Кэш запросов
Кэш запросов — это мощная функция Selena, которая может значительно повысить производительность агрегатных запросов. Сохраняя промежуточные результаты локальных агрегаций в памяти, кэш запросов может избежать ненужного доступа к диску и вычислений для новых запросов, которые идентичны или похожи на предыдущие. Благодаря кэшу запросов Selena может быстро и точно возвращать результаты агрегатных запросов, экономя время и ресурсы и обеспечивая лучшую масштабируемость. Кэш запросов особенно полезен в сценариях с высокой параллельностью, когда много пользователей выполняют похожие запросы к большим и сложным наборам данных.
Эта функция поддерживается в cluster с раздельным хранением (shared-nothing) начиная с версии v1.5.2 и в cluster с разделяемыми данными (shared-data) начиная с версии v1.5.2.
В версии v1.5.2 кэш запросов поддерживает только агрегатные запросы к отдельным плоским таблицам. Начиная с версии v1.5.2, кэш запросов также поддерживает агрегатные запросы к нескольким таблицам, объединённым по схеме «звезда».
Сценарии применения
Рекомендуется использовать кэ�ш запросов в следующих сценариях:
- Вы часто выполняете агрегатные запросы к отдельным плоским таблицам или к нескольким объединённым таблицам, соединённым по схеме «звезда».
- Большинство ваших агрегатных запросов — это агрегатные запросы без GROUP BY и агрегатные запросы с GROUP BY с низкой кардинальностью.
- Ваши данные загружаются в режиме добавления по временным partition и могут быть классифицированы как горячие и холодные данные на основе частоты доступа.
Кэш запросов поддерживает запросы, соответствующие следующим условиям:
-
Используется движок Pipeline. Чтобы включить движок Pipeline, установите сессионную переменную
enable_pipeline_engineв значениеtrue.ПРИМЕЧАНИЕ
Другие движки запросов не поддерживают кэш запросов.
-
Запросы выполняются к нативным OLAP-таблицам (с версии v1.5.2) или облачным нативным таблицам (с версии v1.5.2). Кэш запросов не поддерживает запросы к внешним таблицам. Кэш запросов также поддерживает запросы, планы которых требуют доступа к синхронным материализованным представлениям. Однако кэш запросов не поддерживает запр�осы, планы которых требуют доступа к асинхронным материализованным представлениям.
-
Запросы являются агрегатными запросами к отдельным таблицам или к нескольким объединённым таблицам.
ПРИМЕЧАНИЕ
- Кэш запросов поддерживает Broadcast Join и Bucket Shuffle Join.
- Кэш запросов поддерживает две древовидные структуры, содержащие операторы Join: Aggregation-Join и Join-Aggregation. Shuffle join не поддерживаются в древовидной структуре Aggregation-Join, а Hash join не поддерживаются в древовидной структуре Join-Aggregation.
-
Запросы не включают недетерминированные функции, такие как
rand,random,uuidиsleep.
Кэш запросов поддерживает запросы к таблицам, использующим любую из следующих политик партиционирования: без партиционирования, многостолбцовое партиционирование и одностолбцовое партиционирование.
Ограничения функции
- Кэш запросов основан на вычислениях по tablet движка Pipeline. Вычисление по tablet означает, что pipeline driver может обрабатывать целые tablet по одному, а не обрабатывать часть tablet или много tablet вперемешку. Если количество tablet, которые должны быть обработаны каждым отдельным BE для запроса, больше или равно количеству pipeline driver, которые вызываются для выполнения этого запроса, кэш запросов работает. Количество вызываемых pipeline driver представляет фактическую степень параллелизма (DOP). Если количество tablet меньше количества pipeline driver, каждый pipeline driver обрабатывает только часть конкретного tablet. В этой ситуации результаты вычислений по tablet не могут быть получены, и поэтому кэш запросов не работает.
- В Selena агрегатный запрос состоит как минимум из четырёх стадий. Результаты вычислений по tablet, генерируемые AggregateNode на первой стадии, могут быть кэшированы только когда OlapScanNode и AggregateNode вычисляют данные из одного фрагмента. Результаты вычислений по tablet, генерируемые AggregateNode на других стадиях, не могут быть кэшированы. Для некоторых агрегатных запросов DISTINCT, если сессионная переменная
cbo_cte_reuseустановлена вtrue, кэш запросов не работает, когда OlapScanNode, который производит данные, и AggregateNode первой стадии, который потребляет произведённые данные, вычисляют данные из разных фрагментов и связаны через ExchangeNode. Следующие два примера показывают сценарии, в которых выполняются CTE-оптимизации и поэтому кэш запросов не работает:- Выходные столбцы вычисляются с использованием агрегатной функции
avg(distinct). - Выходные столбцы вычисляются несколькими агрегатными функциями DISTINCT.
- Выходные столбцы вычисляются с использованием агрегатной функции
- Если ваши данные перетасовываются перед агрегацией, кэш запросов не может ускорить запросы к этим данным.
- Если столбцы group-by или столбцы дедупликации таблицы имеют высокую кардинальность, для агрегатных запросов к этой таблице будут генерироваться большие результаты. В этих случаях запросы будут обходить кэш запросов во время выполнения.
- Кэш запросов занимает небольшой объём памяти, предоставляемой BE, для сохранения результатов вычислений. Размер кэша запросов по умолчанию составляет 512 МБ. Поэтому кэш запросов не подходит для сохранения элементов данных большого размера. Кроме того, после включения кэша запросов производительность запросов снижается, если коэффициент попадания в кэш низкий. Поэтому, если размер результатов вычислений, сгенерированных для tablet, превышает порог, указанный параметром
query_cache_entry_max_bytesилиquery_cache_entry_max_rows, кэш запросов больше не работает для запроса, и запрос переключается в режим Passthrough.
Принцип работы
Когда кэш запросов включён, каждый BE разделяет локальную агрегацию запроса на следующие две стадии:
-
Агрегация по tablet
BE обрабатывает каждый tablet индивидуальн�о. Когда BE начинает обработку tablet, он сначала проверяет кэш запросов, чтобы узнать, находится ли промежуточный результат агрегации по этому tablet в кэше запросов. Если да (попадание в кэш), BE напрямую извлекает промежуточный результат из кэша запросов. Если нет (промах кэша), BE обращается к данным на диске и выполняет локальную агрегацию для вычисления промежуточного результата. Когда BE заканчивает обработку tablet, он заполняет кэш запросов промежуточным результатом агрегации по этому tablet.
-
Межtablet агрегация
BE собирает промежуточные результаты со всех tablet, участвующих в запросе, и объединяет их в окончательный результат.
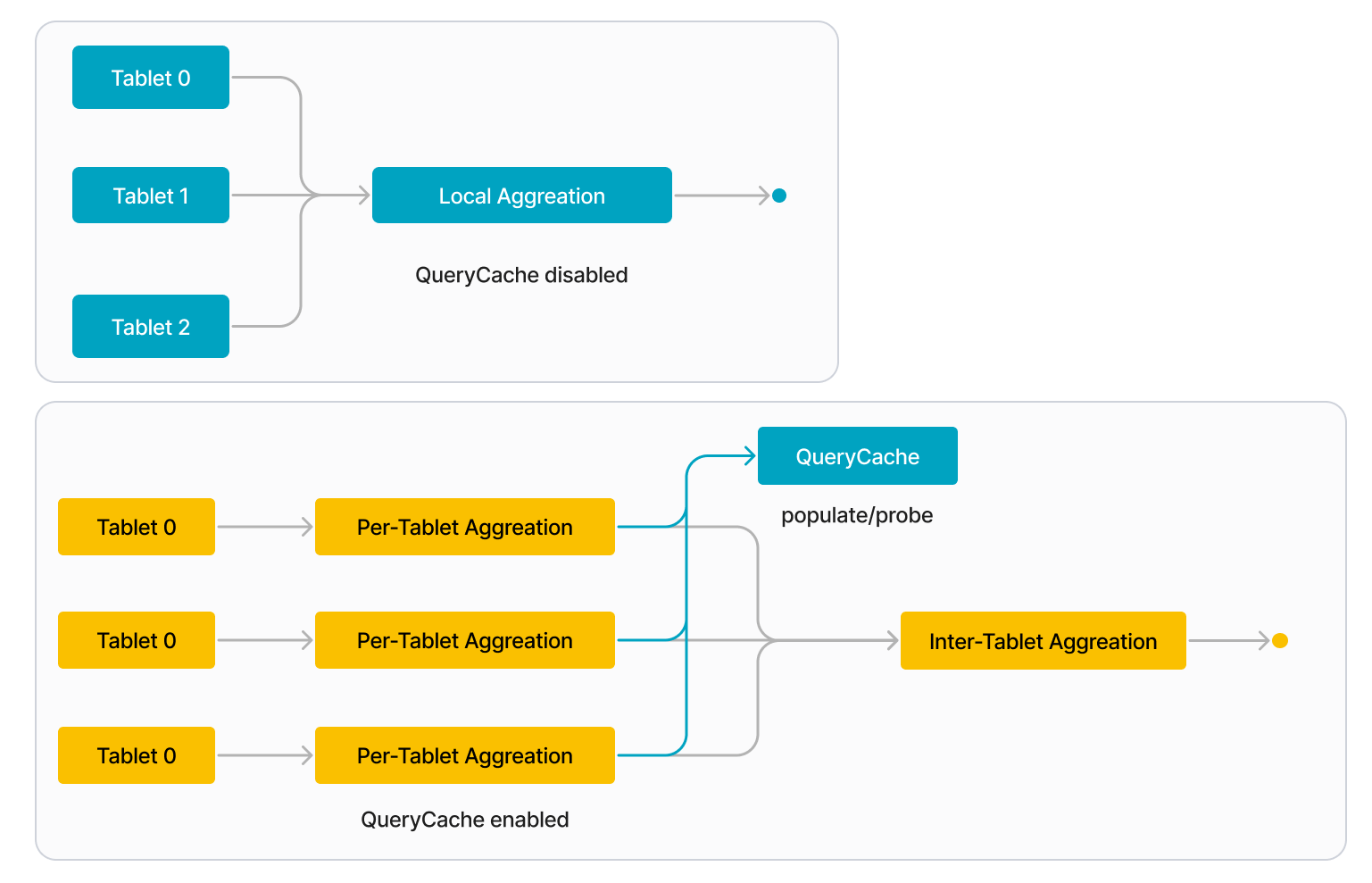
Когда в будущем выдаётся похожий запрос, он может повторно использовать кэшированный результат предыдущего запроса. Например, запрос, показанный на следующем рисунке, включает три tablet (Tablet 0–2), и промежуточный результат для первого tablet (Tablet 0) уже находится в кэше запросов. В этом примере BE может напрямую извлечь результат для Tablet 0 из кэша запросов вместо обращения к данным на диске. Если кэш запросов полностью прогрет, он может содержать промежуточные результаты для всех трёх tablet, и поэтому BE не нужно обращаться к каким-либо данным на диске.
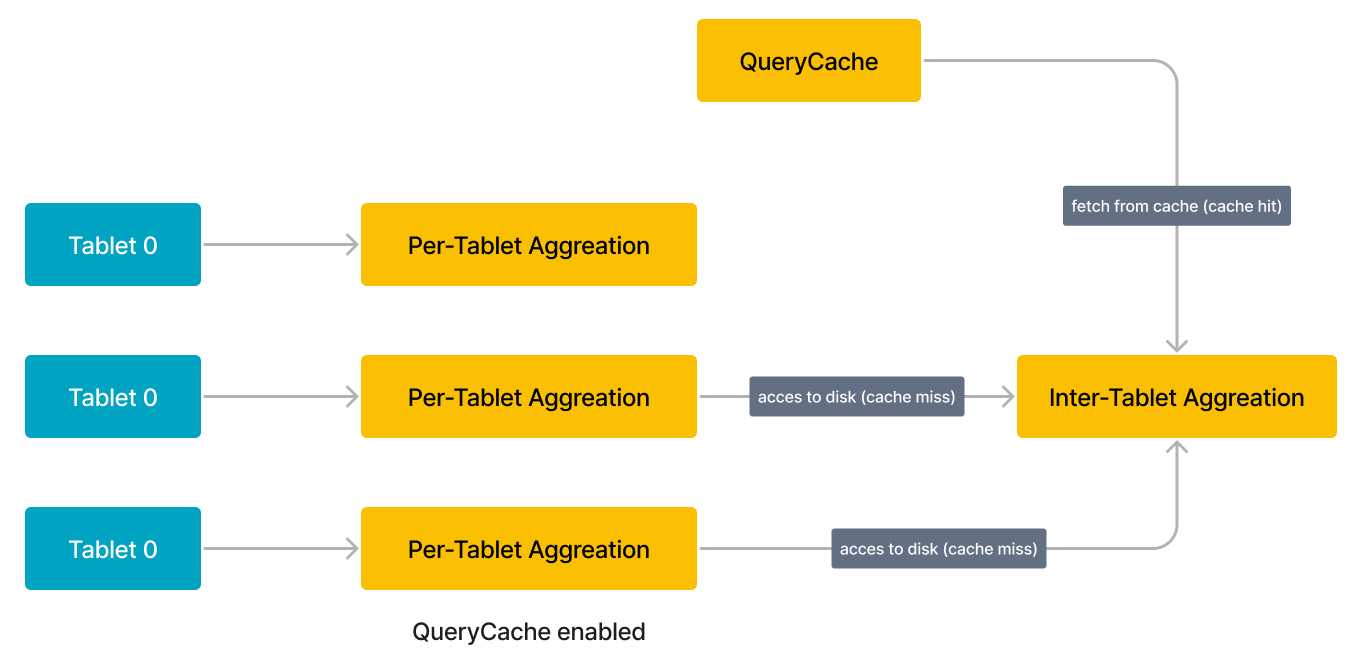
Для освобождения дополнительной памяти кэш запросов использует политику вытеснения на основе LRU (Least Recently Used) для управления записями кэша в нём. Согласно этой политике вытеснения, когда объём памяти, занимаемой кэшем запросов, превышает его предопределённый размер (query_cache_capacity), наименее недавно использованные записи кэша вытесняются из кэша запросов.
ПРИМЕЧАНИЕ
В будущем Selena также будет поддерживать политику вытеснения на основе TTL (Time to Live), согласно которой записи кэша могут быть вытеснены из кэша запросов.
FE определяет, нужно ли ускорять каждый запрос с помощью кэша запросов, и нормализует запросы для устранения тривиальных литеральных деталей, которые не влияют на семантику запросов.
Для предотвращения снижения производ�ительности, вызванного плохими случаями кэша запросов, BE применяет адаптивную политику для обхода кэша запросов во время выполнения.
Включение кэша запросов
В этом разделе описываются параметры и сессионные переменные, используемые для включения и настройки кэша запросов.
Сессионные переменные FE
| Переменная | Значение по умолчанию | Динамическая настройка | Описание |
|---|---|---|---|
| enable_query_cache | false | Да | Указывает, включать ли кэш запросов. Допустимые значения: true и false. true включает эту функцию, а false отключает её. Когда кэш запросов включён, он работает только для запросов, соответствующих условиям, указ�анным в разделе «Сценарии применения» этой темы. |
| query_cache_entry_max_bytes | 4194304 | Да | Указывает порог для запуска режима Passthrough. Допустимые значения: от 0 до 9223372036854775807. Когда количество байтов или строк из результатов вычислений конкретного tablet, к которому обращается запрос, превышает порог, указанный параметром query_cache_entry_max_bytes или query_cache_entry_max_rows, запрос переключается в режим Passthrough.Если параметр query_cache_entry_max_bytes или query_cache_entry_max_rows установлен в 0, режим Passthrough используется даже когда результаты вычислений не генерируются из задействованных tablet. |
| query_cache_entry_max_rows | 409600 | Да | То же, что и выше. |
Параметры BE
Вам нужно настроить следующий параметр в файле конфигурации BE be.conf. После перенастройки этого параметра для BE вы должны перезапустить BE, чтобы новая настройка параметра вступила в силу.
| Параметр | Обязательный | Описание |
|---|---|---|
| query_cache_capacity | Нет | Указывает размер кэша запросов. Единица измерения: байты. Размер по умолчанию — 512 МБ. Каждый BE имеет свой собственный локальный кэш запросов в памяти и заполняет и проверяет только свой собственный кэш запросов. Обратите внимание, что размер кэша запросов не может быть меньше 4 МБ. Если объём памяти BE недостаточен для обеспечения ожидаемого размера кэша запросов, вы можете увеличить объём памяти BE. |
Разработан для максимального коэффициента попадания в кэш во всех сценариях
Рассмотрим три сценария, в которых кэш запросов всё ещё эффективен, даже когда запросы не идентичны буквально. Эти три сценария:
- Семантически эквивалентные запросы
- Запросы с перекрывающимися сканируемыми partition
- Запросы к данным только с добавлением (без операций UPDATE или DELETE)
Семантически эквивалентные запросы
Когда два запроса похожи, что не означает, что они должны быть буквально эквивалентны, но означает, что они содержат семантически эквивалентные фрагменты в своих планах выполнения, они считаются семантически эквивалентными и могут повторно использовать результаты вычислений друг друга. В широком смысле два запроса семантически эквивалентны, если они запрашивают данные из одного источника, используют один и тот же метод вычислений и имеют один и тот же план выполнения. Selena применяет следующие правила для оценки семантической эквивалентности двух запросов:
-
Если два запроса содержат несколько агрегаций, они оцениваются как семантически эквивалентные, если их первые агрегации семантически эквивалентны. Например, следующие два запроса, Q1 и Q2, оба содержат несколько агрегаций, но их первые агрегации семантически эквивалентны. Поэтому Q1 и Q2 оцениваются как семантически эквивалентные.
-
Q1
SELECT
(
ifnull(sum(murmur_hash3_32(hour)), 0) + ifnull(sum(murmur_hash3_32(k0)), 0) + ifnull(sum(murmur_hash3_32(__c_0)), 0)
) AS fingerprint
FROM
(
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
) AS t; -
Q2
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
-
-
Если оба запроса относятся к одному из следующих типов запрос�ов, они могут быть оценены как семантически эквивалентные. Обратите внимание, что запросы, включающие предложение HAVING, не могут быть оценены как семантически эквивалентные запросам, не включающим предложение HAVING. Однако включение предложения ORDER BY или LIMIT не влияет на оценку семантической эквивалентности двух запросов.
-
Агрегации GROUP BY
SELECT <GroupByItems>, <AggFunctionItems>
FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
GROUP BY <GroupByItems>
[HAVING <HavingPredicate>]ПРИМЕЧАНИЕ
В предыдущем примере предложение HAVING является необязательным.
-
Агрегации GROUP BY DISTINCT
SELECT DISTINCT <GroupByItems>, <Items>
FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
GROUP BY <GroupByItems>
HAVING <HavingPredicate>ПРИМЕЧАНИЕ
В предыдущем примере предложение HAVING является необязательным.
-
Агрегации без GROUP BY
SELECT <AggFunctionItems> FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>] -
Агрегации без GROUP BY DISTINCT
SELECT DISTINCT <Items> FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
-
-
Если любой запрос включает
PartitionColumnRangePredicate, он удаляется перед оценкой двух запросов на семантическую эквивалентность.PartitionColumnRangePredicateуказывает один из следующих типов предикатов, ссылающихся на столбец партиционирования:col between v1 and v2: Значения столбца партиционирования находятся в диапазоне [v1, v2], гдеv1иv2— константные выражения.v1 < col and col < v2: Значения столбца партиционирования находятся в диапазоне (v1, v2), гдеv1иv2— константные выражения.v1 < col and col <= v2: Значения столбца партиционирования находятся в диапазоне (v1, v2], гдеv1иv2— константные выражения.v1 <= col and col < v2: Значения столбца партиционирования находятся в диапазоне [v1, v2), гдеv1иv2— константные выражения.v1 <= col and col <= v2: Значения столбца партиционирования находятся в диапазоне [v1, v2], гдеv1иv2— константные выражения.
-
Если выходные столбцы предложений SELECT двух запросов одинаковы после их перестановки, два запроса оцениваются как семантически эквивалентные.
-
Если выходные столбцы предложений GROUP BY двух запросов одинаковы после их перестановки, два запроса оцениваются как семантически эквивалентные.
-
Если оставшиеся предикаты предложений WHERE двух запросов семантически эквивалентны после удаления
PartitionColumnRangePredicate, два запроса оцениваются как семантически эквивалентные. -
Если предикаты в предложениях HAVING двух запросов семантически эквивалентны, два запроса оцениваются как семантически эквивалентные.
Используйте следующую таблицу lineorder_flat в качестве примера:
CREATE TABLE `lineorder_flat`
(
`lo_orderdate` date NOT NULL COMMENT "",
`lo_orderkey` int(11) NOT NULL COMMENT "",
`lo_linenumber` tinyint(4) NOT NULL COMMENT "",
`lo_custkey` int(11) NOT NULL COMMENT "",
`lo_partkey` int(11) NOT NULL COMMENT "",
`lo_suppkey` int(11) NOT NULL COMMENT "",
`lo_orderpriority` varchar(100) NOT NULL COMMENT "",
`lo_shippriority` tinyint(4) NOT NULL COMMENT "",
`lo_quantity` tinyint(4) NOT NULL COMMENT "",
`lo_extendedprice` int(11) NOT NULL COMMENT "",
`lo_ordtotalprice` int(11) NOT NULL COMMENT "",
`lo_discount` tinyint(4) NOT NULL COMMENT "",
`lo_revenue` int(11) NOT NULL COMMENT "",
`lo_supplycost` int(11) NOT NULL COMMENT "",
`lo_tax` tinyint(4) NOT NULL COMMENT "",
`lo_commitdate` date NOT NULL COMMENT "",
`lo_shipmode` varchar(100) NOT NULL COMMENT "",
`c_name` varchar(100) NOT NULL COMMENT "",
`c_address` varchar(100) NOT NULL COMMENT "",
`c_city` varchar(100) NOT NULL COMMENT "",
`c_nation` varchar(100) NOT NULL COMMENT "",
`c_region` varchar(100) NOT NULL COMMENT "",
`c_phone` varchar(100) NOT NULL COMMENT "",
`c_mktsegment` varchar(100) NOT NULL COMMENT "",
`s_name` varchar(100) NOT NULL COMMENT "",
`s_address` varchar(100) NOT NULL COMMENT "",
`s_city` varchar(100) NOT NULL COMMENT "",
`s_nation` varchar(100) NOT NULL COMMENT "",
`s_region` varchar(100) NOT NULL COMMENT "",
`s_phone` varchar(100) NOT NULL COMMENT "",
`p_name` varchar(100) NOT NULL COMMENT "",
`p_mfgr` varchar(100) NOT NULL COMMENT "",
`p_category` varchar(100) NOT NULL COMMENT "",
`p_brand` varchar(100) NOT NULL COMMENT "",
`p_color` varchar(100) NOT NULL COMMENT "",
`p_type` varchar(100) NOT NULL COMMENT "",
`p_size` tinyint(4) NOT NULL COMMENT "",
`p_container` varchar(100) NOT NULL COMMENT ""
)
ENGINE=OLAP
DUPLICATE KEY(`lo_orderdate`, `lo_orderkey`)
COMMENT "olap"
PARTITION BY RANGE(`lo_orderdate`)
(PARTITION p1 VALUES [('0000-01-01'), ('1993-01-01')),
PARTITION p2 VALUES [('1993-01-01'), ('1994-01-01')),
PARTITION p3 VALUES [('1994-01-01'), ('1995-01-01')),
PARTITION p4 VALUES [('1995-01-01'), ('1996-01-01')),
PARTITION p5 VALUES [('1996-01-01'), ('1997-01-01')),
PARTITION p6 VALUES [('1997-01-01'), ('1998-01-01')),
PARTITION p7 VALUES [('1998-01-01'), ('1999-01-01')))
DISTRIBUTED BY HASH(`lo_orderkey`)
PROPERTIES
(
"replication_num" = "3",
"colocate_with" = "groupxx1",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "true",
"compression" = "LZ4"
);
Следующие два запроса, Q1 и Q2, к таблице lineorder_flat семантически эквивалентны после их обработки следующим образом:
- Перестановка выходных столбцов оператора SELECT.
- Перестановка выходных столбцов предложения GROUP BY.
- Удаление выходных столбцов предложения ORDER BY.
- Перестановка предикатов в предложении WHERE.
- Добавление
PartitionColumnRangePredicate.
-
Q1
SELECT sum(lo_revenue), year(lo_orderdate) AS year,p_brand
FROM lineorder_flat
WHERE p_category = 'MFGR#12' AND s_region = 'AMERICA'
GROUP BY year,p_brand
ORDER BY year,p_brand; -
Q2
SELECT year(lo_orderdate) AS year, p_brand, sum(lo_revenue)
FROM lineorder_flat
WHERE s_region = 'AMERICA' AND p_category = 'MFGR#12' AND
lo_orderdate >= '1993-01-01' AND lo_orderdate <= '1993-12-31'
GROUP BY p_brand, year(lo_orderdate)
Семантическая эквивалентность оценивается на основе физических планов запросов. Поэтому буквальны�е различия в запросах не влияют на оценку семантической эквивалентности. Кроме того, константные выражения удаляются из запросов, а выражения cast удаляются во время оптимизации запросов. Поэтому эти выражения не влияют на оценку семантической эквивалентности. В-третьих, псевдонимы столбцов и отношений также не влияют на оценку семантической эквивалентности.
Запросы с перекрывающимися сканируемыми partition
Кэш запросов поддерживает разделение запросов на основе предикатов.
Разделение запросов на основе семантики предикатов помогает реализовать повторное использование частичных результатов вычислений. Когда запрос содержит предикат, ссылающийся на столбец партиционирования таблицы, и предикат указывает диапазон значений, Selena может разделить диапазон на несколько интервалов на основе партицион�ирования таблицы. Результаты вычислений из каждого отдельного интервала могут быть отдельно повторно использованы другими запросами.
Используйте следующую таблицу t0 в качестве примера:
CREATE TABLE if not exists t0
(
ts DATETIME NOT NULL,
k0 VARCHAR(10) NOT NULL,
k1 BIGINT NOT NULL,
v1 DECIMAL64(7, 2) NOT NULL
)
ENGINE=OLAP
DUPLICATE KEY(`ts`, `k0`, `k1`)
COMMENT "OLAP"
PARTITION BY RANGE(ts)
(
START ("2022-01-01 00:00:00") END ("2022-02-01 00:00:00") EVERY (INTERVAL 1 day)
)
DISTRIBUTED BY HASH(`ts`, `k0`, `k1`)
PROPERTIES
(
"replication_num" = "3",
"storage_format" = "default"
);
Таблица t0 партиционирована по дням, и столбец ts является столбцом партиционирования таблицы. Среди следующих четырёх запросов Q2, Q3 и Q4 могут повторно использовать части результатов вычислений, кэшированных для Q1:
-
Q1
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts BETWEEN '2022-01-02 12:30:00' AND '2022-01-14 23:59:59'
GROUP BY day;Диапазон значений, указанный предикатом
ts between '2022-01-02 12:30:00' and '2022-01-14 23:59:59'запроса Q1, может быть разделён на следующие интервалы:1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00),
...
12. [2022-01-13 00:00:00, 2022-01-14 00:00:00),
13. [2022-01-14 00:00:00, 2022-01-15 00:00:00), -
Q2
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts >= '2022-01-02 12:30:00' AND ts < '2022-01-05 00:00:00'
GROUP BY day;Q2 может повторно использовать результаты вычислений в следующих интервалах Q1:
1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00), -
Q3
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts >= '2022-01-01 12:30:00' AND ts <= '2022-01-10 12:00:00'
GROUP BY day;Q3 может повторно использовать результаты вычислений в следующих интервалах Q1:
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00),
...
8. [2022-01-09 00:00:00, 2022-01-10 00:00:00), -
Q4
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts BETWEEN '2022-01-02 12:30:00' and '2022-01-02 23:59:59'
GROUP BY day;Q4 может повторно использовать результаты вычислений в следующих интервалах Q1:
1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
Поддержка повторного использования частичных результатов вычислений варьируется в зависимости от используемой политики партиционирования, как описано в следующей таблице.
| Политика партиционирования | Поддержка повторного использования частичных результатов вычислений |
|---|---|
| Без партиционирования | Не поддерживается |
| Многостолбцовое партиционирование | Не поддерживается ПРИМЕЧАНИЕ Эта функция может быть поддержана в будущем. |
| Одностолбцовое партиционирование | Поддерживается |
Запросы к данным только с добавлением
Кэш запросов поддерживает многоверсионное кэширование.
По мере выполнения загрузок данных генерируются новые версии tablet. Следовательно, кэшированные результаты вычислений, которые генерируются из предыдущих версий tablet, становятся устаревшими и отстают от последних версий tablet. В этой ситуации механизм многоверсионного кэширования пытается объединить устаревшие результаты, сохранённые в кэше запросов, и инкрементальные версии tablet, хранящиеся на диске, в окончательные результаты tablet, чтобы новые запросы могли содержать последние версии tablet. Многоверсионное кэширование ограничено типами таблиц, типами запросов и типами обновления данных.
Поддержка многоверсионного кэширования варьируется в зависимости от типов таблиц и типов запросов, как описано в следующей таблице.
| Тип таблицы | Тип запроса | Поддержка многоверсионного кэширования |
|---|---|---|
| Duplicate Key table |
|
|
| Aggregate table | Запросы к базовым таблицам или запросы к синхронным материализованным представлениям | Поддерживается во всех ситуациях, кроме следующих: схемы базовых таблиц содержат агрегатную функцию replace. Предложения GROUP BY, HAVING или WHERE запросов ссылаются на столбцы агрегации. Инкрементальные версии tablet содержат записи об удалении данных. |
| Unique Key table | Н/Д | Не поддерживается. Однако кэш запросов поддерживается. |
| Primary Key table | Н/Д | Не поддерживается. Однако кэш запросов поддерживается. |
Влияние типов обновления данных на многоверсионное кэширование следующее:
-
Удаление данных
Многоверсионное кэширование не может работать, если инкрементальные версии tablet содержат операции удаления.
-
Вставка данных
- Если для tablet генерируется пустая версия, существующие данные tablet в кэше запросов остаются действительными и всё ещё могут быть извлечены.
- Если для tablet генерируется непустая версия, существующие данные tablet в кэше запросов остаются действительными, но их версия отстаёт от последней версии tablet. В этой ситуации Selena читает инкрементальные данные, сгенерированные от версии существующих данных до последней версии tablet, объединяет существующие данные с инкрементальными данными и заполняет объединённые данные в кэш запросов.
-
Изменения схемы и усечение tablet
Если схема таблицы изменяется или конкретные tablet таблицы усекаются, для таблицы генерируются новые tablet. В результате существующие данные tablet таблицы в кэше запросов становятся недействительными.
Метрики
Профили запросов, для которых работает кэш запросов, содержат статистику CacheOperator.
В исходном плане запроса, если pipeline содержит OlapScanOperator, имена OlapScanOperator и операторов агрегации имеют п�рефикс ML_, чтобы обозначить, что pipeline использует MultilaneOperator для выполнения вычислений по tablet. CacheOperator вставляется перед ML_CONJUGATE_AGGREGATE для обработки логики, управляющей работой кэша запросов в режимах Passthrough, Populate и Probe. Профиль запроса содержит следующие метрики CacheOperator, которые помогают понять использование кэша запросов.
| Метрика | Описание |
|---|---|
| CachePassthroughBytes | Количество байтов, сгенерированных в режиме Passthrough. |
| CachePassthroughChunkNum | Количество chunks, сгенерированных в режиме Passthrough. |
| CachePassthroughRowNum | Количество строк, сгенерированных в режиме Passthrough. |
| CachePassthroughTabletNum | Количество tablet, сгенерированных в режиме Passthrough. |
| CachePassthroughTime: | Количество времени вычислений в режиме Passthrough. |
| CachePopulateBytes | Количество байтов, сгенерированных в режиме Populate. |
| CachePopulateChunkNum | Количество chunks, сгенерированных в режиме Populate. |
| CachePopulateRowNum | Количество строк, сгенерированных в режиме Populate. |
| CachePopulateTabletNum | Количество tablet, сгенерированных в режиме Populate. |
| CachePopulateTime | Количество времени вычислений в режиме Populate. |
| CacheProbeBytes | Количество байтов, сгенерированных для попаданий в кэш в режиме Probe. |
| CacheProbeChunkNum | Количество chunks, сгенерированных для попаданий в кэш в режиме Probe. |
| CacheProbeRowNum | Количество строк, сгенерированных для попаданий в кэш в режиме Probe. |
| CacheProbeTabletNum | Количество tablet, сгенерированных для попаданий в кэш в режиме Probe. |
| CacheProbeTime | Количество времени вычислений в режиме Probe. |
Метрики CachePopulateXXX предоставляют статистику о промахах кэша запросов, для которых кэш запросов обновляется.
Метрики CachePassthroughXXX предоставляют статистику о промахах кэша запросов, для которых кэш запросов не обновляется, потому что размер результатов вычислений по tablet большой.
Метрики CacheProbeXXX предоставляют статистику о попаданиях в кэш запросов.
В механизме многоверсионного кэширования метрики CachePopulate и метрики CacheProbe могут содержать одну и ту же статистику tablet, а метрики CachePassthrough и метрики CacheProbe также могут содержать одну и ту же статистику tablet. Например, когда Selena вычисляет данные каждого tablet, она попадает в результаты вычислений, сгенерированные на исторической версии tablet. В этой ситуации Selena читает инкрементальные данные, сгенерированные от исторической версии до последней версии tablet, вычисляет данные и объединяет инкрементальные данные с кэшированными данными. Если размер результатов вычислений, сгенерированных после объединения, не превышает порог, указанный параметром query_cache_entry_max_bytes или query_cache_entry_max_rows, статистика tablet собирается в метрики CachePopulate. В противном случае статистика tablet собирается в метрики CachePassthrough.
Операции RESTful API
-
metrics |grep query_cacheЭта операция API используется для запроса метрик, связанных с кэшем запросов.
curl -s http://<be_host>:<be_http_port>/metrics |grep query_cache
# TYPE selena_be_query_cache_capacity gauge
selena_be_query_cache_capacity 536870912
# TYPE selena_be_query_cache_hit_count gauge
selena_be_query_cache_hit_count 5084393
# TYPE selena_be_query_cache_hit_ratio gauge
selena_be_query_cache_hit_ratio 0.984098
# TYPE selena_be_query_cache_lookup_count gauge
selena_be_query_cache_lookup_count 5166553
# TYPE selena_be_query_cache_usage gauge
selena_be_query_cache_usage 0
# TYPE selena_be_query_cache_usage_ratio gauge
selena_be_query_cache_usage_ratio 0.000000 -
api/query_cache/statЭта операция API используется для запроса использования кэша запросов.
curl http://<be_host>:<be_http_port>/api/query_cache/stat
{
"capacity": 536870912,
"usage": 0,
"usage_ratio": 0.0,
"lookup_count": 5025124,
"hit_count": 4943720,
"hit_ratio": 0.983800598751394
} -
api/query_cache/invalidate_allЭта операция API используется для очистки кэша запросов.
curl -XPUT http://<be_host>:<be_http_port>/api/query_cache/invalidate_all
{
"status": "OK"
}
Параметры в предыдущих операциях API следующие:
be_host: IP-адрес узла, на котором находится BE.be_http_port: номер HTTP-порта узла, на котором находится BE.
Предостережения
- Selena необходимо заполнить кэш запросов результатами вычислений запросов, которые инициируются впервые. В результате производительность запросов может быть немного ниже ожидаемой, и задержка запросов увеличивается.
- Если вы настроите большой размер кэша запросов, объём памяти, который может быть предоставлен для оценки запросов на BE, уменьшается. Рекомендуется, чтобы размер кэша запросов не превышал 1/6 объёма памяти, предоставляемой для оценки запросов.
- Если количество tablet, которые необходимо обработать, меньше значения
pipeline_dop, кэш запросов не работает. Чтобы кэш запросов работал, вы можете установитьpipeline_dopв меньшее значение, например1. Начиная с версии v1.5.2, Selena адаптивно регулирует этот параметр на основе параллелизма запросов.
Примеры
Набор данных
-
Войдите в свой cluster Selena, перейдите в целевую базу данных и выполните следующую команду для создания таблицы с именем
t0:CREATE TABLE t0
(
`ts` datetime NOT NULL COMMENT "",
`k0` varchar(10) NOT NULL COMMENT "",
`k1` char(6) NOT NULL COMMENT "",
`v0` bigint(20) NOT NULL COMMENT "",
`v1` decimal64(7, 2) NOT NULL COMMENT ""
)
ENGINE=OLAP
DUPLICATE KEY(`ts`, `k0`, `k1`)
COMMENT "OLAP"
PARTITION BY RANGE(`ts`)
(
START ("2022-01-01 00:00:00") END ("2022-02-01 00:00:00") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(`ts`, `k0`, `k1`)
PROPERTIES
(
"replication_num" = "3",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "true"
); -
Вставьте следующие записи данных в
t0:INSERT INTO t0
VALUES
('2022-01-11 20:42:26', 'n4AGcEqYp', 'hhbawx', '799393174109549', '8029.42'),
('2022-01-27 18:17:59', 'i66lt', 'mtrtzf', '100400167', '10000.88'),
...
Примеры запросов
Статистика метрик, связанных с кэшем запросов, в этом разделе является примерами и предназначена только для справки.
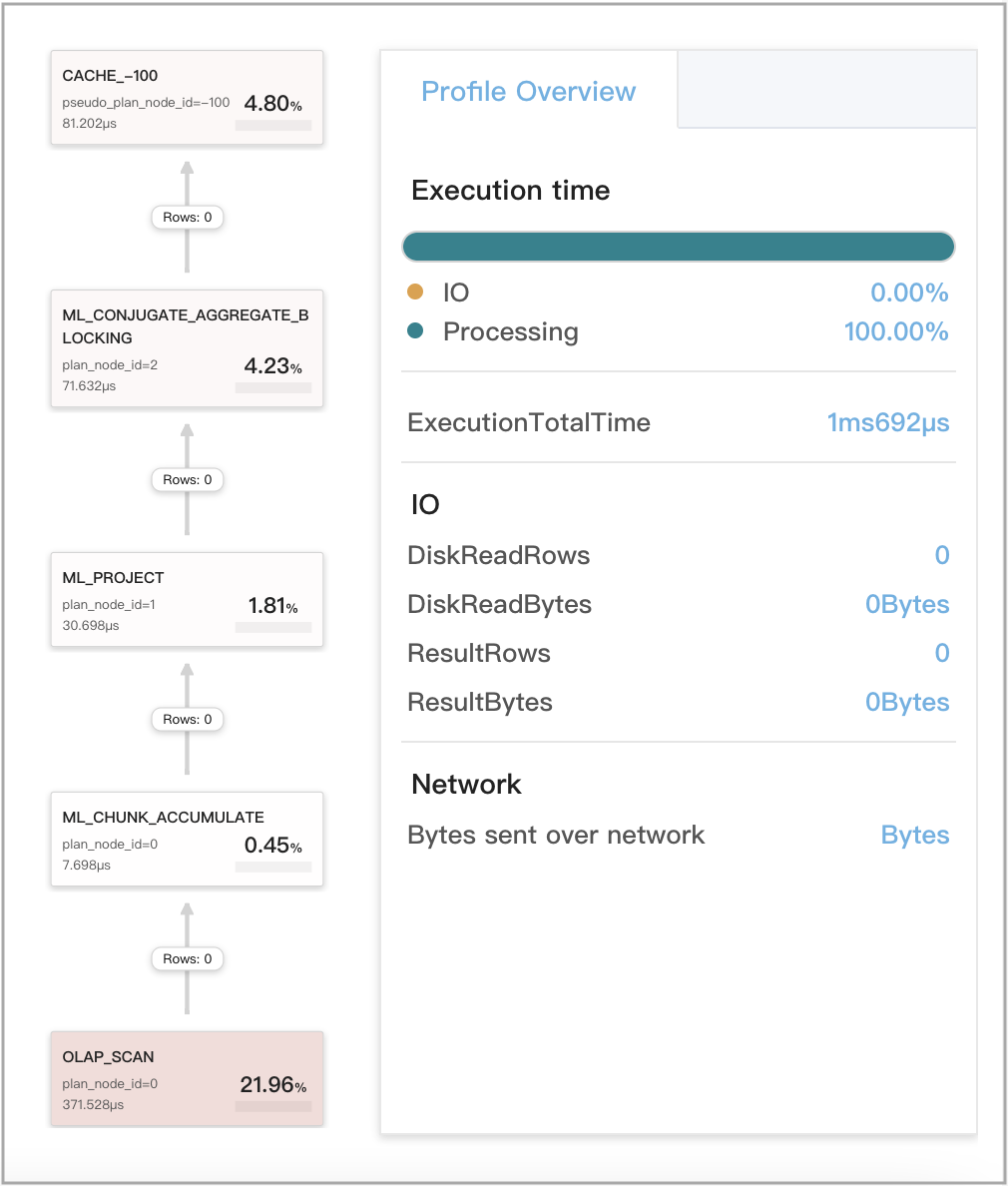
Кэш запросов работает для локальных агрегаций на стадии 1
Это включает три ситуации:
- Запрос обращается только к одному tablet.
- Запрос обращается к нескольким tablet из нескольких partition таблицы, которая сама является colocated-группой, и данные не нужно перетасовывать для агрегаций.
- Запрос обращается к нескольким tablet из одного partition таблицы, и данные не нужно перетасовывать для агрегаций.
Пример запроса:
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
На следующем рисунке показаны метрики, связанные с кэшем запросов, в профиле запроса.
Кэш запросов не работает для удалённых агрегаций на стадии 1
Когда агрегации на нескольких tablet принудительно выполняются на стадии 1, данные сначала перетасовываются, а затем агрегируются.
Пример запроса:
SET new_planner_agg_stage = 1;
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd
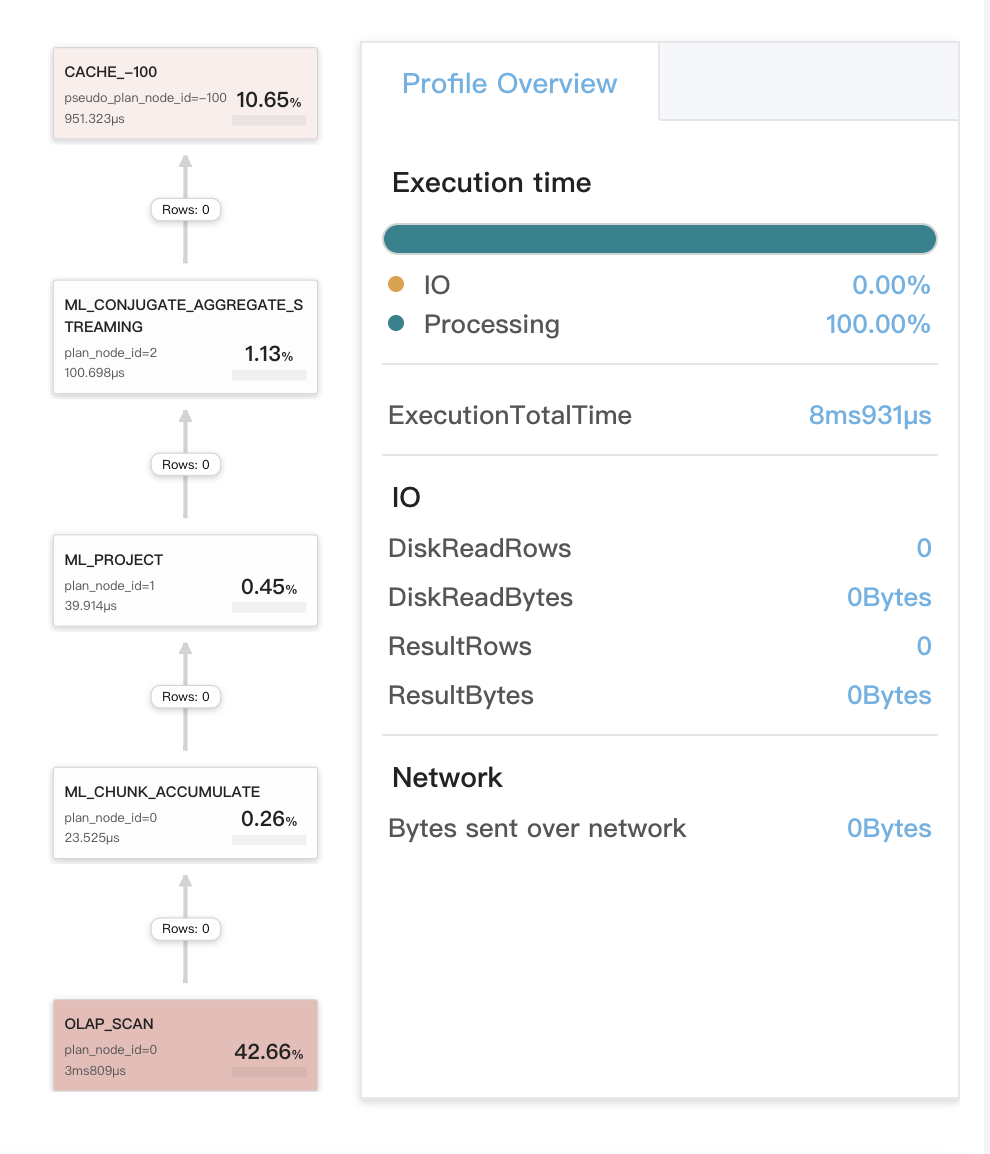
Кэш запросов работает для локальных агрегаций на стадии 2
Это включает три ситуации:
- Агрегации на стадии 2 запроса компилируются для сравнения данных одного типа. Первая агрегация — локальная. После завершения первой агрегации результаты, сгенерированные из первой агрегации, вычисляются для выполнения второй агрегации, которая является глобальной.
- Запрос является запросом SELECT DISTINCT.
- Запрос включает одну из следующих агрегатных функций DISTINCT:
sum(distinct),count(distinct)иavg(distinct). В большинстве случаев агрегации выполняются на стадии 3 или 4 для такого запроса. Однако вы можете выполнитьset new_planner_agg_stage = 1, чтобы принудительно выполнить агрегации на стадии 2 для запроса. Если запрос содержитavg(distinct)и вы хотите выполнить агрегации на стадии, вам также нужно выполнитьset cbo_cte_reuse = false, чтобы отключить CTE-оптимизации.
Пример запроса:
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd
На следующем рисунке показаны метрики, св�язанные с кэшем запросов, в профиле запроса.
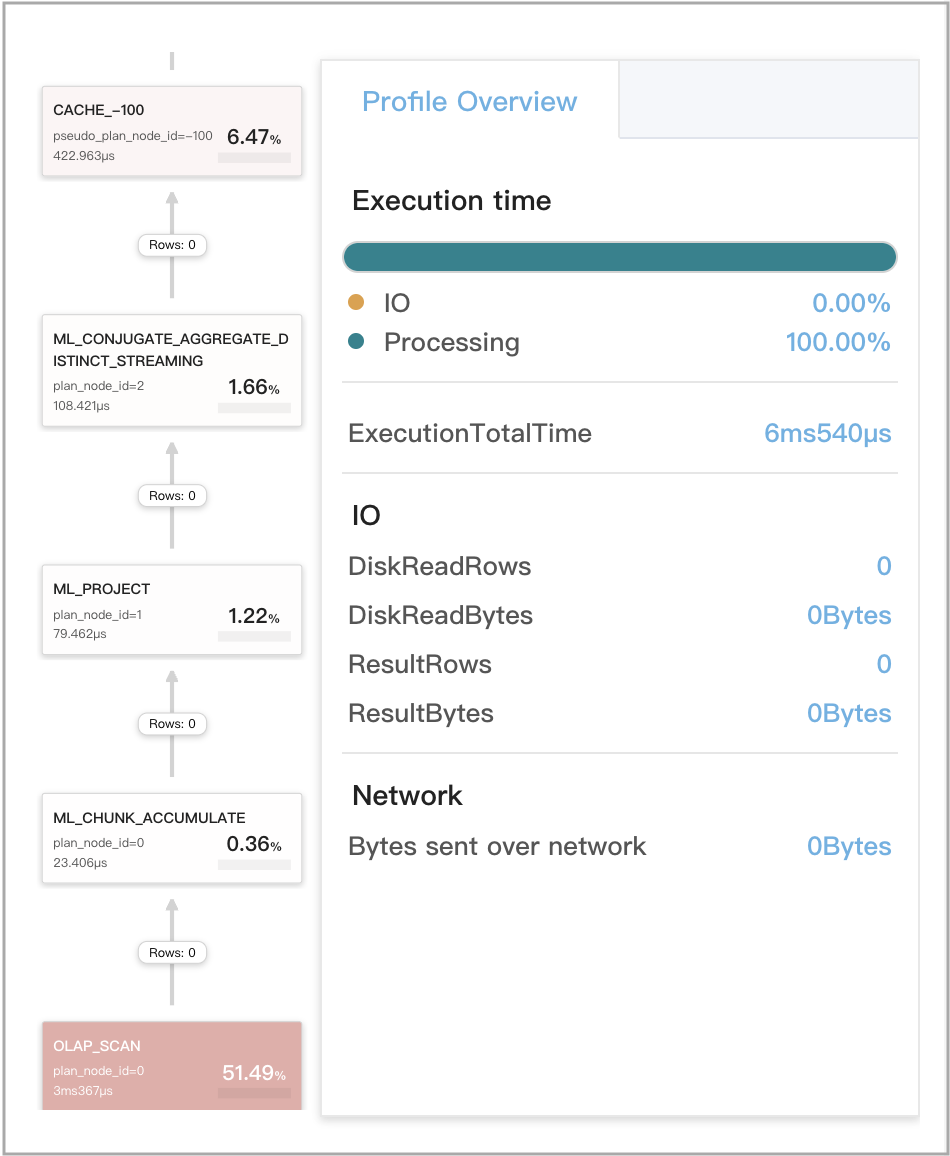
Кэш запросов работает для локальных агрегаций на стадии 3
Запрос является агрегатным запросом GROUP BY, который включает одну агрегатную функцию DISTINCT.
Поддерживаемые агрегатные функции DISTINCT: sum(distinct), count(distinct) и avg(distinct).
ВНИМАНИЕ
Если запрос включает
avg(distinct), вам также нужно выполнитьset cbo_cte_reuse = false, чтобы отключить CTE-оптимизации.
Пример запроса:
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd;
На следующем рисунке показаны метрики, связанные с кэшем запросов, в профиле запроса.
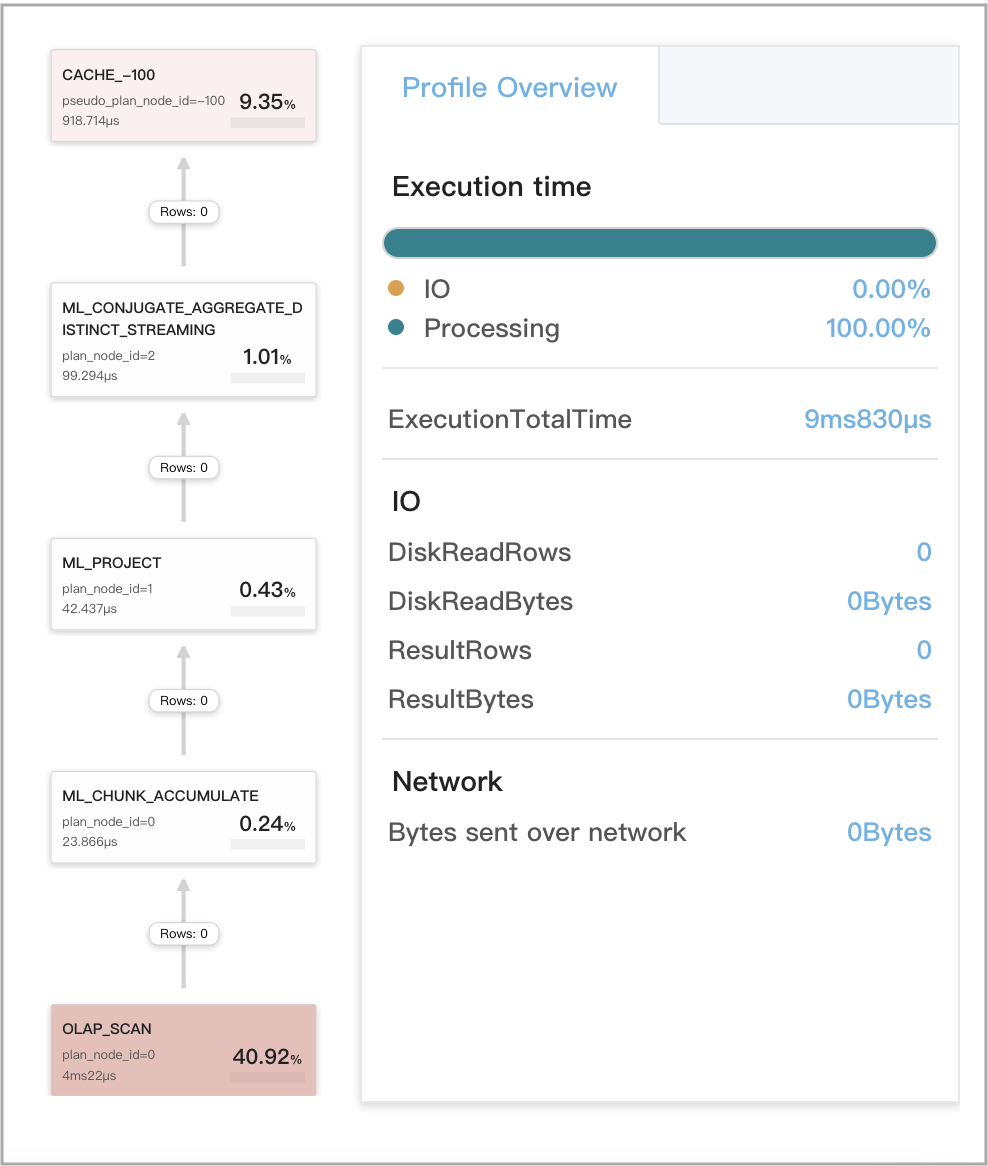
Кэш запросов работает для локальных агрегаций на стадии 4
Запрос является агрегатным запросом без GROUP BY, который включает одну агрегатную функцию DISTINCT. Такие запросы включают классические запросы на удаление дублирующих данных.
Пример запроса:
SELECT
count(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
На следующем рисунке показаны метрики, связанные с кэшем запросов, в профиле запроса.
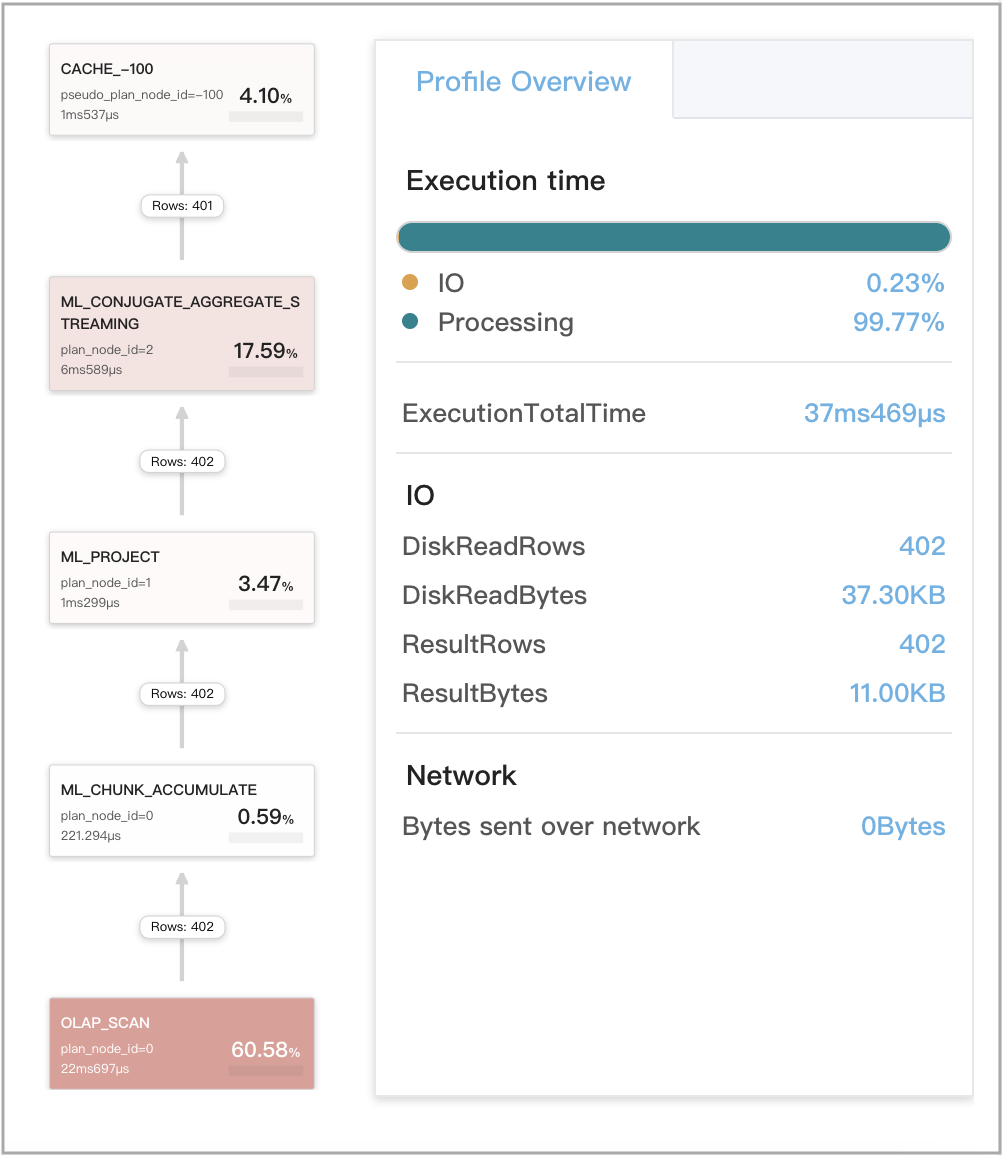
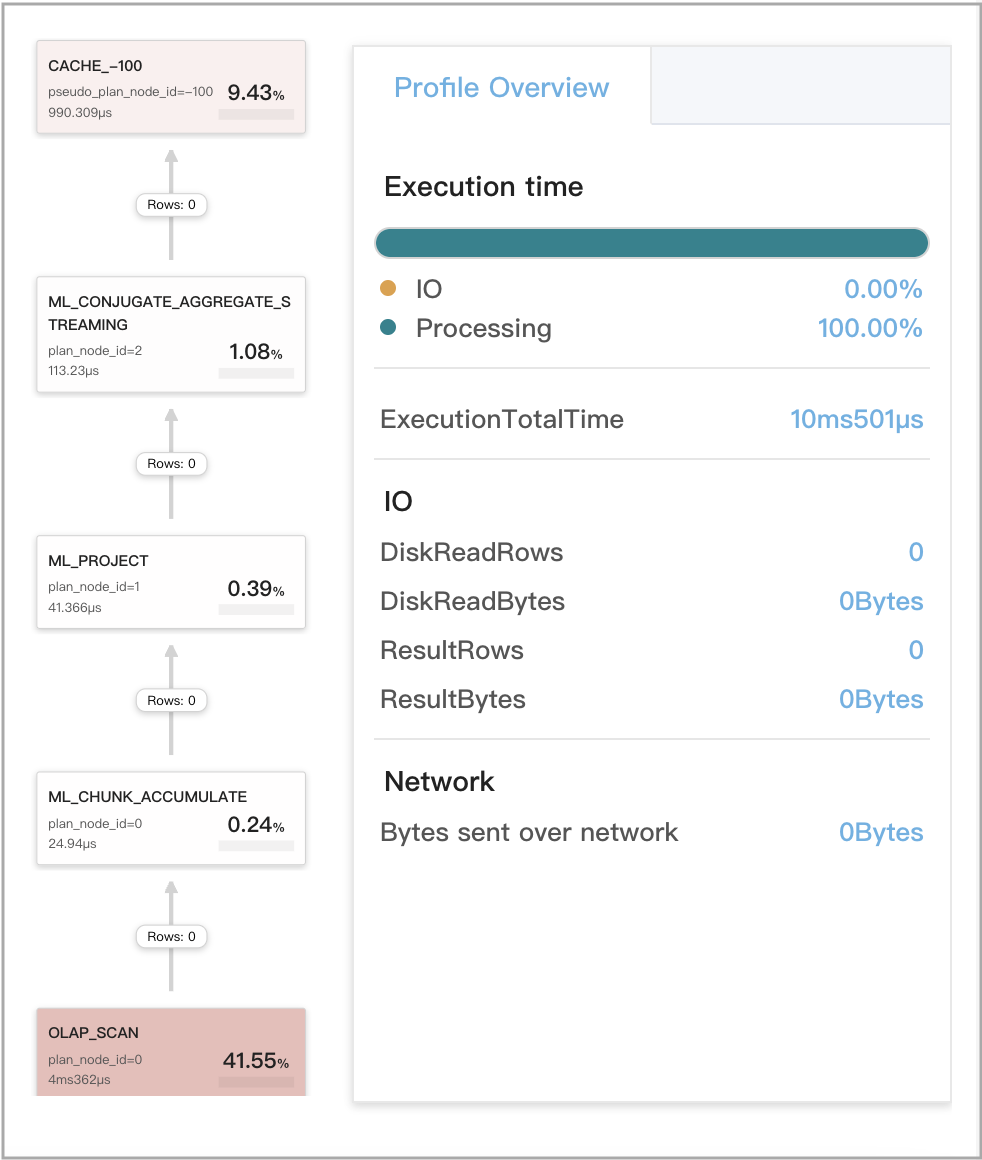
Кэшированные результаты повторно используются для двух запросов, первые агрегации которых семантически эквивалентны
Используйте следующие два запроса, Q1 и Q2, в качестве примера. Q1 и Q2 оба включают несколько агрегаций, но их первые агрегации семантически эквивалентны. Поэтому Q1 и Q2 оцениваются как семантически эквивалентные и могут повторно использовать результаты вычислений друг друга, сохранённые в кэше запросов.
-
Q1
SELECT
(
ifnull(sum(murmur_hash3_32(hour)), 0) + ifnull(sum(murmur_hash3_32(k0)), 0) + ifnull(sum(murmur_hash3_32(__c_0)), 0)
) AS fingerprint
FROM
(
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
) AS t; -
Q2
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
На следующем рисунке показаны метрики CachePopulate для Q1.
На следующем рисунке показаны метрики CacheProbe для Q2.
Кэш запросов не работает для запросов DISTINCT, для которых включены CTE-оптимизации
После выполнения set cbo_cte_reuse = true для включения CTE-оптимизаций результаты вычислений для определённых запросов, включающих агрегатные функции DISTINCT, не могут быть кэшированы. Несколько примеров:
-
Запрос содержит одну агрегатную функцию DISTINCT
avg(distinct):SELECT
avg(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';
-
Запрос содержит несколько агрегатных функций DISTINCT, ссылающихся на один и тот же столбец:
SELECT
avg(distinct v1) AS __c_0,
sum(distinct v1) AS __c_1,
count(distinct v1) AS __c_2
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';

-
Запрос содержит несколько агрегатных функций DISTINCT, каждая из которых ссылается на разный столбец:
SELECT
sum(distinct v1) AS __c_1,
count(distinct v0) AS __c_2
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';

Лучшие практики
При создании таблицы укажите разумное описание partition и разумный метод распределения, включая:
- Выберите один столбец типа DATE в качестве столбца партиционирования. Если таблица содержит более одного столбца типа DATE, выберите столбец, значения которого продвигаются вперёд по мере инкрементального приёма данных и который используется для определения интересующих временных диапазонов запросов.
- Выберите правильную ширину partition. Данные, полученные недавно, могут изменять последние partition таблицы. Поэтому записи кэша, связанные с последними partition, нестабильны и склонны к аннулированию.
- Укажите количество bucket в несколько десятков в описании распределения оператора создания таблицы. Если количество bucket слишком мало, кэш запросов не может работать, когда количество tablet, которые необходимо обработать BE, меньше значения
pipeline_dop.