Primary Key table
Primary Key table использует новый механизм хранения, разработанный Selena. Его основное преимущество заключается в поддержке обновления данных в реальном времени при обеспечении эффективной производительности для сложных ad-hoc запросов. В аналитике бизнеса в реальном времени принятие решений может выиграть от Primary Key tables, которые используют самые свежие данные для анализа результатов в реальном времени, что может смягчить задержку данных в анализе данных.
Первичный ключ Primary Key table имеет ограничение UNIQUE и ограничение NOT NULL, и используется для уникальной идентификации каждой строки данных. Если значение первичного ключа новой строки данных совпадает со значением существующей строки данных в таблице, возникает нарушение ограничения UNIQUE. Тогда новая строка данных заменит существующую строку данных.
- Начиная с версии 3.0, ключ сортировки Primary Key table отделён от первичного ключа таблицы, и ключ сортировки может быть указан отдельно. Таким образом, повышается гибкость создания таблиц.
- Начиная с версии 3.1, Selena shared-data clusters поддерживают создание Primary Key tables.
- Начиная с версии 3.1.4, персистентные индексы могут быть созданы и сохранены на локальных дисках.
- Начиная с версии 3.3.2, персистентные индексы могут быть созданы и сохранены в объектном хранилище.
Сценарии
Primary Key table может поддерживать обновление данных в реальном времени, обеспечивая при этом эффективную производительность запросов. Она подходит для следующих сценариев:
- Потоковая передача данных в реальном времени из систем обработки транзакций в Selena. В обычных случаях системы обработки транзакций включают большое количество операций обновления и удаления в дополнение к операциям вставки. Если вам необходимо синхронизировать данные из системы обработки транзакций в Selena, мы рекомендуем создать Primary Key table. Затем вы можете использовать инструменты, такие как CDC Connectors for Apache Flink®, для синхронизации бинарных логов системы обработки транзакций в Selena. Selena использует бинарные логи для добавления, удаления и обновления данных в таблице в реальном времени. Это упрощает синхронизацию данных и обеспечивает производительность запросов в 3-10 раз выше, чем при использовании Unique Key table, которая использует стратегию Merge-On-Read. Для получения дополнительной информации см. Синхронизация в реальном времени из MySQL.
- Объединение нескольких потоков путём выполнения частичных обновлений отдельных столбцов. В бизнес-сценариях, таких как профилирование пользователей, предпочтительно использовать плоские таблицы для повышения производительности многомерного анализа и упрощения аналитической модели, используемой аналитиками данных. Данные upstream в этих сценариях могут поступать из различных приложений, таких как приложения для шоппинга, приложения для доставки и банковские приложения, или из систем, таких как системы машинного обучения, которые выполняют вычисления для получения различных тегов и свойств пользователей. Primary Key table хорошо подходит для этих сценариев, потому что она поддерживает обновления отдельных столбцов. Каждое приложение или система может обновлять только столбцы, которые содержат данные в пределах их собственной области обслуживания, при этом пользуясь добавлением, удалением и обновлением данных в реальном времени с высокой производительностью запросов.
Как это работает
Unique Key table и Aggregate table используют стратегию Merge-On-Read. Эта стратегия делает запись данных простой и эффективной, но требует объединения нескольких версий файлов данных онлайн во время чтения данных. Более того, поскольку существует оператор Merge, предикаты и индексы не могут быть проталкнуты в базовые данные, что серьёзно влияет на производительность запросов.
Однако для баланса производительности обновлений в реальном времени и запросов структура метаданных и механизм чтения/записи в Primary Key table отличаются от таковых в других типах таблиц. Primary Key table использует стратегию Delete+Insert. Эта стратегия реализуется с использованием индекса первичного ключа и DelVector. Эта стратегия гарантирует, что во время запросов нужно читать только последнюю запись среди записей с одинаковым значением первичного ключа, что устраняет необходимость объединения нескольких версий файлов данных. Более того, предикаты и индексы могут бы�ть проталкнуты в базовые данные, что значительно улучшает производительность запросов.
Общий процесс записи и чтения данных в Primary Key table выглядит следующим образом:
-
Запись данных достигается через внутреннее задание загрузки Selena (Loadjob), которое включает пакет операций изменения данных (Insert, Update и Delete). Selena загружает индексы первичного ключа соответствующих tablets в память. Для операций Delete Selena сначала использует индекс первичного ключа для поиска исходного местоположения (файл данных и номер строки) каждой строки данных, отмечая строку данных как удалённую в DelVector (который хранит и управляет маркерами удаления, сгенерированными во время загрузки данных). Для операций Update, помимо отметки исходной строки данных как удалённой в DelVector, Selena также записывает последнюю строку данных в новый файл данных, по сути преобразуя Update в Delete+Insert (как показано на следующем рисунке). Индекс первичного ключа также обновляется для записи нового местоположения (файл данных и номер строки) изменённой строки данных.
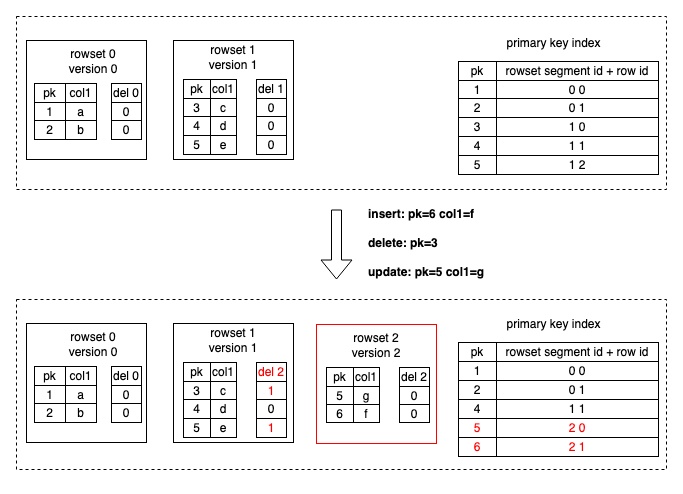
-
Во время чтения данных, поскольку исторические дублирующие записи в различных файлах данных уже были отмечены как удалённые во время записи данных, необходимо читать только последнюю строку данных с одинаковым значением первичного ключа. Больше не нужно читать онлайн несколько версий файлов данных для дедупликации данных и поиска последних данных. Когда сканируются базовые файлы данных, операторы фильтрации и различные индексы помогают уменьшить затраты на сканирование (как показано на следующем рисунке). Таким образом, производительность запросов может быть значительно улучшена. По сравнению со стратегией Merge-On-Read Unique Key table, стратегия Delete+Insert Primary Key table может улучшить производительность запросов в 3-10 раз.
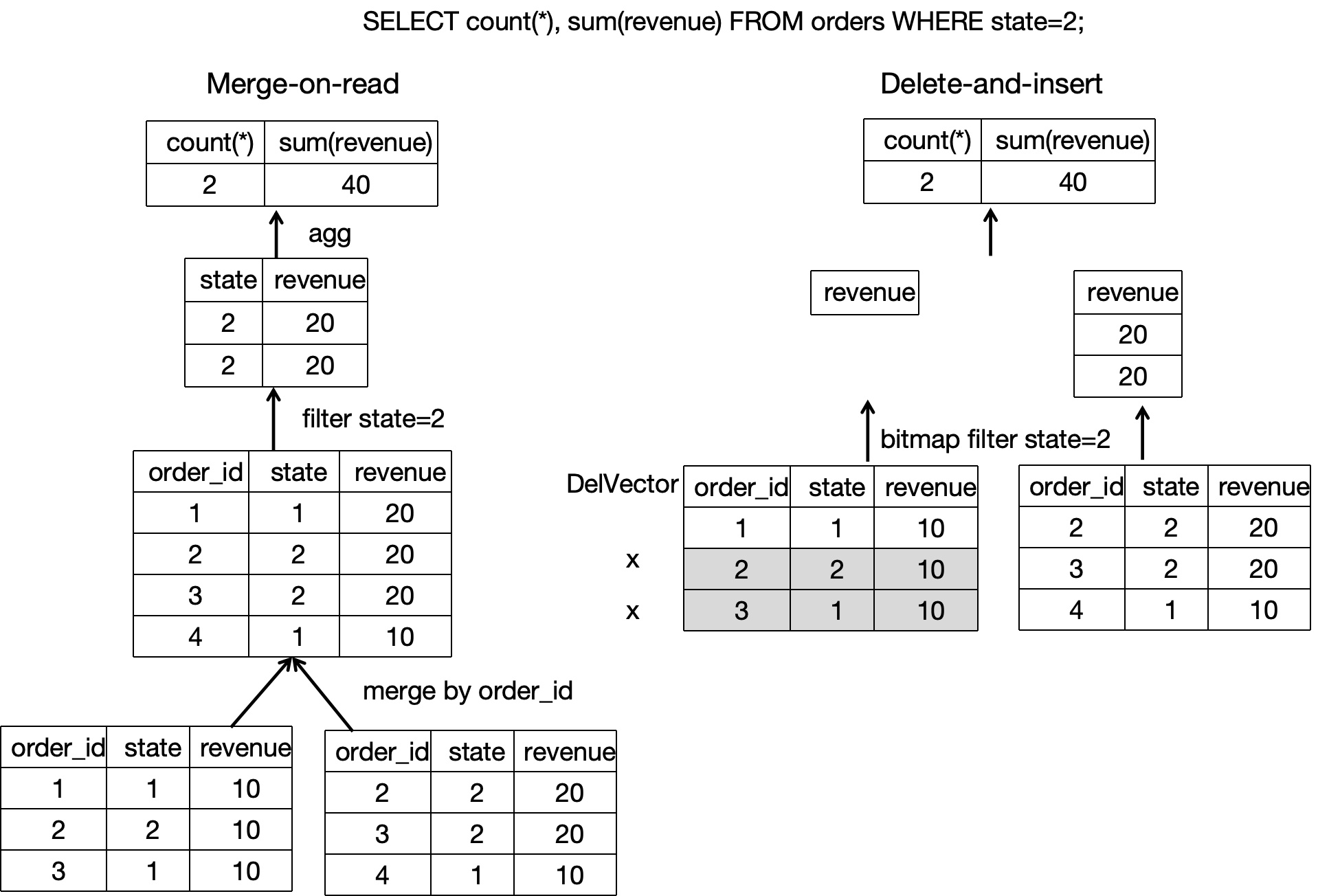
Подробнее
Если вы хотите более глубоко понять, как данные записываются в Primary Key tables или читаются из них, вы можете изучить подробные процессы записи и чтения данных следующим образом:
Selena - это аналитическая база данных, использующая столбцовое хранение. В частности, tablet внутри таблицы часто содержит несколько файлов rowset, и данные каждого файла rowset фактически хранятся в файлах segment. Файлы segment организуют данные в столбцовом формате (аналогично Parquet) и являются неизменяемыми.
Когда данные, которые должны быть записаны, распределяются на узлы Executor BE, каждый узел Executor BE выполняет Loadjob. Loadjob включает пакет изменений данных и может рассматриваться как транзакция со свойствами ACID. Loadjob можно разделить на два этапа: запись и фиксация.
- Этап записи: Данные распределяются в соответствующий tablet на основе информации о партиционировании и bucketing. Когда tablet получает данные, данные хранятся в столбцовом формате, а затем формируется новый rowset.
- Этап фиксации: После успешной записи всех данных FE инициирует фиксации на всех tablets, которые задействованы. Каждая фиксация несёт номер версии, представляющий последнюю версию данных tablet. Процесс фиксации в основном включает поиск и обновление индекса первичного ключа, отметку всех изменённых данных как удалённых, создание DelVector на основе данных, отмеченных как удалённые, и генерацию метаданных для новой версии.
Во время чтения данных метаданные используются для определения того, какие rowsets необходимо прочитать на основе последней версии tablet. Когда читается файл segment в rowset, также проверяется его последняя версия DelVector, что может гарантировать, что нужно читать только последние данные и избежать чтения старых данных с одинаковым значением первичного ключа. Кроме того, операторы фильтрации, проталкиваемые в слой Scan, могут напрямую использовать различные индексы для уменьшения затрат на сканирование.
-
Tablet: Таблица делится на несколько tablets на основе механизмов партиционирования и bucketing. Это фактическая физическая единица хранения, распределённая в виде реплик на р�азных BE.
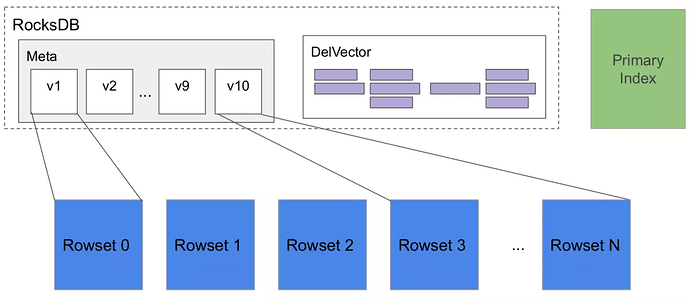
-
Metadata: Метаданные хранят историю версий tablet и информацию о каждой версии (например, какие rowsets включены). Этап фиксации каждого Loadjob или compaction генерирует новую версию.
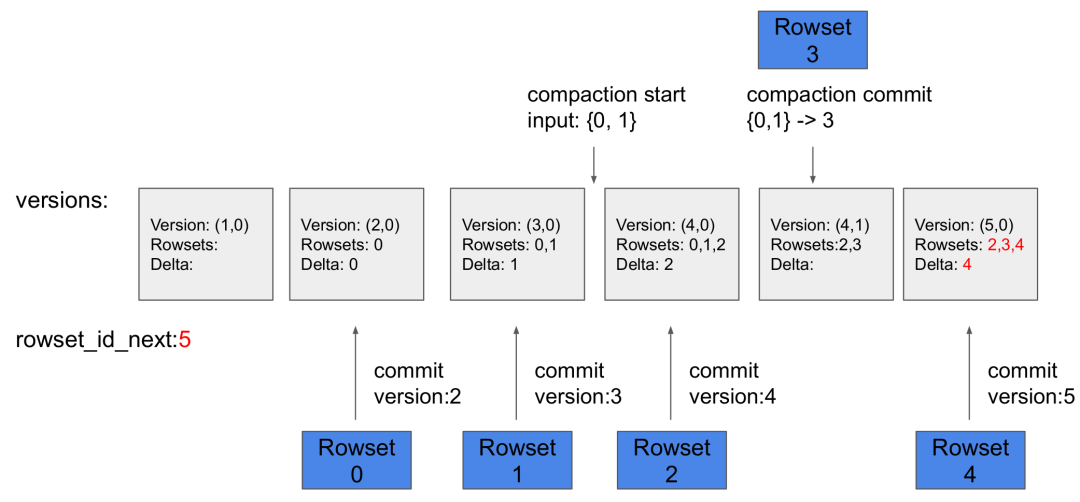
-
Индекс первичного ключа: Индекс первичного ключа хранит отображение между строками данных, идентифицированными значениями первичного ключа, и местоположениями этих строк данных. Он реализован как HashMap, где ключи представляют закодированные значения первичного ключа, а значения представляют местоположения строк данных (включая
rowset_id,segment_idиrowid). Обычно индекс первичного ключа используется только во время записи данных для поиска rowset и строки, в которой находится каждая строка данных, идентифицированная определённым значением первичного ключа. -
DelVector: DelVector хранит маркеры удаления для каждого файла segment (столбцового файла) в каждом rowset.
-
Rowset: Rowset - это логическая к�онцепция, которая хранит набор данных из пакета изменений данных в tablet.
-
Segment: Данные в rowset фактически сегментированы и хранятся в одном или нескольких файлах segment (столбцовых файлах). Каждый файл segment содержит значения столбцов и информацию об индексах, связанных со столбцами.
Использование
Создание Primary Key table
Вам просто нужно определить первичный ключ в операторе CREATE TABLE, чтобы создать Primary Key table. Пример:
CREATE TABLE orders1 (
order_id bigint NOT NULL,
dt date NOT NULL,
user_id INT NOT NULL,
good_id INT NOT NULL,
cnt int NOT NULL,
revenue int NOT NULL
)
PRIMARY KEY (order_id)
DISTRIBUTED BY HASH (order_id)
;
Поскольку Primary Key table поддерживает только hash bucketing в качестве стратегии bucketing, вам также необходимо определить ключ hash bucketing с помощью DISTRIBUTED BY HASH ().
Однако в реальных бизнес-сценариях при создании Primary Key table часто используются дополнительные функции, такие как распределение данных и ключ сортировки, для ускорения запросов и более эффективного управления данными.
Например, поле order_id в таблице заказов может однозначно идентифицировать строки данных, поэтому поле order_id может использоваться в качестве первичного ключа.
Начиная с версии 3.0, ключ сортировки Primary Key table отделён от первичного ключа таблицы. Поэтому вы можете выбрать столбцы, часто используемые в качестве условий фильтрации запросов, для формирования ключа сортировки. Например, если вы часто запрашиваете эффективн�ость продаж товаров на основе комбинации двух измерений, дата заказа и продавец, вы можете указать ключ сортировки как dt и merchant_id с помощью предложения ORDER BY (dt,merchant_id).
Обратите внимание, что если вы используете стратегии распределения данных, Primary Key table в настоящее время требует, чтобы первичный ключ включал столбцы партиционирования и bucketing. Например, стратегия распределения данных использует dt в качестве столбца партиционирования и merchant_id в качестве столбца hash bucketing. Первичный ключ также должен включать dt и merchant_id.
Таким образом, оператор CREATE TABLE для вышеупомянутой таблицы заказов может выглядеть следующим образом:
CREATE TABLE orders2 (
order_id bigint NOT NULL,
dt date NOT NULL,
merchant_id int NOT NULL,
user_id int NOT NULL,
good_id int NOT NULL,
good_name string NOT NULL,
price int NOT NULL,
cnt int NOT NULL,
revenue int NOT NULL,
state tinyint NOT NULL
)
PRIMARY KEY (order_id,dt,merchant_id)
PARTITION BY date_trunc('day', dt)
DISTRIBUTED BY HASH (merchant_id)
ORDER BY (dt,merchant_id)
PROPERTIES (
"enable_persistent_index" = "true"
);
Первичный ключ
Первичный ключ таблицы используется для уникальной идентификации каждой строки в этой таблице. Один или несколько столбцов, составляющих первичный ключ, определяются в PRIMARY KEY и имеют ограничение UNIQUE и ограничение NOT NULL.
Примите во внимание следующие соображения о первичном ключе:
- В операторе CREATE TABLE столбцы первичного ключа должны быть определены перед другими столбцами.
- Столбцы первичного ключа должны включать столбцы партиционирования и bucketing.
- Столбцы первичного ключа поддерживают следующие типы данных: числовые (включая целые числа и BOOLEAN), строковые и дата (DATE и DATETIME).
- По умолчанию максимальная длина закодированного значения первичного ключа составляет 128 байт.
- Первичный ключ нельзя изменить после создания таблицы.
- В целях обеспечения согласованности данных значения первичного ключа не могут быть обновлены.
Индекс первичного ключа
Индекс первичного ключа используется для хранения отображения между значениями первичного ключа и местоположениями строк данных, идентифицированных значениями первичного ключа. Обычно индексы первичного ключа соответствующих tablets загружаются в память только во время загрузки данных (которая включает пакет изменений данных). Вы можете рассмотреть возможность сохранения индексов первичного ключа после комплексной оценки требований к производительности запросов и обновлений, а также памяти и диска.
- Персистентный индекс первичного ключа
- Полностью хранящийся в памяти индекс первичного ключа
Когда enable_persistent_index установлен в true (по умолчанию), индексы первичного ключа могут быть сохранены на диске. Во время загрузки небольшая часть индексов первичного ключа загружается в память, в то время как большая часть хранится на диске, чтобы избежать слишком большого использования памяти. В общем, производительность запросов и обновлений таблицы с персистентными индексами первичного ключа почти эквивалентна таковой у таблицы с полностью хранящимися в памяти индексами первичного ключа.
Если диск является SSD, рекомендуется установить значение true. Если диск является HDD и частота загрузки невысока, вы также можете установить значение true.
Начиная с версии 3.1.4, Primary Key tables, созданные в Selena shared-data clusters, поддерживают сохранение индекса на локальных дисках. А начиная с версии 3.3.2 Selena shared-data clusters дополнительно поддерживают сохранение индекса в объектном хранилище. Вы можете включить эту функцию, установив свойство таблицы persistent_index_type в CLOUD_NATIVE.
Когда enable_persistent_index установлен в false, индексы первичного ключа не сохраняются на диске, то есть индексы первичного ключа полностью хранятся в памяти. Во время загрузки индексы первичного ключа tablets, связанных с загруженными данными, будут загружены в память, что может привести к более высокому потреблению памяти. (Если tablet долгое время не загружал данные, его индекс первичного ключа будет освобождён из памяти.)
При использовании полностью хранящихся в памяти индексов первичного ключа рекомендуется следовать следующим рекомендациям при проектировании Primary Key для контроля использования памяти индексами первичного ключа:
- Количество и общая длина столбцов Primary Key должны быть правильно спроектированы. Мы рекомендуем определить столбцы, типы данных которых занимают меньше памяти, в качестве первичного ключа, такие как INT и BIGINT, а не VARCHAR.
- Перед созданием таблицы рекомендуется оценить память, занимаемую индексами первичного ключа, на основе типов данных столбцов первичного ключа и количества строк в таблице. Таким образом, вы можете предотвратить исчерпание памяти. Следующий пример объясняет, как рассчитать память, занимаемую индексами первичного ключа:
-
Предположим, что столбец
dt, который имеет тип данных DATE и занимает 4 байта, и столбецid, который имеет тип данных BIGINT и занимает 8 байт, определены как Primary Key. В этом случае длина Primary Key составляет 12 байт. -
Предположим, что таблица содержит 10 000 000 строк горячих данных и хранится в трёх репликах.
-
Учитывая вышеуказанную информацию, память, занимаемая индексами первичного ключа, составляет 945 МБ на основе следующей формулы:
(12 + 9) x 10,000,000 x 3 x 1.5 = 945 (MB)В вышеуказанной формуле
9- это неизменяемые накладные расходы на строку, а1.5- это средние дополнительные накладные расходы на хеш-таблицу.
-
Primary Key table с полностью хранящимися в памяти индексами первичного ключа подходит для сценариев, в которых память, занимаемая Primary Key, контролируема. Пример:
-
Таблица содержит как быстро изменяющиеся данные, так и медленно изменяющиеся данные. Быстро изменяющиеся данные часто обновляются в течение последних нескольких дней, тогда как медленно изменяющиеся данные редко обновляются. Предположим, что вам необходимо синхронизировать таблицу заказов MySQL в Selena в реальном времени для аналитики и запросов. В этом примере данные таблицы разделены по дням, и большинство обновлений выполняется для заказов, созданных в течение последних нескольких дней. Исторические заказы больше не обновляются после их завершения. Когда вы запускаете задание загрузки данных, индексы первичного ключа исторических заказов не загружаются в память. Только индексы первичного ключа недавно обновлённых заказов загружаются в память.
Как показано на следующем рисунке, данные в таблице разделены по дням, и данные в двух последних партициях часто обновляются.

-
Таблица является плоской таблицей, состоящей из сотен или тысяч столбцов. Primary Key составляет только небольшую часть данных таблицы и потребляет лишь небольшое количество памяти. Например, таблица статуса пользователя или профиля состоит из большого количества столбцов, но только из десятков или сотен миллионов пользователей. В этой ситуации объём памяти, потребляемой первичным ключом, контролируем.
Как показано на следующем рисунке, таблица содержит только несколько строк, а Primary Key таблицы составляет только небольшую часть таблицы.

Ключ сортировки
Начиная с версии 3.0, Primary Key table отделяет ключ сортировки �от Primary Key. Ключ сортировки состоит из столбцов, определённых в ORDER BY, и может состоять из любой комбинации столбцов, при условии, что тип данных столбцов соответствует требованиям ключа сортировки.
Во время загрузки данных данные хранятся после сортировки в соответствии с ключом сортировки. Ключ сортировки также используется для построения префиксного индекса для ускорения запросов. Рекомендуется правильно спроектировать ключ сортировки для формирования префиксного индекса, который может ускорить запросы.
- Если указан ключ сортировки, префиксный индекс строится на основе ключа сортировки. Если ключ сортировки не указан, префиксный индекс строится на основе Primary Key.
- После создания таблицы вы можете использовать
ALTER TABLE ... ORDER BY ...для изменения ключа сортировки. Удаление ключа сортировки не поддерживается, а изменение типов данных столбцов сортировки не поддерживается.
Что ещё
- Для загрузки данных в созданную таблицу вы можете обратиться к Обзор загрузки, чтобы выбрать подходящий вариант загрузки.
- Если вам необходимо изменить данные в Primary Key table, вы можете обратиться к изменение данных через загрузку или использовать DML (INSERT, UPDATE и DELETE).
- Если вы хотите дополнительно ускорить запросы, вы можете обратиться к Ускорение запросов.
- Если вам необходимо изменить схему таблицы, вы можете обратиться к ALTER TABLE.
- Столбец AUTO_INCREMENT может использоваться в качестве Primary Key.