Таблицы Primary Key
Таблица Primary Key использует новый движок хранения, разработанный Selena. Его основное преимущество заключается в поддержке обно�влений данных в режиме реального времени при сохранении эффективной производительности для сложных ad-hoc запросов. В аналитике бизнеса в реальном времени принятие решений может выиграть от использования таблиц Primary Key, которые используют самые свежие данные для анализа результатов в реальном времени, что может смягчить задержку данных в анализе данных. Однако первичный ключ — это не бесплатный обед. При неправильном использовании он может привести к ненужной трате ресурсов.
Поэтому в этом разделе мы расскажем вам, как более эффективно использовать модель первичного ключа для достижения желаемых результатов.
Выбор индекса Primary Key
Первичный индекс является наиболее критическим компонентом в таблице Primary Key. Индекс первичного ключа используется для хранения сопоставления между значениями первичного ключа и расположениями строк данных, идентифицируемых значениями первичного ключа.
В настоящее время мы п�оддерживаем три типа индекса первичного ключа:
- Полностью в памяти индекс первичного ключа.
PROPERTIES (
"enable_persistent_index" = "false"
);
- Persistent индекс первичного ключа на основе локального диска.
PROPERTIES (
"enable_persistent_index" = "true",
"persistent_index_type" = "LOCAL"
);
- Cloud native persistent индекс первичного ключа.
PROPERTIES (
"enable_persistent_index" = "true",
"persistent_index_type" = "CLOUD_NATIVE"
);
Мы НЕ рекомендуем использовать индексирование в памяти, так как это может привести к значительной трате ресурсов памяти.
Если вы используете shared-data (elastic) cluster Selena, мы рекомендуем выбрать cloud-native persistent индекс первичного ключа. В отличие от локального дискового persistent индекса первичного ключа, он хранит полные данные индекса в удаленном объектном хранилище, используя локальные диски только в качестве кеша. По сравнению с локальным дисковым persistent индексом первичного ключа, его преимущества включают:
- Отсутствие зависимости от емкости локального диска.
- Отсутствие необходимости перестраивать индексы после ребалансировки data shard'ов.
Выбор первичного ключа
Первичный ключ обычно не помогает ускорить запросы. Вы можете указать столбец, отличный от первичного ключа, в качестве ключа сортировки, используя предложение ORDER BY, чтобы ускорить запросы. Поэтому при выборе первичного ключа вам нужно учитывать только уникальность во время процессов импорта и обновления данных.
Чем больше первичный ключ, тем больше памяти, I/O и других ресурсов он потребляет. Поэтому обычно рекомендуется избегать выбора слишком большого количества или слишком больших столбцов в качестве первичного ключа. Максимальный размер первичного ключа по умолчанию составляет 128 байт, управляется параметром primary_key_limit_size в be.conf.
Вы можете увеличить primary_key_limit_size, чтобы выбрать больший первичный ключ, но имейте в виду, что это приведет к более высокому потреблению ресурсов.
Сколько места для хранения и памяти займет persistent индекс?
Формула стоимости места для хранения
(key size + 8 bytes) * row count * 50%
50% — это оценочная эффективность сжатия, фактический эффект сжатия зависит от самих данных.
Формула стоимости памяти
min(l0_max_mem_usage * tablet cnt, update_memory_limit_percent * BE process memory);
Использование памяти
Память, используемая таблицей Primary Key, может отслеживаться через mem_tracker:
// Просмотр общей статистики памяти
http://be_ip:be_http_port/mem_tracker
// Просмотр статистики памяти таблицы primary key
http://be_ip:be_http_port/mem_tracker?type=update
// Просмотр статистики памяти таблицы primary key с более подробной информацией
http://be_ip:be_http_port/mem_tracker?type=update&upper_level=4
Элемент update в mem_tracker записывает всю память, используемую таблицей Primary Key, такую как индекс первичного ключа, delete vector и так далее.
Вы также можете отслеживать этот элемент update через сервис мониторинга метрик. Например, в Grafana вы можете проверить элемент update через (элемент в красной рамке):
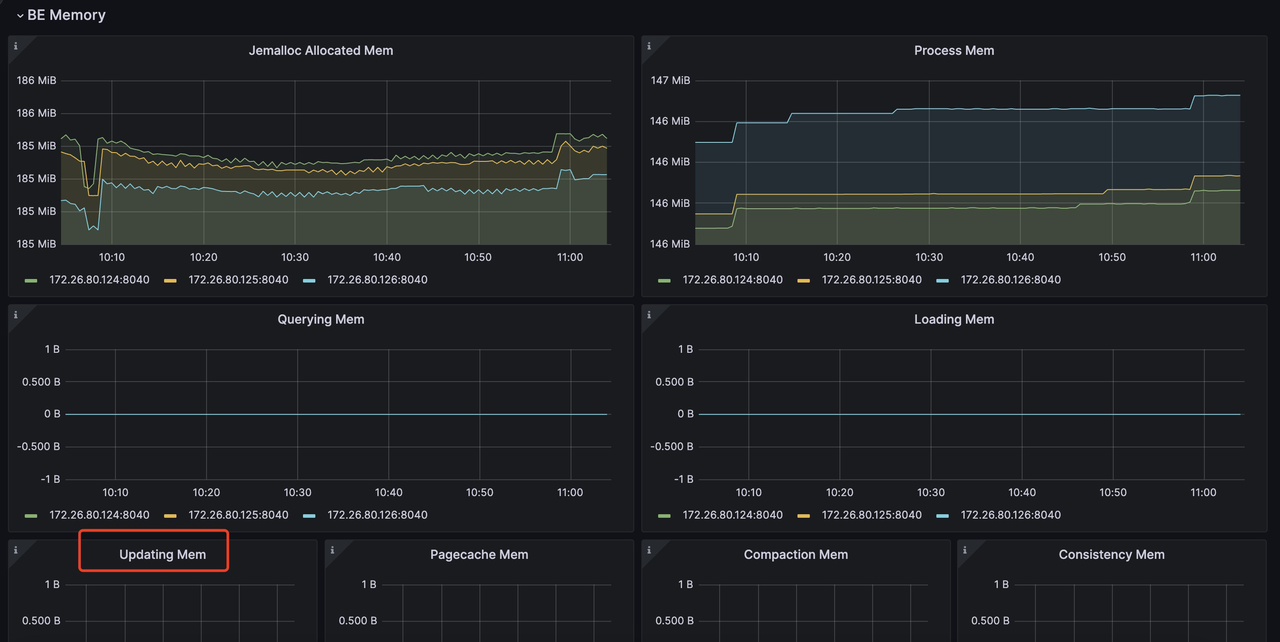
Подробнее о мониторинге и оповещениях с Prometheus и Grafana: https://docs.selena.io/docs/administration/management/monitoring/Monitor_and_Alert/
Если вы чувствительны к использованию памяти и хотите снизить потребление памяти во время процесса импорта в таблицу PK, вы можете достичь этого с помощью следующей конфигурации:
be.conf
l0_max_mem_usage = (некоторое значение меньше 104857600, по умолчанию 104857600)
skip_pk_preload = true
// Shared-nothing cluster
transaction_apply_worker_count = (некоторое значение меньше количества ядер cpu, по умолчанию количество ядер cpu)
// Shared-data cluster
transaction_publish_version_worker_count = (некоторое значение меньше количества ядер cpu, по умолчанию количество ядер cpu)
l0_max_mem_usage контролирует максимальное использование памяти persistent индекса первичного ключа на tablet. transaction_apply_worker_count и transaction_publish_version_worker_count оба контролируют максимальное количество потоков, которые могут использоваться для обработки upsert и delete в таблице primary key.
Но вам нужно помнить, что уменьшение l0_max_mem_usage может увеличить давление I/O, в то время как уменьшение transaction_apply_worker_count или transaction_publish_version_worker_count может замедлить прием данных.
Компромисс между ресурсами compaction, свежестью данных и задержкой запросов
По сравнению с таблицами других моделей, таблицы primary key требуют дополнительных операций для поиска по индексу первичного ключа и генерации delete vector во время импорта, обновления и удаления данных, что вносит дополнительные ресурсные затраты. Поэтому вам нужно сделать компромисс между этими тремя факторами:
- Ограничение ресурсов compaction.
- Свежесть данных
- Задержка запросов
Свежесть данных и задержка запросо�в
Если вы хотите получить лучшую свежесть данных, а также лучшую задержку запросов, это означает, что вы введете высокочастотные записи, а также захотите убедиться, что они могут быть скомпактированы как можно скорее. Тогда вам потребуется больше ресурсов compaction для обработки этих записей:
// shared-data
be.conf
compact_threads = 4
// shared-nothing
be.conf
update_compaction_num_threads_per_disk = 1
update_compaction_per_tablet_min_interval_seconds = 120
Вы можете увеличить compact_threads и update_compaction_num_threads_per_disk или уменьшить update_compaction_per_tablet_min_interval_seconds, чтобы ввести больше ресурсов compaction для обработки высокочастотных записей.
Как узнать, могут ли текущие ресурсы compaction и настройки справиться с текущими высокочастотными записями? Вы можете наблюдать это следующими способами:
- Для shared-data cluster, если compaction не может поспевать за скоростью приема, это может привести к замедлению приема или даже к ошибкам write failure и остановке приема.
a. Замедление приема.
Вы можете использовать
show proc /transactions/{db_name}/running';для проверки текущих выполняющихся транзакций, и если появляется какое-либо сообщение о замедлении, например:
Partition's compaction score is larger than 100.0, delay commit for xxxms. You can try to increase compaction concurrency
появляется в поле ErrMsg, это означает, что про�исходит замедление приема. Например:
mysql> show proc '/transactions/test_pri_load_c/running';
+---------------+----------------------------------------------+------------------+-------------------+--------------------+---------------------+------------+-------------+------------+----------------------------------------------------------------------------------------------------------------------------+--------------------+------------+-----------+--------+
| TransactionId | Label | Coordinator | TransactionStatus | LoadJobSourceType | PrepareTime | CommitTime | PublishTime | FinishTime | Reason | ErrorReplicasCount | ListenerId | TimeoutMs | ErrMsg |
+---------------+----------------------------------------------+------------------+-------------------+--------------------+---------------------+------------+-------------+------------+----------------------------------------------------------------------------------------------------------------------------+--------------------+------------+-----------+--------+
| 1034 | stream_load_d2753fbaa0b343acadd5f13de92d44c1 | FE: 172.26.94.39 | PREPARE | FRONTEND_STREAMING | 2024-10-24 13:05:01 | NULL | NULL | NULL | Partition's compaction score is larger than 100.0, delay commit for 6513ms. You can try to increase compaction concurrency, | 0 | 11054 | 86400000 | |
+---------------+----------------------------------------------+------------------+-------------------+--------------------+---------------------+------------+-------------+------------+----------------------------------------------------------------------------------------------------------------------------+--------------------+------------+-----------+--------+
b. Остановка приема. Если есть ошибка приема, такая как:
Failed to load data into partition xxx, because of too large compaction score, current/limit: xxx/xxx. You can reduce the loading job concurrency, or increase compaction concurrency
Это означает, что прием остановлен, потому что compaction не может поспевать за текущими высокочастотными записями.
- Для shared-nothing cluster нет стратегии замедления приема, если compaction не может поспевать за текущими высокочастотными записями. Прием завершится неудачей и вернет сообщение об ошибке:
Failed to load data into tablet xxx, because of too many versions, current/limit: xxx/xxx. You can reduce the loading job concurrency, or increase loading data batch size. If you are loading data with Routine Load, you can increase FE configs routine_load_task_consume_second and max_routine_load_batch_size.
Свежесть данных и ограничение ресурсов compaction
Если у вас ограниченные ресурсы compaction, но все еще нужно поддерживать достаточную свежесть данных, это означает, что вам нужно пожертвовать некоторой задержкой запросов.
Вы можете внести эти изменения в конфигурацию для достижения этого:
- Shared-data cluster
fe.conf
lake_ingest_slowdown_threshold = xxx (по умолчанию 100, вы можете увеличить)
lake_compaction_score_upper_bound = xxx (по умолчанию 2000, вы можете увеличить)
Параметр lake_ingest_slowdown_threshold контролирует порог для инициирования замедления приема. Когда показатель compaction партиции превышает этот порог, система начнет замедлять прием данных. Аналогично, lake_compaction_score_upper_bound определяет порог для инициирования остановки приема.
- Shared-nothing cluster
be.conf
tablet_max_versions = xxx (по умолчанию 1000, вы можете увеличить)
tablet_max_versions определяет порог для инициирования остановки приема.
Увеличивая эти конфигурации, система может вместить больше небольших файлов данных и снизить частоту compaction, но это также повлияет на задержку запросов.
Задержка запросов и ограничение ресурсов compaction
Если вы хотите достичь хорошей задержки запросов с ограниченными ресурсами compaction, вам нужно снизить частоту записи и создавать более крупные пакеты данных для приема.
Для конкретной реализации, пожалуйста, обратитесь к разделам о различных методах приема, которые подробно описывают, как снизить частоту приема и увеличить размер пакета.