Возможности базы данных
Selena предлагает богатый набор возможностей для обеспечения сверхбыстрой аналитики в реальном времени для больших объемов данных.
MPP framework
Selena использует фреймворк массивно-параллельной обработки (MPP). Один запрос разделяется на несколько физических вычислительных единиц, которые могут выполняться параллельно на нескольких машинах. Каждая машина имеет выделенные ресурсы CPU и памяти. MPP framework полностью использует ресурсы всех ядер CPU и машин. Производительность одного запроса может непрерывно увеличиваться по мере масштабирования cluster.
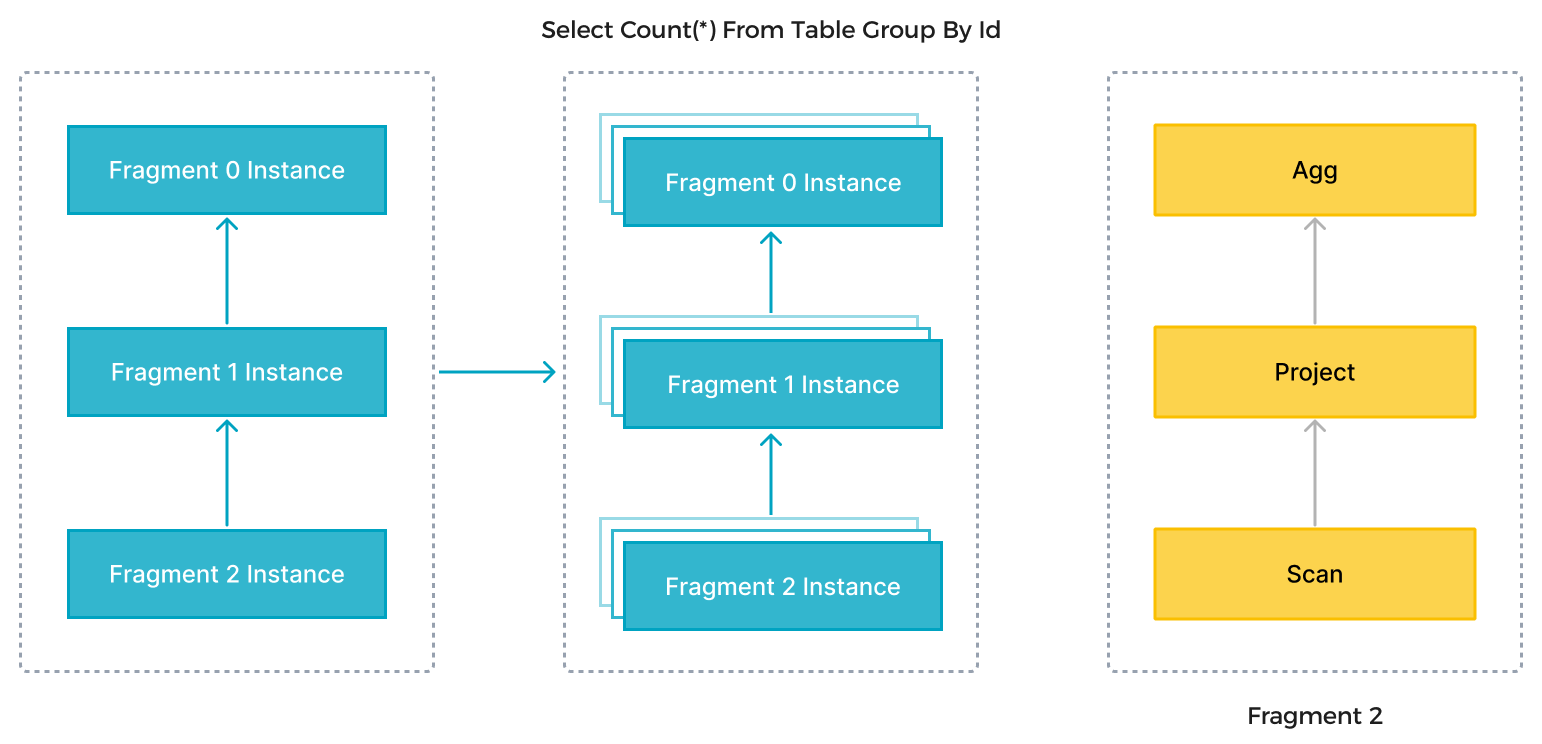
На предыдущем рисунке Selena разбирает SQL-выражение на несколько логических единиц выполнения (query fragments) в соответствии с семантикой выражения. Каждый fragment затем реализуется одной или несколькими физическими единицами выполнения (fragment instances) в зависимости от сложности вычислений. Физическая единица выполнения является наименьшей единицей планирования в Selena. Они будут распределены на backends (BE) для выполнения. Одна логическая единица выполнения может содержать один или несколько операторов, таких как операторы Scan, Project и Agg, как показано на правой стороне рисунка. Каждая физическая единица выполнения обрабатывает только часть данных, а результат будет объединен для генерации окончательных данных. Параллельное выполнение логических единиц выполнения полностью использует ресурсы всех ядер CPU и физических машин и ускоряет скорость запросов.
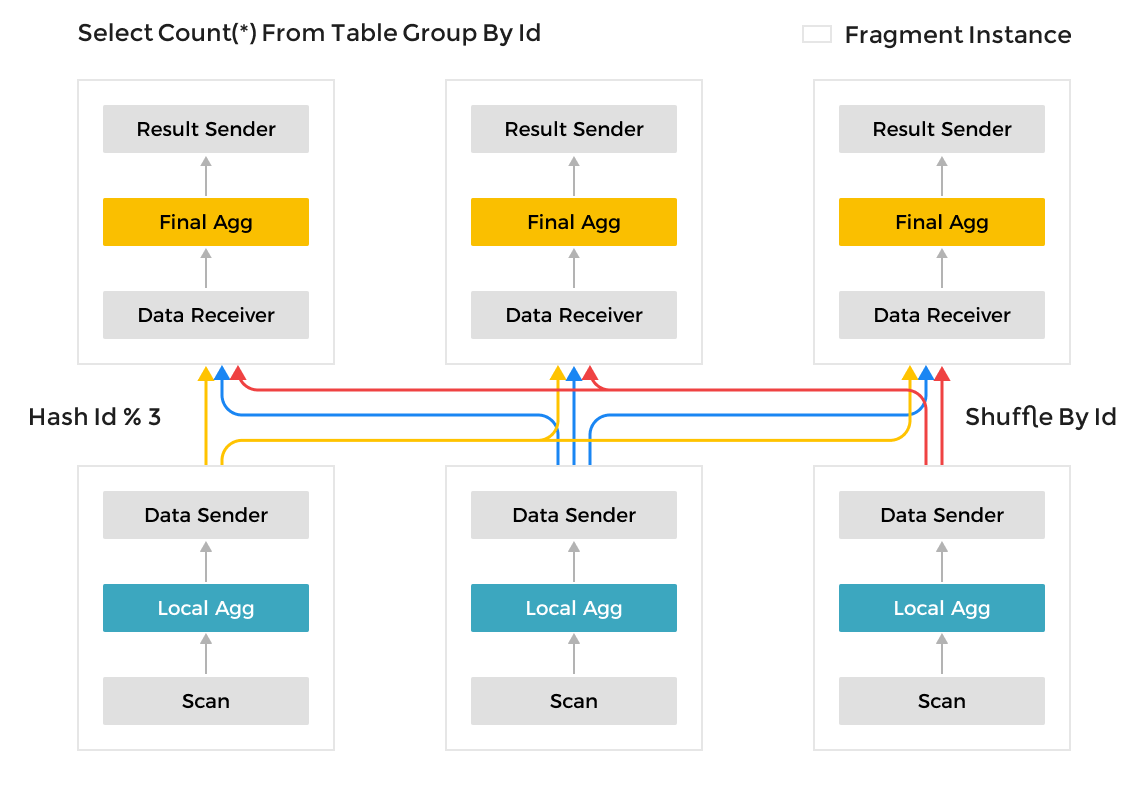
В отличие от фреймворка Scatter-Gather, используемого многими другими системами аналитики данных, MPP framework может использовать больше ресурсов для обработки запросов. Во фреймворке Scatter-Gather только узел Gather может выполнять финальную операцию слияния. В MPP framework данные перемешиваются на несколько узлов для операций слияния. Для сложных запросов, таких как Group By по полям с высокой кардинальностью и соединения больших таблиц, MPP framework Selena имеет заметные преимущества в производительности по сравнению с фреймворком Scatter-Gather.
Полностью векторизованный движок выполнения
Полностью векторизованный движок выполнения более эффективно использует мощность обработки CPU, поскольку этот движок организует и обрабатывает данные в колоночном формате. В частности, Selena хранит данные, организует данные в памяти и вычисляет SQL-операторы полностью в колоночном формате. Колоночная организация полностью использует cache CPU. Колоночные вычисления сокращают количество вызовов виртуальных функций и ветвлений, что приводит к более эффективным потокам инструкций CPU.
Векторизованный движок выполнения также полностью использует инструкции SIMD. Этот движок может выполнять больше операций с данными с меньшим количеством инструкций. Тесты на стандартных наборах данных показывают, что этот движок повышает общую производительность операторов в 3-10 раз.
Помимо векторизации операторов, Selena реализовала другие оптимизации для движка запросов. Например, Selena использует технологию Operation on Encoded Data для непосредственного выполнения операторов на закодированных строках без необходимости декодирования. Это заметно снижает сложность SQL и увеличивает скорость запросов более чем в 2 раза.
Разделение хранилища и вычислений
Архитектура с разделением хранилища и вычислений была представлена начиная с версии 3.0. В этой архитектуре вычисления и хранилище разделены для достижения изоляции ресурсов, эластичного масштабирования вычислительных узлов и высокопроизводительных запросов. Разделение хранилища и вычислений обеспечивает Selena лучшей гибкостью, более высокой производительностью и доступностью данных, а также более низкой стоимостью.
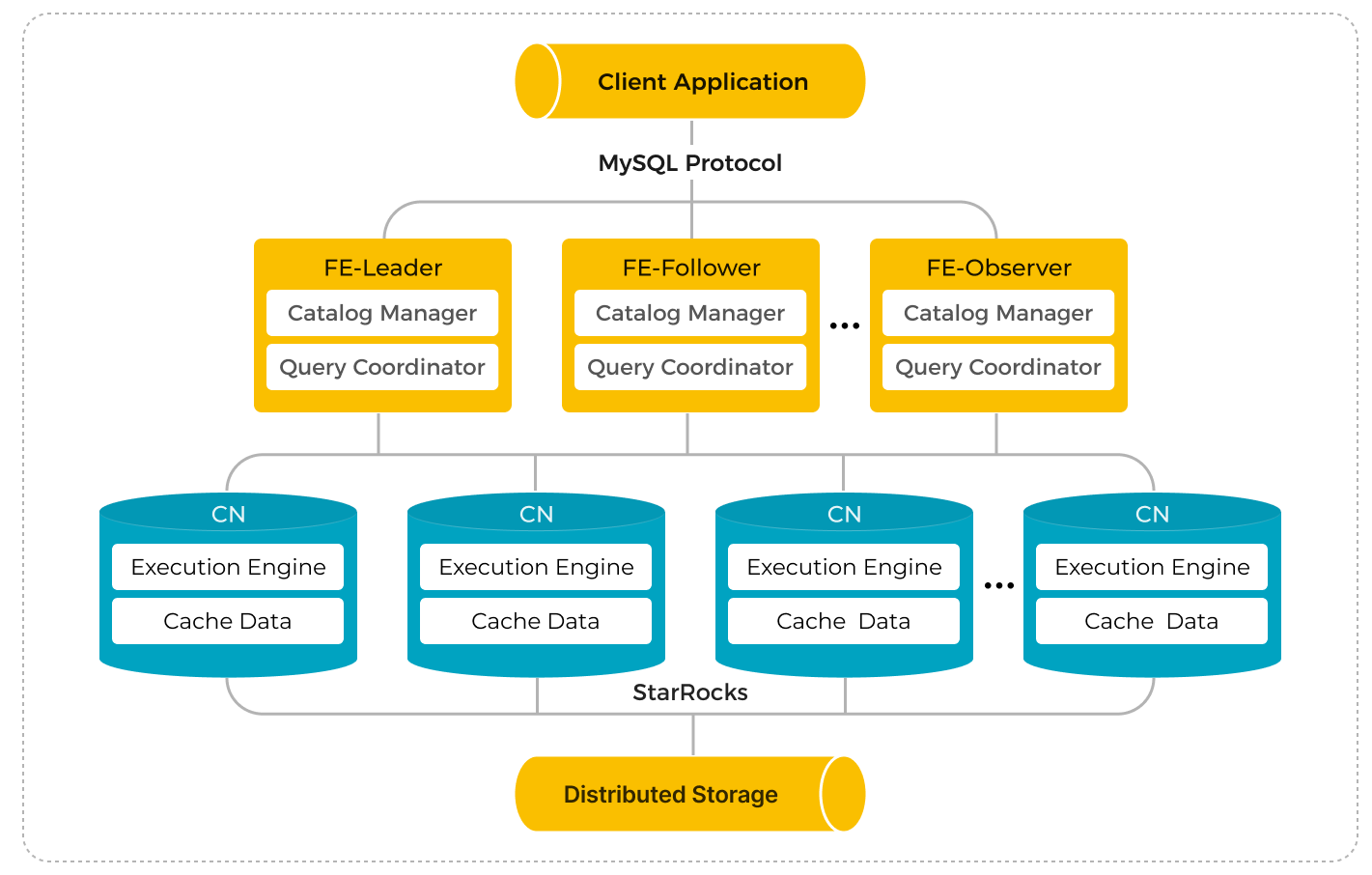
В режиме разделения хранилища и вычислений вычисления и хранилище разделены и могут масштабироваться независимо, что устраняет затраты, давно существующие в режиме связанного хранилища и вычислений, где хранилище должно масштабироваться каждый раз, когда пользователи хотят добавить вычислительные узлы. Кроме того, вычисления могут динамически масштабироваться в течение нескольких секунд, улучшая использование ресурсов, особенно при наличии заметных пиков и спадов трафика.
Слой хранения использует почти неограниченную емкость и высокую надежность object storage для достижения массивного хранения данных и постоянства данных. Selena может работать с различными системами object storage, такими как AWS S3, Google Cloud Storage, Azure Blob Storage, HDFS и другими S3-совместимыми хранилищами, такими как MinIO.
Пользователи могут выбрать развертывание Selena в публичных облаках, частных облаках или локальных дата-центрах. Selena поддерживает развертывания на основе Kubernetes и предоставляет Operator для автоматизированного развертывания clusters с разделенным хранилищем и вычислениями.
Selena в режиме разделения хранилища и вычислений предоставляет те же функциональные возможности, что и в режиме связанного хранилища и вычислений. Производительность записи данных и запросов горячих данных также одинакова. Пользователи могут выполнять обновления данных, аналитику озер данных и ускорение материализованных представлений так же, как в режиме связ�анного хранилища и вычислений.
Оптимизатор на основе стоимости
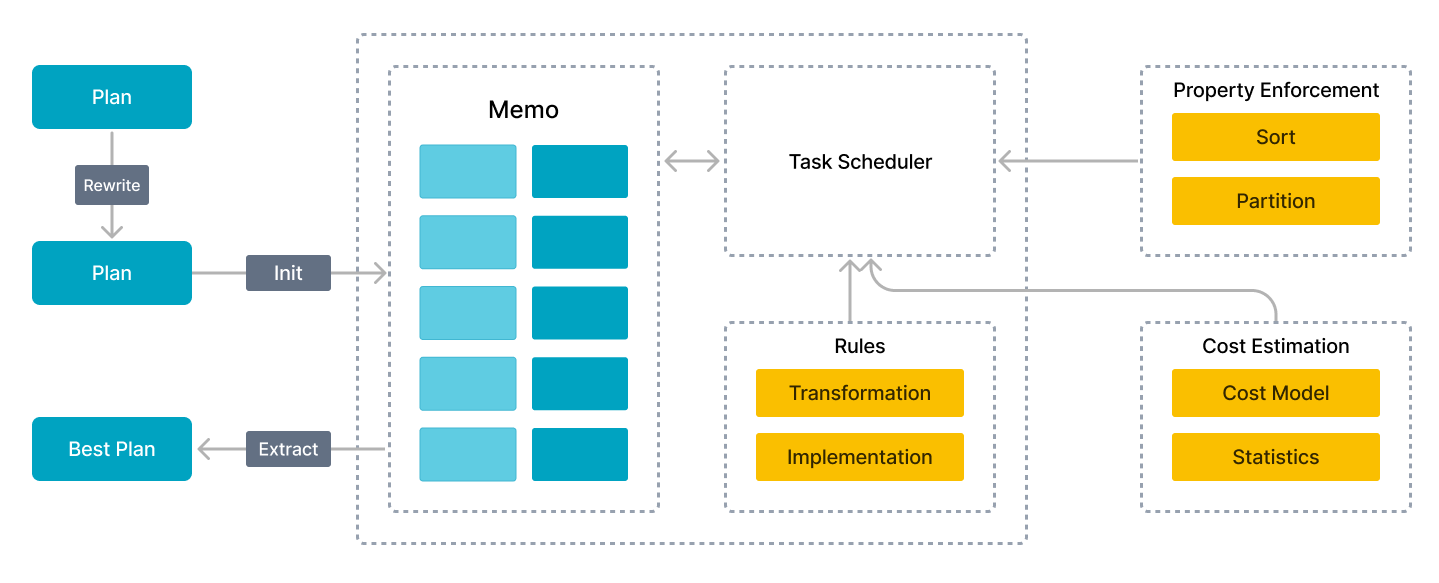
Производительность запросов с соединением нескольких таблиц сложно оптимизировать. Только движки выполнения не могут обеспечить превосходную производительность, потому что сложность планов выполнения может различаться на несколько порядков в сценариях запросов с соединением нескольких таблиц. Чем больше связанных таблиц, тем больше планов выполнения, что делает выбор оптимального плана NP-сложной задачей. Только достаточно хороший оптимизатор запросов может выбрать относительно оптимальный план запроса для эффективной аналитики нескольких таблиц.
Selena разработала совершенно новый CBO с нуля. Этот CBO использует cascades-подобный фреймворк и глубоко настроен для векторизованного движка выполнения с рядом оптимизаций и инноваций. Эти оптимизации включают повторное использование общих табличных выражений (CTE), переписывание подзапросов, Lateral Join, Join Reorder, выбор стратегии для распределенного выполнения Join и оптимизацию низкой кардинальности. CBO поддерживает в общей сложности 99 SQL-выражений TPC-DS.
CBO позволяет Selena обеспечивать лучшую производительность запросов с соединением нескольких таблиц по сравнению с конкурентами, особенно в сложных запросах с соединением нескольких таблиц.
Колоночный движок хранения в реальном времени с возможностью обновления
Selena — это колоночный движок хранения, который позволяет хранить данные одного типа непрерывно. В колоночном хранилище данные могут быть закодированы более эффективным способом, увеличивая коэффициент сжатия и снижая стоимость хранения. Колоночное хранилище также сокращает общее количество операций чтения данных I/O, улучшая производительность запросов. Кроме того, в большинстве OLAP-сценариев запрашиваются только определенные столбцы. Колоночное хранилище позволяет пользователям запрашивать только часть столбцов, значительно сокращая дисковые операции I/O.
Selena может загружать данные в течение нескольких секунд для аналитики практически в реальном времени. Движок хранения Selena гарантирует атомарность, согласованность, изоляцию и долговечность (ACID) каждой операции загрузки данных. Для транзакции загрузки данных вся транзакция либо успешна, либо неудачна. Конкурентные транзакции не влияют друг на друга, обеспечивая изоляцию на уровне транзакций.
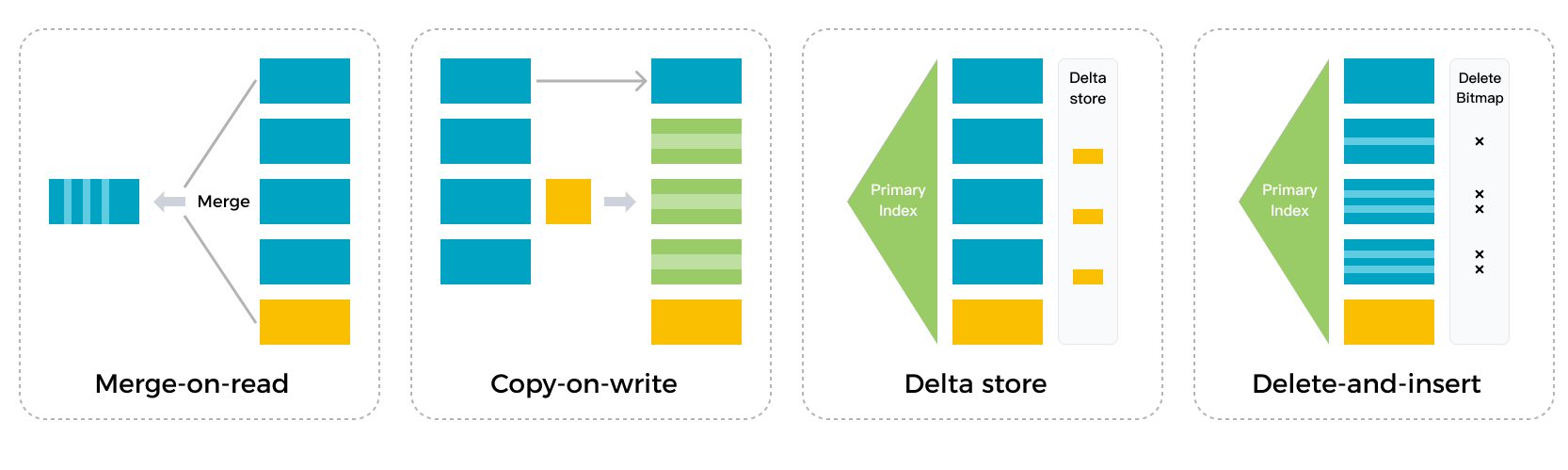
Движок хранения Selena использует паттерн Delete-and-insert, который позволяет эффективно выполнять операции Partial Update и Upsert. Движок хранения может быстро фильтровать данные с использованием индексов первичных ключей, устраняя необходимость в операциях Sort и Merge при чтении данных. Движок также может полностью использовать вторичные индексы. Он обеспечивает быструю и предсказуемую производительность запросов даже при огромных объемах обновлений данных.
Интеллектуальные материализованные представления
Selena использует интеллектуальные материализованные представления для ускорения запросов и слоев хранилища данных. В отличие от материализованных представлений других аналогичных продуктов, которые требуют ручной синхронизации данных с базовой таблицей, материализованные представления Selena автоматически обновляют данные в соответствии с изменениями данных в базовой таблице без необходимости дополнительных операций обслуживания. Кроме того, выбор материализованных представлений также автоматический. Если Selena идентифицирует подходящее материализованное представление (MV) для улучшения производительности запросов, она автоматически переписывает запрос для использования MV. Этот интеллектуальный процесс значительно повышает эффективность запросов без необходимости ручного вмешательства.
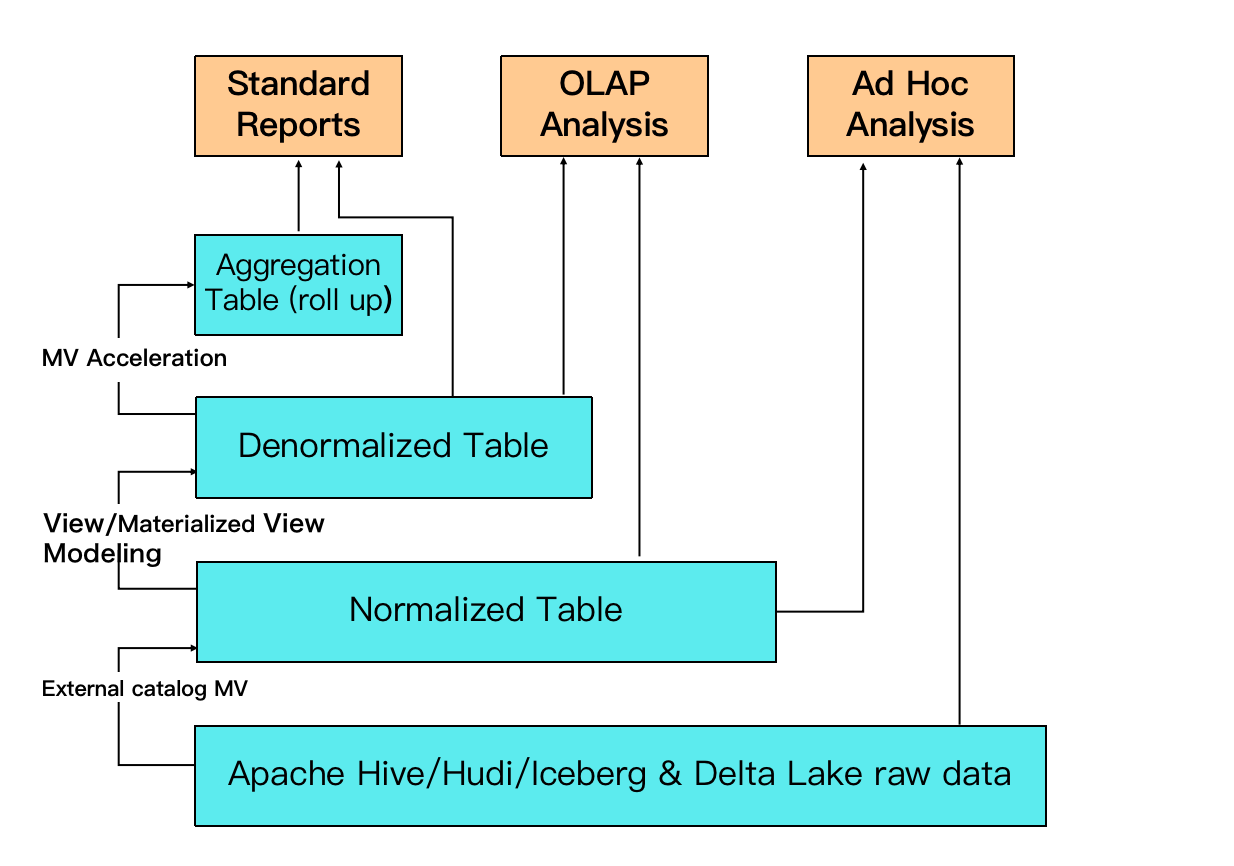
MV Selena могут заменить традиционный процесс моделирования данных ETL: вместо преобразования данных в upstream-приложениях теперь у вас есть возможность преобразовывать данные с помощью MV внутри Selena, упрощая конвейер обработки данных.
Например, на рисунке необработанные данные в озере данных могут быть использованы для создания нормализованной таблицы на основе внешнего MV. Денормализованная таблица может быть создана из нормализованных таблиц через асинхронные материализованные представления. Другое MV может быть создано из нормализованных таблиц для поддержки высококонкурентных запросов и лучшей производительности запросов.
Аналитика озер данных
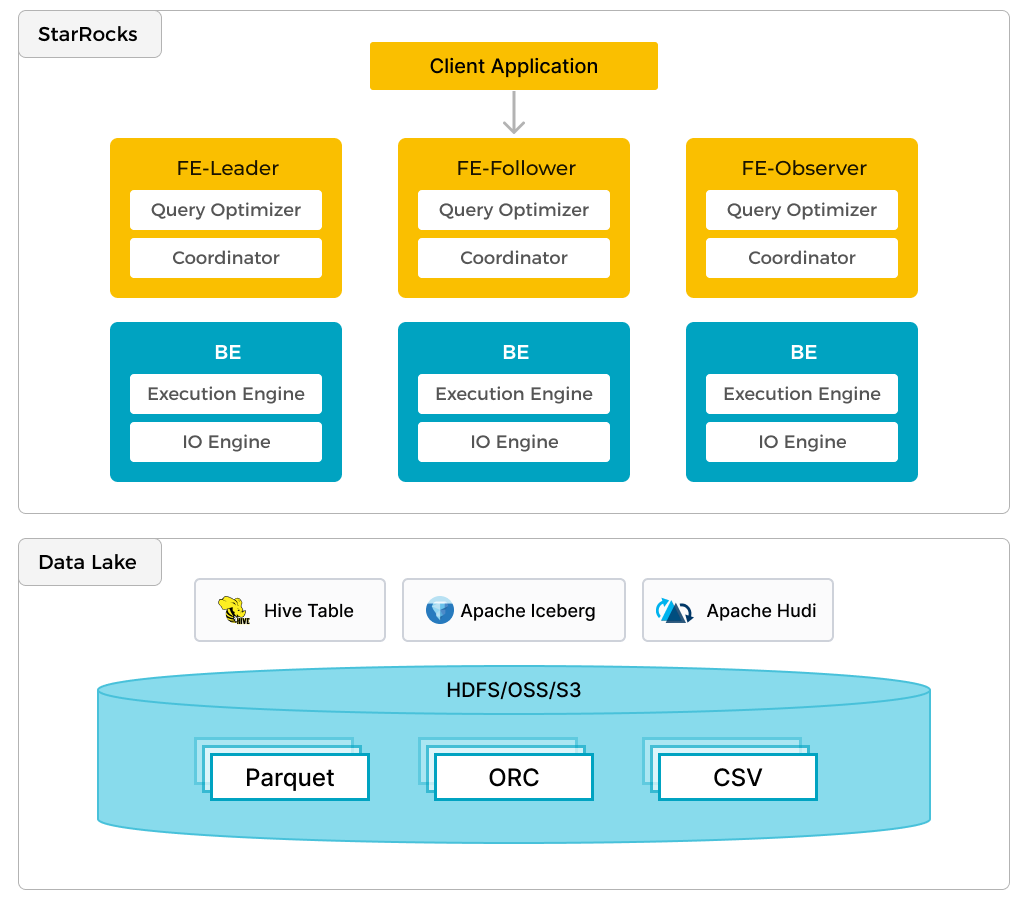
Помимо эффективной аналитики локальных данных, Selena может работать как вычислительный движок для анализа данных, хранящихся в озерах данных, таких как Apache Hive, Apache Iceberg, Apache Hudi и Delta Lake. Одной из ключевых возможностей Selena является ее внешний каталог, который действует как связующее звено с внешне поддерживаемым metastore. Эта функциональность предоставляет пользователям возможность бесшовного запроса внешних источников данных, устраняя необходимость миграции данных. Таким образом, пользователи могут анализировать данные из различных систем, таких как HDFS и Amazon S3, в различных форматах файлов, таких как Parquet, ORC и CSV и т.д.
На предыдущем рисунке показан сценарий аналитики озера данных, где Selena отвечает за вычисления и анализ данных, а озеро данных отвечает за хранение, организацию и обслуживание данных. Озера данных позволяют пользователям хранить данные в открытых форматах хранения и использовать гибкие схемы для создания отчетов на основе "единого источника истины" для различных случаев использования BI, AI, ad-hoc запросов и отчетности. Selena полностью использует преимущества своего векторизованного движка и CBO, значительно улучшая производительность аналитики озер данных.