Apache Hudi Lakehouse
Обзор
- Развертывание Object Storage, Apache Spark, Hudi и Selena с использованием Docker compose
- Загрузка небольшого набора данных в Hudi с помощью Apache Spark
- Настройка Selena для доступа к Hive Metastore с использованием внешнего каталога
- Запросы к данным с помощью Selena непосредственно там, где они находятся
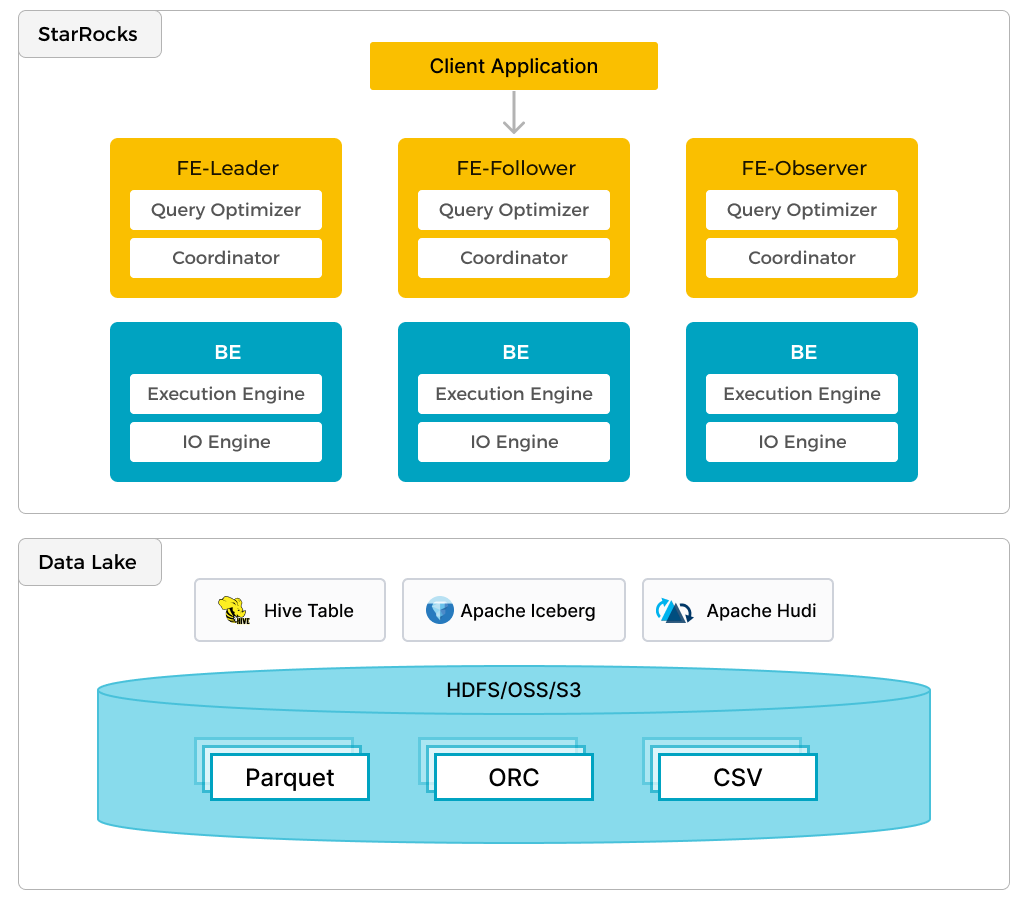
Помимо эффективной аналитики локальных данных, Selena может работать как вычислительный движок для анализа данных, хранящихся в озёрах данных, таких как Apache Hudi, Apache Iceberg и Delta Lake. Одной из ключевых особенностей Selena является внешний каталог, который служит связующим звеном с внешним metastore. Эта функциональность предоставляет пользователям возможность бесшовно выполнять запросы к внешним источникам данных, устраняя необходимость в миграции данных. Таким образом, пользователи могут анализировать данные из различных систем, таких как HDFS и Amazon S3, в различных форматах файлов, таких как Parquet, ORC, CSV и др.
На приведённом рисунке показан сценарий аналитики озера данных, где Selena отвечает за вычисления и анализ данных, а озеро данных — за хранение, организацию и обслуживание данных. Озёра данных позволяют пользователям хранить данные в открытых форматах хранения и использовать гибкие схемы для создания отчётов на основе «единого источника истины» для различных сценариев использования BI, AI, ad-hoc и отчётности. Selena в полной мере использует преимущества своего векторизованного движка и CBO, значительно повышая производительность аналитики озёр данных.
Предварительные требования
Репозиторий demo Selena
Клонируйте репозиторий demo Selena на ваш локальный компьютер.
Все шаги в этом руководстве будут выполняться из директории demo/documentation-samples/hudi/ в директории, куда вы клонировали GitHub-репозиторий demo.
Docker
- Настройка Docker: Для Mac следуйте шагам, описанным в Install Docker Desktop on Mac. Для выполнения запросов Spark-SQL убедитесь, что Docker выделено не менее 5 ГБ памяти и 4 CPU (см. Docker → Preferences → Advanced). В противном случае запросы spark-SQL могут быть завершены из-за проблем с памятью.
- 20 ГБ свободного дискового пространства, выделенного для Docker
SQL-клиент
Вы можете использовать SQL-клиент, предоставленный в среде Docker, или использовать клиент на вашей системе. Многие MySQL-совместимые клиенты будут работать.
Конфигурация
Перейдите в директорию demo/documentation-samples/hudi и просмотрите файлы. Это не руководство по Hudi, поэтому не каждый конфигурационный файл будет описан; но важно, чтобы читатель знал, где искать информацию о настройке. В директории hudi/ вы найдете файл docker-compose.yml, который используется для запуска и настройки сервисов в Docker. Вот список этих сервисов и краткое описание:
Сервисы Docker
| Сервис | Назначение |
|---|---|
selena-fe | Управление метаданными, клиентские подключения, планы и расписание запросов |
selena-be | Выполнение планов запросов |
metastore_db | Postgres DB для хранения метаданных Hive |
hive_metastore | Предоставляет Apache Hive metastore |
minio и mc | MinIO Object Storage и клиент командной строки MinIO |
spark-hudi | Распределенные вычисления и транзакционная платформа data lake |
Конфигурационные файлы
В директории hudi/conf/ вы найдете конфигурационные файлы, которые монтируются в контейнере spark-hudi.
core-site.xml
Этот файл содержит настройки, связанные с объектным хранилищем. Ссылки на этот и другие элементы находятся в разделе дополнительной информации в конце этого документа.
spark-defaults.conf
Настройки для Hive, MinIO и Spark SQL.
hudi-defaults.conf
Файл по умолчанию, используемый для подавления предупреждений в spark-shell.
hadoop-metrics2-hbase.properties
Пустой файл, используемый для подавления предупреждений в spark-shell.
hadoop-metrics2-s3a-file-system.properties
Пустой файл, используемый для подавления предупреждений в spark-shell.
Запуск демо-cluster
Эта демо-система состоит из сервисов Selena, Hudi, MinIO и Spark. Запустите Docker compose для запуска cluster:
docker compose up --detach --wait --wait-timeout 60
[+] Running 8/8
✔ Network hudi Created 0.0s
✔ Container hudi-selena-fe-1 Healthy 0.1s
✔ Container hudi-minio-1 Healthy 0.1s
✔ Container hudi-metastore_db-1 Healthy 0.1s
✔ Container hudi-selena-be-1 Healthy 0.0s
✔ Container hudi-mc-1 Healthy 0.0s
✔ Container hudi-hive-metastore-1 Healthy 0.0s
✔ Container hudi-spark-hudi-1 Healthy 0.1s
При работе с множеством контейнеров вывод docker compose ps легче читать, если передать его в jq:
docker compose ps --format json | \
jq '{Service: .Service, State: .State, Status: .Status}'
{
"Service": "hive-metastore",
"State": "running",
"Status": "Up About a minute (healthy)"
}
{
"Service": "mc",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "metastore_db",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "minio",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "spark-hudi",
"State": "running",
"Status": "Up 33 seconds (healthy)"
}
{
"Service": "selena-be",
"State": "running",
"Status": "Up About a minute (healthy)"
}
{
"Service": "selena-fe",
"State": "running",
"Status": "Up About a minute (healthy)"
}
Настройка MinIO
При выполнении команд Spark вы установите basePath для создаваемой таблицы в URI s3a:
val basePath = "s3a://huditest/hudi_coders"
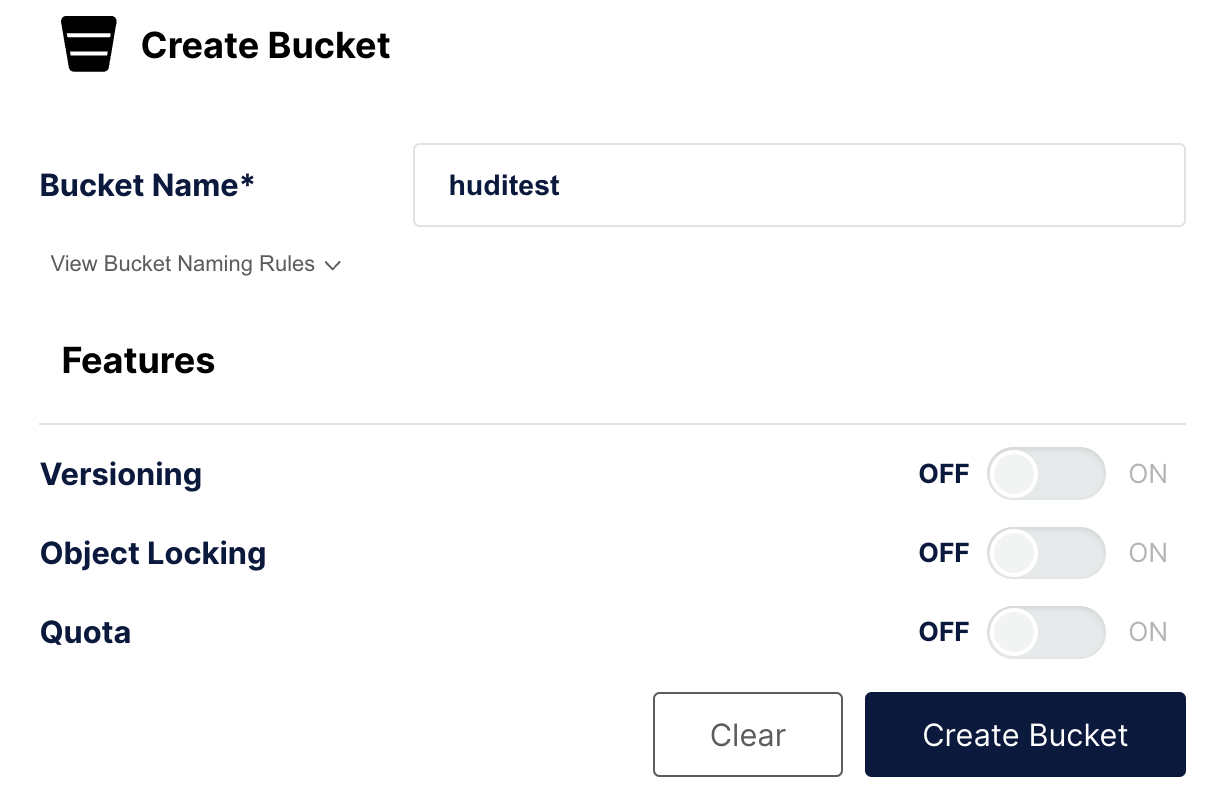
На этом шаге вы создадите bucket huditest в MinIO. Консоль MinIO работает на порту 9000.
Аутентификация в MinIO
Откройт�е браузер по адресу http://localhost:9000/ и выполните аутентификацию. Имя пользователя и пароль указаны в docker-compose.yml; это admin и password.
Создание bucket
В левой навигации выберите Buckets, затем Create Bucket +. Назовите bucket huditest и выберите Create Bucket
Создание и заполнение таблицы, затем синхронизация с Hive
Выполните эту команду и любые другие команды docker compose из директории, содержащей файл docker-compose.yml.
Откройте spark-shell в сервисе spark-hudi
docker compose exec spark-hudi spark-shell
При запуске spark-shell будут предупреждения о нелегальном рефлексивном доступе. Вы можете игнорировать эти предупреждения.
Выполните эти команды в приглашении scala> для:
- Настройки этой сессии Spark для загрузки, обработки и записи данных
- Создания dataframe и записи его в таблицу Hudi
- Синхронизации с Hive Metastore
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("language", StringType, true),
StructField("users", StringType, true),
StructField("id", StringType, true)
))
val rowData= Seq(Row("Java", "20000", "a"),
Row("Python", "100000", "b"),
Row("Scala", "3000", "c"))
val df = spark.createDataFrame(rowData,schema)
val databaseName = "hudi_sample"
val tableName = "hudi_coders_hive"
val basePath = "s3a://huditest/hudi_coders"
df.write.format("hudi").
option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).
option(RECORDKEY_FIELD_OPT_KEY, "id").
option(PARTITIONPATH_FIELD_OPT_KEY, "language").
option(PRECOMBINE_FIELD_OPT_KEY, "users").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", databaseName).
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", "language").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083").
mode(Overwrite).
save(basePath)
System.exit(0)
Вы увидите предупреждение:
WARN
org.apache.hudi.metadata.HoodieBackedTableMetadata -
Metadata table was not found at path
s3a://huditest/hudi_coders/.hoodie/metadata
Это можно игнорировать, файл будет создан автоматически во время этой сессии spark-shell.
Также будет предупреждение:
78184 [main] WARN org.apache.hadoop.fs.s3a.S3ABlockOutputStream -
Application invoked the Syncable API against stream writing to
hudi_coders/.hoodie/metadata/files/.files-0000_00000000000000.log.1_0-0-0.
This is unsupported
Это предупреждение сообщает, что синхронизация файла журнала, открытого для записи, не поддерживается при использовании объектного хранилища. Файл будет синхронизирован только после закрытия. См. Stack Overflow.
Последняя команда в приведенной выше сессии spark-shell должна выйти из контейнера; если этого не произошло, нажмите Enter, и она завершится.
Настройка Selena
Подключение к Selena
Подключитесь к Selena с помощью предоставленного MySQL-клиента сервиса selena-fe или используйте ваш любимый SQL-клиент, настроив его для подключения по протоколу MySQL на localhost:9030.
docker compose exec selena-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="Selena > "
Создание связи между Selena и Hudi
В конце этого руководства есть ссылка с дополнительной информацией о внешних каталогах. Внешний каталог, создаваемый на этом шаге, служит связью с Hive Metastore (HMS), работающим в Docker.
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://hive-metastore:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "admin",
"aws.s3.secret_key" = "password",
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "http://minio:9000"
);
Query OK, 0 rows affected (0.59 sec)
Использование нового каталога
SET CATALOG hudi_catalog_hms;
Query OK, 0 rows affected (0.01 sec)
Переход к данным, вставленным с помощью Spark
SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| default |
| hudi_sample |
| information_schema |
+--------------------+
2 rows in set (0.40 sec)
USE hudi_sample;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
SHOW TABLES;
+-----------------------+
| Tables_in_hudi_sample |
+-----------------------+
| hudi_coders_hive |
+-----------------------+
1 row in set (0.07 sec)
Запрос данных в Hudi с помощью Selena
Выполните этот запрос дважды, первый раз может занять около пяти секунд, так как данные еще не кэшированы в Selena. Второй запрос будет очень быстрым.
SELECT * from hudi_coders_hive\G
Некоторые SQL-запросы в документации Selena заканчиваются на \G вместо точки с запятой. \G заставляет mysql CLI отображать результаты запроса вертикально.
Многие SQL-клиенты не интерпретируют вертикальное форматирование вывода, поэтому вам следует заменить \G на ;, если вы не используете mysql CLI.
*************************** 1. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_0_0
_hoodie_record_key: c
_hoodie_partition_path: language=Scala
_hoodie_file_name: bb29249a-b69d-4c32-843b-b7142d8dc51c-0_0-27-1221_20240208165522561.parquet
language: Scala
users: 3000
id: c
*************************** 2. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_2_0
_hoodie_record_key: a
_hoodie_partition_path: language=Java
_hoodie_file_name: 12fc14aa-7dc4-454c-b710-1ad0556c9386-0_2-27-1223_20240208165522561.parquet
language: Java
users: 20000
id: a
*************************** 3. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_1_0
_hoodie_record_key: b
_hoodie_partition_path: language=Python
_hoodie_file_name: 51977039-d71e-4dd6-90d4-0c93656dafcf-0_1-27-1222_20240208165522561.parquet
language: Python
users: 100000
id: b
3 rows in set (0.15 sec)
Резюме
В этом руководстве вы познакомились с использованием внешнего каталога Selena, чтобы показать, что вы можете запрашивать данные там, где они находятся, с помощью внешнего каталога Hudi. Доступно множество других интеграций с использованием каталогов Iceberg, Delta Lake и JDBC.
В этом руководстве вы:
- Развернули Selena и среду Hudi/Spark/MinIO в Docker
- Загрузили небольшой набор данных в Hudi с п�омощью Apache Spark
- Настроили внешний каталог Selena для обеспечения доступа к каталогу Hudi
- Запросили данные с помощью SQL в Selena без копирования данных из data lake
Дополнительная информация
Краткое руководство Apache Hudi (включает Spark)