Создание разбитого материализованного представления
В этом разделе описано, как соз�дать разбитое материализованное представление для различных вариантов использования.
Обзор
Асинхронные материализованные представления Selena поддерживают различные стратегии partitioning и функции, которые позволяют достичь следующих эффектов:
-
Инкрементное построение
При создании разбитого материализованного представления вы можете настроить задачу создания на обновление partition партиями, чтобы избежать чрезмерного потребления ресурсов.
-
Инкрементное обновление
Вы можете настроить задачу обновления на обновление только соответствующих partition материализованного представления, когда она обнаруживает изменения данных в определенных partition базовой таблицы. Обновление на уровне partition может значительно предотвратить потерю ресурсов, используемых для обновления всего материализованного представления.
-
Частичная материализация
Вы можете установить TTL для partition материализованного представления, что позволяет частичную материализацию данных.
-
Прозрачная перезапись запросов
Запросы могут быть прозрачно перезаписаны на основе только тех обновленных partition материализованного представления. Partition, которые считаются устаревшими, не будут участвовать в плане запроса, и запрос будет выполнен на базовых таблицах для гарантии согласованности данных.
Ограничения
Разбитое материализованное представление может быть создано только на основе разбитой базовой таблицы (обычно таблицы фактов). Только путем отображения отношения partition между базовой таблицей и материализованным представлением вы можете построить синергию между ними.
В настоящее время Selena поддерживает создание разбитых материализованных представлений на таблицах из следующих источников данных:
- Таблицы Selena OLAP в catalog по умолчанию
- Поддерживаемая стратегия partitioning: Range partitioning, List Partitioning и Expression Partitioning
- Поддерживаемые типы данных для Partitioning Key: INT, DATE, DATETIME и STRING
- Поддерживаемые типы таблиц: Primary Key, Duplicate Key, Aggregate Key и Unique Key
- Поддерживается как в shared-nothing cluster, так и в shared-data cluster
- Таблицы в Hive Catalog, Hudi Catalog, Iceberg Catalog и Paimon Catalog
- Поддерживаемый уровень partitioning: Основной уровень
- Поддерживаемые типы данных для Partitioning Key: INT, DATE, DATETIME и STRING
- Вы не можете создать разбитое материализованное представление на основе неразбитой базовой (фактовой) таблицы.
- Для таблиц Selena OLAP две соседние partition базовой таблицы должны иметь последовательные диапазоны.
- Для многоуровневых разбитых базовых таблиц во внешних catalog только путь partitioning основного уровня может быть использован для создания разбитого материализованного представления. Например, для таблицы, разбитой в формате
yyyyMMdd/hour, вы можете построить материализованное представление, разбитое только поyyyyMMdd. - Начиная с v1.5.2, Selena поддерживает создание разбитых материализованных представлений на таблицах Iceberg с Partition Transforms, и материализованные представления разбиваются по столбцу после преобразования. Для получения дополнительной информации см. Data lake query acceleration with materialized views - Choose a suitable refresh strategy.
Варианты использования
Предположим, что есть базовые таблицы следующим образом:
CREATE TABLE IF NOT EXISTS par_tbl1 (
datekey DATE, -- Столбец даты типа DATE, используемый как Partitioning Key.
k1 STRING,
v1 INT,
v2 INT
)
ENGINE=olap
PARTITION BY RANGE (datekey) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(k1);
CREATE TABLE IF NOT EXISTS par_tbl2 (
datekey STRING, -- Столбец даты типа STRING, используемый как Partitioning Key.
k1 STRING,
v1 INT,
v2 INT
)
ENGINE=olap
PARTITION BY RANGE (str2date(datekey, '%Y-%m-%d')) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(k1);
CREATE TABLE IF NOT EXISTS par_tbl3 (
datekey_new DATE, -- Эквивалентный столбец с par_tbl1.datekey.
k1 STRING,
v1 INT,
v2 INT
)
ENGINE=olap
PARTITION BY RANGE (datekey_new) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(k1);
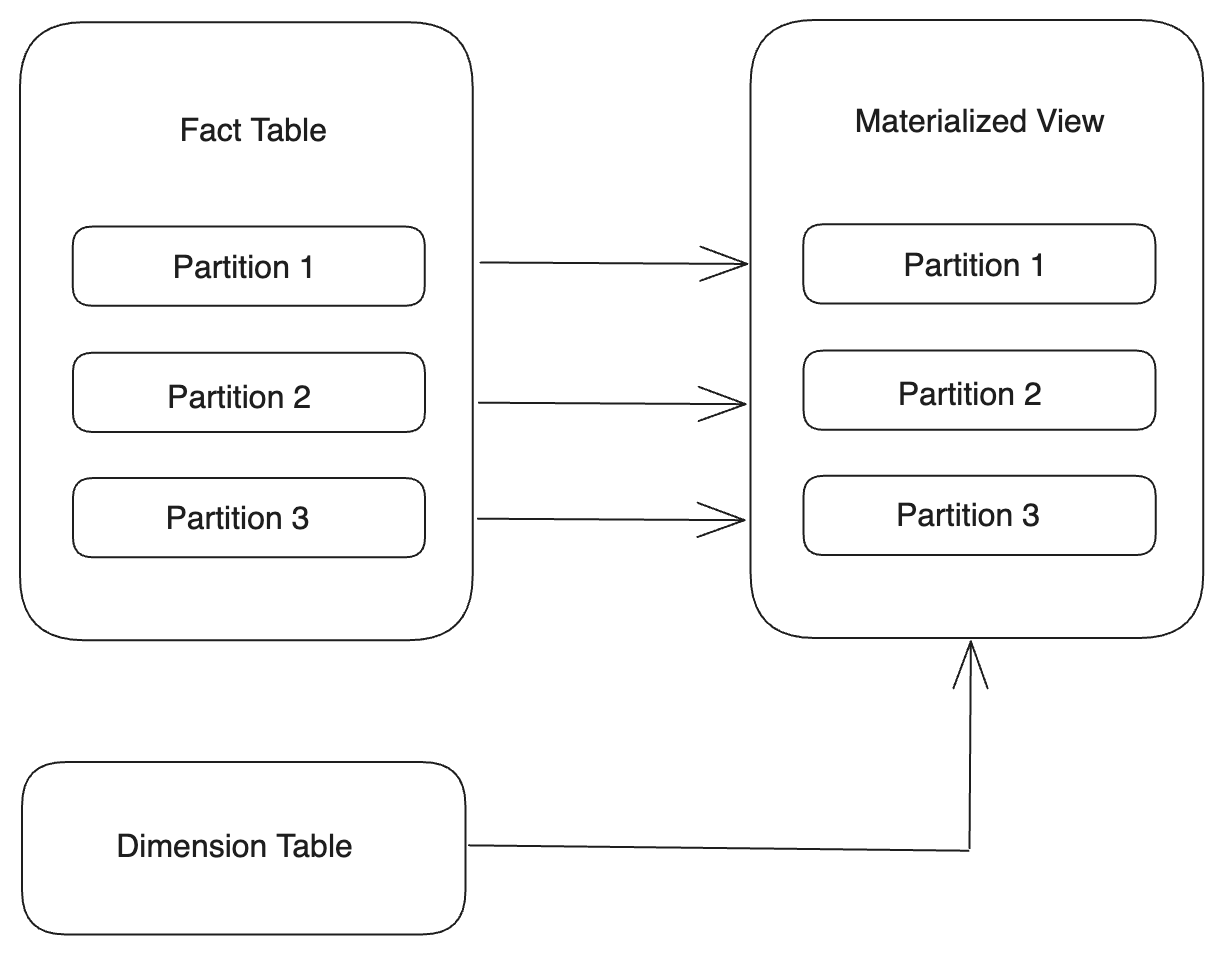
Выравнивание partition один к одному
Вы можете создать материализованное представление, partition которого соответствуют partition базовой таблицы один к одному, используя тот же Partitioning Key.
-
Если Partitioning Key базовой таблицы имеет тип DATE или DATETIME, вы можете напрямую указать тот же Partitioning Key для материализованного представления.
PARTITION BY <base_table_partitioning_column>Пример:
CREATE MATERIALIZED VIEW par_mv1
REFRESH ASYNC
PARTITION BY datekey
AS
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
GROUP BY datekey, k1; -
Если Partitioning Key базовой таблицы имеет тип STRING, вы можете использовать функцию str2date для преобразования строки даты в тип DATE или DATETIME.
PARTITION BY str2date(<base_table_partitioning_column>, <format>)Пример:
CREATE MATERIALIZED VIEW par_mv2
REFRESH ASYNC
PARTITION BY str2date(datekey, '%Y-%m-%d')
AS
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl2
GROUP BY datekey, k1;
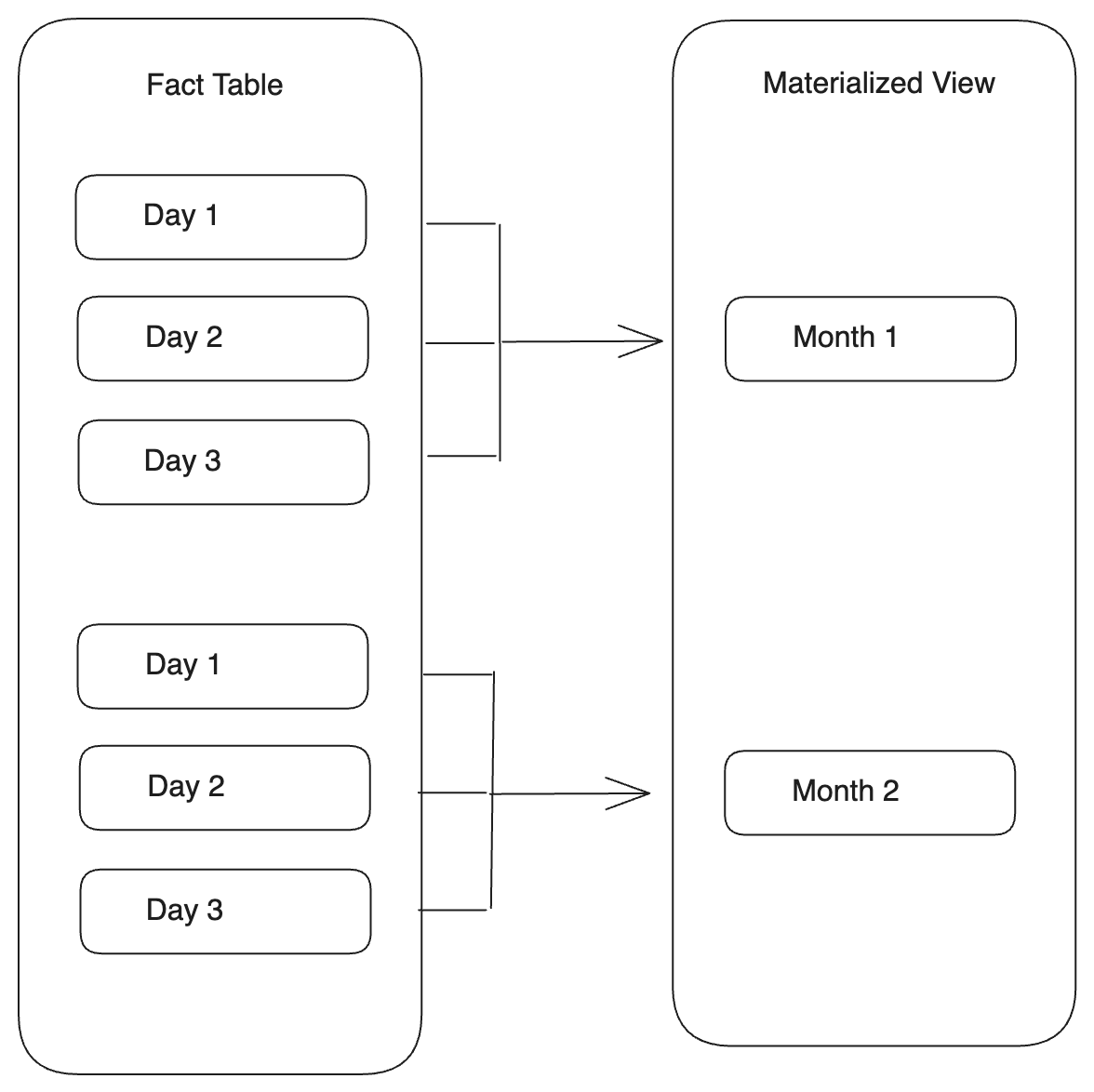
Выравнивание partition с сворачиванием временной детализации
Вы можете создать материализованное представление, детализация partitioning которого больше, чем у базовой таблицы, используя функцию date_trunc на Partitioning Key. Когда обнаруживаются изменения данных в partition базовой таблицы, Selena обновляет соответствующие свёрнутые partition в материализованном представлении.
-
Если Partitioning Key базовой таблицы имеет тип DATE или DATETIME, вы можете напрямую использовать функцию date_trunc на Partitioning Key базовой таблицы.
PARTITION BY date_trunc(<format>, <base_table_partitioning_column>)Пример:
CREATE MATERIALIZED VIEW par_mv3
REFRESH ASYNC
PARTITION BY date_trunc('month', datekey)
AS
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
GROUP BY datekey, k1; -
Если Partitioning Key базовой таблицы имеет тип STRING, вы должны преобразовать Partitioning Key базовой таблицы в тип DATE или DATETIME в списке SELECT, установить для него псевдоним и использовать его в функции date_trunc для указания Partitioning Key материализованного представления.
PARTITION BY
date_trunc(<format>, <mv_partitioning_column>)
AS
SELECT
str2date(<base_table_partitioning_column>, <format>) AS <mv_partitioning_column>Пример:
CREATE MATERIALIZED VIEW par_mv4
REFRESH ASYNC
PARTITION BY date_trunc('month', mv_datekey)
AS
SELECT
datekey,
k1,
sum(v1) AS SUM,
str2date(datekey, '%Y-%m-%d') AS mv_datekey
FROM par_tbl2
GROUP BY datekey, k1;
Выравнивание partition с настраиваемой временной детализацией
Метод сворачивания partition, упомянутый выше, позволяет разбивать материализованное представление только на основе конкретных временных детализаций и не позволяет настраивать диапазон времени partition. Если вашему бизнес-сценарию требуется partitioning с использованием настраиваемой временной детализации, вы можете создать материализованное представление и определить временную детализацию для его partition, используя функцию date_trunc с функцией time_slice, которая может преобразовать заданное время в начало или конец временного интервала на основе указанной временной детализации.
Вам необходимо определить новую временную детализацию (интервал), используя функцию time_slice на Partitioning Key базовой таблицы в списке SELECT, установить для него псевдоним и использовать его в функции date_trunc для указания Partitioning Key материализованного представления.
PARTITION BY
date_trunc(<format>, <mv_partitioning_column>)
AS
SELECT
-- Вы можете использовать time_slice.
time_slice(<base_table_partitioning_column>, <interval>) AS <mv_partitioning_column>
Пример:
CREATE MATERIALIZED VIEW par_mv5
REFRESH ASYNC
PARTITION BY date_trunc('day', mv_datekey)
AS
SELECT
k1,
sum(v1) AS SUM,
time_slice(datekey, INTERVAL 5 MINUTE) AS mv_datekey
FROM par_tbl1
GROUP BY datekey, k1;
Выравнивание partition с несколькими базовыми таблицами
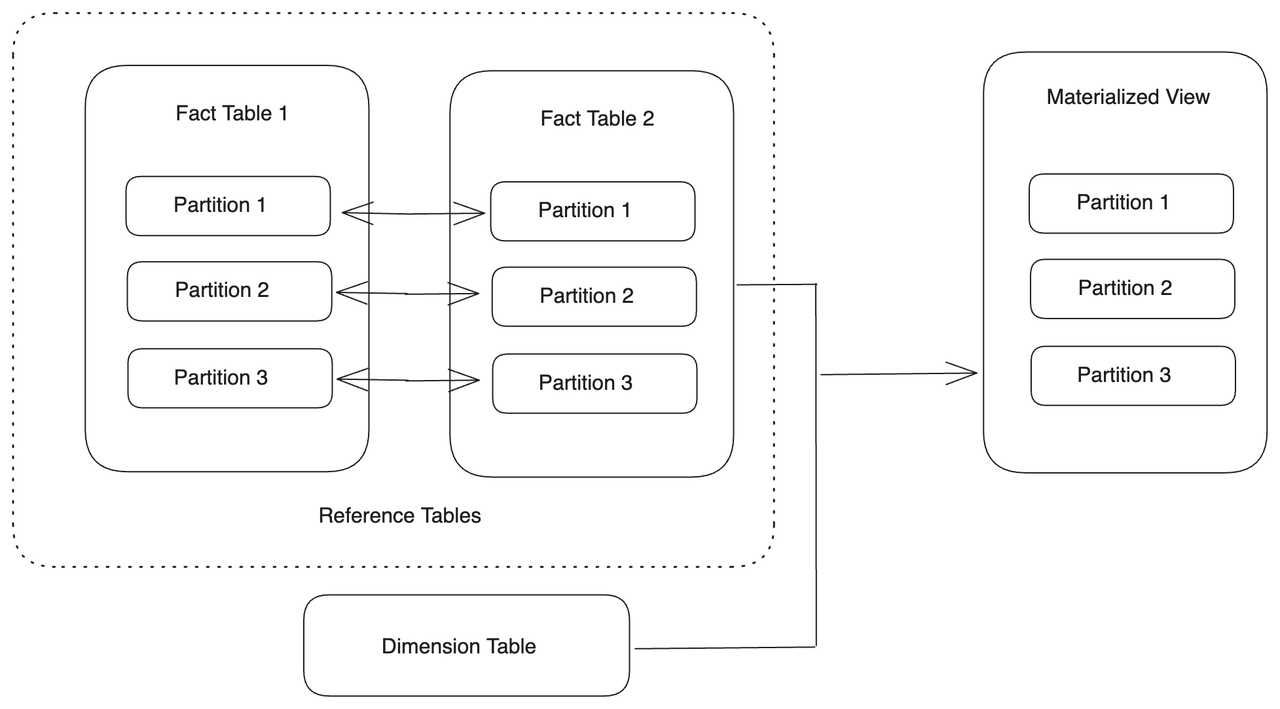
Вы можете создать материализованное представление, partition которого выровнены с partition нескольких базовых таблиц, если partition базовых таблиц могут выравниваться друг с другом, то есть базовые таблицы используют один и тот же тип Partitioning Key. Вы можете использовать JOIN для соединения базовых таблиц и установить Partition Key в качестве общего столбца. Альтернативно, вы можете соединить их с помощью UNION. Базовые таблицы с выровненными partition называются справочными таблицами. Изменения данных в любой из справочных таблиц запустят задачу обновления соответствующих partition материализованного представления.
Эта функция поддерживается начиная с v1.5.2.
-- Соединение таблиц с помощью JOIN.
CREATE MATERIALIZED VIEW par_mv6
REFRESH ASYNC
PARTITION BY datekey
AS SELECT
par_tbl1.datekey,
par_tbl1.k1 AS t1k1,
par_tbl3.k1 AS t2k1,
sum(par_tbl1.v1) AS SUM1,
sum(par_tbl3.v1) AS SUM2
FROM par_tbl1 JOIN par_tbl3 ON par_tbl1.datekey = par_tbl3.datekey_new
GROUP BY par_tbl1.datekey, t1k1, t2k1;
-- Соединение таблиц с помощью UNION.
CREATE MATERIALIZED VIEW par_mv7
REFRESH ASYNC
PARTITION BY datekey
AS SELECT
par_tbl1.datekey,
par_tbl1.k1 AS t1k1,
sum(par_tbl1.v1) AS SUM1
FROM par_tbl1
GROUP BY
par_tbl1.datekey,
par_tbl1.k1
UNION ALL
SELECT
par_tbl3.datekey_new,
par_tbl3.k1 AS t2k1,
sum(par_tbl3.v1) AS SUM2
FROM par_tbl3
GROUP BY
par_tbl3.datekey_new,
par_tbl3.k1;
Выравнивание нескольких столбцов partition
Начиная с v1.5.2, асинхронные материализованные представления поддерживают многостолбцовые выражения partition. Вы можете указать несколько столбцов partition для материализованного представления и отобразить их один к одному на столбцы partition базовых таблиц. Это обеспечивает интеграцию Lakehouse и улучшает повторное использование существующих возможностей внутренних таблиц Selena, предоставляя лучшее решение Lakehouse:
- Упрощенный пользовательский опыт: Упрощает процесс переноса данных из Data Lake в Selena.
- Ускоренная производительность запросов: Повторно использует возможности нативных таблиц, такие как Colocate Group, Bitmap Index, Bloom Filter Index, Sort Key и глобальные словари при создании материализованных представлений. Запросы, напрямую ссылающиеся на базовую таблицу, будут получать преимущества от прозрачного ускорения запросов через автоматическую перезапись.
Примечания к многостолбцовым выражениям partition
-
В настоящее время многостолбцовые partition в материализованных представлениях могут быть отображены только один к одному или в отношении N:1 с partition базовой таблицы, а не в отношении M:N. Например, если базовая таблица имеет столбцы partition
(col1, col2, ..., coln), выражение partition материализованного представления может быть только одностолбцовым partition, таким какcol1,col2илиcoln, или отображением один к одному со столбцами partition базовой таблицы, то есть(col1, col2, ..., coln). Это ограничение разработано для упрощения логики отображения partition между базовой таблицей и материализованным представлением, избегая сложности, вносимой отношениями M:N. -
Поскольку выражения partition Iceberg поддерживают функцию
transform, требуется дополнительная обработка при отображении выражений partition Iceberg на выражения partition материализованного представления Selena. Отношение отображения следующее:Iceberg Transform Выражение partition Iceberg Выражение partition материализованного представления Identity <col><col>hour hour(<col>)date_trunc('hour', <col>)day day(<col>)date_trunc('day', <col>)month month(<col>)date_trunc('month', <col>)year year(<col>)date_trunc('year', <col>)bucket bucket(<col>, <n>)Не поддерживается truncate truncate(<col>)Не поддерживается -
Для столбцов partition не-Iceberg, где вычисление выражения partition не требуется, дополнительная обработка выражения partition не требуется. Вы можете отобразить их напрямую.
Следующий пример создает разбитое материализованное представление с многостолбцовым выражением partition на основе базовой таблицы из Iceberg Catalog (Spark).
Определение базовой таблицы в Spark:
-- Выражение partition базовой таблицы содержит несколько столбцов и преобразование `days`.
CREATE TABLE lineitem_days (
l_orderkey BIGINT,
l_partkey INT,
l_suppkey INT,
l_linenumber INT,
l_quantity DECIMAL(15, 2),
l_extendedprice DECIMAL(15, 2),
l_discount DECIMAL(15, 2),
l_tax DECIMAL(15, 2),
l_returnflag VARCHAR(1),
l_linestatus VARCHAR(1),
l_shipdate TIMESTAMP,
l_commitdate TIMESTAMP,
l_receiptdate TIMESTAMP,
l_shipinstruct VARCHAR(25),
l_shipmode VARCHAR(10),
l_comment VARCHAR(44)
) USING ICEBERG
PARTITIONED BY (l_returnflag, l_linestatus, days(l_shipdate));
Создайте материализованное представление со столбцами partition, отображенными один к одному со столбцами базовой таблицы:
CREATE MATERIALIZED VIEW test_days
PARTITION BY (l_returnflag, l_linestatus, date_trunc('day', l_shipdate))
REFRESH DEFERRED MANUAL
AS
SELECT * FROM iceberg_catalog.test_db.lineitem_days;
Достижение инкрементного обновления и прозрачной перезаписи
Вы можете создать разбитое материализованное представление, которое обновляется по partition для достижения инкрементных обновлений материализованного представления и прозрачной перезаписи запросов с частичной материализацией данных.
Для достижения этих целей вы должны учитывать следующие аспекты при создании материализованного представления:
-
Детализация обновления
Вы можете использовать свойство
partition_refresh_numberдля указания детализации каждой операции обновления.partition_refresh_numberконтролирует максимальное количество partition, которые необходимо обновить в задаче обновления, когда запускается обновление. Если количество partition, которые необходимо обновить, превышает это значение, Selena разделит задачу обновления и выполнит её партиями. Partition обновляются в хронологическом порядке от наименее недавней partition к наиболее недавней partition (исключая partition, созданные динамически для будущего). Когда значение равно-1, задача обновления не будет разделена. Значение по умолчанию изменено с-1на1начиная с v1.5.2, что означает, что Selena обновляет partition по одной.Вы также можете использовать свойство
partition_refresh_strategyдля контроля адаптивности стратегии обновления. Этот параметр поддерживает следующие два значения:- "strict" (по умолчанию): Обновление partition строго следует настройке partition_refresh_number для контроля детализации обновления.
- "adaptive": Адаптивно регулирует количество partition, обновляемых за одну партию, на основе объема данных в partition базовой таблицы, повышая эффективность обновления.
-
Область материализации
Область материализованных данных контролируется свойствами
partition_ttl_number(для версий ранее v1.5.2) илиpartition_ttl(рекомендуется для v1.5.2 и более поздних версий).partition_ttl_numberуказывает количество самых последних partition для сохранения, аpartition_ttlуказывает временной диапазон данных материализованного представления для сохранения. Во время каждого обновления Selena упорядочивает partition в хронологическом порядке и сохраняет только те, которые удовлетворяют требованиям TTL. -
Стратегия обновления
- Материализованные представления с автоматическими стратегиями обновления (
REFRESH ASYNC) автоматически обновляются каждый раз при изменении данных базовой таблицы. - Материализованные представления с регулярными стратегиями обновления (
REFRESH ASYNC [START (<start_time>)] EVERY (INTERVAL <interval>)) обновляются регулярно с определенным интервалом.
примечаниеМатериализованные представления с автоматическими стратегиями обновления и регулярными стратегиями обновления обновляются автоматически после запуска задач обновления. Selena записывает и сравнивает версии данных каждой partition базовой таблицы. Изменение версии данных указывает на изменение данных в partition. Как только Selena обнаруживает изменение данных в partition базовой таблицы, она обновляет соответствующую partition материализованного представления. Когда изменения данных в partition базовой таблицы не обнаружены, обновление соответствующей partition материализованного представления пропускается.
- Материализованные представления с ручными стратегиями обновления (
REFRESH MANUAL) могут быть обновлены только путем ручного выполнения оператора REFRESH MATERIALIZED VIEW. Вы можете указать временной диапазон partition, которые необходимо обновить, чтобы избежать обновления всего материализованного представления. Если вы укажетеFORCEв операторе, Selena принудительно обновит соответствующее материализованное представление или partition независимо от того, изменились ли данные в базовой таблице. ДобавивWITH SYNC MODEк оператору, вы можете сделать синхронный вызов задачи обновления, и Selena вернет результат задачи только тогда, когда задача завершится успешно или неудачно.
- Материализованные представления с автоматическими стратегиями обновления (
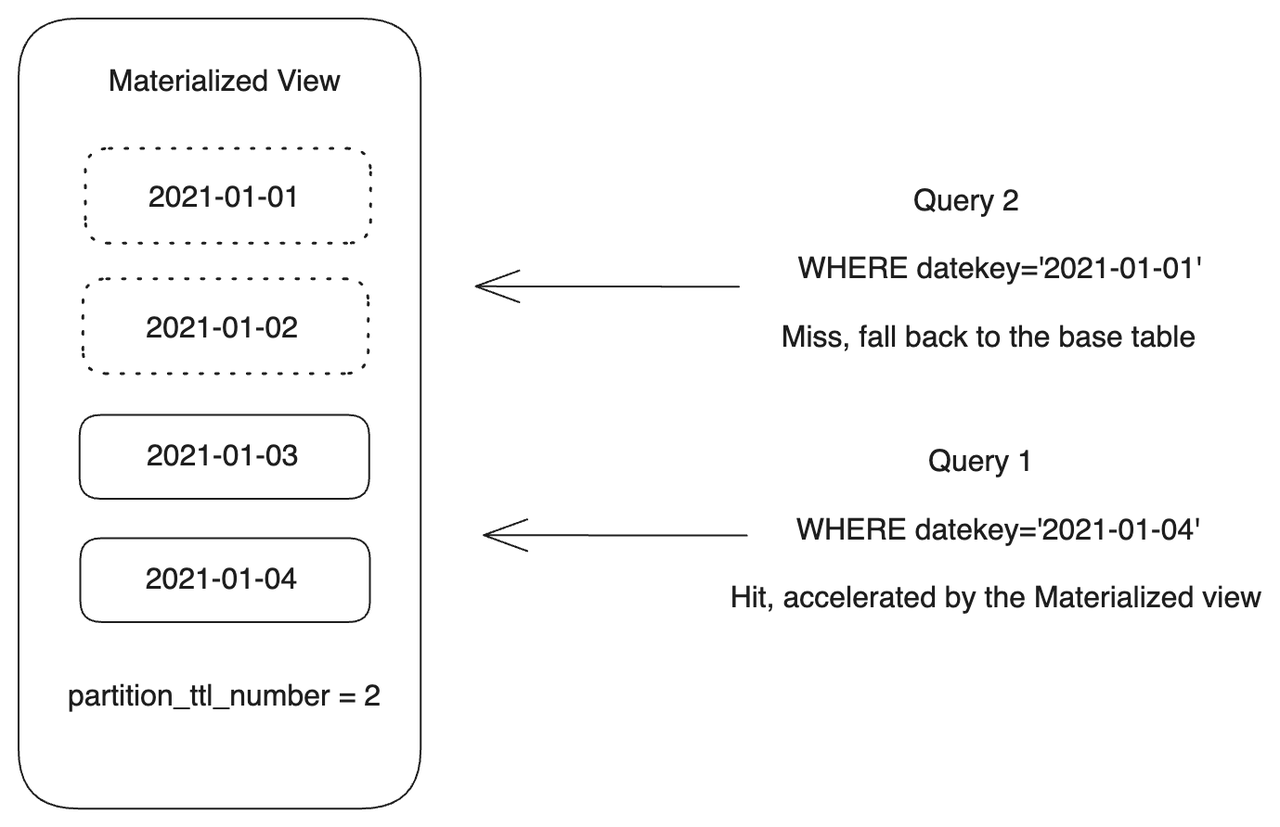
Следующий пример создает разбитое материализованное представление par_mv8. Если Selena обнаруживает изменения данных в partition базовой таблицы, она обновляет соответствующую partition в материализованном представлении. Задача обновления разделяется на партии, каждая из которых обновляет только одну partition ("partition_refresh_number" = "1"). Сохраняются только две самые последние partition ("partition_ttl_number" = "2"), остальные удаляются во время обновления.
CREATE MATERIALIZED VIEW par_mv8
REFRESH ASYNC
PARTITION BY datekey
PROPERTIES(
"partition_ttl_number" = "2",
"partition_refresh_number" = "1"
)
AS
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
GROUP BY datekey, k1;
Вы можете использовать оператор REFRESH MATERIALIZED VIEW для обновления этого материализованного представления. Следующий пример выполняет синхронный вызов для принудительного обновления некоторых partition par_mv8 в определенном временном диапазоне.
REFRESH MATERIALIZED VIEW par_mv8
PARTITION START ("2021-01-03") END ("2021-01-04")
FORCE WITH SYNC MODE;
Вывод:
+--------------------------------------+
| QUERY_ID |
+--------------------------------------+
| 1d1c24b8-bf4b-11ee-a3cf-00163e0e23c9 |
+--------------------------------------+
1 row in set (1.12 sec)
С функцией TTL в par_mv8 сохраняются только некоторые partition. Таким образом, вы достигли материализации частичных данных, что важно в сценариях, где большинство запросов направлены на недавние данные. Функция TTL позволяет прозрачно ускорять запросы на новые данные (например, в течение недели или месяца) с помощью материализованного представления, при этом значительно экономя затраты на хранение. Запросы, которые не попадают в этот временной диапазон, направляются к базовой таблице.
В следующем примере запрос 1 будет ускорен материализованным представлением, потому что он попадает в partition, которая сохранена в par_mv8, в то время как запрос 2 будет направлен к базовой таблице, потому что он не попадает во временной диапазон, где сохранены partition.
-- Запрос 1
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
WHERE datekey='2021-01-04'
GROUP BY datekey, k1;
-- Запрос 2
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
WHERE datekey='2021-01-01'
GROUP BY datekey, k1;