List partitioning (Legacy)
Начиная с версии v1.5.2, Selena поддерживает list partitioning. Данные разбиваются на основе заранее определенного списка значений для каждой partition, что может ускорить запросы и упростить управление в соответствии с перечисляемыми значениями.
Обратите внимание, что начиная с версии v1.5.2, expression partitioning был дополнительно оптимизирован для унификации всех стратегий partitioning и поддержки более сложных решений. Он рекомендуется в большинстве случаев и заменит стратегию list partitioning в будущих релизах.
Введение
Вам необходимо явно указать список значений столбца в каждой partition. Эти значения не обязательно должны быть непрерывными, в отличие от непрерывного временного или числового диапазона, требуемого в Range Partitioning. Во время загрузки данных Selena будет хранить данные в соответствующей partition на основе соответствия между значениями столбца partitioning данных и заранее определенными значениями столбца для каждой partition.
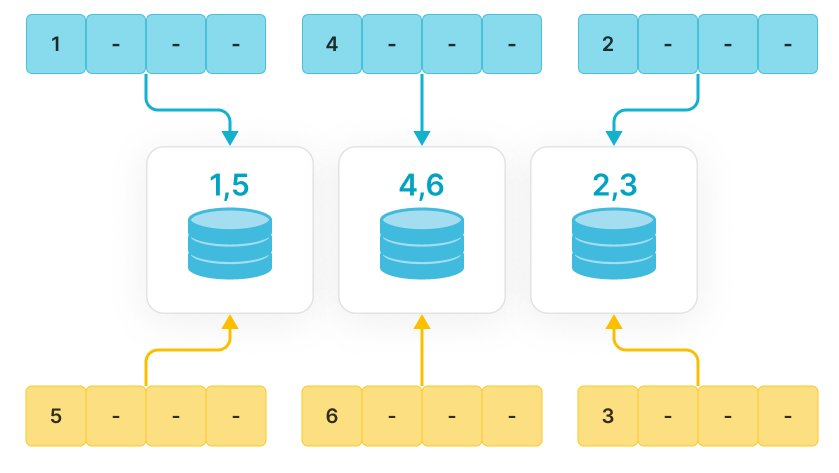
List partitioning подходит для хранения данных, столбцы которых содержат небольшое количество enum значений, и вы часто запрашиваете и управляете данными на основе этих enum значений. Например, столбцы представляют географические местоположения, штаты и категории. Каждое значение в столбце представляет независимую категорию. Разбивая данные на основе enum значений, вы можете улучшить производительность запросов и упростить управление данными.
List partitioning особенно полезен для сценариев, где partition должна включать несколько значений для каждого столбца partitioning. Например, если таблица включает столбец City, представляющий город, из которого человек, и вы часто запрашиваете и управляете данн�ыми по штатам и городам. При создании таблицы вы можете использовать столбец City в качестве столбца partitioning для List Partitioning и указать, что данные различных городов в пределах одного штата помещаются в одну partition, например PARTITION pCalifornia VALUES IN ("Los Angeles", "San Francisco", "San Diego"). Этот метод может ускорить запросы на основе штатов и городов, упрощая управление данными.
Если partition должна содержать только данные с одинаковым значением каждого столбца partitioning, рекомендуется использовать expression partitioning.
Сравнение между list partitioning и expression partitioning
Основное различие между list partitioning и expression partitioning (рекомендуется) заключается в том, что list partitioning требует вручную создавать partitions одну за другой. С другой стороны, expression partitioning может автоматически создавать partitions во время загрузки для упрощения partitioning. И в большинстве случаев expression partitioning может заменить list partitioning. Конкретное сравнение между ними показано в следующей таблице:
| Метод partitioning | List partitioning | Expression partitioning |
|---|---|---|
| Синтаксис | PARTITION BY LIST (partition_columns)( PARTITION <partition_name> VALUES IN (value_list) [, ...] ) | PARTITION BY <partition_columns> |
| Несколько значений для каждого столбца partitioning в partition | Поддерживается. Partition может хранить данные с различными значениями в каждом столбце partitioning. В следующем примере, когда загруженные данные содержат значения Los Angeles, San Francisco и San Diego в столбце city, все данные хранятся в одной partition pCalifornia.PARTITION BY LIST (city) ( PARTITION pCalifornia VALUES IN ("Los Angeles","San Francisco","San Diego") [, ...] ) | Не поддерживается. Partition хранит данные с одинаковым значением в столбце partitioning. Например, выражение PARTITION BY (city) используется в expression partitioning. Когда загруженные данные содержат значения Los Angeles, San Francisco и San Diego в столбце city, Selena автоматически создаст три partitions pLosAngeles, pSanFrancisco и pSanDiego. Три partitions соответственно хранят данные со значениями Los Angeles, San Francisco и San Diego в столбце city. |
| Создание partitions перед загрузкой данных | Поддерживается. Partitions должны быть созданы при создании та�блицы. | Не требуется. Partitions могут быть автоматически созданы во время загрузки данных. |
| Автоматическое создание List partitions во время загрузки данных | Не поддерживается. Если partition, соответствующая данным, не существует во время загрузки данных, возвращается ошибка. | Поддерживается. Если partition, соответствующая данным, не существует во время загрузки данных, Selena автоматически создает partition для хранения данных. Каждая partition может содержать только данные с одинаковым значением для столбца partitioning. |
| SHOW CREATE TABLE | Возвращает определение partitions в операторе CREATE TABLE. | После загрузки данных оператор возвращает результат с предложением partition, использованным в операторе CREATE TABLE, то есть PARTITION BY (partition_columns). Однако возвращенный результат не показывает автоматически созданные partitions. Если вам нужно просмотреть автоматически созданные partitions, выполните SHOW PARTITIONS FROM <table_name>. |
Использование
Синтаксис
PARTITION BY LIST (partition_columns) (
PARTITION <partition_name> VALUES IN (value_list)
[, ...]
)
partition_columns::=
<column> [,<column> [, ...] ]
value_list ::=
value_item [, value_item [, ...] ]
value_item ::=
{ <value> | ( <value> [, <value>, [, ...] ] ) }
Параметры
| Параметры | Обязательно | Описание |
|---|---|---|
partition_columns | ДА | Имена столбцов partitioning. Значения столбца partitioning могут быть строковыми (BINARY не поддерживается), датой или datetime, целочисленными и булевыми значениями. Начиная с v1.5.2, столбец partitioning допускает значения NULL. |
partition_name | ДА | Имя partition. Рекомендуется устанавливать подходящие имена partitions на основе бизнес-сценария для разделения данных в разных partitions. |
value_list | ДА | Список значений столбца partitioning в partition. |
Примеры
Пример 1: Предположим, вы часто запрашиваете детали выставления счетов дата-центра на основе штатов или городов. При создании таблицы вы можете указать столбец partitioning как city и указать, что каждая partition хранит данные городов в пределах одного штата. Этот метод может ускорить запросы для конкретных штатов или городов и упростить управление данными.
CREATE TABLE t_recharge_detail1 (
id bigint,
user_id bigint,
recharge_money decimal(32,2),
city varchar(20) not null,
dt varchar(20) not null
)
DUPLICATE KEY(id)
PARTITION BY LIST (city) (
PARTITION pLos_Angeles VALUES IN ("Los Angeles"),
PARTITION pSan_Francisco VALUES IN ("San Francisco")
)
DISTRIBUTED BY HASH(`id`);
Пример 2: Предположим, вы часто запрашиваете детали выставления счетов дата-центра на основе временных диапазонов и конкретных штатов или городов. При создании таблицы вы можете указать столбцы partitioning как dt и city. Таким образом, данные конкретных дат и конкретных штатов или городов хранятся в одной partition, улучшая скорость запросов и упрощая управление данными.
CREATE TABLE t_recharge_detail4 (
id bigint,
user_id bigint,
recharge_money decimal(32,2),
city varchar(20) not null,
dt varchar(20) not null
) ENGINE=OLAP
DUPLICATE KEY(id)
PARTITION BY LIST (dt,city) (
PARTITION p202204_California VALUES IN (
("2022-04-01", "Los Angeles"),
("2022-04-01", "San Francisco"),
("2022-04-02", "Los Angeles"),
("2022-04-02", "San Francisco")
),
PARTITION p202204_Texas VALUES IN (
("2022-04-01", "Houston"),
("2022-04-01", "Dallas"),
("2022-04-02", "Houston"),
("2022-04-02", "Dallas")
)
)
DISTRIBUTED BY HASH(`id`);
Ограничения
- List partitioning не поддерживает dynamic partitioning и создание нескольких partitions одновременно.
- В настоящее время режим shared-data Selena не поддерживает эту функцию.
- Когда оператор
ALTER TABLE <table_name> DROP PARTITION <partition_name>;используется для удаления partition, созданной с использованием list partitioning, данные в partition непосредственно удаляются и не могут быть восстановлены. - Начиная с версий v1.5.2, Selena поддерживает резервное копирование и восстановление таблиц, созданных со стратегией list partitioning.
- Начиная с версии v1.5.2, Selena поддерживает создание асинхронных материализованных представлений с базовыми таблицами, созданными со стратегией list partitioning.