UNSELECTED_ROWS|SINK_ROWS|ETL_INFO|TASK_INFO |CREATE_TIME |ETL_START_TIME |ETL_FINISH_TIME |LOAD_START_TIME |LOAD_FINISH_TIME |JOB_DETAILS |ERROR_MSG |TRACKING_URL|TRACKING_SQL|REJECTED_RECORD_PATH|
------+-------------------------------------------+-------------+---------+-------------------+------+--------+---------+-------------+---------------+---------+--------+----------------------------------------------------+-------------------+-------------------+-------------------+-------------------+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+------------+------------+--------------------+
10121|user_behavior |mydatabase |CANCELLED|ETL:N/A; LOAD:N/A |BROKER|NORMAL | 0| 0| 0| 0| |resource:N/A; timeout(s):72000; max_filter_ratio:0.0|2023-08-10 14:59:30| | | |2023-08-10 14:59:34|{"All backends":{},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":0,"InternalTableLoadRows":0,"ScanBytes":0,"ScanRows":0,"TaskNumber":0,"Unfinished backends":{}} |type:ETL_RUN_FAIL; msg:listPath failed| | | |
10106|user_behavior |mydatabase |FINISHED |ETL:100%; LOAD:100%|BROKER|NORMAL | 86953525| 0| 0| 86953525| |resource:N/A; timeout(s):72000; max_filter_ratio:0.0|2023-08-10 14:50:15|2023-08-10 14:50:19|2023-08-10 14:50:19|2023-08-10 14:50:19|2023-08-10 14:55:10|{"All backends":{"a5fe5e1d-d7d0-4826-ba99-c7348f9a5f2f":[10004]},"FileNumber":1,"FileSize":1225637388,"InternalTableLoadBytes":2710603082,"InternalTableLoadRows":86953525,"ScanBytes":1225637388,"ScanRows":86953525,"TaskNumber":1,"Unfinished backends":{"a5| | | | |
После того как вы убедитесь, что задание загрузки завершено, вы можете проверить подмножество целевой таблицы, чтобы увидеть, были ли данные успешно загружены. Пример:
SELECT * from user_behavior LIMIT 3;
Возвращается следующий результат запроса, указывающий, что данные были успешно загружены:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 142 | 2869980 | 2939262 | pv | 2017-11-25 03:43:22 |
| 142 | 2522236 | 1669167 | pv | 2017-11-25 15:14:12 |
| 142 | 3031639 | 3607361 | pv | 2017-11-25 15:19:25 |
+--------+---------+------------+--------------+---------------------+
Использование Pipe
Начиная с версии v1.5.2, Selena предоставляет метод загрузки Pipe, который в настоящее время поддерживает только форматы файлов Parquet и ORC.
Преимущества Pipe
Pipe идеально подходит для непрерывной загрузки данных и крупномасштабной загрузки данных:
-
Крупномасштабная загрузка данных микро-пакетами помогает снизить затраты на повторные попытки, вызванные ошибками данных.
С помощью Pipe Selena обеспечивает эффективную загрузку большого количества файлов данных со значительным общим объёмом данных. Pipe автоматически разбивает файлы на основе их количества или размера, разделяя задание загрузки на более мелкие последовательные задачи. Такой подход гарантирует, что ошибки в одном файле не повлияют на всё задание загрузки. Статус загрузки каждого файла записывается Pipe, что позволяет легко идентифицировать и исправлять файлы, содержащие ошибки. Минимизируя необходимость повторных попыток из-за ошибок данных, этот подход помогает снизить затраты.
-
Непрерывная загрузка данных помогает сократить трудозатраты.
Pipe помогает записывать новые или обновлённые файлы данных в определённое место и непрерывно загружать новые данные из этих файлов в Selena. После создания задания Pipe с указанием
"AUTO_INGEST" = "TRUE"оно будет постоянно отслеживать изменения файлов данных, хранящихся по указанному пути, и автоматич�ески загружать новые или обновлённые данные из файлов данных в целевую таблицу Selena.
Кроме того, Pipe выполняет проверку уникальности файлов, чтобы предотвратить повторную загрузку данных. В процессе загрузки Pipe проверяет уникальность каждого файла данных на основе имени файла и дайджеста. Если файл с определённым именем и дайджестом уже был обработан заданием Pipe, это задание Pipe пропустит все последующие файлы с тем же именем и дайджестом. Обратите внимание, что HDFS uses LastModifiedTime используется как дайджест файла.
Статус загрузки каждого файла данных записывается и сохраняется в представлении information_schema.pipe_files. После удаления задания Pipe, связанного с этим представлением, записи о файлах, загруженных в этом задании, также будут удалены.
Поток данных
Pipe идеально подходит для непрерывной загрузки данных и крупномасштабной загрузки данных:
-
Крупномасштабная загрузка данных микропакетами помогает снизить затраты на повторные попытки, вызванные ошибками данных.
С помощью Pipe Selena обеспечивает эффективную загрузку большого количества файлов данных со значительным общим объёмом данных. Pipe автоматически разбивает файлы на основе их количества или размера, разделяя задание загрузки на меньшие последовательные задачи. Этот подход гарантирует, что ошибки в одном файле не повлияют на всё задание загрузки. Статус загрузки каждого файла записывается Pipe, что позволяет легко идентифицировать и исправлять файлы, содержащие ошибки. Минимизируя необходимость повторных попыток из-за ошибок данных, этот подход помогает снизить затраты.
-
Непрерывная загрузка данных помогает сократить трудозатраты.
Pipe помогает записывать новые или обновлённые файлы данных в определённое место и непрерывно загружать новые данные из этих файлов в Selena. После создания задания Pipe с указанием
"AUTO_INGEST" = "TRUE"оно будет постоянно отслеживать изменения в файлах данных, хранящихся по указанно�му пути, и автоматически загружать новые или обновлённые данные из файлов данных в целевую таблицу Selena.
Кроме того, Pipe выполняет проверки уникальности файлов, чтобы предотвратить дублирование загрузки данных. В процессе загрузки Pipe проверяет уникальность каждого файла данных на основе имени файла и дайджеста. Если файл с определённым именем и дайджестом уже был обработан заданием Pipe, задание Pipe пропустит все последующие файлы с тем же именем и дайджестом. Обратите внимание, что HDFS использует LastModifiedTime в качестве дайджеста файла.
Статус загрузки каждого файла данных записывается и сохраняется в представлении information_schema.pipe_files. После удаления задания Pipe, связанного с представлением, записи о файлах, загруженных в этом задании, также будут удалены.
Поток данных
Различия между Pipe и INSERT+FILES()
Задание Pipe разделяется на одну или несколько транзакций в зависимости от размера и количества строк в каждом файле данных. Пользователи могут запрашивать промежуточные результаты во время процесса загрузки. Напротив, задание INSERT+FILES() обрабатывается как одна транзакция, и пользователи не могут просматривать данные во время процесса загрузки.
Последовательность загрузки файлов
Для каждого задания Pipe Selena поддерживает очередь файлов, из которой она извлекает и загружает файлы данных в виде микропакетов. Pipe не гарантирует, что файлы данных загружаются в том же порядке, в котором они были загружены. Поэтому более новые данные могут быть загружены раньше более старых данных.
Типичный пример
Создание базы данных и таблицы
Создайте базу данных и переключитесь на неё:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Создайте таблицу вручную (мы рекомендуем, чтобы таблица имела ту же схему, что и файл Parquet, который вы хотите загрузить из HDFS):
CREATE TABLE user_behavior_replica
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp varbinary
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
Запуск задания Pipe
Выполните следующую команду, чтобы запустить задание Pipe, которое загружает данные из файла данных /user/amber/user_behavior_ten_million_rows.parquet в таблицу user_behavior_replica:
CREATE PIPE user_behavior_replica
PROPERTIES
(
"AUTO_INGEST" = "TRUE"
)
AS
INSERT INTO user_behavior_replica
SELECT * FROM FILES
(
"path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
Это задание имеет четыре основных раздела:
pipe_name: Имя pipe. Имя pipe должно быть уникальным в базе данных, к которой принадлежит pipe.INSERT_SQL: Оператор INSERT INTO SELECT FROM FILES, который используется для загрузки данных из указанного исходного файла данных в целевую таблицу.PROPERTIES: Набор необязательных параметров, которые определяют, как выполнять pipe. Они включаютAUTO_INGEST,POLL_INTERVAL,BATCH_SIZEиBATCH_FILES. Укажите эти свойства в формате"key" = "value".
Подробный синтаксис и описание параметров см. в CREATE PIPE.
Проверка прогресса загрузки
-
Запросите прогресс заданий Pipe с помощью SHOW PIPES.
SHOW PIPES;Если вы отправили несколько заданий загрузки, вы можете фильтровать по
NAME, связанному с заданием. Пример:SHOW PIPES WHERE NAME = 'user_behavior_replica' \G
*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10252
PIPE_NAME: user_behavior_replica
STATE: RUNNING
TABLE_NAME: mydatabase.user_behavior_replica
LOAD_STATUS: {"loadedFiles":1,"loadedBytes":132251298,"loadingFiles":0,"lastLoadedTime":"2023-11-17 16:13:22"}
LAST_ERROR: NULL
CREATED_TIME: 2023-11-17 16:13:15
1 row in set (0.00 sec) -
Запросите прогресс заданий Pipe из представления
pipesв Information Schema Selena.SELECT * FROM information_schema.pipes;Если вы отправили несколько заданий загрузки, вы можете фильтровать по
PIPE_NAME, связанному с заданием. Пример:SELECT * FROM information_schema.pipes WHERE pipe_name = 'user_behavior_replica' \G
*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10252
PIPE_NAME: user_behavior_replica
STATE: RUNNING
TABLE_NAME: mydatabase.user_behavior_replica
LOAD_STATUS: {"loadedFiles":1,"loadedBytes":132251298,"loadingFiles":0,"lastLoadedTime":"2023-11-17 16:13:22"}
LAST_ERROR:
CREATED_TIME: 2023-11-17 16:13:15
1 row in set (0.00 sec)
Проверка статуса файлов�
Вы можете запросить статус загрузки файлов, загруженных из представления pipe_files в Information Schema Selena.
SELECT * FROM information_schema.pipe_files;
Если вы отправили несколько заданий загрузки, вы можете фильтровать по PIPE_NAME, связанному с заданием. Пример:
SELECT * FROM information_schema.pipe_files WHERE pipe_name = 'user_behavior_replica' \G
*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10252
PIPE_NAME: user_behavior_replica
FILE_NAME: hdfs://172.26.195.67:9000/user/amber/user_behavior_ten_million_rows.parquet
FILE_VERSION: 1700035418838
FILE_SIZE: 132251298
LAST_MODIFIED: 2023-11-15 08:03:38
LOAD_STATE: FINISHED
STAGED_TIME: 2023-11-17 16:13:16
START_LOAD_TIME: 2023-11-17 16:13:17
FINISH_LOAD_TIME: 2023-11-17 16:13:22
ERROR_MSG:
1 row in set (0.02 sec)
Управление Pipe
Вы можете изменять, приостанавливать или возобновлять, удалять или запрашивать созданные вами pipe, а также повторять загрузку определённых файлов данных. Для получения дополнительной информации см. ALTER PIPE, SUSPEND or RESUME PIPE, DROP PIPE, SHOW PIPES и RETRY FILE.