Bitmap для Count Distinct
Использование bitmap для вычислен�ия количества уникальных значений.
Bitmap — полезный инструмент для вычисления количества уникальных значений в массиве. Этот метод занимает меньше места для хранения и может ускорить вычисления по сравнению с традиционным Count Distinct. Предположим, есть массив с именем A с диапазоном значений [0, n). Используя bitmap размером (n+7)/8 байт, можно вычислить количество уникальных элементов в массиве. Для этого инициализируйте все биты значением 0, установите значения элементов как индексы битов, а затем установите все биты в 1. Количество единиц в bitmap — это количество уникальных элементов в массиве.
Традиционный Count Distinct
Архитектура MPP базы данных позволяет сохранять детализированные данные при использовании Count Distinct. Однако функция Count Distinct требует множественных операций shuffle данных во время обработки запроса, что потребляет больше ресурсов и приводит к линейному снижению производительности по мере увеличения объёма да�нных.
Следующий сценарий рассчитывает UV на основе детализированных данных в таблице (dt, page, user_id).
| dt | page | user_id |
|---|---|---|
| 20191206 | game | 101 |
| 20191206 | shopping | 102 |
| 20191206 | game | 101 |
| 20191206 | shopping | 101 |
| 20191206 | game | 101 |
| 20191206 | shopping | 101 |
Данные вычисляются согласно следующему рисунку. Сначала данные группируются по столбцам page и user_id, затем подсчитывается обработанный результат.
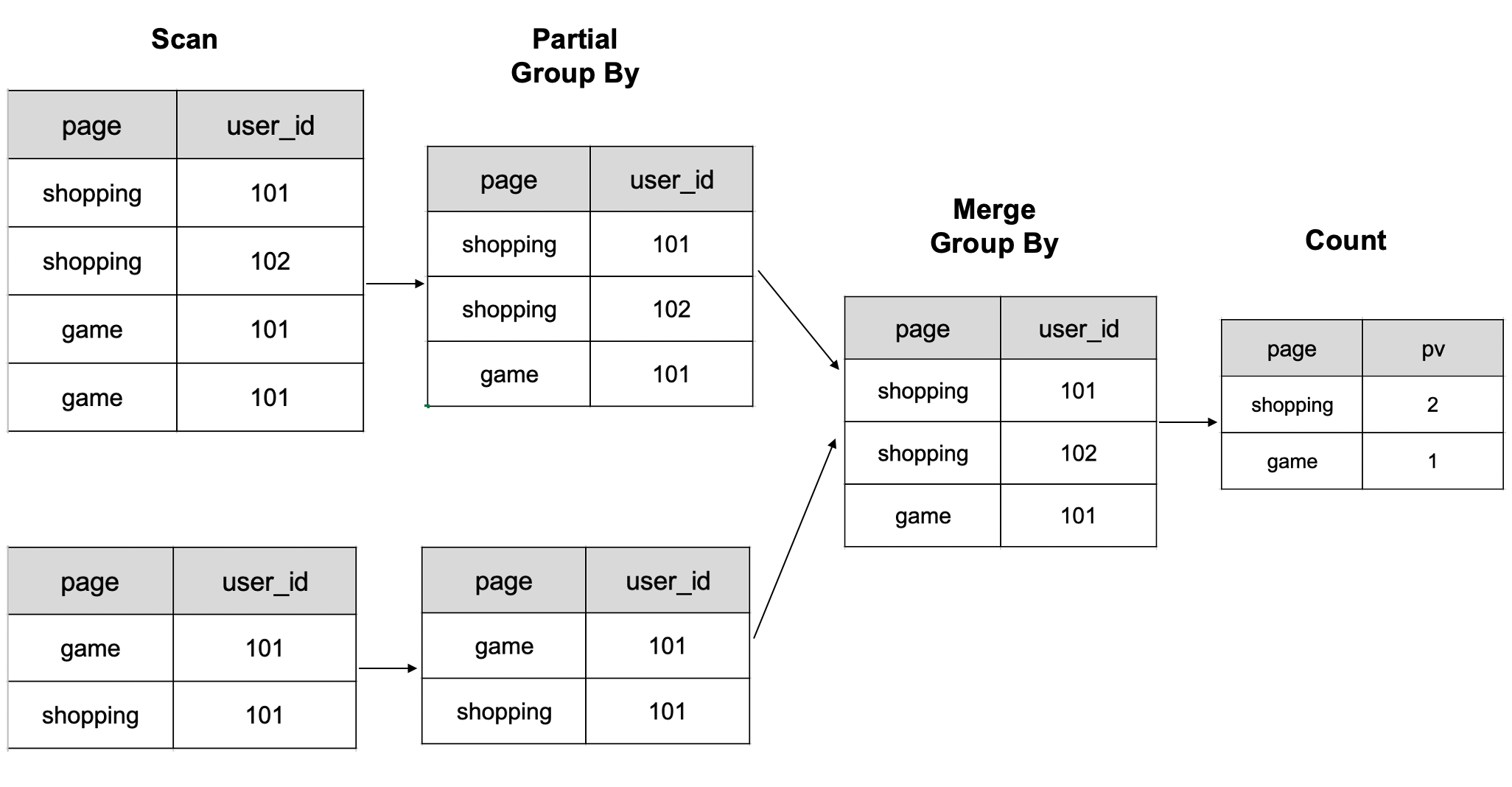
На рисунке показана схема вычисления 6 строк данных на двух узлах BE.
При работе с большими объёмами данных, требующими множественных операций shuffle, необходимые вычислительные ресурсы могут значительно увеличиться. Это замедляет запросы. Однако использование технологии Bitmap может помочь решить эту проблему и улучшить производительность запросов в таких сценариях.
Подсчёт uv с группировкой по page:
select page, count(distinct user_id) as uv from table group by page;
| page | uv |
|---|---|
| game | 1 |
| shopping | 2 |
Преимущества Count Distinct с Bitmap
Вы можете получить следующие преимущества от использования bitmap по сравнению с COUNT(DISTINCT expr):
- Меньше места для хранения: Если вы используете bitmap для вычисления количества уникальных значений для данных
INT32, требуемое пространство для хранения составляет всего 1/32 отCOUNT(DISTINCT expr). Для выполнения вычислений используются сжатые roaring bitmap, что ещё больше сокращает использование пространства для хранения по сравнению с традиционными bitmap. - Более быстрые вычисления: Bitmap используют побитовые операции, что приводит к более быстрым вычислениям по сравнению с
COUNT(DISTINCT expr). Вычисление количества уникальных значений может обрабатываться параллельно, что приводит к дальнейшему улучшению производительности запросов.
Для реализации Roaring Bitmap см. соответствующую статью и реализацию.
Примечания по использованию
- Как bitmap-индексирование, так и bitmap Count Distinct используют технологию bitmap. Однако цель их введения и решаемые ими проблемы совершенно различны. Первое используется для фильтрации перечисляемых столбцов с низкой кардинальностью, а второе — для подсчёта количества уникальных элементов в столбцах значений строки данных.
- Вы можете определить столбец значений как
BITMAPнезависимо от типа таблицы (Aggregate table, Duplicate Key table, Primary Key table или Unique Key table). Однако ключ сортировки таблицы не может иметь типBITMAP. - При создании таблицы вы можете определить столбец значений как
BITMAPи агрегатную функцию какBITMAP_UNION. - Вы можете использовать roaring bitmap только для вычисления количества уникальных значений для данных следующих типов:
TINYINT,SMALLINT,INTиBIGINT. Для данных других типов необходимо построить глобальный словарь.
Count Distinct с Bitmap
Рассмотрим расчёт UV страниц в качестве примера.
-
Создайте Aggregate-таблицу со столбцом
BITMAPvisit_users, который использует агрегатную функциюBITMAP_UNION.CREATE TABLE `page_uv` (
`page_id` INT NOT NULL COMMENT 'ID страницы',
`visit_date` datetime NOT NULL COMMENT 'время доступа',
`visit_users` BITMAP BITMAP_UNION NOT NULL COMMENT 'ID пользователя'
) ENGINE=OLAP
AGGREGATE KEY(`page_id`, `visit_date`)
DISTRIBUTED BY HASH(`page_id`)
PROPERTIES (
"replication_num" = "3",
"storage_format" = "DEFAULT"
); -
Загрузите данные в эту таблицу.
Используйте
INSERT INTOдля загрузки данных:INSERT INTO page_uv VALUES
(1, '2020-06-23 01:30:30', to_bitmap(13)),
(1, '2020-06-23 01:30:30', to_bitmap(23)),
(1, '2020-06-23 01:30:30', to_bitmap(33)),
(1, '2020-06-23 02:30:30', to_bitmap(13)),
(2, '2020-06-23 01:30:30', to_bitmap(23));После загрузки данных:
- В строке
page_id = 1, visit_date = '2020-06-23 01:30:30'полеvisit_usersсодержит три элемента bitmap (13, 23, 33). - В строке
page_id = 1, visit_date = '2020-06-23 02:30:30'полеvisit_usersсодержит один элемент bitmap (13). - В строке
page_id = 2, visit_date = '2020-06-23 01:30:30'полеvisit_usersсодержит один элемент bitmap (23).
- В строке
-
Рассчитайте UV страниц.
SELECT page_id, count(distinct visit_users)
FROM page_uv GROUP BY page_id;+-----------+------------------------------+
| page_id | count(DISTINCT `visit_users`)|
+-----------+------------------------------+
| 1 | 3 |
| 2 | 1 |
+-----------+------------------------------+
2 row in set (0.00 sec)
Глобальный словарь
В настоящее время механизм Count Distinct на основе Bitmap требует, чтобы входные данные были целыми числами. Если пользователю нужно использовать другие типы данных в качестве входных данных для Bitmap, то пользователю необходимо самостоятельно построить глобальный словарь для сопоставления других типов данных (например, строковы�х) с целочисленными типами. Существует несколько подходов к построению глобального словаря:
Глобальный словарь на основе таблицы Hive
Глобальный словарь в этой схеме сам по себе является таблицей Hive с двумя столбцами: один для исходных значений, другой для закодированных Int-значений. Шаги по генерации глобального словаря следующие:
- Дедуплицируйте столбцы словаря таблицы фактов для создания временной таблицы
- Выполните left join временной таблицы и глобального словаря, добавьте
new valueво временную таблицу. - Закодируйте
new valueи вставьте его в глобальный словарь. - Выполните left join таблицы фактов и обновлённого глобального словаря, замените элементы словаря идентификаторами.
Таким образом, глобальный словарь можно обновлять, а столбцы значений в таблице фактов можно заменять с помощью Spark или MR. По сравнению с глобальным словарём на основе trie-дерева, этот подход может быть распределённым, и глобальный словарь можно использовать повторно.
Однако следует учитывать несколько моментов: исходная таблица фактов читается несколько раз, и есть два соединения, которые потребляют много дополнительных ресурсов при вычислении глобального словаря.
Построение глобального словаря на основе trie-дерева
Пользователи также могут самостоятельно строить глобальные словари с использованием trie-деревьев (также известных как префиксные деревья или деревья словарей). Trie-дерево имеет общие префиксы для потомков узлов, что можно использовать для сокращения времени запроса и минимизации сравнений строк, и поэтому хорошо подходит для реализации словарного кодирования. Однако реализация trie-дерева нелегко расп�ределяется и может создавать узкие места производительности при относительно большом объёме данных.
Построив глобальный словарь и преобразовав данные других типов в целочисленные данные, вы можете использовать Bitmap для выполнения точного анализа Count Distinct для столбцов нецелочисленных данных.