Моделирование данных с помощью материализованных представлений
Этот раздел описывает, как выполнять моделирование данных с помощью асинхронных материализованных представлений Selena. Таким образом, вы можете значительно упростить ETL pipeline вашего хранилища данных и значительно улучшить качество данных и производительность запросов.
Обзор
Моделирование данных — это процесс очистки, наслоения, агрегации и связывания данных с рациональными методологиями. Оно может создать понятное представление сырых данных, которые слишком грубые, слишком сложные или слишком дорогие для прямого анализа, и предоставить действенные инсайты в данные.
Однако, обычная проблема в реальном моделировании данных заключается в том, что процесс моделирования с трудом поспевает за темпами развития бизнеса, и трудно измерить возврат инвестиций для усилий по моделированию данных. Несмотря на то, что методологии моделирования просты, бизнес-эксперты должны иметь прочную основу в организации и управлении данными, что является сложным процессом. На ранних стадиях бизнеса лица, принимающие решения, редко выделяют достаточные ресурсы для моделирования данных, и трудно увидеть ценность, которую может принести моделирование данных. Более того, бизнес-модели могут быстро меняться, и сами методологии моделирования нуждаются в итерации и эволюции. Поэтому многие аналитики данных склонны избегать моделирования и использовать сырые данные напрямую, что неизбежно приводит к проблемам качества данных и производительности запросов. Когда возникает необходимость в моделировании, становится трудно реструктурировать паттерны аналитики данных, которые уже были установлены, чтобы соответствовать моделям данных.
Использование материализованных представлений для моделирования данных может эффективно решить эти проблемы. Асинхронные материализованные представления Selena могут:
- Упростить архитектуру хранилища данных: Поскольку Selena может предоставить комплексный опыт управления данными, вам не нужно поддерживать другие системы обработки данных, экономя человеческие и системные ресурсы, потраченные на них.
- Облегчить опыт моделирования данных: Любой аналитик данных, обладающий только базовыми знаниями SQL, способен выполнять моделирование данных с помощью Selena. Моделирование данных больше не является исключительной прерогативой опытных инженеров данных.
- Снизить сложность обслуживания: Асинхронные материализованные представления Selena могут автоматически управлять связями происхождения и зависимостями между слоями данных, устраняя необходимость в целой платформе данных для выполнения этой задачи.
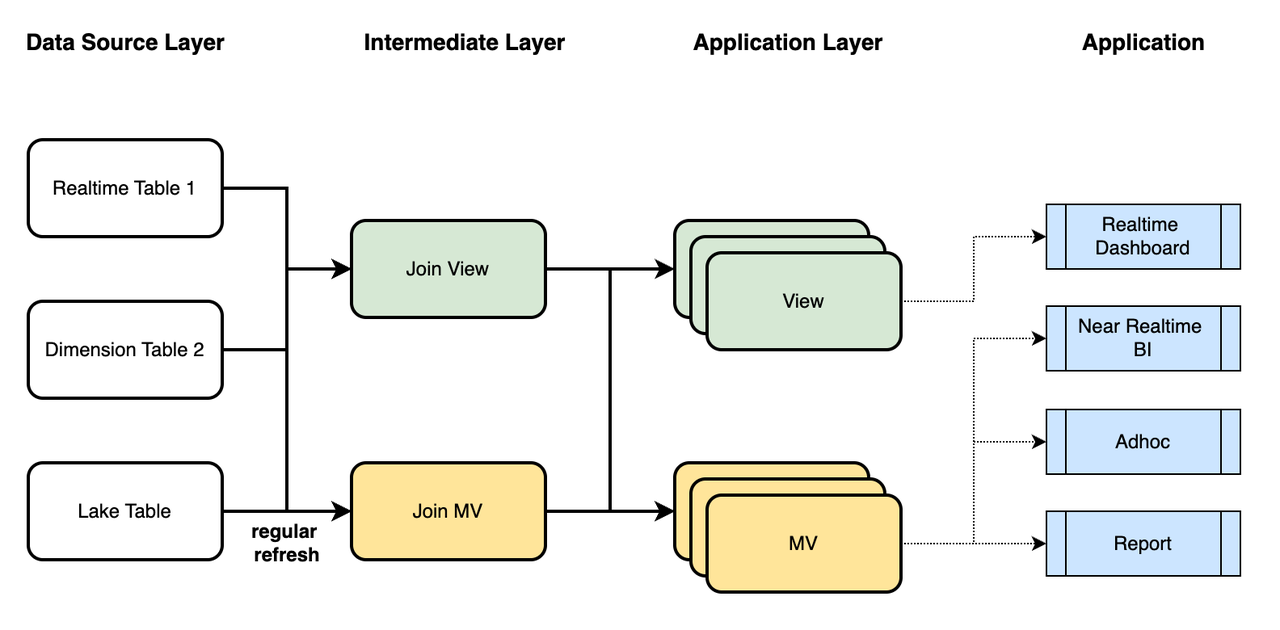
В реальных ситуациях вы можете выполнять моделирование данных, комбинируя использование представлений (логических представлений) Selena и асинхронных материализованных представлений следующим образом:
- Используйте представления для связывания real-time данных с данными измерений и используйте материализованные представления для связывания исторических данных из озера данных с данными измерений. Выполните необходимую очистку данных и семантическое отображение, чтобы получить детальные данные для промежуточного слоя, которые отражают семантику, требуемую в ваших бизнес-сценариях.
- На уровне приложения выполняйте вычисления Join, Aggregation, Union и Window, адаптированные для различных бизнес-сценариев. Это даст представления для real-time конвейеров и материализованные представления для near-real-time конвейеров.
- На стороне приложения выберите подходящее аналитическое хранилище данных (ADS) для анализа запросов на основе ваших требований к своевременности и производительности. Эти ADS могут обслуживать real-time дашборды, near-real-time BI, ad-hoc запросы и запланированные отчеты.
В течение этого процесса вы будете использовать несколько встроенных возможностей Selena, которые будут подробно описаны в следующем разделе.
Возможности асинхронного материализованного представления
Асинхронное материализованное представление Selena обладает следующими атомарными функциями, которые могут помочь в моделировании данных:
- Автоматическое обновление: После загрузки данных в базовые таблицы материализованные представления могут автоматически обновляться. Вам не нужно поддерживать задачу планирования извне.
- Partitioned обновление: Near-real-time вычисления могут быть достигнуты через partitioned обновление материализованных представлений, построенных на таблицах с временными рядами.
- Синергия с представлениями: Вы можете достичь многоуровневого моделирования, используя материализованные представления и логические представления, тем самым обеспечивая повторное использование промежуточного слоя и упрощение моделей данных.
- Изменение схемы: Вы можете изменить результаты вычислений с помощью простых операторов SQL, без необходимости изменять сложные data pipelines.
С этими функциями вы можете разработать комплексные и адаптивные модели данных для удовлетворения различных бизнес-потребностей и сценариев.
Автоматическое обновление
При создании асинхронного материализованного представления вы можете указать стратегию обновления, используя оператор REFRESH. В настоящее время Selena поддерживает следующие стратегии обновления асинхронных материализованных представлений:
- Автоматическое обновление (
REFRESH ASYNC): Задачи обновления запускаются каждый раз, когда данные в базовых таблицах изменяются. Зависимости данных автоматически управляются материализованным представлением. - Запланированное обновление (
REFRESH ASYNC EVERY (INTERVAL <refresh_interval>)): Задачи обновления запускаются через регулярные интервалы, например, каждую минуту, день или месяц. Если нет изменений данных в базовых таблицах, задача обновления не будет запущена. - Ручное обновление (
REFRESH MANUAL): Задачи обновления запускаются только путем выполнения REFRESH MATERIALIZED VIEW вручную. Эта стратегия обновления может использоваться, когда вы поддерживаете внешний framework планирования для запуска задач обновления.
Синтаксис:
CREATE MATERIALIZED VIEW <name>
REFRESH
[ ASYNC |
ASYNC [START <time>] EVERY(<interval>) |
MANUAL
]
AS <query>
Partitioned обновление
При создании асинхронного материализованного представления вы можете указать оператор PARTITION BY для связывания partitions базовой таблицы с partitions материализованного представления, достигая таким образом обновления на уровне partition.
PARTITION BY <column>: Вы можете ссылаться на тот же столбец partitioning для базовой таблицы и материализованного представления. В результате базовая таблица и материализованное представление разбиты на partition с одинаковой гранулярностью.PARTITION BY date_trunc(<column>): Вы можете использовать функцию date_trunc для назначения другой стратегии partition (на уровне гранулярности) для материализованного представления путем усечения единицы времени.PARTITION BY { time_slice | date_slice }(<column>): По сравнению с date_trunc, time_slice и date_slice предлагают более гибкие настройки гранулярности времени, позволяя более точный контроль над partitioning на основе времени.
Синтаксис:
CREATE MATERIALIZED VIEW <name>
REFRESH ASYNC
PARTITION BY
[
<base_table_column> |
date_trunc(<granularity>, <base_table_column>) |
time_slice(<base_table_column>, <granularity>) |
date_slice(<base_table_column>, <granularity>)
]
AS <query>
Синергия с представлениями
- Материализованные представления могут быть созданы на основе представлений. В этом случае, когда базовые таблицы, на которые ссылается представление, претерпевают изменения данных, материализованное представление может автоматически обновляться.
- Вы также можете создавать материализованные представления на основе других материализованных представлений, обеспечивая многоуровневые каскадные механизмы обновления.
- Представления могут быть созданы на основе материализованных представлений, которые эквивалентны обычным таблицам.
Изменение схемы
- Вы можете выполнить атомарный обмен между двумя асинхронными материализованными представлениями, используя оператор ALTER MATERIALIZED VIEW SWAP. Это позволяет создать новое материализованное представление с добавленными столбцами или измененными типами столбцов, а затем заменить старое им.
- Определение представлений может быть напрямую изменено с помощью оператора ALTER VIEW.
- Обычные таблицы в Selena могут быть изменены либо с помощью операций SWAP, либо ALTER.
- Кроме того, когда есть изменения в базовых таблицах (которыми могут быть материализованные представления, представления или обычные таблицы), это запускает каскадные изменения в соответствующих материализованных представлениях.
Многоуровневое моделирование
Во многих реальных бизнес-сценариях существуют различные формы источников данных, включая real-time детальные данные, данные �измерений и исторические данные из озер данных. С другой стороны, бизнес-требования требуют разнообразных аналитических методов, таких как real-time дашборды, near-real-time BI запросы, ad-hoc запросы и запланированные отчеты. Различные сценарии имеют разные требования — некоторые требуют гибкости, некоторые приоритизируют производительность, в то время как другие подчеркивают экономическую эффективность.
Очевидно, что одно решение не может адекватно удовлетворить такие универсальные требования. Selena может эффективно удовлетворить эти потребности, комбинируя использование представлений и материализованных представлений. Поскольку представления не поддерживают физических данных, каждый раз, когда запрашивается представление, запрос анализируется и выполняется в соответствии с определением представления. Для сравнения, материализованные представления, которые содержат предварительно вычисленные результаты, могут предотвратить накладные расходы повторного выполнения. Представления подходят для выражения бизнес-семантики и упрощения сложности SQL, но они не могут снизить затраты на выполнение запросов. Материализованные представления, с другой стороны, оптимизируют производительность запросов через предварительное вычисление и подходят для упрощения ETL pipelines.
Ниже приводится сводка различий между представлениями и материализованными представлениями:
| Представление | Материализованное представление | |
|---|---|---|
| Случаи использования | Бизнес-моделирование, управление данными | Моделирование данных, прозрачное ускорение, интеграция озера данных |
| Стоимость хранения | Нет стоимости хранения | Стоимость хранения возникает при хранении предварительно вычисленных результатов |
| Стоимость обновления | Нет стоимости обновления | Стоимость обновления возникает при обновлении данных базовой таблицы |
| Преимущества производительности | Нет преимущества производительности | Ускорение запросов за счет повторного использования предварительно вычисленных результатов |
| Атрибут real-time данных | Возвращаются последние данные, потому что запросы к представлениям вычисляются в real-time. | Данные могут быть не актуальными, потому что результаты предварительно вычислены. |
| Зависимость | Представления становятся недействительными, если имена базовых таблиц изменены, потому что они ссылаются на базовые таблицы по имени. | Изменения имен базовых таблиц не влияют на доступность материализованных представлений, которые ссылаются на базовые таблицы по ID. |
| Синтаксис создания | CREATE VIEW | CREATE MATERIALIZED VIEW |
| Синтаксис изменения | ALTER VIEW | ALTER MATERIALIZED VIEW |
Вы можете использовать следующие операторы для изменения ваших представлений, материализованных представлений и базовых таблиц:
-- Изменить таблицу.
ALTER TABLE <table_name> ADD COLUMN <column_desc>;
-- Обменять две таблицы.
ALTER TABLE <table1> SWAP WITH <table2>;
-- Изменить определение представления.
ALTER VIEW <view_name> AS <query>;
-- Обменять два материализованных представления
-- (путем обмена имени двух материализованных представлений без влияния на данные внутри).
ALTER MATERIALIZED VIEW <mv1> SWAP WITH <mv2>;
-- Повторно активировать материализованное представление.
ALTER MATERIALIZED VIEW <mv_name> ACTIVE;
Изменения схемы следуют этим принципам:
- Операции Rename и Swap для таблицы устанавливают зависимые материализованные представления неактивными. Для операций Schema Change зависимые материализованные представления устанавливаются неактивными только когда операции Schema Change выполняются для столбцов базовой таблицы, на которые ссылаются материализованны�е представления.
- Если вы изменяете определение представления, зависимые материализованные представления устанавливаются неактивными.
- Если материализованное представление обменивается, любые вложенные материализованные представления, построенные на нем, устанавливаются неактивными.
- Статус неактивности каскадно распространяется вверх, пока не останется зависимостей материализованных представлений.
- Неактивные материализованные представления не могут обновляться или использоваться для автоматической перезаписи запросов.
- Неактивные материализованные представления все еще могут запрашиваться напрямую, но согласованность данных не гарантируется, пока они снова не станут активными.
В то время как согласованность данных неактивных материализованных представлений не может быть гарантирована, вы можете восстановить их функциональность, используя следующие методы:
- Ручная активация: Вы можете вручную восстановить неактивное материализованное представление, выполнив
ALTER MATERIALIZED VIEW <mv_name> ACTIVE. Этот оператор пересоздаст материализованн�ое представление на основе его исходного SQL определения. Обратите внимание, что SQL определение все еще должно быть действительным после изменений базовой схемы. В противном случае операция не удастся. - Активация перед обновлением: Selena попытается активировать неактивное материализованное представление перед его обновлением.
- Автоматическая активация: Selena попытается автоматически активировать неактивные материализованные представления. Однако своевременность этого процесса не может быть гарантирована. Вы можете отключить эту функцию, выполнив
ADMIN SET FRONTEND CONFIG('enable_mv_automatic_active_check'='false'). Эта функция доступна начиная с v1.5.2.
Partitioned моделирование
В дополнение к многоуровневому моделированию, partitioned моделирование также является важным аспектом моделирования данных. Моделирование данных часто включает связывание данных на основе бизнес-семантики и установку Time-To-Live (TTL) данных в соответствии с требованиями своевременности. Partitioned моделирование играет значительную роль в этом процессе.
Partitioned моделирование является важным аспектом моделирования данных, дополняя многоуровневое моделирование. Оно включает связывание данных на основе бизнес-семантики и установку Time-To-Live (TTL) для данных в соответствии с требованиями своевременности. Data partitioning играет значительную роль в этом процессе.
Различные способы связывания данных приводят к различным подходам к моделированию, таким как star schemas и snowflake schemas. Эти модели имеют что-то общее — все они используют таблицы фактов и таблицы измерений. Некоторые бизнес-сценарии требуют нескольких больших таблиц фактов, в то время как другие имеют дело со сложными таблицами измерений и отношениями между ними. Материализованные представления Selena поддерживают partition связывание для таблиц фактов, что означает, что таблица фактов разбита на partition, и результаты join материализованного представления разбиты на partition таким же образом.
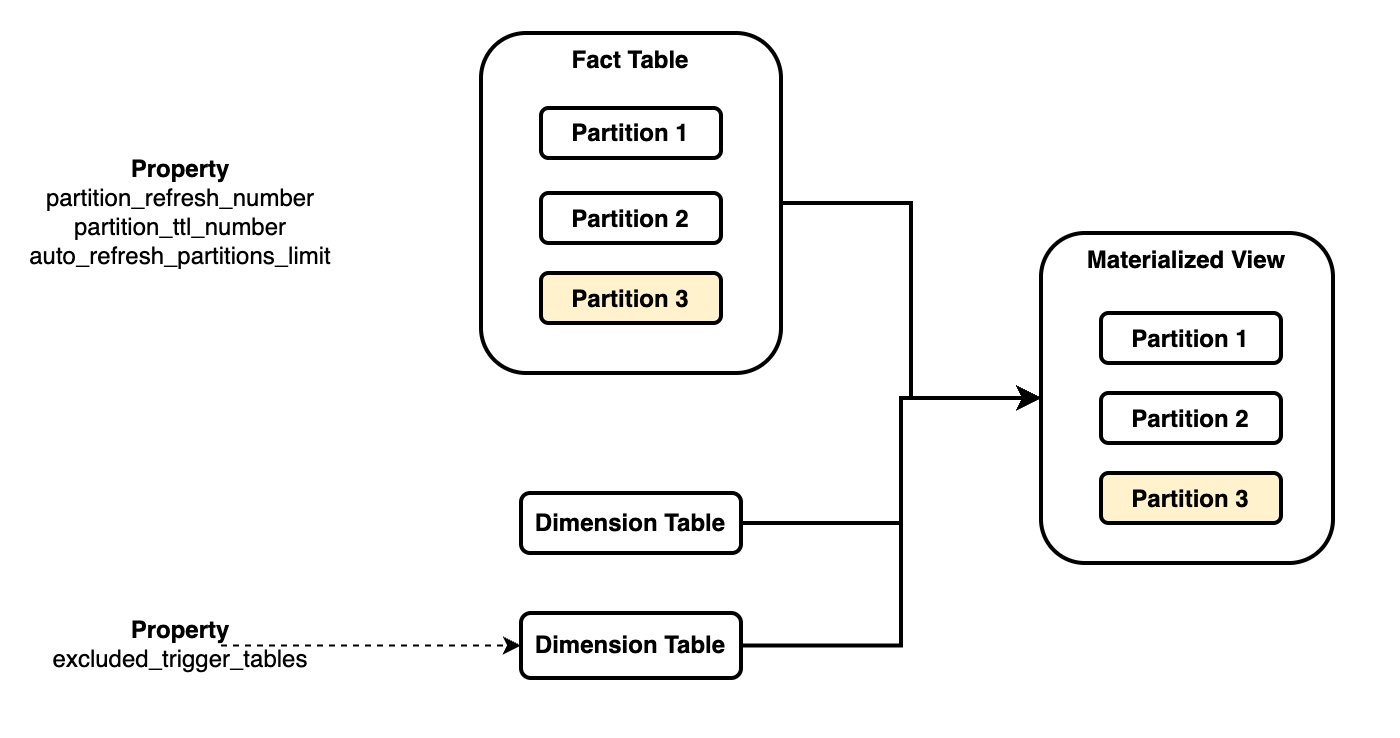
Как по�казано на рисунке выше, материализованное представление связывает таблицу фактов с несколькими таблицами измерений:
- Вам нужно ссылаться на ключ partition определенной базовой таблицы (обычно таблицы фактов) как на ключ partitioning материализованного представления (
PARTITION BY fact_tbl.col), чтобы связать их стратегии partitioning. Каждое материализованное представление может быть связано только с одной базовой таблицей. - Когда данные в partition ссылаемой таблицы изменяются, соответствующий partition в материализованном представлении обновляется, не влияя на другие partitions.
- Когда данные в не ссылаемых таблицах изменяются, все материализованное представление обновляется по умолчанию. Однако, вы можете выбрать игнорировать изменения данных в определенных не ссылаемых базовых таблицах, чтобы материализованное представление не обновлялось при изменении данных в этих таблицах.
Такое partition связывание поддерживает различные бизнес-сценарии:
- Обновления таблицы фактов: Вы можете разбить таблицу фактов на partition на детальном уровне, например, ежедневно или ежечасно. После обновления таблиц�ы фактов соответствующие partitions в материализованном представлении автоматически обновляются.
- Обновления таблицы измерений: Обычно обновления данных в таблицах измерений приводят к обновлению всех связанных результатов, что может быть дорогостоящим. Вы можете выбрать игнорировать обновления данных в некоторых таблицах измерений, чтобы избежать обновления всего материализованного представления, или вы можете указать временной диапазон, чтобы только partitions в пределах временного диапазона могли обновляться.
- Автоматическое обновление внешней таблицы: Во внешних источниках данных, таких как Apache Hive или Apache Iceberg, данные изменяются на уровне partition. Материализованные представления Selena могут подписываться на изменения во внешних каталогах на уровне partition и обновлять только соответствующий partition материализованного представления.
- TTL: При установке стратегии partitioning для материализованного представления вы можете установить количество последних partitions для сохранения, сохраняя таким образом только самые свежие данные. Это полезно в бизнес-сценариях, когда аналитики запрашивают только актуальные данные из определенного окна времени, и им не нужно сохранять все исторические данные.
Несколько параметров могут использоваться для контроля поведения обновления:
partition_refresh_number: количество partitions для обновления в каждой операции обновления.partition_refresh_strategy: стратегия обновления, выбранная для каждой операции обновления.excluded_trigger_tables: таблица, изменения данных которой могут быть проигнорированы, чтобы избежать запуска автоматического обновления.auto_refresh_partitions_limit: количество partitions для обновления в каждой автоматической операции обновления.excluded_refresh_tables: Исключить таблицы, которые нужно обновить, обычно используется вместе сexcluded_trigger_tables.
Для получения дополнительной информации см. CREATE MATERIALIZED VIEW.
В настоящее время partitioned материализованные представления имеют следующие ограничения:
- Вы можете построить partitioned материализованное представление только на основе partitioned таблицы.
- Вы можете использовать только столбцы типа DATE �или DATETIME в качестве ключа partitioning. Тип данных STRING не поддерживается.
- Вы можете выполнять только partition roll-up, используя функции date_trunc, time_slice и date_slice.
- Вы можете указать только один столбец в качестве ключа partitioning. Несколько столбцов partitioning не поддерживаются.
Резюме
Использование асинхронных материализованных представлений Selena для моделирования данных предлагает преимущество упрощения управления pipeline и повышения эффективности и гибкости моделирования данных через декларативный язык моделирования.
Помимо моделирования данных, асинхронные материализованные представления Selena находят применение в различных сценариях, включающих прозрачное ускорение и интеграцию озера данных. Это способствует дальнейшему исследованию ценности данных и повышению эффективности данных.