Kafka routine load в Selena с использованием shared-data хранилища
О Routine Load
Routine load — это метод использования Apache Kafka или, в данной лабораторной работе, Redpanda для непрерывной потоковой передачи данных в Selena. Данные передаются в Kafka topic, а задача Routine Load загружает данные в Selena. Более подробная информация о Routine Load приведена в конце лабораторной работы.
О shared-data
В системах, разделяющих хранение и вычисления, данные хранятся в недорогих надёжных удалённых системах хранения, таких как Amazon S3, Google Cloud Storage, Azure Blob Storage и других S3-совместимых хранилищах, таких как MinIO. Горячие данные кэшируются локально, и при попадании в кэш производительность запросов сопоставима с архитектурой со связанным хранилищем и вычислениями. Compute nodes (CN) можно добавлять или удалять по требованию за секунды. Эта архитектура снижает затраты на хранение, обеспечивает лучшую изоляцию ресурсов и обеспечивает эластичность и масштабируемость.
Это руководство охватывает:
- Запуск Selena, Redpanda и MinIO с помощью Docker Compose
- Использование MinIO в качестве уровня хранения Selena
- Настройку Selena для shared-data
- Добавление задачи Routine Load для загрузки данных из Redpanda
Используемые данные являются синтетическими.
В этом документе много информации, и она представлена с пошаговым содержанием в начале и техническими деталями в конце. Это сделано для достижения следующих целей в таком порядке:
- Настроить Routine Load.
- Позволить читателю загружать данные в развёртывание shared-data и анализировать эти данные.
- Предоставить детали конфигурации для развёртываний shared-data.
Предварительные требования
Docker
- Docker
- 4 GB RAM assigned to Docker
- 10 GB свободного дискового пространства, выделенного Docker
SQL-клиент
Вы можете использовать SQL-клиент, предоставляемый в окружении Docker, или использовать клиент в вашей системе. Многие MySQL-совместимые клиенты будут работать, и это руководство охватывает настройку DBeaver и MySQL Workbench.
curl
curl используется для загрузки файла Compose и скрипта для генерации данных. Проверьте, установлен ли он, запустив curl или curl.exe в командной строке вашей ОС. Если curl не установлен, получите curl здесь.
Python
Требуются Python 3 и Python-клиент для Apache Kafka — kafka-python.
Терминология
FE
Frontend-узлы отвечают за управление метаданными, управление клиентскими подключениями, планирование запросов и диспетчеризацию запросов. Каждый FE хранит и поддерживает полную копию метаданных в своей памяти, что гарантирует равнозначные сервисы между FE.
CN
Compute Nodes отвечают за выполнение планов запросов в развёртываниях shared-data.
BE
Backend-узлы отвечают как за хранение данных, так и за выполнение планов запросов в развёртываниях shared-nothing.
Это руководство не использует BE, эта информация включена здесь, чтобы вы понимали разницу между BE и CN.
Запуск Selena
Для запуска Selena с shared-data с использованием Object Storage вам нужны:
- Frontend engine (FE)
- Compute node (CN)
- Object Storage
Это �руководство использует MinIO, который является S3-совместимым провайдером Object Storage. MinIO предоставляется под лицензией GNU Affero General Public License.
Загрузка файлов лабораторной работы
docker-compose.yml
mkdir routineload
cd routineload
curl -O https://raw.githubusercontent.com/Selena/demo/master/documentation-samples/routine-load-shared-data/docker-compose.yml
gen.py
gen.py — это скрипт, который использует Python-клиент для Apache Kafka для публикации (производства) данных в Kafka topic. Скрипт написан с адресом и портом контейнера Redpanda.
curl -O https://raw.githubusercontent.com/Selena/demo/master/documentation-samples/routine-load-shared-data/gen.py
Запуск Selena, MinIO и Redpanda
docker compose up --detach --wait --wait-timeout 120
Проверьте прогресс сервисов. It should take 30 seconds or more for the containers to become healthy. The routineload-minio_mc-1 container will not show a health indicator, and it will exit once it is done configuring MinIO with the access key that Selena will use. Wait for routineload-minio_mc-1 to exit with a 0 code and the rest of the services to be Healthy.
Запускайте docker compose ps пока сервисы не станут healthy:
docker compose ps
WARN[0000] /Users/droscign/routineload/docker-compose.yml: `version` is obsolete
[+] Running 6/7
✔ Network routineload_default Crea... 0.0s
✔ Container minio Healthy 5.6s
✔ Container redpanda Healthy 3.6s
✔ Container redpanda-console Healt... 1.1s
⠧ Container routineload-minio_mc-1 Waiting 23.1s
✔ Container selena-fe Healthy 11.1s
✔ Container selena-cn Healthy 23.0s
container routineload-minio_mc-1 exited (0)
Проверка учётных данных MinIO
Чтобы использовать MinIO для Object Storage с Selena, Selena нужен access key MinIO. The access key was generated during the startup of the Docker services. To help you better understand the way that Selena connects to MinIO you should verify that the key exists.
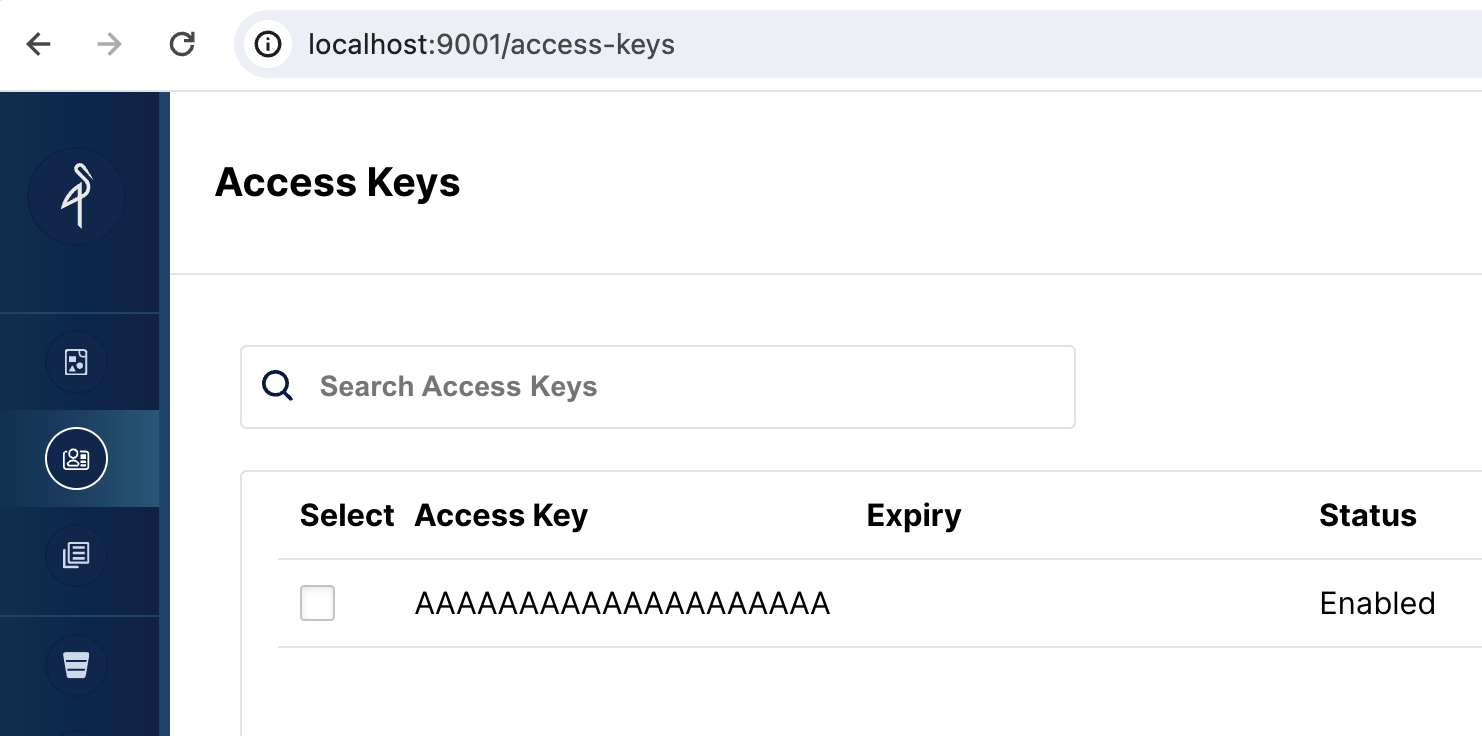
Откройте веб-интерфейс MinIO
Перейдите по адресу http://localhost:9001/access-keys Имя пользователя и пароль указаны в файле Docker compose и являются miniouser и miniopassword. Вы должны увидеть один access key. Ключ — AAAAAAAAAAAAAAAAAAAA, вы не можете увидеть секрет в MinIO Console, но он находится в файле Docker compose и является BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB:
Создание bucket для ваших данных
Когда вы создаёте storage volume в Selena, вы укажете LOCATION для данных:
LOCATIONS = ("s3://my-selena-bucket/")
Откройте http://localhost:9001/buckets и добавьте bucket для storage volume. Назовите bucket my-selena-bucket. Примите значения по умолчанию для трёх перечисленных опций.
SQL-клиенты
С этим руководством протестированы три клиента, вам нужен только один:
- mysql CLI: Вы можете запустить его из среды Docker или с вашей машины.
- DBeaver доступен в версии Community и Pro.
- MySQL Workbench
Настройка клиента
- mysql CLI
- DBeaver
- MySQL Workbench
Самый простой способ использовать mysql CLI — запустить его из контейнера Selena selena-fe:
docker compose exec selena-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="Selena > "
Все команды docker compose должны выполняться из каталога, содержащего файл docker-compose.yml.
Если вы хотите установить mysql CLI, разверните установка mysql клиента ниже:
установка mysql клиента
- macOS: Если вы используете Homebrew и вам не нужен MySQL Server, выполните
brew install mysql-client@8.0для установки CLI. - Linux: Проверьте вашу систему репозиториев для клиента
mysql. Например,yum install mariadb. - Microsoft Windows: Установите MySQL Community Server и запустите предоставленный клиент, или запустите
mysqlиз WSL.
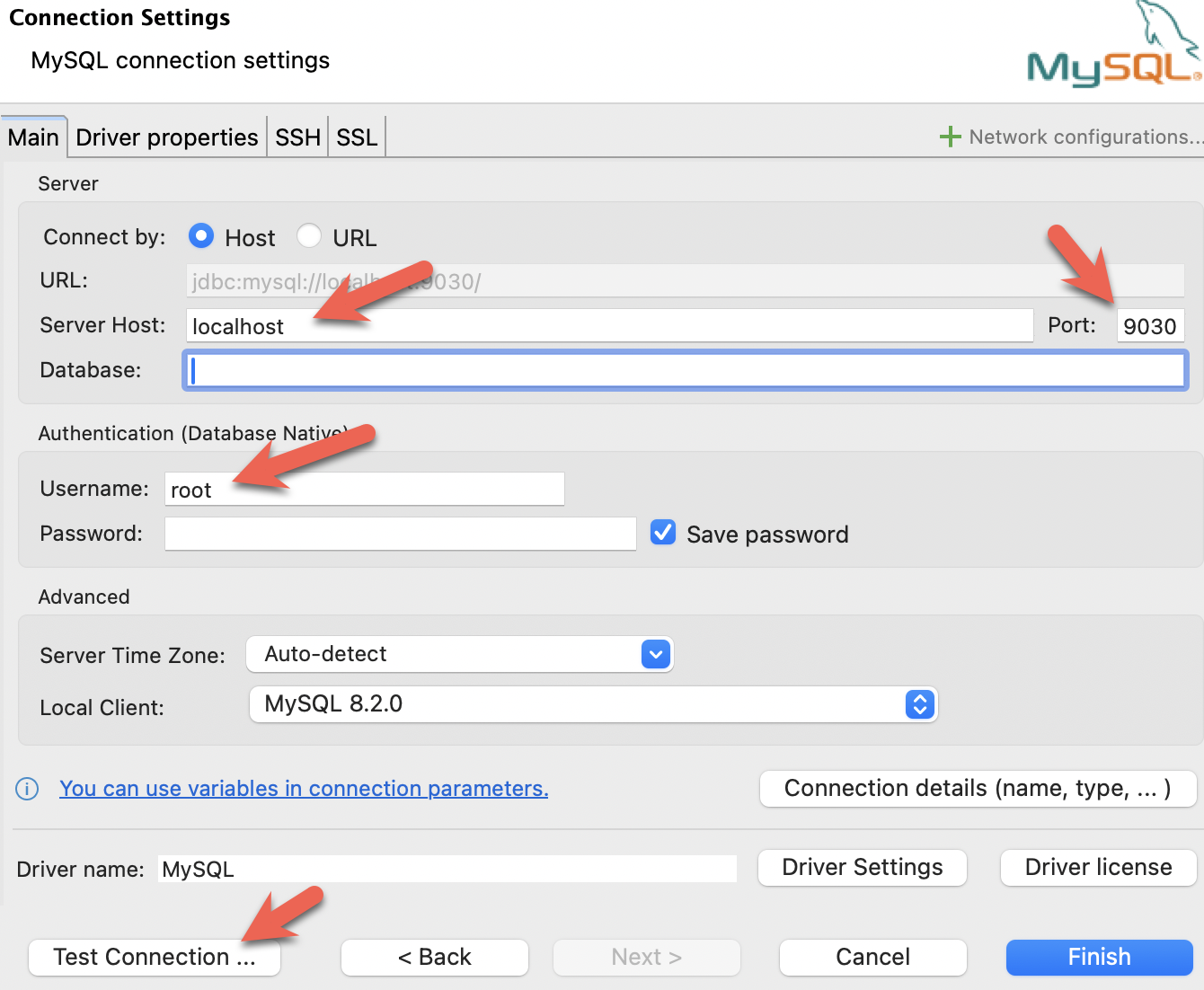
- Установите DBeaver и добавьте подключение:

- Настройте порт, IP и имя пользователя. Проверьте подключение и нажмите Finish, если тест прошёл успешно:
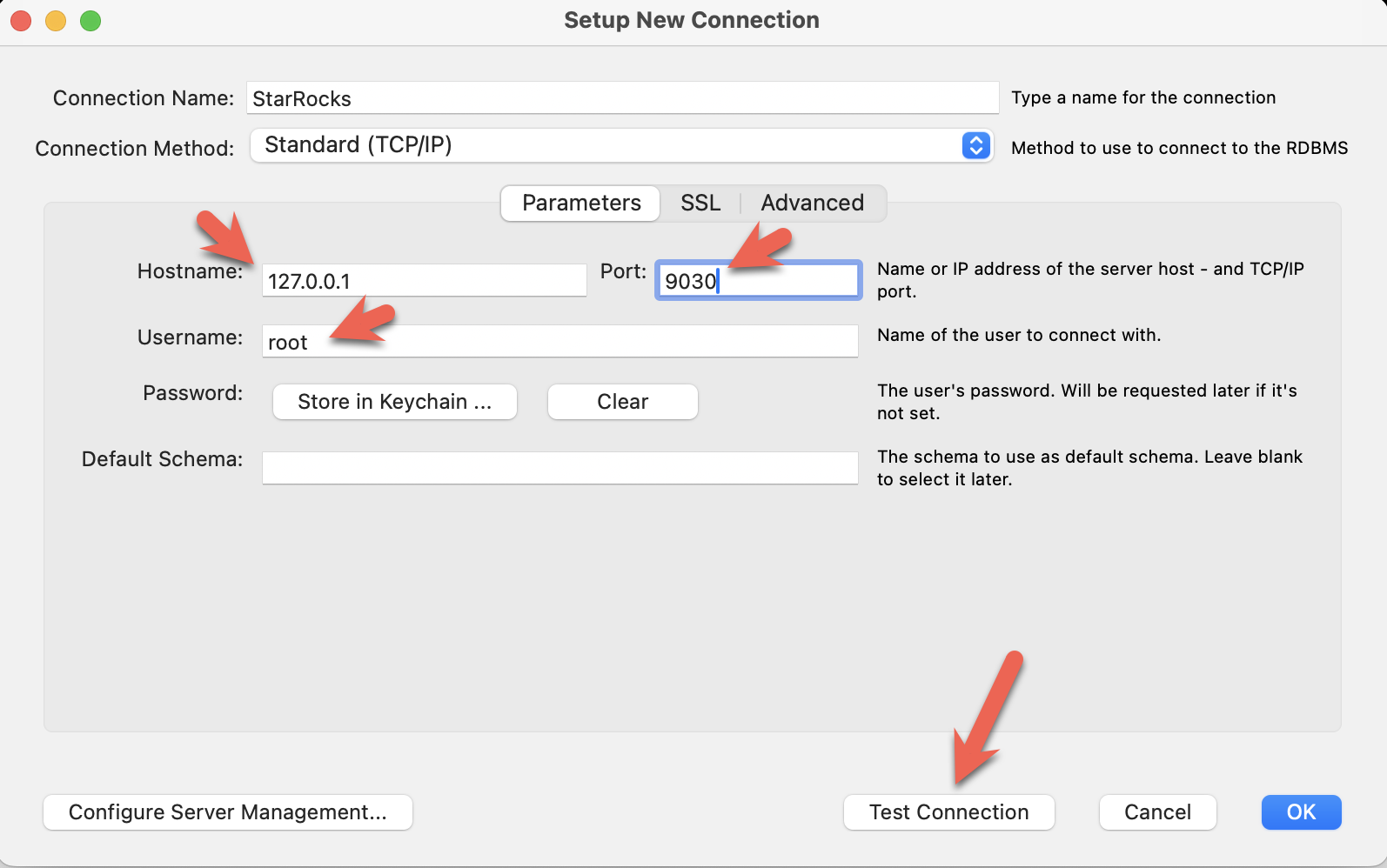
- Установите MySQL Workbench и добавьте подключение.
- Настройте порт, IP и имя пользователя, затем проверьте подключение:
- Вы увидите предупреждения от Workbench, так как он проверяет конкретную версию MySQL. Вы можете игнорировать предупреждения, и при появлении запроса можете настроить Workbench на прекращение отображения предупреждений:
Конфигурация Selena для shared-data
На данный момент у вас запущена Selena и запущен MinIO. Access key MinIO используется для подключения Selena и MinIO.
Это часть конфигурации FE, которая указывает, что развёртывание Selena будет использовать shared data. Это было добавлено в файл fe.conf при создании развёртывания Docker Compose.
# enable the shared data run mode
run_mode = shared_data
cloud_native_storage_type = S3
Вы можете проверить эти настройки, выполнив эту команду из каталога quickstart и посмотрев в конец файла:
docker compose exec selena-fe \
cat /opt/selena/fe/conf/fe.conf
:::
Подключение к Selena с помощью SQL-клиента
Выполните эту команду из каталога, содержащего файл docker-compose.yml.
Если вы используете клиент, отличный от mysql CLI, откройте его сейчас.
docker compose exec selena-fe \
mysql -P9030 -h127.0.0.1 -uroot --prompt="Selena > "
Проверка storage volumes
SHOW STORAGE VOLUMES;
Не должно быть storage volumes, вы создадите один далее.
Empty set (0.04 sec)
Создание shared-data storage volume
Ранее вы создали bucket в MinIO с именем my-selena-volume, и вы проверили, что MinIO имеет access key с именем AAAAAAAAAAAAAAAAAAAA. Следующий SQL создаст storage volume в bucket MinIO, используя access key и секрет.
CREATE STORAGE VOLUME s3_volume
TYPE = S3
LOCATIONS = ("s3://my-selena-bucket/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "minio:9000",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_instance_profile" = "false",
"aws.s3.use_aws_sdk_default_behavior" = "false"
);
Теперь вы должны увидеть перечисленный storage volume, ранее был пустой набор:
SHOW STORAGE VOLUMES;
+----------------+
| Storage Volume |
+----------------+
| s3_volume |
+----------------+
1 row in set (0.02 sec)
Просмотрите детали storage volume и обратите внимание, что это ещё не volume по умолчанию, и что он настроен на использование вашего bucket:
DESC STORAGE VOLUME s3_volume\G
Some of the SQL in this document, and many other documents in the Selena documentation, and with \G instead
of a semicolon. The \G causes the mysql CLI to render the query results vertically.
Many SQL clients do not interpret vertical formatting output, so you should replace \G with ;.
*************************** 1. row ***************************
Name: s3_volume
Type: S3
IsDefault: false
Location: s3://my-selena-bucket/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_web_identity_token_file":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.02 sec)
Установка storage volume по умолчанию
SET s3_volume AS DEFAULT STORAGE VOLUME;
DESC STORAGE VOLUME s3_volume\G
*************************** 1. row ***************************
Name: s3_volume
Type: S3
IsDefault: true
Location: s3://my-selena-bucket/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_web_identity_token_file":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.02 sec)
Создание таблицы
Эти SQL-команды выполняются в вашем SQL-клиенте.
CREATE DATABASE IF NOT EXISTS quickstart;
Убедитесь, что база данных quickstart использует storage volume s3_volume:
SHOW CREATE DATABASE quickstart \G
*************************** 1. row ***************************
Database: quickstart
Create Database: CREATE DATABASE `quickstart`
PROPERTIES ("storage_volume" = "s3_volume")
USE quickstart;
CREATE TABLE site_clicks (
`uid` bigint NOT NULL COMMENT "uid",
`site` string NOT NULL COMMENT "site url",
`vtime` bigint NOT NULL COMMENT "vtime"
)
DISTRIBUTED BY HASH(`uid`)
PROPERTIES("replication_num"="1");
Откройте Redpanda Console
Пока нет topics, topic будет создан на следующем шаге.
http://localhost:8080/overview
Публикация данных в Redpanda topic
Из командной оболочки в папке routineload/ выполните эту команду для генерации данных:
python gen.py 5
В вашей системе вам может потребоваться использовать python3 вместо python в команде.
Если у вас отсутствует kafka-python, попробуйте:
pip install kafka-python
or
pip3 install kafka-python
b'{ "uid": 6926, "site": "https://docs.selena.io/", "vtime": 1718034793 } '
b'{ "uid": 3303, "site": "https://www.selena.io/product/community", "vtime": 1718034793 } '
b'{ "uid": 227, "site": "https://docs.selena.io/", "vtime": 1718034243 } '
b'{ "uid": 7273, "site": "https://docs.selena.io/", "vtime": 1718034794 } '
b'{ "uid": 4666, "site": "https://www.selena.io/", "vtime": 1718034794 } '
Проверка в Redpanda Console
Перейдите к http://localhost:8080/topics in the Redpanda Console, и вы увидите один topic с именем test2. Выберите этот topic, а затем вкладку Messages и вы увидите пять сообщений, соответствующих выводу gen.py.
Обработка сообщений
В Selena вы создадите задачу Routine Load для:
- Обработать сообщения из Redpanda topic
test2 - Загрузить эти сообщения в таблицу
site_clicks
Selena настроена на использование MinIO для хранения, поэтому данные, вставленные в таблицу site_clicks, будут храниться в MinIO.
Создание задачи Routine Load
Выполните эту команду в SQL-клиенте для создания задачи Routine Load, команда будет подробно объяснена в конце лабораторной работы.
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
PROPERTIES
(
"format" = "JSON",
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "redpanda:29092",
"kafka_topic" = "test2",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
);
Проверка задачи Routine Load
SHOW ROUTINE LOAD\G
Проверьте три выделенные строки:
- Состояние должно быть
RUNNING - Topic должен быть
test2а broker должен бытьredpanda:2092 - Статистика должна показывать 0 или 5 загруженных строк в зависимости от того, как скоро вы выполнили команду
SHOW ROUTINE LOAD. Если загружено 0 строк, выполните команду снова.
*************************** 1. row ***************************
Id: 10078
Name: clicks
CreateTime: 2024-06-12 15:51:12
PauseTime: NULL
EndTime: NULL
DbName: quickstart
TableName: site_clicks
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"*","maxBatchIntervalS":"10","partial_update_mode":"null","whereExpr":"*","dataFormat":"json","timezone":"Etc/UTC","format":"json","log_rejected_record_num":"0","taskTimeoutSecond":"60","json_root":"","maxFilterRatio":"1.0","strict_mode":"false","jsonpaths":"[\"$.uid\",\"$.site\",\"$.vtime\"]","taskConsumeSecond":"15","desireTaskConcurrentNum":"5","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"test2","currentKafkaPartitions":"0","brokerList":"redpanda:29092"}
CustomProperties: {"group.id":"clicks_ea38a713-5a0f-4abe-9b11-ff4a241ccbbd"}
Statistic: {"receivedBytes":0,"errorRows":0,"committedTaskNum":0,"loadedRows":0,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":0,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":1}
Progress: {"0":"OFFSET_ZERO"}
TimestampProgress: {}
ReasonOfStateChanged:
ErrorLogUrls:
TrackingSQL:
OtherMsg:
LatestSourcePosition: {}
1 row in set (0.00 sec)
SHOW ROUTINE LOAD\G
*************************** 1. row ***************************
Id: 10076
Name: clicks
CreateTime: 2024-06-12 18:40:53
PauseTime: NULL
EndTime: NULL
DbName: quickstart
TableName: site_clicks
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"*","maxBatchIntervalS":"10","partial_update_mode":"null","whereExpr":"*","dataFormat":"json","timezone":"Etc/UTC","format":"json","log_rejected_record_num":"0","taskTimeoutSecond":"60","json_root":"","maxFilterRatio":"1.0","strict_mode":"false","jsonpaths":"[\"$.uid\",\"$.site\",\"$.vtime\"]","taskConsumeSecond":"15","desireTaskConcurrentNum":"5","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"test2","currentKafkaPartitions":"0","brokerList":"redpanda:29092"}
CustomProperties: {"group.id":"clicks_a9426fee-45bb-403a-a1a3-b3bc6c7aa685"}
Statistic: {"receivedBytes":372,"errorRows":0,"committedTaskNum":1,"loadedRows":5,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":5,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":519}
Progress: {"0":"4"}
TimestampProgress: {"0":"1718217035111"}
ReasonOfStateChanged:
ErrorLogUrls:
TrackingSQL:
OtherMsg:
LatestSourcePosition: {"0":"5"}
1 row in set (0.00 sec)
Проверка хранения данных в MinIO
Откройте MinIO http://localhost:9001/browser/ и убедитесь, что под my-selena-bucket хранятся объекты.
Запрос данных из Selena
USE quickstart;
SELECT * FROM site_clicks;
+------+--------------------------------------------+------------+
| uid | site | vtime |
+------+--------------------------------------------+------------+
| 4607 | https://www.selena.io/blog | 1718031441 |
| 1575 | https://www.selena.io/ | 1718031523 |
| 2398 | https://docs.selena.io/ | 1718033630 |
| 3741 | https://www.selena.io/product/community | 1718030845 |
| 4792 | https://www.selena.io/ | 1718033413 |
+------+--------------------------------------------+------------+
5 rows in set (0.07 sec)
Публикация дополнительных данных
Повторный запуск gen.py опубликует ещё пять записей в Redpanda.
python gen.py 5
Проверка добавления данных
Поскольку задача Routine Load выполняется по расписанию (каждые 10 секунд по умолчанию), данные будут загружены в течение нескольких секунд.
SELECT * FROM site_clicks;
+------+--------------------------------------------+------------+
| uid | site | vtime |
+------+--------------------------------------------+------------+
| 6648 | https://www.selena.io/blog | 1718205970 |
| 7914 | https://www.selena.io/ | 1718206760 |
| 9854 | https://www.selena.io/blog | 1718205676 |
| 1186 | https://www.selena.io/ | 1718209083 |
| 3305 | https://docs.selena.io/ | 1718209083 |
| 2288 | https://www.selena.io/blog | 1718206759 |
| 7879 | https://www.selena.io/product/community | 1718204280 |
| 2666 | https://www.selena.io/ | 1718208842 |
| 5801 | https://www.selena.io/ | 1718208783 |
| 8409 | https://www.selena.io/ | 1718206889 |
+------+--------------------------------------------+------------+
10 rows in set (0.02 sec)
Детали конфигурации
Теперь, когда вы познакомились с использованием Selena с shared-data, важно понять конфигурацию.
Конфигурация CN
Конфигурация CN, используемая здесь, является конфигурацией по умолчанию, поскольку CN предназначен для использования shared-data. Конфигурация по умолчанию показана ниже. Вам не нужно вносить какие-либо изменения.
sys_log_level = INFO
# ports for admin, web, heartbeat service
be_port = 9060
be_http_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
starlet_port = 9070
Конфигурация FE
Конфигурация FE немного отличается от конфигурации по умолчанию, поскольку FE должен быть настроен на ожидание того, что данные хранятся в Object Storage, а не на локальных дисках на BE-узлах.
Файл docker-compose.yml генерирует конфигурацию FE в command.
# enable shared data, set storage type, set endpoint
run_mode = shared_data
cloud_native_storage_type = S3
Этот файл конфигурации не содержит записей по умолчанию для FE, показана только конфигурация shared-data.
Настройки конфигурации FE, отличные от настроек по умолчанию:
Многие параметры конфигурации имеют префикс s3_. Этот префикс используется для всех Amazon S3-совместимых типов хранилищ (например: S3, GCS и MinIO). При использовании Azure Blob Storage префикс — azure_.
run_mode=shared_data
Это включает использование shared-data.
cloud_native_storage_type=S3
Это указывает, используется ли S3-совместимое хранилище или Azure Blob Storage. Для MinIO это всегда S3.
Детали CREATE storage volume
CREATE STORAGE VOLUME s3_volume
TYPE = S3
LOCATIONS = ("s3://my-selena-bucket/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "minio:9000",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_instance_profile" = "false",
"aws.s3.use_aws_sdk_default_behavior" = "false"
);
aws_s3_endpoint=minio:9000
Endpoint MinIO, включая номер порта.
aws_s3_path=selena
Имя bucket.
aws_s3_access_key=AAAAAAAAAAAAAAAAAAAA
Access key MinIO.
aws_s3_secret_key=BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
Секрет access key MinIO.
aws_s3_use_instance_profile=false
При использовании MinIO используется access key, поэтому instance profiles не используются с MinIO.
aws_s3_use_aws_sdk_default_behavior=false
При использовании MinIO этот параметр всегда установлен в false.
Примечания к команде Routine Load
Selena Routine Load принимает множество аргументов. Здесь описаны �только те, которые используются в этом руководстве, остальные будут приведены в разделе дополнительной информации.
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
PROPERTIES
(
"format" = "JSON",
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "redpanda:29092",
"kafka_topic" = "test2",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
);
Параметры
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
Параметры для CREATE ROUTINE LOAD ON are:
- database_name.job_name
- table_name
database_name не обязателен. В этой лабораторной работе это quickstart и указан.
job_name обязателен, and is clicks
table_name обязателен, and is site_clicks
Свойства задачи
Свойство format
"format" = "JSON",
В данном случае, данные в формате JSON, поэтому свойство установлено в JSON. Другие допустимые форматы: CSV, JSON, and Avro. CSV по умолчанию.
Свойство jsonpaths
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
Имена полей, которые вы хотите загрузить из данных в формате JSON. Значение этого параметра — допустимое выражение JsonPath. Дополнительная информация доступна в конце этой страницы.
Свойства источника данных
kafka_broker_list
"kafka_broker_list" = "redpanda:29092",
Информация о подключении broker Kafka. Формат — <kafka_broker_name_or_ip>:<broker_ port>. Несколько brokers разделяются запятыми.
kafka_topic
"kafka_topic" = "test2",
Kafka topic для потребления.
kafka_partitions and kafka_offsets
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
Эти свойства представлены вместе, поскольку для каждой записи kafka_partitions требуется один kafka_offset.
kafka_partitions — это список одной или нескольких partitions для обработки. Если это свойство не установлено, обрабатываются все partitions.
kafka_offsets — это список offsets, по одному для каждой partition, указанной в kafka_partitions. В данном случае the value is OFFSET_BEGINNING which causes all of the data to be consumed. По умолчанию обрабатываются только новые данные.
Резюме
В этом руководстве вы:
- Развернули Selena, Redpanda и MinIO в Docker
- Создали задачу Routine Load для обработки данных из Kafka topic
- Узнали, как настроить Selena Storage Volume, использующий MinIO
Дополнительная информация
Образец, используемый для этой лабораторной работы, очень простой. Routine Load имеет гораздо больше опций и возможностей. узнать больше.