Загрузка данных из локальной файловой системы
Selena предоставляет два метода загрузки данных из локальной файловой системы:
- Синхронная загрузка с использованием Stream Load
- Асинхронная загрузка с использованием Broker Load
Каждый из этих вариантов имеет свои преимущества:
- Stream Load поддерживает форматы CSV и JSON. Этот метод рекомендуется, если вы хотите загрузить данные из небольшого количества файлов, размер каждого из которых не превышает 10 ГБ.
- Broker Load поддерживает форматы Parquet, ORC, CSV и JSON (формат JSON поддерживается начиная с версии v1.5.2). Этот метод рекомендуется, если вы хотите загрузить данные из большого количества файлов, размер каждого из которых превышает 10 ГБ, или если файлы хранятся на сетевом хранилище (NAS). Использование Broker Load для загрузки данных из локальной файловой системы поддерживается начиная с версии v1.5.2.
Для данных в формате CSV обратите внимание на следующее:
- Вы можете использовать строку UTF-8, такую как запятая (,), табуляция или вертикальная черта (|), длиной не более 50 байт в качестве текстового разделителя.
- Значения NULL обозначаются с помощью
\N. Например, если файл данных состоит из трёх столбцов, и запись из этого файла содержит �данные в первом и третьем столбцах, но не содержит данных во втором столбце, необходимо использовать\Nво втором столбце для обозначения значения NULL. Это означает, что запись должна быть записана какa,\N,b, а неa,,b. Записьa,,bозначает, что второй столбец содержит пустую строку.
Stream Load и Broker Load поддерживают трансформацию данных при загрузке, а также изменения данных с помощью операций UPSERT и DELETE во время загрузки. Для получения дополнительной информации см. Трансформация данных при загрузке и Изменение данных через загрузку.
Перед началом работы
Проверка привилегий
Вы можете загружать данные в таблицы Selena только как пользователь, имеющий приви�легию INSERT на эти таблицы Selena. Если у вас нет привилегии INSERT, следуйте инструкциям в разделе GRANT, чтобы предоставить привилегию INSERT пользователю, которого вы используете для подключения к вашему cluster Selena. Синтаксис: GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}.
Проверка сетевой конфигурации
Убедитесь, что машина, на которой находятся загружаемые данные, имеет доступ к узлам FE и BE cluster Selena через порты http_port (по умолчанию: 8030) и be_http_port (по умолчанию: 8040) соответственно.
Загрузка из локальной файловой системы через Stream Load
Stream Load — это синхронный метод загрузки на основе HTTP PUT. После отправки задания загрузки Selena синхронно выполняет задание и возвращает результат после завершения. Вы можете определить успешность задания по его результату.
ПРИМЕЧАНИЕ
После загрузки данных в таблицу Selena с помощью Stream Load данные материализованных представлений, созданных на этой таблице, также обновляются.
Принцип работы
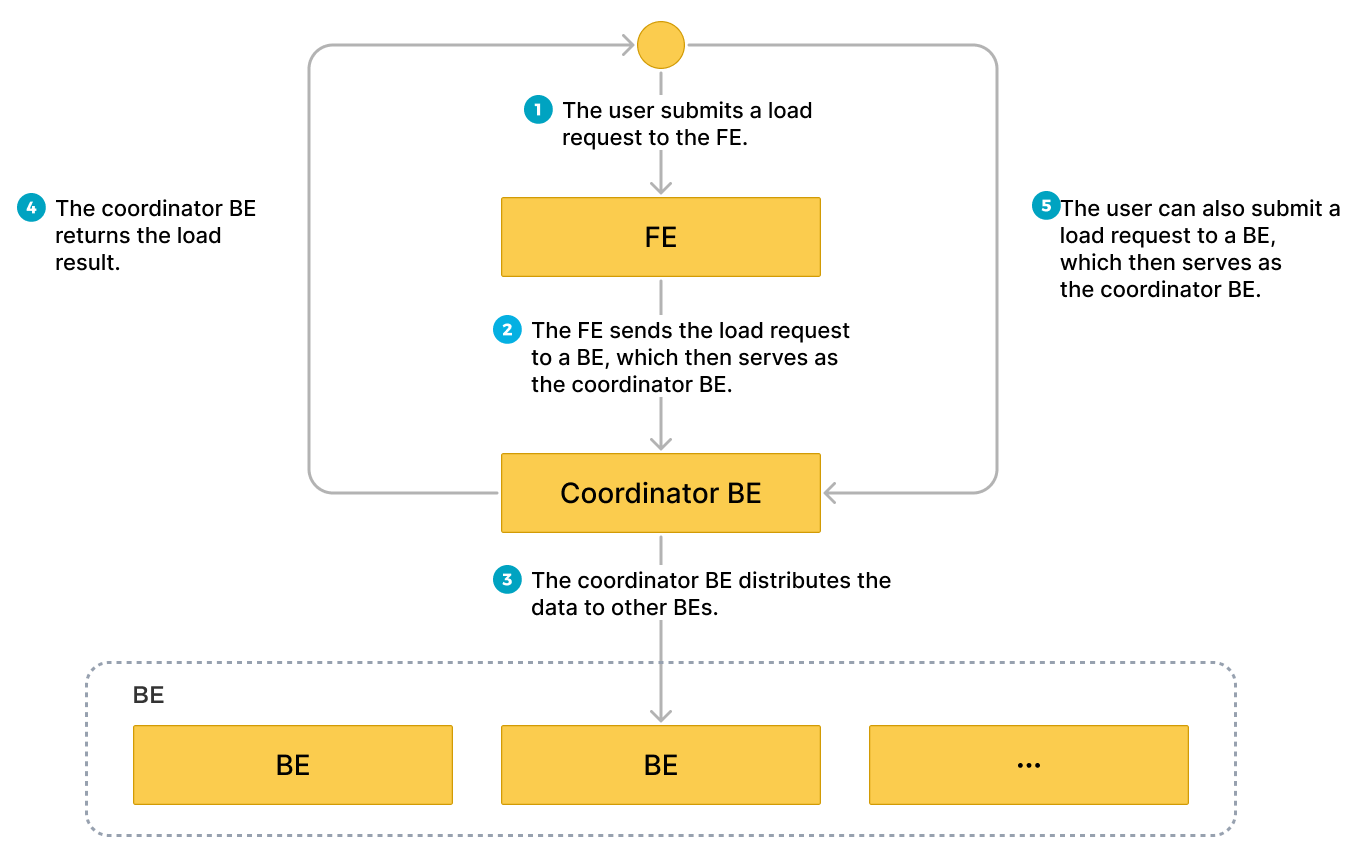
Вы можете отправить запрос загрузки с клиента на FE по протоколу HTTP, и FE затем перенаправит запрос загрузки на конкретный BE или CN с помощью HTTP redirect. Вы также можете напрямую отправить запрос загрузки с клиента на выбранный BE или CN.
Если вы отправляете запросы загрузки на FE, FE использует механизм опроса для определения того, какой BE или CN будет служить координатором для получения и обработки запросов загрузки. Механизм опроса помогает достичь балансировки нагрузки в вашем cluster Selena. Поэтому мы рекомендуем отправлять запросы загрузки на FE.
BE или CN, получивший запрос загрузки, работает как Coordinator BE или CN для разделения данных на основе используемой схемы на части и распределения каждой части данных между другими задействованными BE или CN. После завершения загрузки Coordinator BE или CN возвращает результат задания загрузки вашему клиенту. Обратите внимание, что если вы остановите Coordinator BE или CN во время загрузки, задание загрузки завершится неудачей.
На следующем рисунке показан рабочий процесс задания Stream Load.
Ограничения
Stream Load не поддерживает загрузку данных из CSV-файла, содержащего столбец в формате JSON.
Типичный пример
В этом разделе в качестве примера используется curl для описания загрузки данных из файла CSV или JSON из локальной файловой системы в Selena. Подробный синтаксис и описание параметров см. в STREAM LOAD.
Обратите внимание, что в Selena некоторые литералы используются как зарезервированные ключевые слова языка SQL. Не используйте эти ключевые слова напрямую в SQL-операторах. Если вы хотите использовать такое ключевое слово в SQL-операторе, заключите его в обратные кавычки (`). См. Ключевые слова.
Загрузка данных CSV
Подготовка наборов данных
В локальной файловой системе создайте CSV-файл с именем example1.csv. Файл состоит из трёх столбцов, которые представляют идентификатор пользователя, имя пользователя и оценку пользователя соответственно.
1,Lily,23
2,Rose,23
3,Alice,24
4,Julia,25
Создание базы данных и таблицы
Создайте базу данных и переключитесь на неё:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Создайте таблицу с первичным ключом с именем table1. Таблица состоит из трёх столбцов: id, name и score, где id является первичным ключом.
CREATE TABLE `table1`
(
`id` int(11) NOT NULL COMMENT "user ID",
`name` varchar(65533) NULL COMMENT "user name",
`score` int(11) NOT NULL COMMENT "user score"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);
Начиная с версии v1.5.2, Selena может автоматически устанавливать количество бакетов (BUCKETS) при создании таблицы или добавлении партиции. Вам больше не нужно вручную устанавливать количество бакетов. Подробную информацию см. в установка количества бакетов.
Запуск Stream Load
Выполните следующую команду для загрузки данных из example1.csv в table1:
curl --location-trusted -u <username>:<password> -H "label:123" \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns: id, name, score" \
-T example1.csv -XPUT \
http://<fe_host>:<fe_http_port>/api/mydatabase/table1/_stream_load
- Если вы используете учётную запись без установленного пароля, вам нужно ввести только
<username>:. - Вы можете использовать SHOW FRONTENDS для п�росмотра IP-адреса и HTTP-порта узла FE.
example1.csv состоит из трёх столбцов, разделённых запятыми (,), которые могут быть последовательно сопоставлены со столбцами id, name и score таблицы table1. Поэтому необходимо использовать параметр column_separator для указания запятой (,) в качестве разделителя столбцов. Также необходимо использовать параметр columns для временного именования трёх столбцов example1.csv как id, name и score, которые последовательно сопоставляются с тремя столбцами table1.
После завершения загрузки вы можете запросить table1, чтобы убедиться в успешности загрузки:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 23 |
| 2 | Rose | 23 |
| 3 | Alice | 24 |
| 4 | Julia | 25 |
+------+-------+-------+
4 rows in set (0.00 sec)
Загрузка данных JSON
Начиная с версии v1.5.2, Stream Load поддерживает сжатие данных JSON при передаче, уменьшая накладные расходы на пропускную способность сети. Пользователи могут указать различные алгоритмы сжатия с помощью параметров compression и Content-Encoding. Поддерживаемые алгоритмы сжатия включают GZIP, BZIP2, LZ4_FRAME и ZSTD. Синтаксис см. в STREAM LOAD.
Подготовка наборов данных
В локальной файловой системе создайте JSON-файл с именем example2.json. Файл состоит из двух столбцов, которые представляют идентификатор города и название города соответственно.
{"name": "Beijing", "code": 2}
Создание базы данных и таблицы
Создайте базу данных и переключитесь на неё:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Создайте таблицу с первичным ключом с именем table2. Таблица состоит из двух столбцов: id и city, где id является первичным ключом.
CREATE TABLE `table2`
(
`id` int(11) NOT NULL COMMENT "city ID",
`city` varchar(65533) NULL COMMENT "city name"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);
Начиная с версии v1.5.2, Selena может автоматически устанавливать количество бакетов (BUCKETS) при создании таблицы или добавлении партиции. Вам больше не нужно вручную устанавливать количество бакетов. Подробную информацию см. в установка количества бакетов.
Запуск Stream Load
Выполните следующую команду для загрузки данных из example2.json в table2:
curl -v --location-trusted -u <username>:<password> -H "strict_mode: true" \
-H "Expect:100-continue" \
-H "format: json" -H "jsonpaths: [\"$.name\", \"$.code\"]" \
-H "columns: city,tmp_id, id = tmp_id * 100" \
-T example2.json -XPUT \
http://<fe_host>:<fe_http_port>/api/mydatabase/table2/_stream_load
- Если вы используете учётную запись без установленного пароля, вам нужно ввести только
<username>:. - Вы можете использовать SHOW FRONTENDS для просмотра IP-адреса и HTTP-порта узла FE.
example2.json состоит из двух ключей, name и code, которые сопоставляются со столбцами id и city таблицы table2, как показано на следующем рисунке.
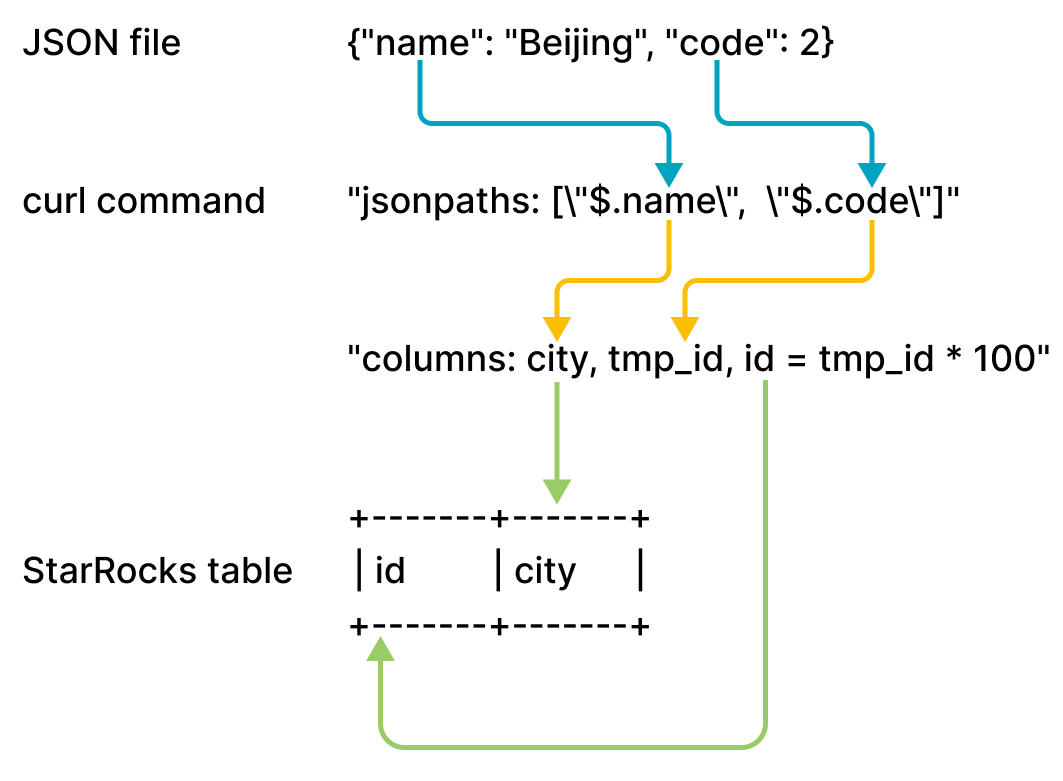
Сопоставления, показанные на предыдущем рисунке, описаны следующим образом:
-
Selena извлекает ключи
nameиcodeизexample2.jsonи сопоставляет их с полямиnameиcode, объявленными в параметреjsonpaths. -
Selena извлекает поля
nameиcode, объявленные в параметреjsonpaths, и последовательно сопоставляет их с полямиcityиtmp_id, объявленными в параметреcolumns. -
Selena извлекает поля
cityиtmp_id, объявленные в параметреcolumns, и сопоставляет их по имени со столбцамиcityиidтаблицыtable2.
В предыдущем примере значение code в example2.json умножается на 100 перед загр�узкой в столбец id таблицы table2.
Подробное описание сопоставлений между jsonpaths, columns и столбцами таблицы Selena см. в разделе "Сопоставление столбцов" в STREAM LOAD.
После завершения загрузки вы можете запросить table2, чтобы убедиться в успешности загрузки:
SELECT * FROM table2;
+------+--------+
| id | city |
+------+--------+
| 200 | Beijing|
+------+--------+
4 rows in set (0.01 sec)
Объединение запросов Stream Load
Начиная с версии v1.5.2, система поддерживает объединение нескольких запросов Stream Load.
Обратите внимание, что оптимизация Merge Commit подходит для сценариев с параллельными заданиями Stream Load на одной таблице. Она не рекомендуется, если параллелизм равен единице. Также хорошо подумайте перед установкой merge_commit_async в false и merge_commit_interval_ms в большое значение, так как это может вызвать снижение производительности загрузки.
Merge Commit — это оптимизация для Stream Load, разработанная для сценариев загрузки в реальном времени с высокой параллельностью и небольшими пакетами (от КБ до десятков МБ). В более ранних версиях каждый запрос Stream Load создавал транзакцию и версию данных, ч�то приводило к следующим проблемам в сценариях загрузки с высокой параллельностью:
- Избыточные версии данных влияют на производительность запросов, а ограничение количества версий может вызвать ошибки
too many versions. - Слияние версий данных через Compaction увеличивает потребление ресурсов.
- Создаются мелкие файлы, увеличивая IOPS и задержку I/O. В cluster с разделяемыми данными это также увеличивает затраты на облачное объектное хранилище.
- Узел Leader FE как менеджер транзакций может стать единой точкой узкого места.
Merge Commit смягчает эти проблемы путём объединения нескольких параллельных запросов Stream Load в течение временного окна в одну транзакцию. Это уменьшает количество транзакций и версий, генерируемых запросами с высокой параллельностью, тем самым улучшая производительность загрузки.
Merge Commit поддерживает как синхронный, так и асинхронный режимы. Каждый режим имеет свои преимущества и недостатки. Вы можете выбрать в зависимости от ваших сценариев использования.
-
Синхронный режим
Сервер возвращает ответ только после фиксации объединённой транзакции, гарантируя успешность и видимость загрузки.
-
Асинхронный режим
Сервер возвращает ответ сразу после получения данных. Этот режим не гарантирует успешность загрузки.
| Режим | Преимущества | Недостатки |
|---|---|---|
| Синхронный |
| Каждый запрос загрузки от клиента блокируется до тех пор, пока сервер не закроет окно слияния. Это может снизить способность обработки данных одного клиента, если окно слишком большое. |
| Асинхронный | Позволяет одному клиенту отправлять последующие запросы загрузки без ожидания закрытия окна слияния сервером, улучшая пропускную способность загрузки. |
|
Запуск Stream Load
-
Выполните следующую команду для запуска задания Stream Load с включённым Merge Commit в синхронном режиме, установив окно слияния на
5000миллисекунд и степень параллелизма на2:curl --location-trusted -u <username>:<password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns: id, name, score" \
-H "enable_merge_commit:true" \
-H "merge_commit_interval_ms:5000" \
-H "merge_commit_parallel:2" \
-T example1.csv -XPUT \
http://<fe_host>:<fe_http_port>/api/mydatabase/table1/_stream_load -
Выполните следующую команду для запуска задания Stream Load с включённым Merge Commit в асинхронном режиме, установив окно слияния на
60000миллисекунд и степень параллелизма на2:curl --location-trusted -u <username>:<password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns: id, name, score" \
-H "enable_merge_commit:true" \
-H "merge_commit_async:true" \
-H "merge_commit_interval_ms:60000" \
-H "merge_commit_parallel:2" \
-T example1.csv -XPUT \
http://<fe_host>:<fe_http_port>/api/mydatabase/table1/_stream_load
- Merge Commit поддерживает только объединение однородных запросов загрузки в одну базу данных и таблицу. "Однородные" означает, что параметры Stream Load идентичны, включая: общие параметры, параметры формата JSON, параметры формата CSV,
opt_propertiesи параметры Merge Commit. - При загрузке данных в формате CSV вы должны убедиться, что каждая строка заканчивается разделителем строк.
skip_headerне поддерживается. - Сервер автомати�чески генерирует метки для транзакций. Указанные метки будут игнорироваться.
- Merge Commit объединяет несколько запросов загрузки в одну транзакцию. Если один запрос содержит проблемы с качеством данных, все запросы в транзакции завершатся неудачей.
Проверка прогресса Stream Load
После завершения задания загрузки Selena возвращает результат задания в формате JSON. Для получения дополнительной информации см. раздел "Возвращаемое значение" в STREAM LOAD.
Stream Load не позволяет запрашивать результат задания загрузки с помощью оператора SHOW LOAD.
Отмена задания Stream Load
Stream Load не позволяет отменить задание загрузки. Если задание загрузки истекает по таймауту или �возникают ошибки, Selena автоматически отменяет задание.
Конфигурация параметров
В этом разделе описаны некоторые системные параметры, которые необходимо настроить при выборе метода загрузки Stream Load. Эти конфигурации параметров влияют на все задания Stream Load.
-
streaming_load_max_mb: максимальный размер каждого файла данных, который вы хотите загрузить. Максимальный размер по умолчанию — 10 ГБ. Для получения дополнительной информации см. Настройка динамических параметров BE или CN.Мы рекомендуем не загружать более 10 ГБ данных за раз. Если размер файла данных превышает 10 ГБ, мы рекомендуем разделить файл данных на небольшие файлы размером менее 10 ГБ каждый, а затем загружать эти файлы по одному. Если вы не можете разделить файл данных размером более 10 ГБ, вы можете увеличить значение этого параметра в зависимости от размера файла.
После увеличения значения этого параметра новое значение вступит в силу только после перезапуска BE или CN вашего cluster Selena. Кроме того, производительность системы может ухудшиться, а затраты на повторные попытки в случае сбоя загрузки также увеличатся.
примечаниеПри загрузке данных из JSON-файла обратите внимание на следующее:
-
Размер каждого объекта JSON в файле не может превышать 4 ГБ. Если какой-либо объект JSON в файле превышает 4 ГБ, Selena выдаёт ошибку "This parser can't support a document that big."
-
По умолчанию тело JSON в HTTP-запросе не может превышать 100 МБ. Если тело JSON превышает 100 МБ, Selena выдаёт ошибку "The size of this batch exceed the max size [104857600] of json type data data [8617627793]. Set ignore_json_size to skip check, although it may lead huge memory consuming." Чт�обы предотвратить эту ошибку, вы можете добавить
"ignore_json_size:true"в заголовок HTTP-запроса, чтобы игнорировать проверку размера тела JSON.
-
-
stream_load_default_timeout_second: тайм-аут для каждого задания загрузки. Тайм-аут по умолчанию — 600 секунд. Для получения дополнительной информации см. Настройка динамических параметров FE.Если многие из созданных вами заданий загрузки истекают по таймауту, вы можете увеличить значение этого параметра на основе результата расчёта, который вы получите по следующей формуле:
Тайм-аут каждого задания загрузки > Объём загружаемых данных / Средняя скорость загрузки
Например, если размер файла данных, который вы хотите загрузить, составляет 10 ГБ, а средняя скорость загрузки вашего cluster Selena составляет 100 МБ/с, установите тайм-аут более 100 секунд.
примечаниеСредняя скорость загрузки в предыдущей формуле — это средняя скорость загрузки вашего cluster Selena. Она зависит от I/O диска и количества BE или CN в вашем cluster Selena.
Stream Load также предоставляет параметр
timeout, который позволяет указать тайм-аут для отдельного задания загрузки. Для получения дополнительной информации см. STREAM LOAD.
Примечания по использованию
Если поле отсутствует для записи в файле данных, который вы хотите загрузить, и столбец, на который сопоставляется поле в вашей таблице Selena, определён как NOT NULL, Selena автоматически заполняет значение NULL в сопоставляемом столбце вашей таблицы Selena во вр�емя загрузки записи. Вы также можете использовать функцию ifnull() для указания значения по умолчанию, которое вы хотите заполнить.
Например, если поле, представляющее идентификатор города, в предыдущем файле example2.json отсутствует, и вы хотите заполнить значение x в сопоставляемом столбце table2, вы можете указать "columns: city, tmp_id, id = ifnull(tmp_id, 'x')".
Загрузка из локальной файловой системы через Broker Load
В дополнение к Stream Load вы также можете использовать Broker Load для загрузки данных из локальной файловой системы. Эта функция поддерживается начиная с версии v1.5.2.
Broker Load — это асинхронный метод загрузки. После отправки задания загрузки Selena асинхронно выполняет задание и не возвращает сразу результат задания. Вам нужно запросить результат задания вручную. См. Проверка прогресса Broker Load.
Ограничения
- В настоящее время Broker Load поддерживает загрузку из локальной файловой системы только через один брокер версии v1.5.2 или выше.
- Запросы с высокой параллельностью к одному брокеру могут вызвать такие проблемы, как тайм-аут и OOM. Для смягчения влияния вы можете использовать переменную
pipeline_dop(см. Системная переменная) для установки параллелизма запросов для Broker Load. Для запросов к одному брокеру мы рекомендуем установитьpipeline_dopна значение менее16.
Типичный пример
Broker Load поддерживает загрузку из одного файла данных в одну таблицу, загрузку из нескольких файлов данных в одну таблицу и загрузку из нескольких файлов данных в несколько таблиц. В этом разделе в качестве примера используется загрузка из нескольких файлов данных в одну таблицу.
Обратите внимание, что в Selena некоторые литералы используются как зарезервированные ключевые слова языка SQL. Не используйте эти ключевые слова напрямую в SQL-операторах. Если вы хотите использовать такое ключевое слово в SQL-операторе, заключите его в обратные кавычки (`). См. Ключевые слова.
Подготовка наборов данных
В качестве примера используется формат CSV. Войдите в локальную файловую систему и создайте два CSV-файла, file1.csv и file2.csv, в определённом месте хранения (например, /home/disk1/business/). Оба файла состоят из трёх столбцов, которые представляют идентификатор пользователя, имя пользователя и оценку пользователя соответственно.
-
file1.csv1,Lily,21
2,Rose,22
3,Alice,23
4,Julia,24 -
file2.csv5,Tony,25
6,Adam,26
7,Allen,27
8,Jacky,28
Создание базы данных и таблицы
Создайте базу данных и переключитесь на неё:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Создайте таблицу с первичным ключом с именем mytable. Таблица состоит из трёх столбцов: id, name и score, где id является первичным ключом.
CREATE TABLE `mytable`
(
`id` int(11) NOT NULL COMMENT "User ID",
`name` varchar(65533) NULL DEFAULT "" COMMENT "User name",
`score` int(11) NOT NULL DEFAULT "0" COMMENT "User score"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`)
PROPERTIES("replication_num"="1");
Запуск Broker Load
Выполните следующую команду для запуска задания Broker Load, которое загружает данные из всех файлов данных (file1.csv и file2.csv), хранящихся по пути /home/disk1/business/ вашей локальной файловой системы, в таблицу Selena mytable:
LOAD LABEL mydatabase.label_local
(
DATA INFILE("file:///home/disk1/business/csv/*")
INTO TABLE mytable
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER "sole_broker"
PROPERTIES
(
"timeout" = "3600"
);
Это задание содержит четыре основных раздела:
LABEL: Строка, используемая при запросе состояния задания загрузки.LOADобъявление: Исходный URI, формат исходных данных и имя целевой таблицы.PROPERTIES: Значение тайм-аута и любые другие свойства, применяемые к заданию загрузки.
Подробный синтаксис и описание параметров см. в BROKER LOAD.
Проверка прогресса Broker Load
В версии v1.5.2 и более ранних используйте оператор SHOW LOAD или команду curl для просмотра прогресса заданий Broker Load.
В версии v1.5.2 и более поздних вы можете просмотреть прогресс заданий Broker Load из представления information_schema.loads:
SELECT * FROM information_schema.loads;
Если вы отправили несколько заданий загрузки, вы можете отфильтровать по LABEL, связанному с заданием. Пример:
SELECT * FROM information_schema.loads WHERE LABEL = 'label_local';
После подтверждения завершения задания загрузки вы можете запросить таблицу, чтобы проверить, были ли данные успешно загружены. Пример:
SELECT * FROM mytable;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 3 | Alice | 23 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 4 | Julia | 24 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
8 rows in set (0.07 sec)
Отмена задания Broker Load
Когда задание загрузки не находится на стадии CANCELLED или FINISHED, вы можете использовать оператор CANCEL LOAD для отмены задания.
Например, вы можете выполнить следующий оператор для отмены задания загрузки с меткой label_local в базе данных mydatabase:
CANCEL LOAD
FROM mydatabase
WHERE LABEL = "label_local";
Загрузка из NAS через Broker Load
Существует два способа загрузки данных из NAS с использованием Broker Load:
- Рассматривать NAS как локальную файловую систему и запускать задание загрузки с брокером. См. предыдущий раздел "Загрузка из локальной системы через Broker Load".
- (Рекомендуется) Рассматривать NAS как облачную систему хранения и запускать задание загрузки без брокера.
В этом разделе описан второй способ. Подробные операции следующие:
-
Смонтируйте устройство NAS по одному и тому же пути на всех узлах BE или CN и узлах FE вашего cluster Selena. Таким образом, все BE или CN могут получить доступ к устройству NAS так же, как они получают доступ к своим локально сохранённым файлам.
-
Используйте Broker Load для загрузки данных с устройства NAS в целевую таблицу Selena. Пример:
LOAD LABEL test_db.label_nas
(
DATA INFILE("file:///home/disk1/sr/*")
INTO TABLE mytable
COLUMNS TERMINATED BY ","
)
WITH BROKER
PROPERTIES
(
"timeout" = "3600"
);Это задание содержит четыре основных раздела:
LABEL: Строка, используемая при запросе состояния задания загрузки.LOADобъявление: Исходный URI, формат исходных данных и имя целевой таблицы. Обратите внимание, чтоDATA INFILEв объявлении используется для указания пути к точке монтирования устройства NAS, как показано в приведённом выше примере, гдеfile:///является префиксом, а/home/disk1/sr— путём к папке точки монтирования.BROKER: Вам не нужно указывать имя брокера.PROPERTIES: Значение тайм-аута и любые другие свойства, применяемые к заданию загрузки.
Подробный синтаксис и описание параметров см. в BROKER LOAD.
После отправки задания вы можете просмотреть прогресс загрузки или отменить задание по мере необходимости. Подробные операции см. в разделах "Проверка прогресса Broker Load" и "Отмена задания Broker Load" в этой теме.