Архитектура
Selena имеет простую архитектуру. Вся система состоит только из двух типов компонентов: frontend и backend. Узлы frontend называются FE. Существует два типа backend-узлов: BE и CN (Compute Nodes). BE развертываются, когда используется локальное хранилище данных, а CN развертываются, когда данные хранятся в object storage или HDFS. Selena не зависит от каких-либо внешних компонентов, что упрощает развертывание и обслуживание. Узлы могут масштабироваться горизонтально без простоя сервиса. Кроме того, Selena имеет механизм репликации для метаданных и служебных данных, что повышает надежность данных и эффективно предотвращает единые точки отказа (SPOF).
Selena совместима с протоколами MySQL и поддерживает стандартный SQL. Пользователи могут легко подключаться к Selena из клиентов MySQL для получения мгновенной и ценной аналитики.
Варианты архитектуры
Selena поддерживает архитектуры shared-nothing (каждый BE имеет часть данных в своем локальном хранилище) и shared-data (все данные в object storage или HDFS, а каждый CN имеет только cache в локальном хранилище). Вы можете решить, где хранить данные, исходя из своих потребностей.
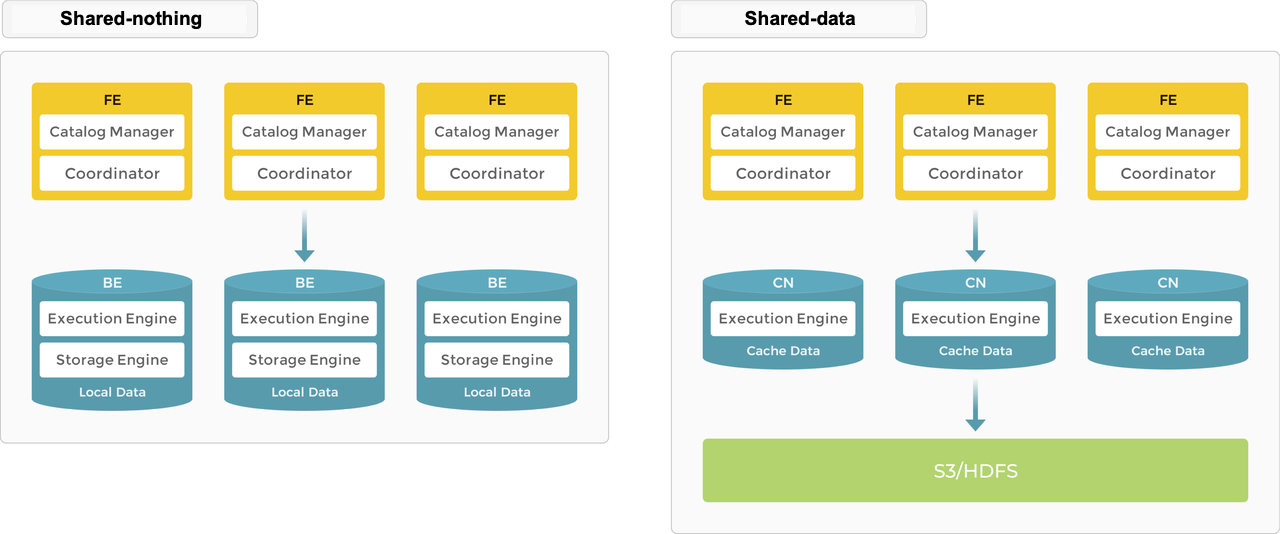
Shared-nothing
Локальное хранилище обеспечивает улучшенную задержку запросов для запросов в реальном времени.
Как типичная база данных с массивно-параллельной обработкой (MPP), Selena поддерживает архитектуру shared-nothing. В этой архитектуре BE отвечают как за хранение данных, так и за вычисления. Прямой доступ к локальным данным на узле BE позволяет выполнять локальные вычисления, избегая передачи и копирования данных, и обеспечивая сверхбыструю производительность запросов и аналитики. Эта архитектура поддерживает хранение данных с несколькими репликами, повышая способность cluster обрабатывать высококонкурентные запросы и обеспечивая надежность данных. Она хорошо подходит для сценариев, требующих оптимальной производительности запросов.
Узлы
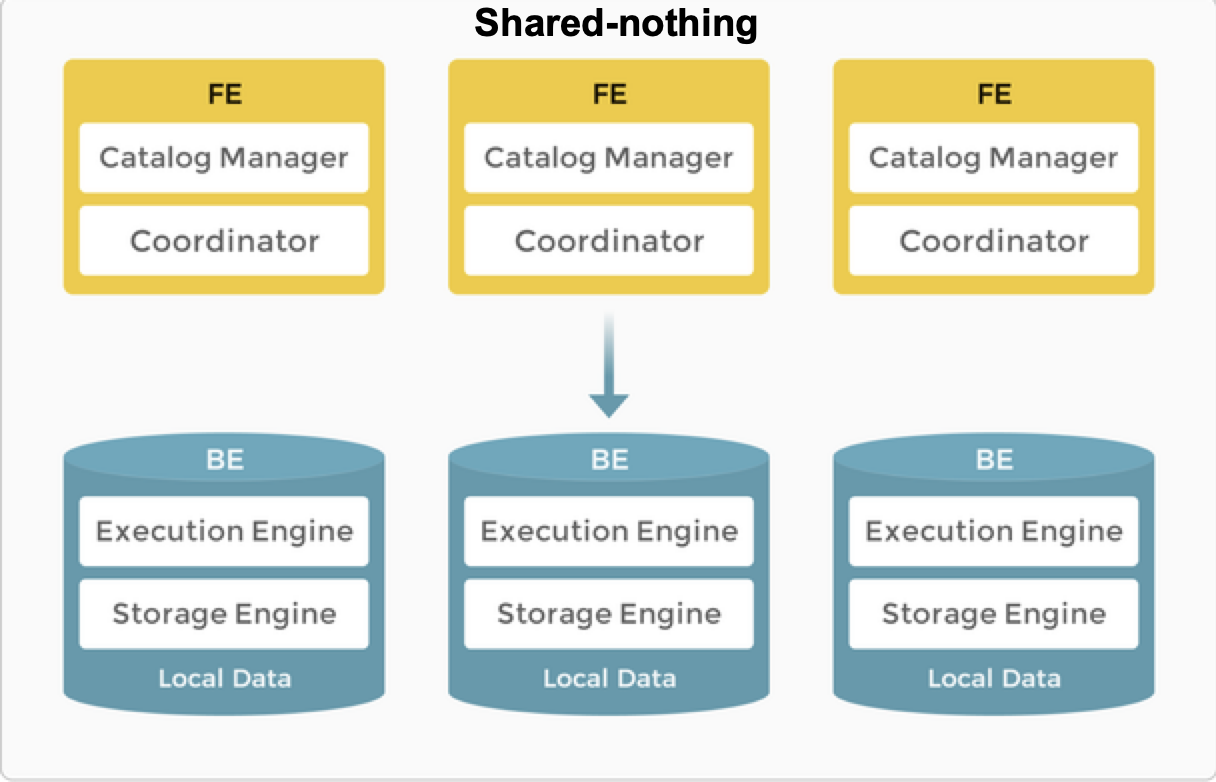
В архитектуре shared-nothing Selena состоит из двух типов узлов: FE и BE.
- FE отвечают за управление метаданными и построение планов выполнения.
- BE выполняют планы запросов и хранят данные. BE используют локальное хранилище для ускорения запросов и механизм множественной репликации для обеспечения высокой доступности данных.
FE
FE отвечают за управление метаданными, управление клиентскими с�оединениями, планирование и планирование выполнения запросов. Каждый FE использует BDB JE (Berkeley DB Java Edition) для хранения и поддержания полной копии метаданных в своей памяти, обеспечивая согласованность сервисов на всех FE. FE могут работать как leader, followers и observers. Если узел leader выходит из строя, followers выбирают нового leader на основе протокола Raft.
| Роль FE | Управление метаданными | Выбор leader |
|---|---|---|
| Leader | Leader FE читает и записывает метаданные. Follower и observer FE могут только читать метаданные. Они направляют запросы на запись метаданных к leader FE. Leader FE обновляет метаданные, а затем использует протокол Raft для синхронизации изменений метаданных с follower и observer FE. Запись данных считается успешной только после синхронизации изменений метаданных более чем с половиной follower FE. | Leader FE, технически говоря, также является follower-узлом и выбирается из follower FE. Для проведения выбора leader более половины follower FE в cluster должны быть активны. Когда leader FE выходит из строя, follower FE начинают новый раунд выбора leader. |
| Follower | Followers могут только читать метаданные. Они синхронизируют и воспроизводят логи от leader FE для обновления метаданных. | Followers участвуют в выборе leader, что требует активности более половины followers в cluster. |
| Observer | Observers синхронизируют и воспроизводят логи от leader FE для обновления метаданных. | Observers в основном используются для увеличения конкурентности запросов cluster. Observers не участвуют в выборе leader и, следовательно, не создают дополнительной нагрузки на процесс выбора leader в cluster. |
BE
BE отвечают за хранение данных и выполнение SQL.
-
Хранение данных: BE имеют эквивалентные возможности хранения данных. FE распределяют данные по BE на основе предопределенных правил. BE преобразуют загруженные данные, записывают данные в требуемый формат и генерируют индексы для данных.
-
Выполнение SQL: FE разбирают каждый SQL-запрос в логический план выполнения в соответствии с семантикой запроса, а затем преобразуют логический план в физические планы выполнения, которые могут быть выполнены на BE. BE, которые хранят целевые данные, выполняют запрос. Это устраняет необходимость в передаче и копировании данных, обеспечивая высокую производительность запросов.
Shared-data
Object storage и HDFS обеспечивают преимущества в стоимости, надежности и масштабируемости. Помимо масштабируемости хранилища, узлы CN могут добавляться и удаляться без необходимости перебалансировки данных, поскольку хранилище и вычисления разделены.
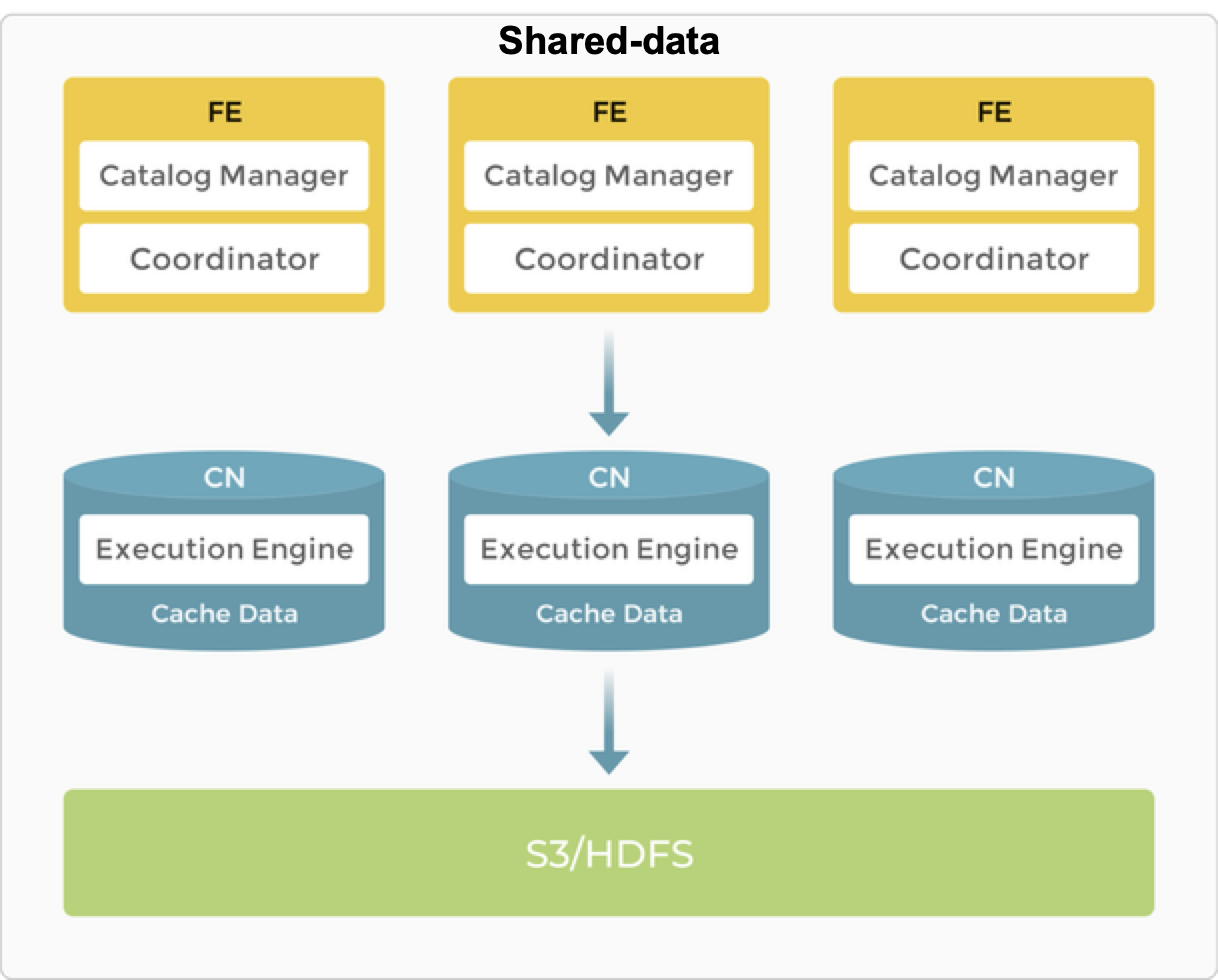
В архитектуре shared-data BE заменяются на "compute nodes (CN)", которые отвечают только за задачи вычисления данных и кэширование горячих данных. Данные хранятся в недорогих и надежных удаленных системах хранения, таких как Amazon S3, Google Cloud Storage, Azure Blob Storage, MinIO и т.д. При попадании в cache производительность запросов сравнима с архитектурой shared-nothing. Узлы CN могут добавляться или удаляться по требованию в течение нескольких секунд. Эта архитектура снижает стоимость хранения, обеспечивает лучшую изоляцию ресурсов, а также высокую эластичность и масштабируемость.
Архитектура shared-data сохраняет такую же простую архите�ктуру, как и ее аналог shared-nothing. Она состоит только из двух типов узлов: FE и CN. Единственное отличие в том, что пользователям необходимо предоставить backend object storage.
Узлы
FE в архитектуре shared-data предоставляют те же функции, что и в архитектуре shared-nothing.
BE заменяются на CN (Compute Nodes), а функция хранения передается в object storage или HDFS. CN — это stateless вычислительные узлы, которые выполняют все функции BE, за исключением хранения данных.
Хранилище
Selena shared-data clusters поддерживают два решения для хранения: object storage (например, AWS S3, Google GCS, Azure Blob Storage или MinIO) и HDFS.
В shared-data cluster формат файлов данных остается согласованным с форматом shared-nothing cluster (с связанным хранилищем и вычислениями). Данные организованы в файлы сегментов, а различные технологии индексиров�ания повторно используются в cloud-native таблицах, которые являются таблицами, используемыми специально в shared-data clusters.
Cache
Selena shared-data clusters разделяют хранение данных и вычисления, позволяя каждому из них масштабироваться независимо, тем самым снижая затраты и повышая эластичность. Однако эта архитектура может влиять на производительность запросов.
Для смягчения этого влияния Selena создает многоуровневую систему доступа к данным, охватывающую память, локальный диск и удаленное хранилище, чтобы лучше удовлетворять различные бизнес-потребности.
Запросы к горячим данным сканируют cache напрямую, а затем локальный диск, в то время как холодные данные необходимо загрузить из object storage в локальный cache для ускорения последующих запросов. Сохраняя горячие данные близко к вычислительным узлам, Selena достигает действительно высокопроизводительных вычислений и экономичного хранения. Более того, доступ к холодным данным был оптимизирован с помощью стратегий предварительной загрузки данных, эффективно устраняя ограничения производительности для запросов.
Кэширование может быть включено при создании таблиц. Если кэширование включено, данные будут записываться как на локальный диск, так и в backend object storage. Во время запросов узлы CN сначала читают данные с локального диска. Если данные не найдены, они будут извлечены из backend object storage и одновременно закэшированы на локальном диске.
Обучение на практике
Попробуйте Краткие руководства, чтобы получить обзор использования Selena в реалистичных сценариях.