Чтение данных из Selena с помощью Flink connector
Selena предоставляет собственный connector под названием Selena Connector for Apache Flink® (сокращенно Flink connector), который помогает вам читать данные массово из Selena cluster с помощью Flink.
Flink connector поддерживает два метода чтения: Flink SQL и Flink DataStream. Рекомендуется использовать Flink SQL.
ПРИМЕЧАНИЕ
Flink connector также поддерживает запись данных, прочитанных Flink, в другой Selena cluster или систему хране�ния. См. Непрерывная загрузка данных из Apache Flink®.
Справочная информация
В отличие от JDBC connector, предоставляемого Flink, Flink connector от Selena поддерживает параллельное чтение данных из нескольких BE вашего Selena cluster, значительно ускоряя задачи чтения. Следующее сравнение показывает разницу в реализации между двумя connectors.
-
Flink connector от Selena
С Flink connector от Selena, Flink может сначала получить план запроса от ответственного FE, затем распределить полученный план запроса в качестве параметров всем задействованным BE и, наконец, получить данные, возвращаемые BE.
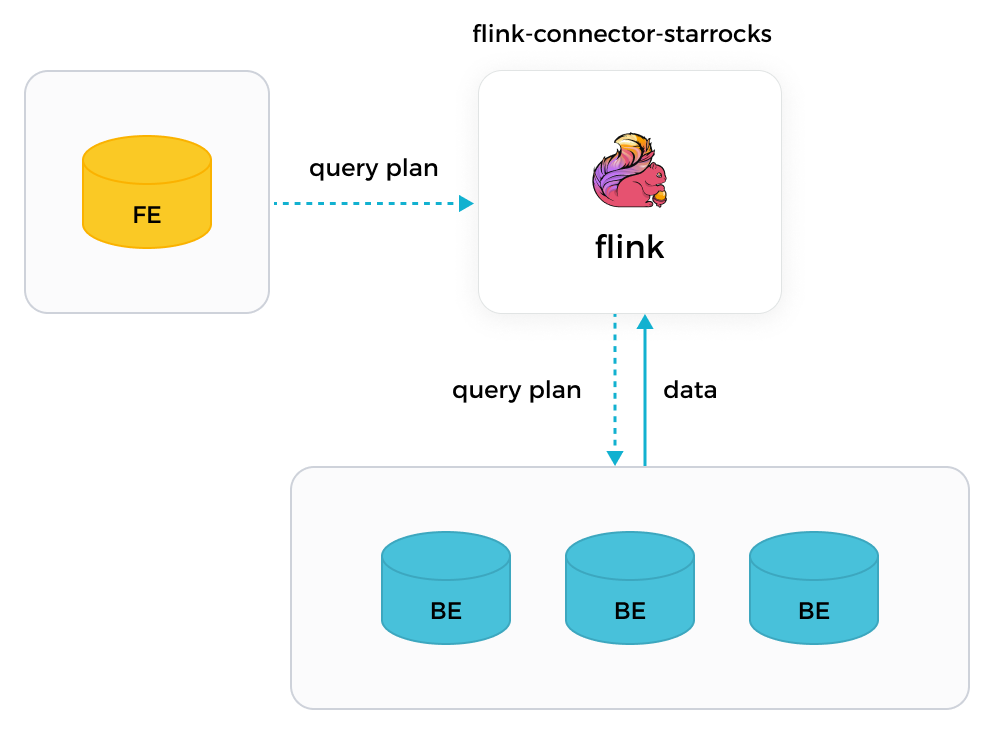
-
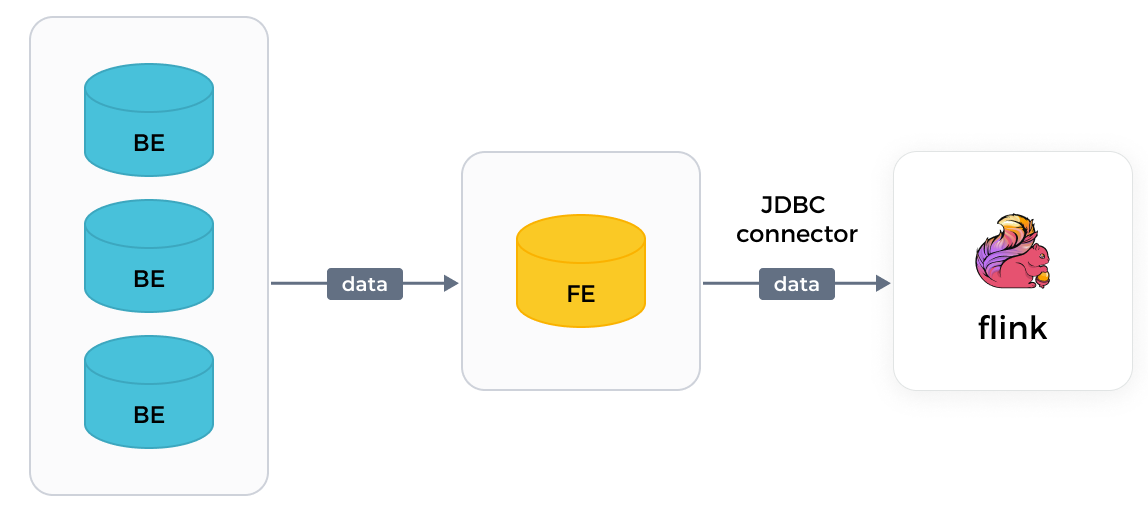
JDBC connector от Flink
С JDBC connector от Flink, Flink может читать данные только из отдельных FE, по одному за раз. Чтение данных происходит медленно.
Требования к версиям
| Connector | Flink | Selena | Java | Scala |
|---|---|---|---|---|
| 1.2.10 | 1.15,1.16,1.17,1.18,1.19 | 2.1 и новее | 8 | 2.11,2.12 |
| 1.2.9 | 1.15,1.16,1.17,1.18 | 2.1 и новее | 8 | 2.11,2.12 |
| 1.2.8 | 1.13,1.14,1.15,1.16,1.17 | 2.1 и новее | 8 | 2.11,2.12 |
| 1.2.7 | 1.11,1.12,1.13,1.14,1.15 | 2.1 и новее | 8 | 2.11,2.12 |
Предварительные требования
Flink должен быть развернут. Если Flink не развернут, следуйте этим шагам для его развертывания:
-
Установите Java 8 или Java 11 в вашей операционной системе, чтобы обеспечить правильную работу Flink. Вы можете использовать следующую команду для проверки версии вашей установки Java:
java -versionНапример, если возвращается следующая информация, Java 8 установлена:
openjdk version "1.8.0_322"
OpenJDK Runtime Environment (Temurin)(build 1.8.0_322-b06)
OpenJDK 64-Bit Server VM (Temurin)(build 25.322-b06, mixed mode) -
Загрузите и разархивируйте пакет Flink по вашему выбору.
ПРИМЕЧАНИЕ
Мы рекомендуем использовать Flink версии 1.14 или новее. Минимальная поддерживаемая версия Flink — 1.11.
# Загрузите пакет Flink.
wget https://dlcdn.apache.org/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.11.tgz
# Разархивируйте пакет Flink.
tar -xzf flink-1.14.5-bin-scala_2.11.tgz
# Перейдите в директорию Flink.
cd flink-1.14.5 -
Запустите ваш Flink cluster.
# Запустите ваш Flink cluster.
./bin/start-cluster.sh
# Когда отображается следующая информация, ваш Flink cluster успешно запущен:
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
Вы также можете развернуть Flink, следуя инструкциям, приведенным в документации Flink.
Прежде чем начать
Развертывание Flink connector
Следуйте этим шагам для развертывания Flink connector:
-
Выберите и загрузите JAR-пакет flink-connector-selena, соответствующий версии Flink, которую вы используете. Если требуется отладка кода, скомпилируйте пакет Flink connector в соответствии с вашими бизнес-требованиями.
ВАЖНО
Мы рекомендуем загрузить пакет Flink connector версии 1.2.x или новее, и чья соответствующая версия Flink имеет те же первые две цифры, что и используемая вами версия Flink. Например, если вы используете Flink версии 1.14.x, вы можете загрузить
flink-connector-selena-1.2.4_flink-1.14_x.yy.jar. -
Поместите загруженный или скомпилированный пакет Flink connector в директорию
libFlink. -
Перезапустите ваш Flink cluster.
Конфигурация сети
Убедитесь, что машина, на которой находится Flink, может получить доступ к узлам FE Selena cluster через http_port (по умолчанию: 8030) и query_port (по умолчанию: 9030), а также к узлам BE через be_port (по умолчанию: 9060).
Параметры
Общие параметры
Следующие параметры применяются к методам чтения как Flink SQL, так и Flink DataStream.
| Параметр | Обязательный | Тип данных | Описание |
|---|---|---|---|
| connector | Да | STRING | Тип connector, который вы хотите использовать для чтения данных. Установите значение selena. |
| scan-url | Да | STRING | Адрес, используемый для подключения FE с веб-сервера. Формат: <fe_host>:<fe_http_port>. Порт по умолчанию — 8030. Вы можете указать несколько адресов, которые должны быть разделены запятой (,). Пример: 192.168.xxx.xxx:8030,192.168.xxx.xxx:8030. |
| jdbc-url | Да | STRING | Адрес, используемый для подключения клиента MySQL к FE. Формат: jdbc:mysql://<fe_host>:<fe_query_port>. Номер порта по умолчанию — 9030. |
| username | Да | STRING | Имя пользователя вашей учетной записи Selena cluster. Учетная запись должна иметь разрешения на чтение таблицы Selena, которую вы хотите прочитать. См. Привилегии пользователя. |
| password | Да | STRING | Пароль вашей учетной записи Selena cluster. |
| database-name | Да | STRING | Имя базы данных Selena, к которой принадлежит таблица Selena, которую вы хотите прочитать. |
| table-name | Да | STRING | Имя таблицы Selena, которую вы хотите прочитать. |
| scan.connect.timeout-ms | Нет | STRING | Максимальное время, после которого соединение от Flink connector к вашему Selena cluster истекает. Единица: миллисекунды. Значение по умолчанию: 1000. Если время, затраченное на установление соединения, превышает этот лимит, задача чтения завершается неудачей. |
| scan.params.keep-alive-min | Нет | STRING | Максимальное время, в течение которого задача чтения остается активной. Время keep-alive проверяется на регулярной основе с использованием механизма опроса. Единица: минуты. Значение по умолчанию: 10. Мы рекомендуем установить этот параметр на значение, большее или равное 5. |
| scan.params.query-timeout-s | Нет | STRING | Максимальное время, после которого задача чтения истекает. Продолжительность timeout проверяется во время выполнения задачи. Единица: секунды. Значение по умолчанию: 600. Если результат чтения не возвращается после истечения времени, задача чтения останавливается. |
| scan.params.mem-limit-byte | Нет | STRING | Максимальный объем памяти, разрешенный для каждого запроса на каждом BE. Единица: байты. Значение по умолчанию: 1073741824, что равно 1 GB. |
| scan.max-retries | Нет | STRING | Максимальное количество раз, которое задача чтения может быть повторена при сбоях. Значение по умолчанию: 1. Если количество повторных попыток задачи чтения превышает этот лимит, задача чтения возвращает ошибки. |
Параметры для Flink DataStream
Следующие параметры применяются только к методу чтения Flink DataStream.
| Параметр | Обязательный | Тип данных | Описание |
|---|---|---|---|
| scan.columns | Нет | STRING | Колонка, которую вы хотите прочитать. Вы можете указать несколько колонок, которые должны быть разделены запятой (,). |
| scan.filter | Нет | STRING | Условие фильтрации, на основе которого вы хотите фильтровать данные. |
Предположим, что в Flink вы создаете таблицу, состоящую из трех колонок: c1, c2, c3. Чтобы прочитать строки, значения в колонке c1 которых равны 100, вы можете указать два условия фильтрации "scan.columns, "c1" и "scan.filter, "c1 = 100".
Соответствие типов данных между Selena и Flink
Следующее соответствие типов данных действительно только для чтения данных Flink из Selena. Для соответствия типов данных, используемого при записи данных Flink в Selena, см. Непрерывная загрузка данных из Apache Flink®.
| Selena | Flink |
|---|---|
| NULL | NULL |
| BOOLEAN | BOOLEAN |
| TINYINT | TINYINT |
| SMALLINT | SMALLINT |
| INT | INT |
| BIGINT | BIGINT |
| LARGEINT | STRING |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| DATE | DATE |
| DATETIME | TIMESTAMP |
| DECIMAL | DECIMAL |
| DECIMALV2 | DECIMAL |
| DECIMAL32 | DECIMAL |
| DECIMAL64 | DECIMAL |
| DECIMAL128 | DECIMAL |
| CHAR | CHAR |
| VARCHAR | STRING |
| JSON | STRING ПРИМЕЧАНИЕ: Поддерживается с версии 1.2.10 |
| ARRAY | ARRAY ПРИМЕЧАНИЕ: Поддерживается с версии 1.2.10, требуется Selena v1.5.2/v1.5.2 или новее. |
| STRUCT | ROW ПРИМЕЧАНИЕ: Поддерживается с версии 1.2.10, требуется Selena v1.5.2/v1.5.2 или новее. |
| MAP | MAP ПРИМЕЧАНИЕ: Поддерживается с версии 1.2.10, требуется Selena v1.5.2/v1.5.2 или новее. |
Примеры
Следующие примеры предполагают, что вы создали базу данных с именем test в вашем Selena cluster и у вас есть права пользователя root.
ПРИМЕЧАНИЕ
Если задача чтения завершается неудачей, вы должны пересоздать её.
Пример данных
-
Перейдите в базу данных
testи создайте таблицу с именемscore_board.MySQL [test]> CREATE TABLE `score_board`
(
`id` int(11) NOT NULL COMMENT "",
`name` varchar(65533) NULL DEFAULT "" COMMENT "",
`score` int(11) NOT NULL DEFAULT "0" COMMENT ""
)
ENGINE=OLAP
PRIMARY KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`)
PROPERTIES
(
"replication_num" = "3"
); -
Вставьте данные в таблицу
score_board.MySQL [test]> INSERT INTO score_board
VALUES
(1, 'Bob', 21),
(2, 'Stan', 21),
(3, 'Sam', 22),
(4, 'Tony', 22),
(5, 'Alice', 22),
(6, 'Lucy', 23),
(7, 'Polly', 23),
(8, 'Tom', 23),
(9, 'Rose', 24),
(10, 'Jerry', 24),
(11, 'Jason', 24),
(12, 'Lily', 25),
(13, 'Stephen', 25),
(14, 'David', 25),
(15, 'Eddie', 26),
(16, 'Kate', 27),
(17, 'Cathy', 27),
(18, 'Judy', 27),
(19, 'Julia', 28),
(20, 'Robert', 28),
(21, 'Jack', 29); -
Выполните запрос к таблице
score_board.MySQL [test]> SELECT * FROM score_board;
+------+---------+-------+
| id | name | score |
+------+---------+-------+
| 1 | Bob | 21 |
| 2 | Stan | 21 |
| 3 | Sam | 22 |
| 4 | Tony | 22 |
| 5 | Alice | 22 |
| 6 | Lucy | 23 |
| 7 | Polly | 23 |
| 8 | Tom | 23 |
| 9 | Rose | 24 |
| 10 | Jerry | 24 |
| 11 | Jason | 24 |
| 12 | Lily | 25 |
| 13 | Stephen | 25 |
| 14 | David | 25 |
| 15 | Eddie | 26 |
| 16 | Kate | 27 |
| 17 | Cathy | 27 |
| 18 | Judy | 27 |
| 19 | Julia | 28 |
| 20 | Robert | 28 |
| 21 | Jack | 29 |
+------+---------+-------+
21 rows in set (0.00 sec)
Чтение данных с помощью Flink SQL
-
В вашем Flink cluster создайте таблицу с именем
flink_testна основе схемы исходной таблицы Selena (которая в этом примереscore_board). В команде создания таблицы вы должны настроить свойства задачи чтения, включая информацию о Flink connector, исходной базе данных Selena и исходной таблице Selena.CREATE TABLE flink_test
(
`id` INT,
`name` STRING,
`score` INT
)
WITH
(
'connector'='selena',
'scan-url'='192.168.xxx.xxx:8030',
'jdbc-url'='jdbc:mysql://192.168.xxx.xxx:9030',
'username'='xxxxxx',
'password'='xxxxxx',
'database-name'='test',
'table-name'='score_board'
); -
Используйте SELECT для чтения данных из Selena.
SELECT id, name FROM flink_test WHERE score > 20;
При чтении данных с помощью Flink SQL обратите внимание на следующие моменты:
- Вы можете использовать только SQL-инструкции вида
SELECT ... FROM <table_name> WHERE ...для чтения данных из Selena. Из всех агрегатных функций поддерживается толькоcount. - Поддерживается проталкивание предикатов (predicate pushdown). Например, если ваш запрос содержит условие фильтрации
char_1 <> 'A' and int_1 = -126, условие фильтрации будет протолкнуто к Flink connector и преобразовано в инструкцию, которая может быть выполнена Selena, перед выполнением запроса. Вам не нужно выполнять дополнительные настройки. - Инструкция LIMIT не поддерживается.
- Selena не поддерживает механизм checkpointing. В результате согласованность данных не может быть гарантирована при сбое задачи чтения.
- Порядок полей в созданной таблице должен быть таким же, как в таблице Selena.
Чтение данных с помощью Flink DataStream
-
Добавьте следующие зависимости в файл
pom.xml:<dependency>
<groupId>com.selena</groupId>
<artifactId>flink-connector-selena</artifactId>
<!-- для Apache Flink® 1.15 -->
<version>x.x.x_flink-1.15</version>
<!-- для Apache Flink® 1.14 -->
<version>x.x.x_flink-1.14_2.11</version>
<version>x.x.x_flink-1.14_2.12</version>
<!-- для Apache Flink® 1.13 -->
<version>x.x.x_flink-1.13_2.11</version>
<version>x.x.x_flink-1.13_2.12</version>
<!-- для Apache Flink® 1.12 -->
<version>x.x.x_flink-1.12_2.11</version>
<version>x.x.x_flink-1.12_2.12</version>
<!-- для Apache Flink® 1.11 -->
<version>x.x.x_flink-1.11_2.11</version>
<version>x.x.x_flink-1.11_2.12</version>
</dependency>Вы должны заменить
x.x.xв приведенном выше примере кода на последнюю версию Flink connector, которую вы используете. См. Информация о версии. -
Вызовите Flink connector для чтения данных из Selena:
import com.selena.connector.flink.SelenaSource;
import com.selena.connector.flink.table.source.SelenaSourceOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.TableSchema;
public class SelenaSourceApp {
public static void main(String[] args) throws Exception {
SelenaSourceOptions options = SelenaSourceOptions.builder()
.withProperty("scan-url", "192.168.xxx.xxx:8030")
.withProperty("jdbc-url", "jdbc:mysql://192.168.xxx.xxx:9030")
.withProperty("username", "root")
.withProperty("password", "")
.withProperty("table-name", "score_board")
.withProperty("database-name", "test")
.build();
TableSchema tableSchema = TableSchema.builder()
.field("id", DataTypes.INT())
.field("name", DataTypes.STRING())
.field("score", DataTypes.INT())
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(SelenaSource.source(tableSchema, options)).setParallelism(5).print();
env.execute("Selena flink source");
}
}
Часто задаваемые вопросы
Я получил ошибку "Failed to get next from be" при экспорте данных с помощью Flink Connector. Что мне делать?
Вы можете установить конфигурацию BE scan_context_gc_interval_min (По умолчанию: 5, Единица: Минуты) на большее значение, чтобы увеличить временной интервал, с которым очищается Scan Context.
Что дальше
После того как Flink успешно прочитает данные из Selena, вы можете использовать Flink WebUI для мониторинга задачи чтения. Например, вы можете просмотреть метрику totalScannedRows на странице Metrics WebUI, чтобы получить количество успешно прочитанных строк. Вы также можете использовать Flink SQL для выполнения вычислений, таких как joins, на прочитанных данных.