Рецепты настройки запросов
Прагматичное руководство: симптом → коренная причина → проверенные решения. Используйте его, когда вы открыли profile и обнаружили тревожную метрику, но все еще нужно ответить на вопрос "что теперь?".
1 · Рабочий процесс быстрой диагностики
-
Просмотрите обзор выполнения Если
QueryPeakMemoryUsagePerNode > 80 %илиQuerySpillBytes > 1 GB, сразу переходите к рецептам по памяти и spillage. -
Найдите самый медленный Pipeline / Operator ⟶ В Query Profile UI нажмите Sort by OperatorTotalTime %. Самый горячий оператор подскажет, какой блок рецептов читать дальше (Scan, Join, Aggregate, …).
-
Подтвердите �подтип узкого места Каждый рецепт начинается со своего характерного паттерна метрик. Сверьте их перед применением исправлений.
2 · Рецепты по операторам
2.1 OLAP / Connector Scan [метрики]
Для облегчения понимания различных метрик внутри Scan Operator следующая диаграмма демонстрирует взаимосвязи между этими метриками и структурами хранения.
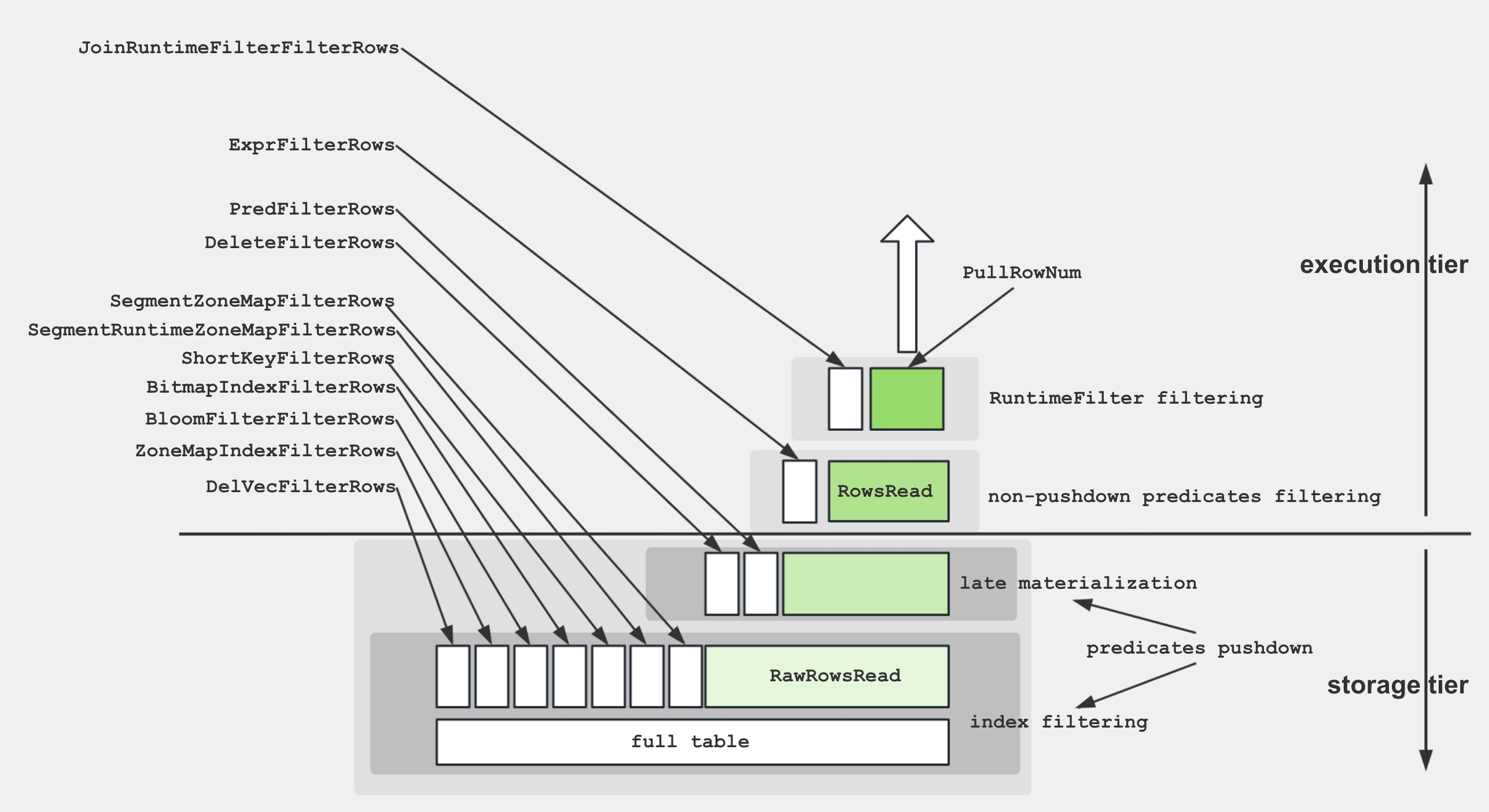
Для извлечения данных с диска и применения предикатов механизм хранения использует несколько техник:
- Хранение данных: Закодированные и сжатые данные хранятся на диске в сегментах, соп�ровождаемые различными индексами.
- Фильтрация по индексам: Движок использует индексы, такие как BitmapIndex, BloomfilterIndex, ZonemapIndex, ShortKeyIndex и NGramIndex, чтобы пропускать ненужные данные.
- Предикаты с Pushdown: Простые предикаты, такие как
a > 1, проталкиваются вниз для оценки на конкретных столбцах. - Поздняя материализация: С диска извлекаются только необходимые столбцы и отфильтрованные строки.
- Предикаты без Pushdown: Оцениваются предикаты, которые не могут быть протолкнуты вниз.
- Выражение проекции: Вычисляются выражения, такие как
SELECT a + 1.
Scan Operator использует дополнительный пул потоков для выполнения задач IO. Поэтому взаимосвязь между метриками времени для этого узла показана ниже:

Распространенные узкие места производительности
Холодное или медленное хранилище – Когда BytesRead, ScanTime или IOTaskExecTime доминируют и дисковый I/O находится около 80‑100 %, сканирование сталкивается с холодным или недостаточно выделенным хранилищем. Переместите горячие данные на NVMe/SSD и включите Data Cache. Настройте его через параметры BE datacache_* (или устаревшие block_cache_*) и включите использование во время сканирования через параметр сессии enable_scan_datacache.
Отсутствие push-down фильтров – Если PushdownPredicates остается близким к 0, а ExprFilterRows высокий, предикаты не достигают уровня хранилища. Перепишите их как простые сравнения (избегайте %LIKE% и широких цепочек OR) или добавьте индексы zonemap/Bloom или материализованные представления, чтобы они могли быть протолкнуты вниз.
Нехватка потоков в пуле – Высокий IOTaskWaitTime вместе с низким PeakIOTasks сигнализирует о насыщенной конкурентности I/O. Включите и настройте размер Data Cache (параметры BE datacache_* и параметр сессии enable_scan_datacache), переместите горячие данные на более быстрое хранилище (NVMe/SSD)
Перекос данных по tablet – Большой разрыв между максимальным и минимальным OperatorTotalTime означает, что некоторые tablet выполняют гораздо больше работы, чем другие. Перебакетируйте по ключу с большей кардинальностью или увеличьте количество bucket для распределения нагрузки.
Фрагментация rowset/segment – Растущие RowsetsReadCount/SegmentsReadCount плюс длинный SegmentInitTime указывают на множество крошечных rowset. Запустите ручную компакцию и пакетируйте небольшие загрузки, чтобы сегменты объединялись заранее.
Накопленные мягкие удаления – Большой DeleteFilterRows подразумевает интенсивное использование мягкого удаления. Запустите компакцию BE для очистки мягких удалений.
2.2 Aggregate [метрики]
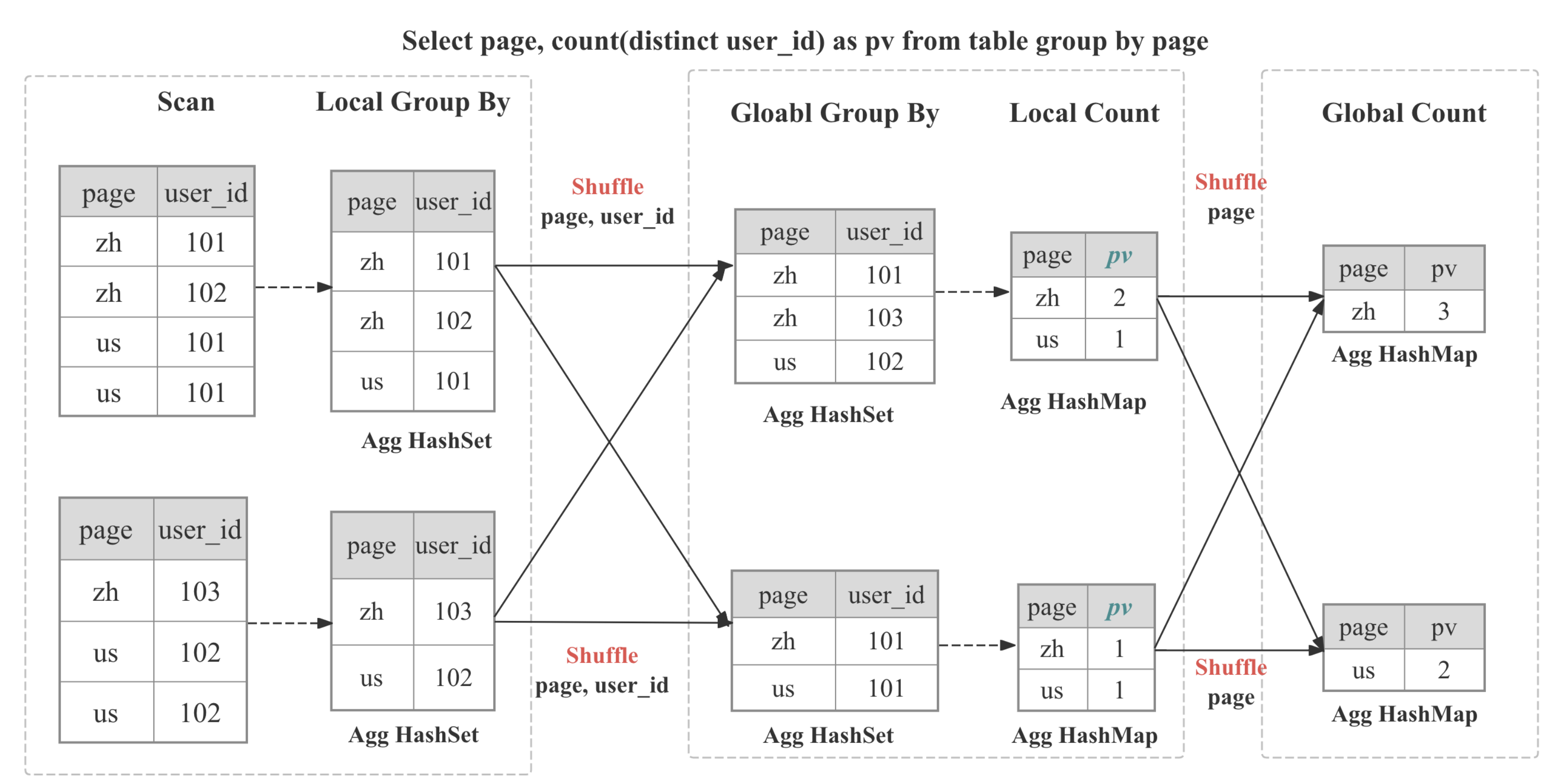 Aggregate Operator отвечает за выполнение функций агрегации,
Aggregate Operator отвечает за выполнение функций агрегации, GROUP BY и DISTINCT.
Множественные формы алгоритма агрегации
| Форма | Когда планировщик выбирает её | Внутренняя структура данных | Особенности / предостережения |
|---|---|---|---|
| Hash aggregation | ключи помещаются в память; кардинальность не экстремальная | Компактная хеш-таблица с SIMD-зондированием | путь по умолчанию, отлично подходит для умеренного количества ключей |
| Sorted aggregation | входные данные уже упорядочены по ключам GROUP BY | Простое сравнение строк + текущее состояние | нулевая стоимость хеш-таблицы, часто в 2-3× быстрее при перекосах с тяжелым зондированием |
| Spillable aggregation (3.2+) | хеш-таблица превышает лимит памяти | Гибридный хеш/слияние с дисковыми partitions | предотвращает OOM, сохраняет параллелизм pipeline |
Многоступенчатая распределенная агрегация
В Selena агрегация реализована распределенным образом, что может быть многоступенчатым в зависимости от паттерна запроса и решения оптимизатора.
┌─────────┐ ┌──────────┐ ┌────────────┐ ┌────────────┐
│ Stage 0 │ local │ Stage 1 │ shard/ │ Stage 2 │ gather/│ Stage 3 │ final
│ Partial │───► │ Update │ hash │ Merge │ shard │ Finalize │ output
└─────────┘ └──────────┘ └────────────┘ └────────────┘
| Стадии | Когда используется | Что происходит |
|---|---|---|
| Одноступенчатая | DISTRIBUTED BY является подмножеством GROUP BY, партиции совмещены | Частичные агрегаты сразу становятся финальным результатом. |
| Двухступенчатая (локальная + глобальная) | Типичная распределенная GROUP BY | Stage 0 внутри каждого BE адаптивно сворачивает дубликаты; Stage 1 перемешивает данные на основе GROUP BY, затем выполня�ет глобальную агрегацию |
| Трехступенчатая (локальная + shuffle + финальная) | Тяжелая DISTINCT и высококардинальная GROUP BY | Stage 0 как выше; Stage 1 перемешивает по GROUP BY, затем агрегирует по GROUP BY и DISTINCT; Stage 2 объединяет частичное состояние как GROUP BY |
| Четырехступенчатая (локальная + частичная + промежуточная + финальная) | Тяжелая DISTINCT и низкокардинальная GROUP BY | Вводит дополнительную стадию для перемешивания по GROUP BY и DISTINCT, чтобы избежать узкого места в одной точке |
Распространенные узкие места производительности
Высококардинальная GROUP BY – Когда HashTableSize или HashTableMemoryUsage раздуваются до лимита памяти, ключ группировки слишком широкий или слишком различный. Включите сортированную потоковую агрегацию (enable_streaming_preaggregation = true), создайте материализованное представление roll-up или приведите широкие строковые ключи к INT.
Перекос Shuffle – Большие различия в HashTableSize или InputRowCount между фрагментами выявляют несбалансированное перемешивание. Добавьте столбец salt к ключу или используйте подсказку DISTINCT [skew], чтобы строки распределялись равномерно.
Функции агрегации с тяжелым состоянием – Если AggregateFunctions доминирует во времени выполнения, а функции включают HLL_, BITMAP_ или COUNT(DISTINCT), перемещаются огромные объекты состояния. Предварительно вычислите HLL/bitmap-скетчи во время загрузки или переключитесь на приблизительные варианты.
Деградированная частичная агрегация – Огромный InputRowCount с умеренным AggComputeTime плюс массивный BytesSent в upstream EXCHANGE означает, что предварительная агрегация была обойдена. Принудительно включите её с помощью SET streaming_preaggregation_mode = "force_preaggregation".
Дорогие выражения ключей – Когда ExprComputeTime соперничает с AggComputeTime, ключи GROUP BY вычисляются п�острочно. Материализуйте эти выражения в подзапросе или продвиньте их в сгенерированные столбцы.
2.3 Join [метрики]
Join Operator отвечает за реализацию явных соединений или неявных соединений.
Во время выполнения оператор join разделяется на фазы Build (построение хеш-таблицы) и Probe, которые выполняются параллельно внутри движка pipeline. Векторные чанки (до 4096 строк) пакетно хешируются с SIMD; потребленные ключи генерируют runtime-фильтры — Bloom или IN фильтры — проталкиваемые обратно к upstream-сканированиям для раннего сокращения входных данных probe.
Стратегии Join
Selena опирается на векторизованное, дружественное к pipeline ядро hash-join, которое может быть подключено к четырем физическим стратегиям, которые оптимизатор на основе стоимости взвешивает во время планирования:
| Стратегия | Когда оптимизатор выбирает её | Что делает её быстрой |
|---|---|---|
| Colocate Join | Обе таблицы принадлежат к одной и той же colocation-группе (идентичные bucket-ключи, количество bucket и размещение replica).  | Нет сетевого перемешивания: каждый BE соединяет только свои локальные bucket. |
| Bucket-Shuffle Join | Одна из таблиц join имеет тот же bucket-ключ, что и ключ join | Необходимо перемешать только одну таблицу join, что может снизить сетевые затраты |
| Broadcast Join | Сторона Build очень мала (пороги строк/байтов или явная подсказка).  | Небольшая таблица реплицируется на каждый узел probe; избегает перемешивания большой таблицы. |
| Shuffle (Hash) Join | Общий случай, ключи не совпадают. | Хеш-партиционирование каждой строки по ключу join, чтобы probe-запросы были сбалансированы по BE. |
Распространенные узкие места производительности
Слишком большая сторона build – Скачки в BuildHashTableTime и HashTableMemoryUsage показывают, что сторона build переросла память. Поменяйте местами таблицы probe/build, предварительно отфильтруйте таблицу build или включите hash spilling.
Probe, неэффективный для кеша – Когда SearchHashTableTime доминирует, сторона probe не эффективна для кеша. Отсортируйте строки probe по ключам join и включите runtime-фильтры.
Перекос Shuffle – Если ProbeRows одного фрагмента затмевает все остальные, данные перекошены. Переключитесь на ключ с более высокой кардинальностью или добавьте salt, такой как key || mod(id, 16).
Случайный broadcast – Тип Join BROADCAST с огромным BytesSent означает, что таблица, которую вы считали маленькой, не является таковой. Снизьте broadcast_row_limit или принудительно используйте shuffle с подсказкой SHUFFLE.
Отсутствующие runtime-фильтры – Крошечный JoinRuntimeFilterEvaluate вместе с полнотабличными сканированиями предполагает, что runtime-фильтры никогда не распространялись. Перепишите join как чистое равенство и убедитесь, что типы столбцов совп�адают.
Откат к non-equi – Когда тип оператора CROSS или NESTLOOP, неравенство или функция предотвращает hash join. Добавьте истинный предикат равенства или предварительно отфильтруйте большую таблицу.
2.4 Exchange (сеть) [метрики]
Слишком большое shuffle или broadcast – Если NetworkTime превышает 30 % и BytesSent большой, запрос отправляет слишком много данных. Пересмотрите стратегию join и уменьшите объем shuffle/broadcast (например, принудительно используйте shuffle вместо broadcast или предварительно отфильтруйте upstream).
Очередь приемника – Высокий WaitTime в приемнике с очередями отправителя, которые остаются заполненными, указывает, что приемник не может справиться. Увеличьте пул потоков приемника (brpc_num_threads) и подтвердите настройки пропускной способности NIC и QoS.
Включите сжатие exchange – Когда пропускная способность сети являетс�я узким местом, сжимайте полезную нагрузку exchange. Установите SET transmission_compression_type = 'zstd'; и опционально увеличьте SET transmission_encode_level = 7;, чтобы включить адаптивное кодирование столбцов. Ожидайте более высокое использование CPU в обмен на уменьшенное количество байтов по сети.
2.5 Sort / Merge / Window
Для облегчения понимания различных метрик Merge можно представить в виде следующего механизма состояний:
┌────────── PENDING ◄──────────┐
│ │
│ │
├──────────────◄───────────────┤
│ │
▼ │
INIT ──► PREPARE ──► SPLIT_CHUNK ──► FETCH_CHUNK ──► FINISHED
▲
|
| one traverse from leaf to root
|
▼
PROCESS
Sort spilling – Когда MaxBufferedBytes поднимается выше примерно 2 GB или SpillBytes не равен нулю, фаза сортировки сбрасывается на диск. Добавьте LIMIT, предварительно агрегируйте upstream или поднимите sort_spill_threshold, если у машины достаточно памяти.
Нехватка Merge – Высокий PendingStageTime говорит вам, что merge ждет upstream-чанков. Сначала оптимизируйте оператор-производитель или увеличьте буферы pipeline.
Широкие партиции window – Огромный PeakBufferedRows внутри оператора window указывает на очень широкие партиции или ORDER BY, лишенный ограничений frame. Партиционируйте более детально, добавьте границы RANGE BETWEEN или материализуйте промежуточные агрегаты.
3 · Шпаргалка по памяти и spillage
| Порог | Что отслеживать | Практическое действие |
|---|---|---|
| 80 % памяти BE | QueryPeakMemoryUsagePerNode | Снизьте exec_mem_limit сессии или добавьте RAM в BE |
Обнаружен spill (SpillBytes > 0) | QuerySpillBytes, SpillBlocks для каждого оператора | Увеличьте лимит памяти; обновитесь до SR 3.2+ для гибридного hash/merge spill |
4 · Шаблон для вашего post-mortem
1. Симптом
– Медленная стадия: Aggregate (OperatorTotalTime 68 %)
– Тревожный сигнал: HashTableMemoryUsage 9 GB (> exec_mem_limit)
2. Коренная причина
– GROUP BY высококардинального UUID
3. Примененное исправление
– Добавлена сортированная потоковая агрегация + roll-up MV
4. Результат
– Время выполнения запроса ↓ с 95 s ➜ 8 s; пик памяти 0.7 GB```