Перезапись запросов с помощью материализованных представлений
Этот раздел описывает, как использовать асинхронные материализованные представления Selena для перезаписи и ускорения запросов.
Обзор
Асинхронное материализованное представление Selena использует широко принятый алгоритм прозрачной перезаписи запросов на основе формы SPJG (select-project-join-group-by). Без необходимости изменять оператор запроса, Selena может автоматически переписывать запросы к базовым таблицам в запросы к соответствующему материализованному представлению, которое содержит предварительно вычисленные результаты. В результате материализованные представления могут помочь вам значительно снизить вычислительные затраты и существенно ускорить выполнение запросов.
Функция перезаписи запросов на основе асинхронных материализованных представлений особенно полезна в следующих сценариях:
-
Предварительная агрегация метрик
Вы можете использовать материализованные представления для создания слоя предварительно агрегированных метрик, если вы имеете дело с данными высокой размерности.
-
Joins широких таблиц
Материализованные представления позволяют прозрачно ускорять запросы с joins нескольких больших широких таблиц в сложных сценариях.
-
Ускорение запросов в озере данных
Создание материализованного представления на основе внешнего каталога может легко ускорить запросы к данным в вашем озере данных.
NOTE
Асинхронные материализованные представления, созданные на базовых таблицах в JDBC catalog, не поддерживают перезапись запросов.
Функции
Автоматическая перезапись запросов на основе асинхронного материализованного представления Selena имеет следующие атрибуты:
- Строгая согласованность данных: Если базовые таблицы являются нативными таблицами, Selena гарантирует, что результаты, полученные через перезапись запросов на основе материализованного представления, согласованы с результатами, возвращаемыми из прямого запроса к ба�зовым таблицам.
- Staleness rewrite: Selena поддерживает staleness rewrite, позволяя вам допустить определенный уровень устаревания данных для решения сценариев с частыми изменениями данных.
- Joins нескольких таблиц: Асинхронное материализованное представление Selena поддерживает различные типы joins, включая некоторые сложные сценарии join, такие как View Delta Joins и Derivable Joins, позволяя ускорять запросы в сценариях, включающих большие широкие таблицы.
- Перезапись агрегации: Selena может переписывать запросы с агрегациями для улучшения производительности отчетов.
- Вложенное материализованное представление: Selena поддерживает перезапись сложных запросов на основе вложенных материализованных представлений, расширяя область запросов, которые могут быть переписаны.
- Union rewrite: Вы можете объединить функцию Union rewrite с TTL (Time-to-Live) partitions материализованного представления для достижения разделения горячих и холодных данных, что позволяет запрашивать горячие данные из материализованных представлений, а исторические данные из базовой таблицы.
- Материализованные предста�вления на представлениях: Вы можете ускорять запросы в сценариях с моделированием данных на основе представлений.
- Материализованные представления на внешних каталогах: Вы можете ускорять запросы в озерах данных.
- Перезапись сложных выражений: Может обрабатывать сложные выражения, включая вызовы функций и арифметические операции, удовлетворяя продвинутые аналитические и вычислительные требования.
Эти функции будут подробно рассмотрены в следующих разделах.
Перезапись Join
Selena поддерживает перезапись запросов с различными типами joins, включая Inner Join, Cross Join, Left Outer Join, Full Outer Join, Right Outer Join, Semi Join и Anti Join.
Следующий пример перезаписи запросов с joins. Создайте две базовые таблицы следующим образом:
CREATE TABLE customer (
c_custkey INT(11) NOT NULL,
c_name VARCHAR(26) NOT NULL,
c_address VARCHAR(41) NOT NULL,
c_city VARCHAR(11) NOT NULL,
c_nation VARCHAR(16) NOT NULL,
c_region VARCHAR(13) NOT NULL,
c_phone VARCHAR(16) NOT NULL,
c_mktsegment VARCHAR(11) NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(c_custkey)
DISTRIBUTED BY HASH(c_custkey) BUCKETS 12;
CREATE TABLE lineorder (
lo_orderkey INT(11) NOT NULL,
lo_linenumber INT(11) NOT NULL,
lo_custkey INT(11) NOT NULL,
lo_partkey INT(11) NOT NULL,
lo_suppkey INT(11) NOT NULL,
lo_orderdate INT(11) NOT NULL,
lo_orderpriority VARCHAR(16) NOT NULL,
lo_shippriority INT(11) NOT NULL,
lo_quantity INT(11) NOT NULL,
lo_extendedprice INT(11) NOT NULL,
lo_ordtotalprice INT(11) NOT NULL,
lo_discount INT(11) NOT NULL,
lo_revenue INT(11) NOT NULL,
lo_supplycost INT(11) NOT NULL,
lo_tax INT(11) NOT NULL,
lo_commitdate INT(11) NOT NULL,
lo_shipmode VARCHAR(11) NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(lo_orderkey)
DISTRIBUTED BY HASH(lo_orderkey) BUCKETS 48;
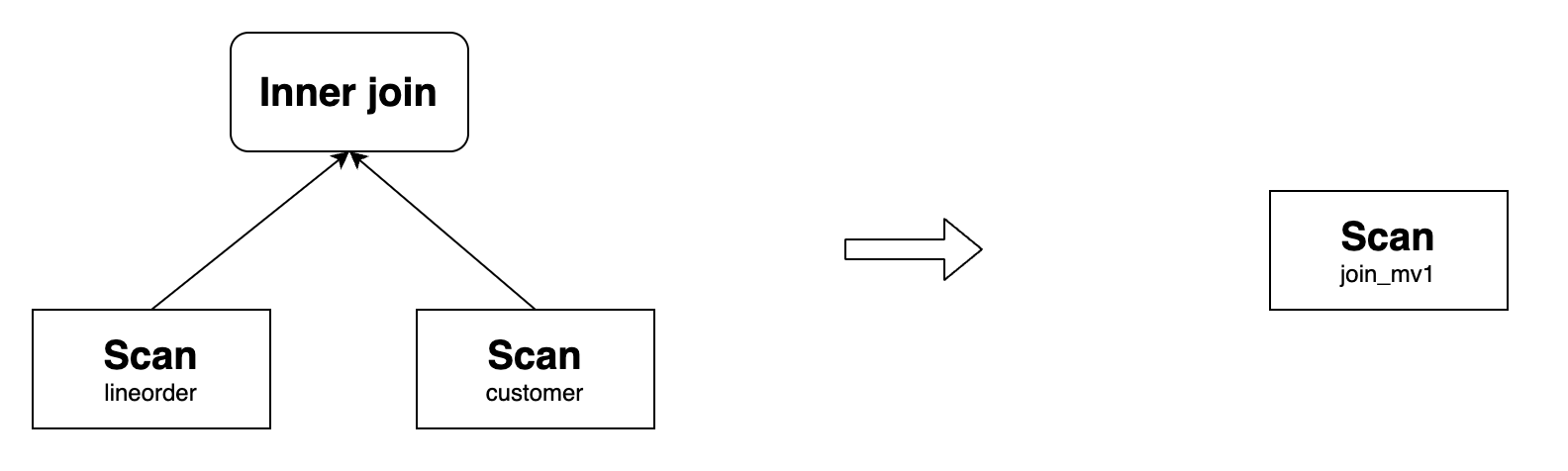
С указанными выше базовыми таблицами вы можете создать материализованное представление следующим образом:
CREATE MATERIALIZED VIEW join_mv1
DISTRIBUTED BY HASH(lo_orderkey)
AS
SELECT lo_orderkey, lo_linenumber, lo_revenue, lo_partkey, c_name, c_address
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey;
Такое материализованное представление может переписать следующий запрос:
SELECT lo_orderkey, lo_linenumber, lo_revenue, c_name, c_address
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey;
Selena поддерживает перезапись запросов join со сложными выражениями, такими как арифметические операции, строковые функции, функции дат, выражения CASE WHEN и предикаты OR. Например, указанное выше материализованное представление может переписать следующий запрос:
SELECT
lo_orderkey,
lo_linenumber,
(2 * lo_revenue + 1) * lo_linenumber,
upper(c_name),
substr(c_address, 3)
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey;
В дополнение к обычному сценарию, Selena доп�олнительно поддерживает перезапись запросов join в более сложных сценариях.
Перезапись Query Delta Join
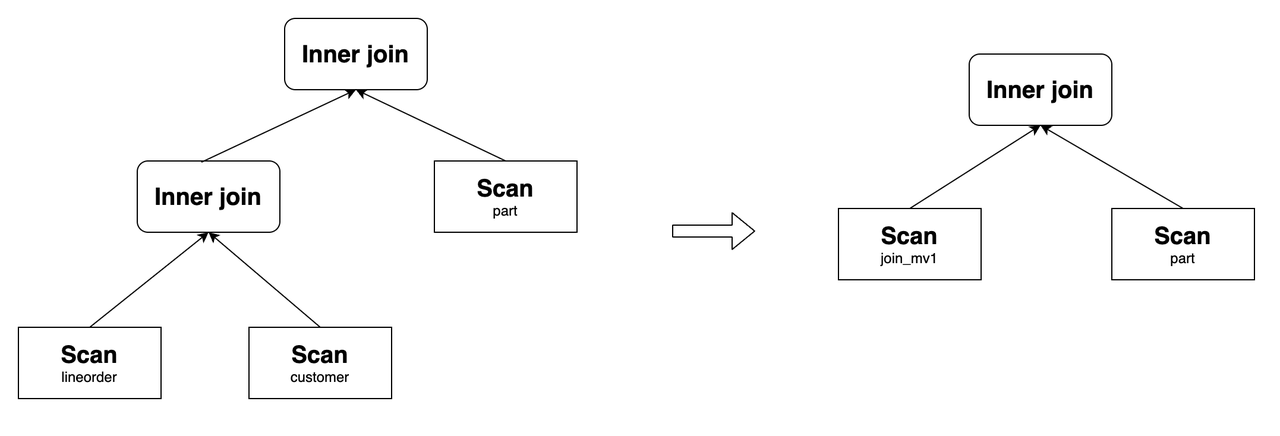
Query Delta Join относится к сценарию, в котором таблицы, объединенные в запросе, являются надмножеством таблиц, объединенных в материализованном представлении. Например, рассмотрим следующий запрос, который включает joins трех таблиц: lineorder, customer и part. Если материализованное представление join_mv1 содержит только join lineorder и customer, Selena может переписать запрос, используя join_mv1.
Пример:
SELECT lo_orderkey, lo_linenumber, lo_revenue, c_name, c_address, p_name
FROM
lineorder INNER JOIN customer ON lo_custkey = c_custkey
INNER JOIN part ON lo_partkey = p_partkey;
Его исходный план запроса и план после перезаписи следующие:
Перезапись View Delta Join
View Delta Join относится к сценарию, в котором таблицы, объединенные в запросе, являются подмножеством таблиц, объединенных в материализованном представлении. Эта функция обычно используется в сценариях, включающих большие широкие таблицы. Например, в контексте Star Schema Benchmark (SSB), вы можете создать материализованное представление, которое объединяет все таблицы для улучшения производительности запросов. Посредством тестирования было обнаружено, что производительность запросов для joins нескольких таблиц может достичь того же уровня производительности, что и запрос к соответствующей большой широкой таблице после прозрачной перезаписи запросов через материализованное представление.
Чтобы выполнить перезапись View Delta Join, материализованное представление должно содержать join сохранения кардинальности 1:1, который не существует в запросе. Вот девять типов joins, которые считаются joins сохранения кардинальности, и удовлетворение любому из них позволяет перезапись View Delta Join:
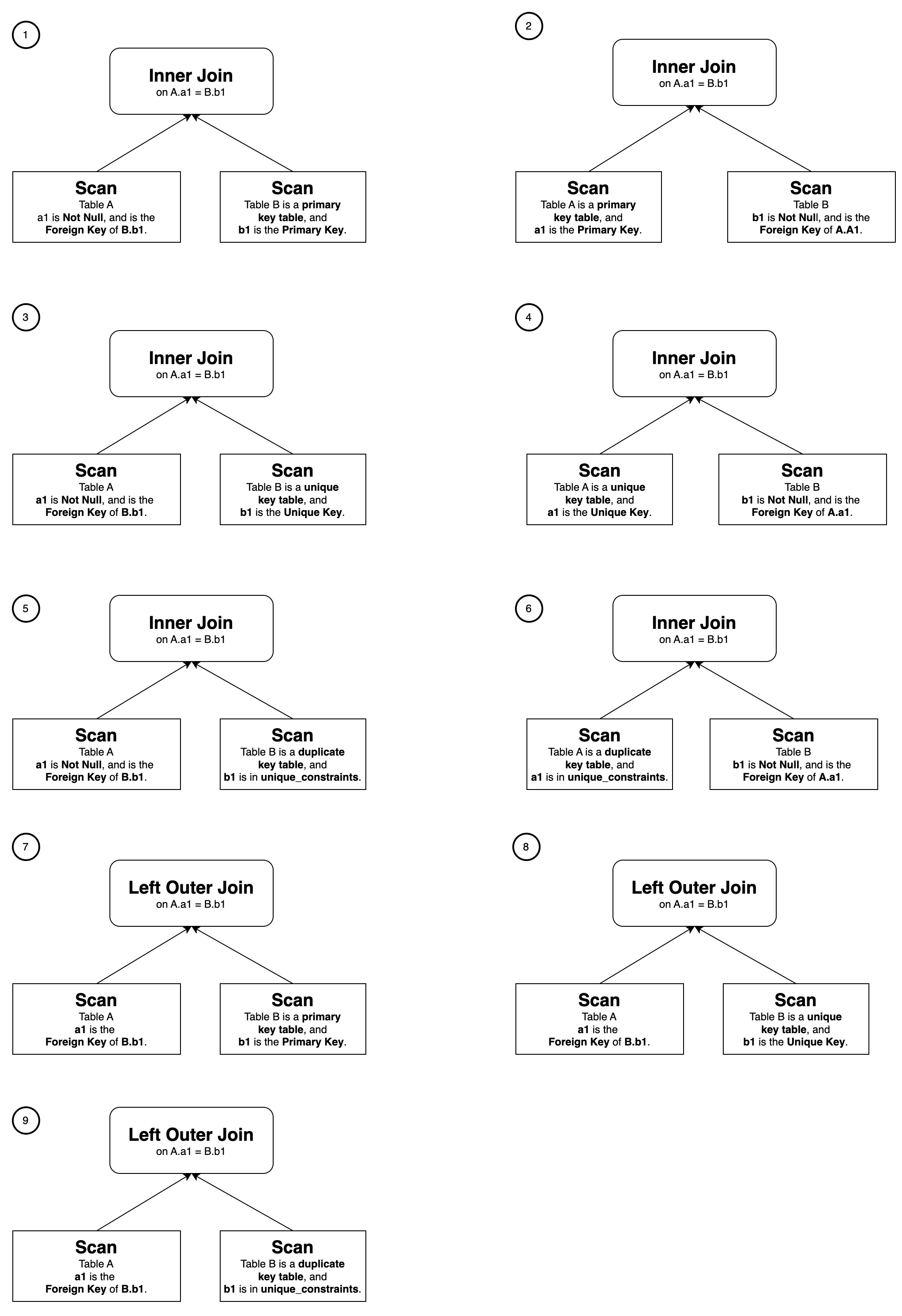
Возьмем SSB тесты в качестве примера, создайте следующие базовые таблицы:
CREATE TABLE customer (
c_custkey INT(11) NOT NULL,
c_name VARCHAR(26) NOT NULL,
c_address VARCHAR(41) NOT NULL,
c_city VARCHAR(11) NOT NULL,
c_nation VARCHAR(16) NOT NULL,
c_region VARCHAR(13) NOT NULL,
c_phone VARCHAR(16) NOT NULL,
c_mktsegment VARCHAR(11) NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(c_custkey)
DISTRIBUTED BY HASH(c_custkey) BUCKETS 12
PROPERTIES (
"unique_constraints" = "c_custkey" -- Указать уникальные ограничения.
);
CREATE TABLE dates (
d_datekey DATE NOT NULL,
d_date VARCHAR(20) NOT NULL,
d_dayofweek VARCHAR(10) NOT NULL,
d_month VARCHAR(11) NOT NULL,
d_year INT(11) NOT NULL,
d_yearmonthnum INT(11) NOT NULL,
d_yearmonth VARCHAR(9) NOT NULL,
d_daynuminweek INT(11) NOT NULL,
d_daynuminmonth INT(11) NOT NULL,
d_daynuminyear INT(11) NOT NULL,
d_monthnuminyear INT(11) NOT NULL,
d_weeknuminyear INT(11) NOT NULL,
d_sellingseason VARCHAR(14) NOT NULL,
d_lastdayinweekfl INT(11) NOT NULL,
d_lastdayinmonthfl INT(11) NOT NULL,
d_holidayfl INT(11) NOT NULL,
d_weekdayfl INT(11) NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(d_datekey)
DISTRIBUTED BY HASH(d_datekey) BUCKETS 1
PROPERTIES (
"unique_constraints" = "d_datekey" -- Указать уникальные ограничения.
);
CREATE TABLE supplier (
s_suppkey INT(11) NOT NULL,
s_name VARCHAR(26) NOT NULL,
s_address VARCHAR(26) NOT NULL,
s_city VARCHAR(11) NOT NULL,
s_nation VARCHAR(16) NOT NULL,
s_region VARCHAR(13) NOT NULL,
s_phone VARCHAR(16) NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(s_suppkey)
DISTRIBUTED BY HASH(s_suppkey) BUCKETS 12
PROPERTIES (
"unique_constraints" = "s_suppkey" -- Указать уникальные ограничения.
);
CREATE TABLE part (
p_partkey INT(11) NOT NULL,
p_name VARCHAR(23) NOT NULL,
p_mfgr VARCHAR(7) NOT NULL,
p_category VARCHAR(8) NOT NULL,
p_brand VARCHAR(10) NOT NULL,
p_color VARCHAR(12) NOT NULL,
p_type VARCHAR(26) NOT NULL,
p_size TINYINT(11) NOT NULL,
p_container VARCHAR(11) NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(p_partkey)
DISTRIBUTED BY HASH(p_partkey) BUCKETS 12
PROPERTIES (
"unique_constraints" = "p_partkey" -- Указать уникальные ограничения.
);
CREATE TABLE lineorder (
lo_orderdate DATE NOT NULL, -- Указать как NOT NULL.
lo_orderkey INT(11) NOT NULL,
lo_linenumber TINYINT NOT NULL,
lo_custkey INT(11) NOT NULL, -- Указать как NOT NULL.
lo_partkey INT(11) NOT NULL, -- Указать как NOT NULL.
lo_suppkey INT(11) NOT NULL, -- Указать как NOT NULL.
lo_orderpriority VARCHAR(100) NOT NULL,
lo_shippriority TINYINT NOT NULL,
lo_quantity TINYINT NOT NULL,
lo_extendedprice INT(11) NOT NULL,
lo_ordtotalprice INT(11) NOT NULL,
lo_discount TINYINT NOT NULL,
lo_revenue INT(11) NOT NULL,
lo_supplycost INT(11) NOT NULL,
lo_tax TINYINT NOT NULL,
lo_commitdate DATE NOT NULL,
lo_shipmode VARCHAR(100) NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(lo_orderdate,lo_orderkey)
PARTITION BY RANGE(lo_orderdate)
(PARTITION p1 VALUES [("0000-01-01"), ("1993-01-01")),
PARTITION p2 VALUES [("1993-01-01"), ("1994-01-01")),
PARTITION p3 VALUES [("1994-01-01"), ("1995-01-01")),
PARTITION p4 VALUES [("1995-01-01"), ("1996-01-01")),
PARTITION p5 VALUES [("1996-01-01"), ("1997-01-01")),
PARTITION p6 VALUES [("1997-01-01"), ("1998-01-01")),
PARTITION p7 VALUES [("1998-01-01"), ("1999-01-01")))
DISTRIBUTED BY HASH(lo_orderkey) BUCKETS 48
PROPERTIES (
"foreign_key_constraints" = "
(lo_custkey) REFERENCES customer(c_custkey);
(lo_partkey) REFERENCES part(p_partkey);
(lo_suppkey) REFERENCES supplier(s_suppkey)" -- Указать Foreign Keys.
);
Создайте материализованное представление lineorder_flat_mv, которое объединяет lineorder, customer, supplier, part и dates:
CREATE MATERIALIZED VIEW lineorder_flat_mv
DISTRIBUTED BY HASH(LO_ORDERDATE, LO_ORDERKEY) BUCKETS 48
PARTITION BY LO_ORDERDATE
REFRESH MANUAL
PROPERTIES (
"partition_refresh_number"="1"
)
AS SELECT /*+ SET_VAR(query_timeout = 7200) */ -- Установить timeout для операции обновления.
l.LO_ORDERDATE AS LO_ORDERDATE,
l.LO_ORDERKEY AS LO_ORDERKEY,
l.LO_LINENUMBER AS LO_LINENUMBER,
l.LO_CUSTKEY AS LO_CUSTKEY,
l.LO_PARTKEY AS LO_PARTKEY,
l.LO_SUPPKEY AS LO_SUPPKEY,
l.LO_ORDERPRIORITY AS LO_ORDERPRIORITY,
l.LO_SHIPPRIORITY AS LO_SHIPPRIORITY,
l.LO_QUANTITY AS LO_QUANTITY,
l.LO_EXTENDEDPRICE AS LO_EXTENDEDPRICE,
l.LO_ORDTOTALPRICE AS LO_ORDTOTALPRICE,
l.LO_DISCOUNT AS LO_DISCOUNT,
l.LO_REVENUE AS LO_REVENUE,
l.LO_SUPPLYCOST AS LO_SUPPLYCOST,
l.LO_TAX AS LO_TAX,
l.LO_COMMITDATE AS LO_COMMITDATE,
l.LO_SHIPMODE AS LO_SHIPMODE,
c.C_NAME AS C_NAME,
c.C_ADDRESS AS C_ADDRESS,
c.C_CITY AS C_CITY,
c.C_NATION AS C_NATION,
c.C_REGION AS C_REGION,
c.C_PHONE AS C_PHONE,
c.C_MKTSEGMENT AS C_MKTSEGMENT,
s.S_NAME AS S_NAME,
s.S_ADDRESS AS S_ADDRESS,
s.S_CITY AS S_CITY,
s.S_NATION AS S_NATION,
s.S_REGION AS S_REGION,
s.S_PHONE AS S_PHONE,
p.P_NAME AS P_NAME,
p.P_MFGR AS P_MFGR,
p.P_CATEGORY AS P_CATEGORY,
p.P_BRAND AS P_BRAND,
p.P_COLOR AS P_COLOR,
p.P_TYPE AS P_TYPE,
p.P_SIZE AS P_SIZE,
p.P_CONTAINER AS P_CONTAINER,
d.D_DATE AS D_DATE,
d.D_DAYOFWEEK AS D_DAYOFWEEK,
d.D_MONTH AS D_MONTH,
d.D_YEAR AS D_YEAR,
d.D_YEARMONTHNUM AS D_YEARMONTHNUM,
d.D_YEARMONTH AS D_YEARMONTH,
d.D_DAYNUMINWEEK AS D_DAYNUMINWEEK,
d.D_DAYNUMINMONTH AS D_DAYNUMINMONTH,
d.D_DAYNUMINYEAR AS D_DAYNUMINYEAR,
d.D_MONTHNUMINYEAR AS D_MONTHNUMINYEAR,
d.D_WEEKNUMINYEAR AS D_WEEKNUMINYEAR,
d.D_SELLINGSEASON AS D_SELLINGSEASON,
d.D_LASTDAYINWEEKFL AS D_LASTDAYINWEEKFL,
d.D_LASTDAYINMONTHFL AS D_LASTDAYINMONTHFL,
d.D_HOLIDAYFL AS D_HOLIDAYFL,
d.D_WEEKDAYFL AS D_WEEKDAYFL
FROM lineorder AS l
INNER JOIN customer AS c ON c.C_CUSTKEY = l.LO_CUSTKEY
INNER JOIN supplier AS s ON s.S_SUPPKEY = l.LO_SUPPKEY
INNER JOIN part AS p ON p.P_PARTKEY = l.LO_PARTKEY
INNER JOIN dates AS d ON l.LO_ORDERDATE = d.D_DATEKEY;
SSB Q2.1 включает join четырех таблиц, но в нем отсутствует таблица customer по сравнению с материализованным представлением lineorder_flat_mv. В lineorder_flat_mv, lineorder INNER JOIN customer по сути является join сохранения кардинальности. Следовательно, логически этот join может быть исключен без влияния на результаты запроса. В результате Q2.1 может быть переписан, используя lineorder_flat_mv.
SSB Q2.1:
SELECT sum(lo_revenue) AS lo_revenue, d_year, p_brand
FROM lineorder
JOIN dates ON lo_orderdate = d_datekey
JOIN part ON lo_partkey = p_partkey
JOIN supplier ON lo_suppkey = s_suppkey
WHERE p_category = 'MFGR#12' AND s_region = 'AMERICA'
GROUP BY d_year, p_brand
ORDER BY d_year, p_brand;
Его исходный план запроса и план после перезаписи следующие:
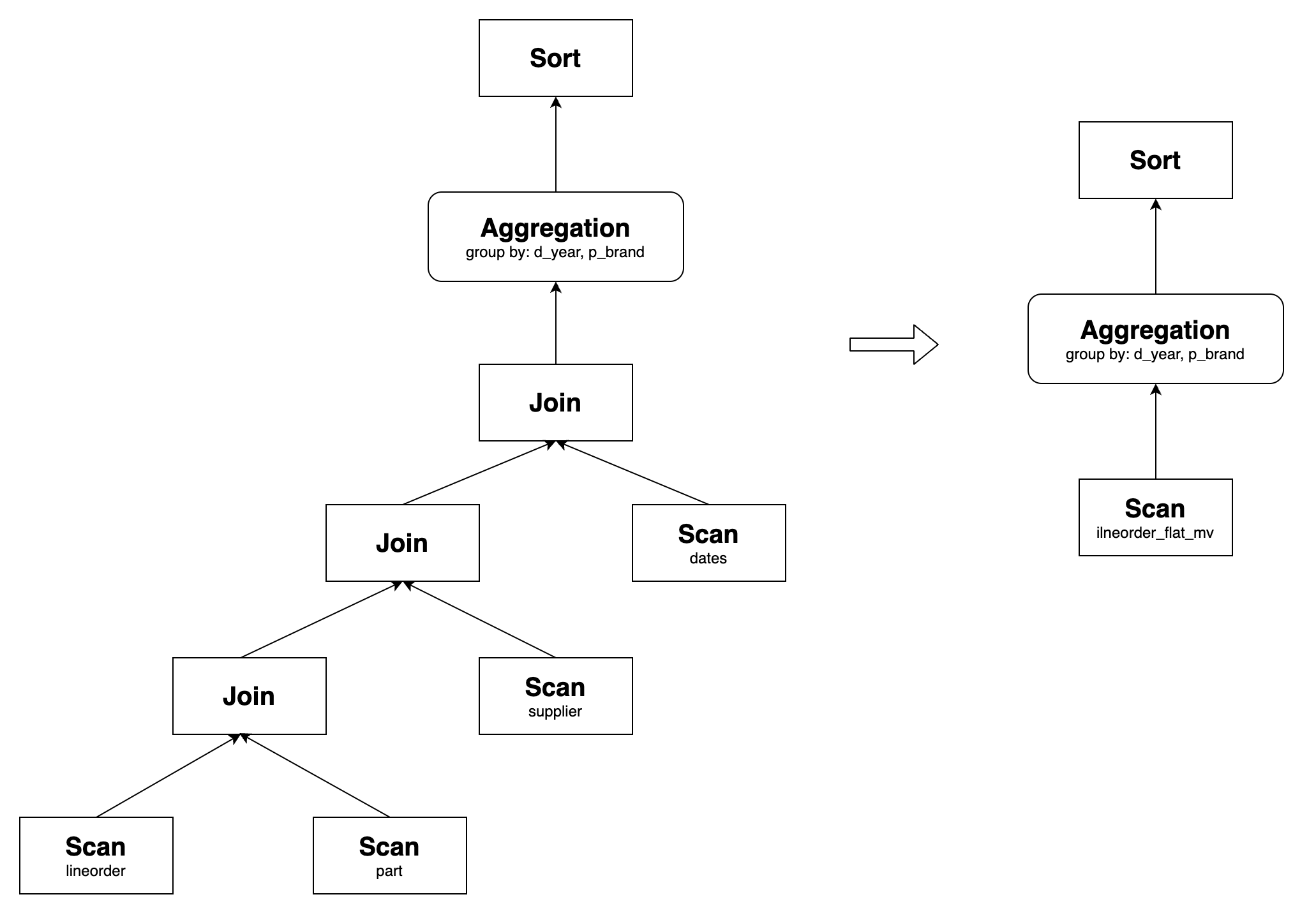
Аналогично, другие запросы в SSB также могут быть прозрачно переписаны, используя lineorder_flat_mv, таким образом оптимизируя производительность запросов.
Перезапись Join Derivability
Join Derivability относится к сценарию, в котором типы join в материализованном представлении и запросе не согласованы, но результаты join материализованного представления содержат результаты join запроса. В настоящее время поддерживаются два сценария — join трех или более таблиц и join двух таблиц.
-
Сценарий первый: Join трех или более таблиц
Предположим, что материализованное представление содержит Left Outer Join между таблицами
t1иt2и Inner Join между таб�лицамиt2иt3. В обоих joins условие join включает столбцы изt2.Запрос, с другой стороны, содержит Inner Join между t1 и t2, и Inner Join между t2 и t3. В обоих joins условие join включает столбцы из t2.
В этом случае запрос может быть переписан, используя материализованное представление. Это происходит потому, что в материализованном представлении сначала выполняется Left Outer Join, а затем Inner Join. Правая таблица, сгенерированная Left Outer Join, не имеет результатов для совпадения (то есть столбцы в правой таблице являются NULL). Эти результаты впоследствии отфильтровываются во время Inner Join. Следовательно, логика материализованного представления и запроса эквивалентна, и запрос может быть переписан.
Пример:
Создайте материализованное представление
join_mv5:CREATE MATERIALIZED VIEW join_mv5
PARTITION BY lo_orderdate
DISTRIBUTED BY hash(lo_orderkey)
PROPERTIES (
"partition_refresh_number" = "1"
)
AS
SELECT lo_orderkey, lo_orderdate, lo_linenumber, lo_revenue, c_custkey, c_address, p_name
FROM customer LEFT OUTER JOIN lineorder
ON c_custkey = lo_custkey
INNER JOIN part
ON p_partkey = lo_partkey;join_mv5может переписать следующий запрос:SELECT lo_orderkey, lo_orderdate, lo_linenumber, lo_revenue, c_custkey, c_address, p_name
FROM customer INNER JOIN lineorder
ON c_custkey = lo_custkey
INNER JOIN part
ON p_partkey = lo_partkey;Его исходный план запроса и план после перезаписи следующие:
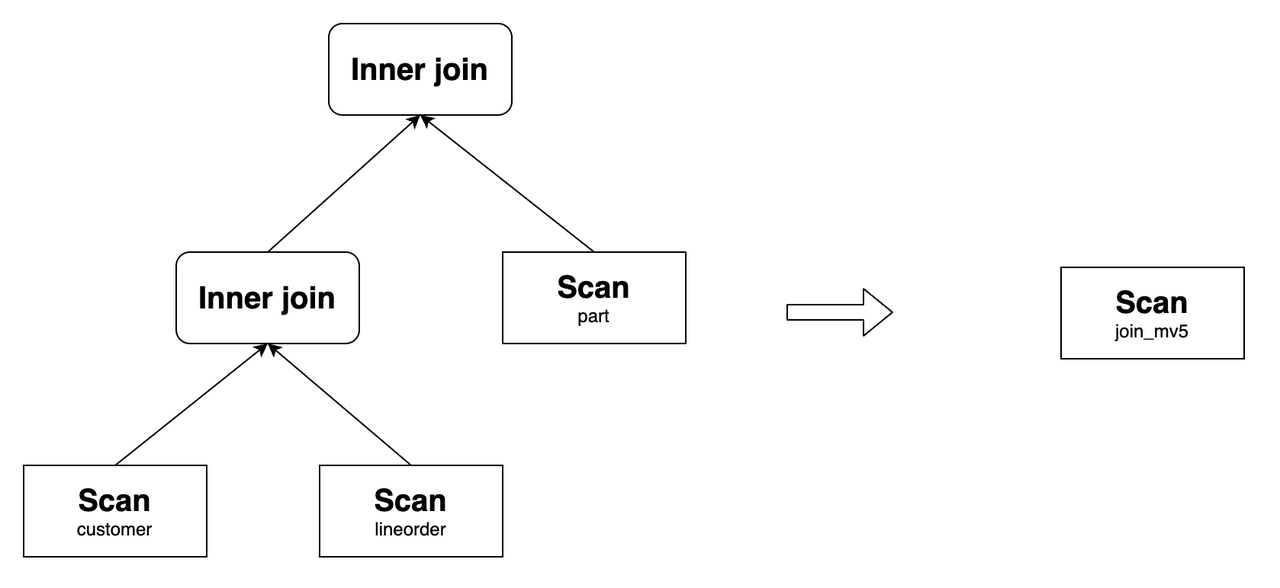
Аналогично, если материализованное представление определено как
t1 INNER JOIN t2 INNER JOIN t3, а запрос —LEFT OUTER JOIN t2 INNER JOIN t3, запрос также может быть переписан. Кроме того, эта возможность перезаписи распространяется на сценарии, включающие более трех таблиц. -
Сценарий второй: Join двух таблиц
Функция Join Derivability Rewrite, включающая две таблицы, поддерживает следующие конкретные случаи:
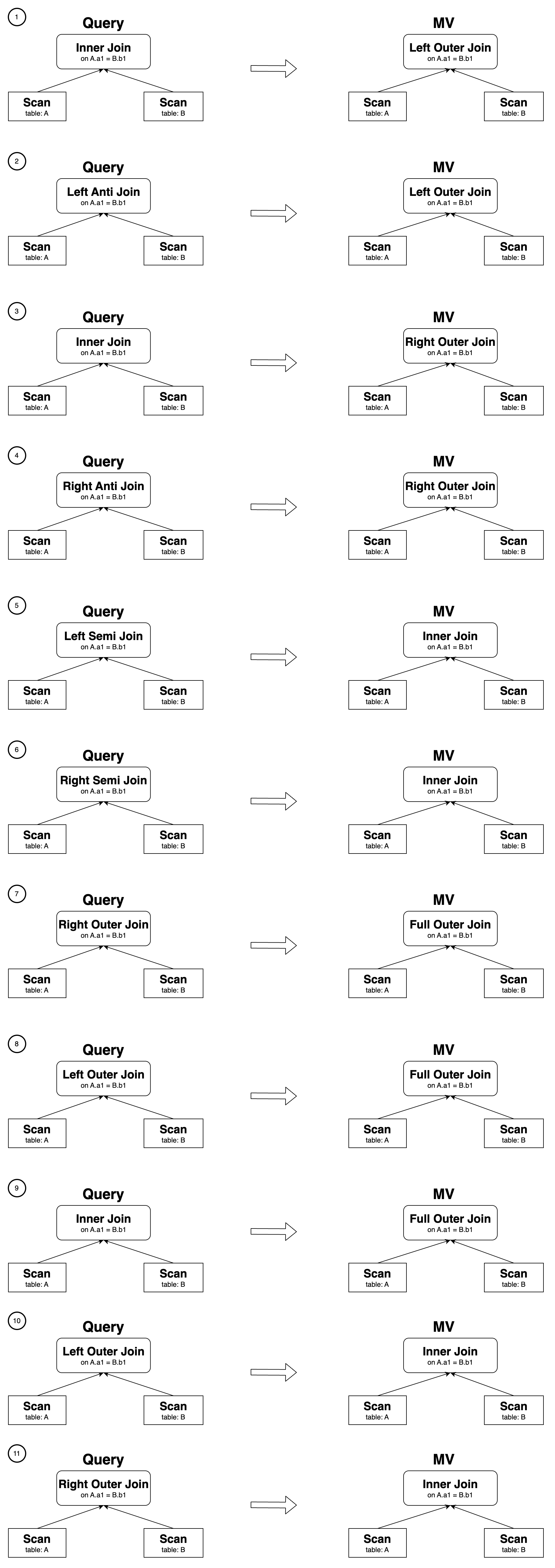
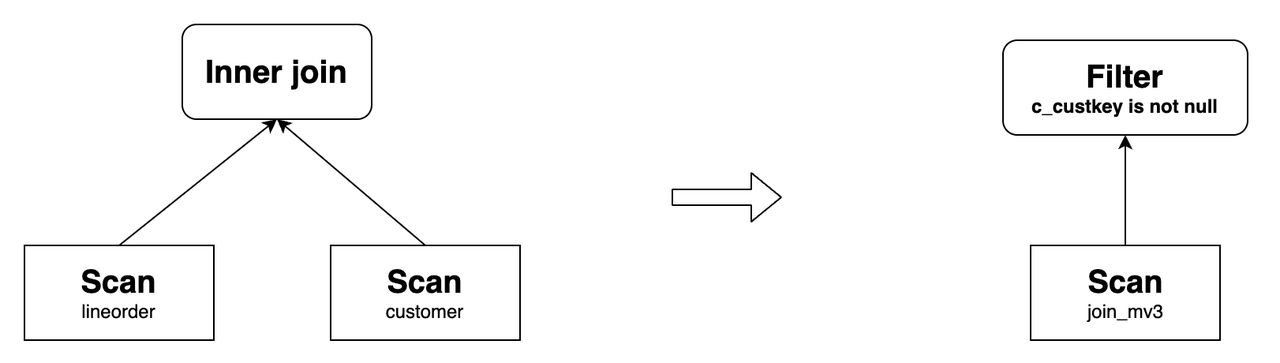
В случаях с 1 по 9 фильтрующие предикаты должны быть добавлены к переписанному результату для обеспечения семантической эквивалентности. Например, �создайте материализованное представление следующим образом:
CREATE MATERIALIZED VIEW join_mv3
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT lo_orderkey, lo_linenumber, lo_revenue, c_custkey, c_address
FROM lineorder LEFT OUTER JOIN customer
ON lo_custkey = c_custkey;Следующий запрос может быть переписан, используя
join_mv3, и предикатc_custkey IS NOT NULLдобавляется к переписанному результату:SELECT lo_orderkey, lo_linenumber, lo_revenue, c_custkey, c_address
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey;Его исходный план запроса и план после перезаписи следующие:
В случае 10, Left Outer Join запрос должен включать фильтрующий предикат
IS NOT NULLв правой таблице, например,=,<>,>,<,<=,>=,LIKE,IN,NOT LIKEилиNOT IN. Например, создайте материализованное представление следующим образом:CREATE MATERIALIZED VIEW join_mv4
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT lo_orderkey, lo_linenumber, lo_revenue, c_custkey, c_address
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey;join_mv4может переписать следующий запрос, гдеcustomer.c_address = "Sb4gxKs7"является фильтрующим предикатомIS NOT NULL:SELECT lo_orderkey, lo_linenumber, lo_revenue, c_custkey, c_address
FROM lineorder LEFT OUTER JOIN customer
ON lo_custkey = c_custkey
WHERE customer.c_address = "Sb4gxKs7";Его исходный план запроса и план после перезаписи следующие:
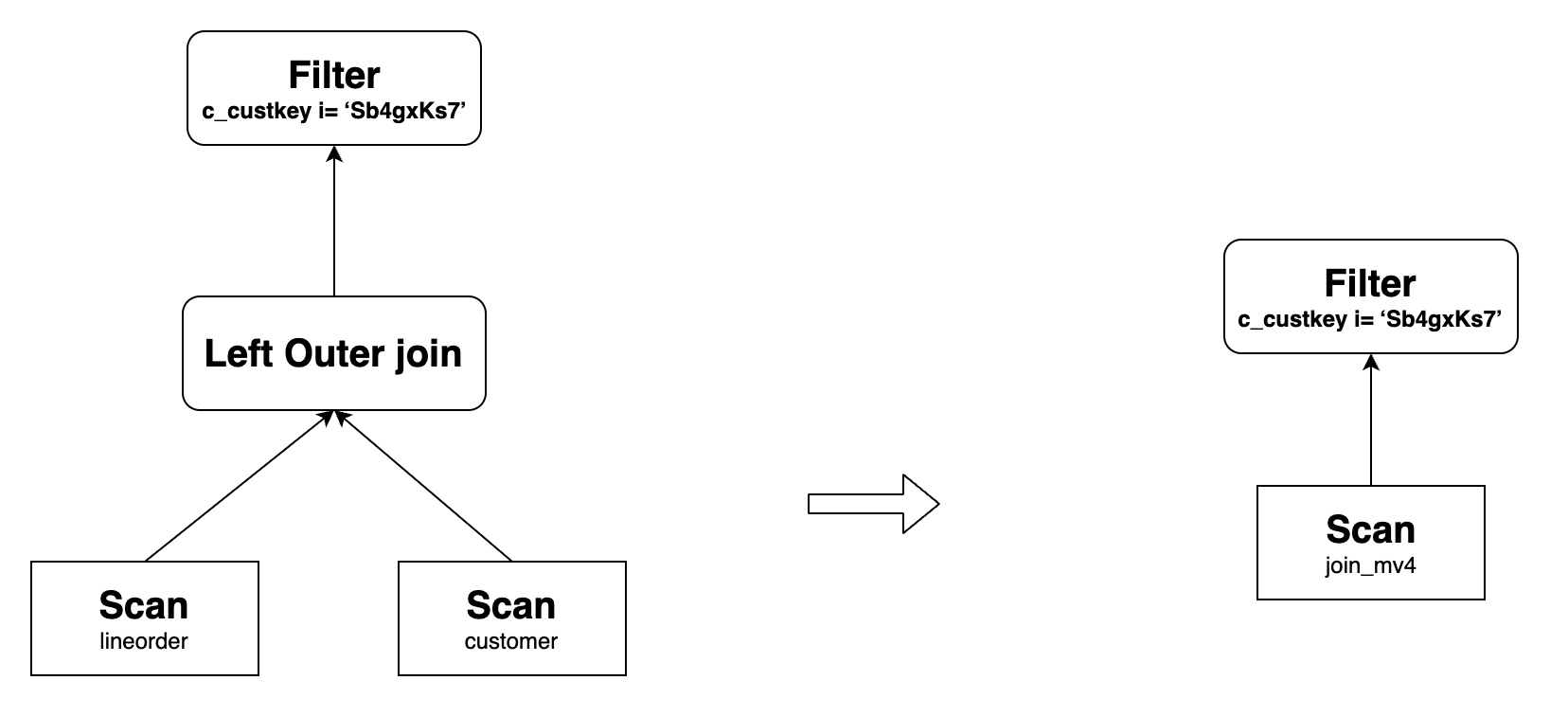
Перезапись агрегации
Асинхронное материализованное представление Selena поддерживает перезапись многотабличных агрегатных запросов со всеми доступными агрегатными функциями, включая bitmap_union, hll_union и percentile_union. Например, создайте материализованное представление следующим образом:
CREATE MATERIALIZED VIEW agg_mv1
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT
lo_orderkey,
lo_linenumber,
c_name,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey
GROUP BY lo_orderkey, lo_linenumber, c_name;
Оно может переписать следующий запрос:
SELECT
lo_orderkey,
lo_linenumber,
c_name,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey
GROUP BY lo_orderkey, lo_linenumber, c_name;
Его исходный план запроса и план после перезаписи следующие:
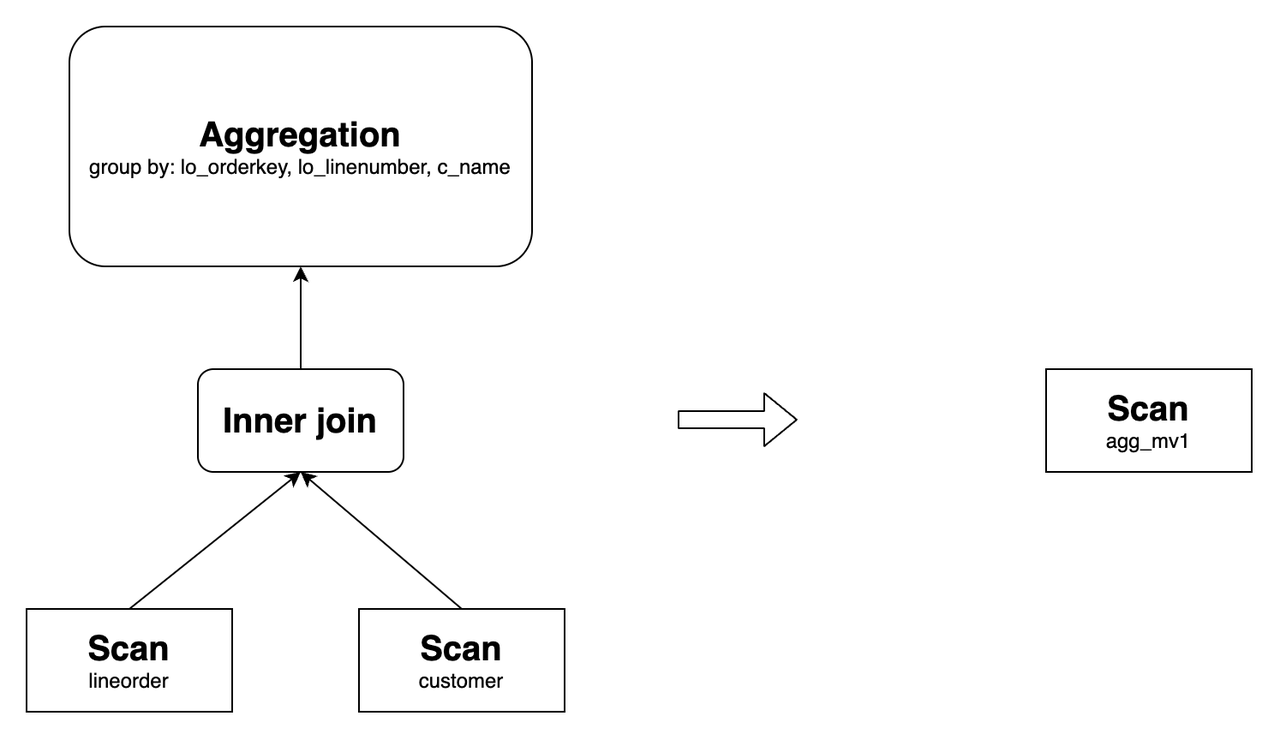
Следующие разделы излагают сценарии, г�де функция Aggregation Rewrite может быть полезной.
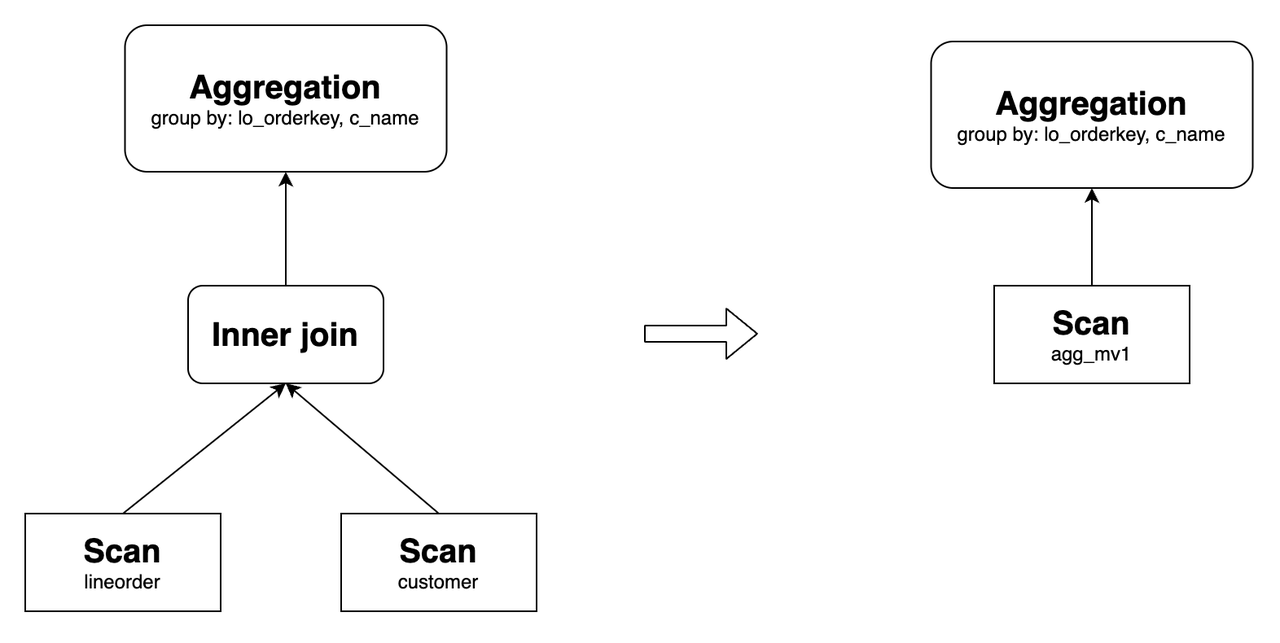
Перезапись Aggregation Rollup
Selena поддерживает перезапись запросов с Aggregation Rollup, то есть Selena может переписывать агрегатные запросы с оператором GROUP BY a, используя асинхронное материализованное представление, созданное с оператором GROUP BY a,b. Например, следующий запрос может быть переписан, используя agg_mv1:
SELECT
lo_orderkey,
c_name,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey
GROUP BY lo_orderkey, c_name;
Его исходный план запроса и план после перезаписи следующие:
NOTE
В настоящее время перезапись grouping set, grouping set with rollup или grouping set with cube не поддерживается.
Только определенные агрегатные функции поддерживают перезапись запросов с Aggregate Rollup. В предыдущем примере, если материализованное представление order_agg_mv использует count(distinct client_id) вместо bitmap_union(to_bitmap(client_id)), Selena не может переписать запросы с Aggregate Rollup.
Следующая таблица показывает соответствие между агрегатными функциями в исходном запросе и агрегатной функцией, используемой для построения материализованного представления. Вы можете выбрать соответствующие агрегатные функции для построения материализованного представления в соответствии с вашим бизнес-сценарием.
| Агрегатная функция, поддерживаемая в исходных запросах | Функция, поддерживающая Aggregate Rollup в материализованном представлении |
|---|---|
| sum | sum |
| count | count |
| min | min |
| max | max |
| avg | sum / count |
| bitmap_union, bitmap_union_count, count(distinct) | bitmap_union |
| hll_raw_agg, hll_union_agg, ndv, approx_count_distinct | hll_union |
| percentile_approx, percentile_union | percentile_union |
DISTINCT агрегаты без соответствующего столбца GROUP BY не могут быть переписаны с Aggregate Rollup. Однако, начиная с Selena v1.5.2, если запрос с Aggregate Rollup DISTINCT агрегатной функцией не имеет столбца GROUP BY, но имеет равенственный предикат, он также может быть переписан соответствующим материализованным представлением, потому что Selena может преобразовать равенственные предикаты в выражение константы GROUP BY.
В следующем примере Selena может переписать запрос с помощью материализованного представления order_agg_mv1.
CREATE MATERIALIZED VIEW order_agg_mv1
DISTRIBUTED BY HASH(`order_id`) BUCKETS 12
REFRESH ASYNC START('2022-09-01 10:00:00') EVERY (interval 1 day)
AS
SELECT
order_date,
count(distinct client_id)
FROM order_list
GROUP BY order_date;
-- Запрос
SELECT
order_date,
count(distinct client_id)
FROM order_list WHERE order_date='2023-07-03';
В дополнение к указанным выше функциям, начиная с Selena v1.5.2, асинхронные материализованные представления также поддерживают универсальные агрегатные функции, которые также могут использоваться для перезаписи запросов. Для получения дополнительной информации об универсальных агрегатных функциях см. Generic aggregate function states.
-- Создать асинхронное материализованное представление test_mv2 для хране�ния aggregate states.
CREATE MATERIALIZED VIEW test_mv2
PARTITION BY (dt)
DISTRIBUTED BY RANDOM
AS
SELECT
dt,
-- Исходные агрегатные функции.
min(id) AS min_id,
max(id) AS max_id,
sum(id) AS sum_id,
bitmap_union(to_bitmap(id)) AS bitmap_union_id,
hll_union(hll_hash(id)) AS hll_union_id,
percentile_union(percentile_hash(id)) AS percentile_union_id,
-- Generic aggregate state функции.
ds_hll_count_distinct_union(ds_hll_count_distinct_state(id)) AS hll_id,
avg_union(avg_state(id)) AS avg_id,
array_agg_union(array_agg_state(id)) AS array_agg_id,
min_by_union(min_by_state(province, id)) AS min_by_province_id
FROM t1
GROUP BY dt;
-- Обновить материализованное представление.
REFRESH MATERIALIZED VIEW test_mv2 WITH SYNC MODE;
-- Прямые запросы к агрегатной функции будут прозрачно ускорены с помощью test_mv2.
SELECT
dt,
min(id),
max(id),
sum(id),
bitmap_union_count(to_bitmap(id)), -- count(distinct id)
hll_union_agg(hll_hash(id)), -- approx_count_distinct(id)
percentile_approx(id, 0.5),
ds_hll_count_distinct(id),
avg(id),
array_agg(id),
min_by(province, id)
FROM t1
WHERE dt >= '2024-01-01'
GROUP BY dt;
SELECT
min(id),
max(id),
sum(id),
bitmap_union_count(to_bitmap(id)), -- count(distinct id)
hll_union_agg(hll_hash(id)), -- approx_count_distinct(id)
percentile_approx(id, 0.5),
ds_hll_count_distinct(id),
avg(id),
array_agg(id),
min_by(province, id)
FROM t1
WHERE dt >= '2024-01-01';
Pushdown агрегации
Начиная с v1.5.2, Selena поддерживает pushdown агрегации для перезаписи запросов материализованного представления. Когда эта функция включена, агрегатные функции будут проталкиваться вниз к Scan Operator во время выполнения запроса и переписываться материализованным представлением до выполнения Join Operator. Это снизит расширение данных, вызванное Join, и тем самым улучшит производительность запросов.
Эта функция отключена по умолчанию. Чтобы включить эту функцию, вы должны установить системную переменную enable_materialized_view_agg_pushdown_rewrite в true.
Предположим, вы хотите ускорить следующий запрос на основе SSB SQL1:
-- SQL1
SELECT
LO_ORDERDATE, sum(LO_REVENUE), max(LO_REVENUE), count(distinct LO_REVENUE)
FROM lineorder l JOIN dates d
ON l.LO_ORDERDATE = d.d_date
GROUP BY LO_ORDERDATE
ORDER BY LO_ORDERDATE;
SQL1 состоит из агрегаций для таблицы lineorder и Join lineorder и dates. Поскольку агрегации происходят внутри lineorder, а Join с dates используется только для фильтрации данных, SQL1 логически эквивалентен следующему SQL2:
-- SQL2
SELECT
LO_ORDERDATE, sum(sum1), max(max1), bitmap_union_count(bitmap1)
FROM
(SELECT
LO_ORDERDATE, sum(LO_REVENUE) AS sum1, max(LO_REVENUE) AS max1, bitmap_union(to_bitmap(LO_REVENUE)) AS bitmap1
FROM lineorder
GROUP BY LO_ORDERDATE) l JOIN dates d
ON l.LO_ORDERDATE = d.d_date
GROUP BY LO_ORDERDATE
ORDER BY LO_ORDERDATE;
SQL2 выносит агрегации вперед, тем самым уменьшая размер данных Join. Вы можете создать материализованное представление на основе подзапроса SQL2 и включить pushdown агрегации для перезаписи и ускорения агрегаций:
-- Создать материализованное представление mv0
CREATE MATERIALIZED VIEW mv0 REFRESH MANUAL AS
SELECT
LO_ORDERDATE,
sum(LO_REVENUE) AS sum1,
max(LO_REVENUE) AS max1,
bitmap_union(to_bitmap(LO_REVENUE)) AS bitmap1
FROM lineorder
GROUP BY LO_ORDERDATE;
-- Включить pushdown агрегации для перезаписи запросов материализованного представления
SET enable_materialized_view_agg_pushdown_rewrite=true;
Затем SQL1 будет переписан и ускорен материализованным представлением. Он переписывается в следующий запрос:
SELECT
LO_ORDERDATE, sum(sum1), max(max1), bitmap_union_count(bitmap1)
FROM
(SELECT LO_ORDERDATE, sum1, max1, bitmap1 FROM mv0) l JOIN dates d
ON l.LO_ORDERDATE = d.d_date
GROUP BY LO_ORDERDATE
ORDER BY LO_ORDERDATE;
Обратите внимание, что только определенные агрегатные функции, которые поддерживают перезапись Aggregate Rollup, подходят для pushdown. Это:
- MIN
- MAX
- COUNT
- COUNT DISTINCT
- SUM
- BITMAP_UNION
- HLL_UNION
- PERCENTILE_UNION
- BITMAP_AGG
- ARRAY_AGG_DISTINCT
- После pushdown агрегатные функции должны быть свернуты для соответствия исходной семантике. Для получения дополнительных инструкций по Aggregation Rollup, пожалуйста, обратитесь к Aggregation Rollup Rewrite.
- Pushdown агрегации поддерживает перезапись Rollup Count Distinct на основе функций Bitmap или HLL.
- Pushdown агрегации поддерживает только проталкивание агрегатных функций вниз к Scan Operator перед операторами Join, Filter или Where.
- Pushdown агрегации поддерживает только перезапись запросов и ускорение на основе материализованного представления, построенного на одной таблице.
Перезапись COUNT DISTINCT
Selena поддерживает перезапись вычислений COUNT DISTINCT в вычисления на основе bitmap, обеспечивая высокопроизводительную точную дедупликацию с использованием материализованных представлений. Например, создайте материализованное представление следующим образом:
CREATE MATERIALIZED VIEW distinct_mv
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT lo_orderkey, bitmap_union(to_bitmap(lo_custkey)) AS distinct_customer
FROM lineorder
GROUP BY lo_orderkey;
Оно может переписать следующий запрос:
SELECT lo_orderkey, count(distinct lo_custkey)
FROM lineorder
GROUP BY lo_orderkey;
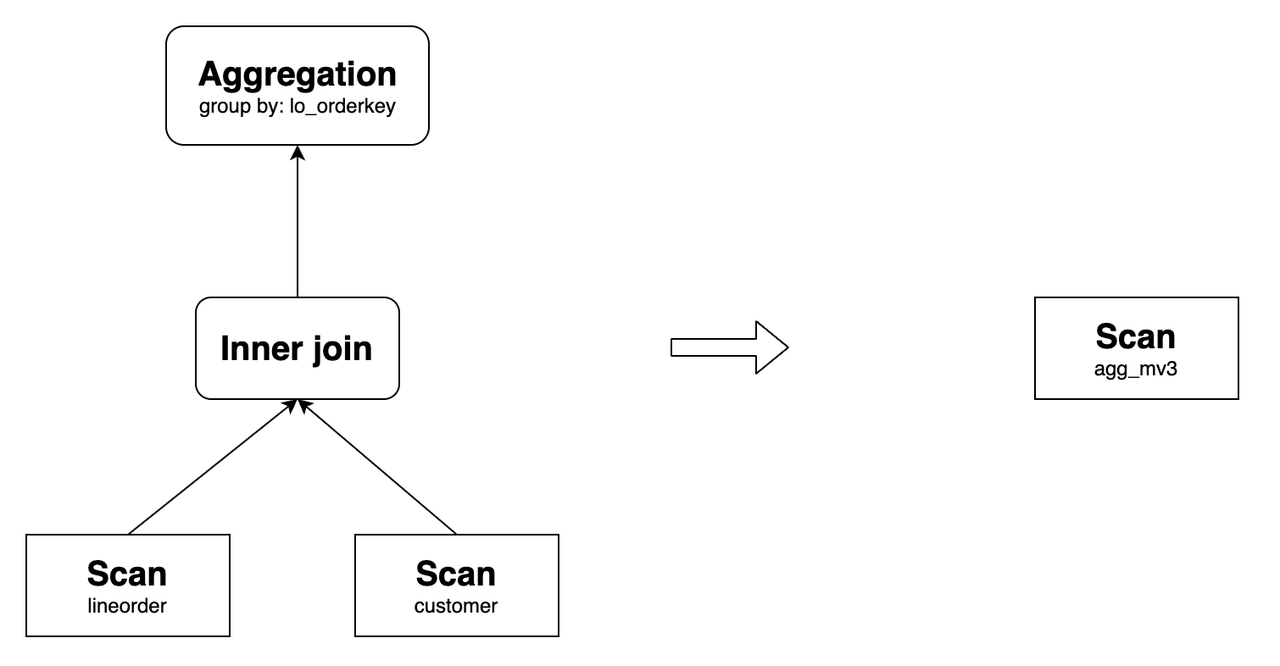
Перезапись вложенного материализованного представления
Selena поддерживает перезапись запросов с использованием вложенного материализованного представления. Например, создайте материализованные представления join_mv2, agg_mv2 и agg_mv3 следующим образом:
CREATE MATERIALIZED VIEW join_mv2
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT lo_orderkey, lo_linenumber, lo_revenue, c_name, c_address
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey;
CREATE MATERIALIZED VIEW agg_mv2
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT
lo_orderkey,
lo_linenumber,
c_name,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM join_mv2
GROUP BY lo_orderkey, lo_linenumber, c_name;
CREATE MATERIALIZED VIEW agg_mv3
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT
lo_orderkey,
sum(total_revenue) AS total_revenue,
max(max_discount) AS max_discount
FROM agg_mv2
GROUP BY lo_orderkey;
Их взаимоотношения следующие:

agg_mv3 может переписать следующий запрос:
SELECT
lo_orderkey,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey
GROUP BY lo_orderkey;
Его исходный план запроса и план после перезаписи следующие:
Перезапись Union
Перезапись Predicate Union
Когда область предиката материализованного представления является подмножеством области предиката запроса, запрос может быть переписан с использованием операции UNION.
Например, создайте материализованное представление следующим образом:
CREATE MATERIALIZED VIEW agg_mv4
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT
lo_orderkey,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder
WHERE lo_orderkey < 300000000
GROUP BY lo_orderkey;
Оно может переписать следующий запрос:
select
lo_orderkey,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder
GROUP BY lo_orderkey;
Его исходный план запроса и план после перезаписи следующие:
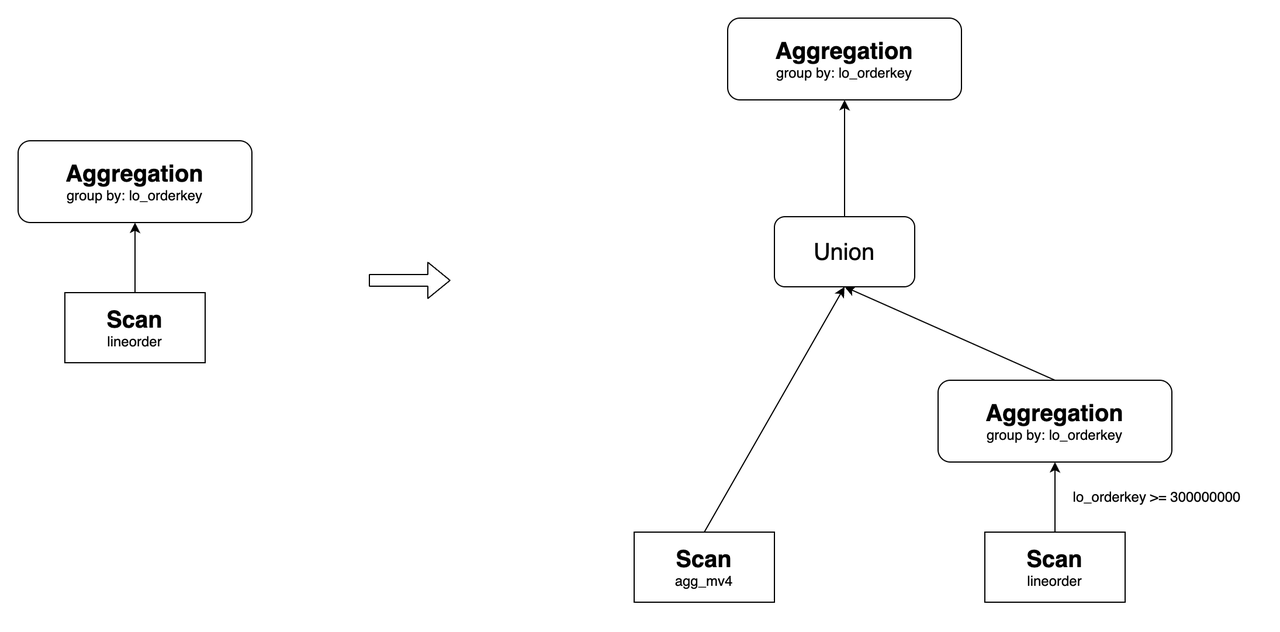
В этом контексте agg_mv5 содержит данные, где lo_orderkey < 300000000. Данные, где lo_orderkey >= 300000000, напрямую получаются из базовой таблицы lineorder. Наконец, эти два набора данных объединяются с использованием операции UNION, а затем агрегируются для получения окончательного результата.
Перезапись Partition Union
Предположим, вы создали partitioned материализованное представление на основе partitioned таблицы. Когда диапазон partition, который сканируется переписываемым запросом, является надмножеством самого последнего диапазона partition материализованного представления, запрос будет переписан с использованием операции UNION.
Например, расс�мотрим следующее материализованное представление agg_mv4. Его базовая таблица lineorder в настоящее время содержит partitions от p1 до p7, и материализованное представление также содержит partitions от p1 до p7.
CREATE MATERIALIZED VIEW agg_mv5
DISTRIBUTED BY hash(lo_orderkey)
PARTITION BY RANGE(lo_orderdate)
REFRESH MANUAL
AS
SELECT
lo_orderdate,
lo_orderkey,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder
GROUP BY lo_orderkey;
Если новый partition p8 с диапазоном partition [("19990101"), ("20000101")) добавляется к lineorder, следующий запрос может быть переписан с использованием операции UNION:
SELECT
lo_orderdate,
lo_orderkey,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder
GROUP BY lo_orderkey;
Его исходный план запроса и план после перезаписи следующие:
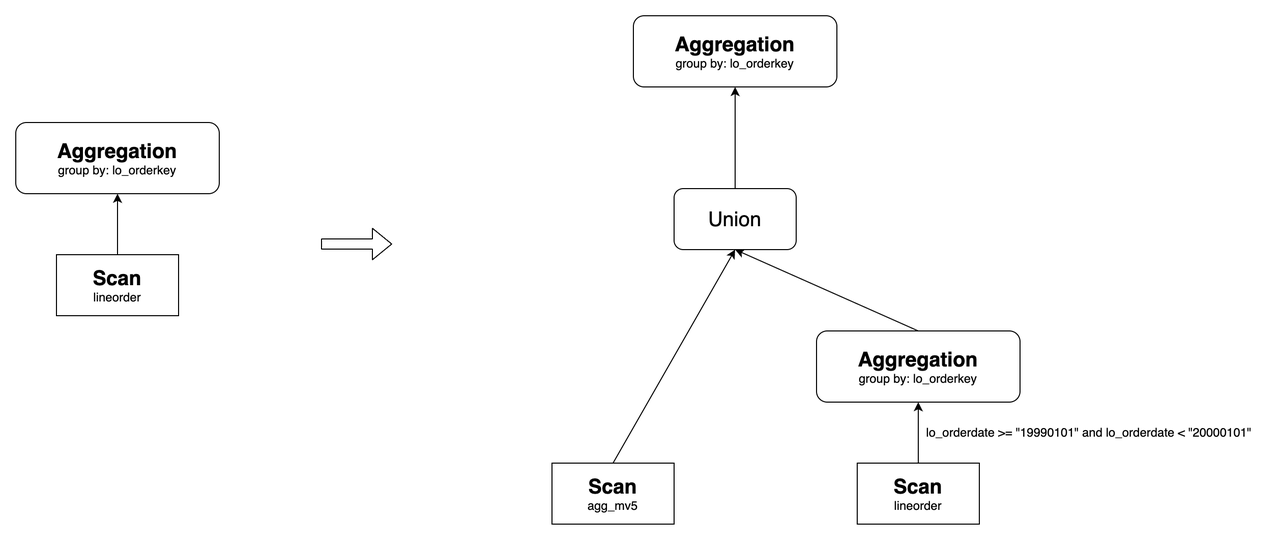
Как показано выше, agg_mv5 содержит данные из partitions от p1 до p7, а данные из partition p8 напрямую запрашиваются из lineorder. Наконец, эти два набора данных объединяются с использованием операции UNION.
Перезапись материализованного представления на основе представления
Начиная с v1.5.2, Selena поддерживает создание материализованных представлений на основе представлений. Последующие запросы к представлениям могут быть переписаны, если они имеют паттерн SPJG. По умолчанию запросы к представлениям автоматически транскрибируются в запросы к базовым таблицам представлений, а затем прозрачно сопоставляются и переписываются.
Однако в реальных сценариях аналитики данных могут выполнять моделирование данных на основе сложных вложенных представлений, которые не могут быть напрямую транскрибированы. В результате материализованные представления, созданные на основе таких представлений, не могут переписывать запросы. Чтобы улучшить свои возможности в предыдущем сценарии, Selena оптимизирует логику перезаписи запросов материализованного представления на основе представления начиная с v1.5.2.
Основы
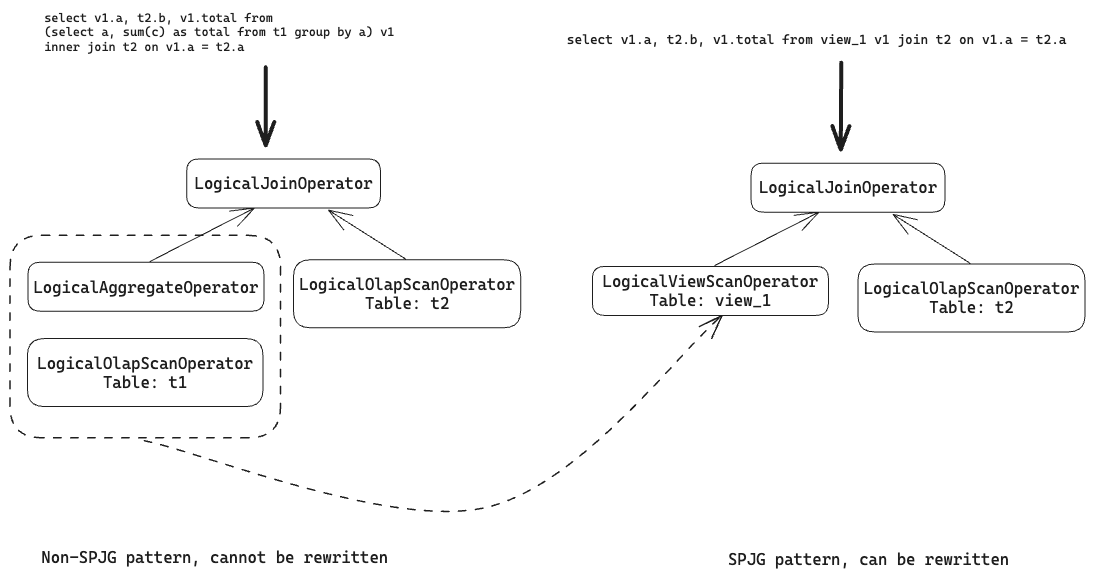
В предыдущей логике перезаписи запросов Selena транскрибирует запросы к представлению в запросы к базовым таблицам представления. Перезапись запросов встретит сбои, если план выполнения транскрибированного запроса не соответствует паттерну SPJG.
Чтобы решить эту проблему, Selena вводит новый оператор - LogicalViewScanOperator, чтобы упростить структуру дерева плана выполнения без транскрибирования запроса. Этот оператор стремится сопоставить дерево плана выполнения с паттерном SPJG, тем самым облегчая перезапись запросов.
Следующий пример перечисляет запрос с подзапросом AGGREGATE, представление, построенное на подзапросе, транскрибированный запрос на основе представления и материализованное представление, построенное на представлении:
-- Исходный запрос:
SELECT
v1.a,
t2.b,
v1.total
FROM(
SELECT
a,
sum(c) AS total
FROM t1
GROUP BY a
) v1
INNER JOIN t2 ON v1.a = t2.a;
-- Представление:
CREATE VIEW view_1 AS
SELECT
t1.a,
sum(t1.c) AS total
FROM t1
GROUP BY t1.a;
-- Транскрибированный запрос:
SELECT
v1.a,
t2.b,
v1.total
FROM view_1 v1
JOIN t2 ON v1.a = t2.a;
-- Материализованное представление:
CREATE MATERIALIZED VIEW mv1
DISTRIBUTED BY hash(a)
REFRESH MANUAL
AS
SELECT
v1.a,
t2.b,
v1.total
FROM view_1 v1
JOIN t2 ON v1.a = t2.a;
План выполнения исходного запроса, как показано слева на следующей диаграмме, не соответствует паттерну SPJG из-за LogicalAggregateOperator внутри JOIN. Selena не поддерживает перезапись запросов для таких случаев. Однако, определив представление на основе подзапроса, исходный запрос может быть транскрибирован в запрос к представлению. С помощью LogicalViewScanOperator Selena может перенести несоответствующую часть в паттерн SPJG, тем самым позволяя перезаписать запрос в этих обстоятельствах.
Использование
Перезапись запросов материализованного представления на основе представления отключена по умолчанию.
Чтобы включить эту функцию, вы должны установить следующую переменную:
SET enable_view_based_mv_rewrite = true;
Случаи использования
Перезапись запросов с использованием материализованных представлений на основе одного представления
Selena поддерживает перезапись запросов с материализованным представлением, построенным на одном представлении, включая запросы с агрегациями.
Например, вы можете построить следующее представление и материализованное представление для TPC-H Query 18:
CREATE VIEW q18_view
AS
SELECT
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice,
sum(l_quantity)
FROM
customer,
orders,
lineitem
WHERE
o_orderkey IN (
SELECT
l_orderkey
FROM
lineitem
GROUP BY
l_orderkey having
sum(l_quantity) > 315
)
AND c_custkey = o_custkey
AND o_orderkey = l_orderkey
GROUP BY
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice;
CREATE MATERIALIZED VIEW q18_mv
DISTRIBUTED BY hash(c_custkey, o_orderkey)
REFRESH MANUAL
AS
SELECT * FROM q18_view;
Материализованное представление может переписать оба следующих запроса:
mysql> EXPLAIN LOGICAL SELECT * FROM q18_view;
+-------------------------------------------------------------------------------------------------------+
| Explain String |
+-------------------------------------------------------------------------------------------------------+
| - Output => [2:c_name, 1:c_custkey, 9:o_orderkey, 10:o_orderdate, 13:o_totalprice, 52:sum] |
| - SCAN [q18_mv] => [1:c_custkey, 2:c_name, 52:sum, 9:o_orderkey, 10:o_orderdate, 13:o_totalprice] |
| MaterializedView: true |
| Estimates: {row: 9, cpu: 486.00, memory: 0.00, network: 0.00, cost: 243.00} |
| partitionRatio: 1/1, tabletRatio: 96/96 |
| 1:c_custkey := 60:c_custkey |
| 2:c_name := 59:c_name |
| 52:sum := 64:sum(l_quantity) |
| 9:o_orderkey := 61:o_orderkey |
| 10:o_orderdate := 62:o_orderdate |
| 13:o_totalprice := 63:o_totalprice |
+-------------------------------------------------------------------------------------------------------+
mysql> EXPLAIN LOGICAL SELECT c_name, sum(`sum(l_quantity)`) FROM q18_view GROUP BY c_name;
+-----------------------------------------------------------------------------------------------------+
| Explain String |
+-----------------------------------------------------------------------------------------------------+
| - Output => [2:c_name, 59:sum] |
| - AGGREGATE(GLOBAL) [2:c_name] |
| Estimates: {row: 9, cpu: 306.00, memory: 306.00, network: 0.00, cost: 1071.00} |
| 59:sum := sum(59:sum) |
| - EXCHANGE(SHUFFLE) [2] |
| Estimates: {row: 9, cpu: 30.60, memory: 0.00, network: 30.60, cost: 306.00} |
| - AGGREGATE(LOCAL) [2:c_name] |
| Estimates: {row: 9, cpu: 61.20, memory: 30.60, network: 0.00, cost: 244.80} |
| 59:sum := sum(52:sum) |
| - SCAN [q18_mv] => [2:c_name, 52:sum] |
| MaterializedView: true |
| Estimates: {row: 9, cpu: 306.00, memory: 0.00, network: 0.00, cost: 153.00} |
| partitionRatio: 1/1, tabletRatio: 96/96 |
| 2:c_name := 60:c_name |
| 52:sum := 65:sum(l_quantity) |
+-----------------------------------------------------------------------------------------------------+
Перезапись запросов с JOIN с использованием материализованных представлений на основе представления
Selena поддерживает перезапись запросов с JOINs между представлениями или между представлениями и таблицами, включая агрегации на JOINs.
Например, вы можете создать следующие представления и материализованное представление:
CREATE VIEW view_1 AS
SELECT
l_partkey,
l_suppkey,
sum(l_quantity) AS total_quantity
FROM lineitem
GROUP BY
l_partkey,
l_suppkey;
CREATE VIEW view_2 AS
SELECT
l_partkey,
l_suppkey,
sum(l_tax) AS total_tax
FROM lineitem
GROUP BY
l_partkey,
l_suppkey;
CREATE MATERIALIZED VIEW mv_1
DISTRIBUTED BY hash(l_partkey, l_suppkey)
REFRESH MANUAL AS
SELECT
v1.l_partkey,
v2.l_suppkey,
total_quantity,
total_tax
FROM view_1 v1
JOIN view_2 v2 ON v1.l_partkey = v2.l_partkey
AND v1.l_suppkey = v2.l_suppkey;
Материализованное представление может переписать оба следующих запроса:
mysql> EXPLAIN LOGICAL
-> SELECT v1.l_partkey,
-> v2.l_suppkey,
-> total_quantity,
-> total_tax
-> FROM view_1 v1
-> JOIN view_2 v2 ON v1.l_partkey = v2.l_partkey
-> AND v1.l_suppkey = v2.l_suppkey;
+--------------------------------------------------------------------------------------------------------+
| Explain String |
+--------------------------------------------------------------------------------------------------------+
| - Output => [4:l_partkey, 25:l_suppkey, 17:sum, 37:sum] |
| - SCAN [mv_1] => [17:sum, 4:l_partkey, 37:sum, 25:l_suppkey] |
| MaterializedView: true |
| Estimates: {row: 799541, cpu: 31981640.00, memory: 0.00, network: 0.00, cost: 15990820.00} |
| partitionRatio: 1/1, tabletRatio: 96/96 |
| 17:sum := 43:total_quantity |
| 4:l_partkey := 41:l_partkey |
| 37:sum := 44:total_tax |
| 25:l_suppkey := 42:l_suppkey |
+--------------------------------------------------------------------------------------------------------+
mysql> EXPLAIN LOGICAL
-> SELECT v1.l_partkey,
-> sum(total_quantity),
-> sum(total_tax)
-> FROM view_1 v1
-> JOIN view_2 v2 ON v1.l_partkey = v2.l_partkey
-> AND v1.l_suppkey = v2.l_suppkey
-> group by v1.l_partkey;
+--------------------------------------------------------------------------------------------------------------------+
| Explain String |
+--------------------------------------------------------------------------------------------------------------------+
| - Output => [4:l_partkey, 41:sum, 42:sum] |
| - AGGREGATE(GLOBAL) [4:l_partkey] |
| Estimates: {row: 196099, cpu: 4896864.00, memory: 3921980.00, network: 0.00, cost: 29521223.20} |
| 41:sum := sum(41:sum) |
| 42:sum := sum(42:sum) |
| - EXCHANGE(SHUFFLE) [4] |
| Estimates: {row: 136024, cpu: 489686.40, memory: 0.00, network: 489686.40, cost: 19228831.20} |
| - AGGREGATE(LOCAL) [4:l_partkey] |
| Estimates: {row: 136024, cpu: 5756695.20, memory: 489686.40, network: 0.00, cost: 18249458.40} |
| 41:sum := sum(17:sum) |
| 42:sum := sum(37:sum) |
| - SCAN [mv_1] => [17:sum, 4:l_partkey, 37:sum] |
| MaterializedView: true |
| Estimates: {row: 799541, cpu: 28783476.00, memory: 0.00, network: 0.00, cost: 14391738.00} |
| partitionRatio: 1/1, tabletRatio: 96/96 |
| 17:sum := 45:total_quantity |
| 4:l_partkey := 43:l_partkey |
| 37:sum := 46:total_tax |
+--------------------------------------------------------------------------------------------------------------------+
Перезапись запросов с использованием материализованных представлений, построенных на представлениях на основе внешних таблиц
Вы можете построить представления на таблицах во внешних каталогах, а затем материализованные представления на представлениях для перезаписи запросов. Использование аналогично таковому для внутренних таблиц.
Перезапись материализованного представления на основе внешнего каталога
Selena поддерживает построение асинхронных материализованных представлений на Hive catalogs, Hudi catalogs, Iceberg catalogs и Paimon catalogs и прозрачную перезапись запросов с их помощью.
Текстовая перезапись материализованного представления
Начиная с v1.5.2, Selena поддерживает текстовую перезапись материализованного представления, которая значительно расширяет возможности перезаписи запросов.
Основы
Для достижения текстовой перезаписи материализованного представления Selena сравнивает абстрактное синтаксическое дерево запроса (или его подзапросов) с таковым определения материализованного представления. Когда они соответствуют друг другу, Selena переписывает запрос на основе материализованного представления. Текстовая перезапись материализованного представления проста, эффективна и имеет меньше ограничений, чем обычная перезапись запросов материализованного представления типа SPJG. При правильном использовании эта функция может значительно ускорить производительность запросов.
Текстовая перезапись материализованного представления не ограничивается операторами типа SPJG. Она также поддерживает операт�оры, такие как Union, Window, Order, Limit и CTE.
Использование
Текстовая перезапись материализованного представления включена по умолчанию. Вы можете вручную отключить эту функцию, установив переменную enable_materialized_view_text_match_rewrite в false.
Элемент конфигурации FE enable_materialized_view_text_based_rewrite контролирует, строить ли абстрактное синтаксическое дерево при создании асинхронного материализованного представления. Эта функция также включена по умолчанию. Установка этого элемента в false отключит текстовую перезапись материализованного представления на системном уровне.
Переменная materialized_view_subuqery_text_match_max_count контролирует максимальное количество раз для сравнения абстрактных синтаксических деревьев материализованного представления и подзапросов. Значение по умолчанию — 4. Увеличение этого значения также увеличит потребление времени оптимизатора.
Обратите внимание, что только когда материализованное представление соответствует требованию своевременности (согласованность данных), оно может использоваться для текстовой перезаписи запросов. Вы можете вручную установить правило проверки согласованности, используя свойство query_rewrite_consistency при создании материализованного представления. Для получения дополнительной информации см. CREATE MATERIALIZED VIEW.
Случаи использования
Запросы подходят для текстовой перезаписи материализованного представления в следующих сценариях:
- Исходный запрос соответствует определению материализованного представления.
- Подзапрос исходного запроса соответствует определению материализованного представления.
По сравнению с обычной перезаписью запросов материализованного представления типа SPJG, текстовая перезапись материализованного представления поддерживает более сложные запросы, например, многоуровневые агрегации.
- Рекомендуется инкапсулировать запрос для соответствия в подзапросе исходного запроса.
- Пожалуйста, не инкапсулируйте операторы ORDER BY в определении материализованного представления или подзапросе исходного запроса. В противном случае запрос не может быть переписан, потому что операторы ORDER BY в подзапросе исключаются по умолчанию.
Например, вы можете создать следующее материализованное представление:
CREATE MATERIALIZED VIEW mv1 REFRESH MANUAL AS
SELECT
user_id,
count(1)
FROM (
SELECT
user_id,
time,
bitmap_union(to_bitmap(tag_id)) AS a
FROM user_tags
GROUP BY
user_id,
time) t
GROUP BY user_id;
Материализованное представление может переписать оба следующих запроса:
SELECT
user_id,
count(1)
FROM (
SELECT
user_id,
time,
bitmap_union(to_bitmap(tag_id)) AS a
FROM user_tags
GROUP BY
user_id,
time) t
GROUP BY user_id;
SELECT count(1)
FROM
(
SELECT
user_id,
count(1)
FROM (
SELECT
user_id,
time,
bitmap_union(to_bitmap(tag_id)) AS a
FROM user_tags
GROUP BY
user_id,
time) t
GROUP BY user_id
)m;
Однако материализованное представление не может переписать следующий запрос, потому что исходный запрос содержит оператор ORDER BY:
SELECT
user_id,
count(1)
FROM (
SELECT
user_id,
time,
bitmap_union(to_bitmap(tag_id)) AS a
FROM user_tags
GROUP BY
user_id,
time) t
GROUP BY user_id
ORDER BY user_id;
Настройка перезаписи запросов
Вы можете настроить перезапись запросов асинхронного материализованного представления через следующие переменные сеанса:
| Переменная | По умолчанию | Описание |
|---|---|---|
| enable_materialized_view_union_rewrite | true | Логическое значение для контроля, включать ли перезапись запросов Union материализованного представления. |
| enable_rule_based_materialized_view_rewrite | true | Логическое значение для контроля, включать ли перезапись запросов материализованного представления на основе правил. Эта переменная в основном используется в перезаписи запросов одной таблицы. |
| nested_mv_rewrite_max_level | 3 | Максимальные уровни вложенных материализованных представлений, которые могут использоваться для перезаписи запросов. Тип: INT. Диапазон: [1, +∞). Значение 1 указывает, что материализованные представления, созданные на других материализованных представлениях, не будут использоваться для перезаписи запросов. |
Проверка, переписан ли запрос
Вы можете проверить, переписан ли ваш запрос, просмотрев его план запроса с помощью оператора EXPLAIN. Если поле TABLE в разделе OlapScanNode показывает имя соответствующего материализованного представления, это означает, что запрос был переписан на основе материализованного представления.
mysql> EXPLAIN SELECT
order_id, sum(goods.price) AS total
FROM order_list INNER JOIN goods
ON goods.item_id1 = order_list.item_id2
GROUP BY order_id;
+------------------------------------+
| Explain String |
+------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:1: order_id | 8: sum |
| PARTITION: RANDOM |
| |
| RESULT SINK |
| |
| 1:Project |
| | <slot 1> : 9: order_id |
| | <slot 8> : 10: total |
| | |
| 0:OlapScanNode |
| TABLE: order_mv |
| PREAGGREGATION: ON |
| partitions=1/1 |
| rollup: order_mv |
| tabletRatio=0/12 |
| tabletList= |
| cardinality=3 |
| avgRowSize=4.0 |
| numNodes=0 |
+------------------------------------+
20 rows in set (0.01 sec)
Отключение перезаписи запросов
По умолчанию Selena включает перезапись запросов для асинхронных материализованных представлений, созданных на основе default catalog. Вы можете отключить эту функцию, установив переменную сеанса enable_materialized_view_rewrite в false.
Для асинхронных материализованных представлений, созданных на основе внешнего каталога, вы можете отключить эту функцию, установив свойство материализованного представления force_external_table_query_rewrite в false, используя ALTER MATERIALIZED VIEW.
Ограничения
В отношении перезаписи запросов материализованного представления Selena в настоящее время имеет следующие ограничения:
- Selena не поддерживает перезапись запросов с недетерминированными функциями, включая rand, random, uuid и sleep.
- Selena не поддерживает перезапись запросов с оконными функциями.
- Материализованные представления, определенные с операторами, содержащими LIMIT, ORDER BY, UNION, EXCEPT, INTERSECT, MINUS, GROUPING SETS, WITH CUBE или WITH ROLLUP, не могут использоваться для перезаписи запросов.
- Строгая согласованность результатов запросов не гарантируется ме�жду базовыми таблицами и материализованными представлениями, построенными на внешних каталогах.
- Асинхронные материализованные представления, созданные на базовых таблицах в JDBC catalog, не поддерживают перезапись запросов.
В отношении перезаписи запросов материализованного представления на основе представления Selena в настоящее время имеет следующие ограничения:
-
В настоящее время Selena не поддерживает перезапись Partition Union.
-
Перезапись запросов не поддерживается, если представление содержит случайные функции, включая rand(), random(), uuid() и sleep().
-
Перезапись запросов не поддерживается, если представление содержит столбцы с одинаковыми именами. Вы должны назначить разные псевдонимы для столбцов с одинаковыми именами.
-
Представления, которые используются для создания материализованного представления, должны содержать по крайней мере один столбец следующих типов данных: целочисленные типы, типы дат и строковые типы. Например, вы не можете создать материализованное, которое запрашивает представление, потому что
total_costявляется столбцом типа DOUBLE.CREATE VIEW v1
AS
SELECT sum(cost) AS total_cost
FROM t1;