Распределение данных
Настройка правильного партиционирования и bucketing'а при создании таблицы помогает обеспечить равномерное распределение данных. Равномерное распределение данных означает разделение данных на подмножества в соответствии с определенными правилами и их равномерное распределение по различным узлам. Это также позволяет уменьшить объем сканируемых данных и в полной мере использовать возможности кластера для параллельной обработки, тем самым улучшая производительность запросов.
ПРИМЕЧАНИЕ
- После того, как распределение данных было указано при создании таблицы и паттерны запросов или характеристики данных в бизнес-сценарии изменились, начиная с версии 3.2 Selena поддерживает изменение определенных свойств, связанных с распределением данных, после создания таблицы, чтобы соответствовать требованиям производительности запросов в последних бизнес-сценариях.
- Начиная с версии 3.1, вам не нужно указывать bucketing key в клаузе DISTRIBUTED BY при создании таблицы или добавлении партиции. Selena поддерживает случайный bucketing, который случайным образом распределяет данные по всем bucket'ам. Для получения дополнительной информации см. Случайный bucketing.
- Начиная с версии 2.5.7, вы можете не устанавливать количество bucket'ов вручную при создании таблицы или добавлении партиции. Selena может автоматически установить количество bucket'ов (BUCKETS). Однако, если производительность не соответствует вашим ожиданиям после того, как Selena автоматически установила количество bucket'ов, и вы знакомы с механизмом bucketing'а, вы все еще можете установить количество bucket'ов вручную.
Введение
Методы распределения в общем случае
Современные системы распределенных баз данных обычно используют следующие базовые методы распределения: Round-Robin, Range, List и Hash.
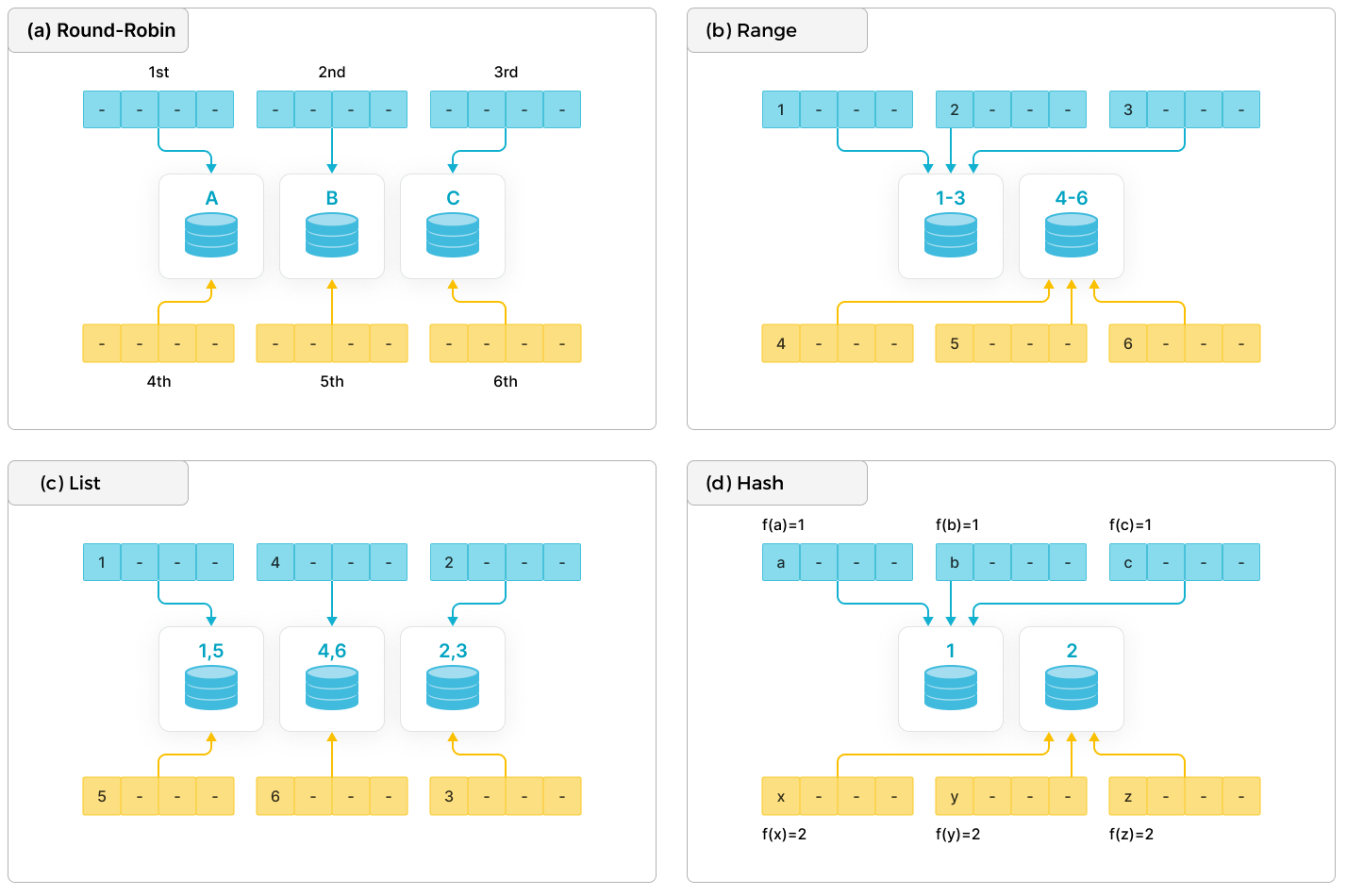
- Round-Robin: распределяет данные по ра�зличным узлам циклически.
- Range: распределяет данные по различным узлам на основе диапазонов значений партиционирующих колонок. Как показано на диаграмме, диапазоны [1-3] и [4-6] соответствуют различным узлам.
- List: распределяет данные по различным узлам на основе дискретных значений партиционирующих колонок, таких как пол и провинция. Каждое дискретное значение сопоставлено с узлом, и несколько различных значений могут быть сопоставлены с одним и тем же узлом.
- Hash: распределяет данные по различным узлам на основе хеш-функции.
Для достижения более гибкого партиционирования данных, помимо использования одного из вышеперечисленных методов распределения данных, вы также можете комбинировать эти методы на основе конкретных бизнес-требований. Распространенные комбинации включают Hash+Hash, Range+Hash и Hash+List.
Методы распределения в Selena
Selena поддерживает как отдельное, так и комбинированное использование методов распределения данных.
ПРИМЕЧАНИЕ
В дополнение к общим методам распределения, Selena также поддерживает Random распределение для упрощения конфигурации bucketing'а.
Также Selena распределяет данные путем реализации двухуровневого метода партиционирования + bucketing'а.
- Первый уровень - это партиционирование: Данные внутри таблицы могут быть партиционированы. Поддерживаемые методы партиционирования - это expression partitioning, range partitioning и list partitioning. Или вы можете не использовать партиционирование (вся таблица рассматривается как одна партиция).
- Второй уровень - это bucketing: Данные в партиции необходимо далее распределить на более мелкие bucket'ы. Поддерживаемые методы bucketing'а - это hash и random bucketing.
| Метод распределения | Метод партиционирования и bucketing'а | Описание |
|---|---|---|
| Random распределение | Random bucketing | Вся таблица рассматривается как партиция. Данные в таблице случайным образом распределяются по различным bucket'ам. Это метод распределения данных по умолчанию. |
| Hash распределение | Hash bucketing | Вся таблица рассматривается как партиция. Данные в таблице распределяются по соответствующим bucket'ам на основе хеш-значений bucketing key данных с использованием хеш-функции. |
| Range+Random распределение |
|
|
| Range+Hash распределение |
|
|
| List+Random распределение |
|
|
| List+Hash распределение |
|
|
-
Random распределение
Если вы не настраиваете методы партиционирования и bucketing'а при создании таблицы, по умолчанию используется random распределение. Этот метод распределения в настоящее время может использоваться только для создания таблицы Duplicate Key.
CREATE TABLE site_access1 (
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT ''
)
DUPLICATE KEY (event_day,site_id,pv);
-- Поскольку методы партиционирования и bucketing'а не настроены, по умолчанию используется random распределение. -
Hash распределение
CREATE TABLE site_access2 (
event_day DATE,
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY (event_day, site_id, city_code, user_name)
-- Использовать hash bucketing в качестве метода bucketing'а и необходимо указать bucketing key.
DISTRIBUTED BY HASH(event_day,site_id); -
Range+Random распределение (Этот метод распределения в настоящее время может использоваться только для создания таблицы Duplicate Key.)
CREATE TABLE site_access3 (
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT ''
)
DUPLICATE KEY(event_day,site_id,pv)
-- Использовать expression партиционирование в качестве метода партиционирования и настроить выражение временной функции.
-- Вы также можете использовать range партиционирование.
PARTITION BY date_trunc('day', event_day);
-- Поскольку метод bucketing'а не настроен, по умолчанию используется random bucketing. -
Range+Hash распределение
CREATE TABLE site_access4 (
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
-- Использовать expression партиционирование в качестве метода партиционирования и настроить выражение временной функции.
-- Вы также можете использовать range партиционирование.
PARTITION BY date_trunc('day', event_day)
-- Использовать hash bucketing в качестве метода bucketing'а и необходимо указать bucketing key.
DISTRIBUTED BY HASH(event_day, site_id); -
List+Random распр�еделение (Этот метод распределения в настоящее время может использоваться только для создания таблицы Duplicate Key.)
CREATE TABLE t_recharge_detail1 (
id bigint,
user_id bigint,
recharge_money decimal(32,2),
city varchar(20) not null,
dt date not null
)
DUPLICATE KEY(id)
-- Использовать expression партиционирование в качестве метода партиционирования и указать партиционирующую колонку.
-- Вы также можете использовать list партиционирование.
PARTITION BY (city);
-- Поскольку метод bucketing'а не настроен, по умолчанию используется random bucketing. -
List+Hash распределение
CREATE TABLE t_recharge_detail2 (
id bigint,
user_id bigint,
recharge_money decimal(32,2),
city varchar(20) not null,
dt date not null
)
DUPLICATE KEY(id)
-- Использовать expression партиционирование в качестве метода партиционирования и указать партиционирующую колонку.
-- Вы также можете использовать list партиционирование.
PARTITION BY (city)
-- Использовать hash bucketing в качестве метода bucketing'а и необходимо указать bucketing key.
DISTRIBUTED BY HASH(city,id);
Партиционирование
Метод партиционирования разделяет таблицу на несколько партиций. Партиционирование в основном используется для разделения таблицы на различные единицы управления (партиции) на основе партиционирующего ключа. Вы можете установить стратегию хранения для каждой партиции, включая количество bucket'ов, стратегию хранения горячих и холодных данных, тип носителя хранения и количество реплик. Selena позволяет использовать различные типы носителей хранения в рамках кластера. Например, вы можете хранить последние данные на твердотельных накопителях (SSD) для повышения производительности запросов, а исторические данные - на жестких дисках SATA для снижения затрат на хранение.
| Метод партиционирования | Сценарии | Методы создания партиций |
|---|---|---|
| Expression партиционирование (рекомендуется) | Ранее известное как автоматическое партиционирование. Этот метод партиционирования более гибкий и простой в использовании. Он подходит для большинства сценариев, включая запросы и управление данными на основе непрерывных диапазонов дат или перечисляемых значений. | Автоматически создается во время загрузки данных |
| Range партиционирование (Legacy) | Типичный сценарий - хранение простых упорядоченных данных, которые часто запрашиваются и управляются на основе непрерывных диапазонов дат/чисел. Например, в некоторых особых случаях исторические данные необходимо партиционировать по месяцам, в то время как последние данные необходимо партиционировать по дням. | Создается вручную, динамически или в пакетном режиме |
| List партиционирование (Legacy) | �Типичный сценарий - запрос и управление данными на основе перечисляемых значений, и партиция должна включать данные с различными значениями для каждой партиционирующей колонки. Например, если вы часто запрашиваете и управляете данными на основе стран и городов, вы можете использовать этот метод и выбрать city в качестве партиционирующей колонки. Таким образом, партиция может хранить данные для нескольких городов, принадлежащих одной стране. | Создается вручную |
Как выбрать партиционирующие колонки и гранулярность
- Партиционирующий ключ состоит из одной или нескольких партиционирующих колонок. Выбор правильной партиционирующей колонки может эффективно уменьшить объем данных, сканируемых во время запросов. В большинстве бизнес-систем партиционирование на основе времени обычно применяется для решения определенных проблем, вызванных удалением устаревших данных, и для облегчения управления многоуровневым хранением горячих и холодных данных. В этом случае вы можете использовать expression партиционирование или range партиционирование и указать колонку времени в качестве партиционирующей колонки. Кроме того, если данные часто запрашиваются и управляются на основе значений ENUM, вы можете использовать expression партиционирование или list партиционирование и указать колонку, включающую эти значения, в качестве партиционирующей колонки.
- При выборе гранулярности партиционирования необходимо учитывать объем данных, паттерны запросов и гранулярность управления данными.
- Пример 1: Если ежемесячный объем данных в таблице невелик, партиционирование по месяцам может уменьшить количество метаданных по сравнению с партиционированием по дням, тем самым уменьшая потребление ресурсов на управление метаданными и планирование.
- Пример 2: Если ежемесячный объем данных в таблице велик, и запросы в основном запрашивают данные определенных дней, партиционирование по дням может эффективно уменьшить объем данных, сканируемых во время запросов.
- Пример 3: Если данные должны истекать ежедневно, рекомендуется партиционирование по дням.
Bucketing
Метод bucketing'а разделяет партицию на несколько bucket'ов. Данные в bucket'е называются tablet.
Поддерживаемые методы bucketing'а - это random bucketing (начиная с версии 3.1) и hash bucketing.
-
Random bucketing: При создании таблицы и�ли добавлении партиций вам не нужно устанавливать bucketing key. Данные внутри партиции случайным образом распределяются по различным bucket'ам.
-
Hash Bucketing: При создании таблицы или добавлении партиций вам необходимо указать bucketing key. Данные внутри одной и той же партиции делятся на bucket'ы на основе значений bucketing key, и строки с одинаковым значением в bucketing key распределяются по соответствующему и уникальному bucket'у.
Количество bucket'ов: По умолчанию Selena автоматически устанавливает количество bucket'ов (начиная с версии 2.5.7). Вы также можете вручную установить количество bucket'ов. Для получения дополнительной информации см. определение количества bucket'ов.
Создание и управление партициями
Создание партиций
Expression партиционирование (рекомендуется)
ВНИМАНИЕ
Режим shared-data Selena поддерживает выражение временной функции начиная с версии 3.1.0 и выражение колонки начиная с версии 3.1.1.
Начиная с версии 3.0, Selena поддерживает expression партиционирование (ранее известное как автоматическое партиционирование), которое более гибкое и простое в использовании. Этот метод партиционирования подходит для большинства сценариев, таких как запросы и управление данными на основе непрерывных диапазонов дат или значений ENUM.
Вам нужно только настроить выражение партиционирования при создании таблицы, и Selena автоматически создаст партиции во время загрузки данных. Вам больше не нужно вручную создавать множество партиций заранее, ни настраивать свойства динамического партиционирования.
Начиная с версии 3.4, expression партиционирование дополнительно оптимизировано для унификации всех стратегий партиционирования и поддерживает более сложные решения. Оно рекомендуется в большинстве случаев и заменит другие стратегии партиционирования в будущих релизах.
Пример 1: Использование простого выражения временной функции с колонкой DATETIME.
CREATE TABLE site_access(
event_day DATETIME NOT NULL,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY time_slice(event_day, INTERVAL 7 day)
DISTRIBUTED BY HASH(event_day, site_id)
Пример 2: Использование выражения колонки с несколькими колонками.
CREATE TABLE t_recharge_detail1 (
id bigint,
user_id bigint,
recharge_money decimal(32,2),
city varchar(20) not null,
dt varchar(20) not null
)
DUPLICATE KEY(id)
PARTITION BY dt,city
DISTRIBUTED BY HASH(`id`);
Пример 3: Использование сложного выражения временной функции с колонкой Unix timestamp.
CREATE TABLE orders (
ts BIGINT NOT NULL,
id BIGINT NOT NULL,
city STRING NOT NULL
)
PARTITION BY from_unixtime(ts,'%Y%m%d');
Пример 4: Использование смешанного выражения временной функции и выражения колонки.
CREATE TABLE orders (
ts BIGINT NOT NULL,
id BIGINT NOT NULL,
city STRING NOT NULL
)
PARTITION BY from_unixtime(ts,'%Y%m%d'), city;
Range партиционирование
Range партиционирование подходит для хранения простых непрерывных данных, таких как данные временных рядов или непрерывные числовые данные.
Ручное создание партиций
Определите отображение между каждой партицией и диапазоном значений партиционирующей колонки.
-
Партиционирующая колонка имеет тип date.
CREATE TABLE site_access(
event_day DATE,
site_id INT,
city_code VARCHAR(100),
user_name VARCHAR(32),
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)(
PARTITION p1 VALUES LESS THAN ("2020-01-31"),
PARTITION p2 VALUES LESS THAN ("2020-02-29"),
PARTITION p3 VALUES LESS THAN ("2020-03-31")
)
DISTRIBUTED BY HASH(site_id); -
Партиционирующая колонка имеет целочисленный тип.
CREATE TABLE site_access(
datekey INT,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (
PARTITION p1 VALUES LESS THAN ("20200131"),
PARTITION p2 VALUES LESS THAN ("20200229"),
PARTITION p3 VALUES LESS THAN ("20200331")
)
DISTRIBUTED BY HASH(site_id); -
Три специфические временные функции могут использоваться в качестве партиционирующих колонок (поддерживается с версии 3.3.0).
При явном определении отображения между партициями и диапазонами значений партиционирующих колонок вы можете использовать специфическую временную функцию для преобразования значений партиционирующих колонок с timestamp'ами или строками в значения дат, а затем разделить партиции на основе преобразованных значений дат.
- Значения партиционирующей колонки являются timestamp'ами
- Значения партиционирующей колонки являются строками
-- 10-значный timestamp с точностью до секунды, например, 1703832553.
CREATE TABLE site_access(
event_time bigint,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_time, site_id, city_code, user_name)
PARTITION BY RANGE(from_unixtime(event_time)) (
PARTITION p1 VALUES LESS THAN ("2021-01-01"),
PARTITION p2 VALUES LESS THAN ("2021-01-02"),
PARTITION p3 VALUES LESS THAN ("2021-01-03")
)
DISTRIBUTED BY HASH(site_id)
;
-- 13-значный timestamp с точностью до миллисекунды, например, 1703832553219.
CREATE TABLE site_access(
event_time bigint,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_time, site_id, city_code, user_name)
PARTITION BY RANGE(from_unixtime_ms(event_time))(
PARTITION p1 VALUES LESS THAN ("2021-01-01"),
PARTITION p2 VALUES LESS THAN ("2021-01-02"),
PARTITION p3 VALUES LESS THAN ("2021-01-03")
)
DISTRIBUTED BY HASH(site_id);CREATE TABLE site_access (
event_time varchar(100),
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_time, site_id, city_code, user_name)
PARTITION BY RANGE(str2date(event_time, '%Y-%m-%d'))(
PARTITION p1 VALUES LESS THAN ("2021-01-01"),
PARTITION p2 VALUES LESS THAN ("2021-01-02"),
PARTITION p3 VALUES LESS THAN ("2021-01-03")
)
DISTRIBUTED BY HASH(site_id);
Динамическое партиционирование
Свойства, связанные с динамическим партиционированием, настраиваются при создании таблицы. Selena автоматически создает новые партиции заранее и удаляет устаревшие партиции для обеспечения свежести данных, что реализует управление временем жизни (TTL) для партиций.
В отличие от возможности автоматического создания партиций, предоставляемой expression партиционированием, динамическое партиционирование может только периодически создавать новые партиции на основе свойств. Если новые данные не принадлежат этим партициям, для задания загрузки возвращается ошибка. Однако возможность автоматического создания партиций, предоставляемая expression партиционированием, может всегда создавать соответствующие новые партиции на основе загружаемых данных.
Создание нескольких партиций в пакетном режиме
Несколько партиций могут быть созданы в пакетном режиме при и после создания таблицы. Вы можете указать начальное и конечное время для всех партиций, созданных в пакетном режиме, в START() и END() и значение приращения партиции в EVERY(). Однако обратите внимание, что диапазон партиций является левозамкнутым и правооткрытым, который включает начальное время, но не включает конечное время. Правило именования для партиций такое же, как и для динамического партиционирования.
-
Партиционирующая колонка имеет тип date.
Когда партиционирующая колонка имеет тип date, при создании таблицы вы можете использовать
START()иEND()для указания начальной и конечной даты для всех партиций, созданных в пакетном режиме, иEVERY(INTERVAL xxx)для указания интерв�ала приращения между двумя партициями. В настоящее время гранулярность интервала поддерживаетHOUR(с версии 3.0),DAY,WEEK,MONTHиYEAR.- с одинаковым интервалом дат
- с разными интервалами дат
В следующем примере партиции, созданные в пакетном режиме, начинаются с
2021-01-01и заканчиваются2021-01-04, с приращением партиции в один день:CREATE TABLE site_access (
datekey DATE,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id);Это эквивалентно использованию следующей клаузы
PARTITION BYв операторе CREATE TABLE:PARTITION BY RANGE (datekey) (
PARTITION p20210101 VALUES [('2021-01-01'), ('2021-01-02')),
PARTITION p20210102 VALUES [('2021-01-02'), ('2021-01-03')),
PARTITION p20210103 VALUES [('2021-01-03'), ('2021-01-04'))
)Вы можете создать пакеты партиций дат с различными интервалами приращения, указав различные интервалы приращения в
EVERYдля каждого пакета партиций (убедитесь, что диапазоны партиций между различными пакетами не перекрываются). Партиции в каждом пакете создаются в соответствии с клаузойSTART (xxx) END (xxx) EVERY (xxx). Например:CREATE TABLE site_access (
datekey DATE,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (
START ("2019-01-01") END ("2021-01-01") EVERY (INTERVAL 1 YEAR),
START ("2021-01-01") END ("2021-05-01") EVERY (INTERVAL 1 MONTH),
START ("2021-05-01") END ("2021-05-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id);Это эквивалентно использованию следующей клаузы
PARTITION BYв операторе CREATE TABLE:PARTITION BY RANGE (datekey) (
PARTITION p2019 VALUES [('2019-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2021-02-01')),
PARTITION p202102 VALUES [('2021-02-01'), ('2021-03-01')),
PARTITION p202103 VALUES [('2021-03-01'), ('2021-04-01')),
PARTITION p202104 VALUES [('2021-04-01'), ('2021-05-01')),
PARTITION p20210501 VALUES [('2021-05-01'), ('2021-05-02')),
PARTITION p20210502 VALUES [('2021-05-02'), ('2021-05-03')),
PARTITION p20210503 VALUES [('2021-05-03'), ('2021-05-04'))
) -
Партиционирующая колонка имеет целочисленный тип.
Когда тип данных партиционирующей колонки - INT, вы указываете диапазон партици�й в
STARTиENDи определяете значение приращения вEVERY. Пример:ПРИМЕЧАНИЕ
Значения партиционирующих колонок в START() и END() должны быть заключены в двойные кавычки, в то время как значение приращения в EVERY() не нужно заключать в двойные кавычки.
- с одинаковым числовым интервалом
- с разными числовыми интервалами
В следующем примере диапазон всех партиций начинается с
1и заканчивается5, с приращением партиции1:CREATE TABLE site_access (
datekey INT,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (
START ("1") END ("5") EVERY (1)
)
DISTRIBUTED BY HASH(site_id);Это эквивалентно использованию следующей клаузы
PARTITION BYв операторе CREATE TABLE:PARTITION BY RANGE (datekey) (
PARTITION p1 VALUES [("1"), ("2")),
PARTITION p2 VALUES [("2"), ("3")),
PARTITION p3 VALUES [("3"), ("4")),
PARTITION p4 VALUES [("4"), ("5"))
)Вы можете создать пакеты числовых партиций с различными интервалами приращения, указав различные интервалы приращения в
EVERYдля каждого пакета партиций (убедитесь, что диапазоны партиций между различными пакетами не перекрываются). Партиции в каждом пакете создаются в соответствии с клаузойSTART (xxx) END (xxx) EVERY (xxx). Например:CREATE TABLE site_access (
datekey INT,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (
START ("1") END ("10") EVERY (1),
START ("10") END ("100") EVERY (10)
)
DISTRIBUTED BY HASH(site_id); -
Три специфические временные функции могут использоваться в качестве партиционирующих колонок (поддерживается с версии 3.3.0).
При явном определении отображения между партициями и диапазонами значений партиционирующих колонок вы можете использовать специфическую временную функцию для преобразования значений партиционирующих колонок с timestamp'ами или строками в значения дат, а затем разделить партиции на основе преобразованных значений дат.
- Значения партиционирующей колонки являются timestamp'ами
- Значения партиционирующей колонки являются строками
-- 10-значный timestamp с точностью до секунды, например, 1703832553.
CREATE TABLE site_access(
event_time bigint,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
PARTITION BY RANGE(from_unixtime(event_time)) (
START ("2021-01-01") END ("2021-01-10") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id);
-- 13-значный timestamp с точностью до миллисекунды, например, 1703832553219.
CREATE TABLE site_access(
event_time bigint,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
PARTITION BY RANGE(from_unixtime_ms(event_time))(
START ("2021-01-01") END ("2021-01-10") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id);CREATE TABLE site_access (
event_time varchar(100),
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
PARTITION BY RANGE(str2date(event_time, '%Y-%m-%d'))(
START ("2021-01-01") END ("2021-01-10") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id);
List партиционирование (с версии 3.1)
List Партиционирование подходит для ускорения запросов и эффективного управления данными на основе перечисляемых значений. Оно особенно полезно для сценариев, где партиция должна включать данные с различными значениями в партиционирующей колонке. Например, если вы часто запрашиваете и управляете данными на основе стран и городов, вы можете использовать этот метод партиционирования и выбрать колонку city в качестве партиционирующей колонки. В этом случае одна партиция может содержать данные для различных городов, принадлежащих одной стране.
Selena хранит данные в соотве�тствующих партициях на основе явного сопоставления предопределенного списка значений для каждой партиции.
Управление партициями
Добавление партиций
Для range партиционирования и list партиционирования вы можете вручную добавить новые партиции для хранения новых данных. Однако для expression партиционирования, поскольку партиции создаются автоматически во время загрузки данных, вам не нужно этого делать.
Следующий оператор добавляет новую партицию в таблицу site_access для хранения данных за новый месяц:
ALTER TABLE site_access
ADD PARTITION p4 VALUES LESS THAN ("2020-04-30")
DISTRIBUTED BY HASH(site_id);
Удаление партиции
Следующий оператор удаляет партицию p1 из таблицы site_access.
ПРИМЕЧАНИЕ
Эта операция не удаляет данн�ые в партиции немедленно. Данные сохраняются в Корзине в течение определенного периода времени (один день по умолчанию). Если партиция была ошибочно удалена, вы можете использовать команду RECOVER для восстановления партиции и ее данных.
ALTER TABLE site_access
DROP PARTITION p1;
Восстановление партиции
Следующий оператор восстанавливает партицию p1 и ее данные в �таблицу site_access.
RECOVER PARTITION p1 FROM site_access;
Просмотр партиций
Следующий оператор возвращает подробную информацию обо всех партициях в таблице site_access.
SHOW PARTITIONS FROM site_access;
Настройка bucketing'а
Random bucketing (с версии 3.1)
Selena распределяет данные в партиции случайным образом по всем bucket'ам. Подходит для сценариев с небольшими объемами данных и относительно низкими требованиями к производительности запросов. Если вы не устанавливаете метод bucketing'а, Selena использует random bucketing по умолчанию и автоматически устанавливает количество bucket'ов.
Однако обратите внимание, что если вы запрашиваете большие объемы данных и часто используете определенные колонки в качестве условий фильтрации, производительность запросов, обеспечиваемая random bucketing, может быть не оптимальной. В таких сценариях рекомендуется использовать hash bucketing. Когда эти колонки используются в качестве условий фильтрации для запросов, необходимо скани�ровать и вычислять только данные в небольшом количестве bucket'ов, которые попадают в запрос, что может значительно улучшить производительность запросов.
Ограничения
- Вы можете использовать random bucketing только для создания таблицы Duplicate Key.
- Вы не можете указать таблицу с random bucketing для принадлежности к Colocation Group.
- Spark Load не может использоваться для загрузки данных в таблицы с random bucketing.
В следующем примере CREATE TABLE оператор DISTRIBUTED BY xxx не используется, поэтому Selena использует random bucketing по умолчанию и автоматически устанавливает количество bucket'ов.
CREATE TABLE site_access1(
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT ''
)
DUPLICATE KEY(event_day,site_id,pv);
Однако, если вы знакомы с механизмом bucketing'а Selena, вы также можете вручную установить количество bucket'ов при создании таблицы с random bucketing.
CREATE TABLE site_access2(
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT ''
)
DUPLICATE KEY(event_day,site_id,pv)
DISTRIBUTED BY RANDOM BUCKETS 8; -- вручную установить количество bucket'ов на 8
Hash bucketing
Selena может использовать hash bucketing для подразделения данных в партиции на bucket'ы на основе bucketing key и количества bucket'ов. При hash bucketing хеш-функция принимает значение bucketing key данных в качестве входных данных и вычисляет хеш-значение. Данные хранятся в соответствующем bucket'е на основе сопоставления между хеш-значениями и bucket'ами.
Преимущества
-
Улучшенная производительность запросов: Строки с одинаковыми значениями bucketing key хранятся в одном bucket'е, что уменьшает объем данных, сканируемых во время запросов.
-
Равномерное распределение данных: Выбирая колонки с более высокой кардинальностью (большее количество уникальных значений) в качестве bucketing key, данные могут быть более равномерно распределены по bucket'ам.
Как выбрать bucketing колонки
Мы рекомендуем выбирать колонку, которая удовлетворяет следующим двум требованиям, в качестве bucketing колонки.
- колонка с высокой кардинальностью, такая как ID
- колонка, которая часто используется в фильтре для запросов
Но если ни одна колонка не удовлетворяет обоим требованиям, вам нужно определить bucketing колонку в соответствии со сложностью запросов.
- Если запрос сложный, рекомендуется выбрать колонки с высокой кардинальностью в качестве bucketing колонок, чтобы обеспечить равномерное распределение данных по всем bucket'ам и улучшить использование ресурсов кластера.
- Если запрос относительно простой, рекомендуется выбрать колонки, которые часто используются в качестве условий фильтрации в запросах, в качестве bucketing колонок для повышения эффективности запросов.
Если данные партиции не могут быть равномерно распределены по всем bucket'ам с использованием одной bucketing колонки, вы можете выбрать несколько bucketing колонок. Обратите внимание, что рекомендуется использовать не более 3 колонок.
Меры предосторожност�и
- При создании таблицы необходимо указать bucketing колонки.
- Типы данных bucketing колонок должны быть INTEGER, DECIMAL, DATE/DATETIME или CHAR/VARCHAR/STRING.
- С версии 3.2 bucketing колонки могут быть изменены с помощью ALTER TABLE после создания таблицы.
Примеры
В следующем примере таблица site_access создается с использованием site_id в качестве bucketing колонки. Кроме того, когда данные в таблице site_access запрашиваются, данные часто фильтруются по сайтам. Использование site_id в качестве bucketing key может исключить значительное количество нерелевантных bucket'ов во время запросов.
CREATE TABLE site_access(
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)
(
PARTITION p1 VALUES LESS THAN ("2020-01-31"),
PARTITION p2 VALUES LESS THAN ("2020-02-29"),
PARTITION p3 VALUES LESS THAN ("2020-03-31")
)
DISTRIBUTED BY HASH(site_id);
Предположим, что каждая партиция таблицы site_access имеет 10 bucket'ов. В следующем запросе 9 из 10 bucket'ов исключаются, поэтому Selena нужно сканировать только 1/10 данных в таблице site_access:
select sum(pv)
from site_access
where site_id = 54321;
Однако, если site_id распределен неравномерно и большое количество запросов запрашивает данные только нескольких сайтов, использование только одной bucketing колонки может привести к серьезному перекосу данных, вызывая узкие места в производительности системы. В этом случае вы можете использовать комбинацию bucketing колонок. Например, следующий оператор использует site_id и city_code в качестве bucketing колонок.
CREATE TABLE site_access
(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code, user_name)
DISTRIBUTED BY HASH(site_id,city_code);
С практической точки зрения, вы можете использовать одну или две bucketing колонки в зависимости от характеристик вашего бизнеса. Использование одной bucketing колонки site_id очень выгодно для коротких запросов, поскольку оно уменьшает обмен данными между узлами, тем самым повышая общую производительность кластера. С другой стороны, принятие двух bucketing колонок site_id и city_code выгодно для длинных запросов, поскольку оно может использовать общую параллельность распределенного кластера для значительного повышения производительности.
ПРИМЕЧАНИЕ
- Короткие запросы включают сканирование небольшого объема данных и могут быть завершены на одном узле.
- Длинные запросы включают сканирование большого объема данных, и их производительность может быть значительно улучшена за счет параллельного сканирования на нескольких узлах в распределенном кластере.
Установка количества bucket'ов
Bucket'ы отражают, как файлы данных фактически организованы в Selena.
При создании таблицы
-
Автоматическая установка количества bucket'ов (рекомендуется)
Начиная с версии 2.5.7, Selena поддерживает автоматическую установку количества bucket'ов на основе ресурсов машины и объема данных для партиции.
подсказкаЕсли размер необработанных данных партиции превышает 100 ГБ, мы рекомендуем вручную настроить количество bucket'ов с помощью Метода 2.
- Таблица настроена с hash bucketing
- Таблица настроена с random bucketing
Пример:
CREATE TABLE site_access (
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
event_day DATE,
pv BIGINT SUM DEFAULT '0')
AGGREGATE KEY(site_id, city_code, user_name,event_day)
PARTITION BY date_trunc('day', event_day)
DISTRIBUTED BY HASH(site_id,city_code); -- не нужно устан�авливать количество bucket'овЧто касается таблиц, настроенных с random bucketing, в дополнение к автоматической установке количества bucket'ов в партиции, Selena дополнительно оптимизирует логику с версии 3.2.0. Selena также может динамически увеличивать количество bucket'ов в партиции во время загрузки данных, на основе емкости кластера и объема загружаемых данных.
warning- Чтобы включить увеличение количества bucket'ов по требованию и динамически, вам нужно установить свойство таблицы
PROPERTIES("bucket_size"="xxx")для указания размера одного bucket'а. Если объем данных в партиции невелик, вы можете установитьbucket_sizeна 1 ГБ. В противном случае вы можете установитьbucket_sizeна 4 ГБ. - После включения увеличения количества bucket'ов по требованию и динамически, и если вам нужно откатиться к версии 3.1, вам сначала нужно удалить таблицу, которая включает динамическое увеличение количества bucket'ов. Затем вам нужно вручную выполнить контрольную точку метаданных с помощью ALTER SYSTEM CREATE IMAGE перед откатом.
Пример:
CREATE TABLE details1 (
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '')
DUPLICATE KEY (event_day,site_id,pv)
PARTITION BY date_trunc('day', event_day)
-- Количество bucket'ов в партиции автоматически определяется Selena, и количество динамически увеличивается по требованию, потому что размер bucket'а установлен на 1 ГБ.
PROPERTIES("bucket_size"="1073741824")
;
CREATE TABLE details2 (
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '')
DUPLICATE KEY (event_day,site_id,pv)
PARTITION BY date_trunc('day', event_day)
-- Количество bucket'ов в партиции таблицы автоматически определяется Selena, и количество фиксированное и не увеличивается динамически по требованию, потому что размер bucket'а не установлен.
; -
Ручная установка количества bucket'ов
Начиная с версии 2.4.0, Selena поддерживает использование нескольких потоков для сканирования tablet параллельно во время запроса, тем самым уменьшая зависимость производительности сканирования от количества tablet'ов. Мы рекомендуем, чтобы каждый tablet содержал около 10 ГБ необработанных данных. Если вы намереваетесь вручную установить количество bucket'ов, вы можете оценить объем данных в каждой партиции таблицы, а затем решить количество tablet'ов.
Чтобы включить параллельное сканирование на tablet'ах, убедитесь, что параметр
enable_tablet_internal_parallelустановлен вTRUEглобально для всей системы (SET GLOBAL enable_tablet_internal_parallel = true;).- Таблица настроена с hash bucketing
- Таблица настроена с random bucketing
CREATE TABLE site_access (
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
event_day DATE,
pv BIGINT SUM DEFAULT '0')
AGGREGATE KEY(site_id, city_code, user_name,event_day)
PARTITION BY date_trunc('day', event_day)
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;
-- Предположим, что объем необработанных данных, которые вы хотите загрузить в партицию, составляет 300 ГБ.
-- Поскольку мы рекомендуем, чтобы каждый tablet содержал 10 ГБ необработанных данных, количество bucket'ов может быть установлено на 30.
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;CREATE TABLE details (
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
event_day DATE,
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY (site_id,city_code)
PARTITION BY date_trunc('day', event_day)
DISTRIBUTED BY RANDOM BUCKETS 30
;
После создания таблицы
-
Автоматическая установка количества bucket'ов (рекомендуется)
Начиная с версии 2.5.7, Selena поддерживает автоматическую установку количества bucket'ов на основе ресурсов машины и объема данных для партиции.
подсказкаЕсли размер необработанных данных партиции превышает 100 ГБ, мы рекомендуем вручную настроить количество bucket'ов с помощью Метода 2.
- Таблица настроена с hash bucketing
- Таблица настроена с random bucketing
-- Автоматически установить количество bucket'ов для всех партиций.
ALTER TABLE site_access DISTRIBUTED BY HASH(site_id,city_code);
-- Автоматически установить количество bucket'ов для конкретных партиций.
ALTER TABLE site_access PARTITIONS (p20230101, p20230102)
DISTRIBUTED BY HASH(site_id,city_code);
-- Автоматически установить количество bucket'ов для новых партиций.
ALTER TABLE site_access ADD PARTITION p20230106 VALUES [('2023-01-06'), ('2023-01-07'))
DISTRIBUTED BY HASH(site_id,city_code);Что касается таблиц, настроенных с random bucketing, в дополнение к автоматической установке количества bucket'ов в партиции, Selena дополнительно оптимизирует логику с версии 3.2.0. Selena также может динамически увеличивать количество bucket'ов в партиции во время загрузки данных, на основе емкости кластера и объема загружаемых данных. Это не только упрощает создание партиций, но и увеличивает производительность массовой загрузки.
warning- Чтобы включить увеличение количества bucket'ов по требованию и динамически, вам нужно установить свойство таблицы
PROPERTIES("bucket_size"="xxx")для указания размера одного bucket'а. Если объем данных в партиции невелик, вы можете установитьbucket_sizeна 1 ГБ. В противном случае вы можете установитьbucket_sizeна 4 ГБ. - После включения увеличения количества bucket'ов по требованию и динамически, и если вам нужно откатиться к версии 3.1, вам сначала нужно удалить таблицу, которая включает динамическое увеличение количества bucket'ов. Затем вам нужно вручную выполнить контрольную точку метаданных с помощью ALTER SYSTEM CREATE IMAGE перед откатом.
-- Количество bucket'ов для всех партиций автоматически устанавливается Selena, и это количество фиксированное, потому что увеличение количества bucket'ов по требованию и динамически отключено.
ALTER TABLE details DISTRIBUTED BY RANDOM;
-- Количество bucket'ов для всех партиций автоматически устанавливается Selena, и увеличение количества bucket'ов по требованию и динамически включено.
ALTER TABLE details SET("bucket_size"="1073741824");
-- Автоматически установить количество bucket'ов для конкретных партиций.
ALTER TABLE details PARTITIONS (p20230103, p20230104)
DISTRIBUTED BY RANDOM;
-- Автоматически установить количество bucket'ов для новых партиций.
ALTER TABLE details ADD PARTITION p20230106 VALUES [('2023-01-06'), ('2023-01-07'))
DISTRIBUTED BY RANDOM; -
Ручная установка количества bucket'ов
Вы также можете вручную указать количество bucket'ов. Чтобы рассчитать количество bucket'ов для партиции, вы можете обратиться к подходу, используемому при ручной установке количества bucket'ов при создании таблицы, как упоминалось выше.
- Таблица настроена с hash bucketing
- Таблица настроена с random bucketing
-- Вручную установить количество bucket'ов для всех партиций
ALTER TABLE site_access
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;
-- Вручную установить количество bucket'ов для конкретных партиций.
ALTER TABLE site_access
partitions p20230104
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;
-- Вручную установить количество bucket'ов для новых партиций.
ALTER TABLE site_access
ADD PARTITION p20230106 VALUES [('2023-01-06'), ('2023-01-07'))
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;-- Вручную установить количество bucket'ов для всех партиций
ALTER TABLE details
DISTRIBUTED BY RANDOM BUCKETS 30;
-- Вручную установить количество bucket'ов для конкретных партиций.
ALTER TABLE details
partitions p20230104
DISTRIBUTED BY RANDOM BUCKETS 30;
-- Вручную установить количество bucket'ов для новых партиций.
ALTER TABLE details
ADD PARTITION p20230106 VALUES [('2023-01-06'), ('2023-01-07'))
DISTRIBUTED BY RANDOM BUCKETS 30;Вручную установить количество bucket'ов по умолчанию для динамических партиций.
ALTER TABLE details_dynamic
SET ("dynamic_partition.buckets"="xxx");
Просмотр количества bucket'ов
После создания таблицы вы можете выполнить SHOW PARTITIONS, чтобы просмотреть количество bucket'ов, установленное Selena для каждой партиции. Таблицы, настроенные с hash bucketing, имеют фиксированное количество bucket'ов на партицию.
- Что касается таблицы, настроенной с random bucketing, которая включает увеличение количества bucket'ов по требованию и динамически, количество bucket'ов в каждой партиции динамически увеличивается. Таким образом, возвращенный результат отображает текущее количество bucket'ов для каждой партиции.
- Для этого типа таблиц фактическая иерархия внутри партиции выглядит следующим образом: партиция > субпартиция > bucket. Чтобы увеличить количество bucket'ов, Selena фактически добавляет новую субпартицию, которая включает определенное количество bucket'ов. В результате оператор SHOW PARTITIONS может вернуть несколько строк данных с одинаковым именем партиции, которые показывают информацию о субпартициях внутри одной и той же партиции.
Оптимизация распределения данных после создания таблицы (с версии 3.2)
ВНИМАНИЕ
Режим shared-data Selena в настоящее время не поддерживает эту функцию.
По мере развития паттернов запросов и объема данных в бизнес-сценариях, конфигурации, указанные при создании таблицы, такие как метод bucketing'а, количество bucket'ов и ключ сортировки, могут больше не подходить для нового бизнес-сценария и даже могут привести к снижению производительности запросов. В этот момент вы можете использовать ALTER TABLE для изменения метода bucketing'а, количества bucket'ов и ключа сортировки для оптимизации распределения данных. Например:
-
Увеличьте количество bucket'ов, когда объем данных внутри партиций значительно увеличился
Когда объем данных внутри партиций становится значительно больше, чем раньше, необходимо изменить количество bucket'ов, чтобы поддерживать размеры tablet в целом в диапазоне от 1 ГБ до 10 ГБ.
-
Измените bucketing key, чтобы избежать перекоса данных
Когда текущий bucketing key может вызвать перекос данных (например, только колонка
k1настроена в качестве bucketing key), необходимо указать более подходящие колонки или добавить дополнительные колонки к bucketing key. Например:ALTER TABLE t DISTRIBUTED BY HASH(k1, k2) BUCKETS 20;
-- Когда версия Selena 3.1 или позже, и таблица является таблицей Duplicate Key, вы можете рассмотреть возможность прямого использо�вания настроек bucketing'а системы по умолчанию, то есть random bucketing и количество bucket'ов, автоматически установленное Selena.
ALTER TABLE t DISTRIBUTED BY RANDOM; -
Адаптация ключа сортировки из-за изменений в паттернах запросов
Если бизнес-паттерны запросов значительно изменились и дополнительные колонки используются в качестве условных колонок, может быть выгодно настроить ключ сортировки. Например:
ALTER TABLE t ORDER BY k2, k1;
Для получения дополнительной информации см. ALTER TABLE.