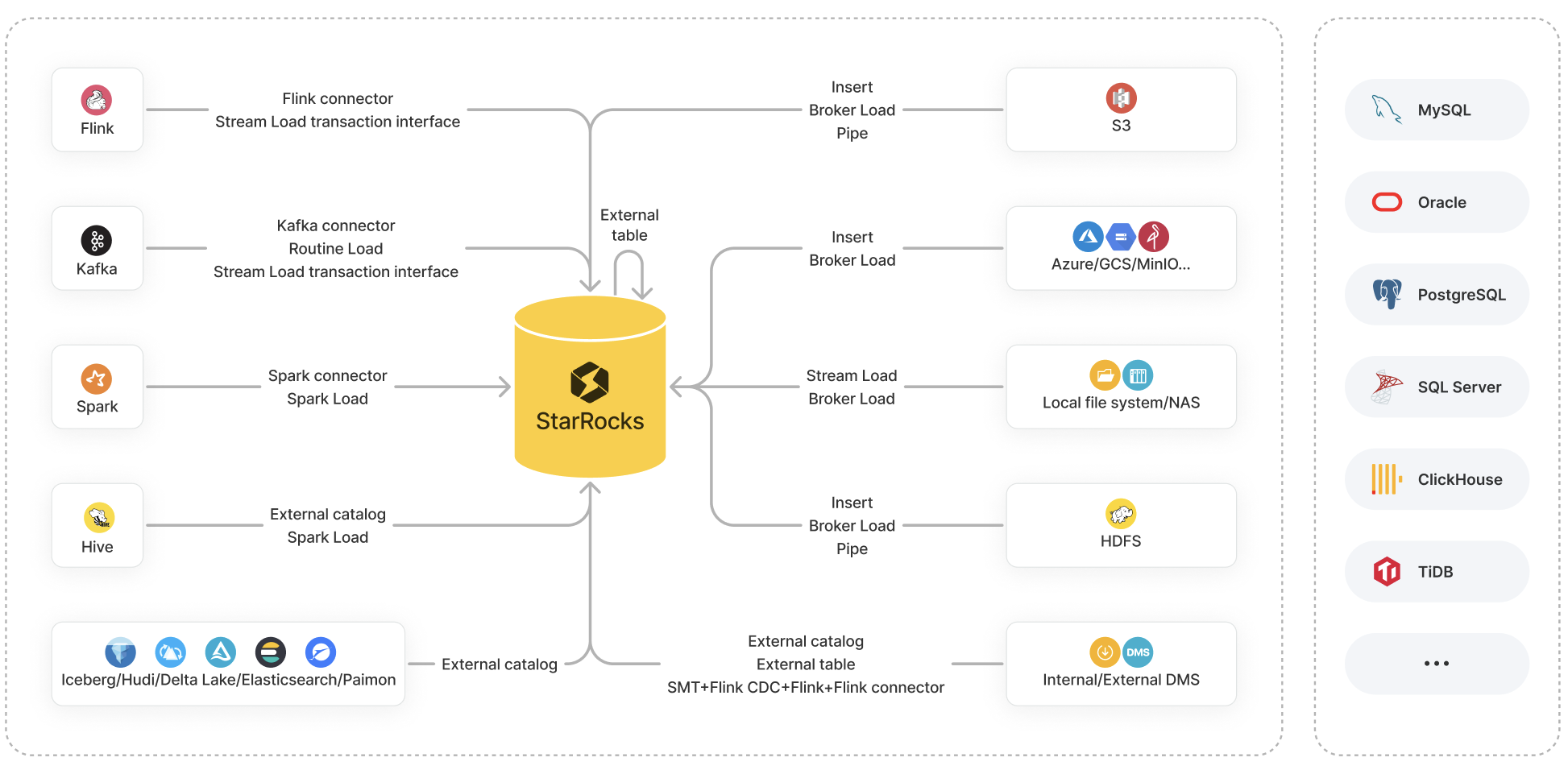
Варианты загрузки
Загрузка данных — это процесс очистки и преобразования необработанных данных из различных источников данных в соответствии с вашими бизнес-требованиями и загрузки результирующих данных в Selena для облегчения анализа.
Selena предоставляет множество вариантов загрузки данных:
- Методы загрузки: Insert, Stream Load, Broker Load, Pipe, Routine Load и Spark Load
- Инструменты экосистемы: Selena Connector for Apache Kafka® (сокращённо Kafka connector), Selena Connector for Apache Spark™ (сокращённо Spark connector), Selena Connector for Apache Flink® (сокращённо Flink connector) и другие инструменты, такие как SMT, DataX, CloudCanal и Kettle Connector
- API: Stream Load transaction interface
Каждый из этих вариантов имеет свои преимущества и поддерживает свой набор систем источников данных для извлечения данных.
В этом разделе представлен обзор этих вариантов, а также сравнения между ними, чтобы помочь вам определить вариант загрузки по вашему выбору на основе источника данных, бизнес-сценария, объёма данных, формата файла данных и частоты загрузки.
Введение в варианты загрузки
В этом разделе в основном описываются характеристики и бизнес-сценарии вариантов загрузки, доступных в Selena.
В следующих разделах "пакетная" или "пакетная загрузка" относится к загрузке большого объёма данных из указанного источника за один раз в Selena, тогда как "потоковая" или "потоковая передача" относится к непрерывной загрузке данных в реальном времени.
Методы загрузки
Insert
Бизнес-сценарий:
- INSERT INTO VALUES: Добавление небольших объёмов данных во внутреннюю таблицу.
- INSERT INTO SELECT:
-
INSERT INTO SELECT FROM
<table_name>: Добавление в таблицу результата запроса к внутренней или внешней таблице. -
INSERT INTO SELECT FROM FILES(): Добавление в таблицу результата запроса к файлам данных в удалённом хранилище.
примечаниеДля AWS S3 эта функция поддерживается начиная с версии v1.5.2. Для HDFS, Microsoft Azure Storage, Google GCS и S3-совместимого хранилища (такого как MinIO) эта функция поддерживается начиная с версии v1.5.2.
-
Формат файла:
- INSERT INTO VALUES: SQL
- INSERT INTO SELECT:
- INSERT INTO SELECT FROM
<table_name>: Таблицы Selena - INSERT INTO SELECT FROM FILES(): Parquet и ORC
- INSERT INTO SELECT FROM
Объём данных: Не фиксирован (Объём данных зависит от размера памяти.)
Stream Load
Бизнес-сценарий: Пакетная загрузка данных из локальной файловой системы.
Формат файла: CSV и JSON
Объём данных: 10 ГБ или менее
Broker Load
Бизнес-сценарий:
- Пакетная загрузка данных из HDFS или облачного хранилища, такого как AWS S3, Microsoft Azure Storage, Google GCS и S3-совместимое хранилище (такое как MinIO).
- Пакетная загрузка данных из локальной файловой системы или NAS.
Формат файла: CSV, Parquet, ORC и JSON (поддерживается начиная с v1.5.2)
Объём данных: От десятков ГБ до сотен ГБ
Pipe
Бизнес-сценарий: Пакетная или потоковая загрузка данных из HDFS или AWS S3.
Этот метод загрузки поддерживается начиная с версии v1.5.2.
Формат файла: Parquet и ORC
Объём данных: От 100 ГБ до 1 ТБ или более
Routine Load
Бизнес-сценарий: Потоковая загрузка данных из Kafka.
Формат файла: CSV, JSON и Avro (поддерживается начиная с v1.5.2)
Объём данных: От МБ до ГБ данных в виде мини-пакетов
Spark Load
Бизнес-сценарий: Пакетная загрузка данных таблиц Apache Hive™, хранящихся в HDFS, с использованием cluster Spark.
Формат файла: CSV, Parquet (поддерживается начиная с v1.5.2) и ORC (поддерживается начиная с v1.5.2)
Объём данных: От десятков ГБ до ТБ
Инструменты экосистемы
Kafka connector
Бизнес-сценарий: Потоковая загрузка данных из Kafka.
Spark connector
Бизнес-сценарий: Пакетная загрузка данных из Spark.
Flink connector
Бизнес-сценарий: Потоковая загрузка данных из Flink.
SMT
Бизнес-сценарий: Загрузка данных из источников данных, таких как MySQL, PostgreSQL, SQL Server, Oracle, Hive, ClickHouse и TiDB через Flink.
DataX
Бизнес-сценарий: Синхронизация данных между различными гетерогенными источниками данных, включая реляционные базы данных (например, MySQL и Oracle), HDFS и Hive.
CloudCanal
Бизнес-сценарий: Миграция или синхронизация данных из исходных баз данных (например, MySQL, Oracle и PostgreSQL) в Selena.
Kettle Connector
Бизнес-сценарий: Интеграция с Kettle. Объединяя мощные возможности обработки и преобразования данных Kettle с высокопроизводительными возможностями хранения и анализа данных Selena, можно достичь более гибких и эффективных рабочих процессов обработки данных.
API
Stream Load transaction interface
Бизнес-сценарий: Реализация двухфазной фиксации (2PC) для транзакций, которые выполняются для загрузки данных из внешних систем, таких как Flink и Kafka, при одновременном повышении производительности высококонкурентных потоковых загрузок. Эта функция поддерживается начиная с версии v1.5.2.
Формат файла: CSV и JSON
Объём данных: 10 ГБ или менее
Выбор вариантов �загрузки
В этом разделе перечислены варианты загрузки, доступные для распространённых источников данных, что поможет вам выбрать вариант, который лучше всего соответствует вашей ситуации.
Объектное хранилище
| Источник данных | Доступные варианты загрузки |
|---|---|
| AWS S3 |
|
| Microsoft Azure Storage |
|
| Google GCS |
|
| S3-совместимое хранилище (такое как MinIO) |
|
Локальная файловая система (включая NAS)
| Источник данных | Доступные варианты загрузки |
|---|---|
| Локальная файловая система (включая NAS) |
|
HDFS
| Источник данных | Доступные варианты загрузки |
|---|---|
| HDFS |
|
Flink, Kafka и Spark
| Источник данных | Доступные варианты загрузки |
|---|---|
| Apache Flink® | |
| Apache Kafka® |
Если исходные данные требуют соединений нескольких таблиц и операций извлечения, преобразования и загрузки (ETL), вы можете использовать Flink для чтения и предварительной обработки данных, а затем использовать Flink connector для загрузки данных в Selena. |
| Apache Spark™ |
Озёра данных
| Источник данных | Доступные варианты загрузки |
|---|---|
| Apache Hive™ |
|
| Apache Iceberg | (Пакетная) Создайте Iceberg catalog, а затем используйте INSERT INTO SELECT FROM <table_name>. |
| Apache Hudi | (Пакетная) Создайте Hudi catalog, а затем используйте INSERT INTO SELECT FROM <table_name>. |
| Delta Lake | (Пакетная) Создайте Delta Lake catalog, а затем используйте INSERT INTO SELECT FROM <table_name>. |
| Elasticsearch | (Пакетная) Создайте Elasticsearch catalog, а затем используйте INSERT INTO SELECT FROM <table_name>. |
| Apache Paimon | (Пакетная) Создайте Paimon catalog, а затем используйте INSERT INTO SELECT FROM <table_name>. |
Обратите внимание, что Selena предоставляет unified catalog начиная с версии v1.5.2, чтобы помочь вам работать с таблицами из источников данных Hive, Iceberg, Hudi и Delta Lake как с единым источником данных без загрузки.
Внутренние и внешние базы данных
| Источник данных | Доступные варианты загрузки |
|---|---|
| Selena | (Пакетная) Создайте внешнюю табл�ицу Selena, а затем используйте INSERT INTO VALUES для вставки нескольких записей данных или INSERT INTO SELECT FROM <table_name> для вставки данных таблицы.ПРИМЕЧАНИЕ Внешние таблицы Selena поддерживают только запись данных. Они не поддерживают чтение данных. |
| MySQL |
|
| Другие базы данных, такие как Oracle, PostgreSQL, SQL Server, ClickHouse и TiDB |
|