Разделение хранения и вычислений
В системах, разделяющих хранение и вычисления, данные хранятся в недорогих надёжных удалённых системах хранения, таких как Amazon S3, Google Cloud Storage, Azure Blob Storage и других S3-совместимых хранилищах, таких как MinIO. Горячие данные кэшируются локально, и при попадании в кэш производительность запросов сопоставима с архитектурой со связанным хранилищем и вычислениями. Compute nodes (CN) можно добавлять или удалять по требованию за секунды. Эта архитектура снижает затраты на хранение, обеспечивает лучшую изоляцию ресурсов и обеспечивает эластичность и масштабируемость.
Это руководство охватывает:
- Запуск Selena в Docker-контейнерах
- Использование MinIO для Object Storage
- Настройку Selena для shared-data
- Загрузку �двух публичных наборов данных
- Анализ данных с помощью SELECT и JOIN
- Базовую трансформацию данных (буква T в ETL)
Данные предоставлены NYC OpenData и National Centers for Environmental Information при NOAA.
Оба этих набора данных очень большие, и поскольку это руководство предназначено для того, чтобы помочь вам познакомиться с работой с Selena, мы не будем загружать данные за последние 120 лет. Вы можете запустить Docker-образ и загрузить эти данные на машине с 4 GB RAM, выделенными Docker. Для более крупных отказоустойчивых и масштабируемых развёртываний у нас есть другая документация, которая будет предоставлена позже.
В этом документе много информации, и она представлена с пошаговым содержанием в начале и техническими деталями в конце. Это сделано для достижения следующих целей в таком порядке:
- Позволить читателю загружать данные в развёртывание shared-data и анализировать эти данные.
- Предоставить детали конфигурации для развёртываний shared-data.
- Объяснить основы трансформации данных во время загрузки.
Предварительные требования
Docker
- Docker
- 4 GB RAM assigned to Docker
- 10 GB свободного дискового пространства, выделенного Docker
SQL-клиент
Вы можете использовать SQL-клиент, предоставляемый в окружении Docker, или использовать клиент в вашей системе. Многие MySQL-совместимые клиенты будут работать, и это руководство охватывает настройку DBeaver и MySQL Workbench.
curl
curl используется для выполнения задачи загрузки данных в Selena и для загрузки наборов данных. Проверьте, установлен ли он, запустив curl или curl.exe в командной строке вашей ОС. Если curl не установле�н, получите curl здесь.
/etc/hosts
Метод загрузки, используемый в этом руководстве, — Stream Load. Stream Load подключается к сервису FE для запуска задачи загрузки. Затем FE назначает задачу backend-узлу — CN в этом руководстве. Чтобы задача загрузки могла подключиться к CN, имя CN должно быть доступно вашей операционной системе. Add this line to /etc/hosts:
127.0.0.1 selena-cn
Терминология
FE
Frontend-узлы отвечают за управлен�ие метаданными, управление клиентскими подключениями, планирование запросов и диспетчеризацию запросов. Каждый FE хранит и поддерживает полную копию метаданных в своей памяти, что гарантирует равнозначные сервисы между FE.
CN
Compute Nodes отвечают за выполнение планов запросов в развёртываниях shared-data.
BE
Backend-узлы отвечают как за хранение данных, так и за выполнение планов запросов в развёртываниях shared-nothing.
Это руководство не использует BE, эта ин�формация включена здесь, чтобы вы понимали разницу между BE и CN.
Редактирование файла hosts
Метод загрузки, используемый в этом руководстве, — Stream Load. Stream Load подключается к сервису FE для запуска задачи загрузки. Затем FE назначает задачу backend-узлу — CN в этом руководстве. Чтобы задача загрузки могла подключиться к CN, имя CN должно быть доступно вашей операционной системе. Add this line to /etc/hosts:
127.0.0.1 selena-cn
Загрузка файлов лабораторной работы
Нужно загрузить три файла:
- Файл Docker Compose, который развёртывает окружение Selena и MinIO
- Данные о ДТП в Нью-Йорке
- Данные о погоде
Это руководство использует MinIO, который является S3-совместимым Object Storage, предоставляемым под лицензией GNU Affero General Public License.
Создание каталога для хранения файлов лабораторной работы
mkdir quickstart
cd quickstart
Загрузка файла Docker Compose
curl -O https://raw.githubusercontent.com/Selena/demo/master/documentation-samples/quickstart/docker-compose.yml
Загрузка данных
Загрузите эти два набора данных:
Данные о ДТП в Нью-Йорке
curl -O https://raw.githubusercontent.com/Selena/demo/master/documentation-samples/quickstart/datasets/NYPD_Crash_Data.csv
Данные о погоде
curl -O https://raw.githubusercontent.com/Selena/demo/master/documentation-samples/quickstart/datasets/72505394728.csv
Развёртывание Selena и MinIO
docker compose up --detach --wait --wait-timeout 120
Для того чтобы сервисы FE, CN и MinIO стали healthy, потребуется около 30 секунд. Контейнер quickstart-minio_mc-1 покажет статус Waiting, а также код выхода. Код выхода 0 указывает на успех.
[+] Running 4/5
✔ Network quickstart_default Created 0.0s
✔ Container minio Healthy 6.8s
✔ Container selena-fe Healthy 29.3s
⠼ Container quickstart-minio_mc-1 Waiting 29.3s
✔ Container selena-cn Healthy 29.2s
container quickstart-minio_mc-1 exited (0)
MinIO
Это краткое руководство использует MinIO для shared storage.
Проверка учётных данных MinIO
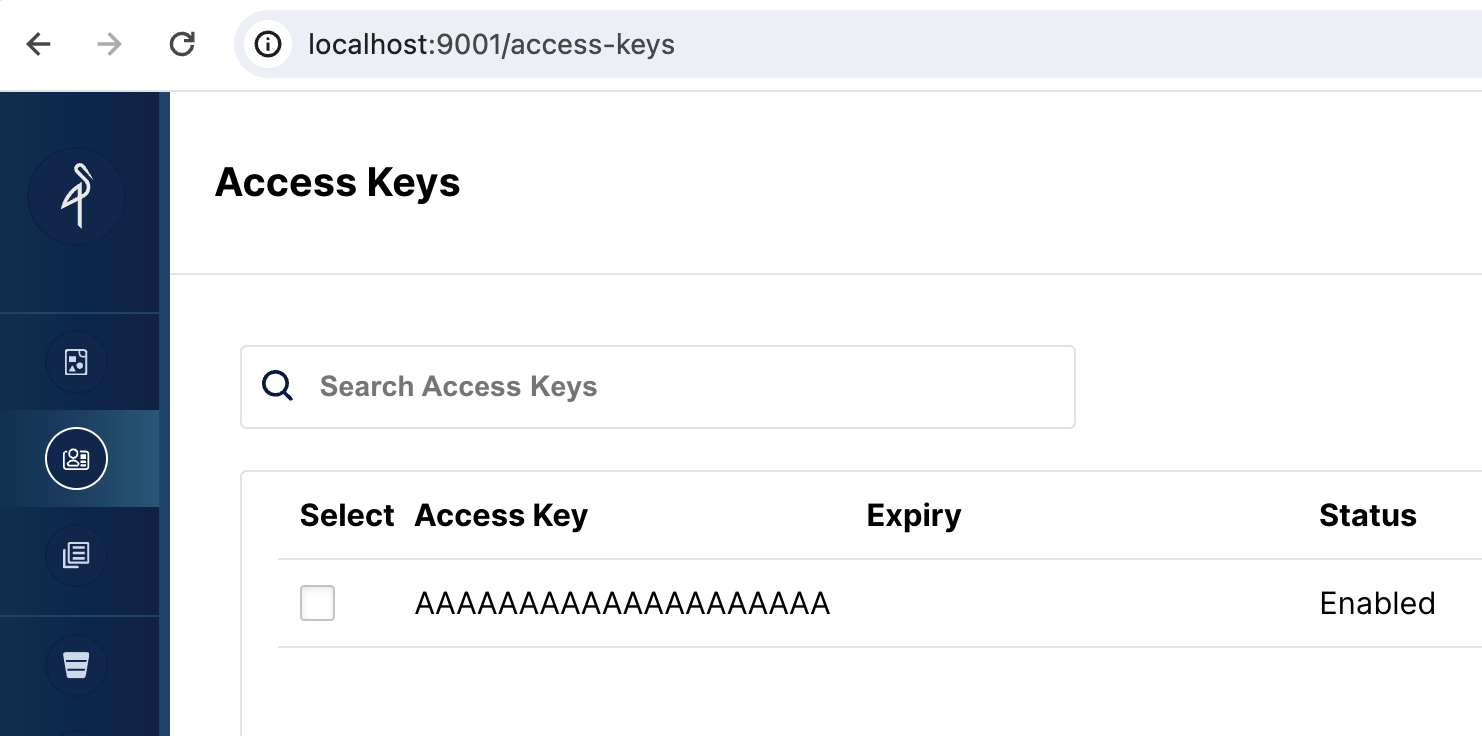
Чтобы использовать MinIO для Object Storage с Selena, Selena нужен access key MinIO. Access key был сгенерирован во время запуска сервисов Docker. Чтобы лучше понять, как Selena подключается к MinIO, вы должны проверить, что ключ существует.
Browse to http://localhost:9001/access-keys Имя пользователя и пароль указаны в файле Docker compose и являются miniouser и miniopassword. Вы должны увидеть один access key. Ключ — AAAAAAAAAAAAAAAAAAAA, вы не можете увидеть секрет в MinIO Console, но он находится в файле Docker compose и является BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB:
Если в веб-интерфейсе MinIO не отображаются access keys, проверьте логи сервиса minio_mc:
docker compose logs minio_mc
Попробуйте перезапустить pod minio_mc:
docker compose run minio_mc
Создание bucket для ваших данных
Когда вы создаёте storage volume в Selena, вы укажете LOCATION для данных:
LOCATIONS = ("s3://my-selena-bucket/")
Open http://localhost:9001/buckets и добавьте bucket для storage volume. Назовите bucket my-selena-bucket. Примите значения по умолчанию для трёх перечисленных опций.
SQL-клиенты
С этим руководством протестированы три клиента, вам нужен только один:
- mysql CLI: Вы можете запустить его из среды Docker или с вашей машины.
- DBeaver доступен в версии Community и Pro.
- MySQL Workbench
Настройка клиента
- mysql CLI
- DBeaver
- MySQL Workbench
Самый простой способ использовать mysql CLI — запустить его из контейнера Selena selena-fe:
docker compose exec selena-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="Selena > "
Все команды docker compose должны выполняться из каталога, содержащего файл docker-compose.yml.
Если вы хотите установить mysql CLI, разверните установка mysql клиента ниже:
установка mysql клиента
- macOS: Если вы используете Homebrew и вам не нужен MySQL Server, выполните
brew install mysql-client@8.0для установки CLI. - Linux: Проверьте вашу систему репозиториев для клиента
mysql. Например,yum install mariadb. - Microsoft Windows: Установите MySQL Community Server и запустите предоставленный клиент, или запустите
mysqlиз WSL.
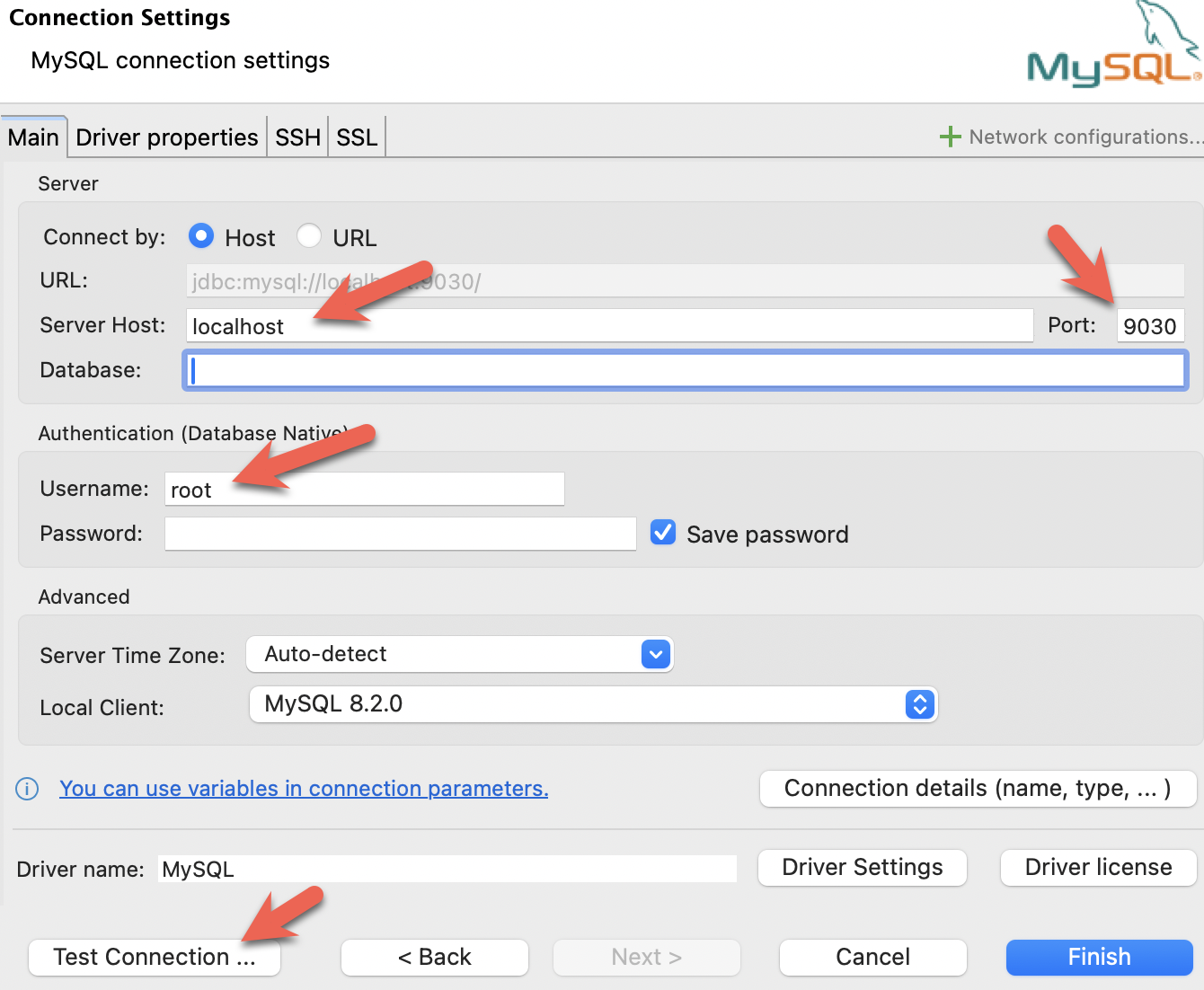
- Установите DBeaver и добавьте подключение:

- Настройте порт, IP и имя пользователя. Проверьте подключение и нажмите Finish, если тест прошёл успешно:
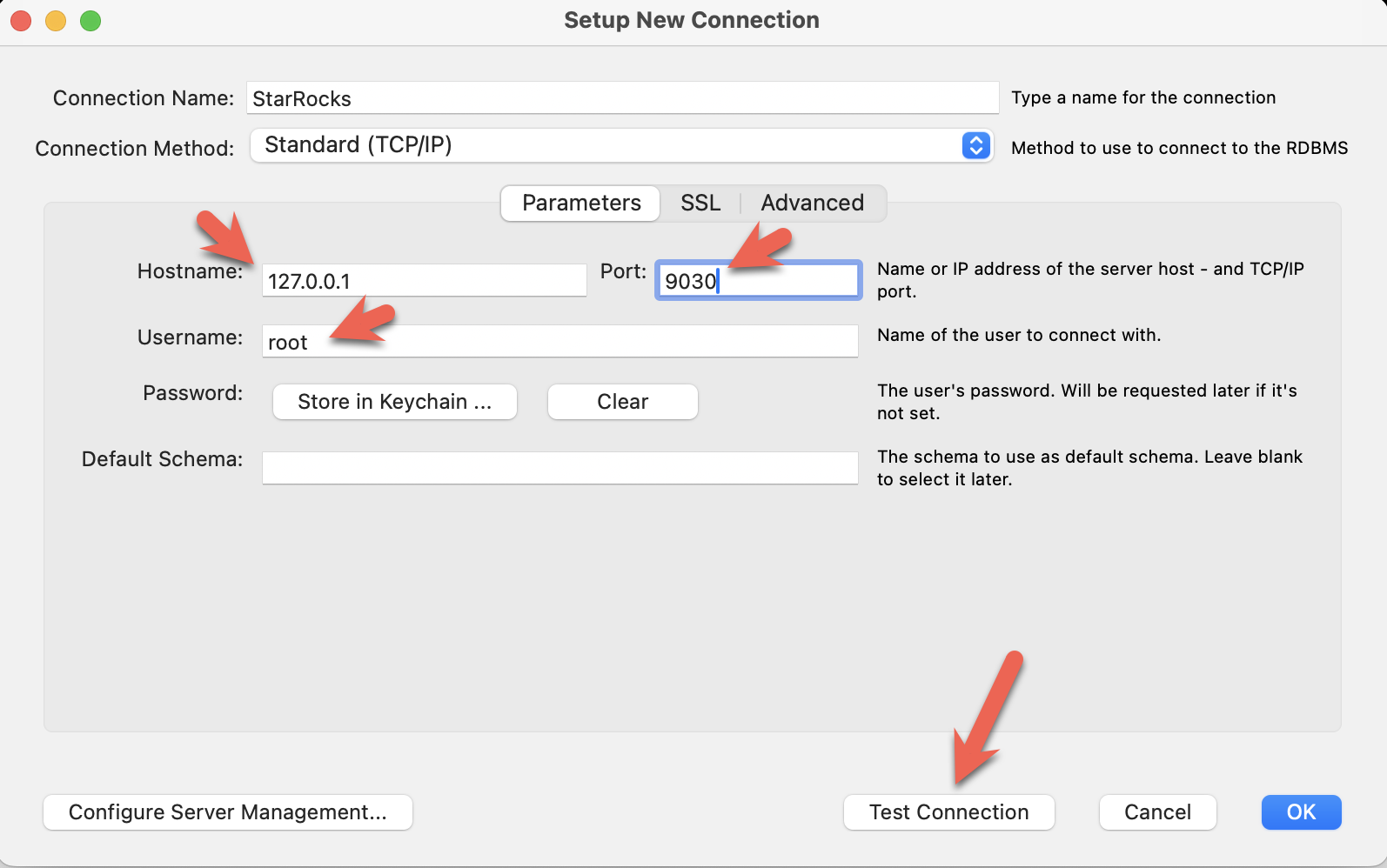
- Установите MySQL Workbench и добавьте подключение.
- Настройте порт, IP и имя пользователя, затем проверьте подключение:
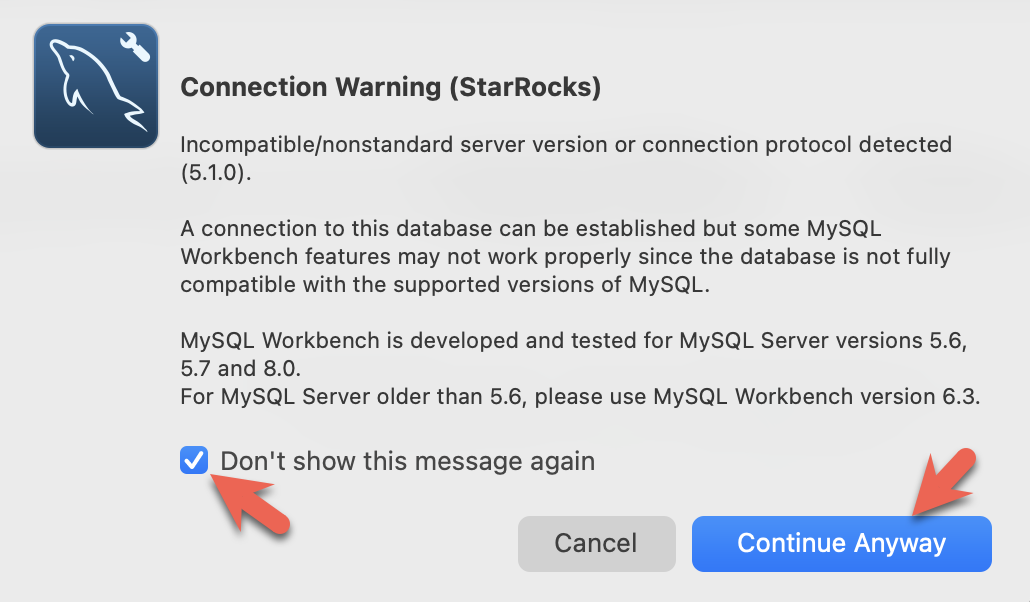
- Вы увидите предупреждения от Workbench, так как он проверяет конкретную версию MySQL. Вы можете игнорировать предупреждения, и при появлении запроса можете настроить Workbench на прекращение отображения предупреждений:
Конфигурация Selena для shared-data
На данный момент у вас запущена Selena и запущен MinIO. Access key MinIO используется для подключения Selena и MinIO.
Это часть конфигурации FE, которая указывает, что развёртывание Selena будет использовать shared data. Это было добавлено в файл fe.conf при создании развёртывания Docker Compose.
# enable the shared data run mode
run_mode = shared_data
cloud_native_storage_type = S3
Вы можете проверить эти настройки, выполнив эту команду из каталога quickstart и посмотрев в конец файла:
docker compose exec selena-fe \
cat /opt/selena/fe/conf/fe.conf
:::
Подключение к Selena с помощью SQL-клиента
Выполните эту команду из каталога, содержащего файл docker-compose.yml.
Если вы используете клиент, отличный от MySQL Command-Line Client, откройте его сейчас.
docker compose exec selena-fe \
mysql -P9030 -h127.0.0.1 -uroot --prompt="Selena > "
Проверка storage volumes
SHOW STORAGE VOLUMES;
Не должно быть storage volumes, вы создадите один далее.
Empty set (0.04 sec)
Создание shared-data storage volume
Ранее вы создали bucket в MinIO с именем my-selena-volume, и вы проверили, что MinIO имеет access key с именем AAAAAAAAAAAAAAAAAAAA. Следующий SQL создаст storage volume в bucket MinIO, используя access key и секрет.
CREATE STORAGE VOLUME s3_volume
TYPE = S3
LOCATIONS = ("s3://my-selena-bucket/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "minio:9000",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_instance_profile" = "false",
"aws.s3.use_aws_sdk_default_behavior" = "false"
);
Теперь вы должны увидеть перечисленный storage volume, ранее был пустой набор:
SHOW STORAGE VOLUMES;
+----------------+
| Storage Volume |
+----------------+
| s3_volume |
+----------------+
1 row in set (0.02 sec)
Просмотрите детали storage volume и обратите внимание, что это ещё не volume по умолчанию, и что он на�строен на использование вашего bucket:
DESC STORAGE VOLUME s3_volume\G
Some of the SQL in this document, and many other documents in the Selena documentation, and with \G instead
of a semicolon. The \G causes the mysql CLI to render the query results vertically.
Many SQL clients do not interpret vertical formatting output, so you should replace \G with ;.
*************************** 1. row ***************************
Name: s3_volume
Type: S3
IsDefault: false
Location: s3://my-selena-bucket/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_web_identity_token_file":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.02 sec)
Установка storage volume по умолчанию
SET s3_volume AS DEFAULT STORAGE VOLUME;
DESC STORAGE VOLUME s3_volume\G
*************************** 1. row ***************************
Name: s3_volume
Type: S3
IsDefault: true
Location: s3://my-selena-bucket/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_web_identity_token_file":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.02 sec)
Создание базы данных
CREATE DATABASE IF NOT EXISTS quickstart;
Убедитесь, что база данных quickstart использует storage volume s3_volume:
SHOW CREATE DATABASE quickstart \G
*************************** 1. row ***************************
Database: quickstart
Create Database: CREATE DATABASE `quickstart`
PROPERTIES ("storage_volume" = "s3_volume")
Создание та�блиц
Создание базы данных
Введите эти две строки в приглашении Selena > и нажмите Enter после каждой:
CREATE DATABASE IF NOT EXISTS quickstart;
USE quickstart;
Создание двух таблиц
Crashdata
Набор данных об авариях содержит гораздо больше полей, чем представлено здесь; схема была сокращена, чтобы включить только поля, которые могут быть полезны для ответа на вопросы о влиянии погоды на условия вождения.
CREATE TABLE IF NOT EXISTS crashdata (
CRASH_DATE DATETIME,
BOROUGH STRING,
ZIP_CODE STRING,
LATITUDE INT,
LONGITUDE INT,
LOCATION STRING,
ON_STREET_NAME STRING,
CROSS_STREET_NAME STRING,
OFF_STREET_NAME STRING,
CONTRIBUTING_FACTOR_VEHICLE_1 STRING,
CONTRIBUTING_FACTOR_VEHICLE_2 STRING,
COLLISION_ID INT,
VEHICLE_TYPE_CODE_1 STRING,
VEHICLE_TYPE_CODE_2 STRING
);
Weatherdata
Аналогично данным об авариях, набор данных о погоде содержит гораздо больше столбцов (всего 125 столбцов), и в базу данных включены только те, которые могут помочь ответить на вопросы.
CREATE TABLE IF NOT EXISTS weatherdata (
DATE DATETIME,
NAME STRING,
HourlyDewPointTemperature STRING,
HourlyDryBulbTemperature STRING,
HourlyPrecipitation STRING,
HourlyPresentWeatherType STRING,
HourlyPressureChange STRING,
HourlyPressureTendency STRING,
HourlyRelativeHumidity STRING,
HourlySkyConditions STRING,
HourlyVisibility STRING,
HourlyWetBulbTemperature STRING,
HourlyWindDirection STRING,
HourlyWindGustSpeed STRING,
HourlyWindSpeed STRING
);
Загрузка двух наборов данных
Существует множество способов загрузки данных в Selena. Для этого руководства самый простой способ — использовать curl и Selena Stream Load.
Выполните эти команды curl из каталога, в который вы загрузили набор данных.
Вам будет предложено ввести пароль. Вы, вероятно, не назначили пароль пользова�телю MySQL root, поэтому просто нажмите Enter.
Команды curl выглядят сложными, но они подробно объясняются в конце руководства. Сейчас мы рекомендуем выполнить команды и выполнить некоторые SQL для анализа данных, а затем прочитать о деталях загрузки данных в конце.
Данные о столкновениях в Нью-Йорке - ДТП
curl --location-trusted -u root \
-T ./NYPD_Crash_Data.csv \
-H "label:crashdata-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i'),BOROUGH,ZIP_CODE,LATITUDE,LONGITUDE,LOCATION,ON_STREET_NAME,CROSS_STREET_NAME,OFF_STREET_NAME,NUMBER_OF_PERSONS_INJURED,NUMBER_OF_PERSONS_KILLED,NUMBER_OF_PEDESTRIANS_INJURED,NUMBER_OF_PEDESTRIANS_KILLED,NUMBER_OF_CYCLIST_INJURED,NUMBER_OF_CYCLIST_KILLED,NUMBER_OF_MOTORIST_INJURED,NUMBER_OF_MOTORIST_KILLED,CONTRIBUTING_FACTOR_VEHICLE_1,CONTRIBUTING_FACTOR_VEHICLE_2,CONTRIBUTING_FACTOR_VEHICLE_3,CONTRIBUTING_FACTOR_VEHICLE_4,CONTRIBUTING_FACTOR_VEHICLE_5,COLLISION_ID,VEHICLE_TYPE_CODE_1,VEHICLE_TYPE_CODE_2,VEHICLE_TYPE_CODE_3,VEHICLE_TYPE_CODE_4,VEHICLE_TYPE_CODE_5" \
-XPUT http://localhost:8030/api/quickstart/crashdata/_stream_load
Вот вывод приведённой выше команды. Первый выделенный раздел показывает, что вы должны ожидать увидеть (OK и все строки, кроме одной, вставлены). Одна строка была отфильтрована, потому что она не содержит правильного количества столбцов.
Enter host password for user 'root':
{
"TxnId": 2,
"Label": "crashdata-0",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 423726,
"NumberLoadedRows": 423725,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 96227746,
"LoadTimeMs": 1013,
"BeginTxnTimeMs": 21,
"StreamLoadPlanTimeMs": 63,
"ReadDataTimeMs": 563,
"WriteDataTimeMs": 870,
"CommitAndPublishTimeMs": 57,
"ErrorURL": "http://selena-cn:8040/api/_load_error_log?file=error_log_da41dd88276a7bfc_739087c94262ae9f"
}%
Если произошла ошибка, вывод предоставляет URL для просмотра сообщений об ошибках. Сообщение об ошибке также содержит backend-узел, которому была назначена задача Stream Load (selena-cn). Поскольку вы добавили запись для selena-cn в файл /etc/hosts, вы должны быть в состоянии перейти к нему и прочитать сообщение об ошибке.
Разверните резюме для содержимого, увиденного при разработке этого руководства:
Чтение сообщений об ошибках в браузере
Error: Value count does not match column count. Expect 29, but got 32.
Column delimiter: 44,Row delimiter: 10.. Row: 09/06/2015,14:15,,,40.6722269,-74.0110059,"(40.6722269, -74.0110059)",,,"R/O 1 BEARD ST. ( IKEA'S
09/14/2015,5:30,BRONX,10473,40.814551,-73.8490955,"(40.814551, -73.8490955)",TORRY AVENUE ,NORTON AVENUE ,,0,0,0,0,0,0,0,0,Driver Inattention/Distraction,Unspecified,,,,3297457,PASSENGER VEHICLE,PASSENGER VEHICLE,,,
Данные о погоде
Загрузите набор данных о погоде таким же образом, как вы загрузили данные о ДТП.
curl --location-trusted -u root \
-T ./72505394728.csv \
-H "label:weather-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns: STATION, DATE, LATITUDE, LONGITUDE, ELEVATION, NAME, REPORT_TYPE, SOURCE, HourlyAltimeterSetting, HourlyDewPointTemperature, HourlyDryBulbTemperature, HourlyPrecipitation, HourlyPresentWeatherType, HourlyPressureChange, HourlyPressureTendency, HourlyRelativeHumidity, HourlySkyConditions, HourlySeaLevelPressure, HourlyStationPressure, HourlyVisibility, HourlyWetBulbTemperature, HourlyWindDirection, HourlyWindGustSpeed, HourlyWindSpeed, Sunrise, Sunset, DailyAverageDewPointTemperature, DailyAverageDryBulbTemperature, DailyAverageRelativeHumidity, DailyAverageSeaLevelPressure, DailyAverageStationPressure, DailyAverageWetBulbTemperature, DailyAverageWindSpeed, DailyCoolingDegreeDays, DailyDepartureFromNormalAverageTemperature, DailyHeatingDegreeDays, DailyMaximumDryBulbTemperature, DailyMinimumDryBulbTemperature, DailyPeakWindDirection, DailyPeakWindSpeed, DailyPrecipitation, DailySnowDepth, DailySnowfall, DailySustainedWindDirection, DailySustainedWindSpeed, DailyWeather, MonthlyAverageRH, MonthlyDaysWithGT001Precip, MonthlyDaysWithGT010Precip, MonthlyDaysWithGT32Temp, MonthlyDaysWithGT90Temp, MonthlyDaysWithLT0Temp, MonthlyDaysWithLT32Temp, MonthlyDepartureFromNormalAverageTemperature, MonthlyDepartureFromNormalCoolingDegreeDays, MonthlyDepartureFromNormalHeatingDegreeDays, MonthlyDepartureFromNormalMaximumTemperature, MonthlyDepartureFromNormalMinimumTemperature, MonthlyDepartureFromNormalPrecipitation, MonthlyDewpointTemperature, MonthlyGreatestPrecip, MonthlyGreatestPrecipDate, MonthlyGreatestSnowDepth, MonthlyGreatestSnowDepthDate, MonthlyGreatestSnowfall, MonthlyGreatestSnowfallDate, MonthlyMaxSeaLevelPressureValue, MonthlyMaxSeaLevelPressureValueDate, MonthlyMaxSeaLevelPressureValueTime, MonthlyMaximumTemperature, MonthlyMeanTemperature, MonthlyMinSeaLevelPressureValue, MonthlyMinSeaLevelPressureValueDate, MonthlyMinSeaLevelPressureValueTime, MonthlyMinimumTemperature, MonthlySeaLevelPressure, MonthlyStationPressure, MonthlyTotalLiquidPrecipitation, MonthlyTotalSnowfall, MonthlyWetBulb, AWND, CDSD, CLDD, DSNW, HDSD, HTDD, NormalsCoolingDegreeDay, NormalsHeatingDegreeDay, ShortDurationEndDate005, ShortDurationEndDate010, ShortDurationEndDate015, ShortDurationEndDate020, ShortDurationEndDate030, ShortDurationEndDate045, ShortDurationEndDate060, ShortDurationEndDate080, ShortDurationEndDate100, ShortDurationEndDate120, ShortDurationEndDate150, ShortDurationEndDate180, ShortDurationPrecipitationValue005, ShortDurationPrecipitationValue010, ShortDurationPrecipitationValue015, ShortDurationPrecipitationValue020, ShortDurationPrecipitationValue030, ShortDurationPrecipitationValue045, ShortDurationPrecipitationValue060, ShortDurationPrecipitationValue080, ShortDurationPrecipitationValue100, ShortDurationPrecipitationValue120, ShortDurationPrecipitationValue150, ShortDurationPrecipitationValue180, REM, BackupDirection, BackupDistance, BackupDistanceUnit, BackupElements, BackupElevation, BackupEquipment, BackupLatitude, BackupLongitude, BackupName, WindEquipmentChangeDate" \
-XPUT http://localhost:8030/api/quickstart/weatherdata/_stream_load
Проверка хранения данных в MinIO
Open MinIO http://localhost:9001/browser/my-selena-bucket и убедитесь, что у вас есть записи под my-selena-bucket/
Имена папок под my-selena-bucket/ генерируются при загрузке данн�ых. Вы должны увидеть один каталог под my-selena-bucket, а затем ещё два под ним. В этих каталогах вы найдёте записи данных, метаданных или схемы.
Ответы на некоторые вопросы
Эти запросы можно выполнить в вашем SQL-клиенте. Все запросы используют базу данных quickstart.
USE quickstart;
Сколько аварий происходит в час в Нью-Йорке?
SELECT COUNT(*),
date_trunc("hour", crashdata.CRASH_DATE) AS Time
FROM crashdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 200;
Вот часть вывода. Обратите внимание, что я рассматриваю более подробно 6 и 7 января, так как это понедельник и вторник обычной рабочей недели. Анализ данных за Новый год, вероятно, не показателен для обычного утра в час пик.
| 14 | 2014-01-06 06:00:00 |
| 16 | 2014-01-06 07:00:00 |
| 43 | 2014-01-06 08:00:00 |
| 44 | 2014-01-06 09:00:00 |
| 21 | 2014-01-06 10:00:00 |
| 28 | 2014-01-06 11:00:00 |
| 34 | 2014-01-06 12:00:00 |
| 31 | 2014-01-06 13:00:00 |
| 35 | 2014-01-06 14:00:00 |
| 36 | 2014-01-06 15:00:00 |
| 33 | 2014-01-06 16:00:00 |
| 40 | 2014-01-06 17:00:00 |
| 35 | 2014-01-06 18:00:00 |
| 23 | 2014-01-06 19:00:00 |
| 16 | 2014-01-06 20:00:00 |
| 12 | 2014-01-06 21:00:00 |
| 17 | 2014-01-06 22:00:00 |
| 14 | 2014-01-06 23:00:00 |
| 10 | 2014-01-07 00:00:00 |
| 4 | 2014-01-07 01:00:00 |
| 1 | 2014-01-07 02:00:00 |
| 3 | 2014-01-07 03:00:00 |
| 2 | 2014-01-07 04:00:00 |
| 6 | 2014-01-07 06:00:00 |
| 16 | 2014-01-07 07:00:00 |
| 41 | 2014-01-07 08:00:00 |
| 37 | 2014-01-07 09:00:00 |
| 33 | 2014-01-07 10:00:00 |
Похоже, что в понедельник или вторник утром в час пик происходит около 40 аварий, и примерно столько же в 17:00.
Какова средняя температура в Нью-Йорке?
SELECT avg(HourlyDryBulbTemperature),
date_trunc("hour", weatherdata.DATE) AS Time
FROM weatherdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 100;
Вывод:
Обратите внимание, что это данные за 2014 год; в последнее время в Нью-Йорке не было так холодно.
+-------------------------------+---------------------+
| avg(HourlyDryBulbTemperature) | Time |
+-------------------------------+---------------------+
| 25 | 2014-01-01 00:00:00 |
| 25 | 2014-01-01 01:00:00 |
| 24 | 2014-01-01 02:00:00 |
| 24 | 2014-01-01 03:00:00 |
| 24 | 2014-01-01 04:00:00 |
| 24 | 2014-01-01 05:00:00 |
| 25 | 2014-01-01 06:00:00 |
| 26 | 2014-01-01 07:00:00 |
Безопасно ли ездить в Нью-Йорке при плохой видимости?
Давайте посмотрим на количество аварий при плохой вид�имости (от 0 до 1,0 мили). Чтобы ответить на этот вопрос, используем JOIN двух таблиц по столбцу DATETIME.
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyVisibility BETWEEN 0.0 AND 1.0
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
Наибольшее количество аварий за один час при низкой видимости составляет 129. Есть несколько факторов, которые следует учитывать:
- 3 февраля 2014 года был понедельник
- 8 утра — час пик
- Шёл дождь (0,12 дюйма осадков за этот час)
- Температура составляла 32 градуса по Фаренгейту (точка замерзания воды)
- Видимость была плохой — 0,25 мили, нормальная для Нью-Йорка — 10 миль
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.33 | 0.03 | 09 Jan 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
| 95 | 26 | 0.37 | 0.12 | 01 Mar 2015 15:00 |
| 93 | 35 | 0.75 | 0.09 | 18 Jan 2015 09:00 |
| 92 | 31 | 0.25 | 0.12 | 03 Feb 2014 10:00 |
| 87 | 26.8 | 0.5 | 0.09 | 01 Mar 2015 16:00 |
| 85 | 55 | 0.75 | 0.20 | 23 Dec 2015 17:00 |
| 85 | 20 | 0.62 | 0.01 | 06 Jan 2015 11:00 |
| 83 | 19.6 | 0.41 | 0.04 | 05 Mar 2015 13:00 |
| 80 | 20 | 0.37 | 0.02 | 06 Jan 2015 10:00 |
| 76 | 26.5 | 0.25 | 0.06 | 05 Mar 2015 09:00 |
| 71 | 26 | 0.25 | 0.09 | 05 Mar 2015 10:00 |
| 71 | 24.2 | 0.25 | 0.04 | 05 Mar 2015 11:00 |
А как насчёт вождения в условиях гололёда?
Водяной пар может десублимироваться в лёд при температуре 40 градусов по Фаренгейту; этот запрос рассматривает температуры от 0 до 40 градусов по Фаренгейту.
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyDryBulbTemperature BETWEEN 0.0 AND 40.5
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
Результаты для минусовых температур меня немного удивили — я не ожидал большого трафика в воскресенье утром в городе в холодный январский день. Быстрый просмотр weather.com показал, что в тот день был сильный шторм с множеством аварий, как и видно из данных.
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 192 | 34 | 1.5 | 0.09 | 18 Jan 2015 08:00 |
| 170 | 21 | NULL | | 21 Jan 2014 10:00 |
| 145 | 19 | NULL | | 21 Jan 2014 11:00 |
| 138 | 33.5 | 5 | 0.02 | 18 Jan 2015 07:00 |
| 137 | 21 | NULL | | 21 Jan 2014 09:00 |
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.7 | 0.04 | 09 Jan 2015 08:00 |
| 98 | 16 | 8 | 0.00 | 06 Mar 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
Водите осторожно!
Настройка Selena для shared-data
Теперь, когда вы познакомились с использованием Selena с shared-data, важно понять конфигурацию.
Конфигурация CN
Конфигурация CN, используемая здесь, является конфигурацией по умолчанию, поскольку CN предназначен для использования shared-data. Конфигурация по умолчанию показана ниже. Вам не нужно вносить какие-либо изменения.
sys_log_level = INFO
# ports for admin, web, heartbeat service
be_port = 9060
be_http_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
starlet_port = 9070
Конфигурация FE
Конфигурация FE немного отличается от конфигурации по умолчанию, поскольку FE должен быть настроен на ожидание того, что данные хранятся в Object Storage, а не на локальных дисках на BE-узлах.
Файл docker-compose.yml генерирует конфигурацию FE в command.
# enable shared data, set storage type, set endpoint
run_mode = shared_data
cloud_native_storage_type = S3
Этот файл конфигурации не содержит записей по умолчанию для FE, показана только конфигурация shared-data.
Настройки конфигурации FE, отличные от настроек по умолчанию:
Многие параметры конфигурации имеют префикс s3_. Этот префикс используется для всех Amazon S3-совместимых типов хранилищ (например: S3, GCS и MinIO). При использовании Azure Blob Storage префикс — azure_.
run_mode=shared_data
Это включает использование shared-data.
cloud_native_storage_type=S3
Это указывает, используется ли S3-совместимое хранилище или Azure Blob Storage. Для MinIO это всегда S3.
Детали CREATE storage volume
CREATE STORAGE VOLUME s3_volume
TYPE = S3
LOCATIONS = ("s3://my-selena-bucket/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "minio:9000",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_instance_profile" = "false",
"aws.s3.use_aws_sdk_default_behavior" = "false"
);
aws_s3_endpoint=minio:9000
Endpoint MinIO, включая номер порта.
aws_s3_path=selena
Имя bucket.
aws_s3_access_key=AAAAAAAAAAAAAAAAAAAA
Access key MinIO.
aws_s3_secret_key=BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
Секрет access key MinIO.
aws_s3_use_instance_profile=false
При использовании MinIO используется access key, поэтому instance profiles не используются с MinIO.
aws_s3_use_aws_sdk_default_behavior=false
При использовании MinIO этот параметр всегда установлен в false.
Настройка режима FQDN
Команда для запуска FE также изменена. Команда сервиса FE в файле Docker Compose имеет добавленную опцию --host_type FQDN. Установив host_type в FQDN, задача Stream Load перенаправляется на полное доменное имя CN pod, а не на IP-адрес. Это делается потому, что IP-адрес находится в диапазоне, назначенном окружению Docker, и обычно недоступен с хост-машины.
Эти три изменения позволяют трафику между сетью хоста и CN:
- установка
--host_typeвFQDN - выставление порта CN 8040 в сеть хоста
- добавление записи в файл hosts для
selena-cn, указывающей на127.0.0.1
Резюме
В этом руководстве вы:
- Развернули Selena и MinIO в Docker
- Создали access key MinIO
- Настроили Selena Storage Volume, использующий MinIO
- За�грузили данные о ДТП, предоставленные Нью-Йорком, и данные о погоде, предоставленные NOAA
- Проанализировали данные с использованием SQL JOINs, чтобы выяснить, что вождение при низкой видимости или на обледенелых улицах — плохая идея
Есть ещё что изучить; мы намеренно упустили трансформацию данных, выполненную во время Stream Load. Детали об этом приведены в примечаниях к командам curl ниже.
Примечания к командам curl
Selena Stream Load и curl принимают множество аргументов. Здесь описаны только те, которые используются в этом руководстве, остальные будут указаны в разделе дополнительной информации.
--location-trusted
Настраивает curl для передачи учётных данных на любые перенаправленные URL.
-u root
Имя пользователя для входа в Selena
-T filename
T означает transfer (передача), имя файла для передачи.
label:name-num
Метка, связанная с этим заданием Stream Load. Метка должна быть уникальной, поэтому если вы запускаете задание несколько раз, вы можете добавить номер и продолжать его увеличивать.
column_separator:,
Если вы загружаете файл, использующий одиночную ,, установите её, как показано выше; если вы используете другой разделитель, укажите его здесь. Распространённые варианты: \t, , и |.
skip_header:1
Некоторые CSV-файлы имеют одну строку заголовка со всеми именами столбцов, а некоторые добавляют вторую строку с типами данных. Установите skip_header в 1 или 2, если у вас одна или две строки заголовка, и установите в 0, если их нет.
enclose:\"
Обычно строки, содержащие встроенные запятые, заключаются в двойные кавычки. Образцы наборов данных, используемые в этом руководстве, содержат геолокации с запятыми, поэтому параметр enclose установлен в \". Не забудьте экранировать " с помощью \.
max_filter_ratio:1
Это позволяет некоторые ошибки в данных. В идеале это должно быть установлено в 0, и задание должно завершиться с ошибкой при любых ошибках. Установлено в 1, чтобы разрешить ошибки во всех строках во время отладки.
columns:
Сопоставление столбцов CSV-файла со столбцами таблицы Selena. Вы заметите, что в CSV-файлах гораздо больше столбцов, чем в таблице. Любые столбцы, не включённые в таблицу, пропускаются.
Вы также заметите, что в строке columns: для набора данных об авариях включено некоторое преобразование данных. Очень часто даты и время в CSV-файлах не соответствуют стандартам. Вот логика преобразования данных CSV для времени и даты аварии в тип DATETIME:
Строка columns
Это начало одной записи данных. Дата в формате MM/DD/YYYY, а время в формате HH:MI. Поскольку DATETIME обычно имеет формат YYYY-MM-DD HH:MI:SS, нам нужно преобразовать эти данные.
08/05/2014,9:10,BRONX,10469,40.8733019,-73.8536375,"(40.8733019, -73.8536375)",
Это начало параметра columns::
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i')
Это указывает Selena:
- Присвоить содержимое первого столбца CSV-файла переменной
tmp_CRASH_DATE - Присвоить содержимое второго столбца CSV-файла переменной
tmp_CRASH_TIME concat_ws()объединяетtmp_CRASH_DATEиtmp_CRASH_TIMEс пробелом между нимиstr_to_date()создаёт DATETIME из объединённой строки- сохранить полученный DATETIME в столбце
CRASH_DATE
Дополнительная информация
The Motor Vehicle Collisions - Crashes dataset is provided by New York City subject to these terms of use and privacy policy.
The Local Climatological Data(LCD) is provided by NOAA with this disclaimer and this privacy policy.