Загрузка данных с помощью Routine Load
Попробуйте Routine Load в этом Кратком руководстве
В этом разделе описывается, как создать задачу Routine Load для потоковой передачи сообщений Kafka (событий) в Selena, а также знакомит вас с основными концепциями Routine Load.
Для непрерывной загрузки сообщений потока в Selena вы можете сохранить поток сообщений в topic Kafka и создать задачу Routine Load для потребления сообщений. Задача Routine Load сохраняется в Selena, генерирует серию подзадач загрузки для потребления сообщений из всех или части partition в topic и загружает сообщения в Selena.
Задача Routine Load поддерживает семантику exactly-once доставки, гарантируя, что данные, загруженные в Selena, не будут потеряны или дублированы.
Routine Load поддерживает преобразование данных при загрузке и поддерживает изменения данных, выполняемые операциями UPSERT и DELETE во время загрузки данных. Для получения дополнительной информации см. Преобразование данных при загрузке и Изменение данных через загрузку.
Вы можете загружать данные в таблицы Selena только как пользователь, имеющий привилегию INSERT на эти таблицы Selena. Если у вас нет привилегии INSERT, следуйте инструкциям в разделе GRANT, чтобы предоставить привилегию INSERT пользователю, которого вы используете для подключения к вашему cluster Selena. Синтаксис: GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}.
Поддерживаемые форматы данных
Routine Load в настоящее время поддерживает потребление данных в форматах CSV, JSON и Avro (поддерживается начиная с v1.5.2) из cluster Kafka.
ПРИМЕЧАНИЕ
Для данных CSV обратите внимание на следующие моменты:
- Вы можете использовать строку UTF-8, такую как запятая (,), табуляция или вертикальная черта (|), длиной не более 50 байт в качестве текстового разделителя.
- Null-значения обозначаются с помощью
\N. Например, файл данных состоит из трёх столбцов, и запись из этого файла данных содержит данные в первом и третьем столбцах, но не содержит данных во втором столбце. В этой ситуации вам нужно использовать\Nво втором столбце для обозначения null-значения. Это означает, что запись должна быть скомпилирована какa,\N,bвместоa,,b.a,,bозначает, что второй столбец записи содержит пустую строку.
Основные концепции
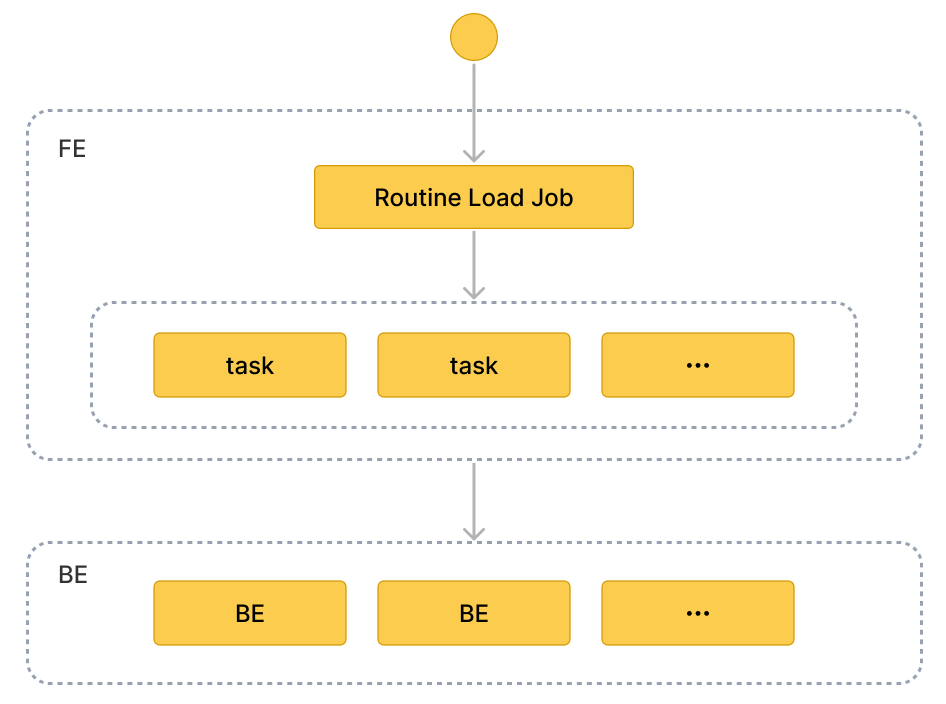
Терминология
-
Задача загрузки (Load job)
Задача Routine Load — это долгосрочная задача. Пока её статус RUNNING, задача загрузки непрерывно генерирует одну или несколько параллельных подзадач загрузки, которые потребляют сообщения из topic cluster Kafka и загружают данные в Selena.
-
Подзадача загрузки (Load task)
Задача загрузки разделяется на несколько подзадач загрузки по определённым правилам. Подзадача загрузки — это базовая единица загрузки данных. Как отдельное событие, подзадача загрузки реализует механизм загрузки на основе Stream Load. Несколько подзадач загрузки одновременно потребляют сообщения из разных partition topic и загружают данные в Selena.
Рабочий процесс
-
Создайте задачу Routine Load. Для загрузки данных из Kafka вам нужно создать задачу Routine Load, выполнив оператор CREATE ROUTINE LOAD. FE анализирует оператор и создаёт задачу в соответствии с указанными вами свойствами.
-
FE разделяет задачу на несколько подзадач загрузки.
FE разделяет задачу на несколько подзадач загрузки на основе определённых правил. Каждая подзадача загрузки является отдельной транзакцией. Правила разделения следующие:
- FE вычисляет фактическое количество параллельных подзадач загрузки в соответствии с желаемым количеством параллелизма
desired_concurrent_number, количеством partition в topic Kafka и количеством активных узлов BE. - FE разделяет задачу на подзадачи загрузки на основе вычисленного фактического количества параллелизма и размещает подзадачи в очереди задач.
Каждый topic Kafka состоит из нескольких partition. Связь между partition topic и подзадачей загрузки следующая:
- Partition однозначно назначает�ся подзадаче загрузки, и все сообщения из partition потребляются подзадачей загрузки.
- Подзадача загрузки может потреблять сообщения из одной или нескольких partition.
- Все partition распределяются равномерно между подзадачами загрузки.
- FE вычисляет фактическое количество параллельных подзадач загрузки в соответствии с желаемым количеством параллелизма
-
Несколько подзадач загрузки выполняются параллельно для потребления сообщений из нескольких partition topic Kafka и загрузки данных в Selena
-
FE планирует и отправляет подзадачи загрузки: FE планирует подзадачи загрузки в очереди на регулярной основе и назначает их выбранным узлам Coordinator BE. Интервал между подзадачами загрузки определяется параметром конфигурации
max_batch_interval. FE равномерно распределяет подзадачи загрузки по всем узлам BE. См. CREATE ROUTINE LOAD для получения дополнительной информации оmax_batch_interval. -
Coordinator BE запускает подзадачу загрузки, потребляет сообщения в partition, анализирует и фильтрует данные. Подзадача загрузки продолжается до тех пор, пока не будет потреблено заранее определённое количество сообщений или не будет достигнут заранее определённый лимит времени. Размер пакета сообщений и лимит времени определяются в конфигурациях FE
max_routine_load_batch_sizeиroutine_load_task_consume_second. Для получения подробной информации см. Конфигурация FE. Затем Coordinator BE распределяет сообщения на Executor BE. Executor BE записывают сообщения на диски.ПРИМЕЧАНИЕ
Selena поддерживает доступ к Kafka через протоколы безопасности, включая SASL_SSL, SAS_PLAINTEXT, SSL и PLAINTEXT. В этом разделе в качестве примера используется подключение к Kafka через PLAINTEXT. Если вам нужно подключиться к Kafka через другие протоколы безопасности, см. CREATE ROUTINE LOAD.
-
-
FE генерирует новые подзадачи загрузки для непрерывной загрузки данных. После того как Executor BE записали данные на диски, Coordinator BE сообщает результат подзадачи загрузки в FE. На основе результата FE затем генерирует новые подзадачи загрузки для непрерывной загрузки данных. Или FE повторяет неудачные подзадачи, чтобы гарантировать, что данные, загруженные в Selena, не будут потеряны или дублированы.
Создание задачи Routine Load
Следующие три примера описывают, как потреблять данные в форматах CSV, JSON и Avro из Kafka и загружать данные в Selena путём создания задачи Routine Load. Для получения подробного синтаксиса и описания параметров см. CREATE ROUTINE LOAD.
Загрузка данных в формате CSV
В этом разделе описывается, как создать задачу Routine Load для потребления данных в формате CSV из cluster Kafka и загрузки данных в Selena.
Подготовка набора данных
Предположим, что в topic ordertest1 в cluster Kafka ест�ь набор данных в формате CSV. Каждое сообщение в наборе данных включает шесть полей: идентификатор заказа, дата оплаты, имя клиента, национальность, пол и цена.
2020050802,2020-05-08,Johann Georg Faust,Deutschland,male,895
2020050802,2020-05-08,Julien Sorel,France,male,893
2020050803,2020-05-08,Dorian Grey,UK,male,1262
2020050901,2020-05-09,Anna Karenina",Russia,female,175
2020051001,2020-05-10,Tess Durbeyfield,US,female,986
2020051101,2020-05-11,Edogawa Conan,japan,male,8924
Создание таблицы
В соответствии с полями данных в формате CSV создайте таблицу example_tbl1 в базе данны�х example_db. Следующий пример создаёт таблицу с 5 полями, исключая поле пола клиента из данных в формате CSV.
CREATE TABLE example_db.example_tbl1 (
`order_id` bigint NOT NULL COMMENT "Order ID",
`pay_dt` date NOT NULL COMMENT "Payment date",
`customer_name` varchar(26) NULL COMMENT "Customer name",
`nationality` varchar(26) NULL COMMENT "Nationality",
`price`double NULL COMMENT "Price"
)
ENGINE=OLAP
DUPLICATE KEY (order_id,pay_dt)
DISTRIBUTED BY HASH(`order_id`);
ВНИМАНИЕ
Начиная с версии v1.5.2, Selena может автоматически устанавливать количество bucket (BUCKETS) при создании таблицы или добавлении partition. Вам больше не нужно вручную устанавливать количество bucket. Для получения подробной информации см. установка количества bucket.
Отправка задачи Routine Load
Выполните следующий оператор, чтобы отправить задачу Routine Load с именем example_tbl1_ordertest1 для потребления сообщений из topic ordertest1 и загрузки данных в таблицу example_tbl1. Подзадача загрузки потребляет сообщения с начального смещения в указанных partition topic.
CREATE ROUTINE LOAD example_db.example_tbl1_ordertest1 ON example_tbl1
COLUMNS TERMINATED BY ",",
COLUMNS (order_id, pay_dt, customer_name, nationality, temp_gender, price)
PROPERTIES
(
"desired_concurrent_number" = "5"
)
FROM KAFKA
(
"kafka_broker_list" = "<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>",
"kafka_topic" = "ordertest1",
"kafka_partitions" = "0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
После отправки задачи загрузки вы можете выполнить оператор SHOW ROUTINE LOAD, чтобы проверить статус задачи загрузки.
-
Имя задачи загрузки
На одной таблице может быть несколько задач загрузки. Поэтому мы рекомендуем называть задачу загрузки с соответствующим topic Kafka и временем отправки задачи загрузки. Это помогает различать задачи загрузки на каждой таблице.
-
Разделитель столбцов
Свойство
COLUMN TERMINATED BYопределяет разделитель столбцов данных в формате CSV. По умолчанию это\t. -
Partition и смещение topic Kafka
Вы можете указать свойства
kafka_partitionsиkafka_offsets, чтобы указать partition и смещения для потребления сообщений. Например, если вы хотите, чтобы задача загрузки потребляла сообщения из partition Kafka"0,1,2,3,4"topicordertest1все с начальными смещениями, вы можете указать свойства следующим образом: Если вы хотите, чтобы задача загрузки потребляла сообщения из partition Kafka"0,1,2,3,4"и вам нужно указать отдельное начальное смещение для каждой partition, вы можете настроить следующим образом:"kafka_partitions" ="0,1,2,3,4",
"kafka_offsets" = "OFFSET_BEGINNING, OFFSET_END, 1000, 2000, 3000"Вы также можете установить смещения по умолчанию для всех partition с помощью свойства
property.kafka_default_offsets."kafka_partitions" ="0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"Для получения подробной информации см. CREATE ROUTINE LOAD.
-
Сопоставление и преобразование данных
Чтобы указать связь сопоставления и преобразования между данными в формате CSV и таблицей Selena, вам нужно использовать параметр
COLUMNS.Сопоставление данных:
-
Selena извлекает столбцы из данных в формате CSV и сопоставляет их последовательно с полями, объявленными в параметре
COLUMNS. -
Selena извлекает поля, объявленные в параметре
COLUMNS, и сопоставляет их по имени со столбцами таблицы Selena.
Преобразование данных:
И поскольку пример исключает столбец пол�а клиента из данных в формате CSV, поле
temp_genderв параметреCOLUMNSиспользуется в качестве заполнителя для этого поля. Остальные поля сопоставляются со столбцами таблицы Selenaexample_tbl1напрямую.Для получения дополнительной информации о преобразовании данных см. Преобразование данных при загрузке.
ПРИМЕЧАНИЕ
Вам не нужно указывать параметр
COLUMNS, если имена, количество и порядок столбцов в данных в формате CSV полностью соответствуют таковым в таблице Selena. -
-
Параллелизм задач
Когда есть много partition topic Kafka и достаточно узлов BE, вы можете ускорить загрузку, увеличив параллелизм задач.
Чтобы увеличить фактический параллелизм подзадач загрузки, вы можете увеличить желаемый параллелизм подзадач загрузки
desired_concurrent_numberпри создании задачи routine load. Вы также можете установить динамический параметр конфигурации FEmax_routine_load_task_concurrent_num(максимальный параллелизм подзадач загрузки по умолчанию) на большее значение. Для получения дополнительной информации оmax_routine_load_task_concurrent_numсм. Параметры конфигурации FE.Фактический параллелизм задач определяется минимальным значением среди количества активных узлов BE, количества предварительно указанных partition topic Kafka и значений
desired_concurrent_numberиmax_routine_load_task_concurrent_num.В примере количество активных узлов BE равно
5, количество предварительно указанных partition topic Kafka равно5, а значениеmax_routine_load_task_concurrent_numравно5. Чтобы увеличить фактический параллелизм подзадач загрузки, вы можете увеличитьdesired_concurrent_numberсо значения по умолчанию3до5.Для получения дополнительной информации о свойствах см. CREATE ROUTINE LOAD.
Загрузка данных в формате JSON
В этом разделе описывается, как создать задачу Routine Load для потребления данных в формате JSON из cluster Kafka и загрузки данных в Selena.
Подготовка набора данных
Предположим, что в topic ordertest2 в cluster Kafka есть набор данных в формате JSON. Набор данных включает шесть ключей: идентификатор товара, имя клиента, национальность, время оплаты и цена. Кроме того, вы хотите преобразовать столбец времени оплаты в тип DATE и загрузить его в столбец pay_dt в таблице Selena.
{"commodity_id": "1", "customer_name": "Mark Twain", "country": "US","pay_time": 1589191487,"price": 875}
{"commodity_id": "2", "customer_name": "Oscar Wilde", "country": "UK","pay_time": 1589191487,"price": 895}
{"commodity_id": "3", "customer_name": "Antoine de Saint-Exupéry","country": "France","pay_time": 1589191487,"price": 895}
ВНИМАНИЕ Каждый JSON-объект в строке должен находиться в одном сообщении Kafka, иначе будет возвращена ошибка парсинга JSON.
Создание таблицы
В соответствии с ключами данных в формате JSON создайте таблицу example_tbl2 в базе данных example_db.
CREATE TABLE `example_tbl2` (
`commodity_id` varchar(26) NULL COMMENT "Commodity ID",
`customer_name` varchar(26) NULL COMMENT "Customer name",
`country` varchar(26) NULL COMMENT "Country",
`pay_time` bigint(20) NULL COMMENT "Payment time",
`pay_dt` date NULL COMMENT "Payment date",
`price`double SUM NULL COMMENT "Price"
)
ENGINE=OLAP
AGGREGATE KEY(`commodity_id`,`customer_name`,`country`,`pay_time`,`pay_dt`)
DISTRIBUTED BY HASH(`commodity_id`);
ВНИМАНИЕ
Начиная с версии v1.5.2, Selena может автоматически устанавливать количество bucket (BUCKETS) при создании таблицы или добавлении partition. Вам больше не нужно вручную устанавливать количество bucket. Для получения подробной информации см. установка количества bucket.
Отправка задачи Routine Load
Выполните следующий оператор, чтобы отправить задачу Routine Load с именем example_tbl2_ordertest2 для потребления сообщений из topic ordertest2 и загрузки данных в таблицу example_tbl2. Подзадача загрузки потребляет сообщения с начального смещения в указанных partition topic.
CREATE ROUTINE LOAD example_db.example_tbl2_ordertest2 ON example_tbl2
COLUMNS(commodity_id, customer_name, country, pay_time, price, pay_dt=from_unixtime(pay_time, '%Y%m%d'))
PROPERTIES
(
"desired_concurrent_number" = "5",
"format" = "json",
"jsonpaths" = "[\"$.commodity_id\",\"$.customer_name\",\"$.country\",\"$.pay_time\",\"$.price\"]"
)
FROM KAFKA
(
"kafka_broker_list" ="<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>",
"kafka_topic" = "ordertest2",
"kafka_partitions" ="0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
После отправки задачи загрузки вы можете выполнить оператор SHOW ROUTINE LOAD, чтобы проверить статус задачи загрузки.
-
Формат данных
Вам нужно указать
"format" = "json"в предложенииPROPERTIES, чтобы определить, что формат данных — JSON. -
Сопоставление и преобразование данных
Чтобы указать связь сопоставления и преобразования между данными в формате JSON и таблицей Selena, вам нужно указать параметр
COLUMNSи свойствоjsonpaths. Порядок полей, указанных в параметреCOLUMNS, должен соответствовать порядку данных в формате JSON, а имена полей должны соответствовать именам в таблице Selena. Свойствоjsonpathsиспользуется для извлечения необходимых полей из данных JSON. Затем эти поля именуются свойствомCOLUMNS.Поскольку в примере необходимо преобразовать поле времени оплаты в тип данных DATE и загрузить данные в столбец
pay_dtв таблице Selena, вам нужно использовать функцию from_unixtime. Остальные поля сопоставляются с полями таблицыexample_tbl2напрямую.Сопоставление данных:
-
Selena извлекает ключи
nameиcodeиз данных в формате JSON и сопоставляет их с ключами, объявленными в свойствеjsonpaths. -
Selena извлекает ключи, объявленные в свойстве
jsonpaths, и сопоставляет их последовательно с полями, объявленными в параметреCOLUMNS. -
Selena извлекает поля, объявленные в параметре
COLUMNS, и сопоставляет их по имени со столбцами таблицы Selena.
Преобразование данных:
-
Поскольку в примере необходимо преобразовать ключ
pay_timeв тип данных DATE и загрузить данные в столбецpay_dtв таблице Selena, вам нужно использовать функцию from_unixtime в параметреCOLUMNS. Остальные поля сопоставляются с полями таблицыexample_tbl2напрямую. -
И поскольку пример исключает столбец пола клиента из данных в формате JSON, поле
temp_genderв параметреCOLUMNSиспользуется в качестве заполнителя для этого поля. Остальные поля сопоставляются со столбцами таблицы Selenaexample_tbl1напрямую.Для получения дополнительной информации о преобразовании данных см. Преобразование д�анных при загрузке.
ПРИМЕЧАНИЕ
Вам не нужно указывать параметр
COLUMNS, если имена и количество ключей в JSON-объекте полностью соответствуют именам и количеству полей в таблице Selena.
-
Загрузка данных в формате Avro
Начиная с версии v1.5.2, Selena поддерживает загрузку данных Avro с помощью Routine Load.
Подготовка набора данных
Схема Avro
-
Создайте следующий файл схемы Avro
avro_schema.avsc:{
"type": "record",
"name": "sensor_log",
"fields" : [
{"name": "id", "type": "long"},
{"name": "name", "type": "string"},
{"name": "checked", "type" : "boolean"},
{"name": "data", "type": "double"},
{"name": "sensor_type", "type": {"type": "enum", "name": "sensor_type_enum", "symbols" : ["TEMPERATURE", "HUMIDITY", "AIR-PRESSURE"]}}
]
} -
Зарегистрируйте схему Avro в Schema Registry.
Данные Avro
Подготовьте данные Avro и отправьте их в topic Kafka topic_0.
Создание таблицы
В соответствии с полями данных Avro создайте таблицу sensor_log в целевой базе данных example_db в cluster Selena. Имена столбцов таблицы должны соответствовать именам полей в данных Avro. Для сопоставления типов данных между столбцами таблицы и полями данных Avro см. Сопоставление типов данных.
CREATE TABLE example_db.sensor_log (
`id` bigint NOT NULL COMMENT "sensor id",
`name` varchar(26) NOT NULL COMMENT "sensor name",
`checked` boolean NOT NULL COMMENT "checked",
`data` double NULL COMMENT "sensor data",
`sensor_type` varchar(26) NOT NULL COMMENT "sensor type"
)
ENGINE=OLAP
DUPLICATE KEY (id)
DISTRIBUTED BY HASH(`id`);
ВНИМАНИЕ
Начиная с версии v1.5.2, Selena может автоматически устанавливать количество bucket (BUCKETS) при создании таблицы или добавлении partition. Вам больше не нужно вручную устанавливать количество bucket. Для получения подробной информации см. установка количества bucket.
Отправка задачи Routine Load
Выполните следующий оператор, чтобы отправить задачу Routine Load с именем sensor_log_load_job для потребления сообщений Avro из topic Kafka topic_0 и загрузки данных в таблицу sensor_log в базе данных sensor. Задача загрузки потребляет сообщения с начального смещения в указанных partition topic.
CREATE ROUTINE LOAD example_db.sensor_log_load_job ON sensor_log
PROPERTIES
(
"format" = "avro"
)
FROM KAFKA
(
"kafka_broker_list" = "<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>,...",
"confluent.schema.registry.url" = "http://172.xx.xxx.xxx:8081",
"kafka_topic" = "topic_0",
"kafka_partitions" = "0,1,2,3,4,5",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
-
Формат данных
Вам нужно указать
"format = "avro"в предложенииPROPERTIES, чтобы определить, что формат данных — Avro. -
Schema Registry
Вам нужно настроить
confluent.schema.registry.url, чтобы указать URL Schema Registry, где зарегистрирована схема Avro. Selena получает схему Avro, используя этот URL. Формат следующий:confluent.schema.registry.url = http[s]://[<schema-registry-api-key>:<schema-registry-api-secret>@]<hostname|ip address>[:<port>] -
Сопоставление и преобразование данных
Чтобы указать связь сопоставления и преобразования между данными в формате Avro и таблицей Selena, вам нужно указать параметр
COLUMNSи свойствоjsonpaths. Порядок полей, указанных в параметреCOLUMNS, должен соответствовать порядку полей в свойствеjsonpaths, а имена полей должны соответствовать именам в таблице Selena. Свойствоjsonpathsиспользуется для извлечения необходимых полей из данных Avro. Затем эти поля именуются свойствомCOLUMNS.Для получения дополнительной информации о преобразовании данных см. Преобразование данных при загрузке.
ПРИМЕЧАНИЕ
Вам не нужно указывать параметр
COLUMNS, если имена и количество полей в записи Avro полностью соответствуют именам и количеству столбцов в таблице Selena.
После отправки задачи загрузки вы можете выполнить оператор SHOW ROUTINE LOAD, чтобы проверить статус задачи загрузки.
Сопоставление типов данных
Сопоставление типов данных межд�у полями данных Avro, которые вы хотите загрузить, и столбцами таблицы Selena следующее:
Примитивные типы
| Avro | Selena |
|---|---|
| nul | NULL |
| boolean | BOOLEAN |
| int | INT |
| long | BIGINT |
| float | FLOAT |
| double | DOUBLE |
| bytes | STRING |
| string | STRING |
Сложные типы
| Avro | Selena |
|---|---|
| record | Загружает всю RECORD или её подполя в Selena как JSON. |
| enums | STRING |
| arrays | ARRAY |
| maps | JSON |
| union(T, null) | NULLABLE(T) |
| fixed | STRING |
Ограничения
- В настоящее время Selena не поддерживает эволюцию схемы.
- Каждое сообщение Kafka должно содержать только одну запись данных Avro.
Проверка задачи загрузки и подзадачи
Проверка задачи загрузки
Выполните оператор SHOW ROUTINE LOAD, чтобы проверить статус задачи загрузки example_tbl2_ordertest2. Selena возвращает состояние выполнения State, статистическую информацию (включая общее количество потреблённых строк и общее количество загруженных строк) Statistics и прогресс задачи загрузки progress.
Если состояние задачи загрузки автоматически изменилось на PAUSED, это возможно потому, что количество ошибочных строк превысило порог. Для получения подробных инструкций по установке этого порога см. CREATE ROUTINE LOAD. Вы можете проверить файлы ReasonOfStateChanged и ErrorLogUrls, чтобы выявить и устранить проблему. Устранив проблему, вы можете затем выполнить оператор RESUME ROUTINE LOAD, чтобы возобновить приостановленную (PAUSED) задачу загрузки.
Если состояние задачи загрузки — CANCELLED, возможно, задача загрузки столкнулась с исключением (например, таблица была удалена). Вы можете проверить файлы ReasonOfStateChanged и ErrorLogUrls, чтобы выявить и устранить проблему. Однако вы не можете возобновить отменённую (CANCELLED) задачу загрузки.
MySQL [example_db]> SHOW ROUTINE LOAD FOR example_tbl2_ordertest2 \G
*************************** 1. row ***************************
Id: 63013
Name: example_tbl2_ordertest2
CreateTime: 2022-08-10 17:09:00
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:example_db
TableName: example_tbl2
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 3
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"commodity_id,customer_name,country,pay_time,pay_dt=from_unixtime(`pay_time`, '%Y%m%d'),price","maxBatchIntervalS":"20","whereExpr":"*","dataFormat":"json","timezone":"Asia/Shanghai","format":"json","json_root":"","strict_mode":"false","jsonpaths":"[\"$.commodity_id\",\"$.customer_name\",\"$.country\",\"$.pay_time\",\"$.price\"]","desireTaskConcurrentNum":"3","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"3","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"ordertest2","currentKafkaPartitions":"0,1,2,3,4","brokerList":"<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING"}
Statistic: {"receivedBytes":230,"errorRows":0,"committedTaskNum":1,"loadedRows":2,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":2,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":522}
Progress: {"0":"1","1":"OFFSET_ZERO","2":"OFFSET_ZERO","3":"OFFSET_ZERO","4":"OFFSET_ZERO"}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
ВНИМАНИЕ
Вы не можете проверить задачу загрузки, которая остановлена или ещё не запущена.
Проверка подзадачи загрузки
Выполните оператор SHOW ROUTINE LOAD TASK, чтобы проверить подзадачи загрузки задачи загрузки example_tbl2_ordertest2, такие как количество текущих выполняемых подзадач, partition topic Kafka, которые потребляются, и прогресс потребления DataSourceProperties, а также соответствующий узел Coordinator BE BeId.
MySQL [example_db]> SHOW ROUTINE LOAD TASK WHERE JobName = "example_tbl2_ordertest2" \G
*************************** 1. row ***************************
TaskId: 18c3a823-d73e-4a64-b9cb-b9eced026753
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:05
LastScheduledTime: 2022-08-10 17:47:27
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"1":0,"4":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
*************************** 2. row ***************************
TaskId: f76c97ac-26aa-4b41-8194-a8ba2063eb00
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:05
LastScheduledTime: 2022-08-10 17:47:26
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"2":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
*************************** 3. row ***************************
TaskId: 1a327a34-99f4-4f8d-8014-3cd38db99ec6
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:26
LastScheduledTime: 2022-08-10 17:47:27
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"0":2,"3":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
Приостановка задачи загрузки
Вы можете выполнить оператор PAUSE ROUTINE LOAD, чтобы приостановить задачу загрузки. Состояние задачи загрузки станет PAUSED после выполнения оператора. Однако она не остановлена. Вы можете выполнить оператор RESUME ROUTINE LOAD, чтобы возобновить её. Вы также можете проверить её статус с помощью оператора SHOW ROUTINE LOAD.
Следующий пример приостанавливает задачу загрузки example_tbl2_ordertest2:
PAUSE ROUTINE LOAD FOR example_tbl2_ordertest2;
Возобновление задачи загрузки
Вы можете выполнить оператор RESUME ROUTINE LOAD, чтобы возобновить приостановленную задачу загрузки. Состояние задачи загрузки временно станет NEED_SCHEDULE (поскольку задача загрузки перепланируется), а затем станет RUNNING. Вы можете проверить её статус с помощью оператора SHOW ROUTINE LOAD.
Следующий пример возобновляет приостановленную задачу загрузки example_tbl2_ordertest2:
RESUME ROUTINE LOAD FOR example_tbl2_ordertest2;
Изменение задачи загрузки
Перед изменением задачи загрузки вы должны приостановить её с помощью оператора PAUSE ROUTINE LOAD. Затем вы можете выполнить ALTER ROUTINE LOAD. После изменения вы можете выполнить оператор RESUME ROUTINE LOAD, чтобы возобновить её, и проверить её статус с помощью оператора SHOW ROUTINE LOAD.
П�редположим, что количество активных узлов BE увеличилось до 6, а partition topic Kafka для потребления — "0,1,2,3,4,5,6,7". Если вы хотите увеличить фактический параллелизм подзадач загрузки, вы можете выполнить следующий оператор, чтобы увеличить количество желаемого параллелизма задач desired_concurrent_number до 6 (больше или равно количеству активных узлов BE) и указать partition topic Kafka и начальные смещения.
ПРИМЕЧАНИЕ
Поскольку фактический параллелизм задач определяется минимальным значением нескольких параметров, вы должны убедиться, что значение динамического параметра FE
max_routine_load_task_concurrent_numбольше или равно6.
ALTER ROUTINE LOAD FOR example_tbl2_ordertest2
PROPERTIES
(
"desired_concurrent_number" = "6"
)
FROM kafka
(
"kafka_partitions" = "0,1,2,3,4,5,6,7",
"kafka_offsets" = "OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_END,OFFSET_END,OFFSET_END,OFFSET_END"
);
Остановка задачи загрузки
Вы можете выполнить оператор STOP ROUTINE LOAD, чтобы остановить задачу загрузки. Состояние задачи загрузки станет STOPPED после выполнения оператора, и вы не сможете возобновить остановленную задачу загрузки. Вы не можете проверить статус остановленной задачи загрузки с помощью оператора SHOW ROUTINE LOAD.
Следующий пример останавливает задачу загрузки example_tbl2_ordertest2:
STOP ROUTINE LOAD FOR example_tbl2_ordertest2;