Query Hint
Query hint — это директивы или комментарии, которые явно подсказывают оптимизатору запросов, как выполнять запрос. В настоящее время Selena поддерживает три типа hint: hint системных переменных (SET_VAR), hint пользовательских переменных (SET_USER_VARIABLE) и Join hint. Hint действуют только в пределах одного запроса.
Hint системных переменных
Вы можете использовать hint SET_VAR для установки одной или нескольких системных переменных в операторах SELECT и SUBMIT TASK, а затем выполнить эти операторы. Вы также можете использовать hint SET_VAR в предложении SELECT, включенном в другие операторы, такие как CREATE MATERIALIZED VIEW AS SELECT и CREATE VIEW AS SELECT. Обратите внимание, что если hint SET_VAR используется в предложении SELECT в CTE, то hint SET_VAR не де�йствует, даже если оператор выполнен успешно.
По сравнению с общим использованием системных переменных, которое действует на уровне сессии, hint SET_VAR действует на уровне оператора и не влияет на всю сессию.
Синтаксис
[...] SELECT /*+ SET_VAR(key=value [, key = value]) */ ...
SUBMIT [/*+ SET_VAR(key=value [, key = value]) */] TASK ...
Примеры
Чтобы указать режим агрегации для агрегирующего запроса, используйте hint SET_VAR для установки системных переменных streaming_preaggregation_mode и new_planner_agg_stage в агрегирующем запросе.
SELECT /*+ SET_VAR (streaming_preaggregation_mode = 'force_streaming',new_planner_agg_stage = '2') */ SUM(sales_amount) AS total_sales_amount FROM sales_orders;
Чтобы указать таймаут выполнения для оператора SUBMIT TASK, используйте hint SET_VAR для установки системной переменной insert_timeout в операторе SUBMIT TASK.
SUBMIT /*+ SET_VAR(insert_timeout=3) */ TASK AS CREATE TABLE temp AS SELECT count(*) AS cnt FROM tbl1;
Чтобы указать таймаут выполнения подзапроса при создании материализованного представления, используйте hint SET_VAR для установки системной переменной query_timeout в предложении SELECT.
CREATE MATERIALIZED VIEW mv
PARTITION BY dt
DISTRIBUTED BY HASH(`key`)
BUCKETS 10
REFRESH ASYNC
AS SELECT /*+ SET_VAR(query_timeout=500) */ * from dual;
Hint пользовательских переменных
Вы можете использовать hint SET_USER_VARIABLE для установки одной или нескольких пользовательских переменных в операторах SELECT или INSERT. Если другие операторы содержат предложение SELECT, вы также можете использовать hint SET_USER_VARIABLE в этом предложении SELECT. Другими операторами могут быть операторы SELECT и INSERT, но не операторы CREATE MATERIALIZED VIEW AS SELECT и CREATE VIEW AS SELECT. Обратите внимание, что если hint SET_USER_VARIABLE используется в предложении SELECT в CTE, то hint SET_USER_VARIABLE не действует, даже если оператор выполнен успешно. Начиная с версии v1.5.2, Selena поддерживает hint пользовательских переменных.
По сравнению с общим использованием пользовательских переменных, которое действует на уровне сессии, hint SET_USER_VARIABLE действует на уровне оператора и не влияет на всю сессию.
Синтаксис
[...] SELECT /*+ SET_USER_VARIABLE(@var_name = expr [, @var_name = expr]) */ ...
INSERT /*+ SET_USER_VARIABLE(@var_name = expr [, @var_name = expr]) */ ...
Примеры
Следующий оператор SELECT ссылается на скалярные подзапросы select max(age) from users и select min(name) from users, поэтому вы можете использовать hint SET_USER_VARIABLE для установки этих двух скалярных подзапросов в качестве пользовательских переменных, а затем выполнить запрос.
SELECT /*+ SET_USER_VARIABLE (@a = (select max(age) from users), @b = (select min(name) from users)) */ * FROM sales_orders where sales_orders.age = @a and sales_orders.name = @b;
Join hint
Для многотабличных Join-запросов оптимизатор обычно выбирает оптимальный метод выполнения Join. В особых случаях вы можете использовать Join hint, чтобы явно подсказать оптимизатору метод выполнения Join или отключить Join Reorder. В настоящее время Join hint поддерживает указание Shuffle Join, Broadcast Join, Bucket Shuffle Join или Colocate Join в качестве метода выполнения Join. При использовании Join hint оптимизатор не выполняет Join Reorder. Поэтому вам нужно выбрать меньшую таблицу в качестве правой таблицы. Кроме того, при указании Colocate Join или Bucket Shuffle Join в качестве метода выполнения Join убедитесь, что распределение данных объединяемой таблицы соответствует требованиям этих методов выполнения Join. В противном случае предложенный метод выполнения Join не сможет вступить в силу.
Синтаксис
... JOIN { [BROADCAST] | [SHUFFLE] | [BUCKET] | [COLOCATE] | [UNREORDER]} ...
Join Hint не чувствителен к регистру.
Примеры
-
Shuffle Join
Если вам нужно перемешать строки данных с одинаковыми значениями ключа бакетирования из таблиц A и B на одной машине перед выполнением операции Join, вы можете указать метод выполнения Join как Shuffle Join.
select k1 from t1 join [SHUFFLE] t2 on t1.k1 = t2.k2 group by t2.k2; -
Broadcast Join
Если таблица A — большая таблица, а таблица B — маленькая таблица, вы можете указать метод выполнения Join как Broadcast Join. Данные таблицы B полностью транслируются на машины, на которых находятся данные таблицы A, а затем выполняется операция Join. По сравнению с Shuffle Join, Broadcast Join экономит затраты на перемешивание данных таблицы A.
select k1 from t1 join [BROADCAST] t2 on t1.k1 = t2.k2 group by t2.k2; -
Bucket Shuffle Join
Если выражение эквисоединения Join в запросе Join содержит ключ бакетирования таблицы A, особенно когда обе таблицы A и B являются большими таблицами, вы можете указать метод выполнения Join как Bucket Shuffle Join. Данные таблицы B перемешиваются на машины, на которых находятся данные таблицы A, в соответствии с распределением данных таблицы A, а затем выполняется операция Join. По сравнению с Broadcast Join, Bucket Shuffle Join значительно сокращает передачу данных, поскольку данные таблицы B пер�емешиваются только один раз глобально. Таблицы, участвующие в Bucket Shuffle Join, должны быть либо несекционированными, либо размещенными совместно (colocated).
select k1 from t1 join [BUCKET] t2 on t1.k1 = t2.k2 group by t2.k2; -
Colocate Join
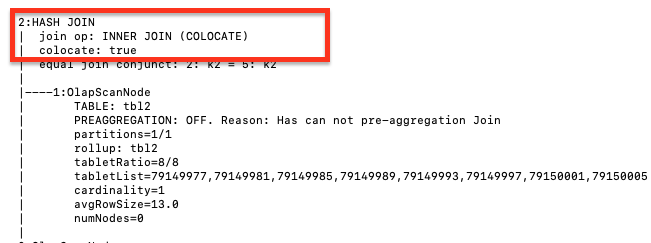
Если таблицы A и B принадлежат к одной Colocation Group, которая указана при создании таблицы, строки данных с одинаковыми значениями ключа бакетирования из таблиц A и B распределяются на одном узле BE. Когда выражение эквисоединения Join содержит ключ бакетирования таблиц A и B в запросе Join, вы можете указать метод выполнения Join как Colocate Join. Данные с одинаковыми значениями ключей объединяются напрямую локально, сокращая время, затрачиваемое на передачу данных между узлами, и повышая производительность запросов.
select k1 from t1 join [COLOCATE] t2 on t1.k1 = t2.k2 group by t2.k2;
Просмотр метода выполнения Join
Используйте команду EXPLAIN для просмотра фактического метода выполнения Join. Если возвращенный результат показывает, что метод выполнения Join соответствует Join hint, это означает, что Join hint эффективен.
EXPLAIN select k1 from t1 join [COLOCATE] t2 on t1.k1 = t2.k2 group by t2.k2;