Экспорт данных с помощью EXPORT
В этой теме описывается, как экспортировать данные из указанных таблиц или partitions в вашем Selena cluster в виде CSV файлов данных во внешнюю систему хранения, которой может быть распределенная файловая система HDFS или облачная система хранения, такая как AWS S3.
ВАЖНО
Вы можете экспортировать данные из таблиц Selena только как пользователь, имеющий привилегию EXPORT для этих таблиц Selena. Если у вас нет привилегии EXPORT, следуйте инструкциям, приведенным в GRANT, чтобы предоставить привилегию EXPORT пользователю, которого вы используете для подключения к вашему Selena cluster.
Справочная информация
В версиях 2.4 и более ранних Selena зависела от brokers для установки соединений между вашим Selena cluster и внешней системой хранения при использовании инструкции EXPORT для экспорта данных. Поэтому вам нужно было указать WITH BROKER "<broker_name>" для указания broker, который вы хотите использовать в инструкции EXPORT. Это называется "выгрузка на основе broker". Broker — это независимый, stateless сервис, интегрированный с интерфейсом файловой системы, помогающий Selena экспортировать данные во внешнюю систему хранения.
Начиная с версии 2.5, Selena больше не зависит от brokers для установки соединений между вашим Selena cluster и внешней системой хранения при использовании инструкции EXPORT для экспорта данных. Поэтому вам больше не нужно указывать broker в инструкции EXPORT, но вам все еще нужно сохранить ключевое слово WITH BROKER. Это называется "выгрузка без broker".
Однако, когда ваши данные хранятся в HDFS, выгрузка без broker может не работать, и вы можете прибегнуть к выгрузке на основе broker:
- Если вы экспортируете данные в несколько HDFS clusters, вам нужно развернуть и настроить независимый broker для каждого из этих HDFS clusters.
- Если вы экспортируете данные в один HDFS cluster и у вас настроено несколько пользователей Kerberos, вам нужно развернуть один независимый broker.
Поддерживаемые системы хранения
- Распределенная файловая система HDFS
- Облачные системы хранения, такие как AWS S3
Меры предосторожности
-
Мы рекомендуем, чтобы объем данных, экспортируемых за один раз, не превышал несколько десятков GB. Если вы экспортируете чрезмерно большой объем данных за один раз, экспорт может завершиться неудачей, и стоимость повторной попытки экспорта увеличивается.
-
Если исходная таблица Selena содержит большой объем данных, мы рекомендуем экспортировать данные только из нескольких partitions таблицы за раз, пока все данные из таблицы не будут экспортированы.
-
Если FE в вашем Selena cluster перезапускаются или выбирается новый leader FE во время выполнения задачи экспорта, задача экспорта завершается неудачей. В этой ситуации вы должны отправить задачу экспорта снова.
-
Если FE в вашем Selena cluster перезапускаются или выбирается новый leader FE после завершения задачи экспорта, некоторая информация о задаче, возвращаемая инструкцией SHOW EXPORT, может быть потеряна.
-
Selena экспортирует только данные базовых таблиц. Selena не экспортирует данные материализованных представлений, созданных на базовых таблицах.
-
Задачи экспорта требуют сканирования данных, что занимает I/O ресурсы и, следовательно, увеличивает задержку запросов.
Рабочий процесс
После отправки задачи экспорта Selena идентифицирует все tablets, участвующие в задаче экспорта. Затем Selena разделяет участвующие tablets на группы и генерирует планы запросов. Планы запросов используются для чтения данных из участвующих tablets и для записи данных в указанный путь целевой системы хранения.
Следующая диаграмма показывает общий рабочий процесс.
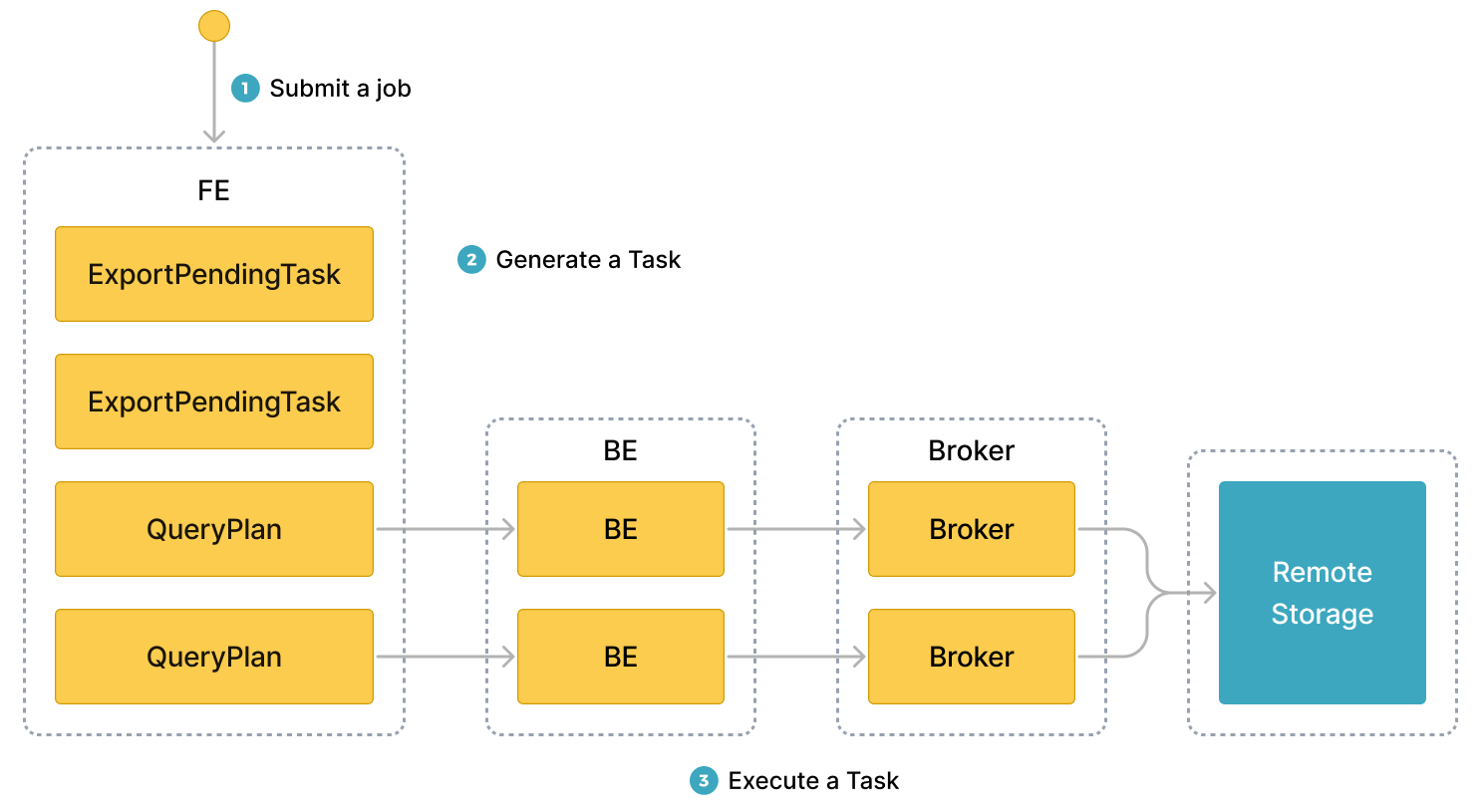
Общий рабочий процесс состоит из следующих трех шагов:
-
Пользователь отправляет задачу экспорта на leader FE.
-
Leader FE выдает инструкции
snapshotвсем BE или CN в Selena cluster, чтобы BE или CN могли делать snapshots участвующих tablets для обеспечения согласованности данных, которые нужно экспортировать. Leader FE также генерирует несколько задач экспорта. Каждая за�дача экспорта — это план запроса, и каждый план запроса используется для обработки части участвующих tablets. -
Leader FE распределяет задачи экспорта между BE или CN.
Принципы работы
Когда Selena выполняет планы запросов, она сначала создает временную папку с именем __selena_export_tmp_xxx в указанном пути целевой системы хранения. В имени временной папки xxx представляет ID задачи экспорта. Примером имени временной папки является __selena_export_tmp_921d8f80-7c9d-11eb-9342-acde48001122. После успешного выполнения плана запроса Selena генерирует временный файл во временной папке и записывает экспортированные данные в сгенерированный временный файл.
После экспорта всех данных Selena использует инструкцию RENAME для сохранения сгенерированных временных файлов в указанный путь.
Связанные параметры
В этом разделе описываются некоторые параметры, связанные с экспортом, которые вы можете настроить в FE вашего Selena cluster.
-
export_checker_interval_second: интервал, с которым планируются задачи экспорта. Интервал по умолчанию составляет 5 секунд. После перенастройки этого параметра для FE вам нужно перезапустить FE, чтобы новая настройка параметра вступила в силу. -
export_running_job_num_limit: максимальное количество выполняющихся задач экспорта, которое разрешено. Если количество выполняющихся задач экспорта превышает этот лимит, избыточные задачи экспорта переходят в состояние ожидания после выполненияsnapshot. Максимальное количество по умолчанию равно 5. Вы можете перенастроить этот параметр во время выполнения задач экспорта. -
export_task_default_timeout_second: период timeout для задач экспорта. Период timeout по умолчанию составляет 2 часа. Вы можете перенастроить этот параметр во время выполнения задач экспорта. -
export_max_bytes_per_be_per_task: максимальный объем данных в сжатом виде, который может быть экспортирован на задачу экспорта с каждого BE ил�и CN. Этот параметр предоставляет политику, на основе которой Selena разделяет задачи экспорта на задачи экспорта, которые могут выполняться одновременно. Максимальный объем по умолчанию составляет 256 MB. -
export_task_pool_size: максимальное количество задач экспорта, которые могут выполняться одновременно в thread pool. Максимальное количество по умолчанию равно 5.
Основные операции
Отправка задачи экспорта
Предположим, что ваша база данных Selena db1 содержит таблицу с именем tbl1. Чтобы экспортировать данные колонок col1 и col3 из partitions p1 и p2 таблицы tbl1 в путь export вашего HDFS cluster, выполните следующую команду:
EXPORT TABLE db1.tbl1
PARTITION (p1,p2)
(col1, col3)
TO "hdfs://HDFS_IP:HDFS_Port/export/lineorder_"
PROPERTIES
(
"column_separator"=",",
"load_mem_limit"="2147483648",
"timeout" = "3600"
)
WITH BROKER
(
"username" = "user",
"password" = "passwd"
);
Для подробного синтаксиса и описания параметров, а также примеров команд экспорта данных в AWS S3 см. EXPORT.
Получение query ID задачи экспорта
После отправки задачи экспорта вы можете использовать инструкцию SELECT LAST_QUERY_ID() для запроса query ID задачи экспорта. С query ID вы можете просматривать или отменять задачу экспорта.
Для подробного синтаксиса и описания параметров см. last_query_id.
Просмотр статуса задачи экспорта
После отправки задачи экспорта вы можете использовать инструкцию SHOW EXPORT для просмотра статуса задачи экспорта. Пример:
SHOW EXPORT WHERE queryid = "edee47f0-abe1-11ec-b9d1-00163e1e238f";
ПРИМЕЧАНИЕ
В приведенном выше примере
queryid— это query ID задачи экспорта.
Возвращается информация, аналогичная следующему выводу:
JobId: 14008
State: FINISHED
Progress: 100%
TaskInfo: {"partitions":["*"],"mem limit":2147483648,"column separator":",","line delimiter":"\n","tablet num":1,"broker":"hdfs","coord num":1,"db":"default_cluster:db1","tbl":"tbl3",columns:["col1", "col3"]}
Path: oss://bj-test/export/
CreateTime: 2019-06-25 17:08:24
StartTime: 2019-06-25 17:08:28
FinishTime: 2019-06-25 17:08:34
Timeout: 3600
ErrorMsg: N/A
Для подробного синтаксиса и описания параметров см. SHOW EXPORT.
Отмена задачи экспорта
Вы можете использовать инструкцию CANCEL EXPORT для отмены задачи экспорта, которую вы отправили. Пример:
CANCEL EXPORT WHERE queryid = "921d8f80-7c9d-11eb-9342-acde48001122";
ПРИМЕЧАНИЕ
В приведенном выше примере
queryid— это query ID задачи экспорта.
Для подробного синтаксиса и описания параметров см. CANCEL EXPORT.
Лучшие практики
Разделение плана запроса
Количество планов запросов, на которые разделяется задача экспорта, варьируется в зависимости от количества tablets, участвующих в задаче экспорта, и от максимального объема данных, который может быть обработан на план запроса. Задачи экспорта повторяются как планы запросов. Если объем данных, обрабатываемый планом запроса, превышает максимально допустимый объем, план запроса сталкивается с ошибками, такими как колебания в удаленном хранилище. В результате стоимость повторной попытки плана запроса увеличивается. Максимальный объем данных, который может быть обработан на план запроса каждым BE или CN, указывается параметром export_max_bytes_per_be_per_task, который по умолчанию равен 256 MB. В плане запроса каждому BE или CN выделяется как минимум один tablet, и он может экспортировать объем данных, не превышающий лимит, указанный параметром export_max_bytes_per_be_per_task.
Несколько планов запросов задачи экспорта выполняются одновременно. Вы можете использовать параметр FE export_task_pool_size для указания максимального количества задач экспорта, которым разрешено одновременное выполнение в thread pool. По умолчанию этот параметр равен 5.
В обычных случаях каждый план запроса задачи экспорта состоит только из двух частей: сканирование и экспорт. Логика выполнения вычислений, требуемых планами запросов, не потребляет много памяти. Поэтому лимит памяти по умолчанию в 2 GB может удовлетворить большинство ваших бизнес-требований. Однако в определенных обстоятельствах, таких как когда план запроса требует сканирования многих tablets на BE или CN, или tablet имеет много версий, емкости памяти в 2 GB может быть недостаточно. В этих обстоятельствах вам нужно использовать параметр load_mem_limit для указания более высокого лимита емкости памяти, такого как 4 GB или 8 GB.