Синхронизация в реальном времени из MySQL
Selena поддерживает несколько методов синхронизации данных из MySQL в Selena в реальном времени, обеспечивая аналитику больших объемов данных с низкой задержкой.
В этой теме описывается, как синхронизировать данные из MySQL в Selena в реальном времени (в течение секунд) через Apache Flink®.
Вы можете загружать данные в таблицы Selena только как пользователь, имеющий привилегию INSERT на эти таблицы Selena. Если у вас нет привилегии INSERT, следуйте инструкциям в разделе GRANT, чтобы предоставить привилегию INSERT пользователю, которого вы используете для подключения к вашему cluster Selena. Синтаксис: GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}.
Как это работает
Flink CDC используется для синхронизации из MySQL в Flink. В этой теме используется Flink CDC версии ниже 3.0, поэтому SMT используется для синхронизации схем таблиц. Однако, если используется Flink CDC 3.0, не требуется использовать SMT для синхронизации схем таблиц в Selena. Flink CDC 3.0 может даже синхронизировать схемы всей базы данных MySQL, шардированные базы данных и таблицы, а также поддерживает синхронизацию изменений схемы. Подробное описание использования см. в Streaming ELT from MySQL to Selena.
На следующем рисунке показан весь процесс синхронизации.

Синхронизация в реальном времени из MySQL через Flink в Selena реализуется в два этапа: синхронизация схемы базы данных и таблиц и синхронизация данных. Сначала SMT преобразует схему базы данных и таблиц MySQL в операторы создания таблиц для Selena. Затем cluster Flink запускает задания Flink для синхронизации полных и инкрементальных данных MySQL в Selena.
Процесс синхронизации гарантирует exactly-once семантику.
Процесс синхронизации:
-
Синхронизация схемы базы данных и таблиц.
SMT читает схему базы данных и таблиц MySQL для синхронизации и генерирует SQL файлы для создания целевой базы данных и таблиц в Selena. Эта операция основана на информации MySQL и Selena в конфигурационном файле SMT.
-
Синхронизация данных.
a. SQL клиент Flink выполняет оператор загрузки данных
INSERT INTO SELECTдля отправки одного или нескольких заданий Flink в cluster Flink.b. Cluster Flink выполняет задания Flink для получения данных. Коннектор Flink CDC сначала читает полные исторические данные из исходной базы данных, затем бесшовно переключается на инкрементальное чтение и отправляет данные в flink-connector-selena.
c. flink-connector-selena накапливает данные в мини-батчах и синхронизирует каждый батч данных в Selena.
к сведениюТолько операции языка манипулирования данными (DML) в MySQL могут быть синхронизированы в Selena. Операции языка определения данных (DDL) не могут быть синхронизированы.
Сценарии использования
Синхронизация в реальном времени из MySQL имеет широкий спектр применения, где данные постоянно изменяются. Возьмем в качестве примера реальный сценарий "ранжирование продаж товаров в реальном времени".
Flink рассчитывает ранжирование продаж товаров в реальном времени на основе исходной таблицы заказов в MySQL и синхронизирует рейтинг в таблицу Primary Key Selena в реальном времени. Пользователи могут подключить инструмент визуализации к Selena для просмотра рейтинга в реальном времени и получения оперативной информации по требованию.
Подготовка
Загрузка и установка инструментов синхронизации
Для синхронизации данных из MySQL необходимо установить следующие инструменты: SMT, Flink, коннектор Flink CDC и flink-connector-selena.
-
Загрузите и установите Flink, затем запустите cluster Flink. Вы также можете выполнить этот шаг, следуя инструкциям в официальной документации Flink.
a. Установите Java 8 или Java 11 в вашей операционной системе перед запуском Flink. Вы можете выполнить следующую команду для проверки установленной версии Java.
# Просмотр версии Java.
java -version
# Java 8 установлена, если возвращается следующий вывод.
java version "1.8.0_301"
Java(TM) SE Runtime Environment (build 1.8.0_301-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)b. Загрузите установочный пакет Flink и распакуйте его. Рекомендуется использовать Flink 1.14 или более поздней версии. Минимальная допустимая версия - Flink 1.11. В этой теме используется Flink 1.14.5.
# Загрузка Flink.
wget https://archive.apache.org/dist/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.11.tgz
# Распаковка Flink.
tar -xzf flink-1.14.5-bin-scala_2.11.tgz
# Переход в каталог Flink.
cd flink-1.14.5c. Запуск cluster Flink.
# Запуск cluster Flink.
./bin/start-cluster.sh
# Cluster Flink запущен, если возвращается следующий вывод.
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host. -
Загрузите коннектор Flink CDC. В этой теме MySQL используется в качестве источника данных, поэтому загружается
flink-sql-connector-mysql-cdc-x.x.x.jar. Версия коннектора должна соответствовать версии Flink. В этой теме используется Flink 1.14.5, и вы можете загрузитьflink-sql-connector-mysql-cdc-2.2.0.jar.wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.1.1/flink-sql-connector-mysql-cdc-2.2.0.jar -
Загрузите flink-connector-selena. Версия должна соответствовать версии Flink.
Пакет flink-connector-selena
x.x.x_flink-y.yy _ z.zz.jarсодержит три номера версий:x.x.x- номер версии flink-connector-selena.y.yy- поддерживаемая версия Flink.z.zz- версия Scala, поддерживаемая Flink. Если версия Flink 1.14.x или более ранняя, необходимо загрузить пакет с указанием версии Scala.
В этой теме используется Flink 1.14.5 и Scala 2.11. Следовательно, вы можете загрузить следующий пакет:
1.2.3_flink-14_2.11.jar. -
Переместите JAR пакеты коннектора Flink CDC (
flink-sql-connector-mysql-cdc-2.2.0.jar) и flink-connector-selena (1.2.3_flink-1.14_2.11.jar) в каталогlibFlink.Примечание
Если cluster Flink уже запущен в вашей системе, необходимо остановить cluster Flink и перезапустить его для загрузки и проверки JAR пакетов.
$ ./bin/stop-cluster.sh
$ ./bin/start-cluster.sh -
Загрузите и распакуйте пакет SMT (обратитесь в техническую поддержку для получения дистрибутива) и поместите его в каталог
flink-1.14.5. Selena предоставляет пакеты SMT для Linux x86 и macOS ARM64. Вы можете выбрать один в зависимости от вашей операционной системы и процессора.# для Linux x86
wget https://releases.selena.io/resources/smt.tar.gz
# для macOS ARM64
wget https://releases.selena.io/resources/smt_darwin_arm64.tar.gz
Включение бинарного лога MySQL
Для синхронизации данных из MySQL в реальном времени система должна читать данные из бинарного лога MySQL (binlog), анализировать данные, а затем синхронизировать их в Selena. Убедитесь, что бинарный лог MySQL включен.
-
Отредактируйте конфигурационный файл MySQL
my.cnf(путь по умолчанию:/etc/my.cnf) для включения бинарного лога MySQL.# Включение MySQL Binlog.
log_bin = ON
# Настройка пути сохранения для Binlog.
log_bin =/var/lib/mysql/mysql-bin
# Настройка server_id.
# Если server_id не настроен для MySQL 5.7.3 или более поздней версии, служба MySQL не может быть использована.
server_id = 1
# Установка формата Binlog в ROW.
binlog_format = ROW
# Базовое имя файла Binlog. Идентификатор добавляется для идентификации каждого файла Binlog.
log_bin_basename =/var/lib/mysql/mysql-bin
# Индексный файл файлов Binlog, который управляет каталогом всех файлов Binlog.
log_bin_index =/var/lib/mysql/mysql-bin.index -
Выполните одну из следующих команд для перезапуска MySQL, чтобы измененный конфигурационный файл вступил в силу.
# Использование service для перезапуска MySQL.
service mysqld restart
# Использование скрипта mysqld для перезапуска MySQL.
/etc/init.d/mysqld restart -
Подключитесь к MySQL и проверьте, включен ли бинарный лог MySQL.
-- Подключение к MySQL.
mysql -h xxx.xx.xxx.xx -P 3306 -u root -pxxxxxx
-- Проверка, включен ли бинарный лог MySQL.
mysql> SHOW VARIABLES LIKE 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.00 sec)
Синхронизация схемы базы данных и таблиц
-
Отредактируйте конфигурационный файл SMT. Перейдите в каталог SMT
confи отредактируйте конфигурационный файлconfig_prod.conf, такие как информация о подключении MySQL, правила сопоставления базы данных и таблиц для синхронизации и конфигурационная информация flink-connector-selena.[db]
type = mysql
host = xxx.xx.xxx.xx
port = 3306
user = user1
password = xxxxxx
[other]
# Количество BE в Selena
be_num = 3
# `decimal_v3` поддерживается с Selena-1.18.1.
use_decimal_v3 = true
# Файл для сохранения преобразованного DDL SQL
output_dir = ./result
[table-rule.1]
# Шаблон для сопоставления баз данных для установки свойств
database = ^demo.*$
# Шаблон для сопоставления таблиц для установки свойств
table = ^.*$
############################################
### Конфигурации Flink sink
### НЕ устанавливайте `connector`, `table-name`, `database-name`. Они генерируются автоматически.
############################################
flink.selena.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.selena.load-url= <fe_host>:<fe_http_port>
flink.selena.username=user2
flink.selena.password=xxxxxx
flink.selena.sink.properties.format=csv
flink.selena.sink.properties.column_separator=\x01
flink.selena.sink.properties.row_delimiter=\x02
flink.selena.sink.buffer-flush.interval-ms=15000-
[db]: информация, используемая для доступа к исходной базе данных.type: тип исходной базы данных. В этой теме исходная база данных -mysql.host: IP-адрес сервера MySQL.port: номер порта базы данных MySQL, по умолчанию3306user: имя пользователя для доступа к базе данных MySQLpassword: пароль имени пользователя
-
[table-rule]: правила сопоставления базы данных и таблиц и соответствующая конфигурация flink-connector-selena.Database,table: имена базы данных и таблицы в MySQL. Поддерживаются регулярные выражения.flink.selena.*: конфигурационная информация flink-connector-selena. Для получения дополнительных конфигураций и информации см. flink-connector-selena.
Если вам необходимо использовать разные конфигурации flink-connector-selena для разных таблиц. Например, если некоторые таблицы часто обновляются и вы хотите ускорить загрузку данных, см. Использование разных конфигураций flink-connector-selena для разных таблиц. Если вам необходимо загрузить несколько таблиц, полученных из шардирования MySQL, в одну таблицу Selena, см. Синхронизация нескольких таблиц после шардирования MySQL в одну таблицу в Selena.
-
[other]: другая информацияbe_num: Количество BE в вашем cluster Selena (Этот параметр будет использоваться для установки разумного количества tablets при последующем создании таблицы Selena).use_decimal_v3: Включить ли Decimal V3. После включения Decimal V3 данные decimal MySQL будут преобразованы в данные Decimal V3 при синхронизации данных в Selena.output_dir: Путь для сохранения SQL файлов, которые будут сгенерированы. SQL файлы будут использоваться для создания базы данных и таблицы в Selena и отправки задания Flink в cluster Flink. Путь по умолчанию -./result, и рекомендуется сохранить настройки по умолчанию.
-
-
Запустите SMT для чтения схемы базы данных и таблиц в MySQL и генерации SQL файлов в каталоге
./resultна основе конфигурационного файла. Файлselena-create.all.sqlиспользуется для создания базы данных и таблицы в Selena, а файлflink-create.all.sqlиспользуется для отправки задания Flink в cluster Flink.# Запуск SMT.
./selena-migrate-tool
# Переход в каталог result и проверка файлов в этом каталоге.
cd result
ls result
flink-create.1.sql smt.tar.gz selena-create.all.sql
flink-create.all.sql selena-create.1.sql -
Выполните следующую команду для подключения к Selena и выполнения файла
selena-create.all.sqlдля создания базы данных и таблицы в Selena. Рекомендуется использовать оператор создания таблицы по умолчанию в SQL файле для создания таблицы Primary Key table.Примечание
Вы также можете изменить оператор создания таблицы в соответствии с вашими бизнес-потребностями и создать таблицу, которая не использует Primary Key table. Однако операция DELETE в исходной базе данных MySQL не может быть синхронизирована с таблицей, не являющейся Primary Key table. Будьте осторожны при создании такой таблицы.
mysql -h <fe_host> -P <fe_query_port> -u user2 -pxxxxxx < selena-create.all.sqlЕсли данные должны быть обработаны Flink перед записью в целевую таблицу Selena, схема таблицы будет отличаться между исходной и целевой таблицами. В этом случае необходимо изменить оператор создания таблицы. В этом примере целевая таблица требует только столбцы
product_idиproduct_nameи ранжирование продаж товаров в реальном времени. Вы можете использовать следующий оператор создания таблицы.CREATE DATABASE IF NOT EXISTS `demo`;
CREATE TABLE IF NOT EXISTS `demo`.`orders` (
`product_id` INT(11) NOT NULL COMMENT "",
`product_name` STRING NOT NULL COMMENT "",
`sales_cnt` BIGINT NOT NULL COMMENT ""
) ENGINE=olap
PRIMARY KEY(`product_id`)
DISTRIBUTED BY HASH(`product_id`)
PROPERTIES (
"replication_num" = "3"
);ВАЖНО
Начиная с v1.5.2, Selena может автоматически устанавливать количество buckets (BUCKETS) при создании таблицы или добавлении partition. Вам больше не нужно вручную устанавливать количество buckets. Подробную информацию см. в установка количества buckets.
Синхронизация данных
Запустите cluster Flink и отправьте задание Flink для непрерывной синхронизации полных и инкрементальных данных из MySQL в Selena.
-
Перейдите в каталог Flink и выполните следующую команду для запуска файла
flink-create.all.sqlна вашем SQL клиенте Flink../bin/sql-client.sh -f flink-create.all.sqlЭтот SQL файл определяет динамические таблицы
source tableиsink table, оператор запросаINSERT INTO SELECTи указывает коннектор, исходную базу данных и целевую базу данных. После выполнения этого файла задание Flink отправляется в cluster Flink для запуска синхронизации данных.Примечание
- Убедитесь, что cluster Flink был запущен. Вы можете запустить cluster Flink, выполнив
flink/bin/start-cluster.sh. - Если ваша версия Flink более ранняя, чем 1.13, вы можете не иметь возможности напрямую запустить SQL файл
flink-create.all.sql. Необходимо выполнять SQL операторы один за другим в этом файле в интерфейсе командной строки (CLI) SQL клиента. Вам также необходимо экранировать символ\.
'sink.properties.column_separator' = '\\x01'
'sink.properties.row_delimiter' = '\\x02'Обработка данных во время синхронизации:
Если вам необходимо обработать данные во время синхронизации, такие как выполнение GROUP BY или JOIN на данных, вы можете изменить файл
flink-create.all.sql. Следующий пример вычисляет ранжирование продаж товаров в реальном времени, выполняя COUNT (*) и GROUP BY.$ ./bin/sql-client.sh -f flink-create.all.sql
No default environment is specified.
Searching for '/home/disk1/flink-1.13.6/conf/sql-client-defaults.yaml'...not found.
[INFO] Executing SQL from file.
Flink SQL> CREATE DATABASE IF NOT EXISTS `default_catalog`.`demo`;
[INFO] Execute statement succeed.
-- Создание динамической таблицы `source table` на основе таблицы заказов в MySQL.
Flink SQL>
CREATE TABLE IF NOT EXISTS `default_catalog`.`demo`.`orders_src` (`order_id` BIGINT NOT NULL,
`product_id` INT NULL,
`order_date` TIMESTAMP NOT NULL,
`customer_name` STRING NOT NULL,
`product_name` STRING NOT NULL,
`price` DECIMAL(10, 5) NULL,
PRIMARY KEY(`order_id`)
NOT ENFORCED
) with ('connector' = 'mysql-cdc',
'hostname' = 'xxx.xx.xxx.xxx',
'port' = '3306',
'username' = 'root',
'password' = '',
'database-name' = 'demo',
'table-name' = 'orders'
);
[INFO] Execute statement succeed.
-- Создание динамической таблицы `sink table`.
Flink SQL>
CREATE TABLE IF NOT EXISTS `default_catalog`.`demo`.`orders_sink` (`product_id` INT NOT NULL,
`product_name` STRING NOT NULL,
`sales_cnt` BIGINT NOT NULL,
PRIMARY KEY(`product_id`)
NOT ENFORCED
) with ('sink.max-retries' = '10',
'jdbc-url' = 'jdbc:mysql://<fe_host>:<fe_query_port>',
'password' = '',
'sink.properties.strip_outer_array' = 'true',
'sink.properties.format' = 'json',
'load-url' = '<fe_host>:<fe_http_port>',
'username' = 'root',
'sink.buffer-flush.interval-ms' = '15000',
'connector' = 'selena',
'database-name' = 'demo',
'table-name' = 'orders'
);
[INFO] Execute statement succeed.
-- Реализация ранжирования продаж товаров в реальном времени, где `sink table` динамически обновляется для отражения изменений данных в `source table`.
Flink SQL>
INSERT INTO `default_catalog`.`demo`.`orders_sink` select product_id,product_name, count(*) as cnt from `default_catalog`.`demo`.`orders_src` group by product_id,product_name;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 5ae005c4b3425d8bb13fe660260a35daЕсли вам необходимо синхронизировать только часть данных, таких как данные, время оплаты которых позже 21 декабря 2021 года, вы можете использовать предложение
WHEREвINSERT INTO SELECTдля установки условия фильтрации, напримерWHERE pay_dt > '2021-12-21'. Данные, которые не соответствуют этому условию, не будут синхронизированы в Selena.Если возвращается следующий результат, задание Flink было отправлено для полной и инкрементальной синхронизации.
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 5ae005c4b3425d8bb13fe660260a35da - Убедитесь, что cluster Flink был запущен. Вы можете запустить cluster Flink, выполнив
-
Вы можете использовать Flink WebUI или выполнить команду
bin/flink list -runningна вашем SQL клиенте Flink для просмотра заданий Flink, которые выполняются в cluster Flink, и идентификаторов заданий.-
Flink WebUI
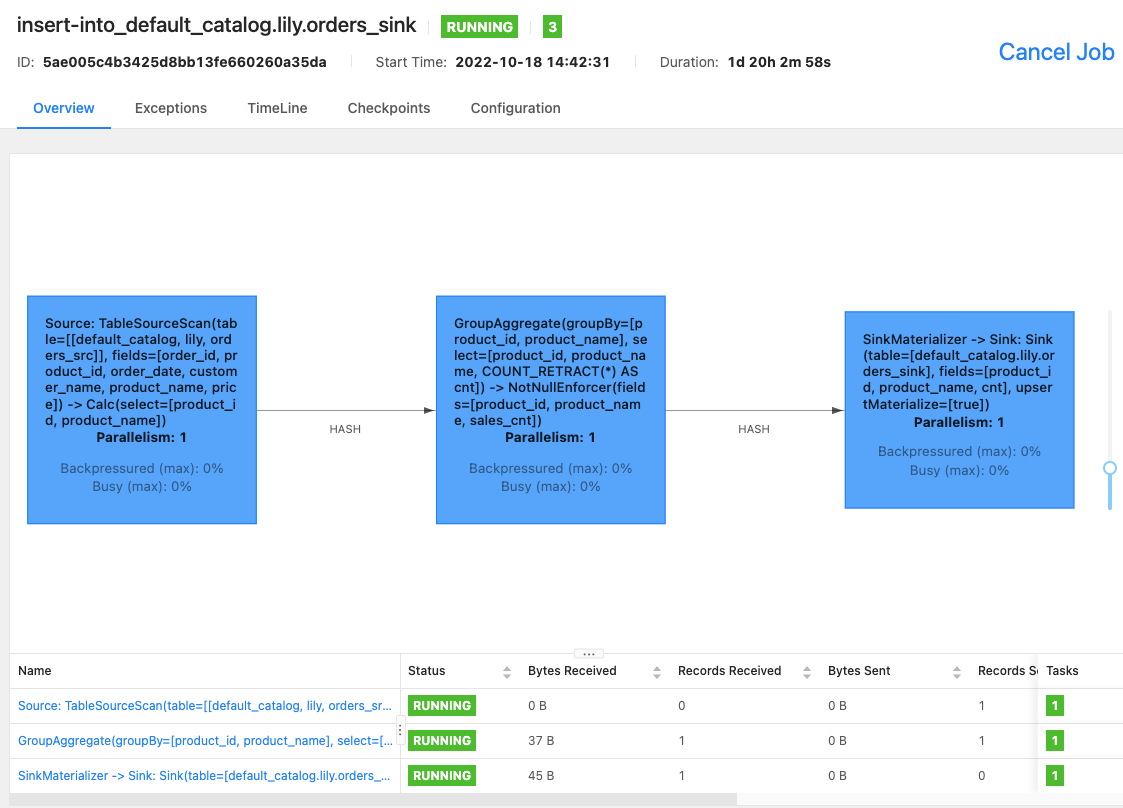
-
bin/flink list -running
$ bin/flink list -running
Waiting for response...
------------------ Running/Restarting Jobs -------------------
13.10.2022 15:03:54 : 040a846f8b58e82eb99c8663424294d5 : insert-into_default_catalog.lily.example_tbl1_sink (RUNNING)
--------------------------------------------------------------Примечание
Если задание является аномальным, вы можете выполнить устранение неполадок, используя Flink WebUI или просмотрев файл лога в каталоге
/logFlink 1.14.5. -
FAQ
Использование разных конфигураций flink-connector-selena для разных таблиц
Если некоторые таблицы в источнике данных часто обновляются и вы хотите ускорить скорость загрузки flink-connector-selena, необходимо установить отдельную конфигурацию flink-connector-selena для каждой таблицы в конфигурационном файле SMT config_prod.conf.
[table-rule.1]
# Шаблон для сопоставления баз данных для установки свойств
database = ^order.*$
# Шаблон для сопоставления таблиц для установки свойств
table = ^.*$
############################################
### Конфигурации Flink sink
### НЕ устанавливайте `connector`, `table-name`, `database-name`. Они генерируются автоматически
############################################
flink.selena.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.selena.load-url= <fe_host>:<fe_http_port>
flink.selena.username=user2
flink.selena.password=xxxxxx
flink.selena.sink.properties.format=csv
flink.selena.sink.properties.column_separator=\x01
flink.selena.sink.properties.row_delimiter=\x02
flink.selena.sink.buffer-flush.interval-ms=15000
[table-rule.2]
# Шаблон для сопоставления баз данных для установки свойств
database = ^order2.*$
# Шаблон для сопоставления таблиц для установки свойств
table = ^.*$
############################################
### Конфигурации Flink sink
### НЕ устанавливайте `connector`, `table-name`, `database-name`. Они генерируются автоматически
############################################
flink.selena.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.selena.load-url= <fe_host>:<fe_http_port>
flink.selena.username=user2
flink.selena.password=xxxxxx
flink.selena.sink.properties.format=csv
flink.selena.sink.properties.column_separator=\x01
flink.selena.sink.properties.row_delimiter=\x02
flink.selena.sink.buffer-flush.interval-ms=10000
Синхронизация нескольких таблиц после шардирования MySQL в одну таблицу в Selena
После выполнения шардирования данные в одной таблице MySQL могут быть разделены на несколько таблиц или даже распределены по нескольким базам данных. Все таблицы имеют одинаковую схему. В этом случае вы можете установить [table-rule] для синхронизации этих таблиц в одну таблицу Selena. Например, MySQL имеет две базы данных edu_db_1 и edu_db_2, каждая из которых имеет две таблицы course_1 и course_2, и схема всех таблиц одинакова. Вы можете использовать следующую конфигурацию [table-rule] для синхронизации всех таблиц в одну таблицу Selena.
Примечание
Имя таблицы Selena по умолчанию -
course__auto_shard. Если вам необходимо использовать другое имя, вы можете изменить его в SQL файлахselena-create.all.sqlиflink-create.all.sql
[table-rule.1]
# Шаблон для сопоставления баз данных для установки свойств
database = ^edu_db_[0-9]*$
# Шаблон для сопоставления таблиц для установки свойств
table = ^course_[0-9]*$
############################################
### Конфигурации Flink sink
### НЕ устанавливайте `connector`, `table-name`, `database-name`. Они генерируются автоматически
############################################
flink.selena.jdbc-url = jdbc: mysql://xxx.xxx.x.x:xxxx
flink.selena.load-url = xxx.xxx.x.x:xxxx
flink.selena.username = user2
flink.selena.password = xxxxxx
flink.selena.sink.properties.format=csv
flink.selena.sink.properties.column_separator =\x01
flink.selena.sink.properties.row_delimiter =\x02
flink.selena.sink.buffer-flush.interval-ms = 5000
Импорт данных в формате JSON
Данные в предыдущем примере импортируются в формате CSV. Если вы не можете выбрать подходящий разделитель, необходимо заменить следующие параметры flink.selena.* в [table-rule].
flink.selena.sink.properties.format=csv
flink.selena.sink.properties.column_separator =\x01
flink.selena.sink.properties.row_delimiter =\x02
Данные импортируются в формате JSON после передачи следующих параметров.
flink.selena.sink.properties.format=json
flink.selena.sink.properties.strip_outer_array=true
Примечание
Этот метод немного замедляет скорость загрузки.
Выполнение нескольких операторов INSERT INTO как одного задания Flink
Вы можете использовать синтаксис STATEMENT SET в файле flink-create.all.sql для выполнения нескольких операторов INSERT INTO как одного задания Flink, что предотвращает использование слишком большого количества ресурсов задания Flink несколькими операторами и повышает эффективность выполнения нескольких запрос�ов.
Примечание
Flink поддерживает синтаксис STATEMENT SET начиная с версии 1.13.
-
Откройте файл
result/flink-create.all.sql. -
Измените SQL операторы в файле. Переместите все операторы INSERT INTO в конец файла. Поместите
EXECUTE STATEMENT SET BEGINперед первым оператором INSERT INTO и поместитеEND;после последнего оператора INSERT INTO.
Примечание
Позиции CREATE DATABASE и CREATE TABLE остаются неизменными.
CREATE DATABASE IF NOT EXISTS db;
CREATE TABLE IF NOT EXISTS db.a1;
CREATE TABLE IF NOT EXISTS db.b1;
CREATE TABLE IF NOT EXISTS db.a2;
CREATE TABLE IF NOT EXISTS db.b2;
EXECUTE STATEMENT SET
BEGIN-- один или несколько операторов INSERT INTO
INSERT INTO db.a1 SELECT * FROM db.b1;
INSERT INTO db.a2 SELECT * FROM db.b2;
END;