Кластеризация таблиц
Продуманный ключ сортировки — это самый эффективный рычаг физического проектирования в Selena. Это руководство объясняет, как работает ключ сортировки под капотом, какие системные преимущества он открывает, и предоставляет конкретный план для выбора эффективного ключа для вашей рабочей нагрузки.
Пример
Предположим, у вас есть телеметрическая система, которая получает миллиарды строк в день, каждая помечена device_id и ts (timestamp). Определение ORDER BY (device_id, ts) для вашей таблицы фактов обеспечивает:
- Точечные запросы по
device_idвыполняются за миллисекунды. - Дашборды фильтруют последние временные окна для каждого устройства, отсекая большую часть данных.
- Агрегации вроде
GROUP BY device_idполучают выгоду от потоковой агрегации. - Сжатие улучшается благодаря последовательности близких временных меток для каждого устройства.
Этот простой двухколоночный ключ сортировки ORDER BY (device_id, ts) обеспечивает сокращение I/O, экономию CPU и более стабильную производительность запросов для миллиардов строк.
CREATE TABLE telemetry (
device_id VARCHAR,
ts DATETIME,
value DOUBLE
)
ENGINE=OLAP
PRIMARY KEY(device_id, ts)
PARTITION BY date_trunc('day', ts)
DISTRIBUTED BY HASH(device_id) BUCKETS 16
ORDER BY (device_id, ts);
Преимущества в деталях
-
Массовое устранение I/O — Pruning сегментов и страниц
Как это работает:
Каждый сегмент и страница в 64 КБ хранят минимальные/максимальные значения для всех колонок. Если предикат выходит за пределы этого диапазона, Selena пропускает весь блок и никогда не обращается к диску.
Пример:
SELECT count(*)
FROM events
WHERE tenant_id = 42
AND ts BETWEEN '2025-05-01' AND '2025-05-07';С
ORDER BY (tenant_id, ts)рассматриваются только сегменты, у которых первый ключ равен 42, и в них только те страницы, чье временное окно ts пересекается с этими семью днями. Таблица из 100 млрд строк может сканировать менее 1 млрд строк, превращая минуты в секунды.
-
Точечные поиски за миллисекунды — Sparse Prefix Index
Как это работает:
Разреженный префиксный индекс хранит каждое ~1000-е значение ключа сортировки. Бинарный поиск попадает на нужную страницу, затем одно чтение с диска (часто �уже в кэше) возвращает строку.
Пример:
SELECT *
FROM orders
WHERE order_id = 982347234;С
ORDER BY (order_id)поиск требует ≈ 50 сравнений ключей для таблицы из 50 млрд строк — латентность менее 10 мс даже на холодном кэше данных.
-
Более быстрая сортированная агрегация
Как это работает:
Когда ключ сортировки совпадает с GROUP BY, Selena выполняет потоковую агрегацию при сканировании — не требуется сортировка или хеш-таблица.
Этот план сортированной агрегации сканирует с�троки в порядке ключа сортировки и формирует группы на лету, используя локальность CPU-кэша и пропуская промежуточную материализацию.
Пример:
SELECT device_id, COUNT(*)
FROM telemetry
WHERE ts BETWEEN '2025-01-01' AND '2025-01-31'
GROUP BY device_id;Если таблица имеет
ORDER BY (device_id, ts), движок группирует строки по мере их поступления — без построения хеш-таблицы или пересортировки. Для высококардинальных ключей, таких как device_id, это может радикально снизить использование CPU и памяти.Потоковая агрегация с сортированным вводом обычно улучшает пропускную способность в 2–3× по сравнению с хеш-агрегацией для больших мощностей групп.
-
Более высокое сжатие и горячий кэш
Как это работает:
Сортированные данные показывают небольшие дельты или длинные последовательности, ускоряя словарное кодирование, RLE и frame-of-reference кодирование. Компактные страницы последовательно передаются через CPU-кэши.
Пример:
Таблица телеметрии, отсортированная по (device_id, ts), достигла в 1.8× лучшего сжатия (LZ4) и на 25% меньшего CPU/сканирование, чем те же данные, загруженные без сортировки.
Как работает ключ сортировки
Влияние ключа сортировки начинается с момента записи строки и сохраняется через каждую оптимизацию при чтении. Этот раздел проходит через жизненный цикл — путь записи ➜ иерархия хранения ➜ внутренности сегмента ➜ путь чтения — чтобы показать, как каждый слой усиливает ценность упорядочивания.
- Путь записи
- Ingest: строки попадают в MemTable, сортируются по объявленному ключу сортировки, затем сбрасываются как новый Rowset, содержащий один или несколько упорядоченных сегментов.
- Compaction: фоновые cumulative/base задачи объединяют множество маленьких Rowset'ов в более крупные, восстанавливая удаления и снижая количество сегментов без пересортировки, поскольку каждый исходный Rowset уже имеет тот же порядок.
- Replication: каждый Tablet (shard, владеющий Rowset'ом) синхронно реплицируется на узлы Back-End, гарантируя, что сортированный порядок согласован между репликами.
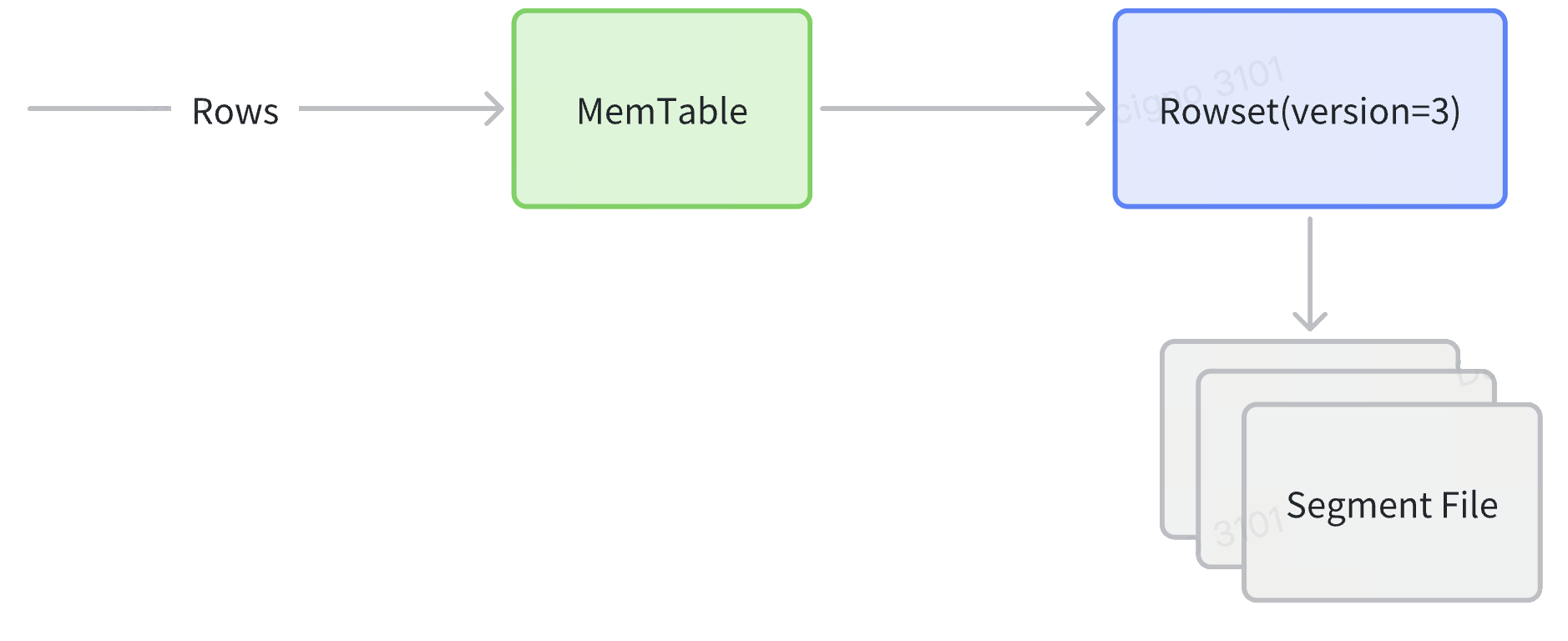
- Иерархия хранения
| Объект | Что это | Почему важно для ключа сортировки |
|---|---|---|
| Partition | Грубозернистый логический срез таблицы (например, дата или tenant_id). | Позволяет partition pruning на этапе планировщика и изолирует операции жизненного цикла (TTL, массовая загрузка). |
| Tablet | Hash/random bucket внутри partition, независимо реплицируемый между узлами Back-End. | Единица, строки которой физически упорядочены по ключу сортировки; весь внутрипартиционный pruning начинается здесь. |
| MemTable | Буфер записи в памяти (~96 МБ), который сортирует по объявленному ключу перед сбросом на диск. | Гарантирует, что каждый сегмент на диске уже упорядочен — внешняя сортировка не требуется позже. |
| Rowset | Неизменяемый набор одного или нескольких сегментов, созданный сбросом, потоковой загрузкой или циклом compaction. | Дизайн append-only позволяет Selena загружать данные одновременно, пока читатели остаются без блокировок. |
| Segment | Самодостаточный колоночный файл (~512 МБ) внутри Rowset'а, содержащий страницы данных плюс pruning-индексы. | Zone-map и prefix-и�ндексы на уровне сегмента зависят от порядка, установленного на этапе MemTable. |
- Внутри файла сегмента
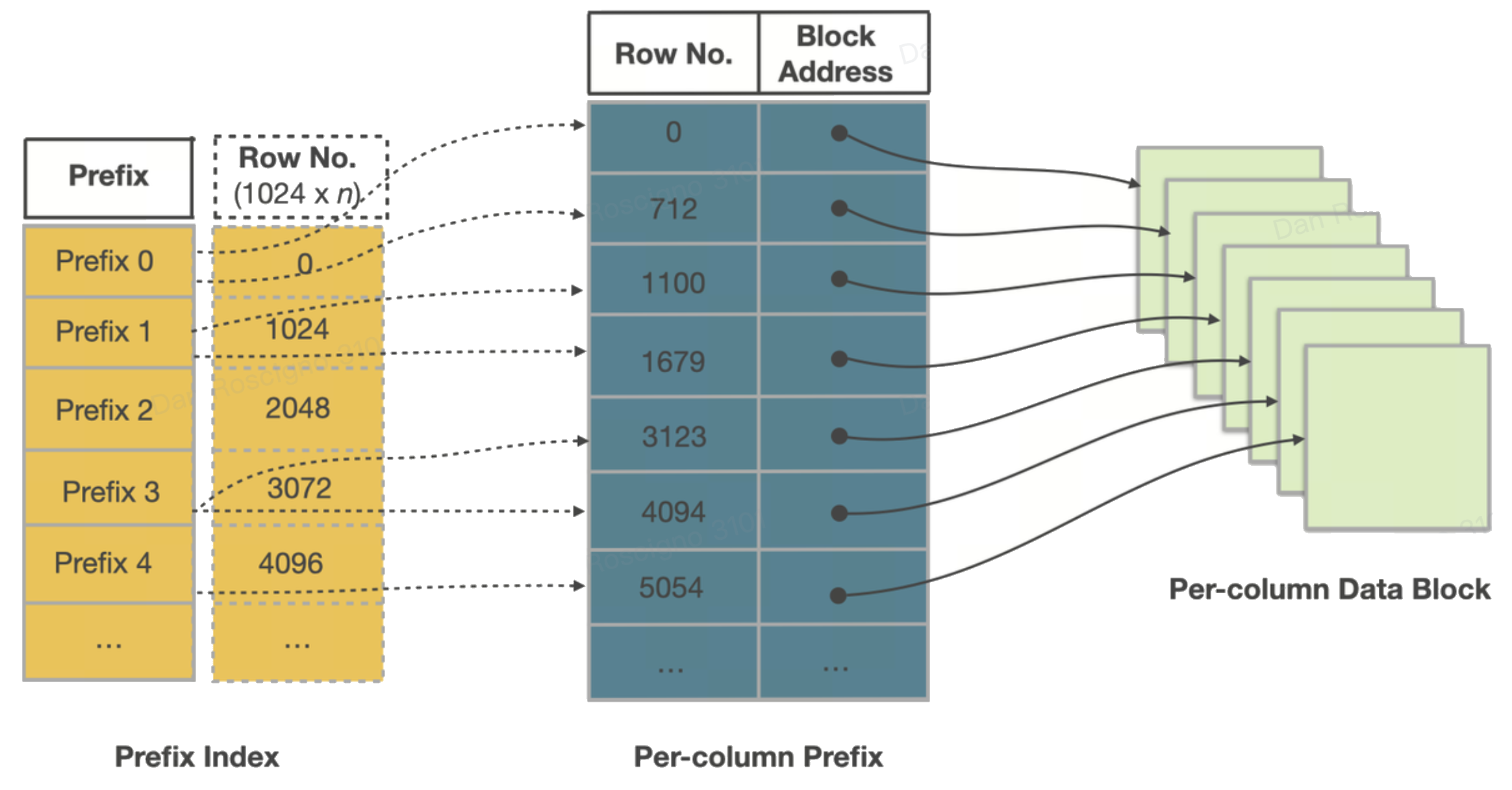
Каждый сегмент самоописываемый. Сверху вниз вы найдете:
- Страницы данных колонок: блоки по 64 КБ, закодированные (Dictionary, RLE, Delta) и сжатые (по умолчанию LZ4).
- Ordinal index: отображает порядковый номер строки → смещение страницы, чтобы движок мог перейти непосредственно к странице n.
- Zone-map index: min, max и has_null для каждой страницы и для всего сегмента — первая линия защиты для pruning.
- Short-key (prefix) index: разреженная таблица бинарного поиска первых 36 байт ключа сортировки каждые ~1K строк — позволяет точечные/диапазонные поиски за миллисекунды.
- Footer & magic number: смещения для каждого индекса и контрольная сумма для целостности; позволяет Selena отображать в память только хвост, чтобы обнаружить остальное.
Поскольку страницы уже отсортированы по ключу, эти индексы крошечные, но чрезвычайно эффективные.
-
Путь чтения
- Partition pruning (время планировщика): если WHERE ограничивает ключ partition (например,
dt BETWEEN '2025-05-01' AND '2025-05-07'), оптимизатор открывает только соответствующие каталоги partition. - Tablet pruning (время планировщика): когда фильтр равенства включает колонку хеш-распределения, Selena вычисляет целевые ID tablet'ов и планирует только эти Tablet'ы.
- Prefix-index seek: разреженный short-key индекс по ведущим колонкам сортировки направляет точно к нужному сегменту или странице.
- Zone-map pruning: метаданные min/max для каждого сегмента и страницы 64 КБ отбрасывают блоки, которые не попадают в окно предиката.
- Vectorized scan & late materialization: выжившие страницы колонок последовательно передаются через CPU-кэши; материализуются только ссылочные строки и колонки, сохраняя память тесной.
Поскольку данные зафиксированы в порядке ключа при каждом сбросе, каждый слой pruning при чтении усиливается предыдущим, обеспечивая сканирования менее секунды для таблиц с миллиардами строк.
- Partition pruning (время планировщика): если WHERE ограничивает ключ partition (например,
Как выбрать эффективный ключ сортировки
-
Начните с анализа рабочей нагрузки
Сначала проанализируйте top-N паттернов запросов:
- Предикаты равенства (
=/IN). Колонки, почти всегда фильтруемые по равенству, являются идеальными ведущими кандидатами. - Предикаты диапазона. Временные метки и числовые диапазоны обычно следуют за колонками равенства в ключе сортировки.
- Ключи агрегации. Если колонка диапазона также появляется в
GROUP BY, размещение её раньше в ключе (после селективных фильтров) может включить сортированную агрегацию. - Ключи join/group-by. Рассмотрите размещение ключей join или группировки рано, если они распространены.
Измерьте кардинальность колонок: высококардинальные колонки (миллионы различных значений) лучше всего отсекают данные.
- Предикаты равенства (
-
Эвристики и правила большого пальца
- Правило порядка: (высокоселективные колонки равенства) → (основная колонка диапазона) → (помощники кластера).
- Упорядочивание по кардинальности: размещение низкокардинальных колонок перед высококардинальными может улучшить сжатие данных.
- Ширина: держите 3‑5 колонок. Очень широкие ключи замедляют загрузку и переполняют 36-байтный лимит prefix-индекса.
- Строковые колонки: длинная ведущая строковая колонка может занять большую часть или весь 36-байтный лимит в prefix-индексе, не позволяя последующим колонкам в ключе сортировки эффективно индексироваться.
Это снижает мощность pruning prefix-индекса и ухудшает производительность точечных запросов.
-
Координируйте с другими рычагами проектирования
- Partitioning: выберите ключ partition, который грубее ведущей колонки сортировки (например,
PARTITION BY date,ORDER BY (tenant_id, ts)). Таким образом, partition pruning сначала удаляет целые диапазоны дат, а затем sort pruning очищает внутри. - Bucketing: использование одних и тех же колонок для bucketing и clustering служит разным целям. Bucketing обеспечивает равномерное распределение данных по cluster'у, в то время как сортировка позволяет эффективно устранять I/O.
- Тип таблицы: Primary-Key таблицы по умолчанию используют первичный ключ как ключ сортировки, но они также могут указывать дополнительные колонки для уточнения физического порядка и улучшения pruning. Aggregate и duplicate таблицы должны следовать стратегиям ключа сортировки, управляемым аналитическими предикатами, обсуждаемым выше.
- Partitioning: выберите ключ partition, который грубее ведущей колонки сортировки (например,
- Справочные шаблоны
| Сценарий | Partition | Ключ сортировки | Обоснование |
|---|---|---|---|
| B2C заказы | date_trunc('day', order_ts) | (user_id, order_ts) | Большинство запросов фильтруют сначала по пользователю, затем по последним временным диапазонам. |
| IoT телеметрия | date_trunc('day', ts) | (device_id, ts) | Чтения временных рядов с областью действия устройства доминируют. |
| SaaS Multi-Tenant | tenant_id | (dt, event_id) | Изоляция tenant'а через partition; сортировка кластеризует по дню для дашбордов. |
| Поиск в измерении | none | (dim_id) | Маленькая таблица, чистые точечные поиски — одной колонки достаточно. |
Заключение
Хорошо спроектированный ключ сортировки обменивает небольшие, предсказуемые накладные расходы при загрузке на радикальные улучшения латентности сканирования, эффективности хранения и использования CPU. Основывая свой выбор на реалиях рабочей нагрузки, уважая кардинальность и проверяя с помощью EXPLAIN, вы можете поддерживать Selena в работе, даже когда данные и количество пользователей растут в 10× и более.