Обзо�р таблиц
Таблицы являются единицами хранения данных. Понимание структуры таблиц в Selena и того, как проектировать эффективную структуру таблиц, помогает оптимизировать организацию данных и повысить эффективность запросов. Кроме того, по сравнению с традиционными базами данных, Selena может хранить сложные полуструктурированные данные, такие как JSON, ARRAY, в колоночном формате для повышения производительности запросов.
Эта тема знакомит со структурой таблиц в Selena как с базовой, так и с общей точки зрения.
Начиная с версии v1.5.2, Selena поддерживает создание временных таблиц в Default Catalog.
Знакомство с базовой структурой таблиц
Как и в других реляционных базах данных, таблица логически состоит из строк и столбцов:
- Строки: Каждая строка содержит запись. Каждая строка содержит набор связанных значений данных.
- Столбцы: Столбцы определяют атрибуты для каждой записи. Каждый столбец содержит данные определенного атрибута. Например, таблица сотрудников может включать столбцы, такие как имя, ID сотрудника, отдел и зарплата, где каждый столбец хранит соответствующие данные. Данные в каждом столбце имеют одинаковый тип данных. Все строки в таблице имеют одинаковое количество столбцов.
Создать таблицу в Selena просто. Вам просто нужно определить столбцы и их типы данных в операторе CREATE TABLE, чтобы создать таблицу. Пример:
CREATE DATABASE example_db;
USE example_db;
CREATE TABLE user_access (
uid int,
name varchar(64),
age int,
phone varchar(16),
last_access datetime,
credits double
)
ORDER BY (uid, name);
Приведенный выше пример CREATE TABLE создает таблицу Duplicate Key. К столбцам в этом типе таблиц не добавляются ограничения, поэтому в таблице могут существовать дублирующиеся строки данных. Первые два столбца таблицы Duplicate Key указываются как столбцы сортировки для формирования ключа сортировки. Данные хранятся после сортировки на основе ключа сортировки, что может ускорить индексирование во время запросов.
Начиная с версии v1.5.2, таблица Duplicate Key поддерживает указание ключа сортировки с помощью ORDER BY. Если используются и ORDER BY, и DUPLICATE KEY, DUPLICATE KEY не действует.
Если cluster Selena в тестовой среде содержит только один BE, количество replica можно установить равным 1 в предложении PROPERTIES, например PROPERTIES( "replication_num" = "1" ). Количество replica по умолчанию равно 3, что также является рекомендуемым значением для production-кластеров Selena. Если вы хотите использовать значение по умолчанию, настраивать параметр replication_num не нужно.
Выполните DESCRIBE для просмотра схемы таблицы.
MySQL [test]> DESCRIBE user_access;
+-------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-------+---------+-------+
| uid | int | YES | true | NULL | |
| name | varchar(64) | YES | true | NULL | |
| age | int | YES | false | NULL | |
| phone | varchar(16) | YES | false | NULL | |
| last_access | datetime | YES | false | NULL | |
| credits | double | YES | false | NULL | |
+-------------+-------------+------+-------+---------+-------+
6 rows in set (0.00 sec)
Выполните SHOW CREATE TABLE для просмотра оператора CREATE TABLE.
MySQL [example_db]> SHOW CREATE TABLE user_access\G
*************************** 1. row ***************************
Table: user_access
Create Table: CREATE TABLE `user_access` (
`uid` int(11) NULL COMMENT "",
`name` varchar(64) NULL COMMENT "",
`age` int(11) NULL COMMENT "",
`phone` varchar(16) NULL COMMENT "",
`last_access` datetime NULL COMMENT "",
`credits` double NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY RANDOM
ORDER BY(`uid`, `name`)
PROPERTIES (
"bucket_size" = "4294967296",
"compression" = "LZ4",
"fast_schema_evolution" = "true",
"replicated_storage" = "true",
"replication_num" = "3"
);
1 row in set (0.01 sec)
Понимание комплексной структуры таблиц
Глубокое погружение в структуры таблиц Selena помогает проектировать эффективную структуру управления данными, адаптированную к вашим бизнес-потребностям.
Типы таблиц
Selena предоставляет четыре типа таблиц: таблицы Duplicate Key, таблицы Primary Key, таблицы Aggregate и таблицы Unique Key для хранения данных в различных бизнес-сценариях, таких как необработанные данные, часто обновляемые данные в реальном времени и агрегированные данные.
- Таблицы Duplicate Key просты и легки в использовании. К столбцам в этом типе таблиц не добавляются ограничения, поэтому в таблице могут существовать дублирующиеся строки данных. Таблицы Duplicate Key подходят для хранения необработанных данных, таких как логи, которые не нуждаются в каких-либо ограничениях или предварительной агрегации.
- Таблицы Primary Key являются мощными. К столбцам первичного ключа добавляются ограничения уникальности и NOT NULL. Таблицы Primary Key поддерживают частые обновления в реальном времени и частичные обновления столбцов, обеспечивая при этом высокую производительность запросов, и поэтому подходят для сценариев запросов в реальном времени.
- Таблицы Aggregate подходят для хранения предварительно агрегированных данных, помогая уменьшить объем сканируемых и вычисляемых данных и повысить эффективность для агрегационных запросов.
- Таблицы Unique также подходят для хранения часто обновляемых данных в реальном времени. Однако этот тип таблиц заменяется таблицами Primary Key, которые более мощные.
Распределение данных
Selena использует двухуровневую стратегию распределения данных с разбиением на партиции+bucketing, чтобы равномерно распределять данные по BE. Хорошо спроектированная стратегия распределения данных может эффективно уменьшить объем сканируемых данных и максимизировать возможности параллельной обработки Selena, тем самым повышая производительность запросов.
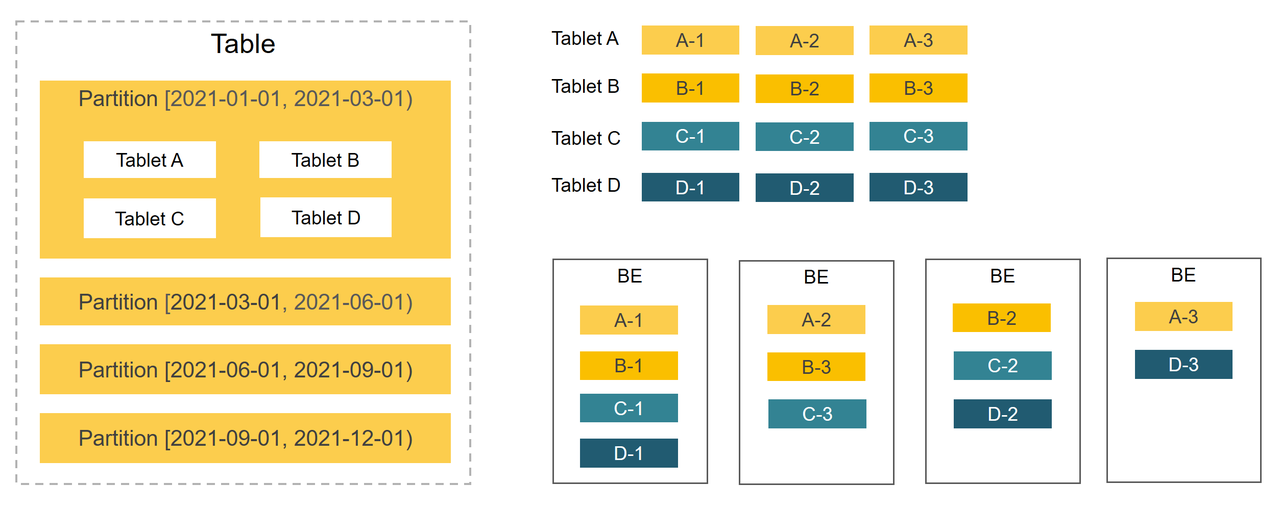
Партиционирование
Первый уровень - это партиционирование: Данные в таблицах могут быть разделены на более мелкие единицы управления данными на основе столбцов партиционирования, которые обычно являются столбцами, содержащими даты и время. Во время запросов отсечение партиций может уменьшить объем данных, которые необходимо сканировать, эффективно оптимизируя производительность запросов.
Selena предоставляет простой в использовании метод партиционирования, партиционирование по выражению, а также предлагает более гибкие методы, такие как партиционирование по диапазону и списку.
Bucketing
Второй уровень - это bucketing: Данные внутри партиции далее делятся на более мелкие единицы управления данными через bucketing. Реплики каждого bucket равномерно распределены по BE для обеспечения высокой доступности данных.
Selena предоставляет два метода bucketing:
- Hash bucketing: Данные распределяются в bucket на основе хеш-значений ключа bucketing. Вы можете выбрать столбцы, часто используемые в качестве условных столбцов в запросах, в качестве столбцов bucketing, что помогает повысить эффективность запросов.
- Random bucketing: Данные случайным образом распределяются в bucket. Этот метод bucketing более простой и легкий в использовании.
Типы данных
Помимо базовых типов данных, таких как NUMERIC, DATE и STRING, Selena поддерживает сложные полуструктурированные типы данных, включая ARRAY, JSON, MAP и STRUCT.
Индексы
Индекс - это специальная структура данных, используемая в качестве указателя на данные в таблице. Когда условные столбцы в запросах являются индексированными столбцами, Selena может быстро найти данные, которые соответствуют условиям.
Selena предоставляет встроенные индексы: индексы Prefix, индексы Ordinal и индексы ZoneMap. Selena также позволяет пользователям создавать индексы, то есть индексы Bitmap и индексы Bloom Filter, для дальнейшего повышения эффективности запросов.
Ограничения
Ограничения помогают обеспечить целостность, согласованность и точность данных. Столбцы первичного ключа в таблицах Primary Key должны иметь уникальные значе�ния и значения NOT NULL. Столбцы ключа агрегации в таблицах Aggregate и столбцы уникального ключа в таблицах Unique Key должны иметь уникальные значения.
Временные таблицы
При обработке данных вам может потребоваться сохранить промежуточные результаты для будущего повторного использования. В ранних версиях Selena поддерживает только использование CTE (Common Table Expressions) для определения временных результатов в рамках одного запроса. Однако CTE являются просто логическими конструкциями, не хранят результаты физически и не могут использоваться в разных запросах, что представляет определенные ограничения. Если вы решите создать таблицы для сохранения промежуточных результатов, вам нужно будет управлять жизненным циклом этих таблиц, что может быть затратным.
Чтобы решить эту проблему, Selena вводит временные таблицы в версии v1.5.2. Временные таблицы позволяют временно хранить данные (например, промежуточные результаты из ETL-процессов) в табли�це, причем их жизненный цикл привязан к сессии и управляется Selena. Когда сессия завершается, временные таблицы автоматически очищаются. Временные таблицы видны только в текущей сессии, и разные сессии могут создавать временные таблицы с одинаковыми именами.
Использование
Вы можете использовать ключевое слово TEMPORARY в следующих SQL-операторах для создания и удаления временных таблиц:
Подобно другим типам нативных таблиц, временные таблицы должны быть созданы в базе данных под Default Catalog. Однако, поскольку временные таблицы основаны на сессиях, они не подчиняются ограничениям уникальности имен. Вы можете создавать временные таблицы с одинаковыми именами в разных сессиях или даже создавать временные таблицы с теми же именами, что и другие не-временные, нативные таблицы.
Если в базе данных есть временные и не-временные таблицы с одинаковым именем, временная таблица имеет приоритет. В рамках сессии все запросы и операции над таблицами с одинаковым именем будут влиять только на временную таблицу.
Ограничения
Хотя использование временных таблиц аналогично использованию нативных таблиц, существуют некоторые ограничения и различия:
- Временные таблицы должны быть создан�ы в Default Catalog.
- Установка colocate group не поддерживается. Если свойство
colocate_withявно указано при создании таблицы, оно будет проигнорировано. ENGINEдолжен быть указан какolapпри создании таблицы.- Операторы ALTER TABLE не поддерживаются.
- Создание представлений и материализованных представлений на основе временных таблиц не поддерживается.
- Операторы EXPORT не поддерживаются.
- Создание временных таблиц или загрузка данных из/в них с помощью асинхронных задач с использованием SUBMIT TASK не поддерживается.
Дополнительные функции
Помимо перечисленных выше функций, вы можете использовать дополнительные функции на основе ваших бизнес-требований для проектирования более надежной структуры таблиц. Например, использование столбцов Bitmap и HLL для ускорения подсчета уникальных значений, указание генерируемых столбцов или столбцов с автоинкрементом для ускорения некоторых за�просов, настройка гибких и автоматических методов охлаждения хранилища для снижения затрат на обслуживание и настройка Colocate Join для ускорения многотабличных JOIN-запросов. Для получения дополнительной информации см. CREATE TABLE.