План запроса
Оптимизация производительности запросов — распространенная задача в аналитических системах. Медленные запросы могут ухудшить пользовательский опыт и общую производительность cluster. В Selena понимание и интерпретация планов запросов и профилей запросов является основой для диагностики и улучшения медленных запросов. Эти инструменты помогают вам:
- Определить узкие места и дорогостоящие операции
- Обнаружить неоптимальные стратегии соединения или отсутствующие индексы
- Понять, как данные фильтруются, агрегируются и перемещаются
- Устранять неполадки и оптимизировать использование ресурсов
План запроса — это подробная дорожная карта, созданная Selena FE, которая описывает, как будет выполнен ваш SQL-оператор. Он разбивает запрос на серию операций — таких как сканирование, соединение, агрегация и сортировка — и определяет наиболее эффективный способ их выполнения.
Selena предоставляет нес�колько способов просмотра плана запроса:
-
Оператор EXPLAIN: Используйте
EXPLAINдля отображения логического или физического плана выполнения запроса. Вы можете добавить опции для управления выводом:EXPLAIN LOGICAL <query>: Показывает упрощенный план.EXPLAIN <query>: Показывает базовый физический планEXPLAIN VERBOSE <query>: Показывает физический план с подробной информацией.EXPLAIN COSTS <query>: Включает оценочные затраты для каждой операции, что используется для диагностики проблем со статистикой
-
EXPLAIN ANALYZE: Используйте
EXPLAIN ANALYZE <query>для выполнения запроса и отображения фактического плана выполнения вместе с реальной статистикой времени выполнения. См. документацию по Explain Anlayze для подробностей.Пример:
EXPLAIN ANALYZE SELECT * FROM sales_orders WHERE amount > 1000; -
Query Profile: После выполнения запроса вы можете просмотреть его подробный профиль выполнения, который включает время, использование ресурсов и статистику на уровне операторов. См. документацию по Query Profile для получения информации о том, как получить доступ и интерпретировать эту информацию.
- SQL-команды:
SHOW PROFILELISTиANALYZE PROFILE FOR <query_id>: можно использовать для получения профиля выполнения для конкретного запроса. - HTTP-сервис FE: Доступ к профилям запросов через веб-интерфейс Selena FE, перейдя в раздел Query или Profile, где вы можете искать и просматривать детали выполнения запросов.
- Управляемая версия: В облачных или управляемых развертываниях используйте предоставленную веб-консоль или панель мониторинга для просмотра планов запросов и профилей, часто с расширенными возможностями визуализации и фильтрации.
- SQL-команды:
Обычно план запроса используется для диагностики проблем, связанных с тем, как запрос планируется и оптимизируется, в то время как профиль запроса помогает выявить проблемы производительности во время выполнения запроса. В следующих разделах мы рассмотрим ключевые концепции выполнения запросов и пройдем через конкретный пример анализа плана запроса.
Поток выполнения запроса
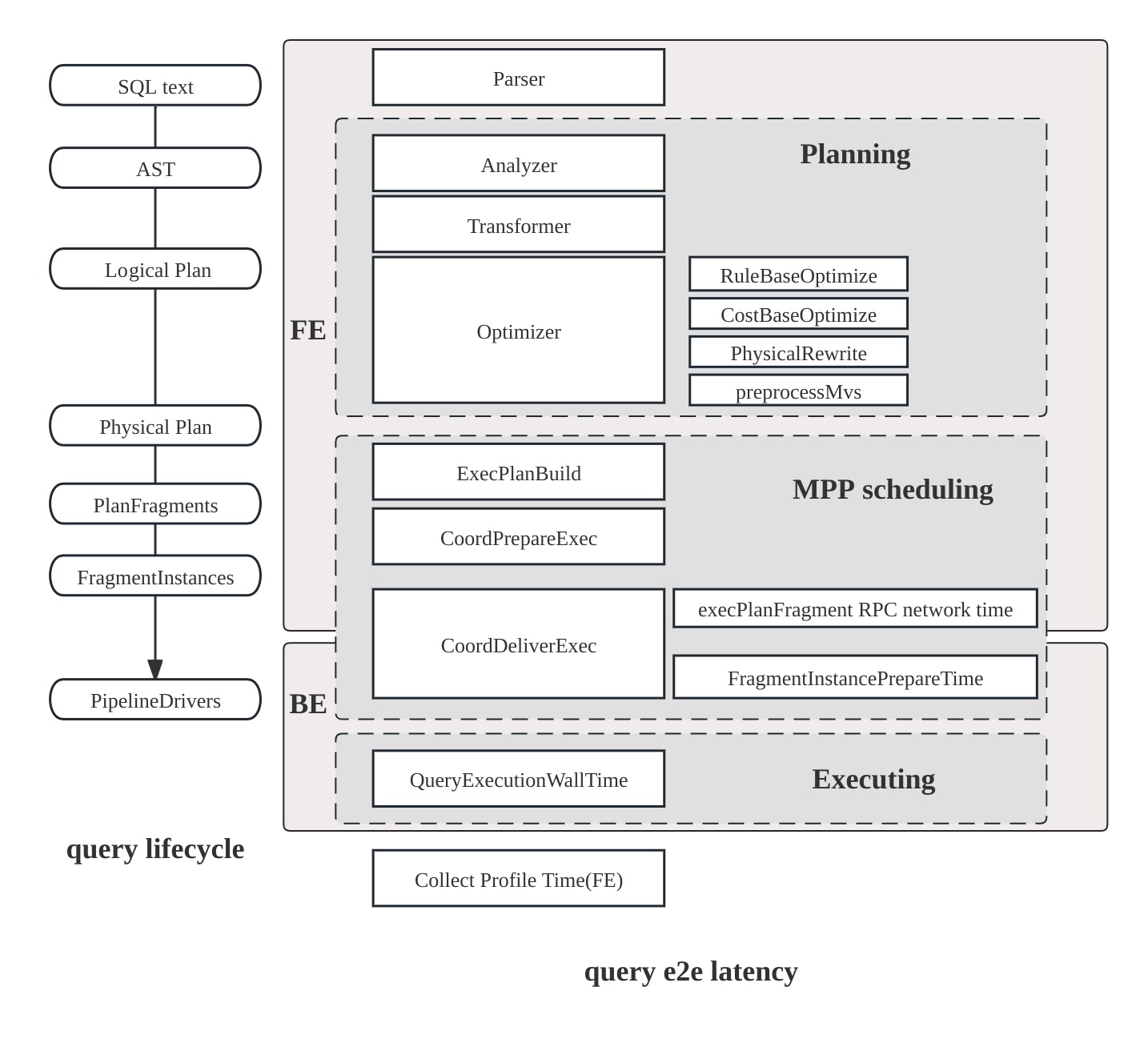
Жизненный цикл запроса в Selena состоит из трех основных фаз:
- Планирование: Запрос проходит через парсинг, анализ и оптимизацию, завершаясь генерацией плана запроса.
- Планирование выполнения: Планировщик и координатор распределяют план по всем участвующим backend-узл�ам.
- Выполнение: План выполняется с использованием pipeline-движка выполнения.
Структура плана
План Selena имеет иерархическую структуру:
- Fragment: Срез работы верхнего уровня; каждый fragment порождает множество FragmentInstances, которые выполняются на разных backend-узлах.
- Pipeline: Внутри instance pipeline связывает операторы вместе; несколько PipelineDrivers выполняют один и тот же pipeline параллельно на отдельных ядрах CPU.
- Operator: Атомарный шаг — сканирование, соединение, агрегация — который фактически обрабатывает данные.
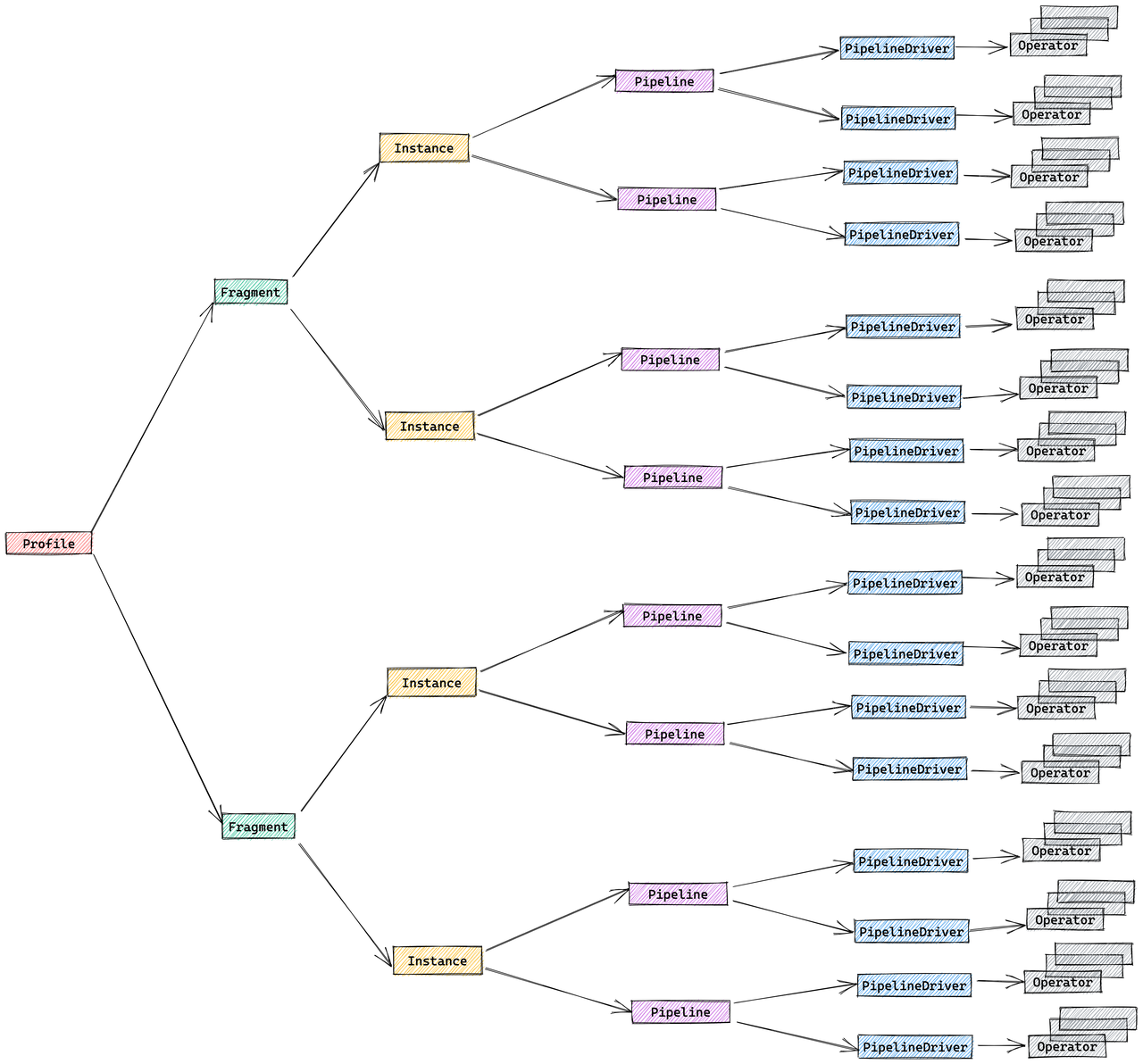
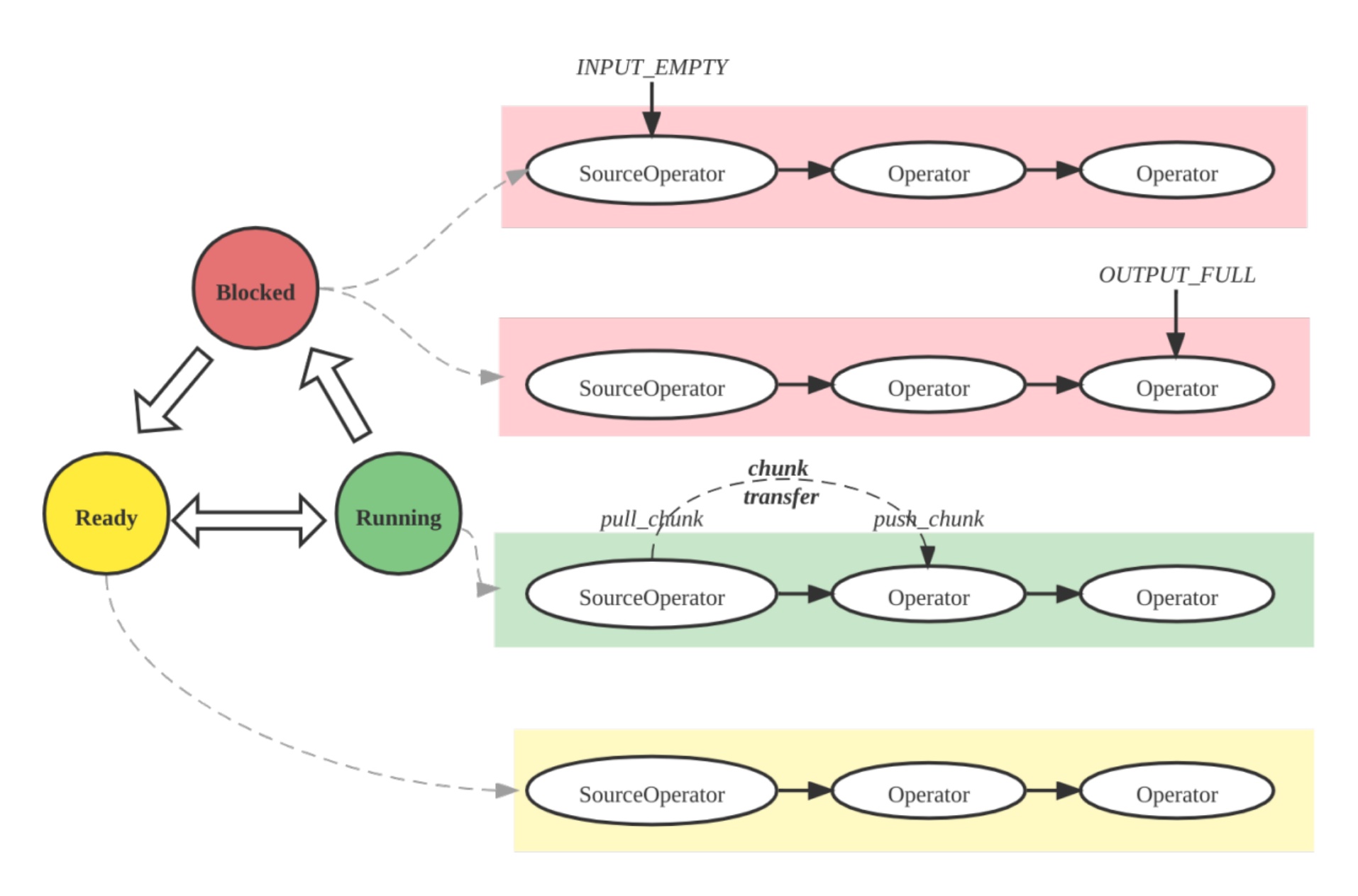
Pipeline-движок выполнения
Pipeline Engine выполняет план запроса параллельно и эффективно, обрабатывая сложные планы и большие объемы данных для высокой производительности и масштабируемости.
Стратегия объединения метрик
По умолчанию Selena объединяет уровни FragmentInstance и PipelineDriver для уменьшения объема профиля, в результате чего получается упрощенная трехуровневая структура:
- Fragment
- Pipeline
- Operator
Вы можете управлять этим поведением объединения через переменную сессии pipeline_profile_level.
Пример
Как читать план запроса и профиль
-
Понимание структуры: Планы запросов разделены на фрагменты, каждый из которых представляет этап выполнения. Читайте снизу вверх: сначала узлы сканирования, затем соединения, агрегации и, наконец, результат.
-
Общий анализ:
- Проверьте общее время выполнения, использование памяти и соотношение CPU/wall time.
- Найдите медленные операторы, отсортировав по времени оператора.
- Убедитесь, что фильтры проталкиваются вниз, где это возможно.
- Ищите перекос данных (неравномерное время операторов или количество строк).
- Следите за высокой памятью или переполнением на диск; при необходимости отрегулируйте порядок соединения или используйте rollup-представления.
- Используйте материализованные представления и query hint (
BROADCAST,SHUFFLE,COLOCATE) для оптимизации по мере необходимости.
-
Операции сканирования: Ищите
OlapScanNodeили аналогичные. Обратите внимание, какие таблицы сканируются, какие фильтры применяются и используются ли предварительная агрегация или материализованные представления. -
Операции соединения: Определите типы соединений (
HASH JOIN,BROADCAST,SHUFFLE,COLOCATE,BUCKET SHUFFLE). Метод соединения влияет на производительность:- Broadcast: Маленькая таблица отправляется на все узлы; хорошо для маленьких таблиц.
- Shuffle: Строки секционируются и перемешиваются; хорошо для больших таблиц.
- Colocate: Таблицы секционированы одинаково; позволяет выполнять локальные соединения.
- Bucket Shuffle: Перемешивается только одна таблица для сокращения сетевых затрат.
-
Агрегация и сортировка: Ищите
AGGREGATE,TOP-NилиORDER BY. Эти операции могут быть дорогостоящими при больших данных или данных с высокой мощностью. -
Перемещение данных: Узлы
EXCHANGEпоказывают передачу данных между фрагментами или узлами. Слишком большое перемещение данных может снизить производительность. -
Проталкивание предикатов: Фильтры, примененные рано (при сканировании), сокращают нижестоящие данные. Проверьте
PREDICATESилиPushdownPredicates, чтобы увидеть, какие фильтры проталкиваются вниз.
Пример плана запроса
Это запрос 96 из бенчмарка TPC-DS.
explain logical
select count(*)
from store_sales
,household_demographics
,time_dim
, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'
order by count(*) limit 100;
Вывод представляет собой иерархический план, показывающий, как Selena будет выполнять запрос. План структурирован как дерево операторов, читаемое снизу вверх. Логический план показывает последовательность операций с оценкой затрат:
- Output => [69:count]
- TOP-100(FINAL)[69: count ASC NULLS FIRST]
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 8.00, cost: 68669801.20}
- TOP-100(PARTIAL)[69: count ASC NULLS FIRST]
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 8.00, cost: 68669769.20}
- AGGREGATE(GLOBAL) []
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 0.00, cost: 68669737.20}
69:count := count(69:count)
- EXCHANGE(GATHER)
Estimates: {row: 1, cpu: 8.00, memory: 0.00, network: 8.00, cost: 68669717.20}
- AGGREGATE(LOCAL) []
Estimates: {row: 1, cpu: 3141.35, memory: 0.80, network: 0.00, cost: 68669701.20}
69:count := count()
- HASH/INNER JOIN [9:ss_store_sk = 40:s_store_sk] => [71:auto_fill_col]
Estimates: {row: 3490, cpu: 111184.52, memory: 8.80, network: 0.00, cost: 68668128.93}
71:auto_fill_col := 1
- HASH/INNER JOIN [7:ss_hdemo_sk = 25:hd_demo_sk] => [9:ss_store_sk]
Estimates: {row: 19940, cpu: 1841177.20, memory: 2880.00, network: 0.00, cost: 68612474.92}
- HASH/INNER JOIN [4:ss_sold_time_sk = 30:t_time_sk] => [7:ss_hdemo_sk, 9:ss_store_sk]
Estimates: {row: 199876, cpu: 69221191.15, memory: 7077.97, network: 0.00, cost: 67671726.32}
- SCAN [store_sales] => [4:ss_sold_time_sk, 7:ss_hdemo_sk, 9:ss_store_sk]
Estimates: {row: 5501341, cpu: 66016092.00, memory: 0.00, network: 0.00, cost: 33008046.00}
partitionRatio: 1/1, tabletRatio: 192/192
predicate: 7:ss_hdemo_sk IS NOT NULL
- EXCHANGE(BROADCAST)
Estimates: {row: 1769, cpu: 7077.97, memory: 7077.97, network: 7077.97, cost: 38928.81}
- SCAN [time_dim] => [30:t_time_sk]
Estimates: {row: 1769, cpu: 21233.90, memory: 0.00, network: 0.00, cost: 10616.95}
partitionRatio: 1/1, tabletRatio: 5/5
predicate: 33:t_hour = 8 AND 34:t_minute >= 30
- EXCHANGE(BROADCAST)
Estimates: {row: 720, cpu: 2880.00, memory: 2880.00, network: 2880.00, cost: 14400.00}
- SCAN [household_demographics] => [25:hd_demo_sk]
Estimates: {row: 720, cpu: 5760.00, memory: 0.00, network: 0.00, cost: 2880.00}
partitionRatio: 1/1, tabletRatio: 1/1
predicate: 28:hd_dep_count = 5
- EXCHANGE(BROADCAST)
Estimates: {row: 2, cpu: 8.80, memory: 8.80, network: 8.80, cost: 44.15}
- SCAN [store] => [40:s_store_sk]
Estimates: {row: 2, cpu: 17.90, memory: 0.00, network: 0.00, cost: 8.95}
partitionRatio: 1/1, tabletRatio: 1/1
predicate: 45:s_store_name = 'ese'
Чтение плана снизу вверх
План запроса следует читать снизу (листовые узлы) вверх к верху (корневой узел), следуя потоку данных:
-
Операции сканирования (нижний уровень): Операторы
SCANвнизу читают данные из базовых таблиц:SCAN [store_sales]читает основную таблицу фактов с предикатомss_hdemo_sk IS NOT NULLSCAN [time_dim]читает таблицу измерения времени с предикатамиt_hour = 8 AND t_minute >= 30SCAN [household_demographics]читает таблицу демографии с предикатомhd_dep_count = 5SCAN [store]читает таблицу магазинов с предикатомs_store_name = 'ese'
Каждая операция сканирования показывает:
- Estimates: Оценка количества строк, CPU, памяти, сети и затрат
- Соотношения секций и tablet: Сколько секций/tablet сканируется (например,
partitionRatio: 1/1, tabletRatio: 192/192) - Predicates: Условия запроса, которые проталкиваются до уровня сканирования, сокращая объем считываемых данных
-
Обмен данными (Broadcast): Операции
EXCHANGE(BROADCAST)распределяют меньшие таблицы измерений на все узлы, обрабатывающие большую таблицу фактов. Это эффективно, когда таблицы измерений малы по сравнению с таблицей фактов, как видно сtime_dim,household_demographicsиstore, которые транслируются. -
Операции соединения (средний уровень): Данные поступают вверх через операции
HASH/INNER JOIN:- Сначала
store_salesсоединяется сtime_dimпоss_sold_time_sk = t_time_sk - Затем результат соединяется с
household_demographicsпоss_hdemo_sk = hd_demo_sk - Наконец, результат соединяется с
storeпоss_store_sk = s_store_sk
Каждое соединение показывает условие соединения и оценки для результирующего количества строк и использования ресурсов.
- Сначала
-
Агрегация (верхний уровень):
AGGREGATE(LOCAL)выполняет локальную агрегацию на каждом узле, вычисляяcount()EXCHANGE(GATHER)собирает результаты со всех узловAGGREGATE(GLOBAL)объединяет локальные результаты в окончательный подсчет
-
Финальные операции (верхний уровень):
- Операции
TOP-100(PARTIAL)иTOP-100(FINAL)обрабатывают предложениеORDER BY count(*) LIMIT 100, выбирая верхние 100 результатов после упорядочивания
- Операции
Логический план предоставляет оценки затрат для каждой операции, помогая вам понять, где запрос тратит большую часть своих ресурсов. Фактический физический план выполнения (из EXPLAIN или EXPLAIN VERBOSE) включает дополнительные детали о том, как операции распределяются по узлам и выполняются параллельно.